1.1什么是机器学习
Arthur Samuel(1959):在没有明确设置的情况下,是计算机具有学习能力的研究领域 Tom Mitchell (1998):计算机程序从经验E中学习,解决某一任务T,进行某一性能度量P,通过P测定在T上的表现因经验E而提高


监督学习:给一个算法数据集 ,其中包含了正确答案,也就是说我们给它一个房价数据集,我们都给出正确的价格,即这个房子实际卖价。算法的目的就是给出更多的正确答案。例如为你朋友想卖掉这个所新房子给出估价
回归问题:预测连续的数值输出
分类问题:预测离散值输出

1.2监督学习
监督学习:给一个算法数据集 ,其中包含了正确答案,也就是说我们给它一个房价数据集,我们都给出正确的价格,即这个房子实际卖价。算法的目的就是给出更多的正确答案。例如为你朋友想卖掉这个所新房子给出估价
回归问题:预测连续的数值输出
分类问题:预测离散值输出
1.3无监督学习
监督学习中,我们有一系列标签,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们由一系列标签,我们需要剧此拟合一个假设函数。
在无监督学习中,我们所给的数据都具有相同的标签或者都没有标签,拿到这个数据集后,不知道每个数据点究竟是什么,但是要在其中找到某种结构,我们拿到的数据就是下面这样的:
也就是说,在非监督学习中,我们需要将一系列无标签的训练数据,输入到一个算法中,然后我们告诉这个算法,快去为我们找找这个数据的内在结构给定数据。我们可能需要某种算法帮助我们寻找一种结构。图上的数据看起来可以分成两个分开的点集(称为簇),一个能够找到我圈出的这些点集的算法,就被称为聚类算法。
这将是我们介绍的第一个非监督学习算法。当然,此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者其他的一些模式,而不只是簇。
我们将先介绍聚类算法。此后,我们将陆续介绍其他算法。那么聚类算法一般用来做什么呢?<br />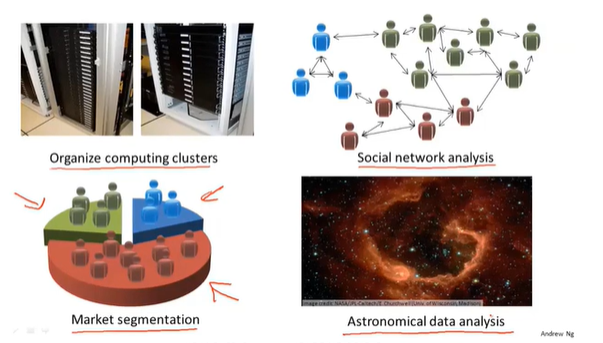我曾经列举过一些应用:比如市场分割。也许你在数据库中存储了许多客户的信息,而你希望将他们分成不同的客户群,这样你可以对不同类型的客户分别销售产品或者分别提供更适合的服务。最后,我实际上还在研究如何利用聚类算法了解星系的形成。然后用这个知识,了解一些天文学上的细节问题。好的,这就是聚类算法。这将是我们介绍的第一个非监督学习算法。在后面的学习中,我们将开始介绍一个具体的聚类算法。

若有收获,就点个赞吧
0 人点赞
