要学习编码算法,我们先来看一看什么是编码。
ASCII码就是一种编码,字母A的编码是十六进制的0x41,字母B是0x42,以此类推
| 字母 | ASCII编码 |
|---|---|
| A | 0x41 |
| B | 0x42 |
| C | 0x43 |
| D | 0x44 |
| … | … |
因为ASCII编码最多只能有127个字符,要想对更多的文字进行编码,就需要用Unicode。
中文的中使用Unicode编码就是0x4e2d,使用UTF-8则需要3个字节编码
| 汉字 | Unicode编码 | UTF-8编码 |
|---|---|---|
| 中 | 0x4e2d | 0xe4b8ad |
| 文 | 0x6587 | 0xe69687 |
| 编 | 0x7f16 | 0xe7bc96 |
| 码 | 0x7801 | 0xe7a081 |
| … | … | … |
因此,最简单的编码是直接给每个字符指定一个若干字节表示的整数,复杂一点的编码就需要根据一个已有的编码推算出来。(例如: I love you 用ASCII编码表示就是0x49 0x20 0x6C 0x6F 0x76 0x65 0x20 0x79 0x6F 0x75,是不是有内味了)。
URL编码
URLEncoder.encode("中文!",StandardCharsets.UTF_8);
URL编码是浏览器发送数据给服务器时使用的编码,它通常附加在URL的参数部分,例如[https://www.baidu.com/s?wd=%E4%B8%AD%E6%96%87](https://www.baidu.com/s?wd=%E4%B8%AD%E6%96%87)
之所以需要URL编码,是因为出于兼容性考虑,很多服务器只识别ASCII字符。但如果URL中包含中文、日文这些非ASCII字符怎么办?URL编码有一套规则
- 如果字符是A~Z,a~z,0~9以及
**-**``**_**``**.**``*****,则保持不变 。~~(ASCII码能表示的不变) ~~(属于ASCII码的也会对其编码) - 如果是其他字符,先转换为UTF-8编码,然后对每个字节以
**%XX**表示 - 空格字符
" "转换为加号"%20"
例如,字符中的UTF-8编码是0xe4b8ad,因此,它的URL编码是%E4%B8%AD,URL编码总是大写。
Java标准库提供了一个URLEncoder类来对任意字符串进行URL编码
public class Main {public static void main(String[] args){String encode = URLEncoder.encode("中文!","UTF-8");System.out.println(encoded);}}
上述代码运行结果是 %E4%B8%AD%E6%96%87%21,中的URL编码是%E4%B8%87,!虽然是ASCII字符,也要对其编码%21。
和标准的URL编码稍有不同,URLEncoder把空格字符编码成+,而现在的URL编码标准要求空格被编码为%20,不过,服务器都可以处理这两种情况。
URL编码解码
URLDecoder.decode("%E4%B8%AD%E6%96%87%21",StandardCharsets.UTF_8);
如果服务器收到URL编码的字符串,就可以对其进行解码,还原成原始字符串。Java标准库URLDecoder就可以解码
public class Main{
public static void main(String[] args){
String decoded = URLDecoder.decode("%E4%B8%AD%E6%96%87%21",StandardCharsets.UTF_8);
System.out.println(decoded);
}
}
要特别注意:URL编码是编码算法,不是加密算法。URL编码的目的是把任意文本数据编码为%前缀表示的文本,编码后的文本仅包含A~Z,a~z,0~9,-,_,.,*,%,便于浏览器和服务器处理。
Base64编码
URL编码是对字符进行编码,表示成%xx的形式,而Base64编码是对二进制数据进行编码,表示成文本格式。
Base64编码可以把任意长度的二进制数据变为纯文本,且只包含A~Z,a~z,0~9,+ 、/、= 这些字符。
每个字节8bit,3字节就是24位,按6bit一组正好是4组,每组用int表示。
它的原理是把每3字节的二进制数据按6bit一组,用4个int整数表示,然后查表(Base64索引表),把int整数用索引对应到字符,得到编码后的字符串。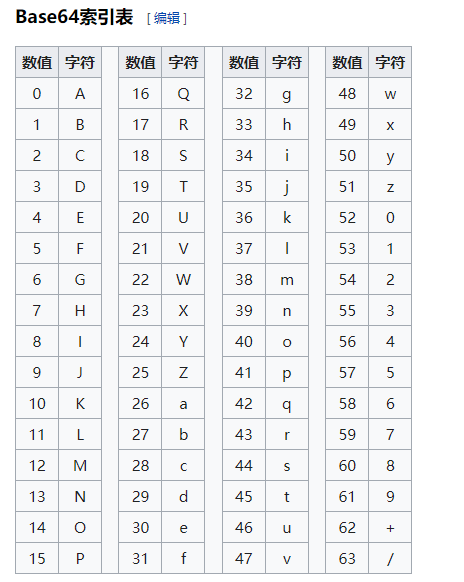
举个例子:3个byte数据分别是e4、b8、ad,按6bit分组得到39、0b、22和2d:
因为6位整数的范围总是0~63,所以,能用64个字符表示:字符A~Z 对应0~25,字符a~z对应索引26~51,字符0~9对应索引52~61,最后两个索引62、63分别用字符+和/。
在Java中,二进制数据就是byte[]数组,Java标准库提供了Base64来对byte[]数组进行编解码。
public class Main {
public static void main(String[] args){
byte[] input = new byte[] {(byte) 0xe4,(byte) 0xb8,(byte) 0xad};
String b64encoded = Base64.getEncoder().encodeToString(input);
System.out.pritnln(b64encoded);
}
}
编码后得到 5List4个字符,要对Base64解码,仍然用Base64这个类
public class Main{
public static void main(String[] args){
byte[] output = Base64.getDecoder().decode("5List");
System.out.println(Arrays.toString(output));
}
}
如果输入的byte[]数组长度不是3的整数倍怎么办?
这种情况下,需要对输入的末尾补一个或两个0x00,编码后,在结尾加一个=,表示补充了1个0x00,加两个=表示补充了2个0x00,解码的时候,去掉末尾补充的一个或两个0x00即可。
实际上,因为编码后的长度加上=总是4的位数,所以即使不加=也可以计算出原始输入的byte[]。Base64编码的时候可以用withoutPadding()去掉=,解码出来的结果是一样的。
public class Main {
public static void main(String[] args) {
byte[] input = new byte[] { (byte) 0xe4, (byte) 0xb8, (byte) 0xad, 0x21};
String b64enCoded = Base64.getEncoder().encodeToString(input);
String b64encoded2 = Base64.getEncoder().withoutPadding().encodeToString(input);
System.out.println(b64encoded);
System.out.println(b64encoded2);
byte[] output = Base64.getDecoder().decode(b64encoded2);
System.out.println(Arrays.toString(outpu));
}
}
因为标准的Base64编码会出现+、/、=,所以不适合把Base64编码后的字符串放到URL中。一种针对URL的Base64编码——可以在URL中使用的Base64编码,它仅仅是把+变成了-,/变成了_。
public class Main {
public static void main(String[] args) {
byte[] input = new byte[] { 0x01, 0x02, 0x7f, 0x00};
String b64encoded = Base64.geturlEncoder().encodeToString(input);
System.out.println(b64encoded);
byte[] output = Base64.getUrlDecoder().decode(b64encoded);
System.out.println(Arrays.toString(output));
}
}
Base64编码的目的是把二进制数据变成文本格式,这样在很多文本中就可以处理二进制数据。例如,电子邮件协议就是文本协议,如果要在电子邮件中添加一个二进制文件,就可以用Base64编码,然后以文本的形式传送。
Base64编码的缺点是传输效率会降低,因为它把原始数据的长度增加了1/3。
和URL编码一样,Base64编码是一种编码算法,不是加密算法。
如果把base64的64个字符编码表换成32个、48个或者58个,就可以使用Base32编码,Base48编码和Base58编码。字符越少,编码效率就会越低。
ASCII码,用一个字节(8bit)来表示,因为最高位始终是0,因此只有7位(128个,0~127)存储空间,主要存储的是英文字符和一些常用符号及特殊符号。
https://www.yuque.com/docs/share/371c8036-cb9b-4ed3-a522-f31b3a107800?# 《ASCII 码》
GB2312,用两个字节来表示,最高位始终是1,因此只有32767个存储空间,用来存储中文常用汉字。
Unicode编码,用两个字节或者更多字节来表示。
Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。 https://www.yuque.com/u835533/ieb2hl/ansu5f

若有收获,就点个赞吧
0 人点赞
