String
在Java中,String是一个引用类型,它本身也是一个class。但是Java编译器对String有特殊处理,即可以直接用"..."来表示一个字符串:
String s1 = "Hello!";
实际上,字符串在String内部是通过一个char[]数组表示的,因此,下面的写法也是可以的
String s2 =new String(new char[] {'H','e','l','l','0','!'});
Java字符串的一个重要特点就是字符串不可变 ,这种不可变性是通过内部的private final char[]字段,以及没有任何修改char[]的方法实现的。
public class Main{public static void main(String[] args) {String s = "Hello!";System.out.println(s);s = s.toUpperCase();System.out.println(s);}}
ps: 没兴趣可以直接跳到下一块
查看toUpperCase()源码时发现一个用法,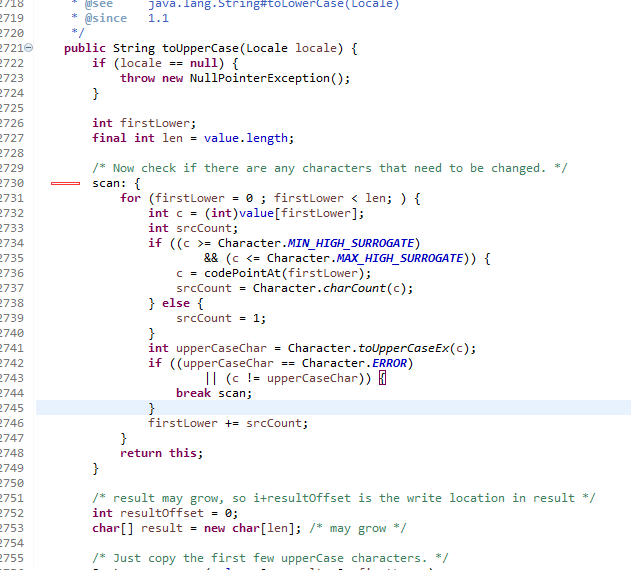
阿诚: https://docs.oracle.com/javase/specs/jls/se7/html/jls-14.html#jls-14.7 https://www.jianshu.com/p/7954b61bc6ee 一般场景没那么复杂的循环,如果这么复杂了,拆成多个函数比较好
张扬: 就是一个goto 功能 不建议使用 一般在多层for 循环的时候 可以直接break 到外层for
字符串比较
当我们想要比较两个字符串是否相同时,要特别注意,我们实际上是想比较字符串的内容是否相同。
必须使用equals()方法而不能用==。
public class Main{public static void main(String[] args){String s1 = "hello";String s2 = "hello";System.out.println(s1 == s2); //trueSystem.out.println(s1.equals(s2));//true}}
从表面上看,两个字符串用==和equals()比较都为true,但实际上那只是Java编译器在编译期,会自动把所有相同的字符串当作一个对象放入常量池,自然s1和s2的引用就是相同的。
所以,这种==比较返回true纯属巧合,换一种写法==就会失败
public class Main{public static void main(String[] args){String s1 = "hello";String s2 = "HELLO".toLowerCase();System.out.println(s1 ==s2);System.out.println(s1.equals(s2));}}
结论: 两个字符串比较,必须总是使用equals()方法
要忽略大小写比较,使用equalsIgnoreCase()方法
搜索字符串
"hello".contains("ll");//是否包含子串 true
注意到contains()方法的参数是CharSequence而不是String,因为CharSequence是String 的父类。
搜索子串的更多例子
"Hello".indexOf("l");//返回子串存在的索引,如果匹配失败会返回-1"Hello".lastIndexOf("l");//返回子串最后出现的索引,匹配失败会返回-1"Hello".starsWith("He");//是否以子串开始"Hello".endsWith("lo");//是否以子串结尾
索引从0开始
提取子串的例子:
"Hello".substring(2);//将从第三个字符开始一直截取到结尾"Hello world!".substring(2,10);//将从第三个字符开始截取到索引为10的字符,包含索引
去除首尾空白字符
使用trim()方法只可以移除字符串首尾空白字符。空白字符包括空格,\t,\r,\n
" \tHello\r\n ".trim();//Hello//strip jdk11"\u3000Hello\u3000".strip();//Hello" Hello ".stripLeading();//"Hello "" Hello ".stripTrailing();//" Hello"
替换子串
要在字符串中替换子串,有两种方法。一种是根据字符或字符串替换:
String s ="hello";s.replace('l','w');s.replace("ll","ww");
另一种是通过正则表达式替换:
String s = "A,,B;C ,D";s.replaceAll("[\\,\\\\s]+",",");
分割字符串
要分割字符串,使用split()方法,并且传入的也是正则表达式
String s = "A,B,C,D";String[] ss = s.split("\\,");
拼接字符串
拼接字符串使用静态方法join(),它用指定的字符串连接字符串数组
String[] ss = {"A","B","C"};String s = String.join("***",ss);
格式化字符串
字符串提供了formatted()方法和format()静态方法,可以传入其他参数,替换占位符,然后生成新的字符串。
public class Main{public static void main(String[] args) {String s = "Hi %s, your score is %d";System.out.println(s.formatted("Alice",90));//java 8 不能用System.out.println(String.format("Hi %s,your score is %.2f!","bob",50.9));}}
有几个占位符,后面就传入几个参数。参数类型要和占位符一致。我们经常用这个方法来格式化信息,常用的占位符有:
%s显示字符串%d显示整数%x显示十六进制%f显示浮点数
占位符还可以带格式,例如%.2f表示显示两位小数。如果你不确定用啥占位符,那就始终用%s,因为%s可以显示任何数据类型。
类型转换
要把任意基本类型或引用类型转换为字符串,可以使用静态方法valueOf()。这是一个重载方法,编译器会根据参数自动选择合适的方法
String.valueOf(123);String.valueOf(4.533);String.valueOf(true);//"true"String.valueOf(New Object());//java.lang.Object@15db9742
要把字符串转换为其他类型,就需要根据情况。例如,把字符串转换为int类型
int n1 = Integer.parseInt("123");//123int n2 = Integer.parseInt("ff",16);//255int n3 = Integer.parseInt("20",8);//16int n4 = Integer.parseInt("1111",2);//15int n5 = Integer.parseInt("20",7);//14int n6 = Integer.parseInt("f",20);//15int n7 = Integer.parseInt("j",20);//15double d1 = Double.parseDouble("123.212");
字符串转boolean
boolean b1 = Boolean.parseBoolean("true");//true
boolean b2 = Boolean.parseBoolean("FALSE");//false
boolean b3 = Boolean.parseBoolean("1");//false
要特别注意,Integer有个getInteger(String)方法,它不是将字符串转换为int,而是把该字符串对应的系统变量转换为Integer
Integer.getInteger("java.version");//我的返回了个Null??
转换为char[]
String和char[]类型可以互相转换,方法是
char[] cs = "Hello".toCharArray();//String -> char[]
String s = new String(cs);//char[] -> String
如果修改了char[]数组,String并不会改变
public class Main{
public static void main(String[] args){
char[] cs = "Hello".toCharArray();
String s = new String(cs);
System.out.println(s);
cs[0] = 'X';
System.out.println(s);
}
}
这是因为通过new String(char[])创建新的String实例时,它并不会直接引用传入的char[]数组,而是分复制一份,所以,修改外部的char[]数组不会影响String实例内部的char[]数组,因为这是两个不同的数组。
从String的不变性设计可以看出,如果传入的对象有可能改变,我们需要复制而不是直接引用。
例如下面的代码设计了一个Score类保存一组学生的成绩
public class Main{
public static void main(String[] args){
int[] scores = new int[] {88,77.51,66};
Score s = new Score(scores);
s.printScores();
scores[2] = 99;
s.printScores();
}
}
class Score {
private int[] scores;
public Score(int[] scores){
this.scores = scores;
}
public void printScores(){
System.out.println(Arrays.toString(scores));
}
}
观察两次输出,由于Score内部直接引用了外部传入的int[]数组,这会造成外部代码对int[]数组的修改,影响到Score类的字段。如果外部代码不可信,这就会造成安全隐患。
请修复Score的构造方法,使得外部代码对数组的修改不影响Score实例的int[]字段。
//参考new String(char[])源码,所以只需要在赋值时将数组复制一份即可
public Score(int[] scores){
this.scores = Arrays.copyOf(scores,scores.length);
}
//还有一种使用`clone` 的方法,用法类似
this.scores = scores.clone();
字符编码
在早期的计算机系统中,为了给字符编码,美国国家标准学会(American National Standard Institute:ANSI)制定了一套英文字母、数字和常用符号的编码,它占用一个字节,编码范围从0到127,最高位始终为0,称为ASCII编码。例如,字符'A'的编码是0x41,字符'1'的编码是0x31。
如果要把汉字也纳入计算机编码,很显然一个字节是不够的。GB2312标准使用两个字节表示一个汉字,其中第一个字节的最高位始终为1,以便和ASCII编码区分开。
例如,汉字'中'的GB2312编码是0xd6d0,类似的,日文有Shift_JIS编码,韩文有EUC-KR编码,这些编码因为标准不统一,同时使用,就会产生冲突。
为了统一全球所有语言的编码,全球统一码联盟发布了Unicode编码,它把世界上主要语言都纳入同一个编码,这样,中文、日文、韩文和其他语言就不会冲突 。
Unicode编码需要两个或者更多字节表示,我们可以比较中英文字符在ASCII、GB2312和Unicode的编码

英文字符的Unicode编码就是简单地在前面添加一个00字节。
中文字符'中'的GB2312编码和Unicode编码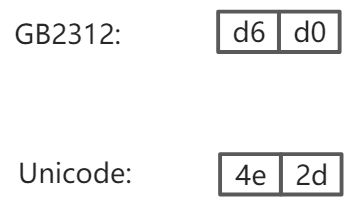
那我们经常使用的UTF-8又是什么编码呢?因为英文字符的Unicode编码高字节总是00,包含大量英文的文本会浪费空间,所以,出现了UTF-8编码,用来把固定长度的Unicode编码变成1~4字节的变长编码。通过UTF-8编码,英文字符A的UTF-8编码变为0x41,正好和ASCII一致,而中文'中'的UTF-8编码为3字节0xe4b8ad。UTF-8编码的另一个好处是容错能力强。如果传输过程中某些字符出错,不会影响后续字符,因为UTF-8编码依靠高字节位来确定一个字符究竟是几个字节,它经常用来作为传输编码。
在Java中,char类型实际上就是两个字节的Unicode编码,如果有我们要手动把字符串转换成其他编码,可以
byte[] b1 = "Hello".getBytes();//按系统默认编码转换,不推荐
byte[] b2 = "Hello".getBytes("UTF-8");//按UTF-8编码转换 java8不能用
byte[] b3 = "Hello".getBytes("GBK");//按GBK编码转换 java8不能用
byte[] b4 = "Hello".getBytes(StandardCharsets.Utf_8);//按UTF-8编码转换
注意:转换编码后,就不再是char类型,而是byte类型表示的数组。
如果要把已和编码的byte[]转换为String,可以这么做
byte[] b = ...;
String s1 = new String(b,"GBk");
String s2 = new String(b,StandardCharsets.UTF-8);//按UTF8转换
:::warning
始终牢记:Java的String和char在内存中总是以Unicode编码表示
:::
延伸阅读
对于不同版本的JDK,String类在内存中有不同的优化方式。具体来说,早期JDK版本String 总是以char[]存储,它的定义如下
public final class String {
private final char[] value;
private final int offset;
private final int count;
}
而较新的JDK版本的String则以byte[]存储:如果String仅包含ASCII字符,则每个byte存储一个字符,否则,每两个byte存储一个字符,这样做的目的是为了节省内存,因为大量的长度较短的String通常仅包含ASCII字符
public final class String {
private final byte[] value;
private final byte coder;// 0 = LATIN,1= UTF16
}
小结:
- Java字符串
String是不可变对象 - 字符串操作不改变原字符串内容,而返回新字符串
- 常用的字符串操作:提取子串、查找、替换、大小写转换等
- Java使用Unicode编码表示
String和char - 转换编码就是将
String和byte[]转换,需要指定编码 - 转换为
byte[]时,始终优先考虑UTF-8编码

若有收获,就点个赞吧
0 人点赞
