建筑应该反应时代特征与地理特征,同时追求永恒 —-Frank Gehry
DDD的一大好处便是它并不需要使用特定的架构。由于核心域位于限界上下文中,我们可以在整个系统中使用多种风格的架构。有些架构包围这领域模型,能够全局性地影响系统,而有些架构则满足了某些特定的需求。我们的目标是选择适合于自己的架构和架构模式。
对架构风格和模式的选择受到功能需求的限制,比如用例或用户故事。换句话说,在没有功能需求的情况下,我们是不能对软件质量做出评价的,亦不能做出正确的架构选择。这也说明用例驱动架构在当今的软件开发中依然适用。
分层
分层架构模式被认为是所有架构的始祖。它支持N层架构系统,因此被广泛地应用于web、企业级应用和桌面应用。在这种架构中,我们将一个应用程序或者系统分为不同的层次。
图4.1所示为一个典型的DDD系统采用的传统分层架构,其中核心域只位于架构中的其中一层,其上为用户层界面(User Interface)和应用层(Application Layer),其下是基础设施层(Infrastructure Layer)。
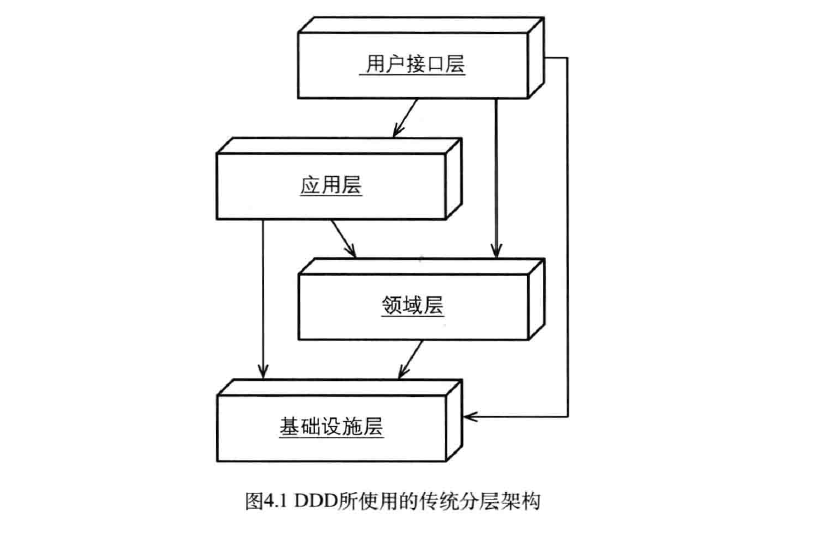
分层架构的一个重要原则是:每层只能与位于其下方的层发生耦合。
- 在严格分层架构(Strict Layers Architecture)中,某层只能与直接位于其下方的层发生耦合
- 而松散分层架构(Relaxed Layers Architecture),则允许任务上方层与任意下方层发生耦合。
由于用户界面和应用服务通常需要与基础设施打交道,许多系统都是基于松散分层架构的。
事实上,较低层也是可以和较高层发生耦合的,但只局限于采用观察者(Observer)模式和调停者模式(Mediator)模式的情况。较低层是绝对不能直接访问较高层的。
例如,在使用调停者模式时,较高层肯实现了较低层的接口,然后将实现对象作为参数传递到较低层。当较低层调用该实现时,并不知道实现出自何处。
用户接口层
用户接口层只用于处理用户显示和用户请求,它不应该包含领域或业务逻辑。有人可能认为,既然用户界面需要对用户界面需要对用户输入进行验证,那么它就应该包含业务逻辑。事实上,用户界面所进行的验证和对领域验证是不同的。
应用层
应用服务(Application Services)位于应用层中。应用服务和领域服务是不同的,因此领域逻辑也不应该出现在应用服务中。
应用服务可以用于控制持久化事务和安全认证。或者想其他系统发送基于事件消息通知,另外还可以用于创建邮件以发送给用户。
应用服务并不处理业务逻辑,但它却是领域模型的直接客户。应用服务是轻量的,它主要用于协调对领域对象的操作,比如聚合。同时,应用服务是表达用例和用户故事的主要手段。
因此,应用层服务的通常用户是:接受来自用户界面的输入参数,在通过资源库获取到聚合实例,然后执行相应的命令操作。
六边形架构(端口与适配器)
在六边形架构中,Alistair Cockburn提出了一种具有对称性特征的架构风格。在这种架构中,不同的客户通过“平等”的方式与系统交互。需要新的客户?不是问题。只需要添加一个新的适配器将客户输入转化成能被系统API所理解的参数就行。同时,系统输出,比如图形界面、持久化和消息等都可以通过不同方式实现,并且是可互换的。这是可能的,因为对于每种特定的输出,都有一个新建的适配器复制完成相应的转化功能。
在图4.4中,每种类型的客户都有它自己的适配器,该适配器用于将客户输入转化为程序内部APi所能理解的输入。六边形每条不同的边代表了不同类型的端口,端口要么处理输入,要么处理输出。图4.4中有3个客户请求均抵达相同的输入端口(适配器A,B和C),另一个客户请求使用适配器D。可能前3个请求使用了HTTp协议,而后一个请求使用了AMQP协议。
端口并没有明确的定义,它是一个非常灵活的概念。无论采用哪种方式对端口进行划分,当客户请求到达时,都应该有相应的适配器对输入进行转化,然后端口将调用应用程序的某个操作或者向应用程序发送一个事件,控制权由此交给内部区域。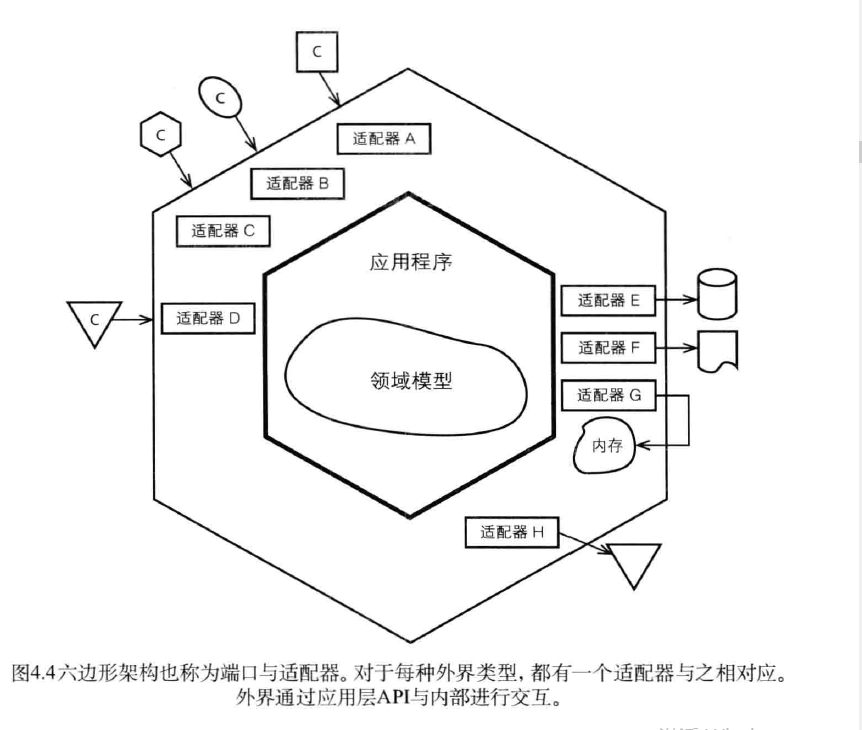
对于图4.4中的右侧的端口和适配器,我们应该如何看待呢?我们可以将资源库的实现看作是持久化适配器,该适配器用于访问先前存储的聚合实例,或者保存新的聚合实例。
六边形架构的一大好处在于,我们可以轻易地开发用于测试的适配器。整个应用程序和领域模型可以在没有客户和存储机制的条件下进行设计开发。在测试时,我们可以方便地对ProductService进行替换,而无需考虑它是应该支持Http、REST呢还是SOAP呢,或者是消息端口。
六边形架构的功能如此强大,以致于他可以用来支持系统中的其他架构。比如,我们可能采用SOA架构、REST或者事件驱动;也有可能采用CQRS;或者数据网织或基于网格的分布式缓存;还有可能采用Map-Reduce这种分布式并行处理方式。
面向服务架构
面向服务架构(Service-Oriented Architecture,SOA)对于不同的人来说具有不同的意思。这对于讨论SOA架构来说可能是一种架构来说可能是一种挑战,因此我们最好能找到一些共同的基础,或者至少应该给出一些定义以便讨论。服务除了拥有互操作性外,还具有以下8中设计原则。
| 服务设计原则 | 描述 |
|---|---|
| 服务契约 | 通过契约文档,服务阐述自身的目的与功能 |
| 松耦合 | 服务将依赖关系最小化 |
| 服务抽象 | 服务只发布契约,而项客户隐藏内部逻辑 |
| 服务重用性 | 一种服务可以被其他服务所重用 |
| 服务自治性 | 服务咨询控制环境与资源以保持独立性,这有助于保持服务的一致性和可靠性 |
| 服务的无状态性 | 服务负责消费方的状态管理,这不能与服务的自治性发生冲突 |
| 服务可发现性 | 客户可以通过服务元数据来查找服务和理解服务 |
| 服务的组合型 | 一种服务可以由其他的服务组合而成,而不管其他服务的大小和复杂性如何 |
我们可以将这些原则和六边形架构结合起来,此时服务边界位于最左侧,而领域模型位于中心位置,如图4.5所示。消费方可以通过REST、SOAP和消息机制获取服务。请注意,一个六边形架构系统支持多种类型的服务端点(Endpoint),这依赖于DDD是如何应用于SOA的。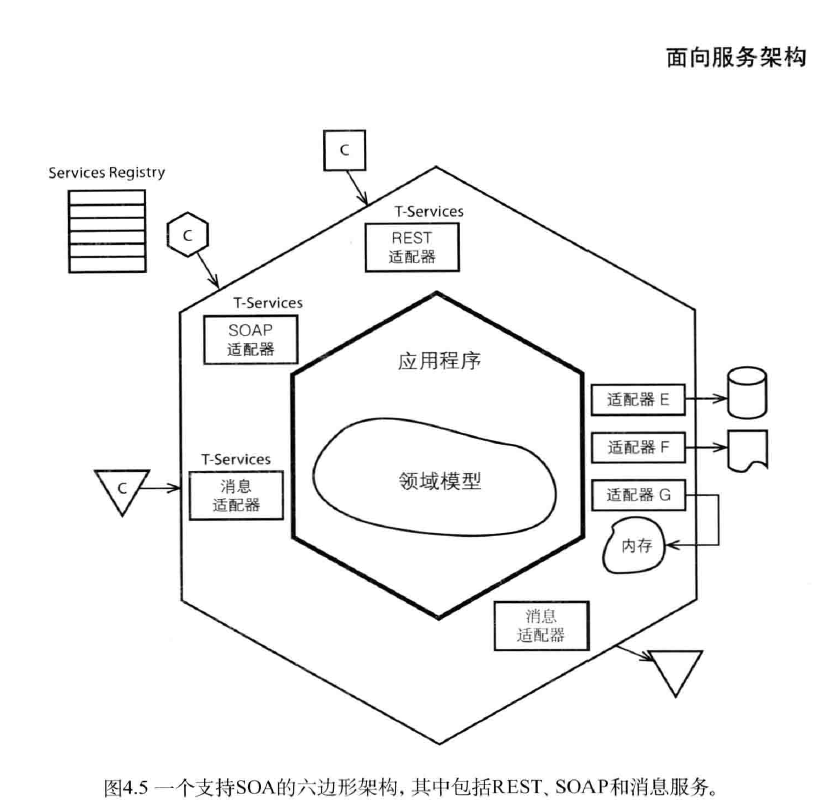
REST
在过去几年里,REST成为了一种被广泛使用,甚至被滥用的架构流行语。和SOA一样,不同的人对于REST有不同的理解。有人认为REST就是使用HTTP来直接发送XML的,但并不采用SOAP规范;还有人采用相似的方法来解释道:REST就是用HTTP来发送JSON数据的;以上的解释都是错误的。
REST作为一种架构风格
架构风格之与架构就想设计模式一样。它将不同架构实现所共同的东西抽象出来,使得我们在谈及到架构时不至于陷入技术细节中。分布式系统架构存在着多种架构风格,包括客户端-服务端架构风格和分布式对象风格。
RESTful HTTP服务器的关键方面
那么,对于采用“RESTful HTTP”的分布式系统来说,它具有哪些关键方面呢?让我们先来看看服务器端。请注意,在我们讨论服务器端时,无论客户是操作Web浏览器的某个人,还是有编程语言开发的客户端程序,对它们都是同等处理的,没有区别。
首先,就像其名字所指出的,资源是关键概念。作为一个系统设计者,你决定哪些有意义的“东西”一个唯一的身份标识。
通常来说,每种资源都拥有一个URI,更重要的是,每个URI都需要只想某个资源———即向外界暴露的“东西”。比如,你可能会做出这样决定:每一个客户、产品、产品列表、搜索结果和每次对产品目录的修改都应该分别作为一种资源。资源是具有展现(representation)和状态的,这些展现的格式可能不同。
客户通过资源的展现与服务器交互,格式可以为XML,JSON,HTML或二进制数据。
另一个关键方面是无状态通信,此时我们将采用具有自描述功能的消息。比如,HTTP请求便包含了服务器所需的所有信息。当然服务器也可以使用其本身的状态来辅助通信,但是重要的是: 我们不能依靠请求本身来创建一个隐式上下文环境(对话)。无状态通信保证了不同请求之间的相互独立性,这在很大程度上提高了系统的可伸缩性。
如果你将资源看做对象———这是合理的的。每一个对象都支持相同的接口。在RESTful HTTP中,对象方法便可以表示为可以操作资源的HTTP动词,其中最重要的有GET、PUT、POST和DELETE。
虽然乍一看这些方法将会转化成CRUD操作,但是事实却并非如此。通常我们所创建的资源并不代表任何持久化实体,而是封装了某种行为,当我们将HTTP动词应用到这些资源上时,我们实际上是在调用这些行为。
REST和DDD
Restful HTTP是具有诱惑力的,但是我们并不建议将领域模型直接暴露给外界,因为这会使得系统接口变得非常脆弱,原因在于对领域模型的每次改变都会导致对系统接口的改变。要将DDD与RESTful HTTP合并起来使用,我们有两种方法。
第一种方法是为系统接口层单独创建一个限界上下文,再在此上下文中通过适当的策略来访问实际的核心模型。这是一种经典的方法,它将系统接口看做一个整体,通过资源抽象将系统功能暴露给外界,而不是通过服务或者远程接口。
让我们看一个实际的例子。我们创建一份系统来管理工作组,其中包括任务、计划、预约和子工作组管理等。我们将创建一个纯净的、不受架构影响的领域模型,该模型能正确的反映通用语言。如果要为这个领域模型发布一个接口,我们便可以通过REST资源的形式向外提供一个远程接口。这些资源反映了客户所需的用例,它们和领域模型是存在区别的。但是每一种资源归根结底都创建自核心域。
命令和查询职责分离——CQRS
有没有一种完全不同的方法可以将领域数据映射到界面显示中呢?答案是CQRS(cammand-Query Resposibility Segregation)。CQRS是将紧缩(Stringgent)对象(或者组件)设计原则和命令—-查询分离(CQS)应用的架构模式的结果。
Bertrand Meyer对CQRS模式有一下评述
一个方法要么是执行某种动作的命令,要么是返回数据的查询,而不能两者皆是。换句话说,问题不应该对答案进行修改。更正式的解释是,一个方法只有在具有参考透明性时才返回数据,此时该方法不会产生副作用。
在对象层面,这意味着:
- 如果一个方法修改了对象的状态,该方法便是一个命令(Command),它不应该返回数据。在Java和C#中,这样的方法应该声明为void。
- 如果一个方法返回了数据,该方法便是一个查询(Query),此时它不应该通过直接的或间接的手段修改对象的状态。在Java和C#中,这样的方法应该以其返回的数据类型进行声明。
这样的指导原则是非常直接明了的,同时具有实践和理论基础作为支撑。但是在DDD的架构模式中,我们为什么应该使用CQRS呢,又如何使用CQRS呢?
在领域模型中——比如限界上下文中所讨论的领域模型——-我们通常会看到同时包含命令和查询的聚合。同时,我们也经常在资源库中看到不同的查找方法,这些方法对对象进行过滤。但是CQRS中,我们将忽略这些看似常态的情形,我们将通过不同的方式来查询用于显示的数据。
现在,对于同一模型,考虑将那些纯粹的查询功能从命理功能中分离看来。聚合将不再有查询方法,而只有命令方法。资源库也将只有add()或save()方法(分别支持创建和更新操作),同时只有一个查询方法,比如formId()。这个唯一的查询方法将聚合的身份表示作为参数,然后返回该聚合实例。
资源库不能使用其他方法来查询聚合,比如对属性进行过滤等。在将所有的查询方法移除后,我们此时的模型称为命令模型(Command Model)。但是我们仍然需要向用户显示数据,为此我们将创建第二个模型,该模型专门用于优化查询,我们称之为查询模型(Query Model)。
CQRS的各个方面
接下来,让我们依次了解CQRS模式的各个方面。我们先从客户端和查询模型开始,再了解命令模型。
客户端和查询处理器
客户端可以是Web浏览器,也可以是定制开发的桌面应用程序。它们将使用运行在服务器端的一组查询处理器。图4.6并没有显示服务器的架构层次。不管使用什么样的架构层,查询处理器都表示一个只知道如何向数据库执行基本查询(比如SQL)的简单组件。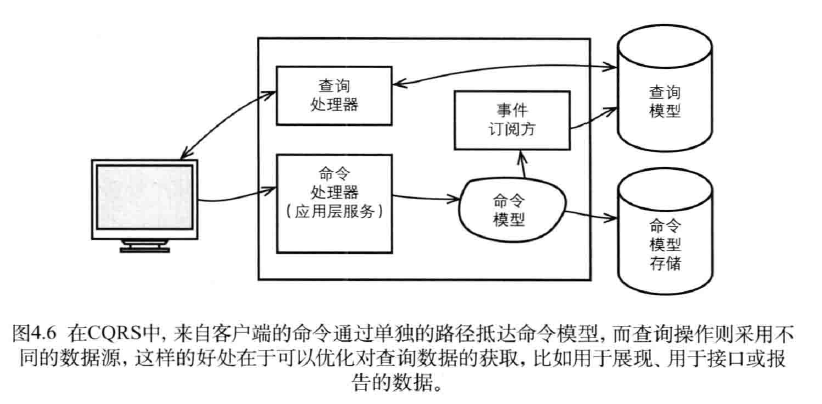
查询模型(读模型)
查询模型是一种非规范数据模型,它并不反应领域行为,只是用于数据显示(也可能是生成数据报告)。如果数据模型是SQL数据库,那么每张数据库表便是一种数据显示视图,它可以包含很多列,甚至是所显示数据的一个超集。表视图可以多张表进行创建,此时每张表代表整个显示数据的一个逻辑子集。
值得一提的是,创建CQRS数据视图可以是非常廉价的,特别是在使用单种形式的事件源(Event Sourcing)时,此时所有的事件都将持久化,这样在任何时候我们都可以重新发布显示数据,我们也可以重建单个显示视图,或者将整个查询模型转向另外的持久化机制。事件源使我们可以简单地创建和维护显示视图以响应UI的变化,这样我们可以在不考虑数据库表结构的前提下获得更直观的用户体验。
客户端驱动命令处理
用户界面客户端向服务器发送命令(或者间接地执行应用服务)以在聚合上执行响应的行为操作,此时的聚合即属于命令模型。提交的命令包含了行为操作的名称和所需参数。
命令处理器
客户端提交的命令将被命令处理器(Command Processor)所接收。命令处理器可以有不同的类型风格,这里我们将讨论它们的优缺点。
我们可以使用分类风格(categorized style),此时多个命令处理器位于同一个应用服务中。在这种风格中,我们根据命令类型来实现应用服务。每个应用服务都拥有多个方法,每个方法处理某种类型的命令。该风格最大的优点是简单。分类风格处理器易于理解,创建简单,维护方便。
我们也可以使用专属风格(dedicated style),此时每种命令都对应与某个单独的类,并且该类只有一个方法。这种风格的优点是:每个处理器的职责是单一的,命令处理器之间相互独立,我们可以通过增加处理器种类来处理更多的命令。
专属风格可能发展成为消息风格(Messaging style),其中每个命令将通过异步的消息发送到某个命令处理器。消息风格使得每个命令处理器可以处理特殊的消息类型,同时我们可以增加单种处理器的数量来缓解消息负载。但是,消息风格并不能作为默认的命令处理方式,因为他的设计比其他两种都复杂。
无论采用哪种风格的命令处理器,我们都应该在不同的处理器间进行解耦,我能使一个处理器依赖于另一个处理器。这样,对一种处理器的重新部署不会影响到其他处理器。
命令模型(写模型)执行业务行为
命令模型上每个方法在执行完成时都将发布领域事件。以BackLogItem为例:
public class BackLogItem extends ConcurrencySafeEntity {...public void commitTo(Sprint aspring) {...DomainEventPublisher.instance().publish(new BackLogItemCommitted(this.tenant(),this.backlogItemId(),this.sprintId()));}}
在命令模式更新之后,如果我们希望查询模型也得到相应的更新,那么从命令模型中发布的领域事件便是关键所在
有时,对命令的执行并不会发布领域事件。比如,如果命令是通过“至少一次的”消息进行提交的,而同时应用程序又支持幂等操作,那么重新发出的消息将被忽略掉。
事件订阅器更新查询模型
一个特殊的时间订阅器用于接收命令模型所发出的所有领域事件。有了领域事件,订阅器会根据命令模型的更改来更新查询模型。这意味着,每种领域事件都应该包含有足够的数据以正确更新查询模型。
对查询模型的更新应该是同步的呢,还是异步的?这取决于系统的负荷,也有可能取决于查询模型数据库的存储位置。数据的一致性约束和性能需求等因素对此也有很大的影响作用。
事件驱动架构
基于消息的系统通常呈现出一种管道和过滤器风格。
cat phone_number.txt | grep 303 | wc -1
上面的Linux命令用于在phone_number.txt文件中统计含有电话区号“303”的所有文本行的数量。该命令同时使用了管道和过滤器。
| 特征 | 描述 |
|---|---|
| 管道是消息通道 | 过滤器通过输入管道接收数据,通过输出管道发送数据。实际上,管道即是一个消息通道。 |
| 端口连接过滤器和管道 | 过滤器通过端口连接到输入和输出管道。端口使得六边形架构成为首选的架构。 |
| 过滤器即是处理器 | 每个过滤器可以对消息进行处理,而不见得一定对消息进行过滤 |
| 分离器处理器 | 每个过滤处理器都是一个分离的组件 |
| 松耦合 | 每个过滤器都相对独立地参与处理过程,处理器组合可以通过配置完成 |
| 可换性 | 根据用例需求,我们可以重新组织不同处理器的执行顺序,这同样是通过配置完成的 |
| 过滤器可以使用多个管道 | 在命令行例子中,过滤器只从一个管道中读写数据,但是消息过滤器可以从不同的管道中读写数据,这表示了一种并行的处理过程 |
| 并行使用同种类型的过滤器 | 对于最繁忙的和最慢的过滤器来说,我们可以并行地采用多个相同类型的过滤器来增加处理量 |
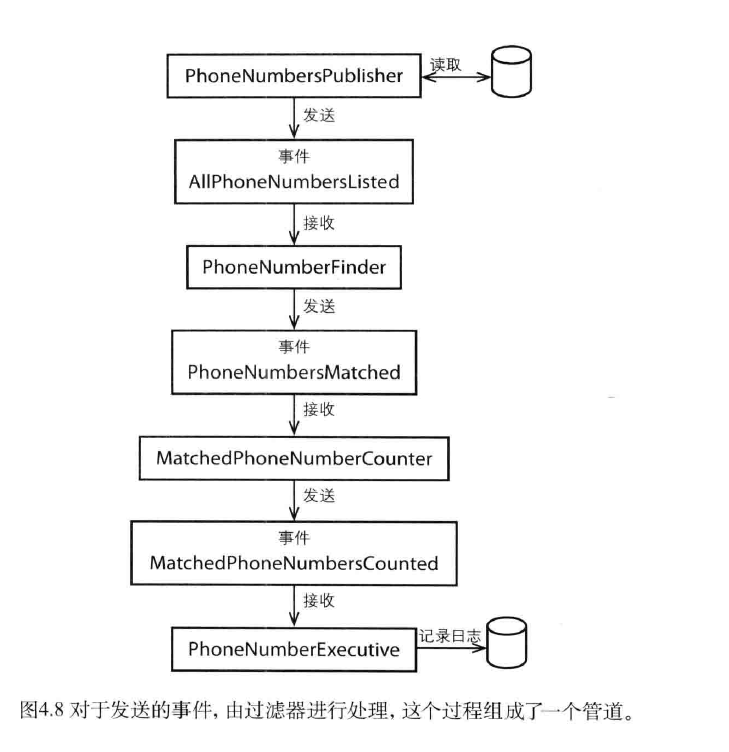
长时处理过程(也叫Saga)
我们可以对上面的管道和过滤器的例子进行扩展,从而得到另一种事件驱动的、分布式的并行处理模式———-长时处理模式(Long-Running Process)。
和先前的例子不同的是,此时长时处理器将由PhoneNumberExecutive来启动,同时它还将对处理过程进行跟踪。
PhongNumberExecutive可以通过应用服务或者命令处理器的形式实现,它将跟踪长时间处理过程的各个阶段。同时,PhongNumberExecutive它还知道一个长时处理过程何时执行完毕,并在这些过程执行完毕之后,再执行其他任务。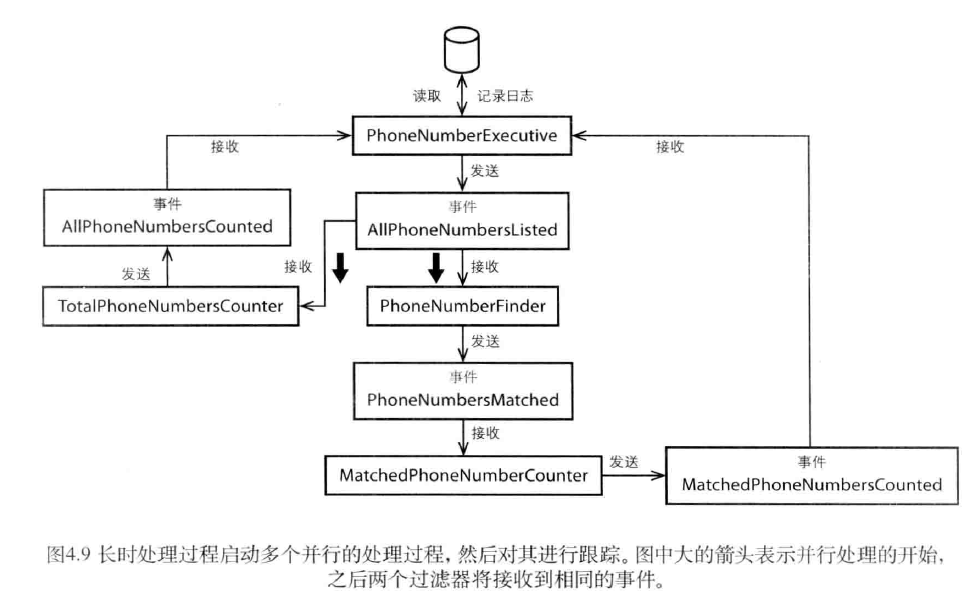 设计长时处理过程的不同方法
设计长时处理过程的不同方法
- 将处理过程设计成一个组合任务,使用一个执行组件对任务进行跟踪,并对各个步骤和任务完成情况进行持久化。
- 将处理过程设计成一组聚合,这些聚合在一系列的活动中相互协作。一个或多个聚合实例充当执行组件并维护整个处理过程的状态。
- 设计一个无状态的处理过程,其中每一个消息处理组件都将对所接收到的消息进行扩充——-即向其中加入额外的数据信息——然后再讲消息发送到下一个处理组件。
PhoneNumberExecutive同时订阅了MactchedPhoneNumbersCounted和AllPhoneNumbersCounted事件。只有两个领域事件都被PhoneNumberExecutive接收到时,整个并行处理过程才算完成,此时两个并行处理的结果合二为一。
3 of 15 phone numbers matched on july 15,2012 at 11:27 PM
然而这个长时处理过程还有一个问题。PhoneNumberExecutive无法知道所接收到的两个领域事件是否来自同一个并行处理过程。解决这个问题的第一步是在每个领域事件的标识相同。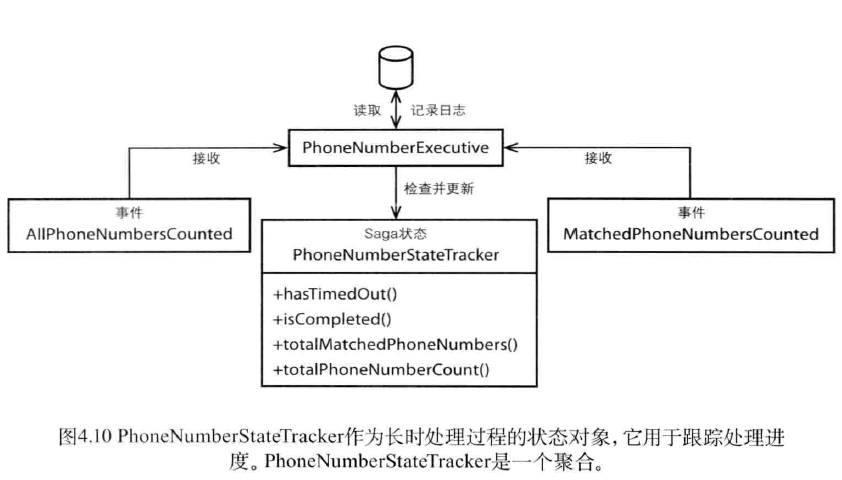
消息幂等
当一个完成事件到达时,执行器将检查该事件中相应的状态属性,该状态属性表示该事件是否已经存在。如果状态已经被设值,那么该事件便是一个重复事件,执行器将忽略该事件,但是还是会对事件做出应答。
另一种方式是将状态对象设计成幂等。这样执行器接收到重复消息,它将同等对待,即执行器依然会使用该消息来更新处理过程的状态,但是此时更新不会产生任何效果。
超时处理
对于跟踪有些长时处理过程来说,我们需要考虑时间敏感性。在过程处理超时,我们既可以采用被动,亦可以采用主动。
被动超时检查由执行器在每次并行执行流的完成事件到达时执行。执行器根据状态跟踪器来决定是否出现超时,比如调用名为hasTimedOut()方法。如果执行流的处理时间超过最大允许处理时间,状态跟踪器将被标记“遗弃”状态。
被动超时检查的一个缺点是,如果由于某些导致执行器始终接收不到完成领域事件,那么即便处理过程已经超时,执行器还是会认为处理器正处于活跃状态。如果还有更大的并发过程依赖于该过程处理,那么这将是不可接受的。
主动超时检查可以通过一个外部定时器来进行管理。在处理过程开始时,定时器便被设以最大允许处理时间。定时时间到,定时监听器将访问状态跟踪器的状态。

若有收获,就点个赞吧
0 人点赞
