什么是领域
从广义上来讲,领域(domain)即是一个组织所做的事情以及其中所包含的一切。
“领域”这个词可能承载了太多的含义。领域既可以表示整个业务系统,也可以表示其中某个核心域或者支撑子域
由于“领域模型”包含领域这个词,我们可能认为应该为整个业务系统创建一份单一的、内聚的、全功能的模型。然而,这并不是我们使用DDD的目的。正好相反,在DDD中,一个领域被分为若干个子域,领域模型在限界上下文中完成开发。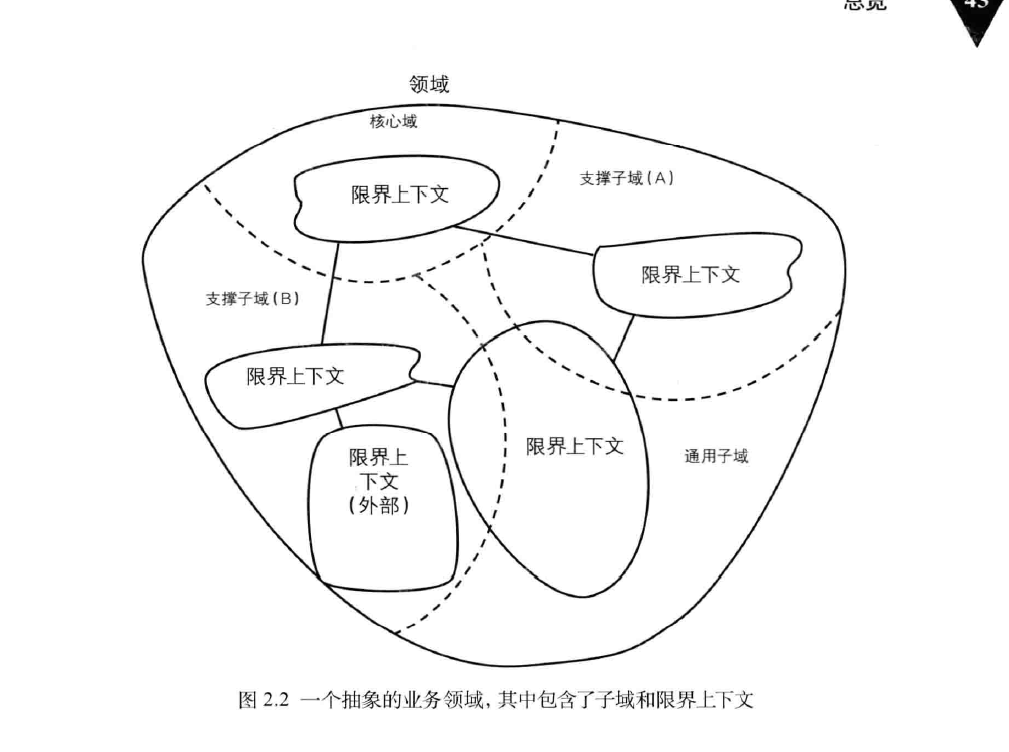
现在看看图2.2上半部分的领域边界,你会看到一个叫核心域的子域。对于核心域,我们在前面的章节中已经讲到了,他是整个业务领域的一部分,也是业务成功的主要促成因素。从战略层面上讲,企业应该在核心域上胜人一筹。我们应该给予核心域最高的优先级、最资深的领域专家和最优秀的开发团队。在实施DDD的过程中,你将关注核心域。
有时我们会创建或者购买一个限界上下文来支撑我们的业务。
支撑子域:如果这样的限界上下文对应着一些重要的业务,但却不是核心,那么它便是一个支撑子域
通用子域:创建支撑子域的原因在与它们专注于业务的某个方面,否则如果一个子域被用于整个业务系统,那么这个子域便是通用子域。
理解限界上下文
限界上下文是一个显式的边界,领域模型便存在于这个边界之内。领域模型把通用语言表达成软件模型。
创建边界的原因在于,每一个模型概念,包括他的属性和操作,在边界之内都具有特殊含义。
限界上下文是一个显式边界,领域模型便存在于这个边界之内。在边界内,通用语言中所有术语和词组都有特定的含义,而模型需要准确地反映通用语言。
在很多情况下,在不同模型中存在名字相同或相近的对象,但是它们的意思却不同。当模型被一个显式的边界所包围时,其中每个概念的含义便是确定的了。因此限界上下文主要是一个语义上的边界,我们应该通过这一点来衡量对一个限界上下文的使用正确与否。
有些项目试图创建一个“大而全”的软件模型,其中每个概念在全局范围之内只有一种定义。这是一个陷阱。首先,要使得所有都对某个概念的定义达成一致几乎不可能。有些项目太庞大,太复杂,以至于你根本无法将所有的利益相关方聚集到一起,更不用提达成一致了。即便是那些规模相对较小的公司,要维持一个全局性的,并且经得住时间考验的概念定义也是困难的。因此,最好的方法是正视这些不同,然后使用限界上下文对领域模型进行分离。
让我们来看看一个账户(Account)模型在银行上下文(Banking Context)和文学上下文(Literary Context)中的不同。
| 限界上下文 | 含义 | 例子 |
|---|---|---|
| 银行上下文 | 账户表示一个客户在银行的存款状态,并记录每次交易信息。 | 支票账户和储蓄账户 |
| 文学上下文 | 账户表示用文字记录的在一段时间之内发生的一系列事件 | Amazon.com售出图书《Into Thin Air:A Personal Account of the Mt.Everest Disaster》 |
通常情况下,你是可以识别那些概念分离正确的情况的,因为有些相似的对象拥有不同的属性和行为,此时我们可以认为上下文边界的划分是合理的。然而,如果你在不同的限界上下文中看到了完全相同的对象,这通常意味着你的模型是错误的,除非这些上下文使用了共享内核。
限界上下文不仅仅只包含模型
一个限界上下文并不是只包含领域模型。诚然,模型是限界上下文的主要“公民”。但是,限界上下文并不只局限于容纳模型,他通常标定了一个系统、一个应用程序或一种业务服务。
有时,限界上下文所包含的内容可能比较少,比如,一个通用子域便可以只包含领域模型。
Web服务
通常情况下,一个系统、应用程序的使用者并不只是人,还可能是另外的计算机系统。系统中有可能存在诸如Web服务(Web Service)之类的组件。我们也可以使用REST资源来与资源来与模型交互,此时REST资源即被称为开放主机服务(Open Host Service),这些面向服务的组件都应该位于上下文边界之内。
应用服务
用户界面和面向服务端点都会将操作委派给应用服务。应用服务包含了不同类型的服务,比如安全和事务管理等。对于模型来讲,应用服务扮演的是一种门面模式Facade。同时,应用服务还具有任务管理功能,它将来自用例流(Use Case Flow)的请求转换成领域逻辑的执行流。应用服务也是位于上下文边界之内。
当模型驱动着数据库Schema的设计时,此时数据库Schema也应该位于该模型所处的上下文边界之内。这是因为数据库Schema是由建模团队设计、开发并维护的。这也意味着数据库中表和列的名字应该和模型的名字保持一致。
比如,对于模型中包含的BacklogItem类,他拥有值对象backlogitem和businessPriority:
public class BacklogItem extends Entity {...private BacklogItem backlogItemId;private BusinessPriority businessPriority;...}
在数据库中对应的表定义为:
create table `tbl_backlog_item` (...`backlog_item_id_id` varchar(36) not null,.....) engine=Innodb;
如果用户界面(User Interface)被用于渲染模型,并且驱动着模型的行为设计,同样,该用户界面也应该属于模型所在的上下文边界之内。但是,这并不表示我们应该在用户界面中对领域进行建模,因为这样将导致贫血领域对象。我们应该拒绝使用智能UI反模式(Smart UI Anti-Pattern),或者任何试图将领域概念带到领域模型之外的举措。
限界上下文主要是用来封装通用语言和领域对象,但同时也包含了那些为领域模型提供交互手段和辅助功能的内容。需要注意的是,对于架构中的每个组件,我们都应该将其放在适当的地方。
限界上下文的大小
限界上下文中可以包含多少领域模型中的基础部件呢,比如模块、聚合、领域事件、领域服务 。限界上下文应该足够大,已能够表达它所对应的整套通用语言。
核心领域之外的概念不应该包含在限界上下文中。如果一个概念不属于你的通用语言,那么一开始你就不应该将其引入到模型中。此外,如果有外部概念“偷偷潜入”了你的限界上下文,你需要将其清除,它们可能属于另外的支撑或者通用子域,或者根本不属于某个模型。
请注意,不要将本应该属于核心域的概念清除掉了。你的模型应该能够完全地展示上下文中的通用语言,而不能遗漏任何重要的概念。
任何时候,我们都有可能错失改进领域模型的机会。在每个迭代中,我们都应该对先前的假设提出挑战,这使得我们向模型中添加或删除一些概念,或者改变概念的行为和协作方式。
在使用DDD原则时,我们会认真思考应该添加哪些概念,又应该删除哪些概念。使用限界上下文和上下文映射图这样的工具可以帮助我们分析哪些概念属于核心领域。
哪些因素会导致创建的限界上下文大小不正确
- 我们可能错误地采用架构来知道设计开发,而不是通用语言。一些平台、框架或者基础设施通常是用来打包个部署组件的,它们可能影响我们对限界上下文的设计,此时我们会从技术层面而不是语义边界来考虑问题。
- 根据开发任务的分配来拆分限界上下文。为了分配任务而拆分限界上下文是一种错误的上下文建模方式。事实上,我们没有必要为了管理技术资源而创建一些假的(fake)的上下文边界。
如何创建大小合适的限界上下文
这里有一个重要的问题:领域专家所采用的的语言是如何划定上下文边界的?
我们应该考虑领域专家所讲的通用语言,将核心域的概念自然地组织成单一的限界上下文。这样一来,你便可以识别出那些单一的、内聚的模型组件。你应该将这些组件放在限界上下文之内。
有时,我们可以使用模块来避免创建一些微小的限界上下文。通过分析分散限界上下文中的服务,你可能会发现,模块可以将多个限界上下文减少到一个。
模块也可以用来拆分开发者的任务职责,因此我们可以使用更加战术化的手段来管理团队的任务分配。
与技术组件保持一致
将限界上下文想成是技术组件并无大碍,只是我们需要记住:技术组件并不能定义限界上下文。
当时用IDE时,比如说Eclipse或者InteliJ IDEA,一个限界上下文通常是一个项目工程。当时用Visual studio和.NET时,在同一个解决方案中将用户界面、应用服务和领域对象分离在不同的子项目中是合理的。
项目的源代码可以只包含领域模型,也可以包含一些周边的层或六边形区域等。
请注意,即便存在这种模块的拆分,团队依然应该只工作在一个限界上下文中。
在使用Java时,我们可能从技术层面上讲一个限界上下文放在一个jar文件中,包括war或ear文件中。这种做法可能受到模块化的影响。
示例上下文
我们的SaaSOvation团队所选择的3个限界上下文最终将于各自所对应的子域形成一对一的关系。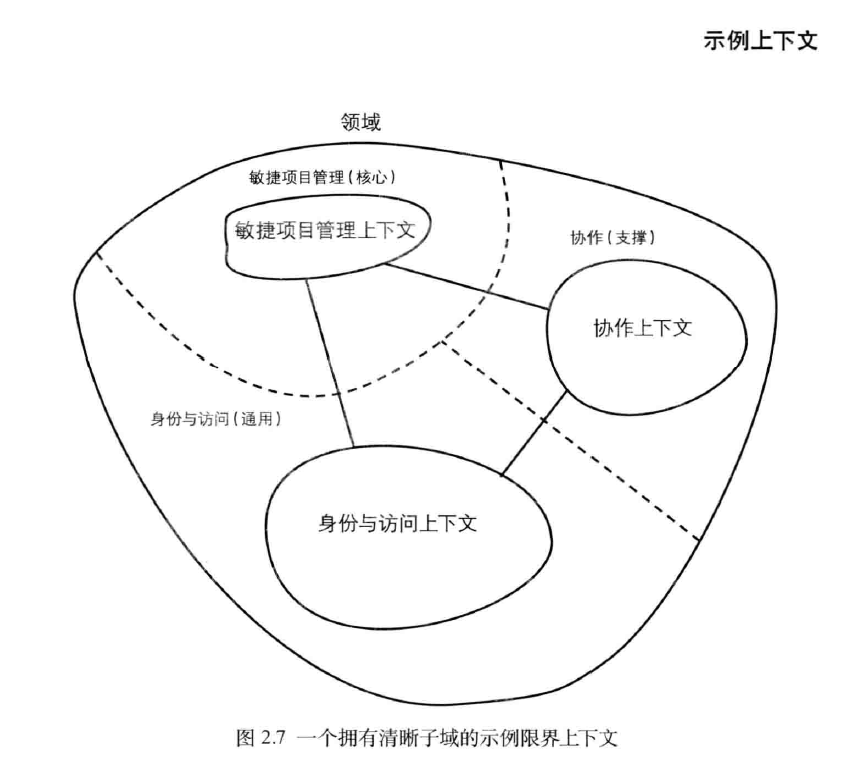
让我们来看看DDD项目中的这3个限界上下文。它们分别是协作上下文、身份与访问上下文和敏捷项目管理上下文。

若有收获,就点个赞吧
0 人点赞
