官网:https://zookeeper.apache.org/
学习视频:https://www.bilibili.com/video/BV1to4y1C7gw(入门到31集)
xmind:
Zookeeper从入门到精通.xmind
pdf:
08_尚硅谷技术之Zookeeper(源码解析)V3.3.pdf
08_尚硅谷技术之ZookeeperV3.3.pdf
随堂笔记.pdf
一、Zookeeper入门
1.介绍
Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的 Apache 项目。
2、zookeeper工作机制
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper 就将负责通知已经在zookeeper上注册的那些观察者做出相应的反应。
3、zookeeper的特点
1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
5)数据更新原子性,一次数据更新要么成功,要么失败。
6)实时性,在一定时间范围内,Client能读到最新数据。 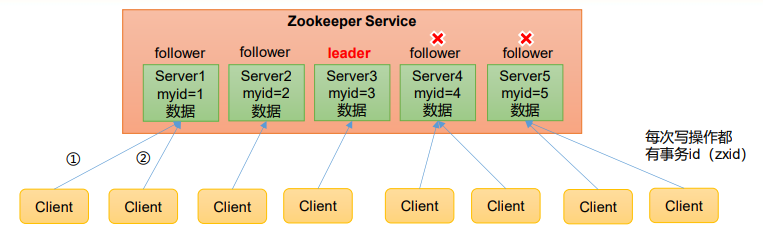
4、数据结构
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个 节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识。 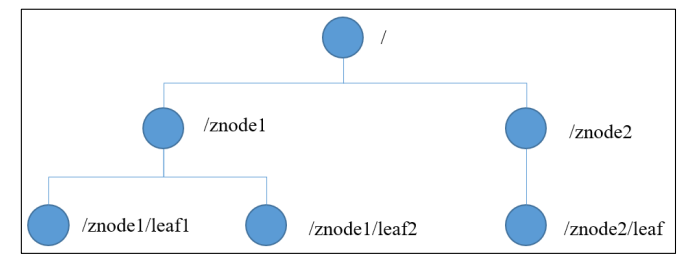
5、应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下 线、软负载均衡等。
统一命名服务
在分布式环境下,经常需要对应用/服 务进行统一命名,便于识别。 例如:IP不容易记住,而域名容易记住。 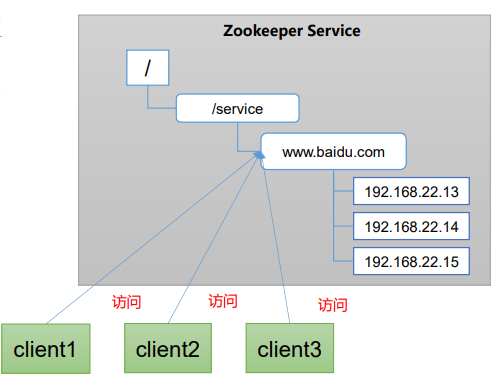
统一配置管理
1)分布式环境下,配置文件同步非常常见。
(1)一般要求一个集群中,所有节点的配置信息是 一致的,比如 Kafka 集群。
(2)对配置文件修改后,希望能够快速同步到各个 节点上。
2)配置管理可交由ZooKeeper实现。
(1)可将配置信息写入ZooKeeper上的一个Znode。
(2)各个客户端服务器监听这个Znode。
(3)一 旦Znode中的数据被修改,ZooKeeper将通知 各个客户端服务器。 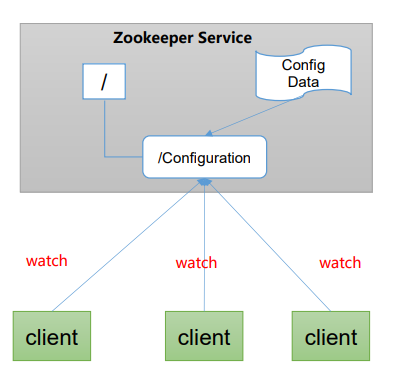
统一集群管理
1)分布式环境中,实时掌握每个节点的状态是必要的。
(1)可根据节点实时状态做出一些调整。
2)ZooKeeper可以实现实时监控节点状态变化
(1)可将节点信息写入ZooKeeper上的一个ZNode。
(2)监听这个ZNode可获取它的实时状态变化。 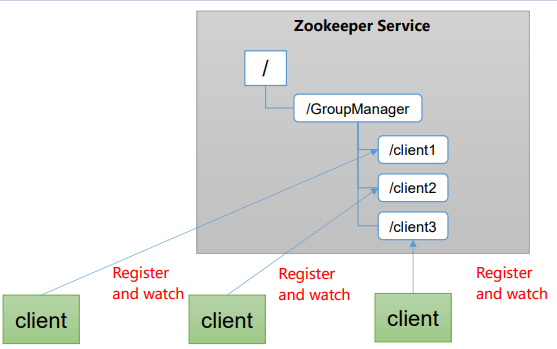
服务器节点动态上下线
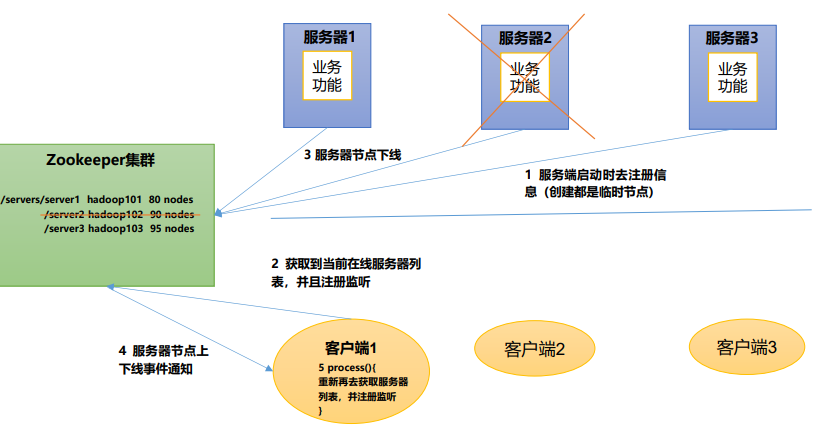 软负载均衡
软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求 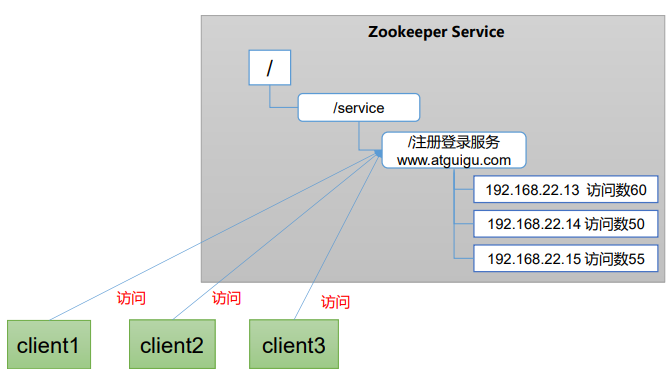
二、安装
1、准备
(1)安装 JDK
(2)拷贝 apache-zookeeper-3.5.7-bin.tar.gz 安装包到 Linux 系统下
(3)解压到指定目录 tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
2、配置修改
(1)将apache-zookeeper-3.5.7-bin/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg;
mv zoo_sample.cfg zoo.cfg
(2)打开 zoo.cfg 文件,修改 dataDir 路径
vim zoo.cfg
修改如下内容:
dataDir=解压路径/apache-zookeeper-3.5.7-bin/zkData
(3)在 解压路径/apache-zookeeper-3.5.7-bin/这个目录上创建 zkData 文件
3、操作zookeeper
(1)启动 Zookeeper bin/zkServer.sh start
(2)查看进程是否启动 jps -l
(3)查看状态 bin/zkServer.sh status
(4)启动客户端 bin/zkCli.sh
(5)退出客户端: quit
(6)停止 Zookeeper bin/zkServer.sh stop
4、zoo.conf的配置解读
1)tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
2)initLimit = 10:LF初始通信时限 Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)
3)syncLimit = 5:LF同步通信时限 Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为 Follwer死 掉,从服务器列表中删除Follwer。
4)dataDir:保存Zookeeper中的数据 注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
5)clientPort = 2181:客户端连接端口,通常不做修改。
三、集群
1、安装查看最上方pdf
2、选举机制(面试重点)
基本概念:
SID:服务器ID。用来唯一标识一台 ZooKeeper集群中的机器,每台机器不能重 复,和myid一致。
ZXID:事务ID。ZXID是一个事务ID,用来 标识一次服务器状态的变更。在某一时刻, 集群中的每台机器的ZXID值不一定完全一 致,这和ZooKeeper服务器对于客户端“更 新请求”的处理逻辑有关。
Epoch:每个Leader任期的代号。没有 Leader时同一轮投票过程中的逻辑时钟值是 相同的。每投完一次票这个数据就会增加
情况一 第一次启动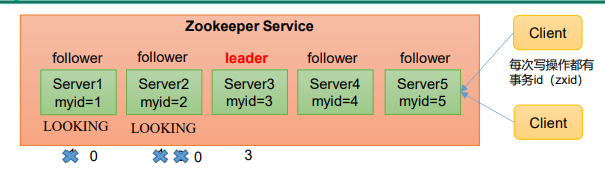
(1)服务器1启 动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为 LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1) 大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服 务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为 1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
情况二 非第一次启动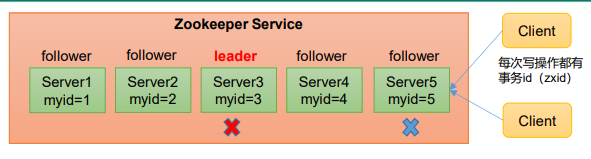
(1)当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
• 服务器初始化启动。
• 服务器运行期间无法和Leader保持连接。
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
• 集群中本来就已经存在一个Leader。 对于第一种已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连 接,并进行状态同步即可。
• 集群中确实不存在Leader。 假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻, 3和5服务器出现故障,因此开始进行Leader选举。
(EPOCH,ZXID,SID )(EPOCH,ZXID,SID )(EPOCH,ZXID,SID )
SID为1、2、4的机器投票情况:(1,8,1) (1,8,2) (1,7,4)
选举Leader规则: ①EPOCH大的直接胜出 ②EPOCH相同,事务id大的胜出 ③事务id相同,服务器id大的胜出
3、客户端操作命令
1)查看当前znode中所包含的内容 ls /
2)查看当前节点详细数据 ls -s /
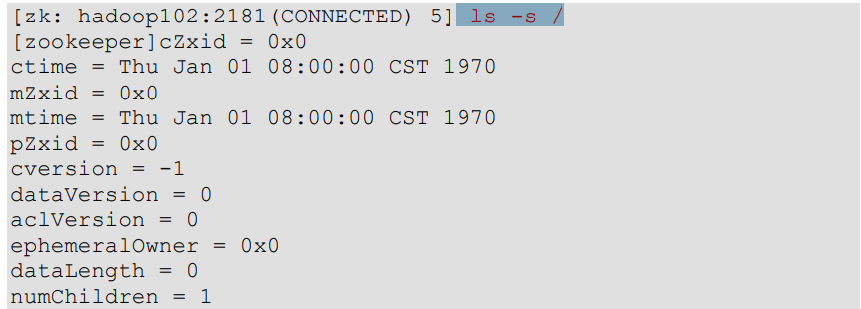
(1)czxid:创建节点的事务 zxid
每次修改 ZooKeeper 状态都会产生一个 ZooKeeper 事务 ID。事务 ID 是 ZooKeeper 中所 有修改总的次序。每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之 前发生。
(2)ctime:znode 被创建的毫秒数(从 1970 年开始)
(3)mzxid:znode 最后更新的事务 zxid
(4)mtime:znode 最后修改的毫秒数(从 1970 年开始)
(5)pZxid:znode 最后更新的子节点 zxid
(6)cversion:znode 子节点变化号,znode 子节点修改次数
(7)dataversion:znode 数据变化号
(8)aclVersion:znode 访问控制列表的变化号
(9)ephemeralOwner:如果是临时节点,这个是 znode 拥有者的 session id。如果不是 临时节点则是 0。 (10)dataLength:znode 的数据长度
(11)numChildren:znode 子节点数量
3)创建节点
持久(Persistent):客户端和服务器端断开连接后,创建的节点不删除
短暂(Ephemeral):客户端和服务器端断开连接后,创建的节点自己删除
(1)持久化目录节点
客户端与Zookeeper断开连接后,该节点依旧存在
create /sanguo “diaochan”
(2)持久化顺序编号目录节点
客户端与Zookeeper断开连接后,该节点依旧存 在,只是Zookeeper给该节点名称进行顺序编号
create -s /sanguo/weiguo/zhangliao “zhangliao”
(3)临时目录节点
客户端与Zookeeper断开连接后,该节点被删除
create -e /sanguo/wuguo “zhouyu”
(4)临时顺序编号目录节点
客户端与 Zookeeper 断开连接后 , 该节点被删除 , 只是Zookeeper给该节点名称进行顺序编号。
create -e -s /sanguo/wuguo “zhouyu”
4)获得节点的值 get -s /sanguo
5)修改节点数据值 set /sanguo/weiguo “simayi”
6) 删除节点 delete /sanguo/jin
7)递归删除节点 deleteall /sanguo/shuguo
8) 查看节点状态 stat /sanguo
四、客户端API操作
1、创建工程查看pdf
2、 监听器原理
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、节点删除、子目 录节点增加删除)时,ZooKeeper 会通知客户端。监听机制保证 ZooKeeper 保存的任何的数 据的任何改变都能快速的响应到监听了该节点的应用程序。 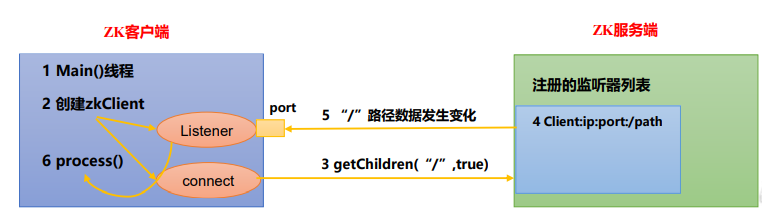
监听原理详解
1)首先要有一个main()线程
2)在main线程中创建Zookeeper客户端,这时就会创建两个线 程,一个负责网络连接通信(connet),一个负责监听(listener)。
3)通过connect线程将注册的监听事件发送给Zookeeper。
4)在Zookeeper的注册监听器列表中将注册的监听事件添加到列表中。
5)Zookeeper监听到有数据或路径变化,就会将这个消息发送给listener线程。
6)listener线程内部调用了process()方法。
常见的监听
1)监听节点数据的变化 get path [watch]
2)监听子节点增减的变化 ls path [watch]
3、创建实例
//建立连接ZooKeeper zooKeeper=null;try {zooKeeper= new ZooKeeper("10.228.141.64:2181", 2000, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {}});}catch (IOException e) {e.printStackTrace();}//创建节点String node = zooKeeper.create("/sanguo3", "test-a".getBytes(),Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
4、监控服务器上下线demo
package com.mongo.test.zktest;import org.apache.zookeeper.*;import java.io.IOException;public class DistributionServer {private ZooKeeper zooKeeper=null;public static void main(String[] args) {DistributionServer distributionServer = new DistributionServer();distributionServer.createConnect();distributionServer.registerServer(args[0],args[0]+"有n个节点");try {Thread.sleep(1000*60*60);} catch (InterruptedException e) {e.printStackTrace();}}private void registerServer(String serverName,String serverContent){try {zooKeeper.create("/server/"+serverName,serverContent.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}private void createConnect(){try {zooKeeper= new ZooKeeper("10.228.141.64:2181", 2000, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {}});} catch (IOException e) {e.printStackTrace();}}}
package com.mongo.test.zktest;import org.apache.zookeeper.KeeperException;import org.apache.zookeeper.WatchedEvent;import org.apache.zookeeper.Watcher;import org.apache.zookeeper.ZooKeeper;import java.io.IOException;import java.util.ArrayList;import java.util.List;public class DistributionClient {private ZooKeeper zooKeeper=null;public static void main(String[] args) {DistributionClient distributionClient = new DistributionClient();distributionClient.createConnect();distributionClient.watchChlid();try {Thread.sleep(1000*60*60);} catch (InterruptedException e) {e.printStackTrace();}}private void watchChlid(){try {List<String> children = zooKeeper.getChildren("/server", true);List<String> server = new ArrayList<>();for(String s:children){server.add(s);}System.out.println(children);} catch (KeeperException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}}private void createConnect(){try {zooKeeper= new ZooKeeper("10.228.141.64:2181", 2000, new Watcher() {@Overridepublic void process(WatchedEvent watchedEvent) {watchChlid();}});} catch (IOException e) {e.printStackTrace();}}}
4、客户端向服务端写流程
(1) 写流程之写入请求直接发送给Leader节点 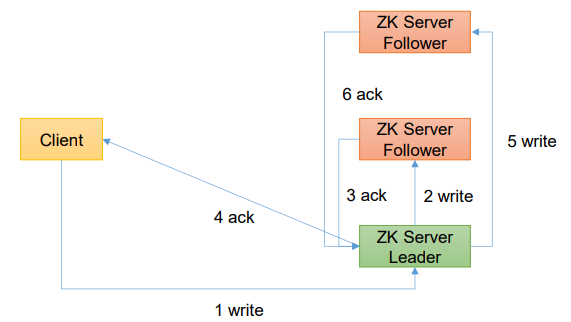
(2) 写流程之写入请求发送给follower节点 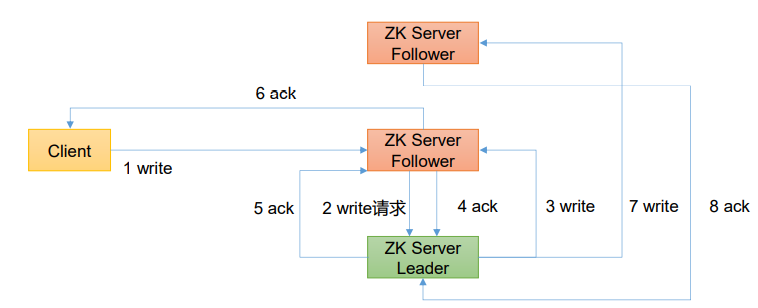
5、分布式锁案例
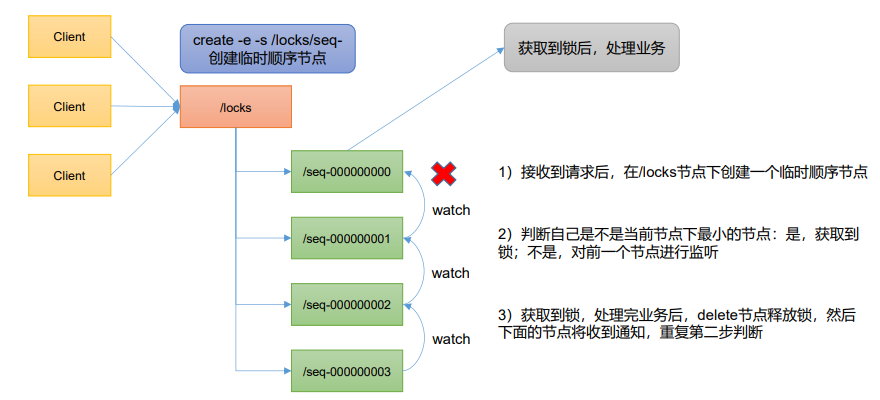
原生 Zookeeper 实现分布式锁案例 见pdf
08_尚硅谷技术之ZookeeperV3.3.pdf
Curator 是一个专门解决分布式锁的框架,解决了原生 JavaAPI 开发分布式遇到的问题。
Curator 官网:https://curator.apache.org/index.html
package com.mongo.test.zktest;public class CuratorLockTest {private String rootNode = "/locks";// zookeeper server 列表private String connectString ="hadoop102:2181,hadoop103:2181,hadoop104:2181";// connection 超时时间private int connectionTimeout = 2000;// session 超时时间private int sessionTimeout = 2000;public static void main(String[] args) {new CuratorLockTest().test();}// 测试private void test() {// 创建分布式锁 1final InterProcessLock lock1 = newInterProcessMutex(getCuratorFramework(), rootNode);// 创建分布式锁 2final InterProcessLock lock2 = newInterProcessMutex(getCuratorFramework(), rootNode);new Thread(new Runnable() {@Overridepublic void run() {// 获取锁对象try {lock1.acquire();System.out.println("线程 1 获取锁");// 测试锁重入lock1.acquire();System.out.println("线程 1 再次获取锁");Thread.sleep(5 * 1000);lock1.release();System.out.println("线程 1 释放锁");lock1.release();System.out.println("线程 1 再次释放锁");} catch (Exception e) {e.printStackTrace();}}}).start();new Thread(new Runnable() {@Overridepublic void run() {// 获取锁对象try {lock2.acquire();System.out.println("线程 2 获取锁");// 测试锁重入lock2.acquire();System.out.println("线程 2 再次获取锁");Thread.sleep(5 * 1000);lock2.release();System.out.println("线程 2 释放锁");lock2.release();System.out.println("线程 2 再次释放锁");} catch (Exception e) {e.printStackTrace();}}}).start();}// 分布式锁初始化public CuratorFramework getCuratorFramework (){//重试策略,初试时间 3 秒,重试 3 次RetryPolicy policy = new ExponentialBackoffRetry(3000, 3);//通过工厂创建 CuratorCuratorFramework client =CuratorFrameworkFactory.builder().connectString(connectString).connectionTimeoutMs(connectionTimeout).sessionTimeoutMs(sessionTimeout).retryPolicy(policy).build();//开启连接client.start();System.out.println("zookeeper 初始化完成...");return client;}}

若有收获,就点个赞吧
0 人点赞
