Cache
介于数据访问者和数据源之间的一种高速存储,当数据需要多次读取时,用于加快读取速度
- 和Buffer的区别
- Buffer是当数据源和数据访问者之间速度不匹配时,充当缓冲作用,用于加快访问速度
- Buffer不止只有读操作,写操作也可以
- 比如硬盘、网络的读写
- 无处不在的Cache
- CPU、操作系统、数据库、JVM
- CDN、代理、前端、应用程序、分布式对象
缓存实现的数据结构(Hash表)
- 怎样快速定位
- 怎样管理数据
- Hash表的实现
- 复杂度是O(1)
- 本质是数组,通过下标方法
- 用对象的hashcode取模,得到下标
- hashcode存储的是对象的内存地址
- 数组中每个对象的长度是相同的
- 数组是内存中一段连续的空间,所以内存地址是呈倍数递增的
- 缓存的关键指标
- 命中率
- 缓存的键集合大小
- 键的数量越小,命中率就越高
- 缓存可使用的内存空间
- 物理上能缓存的对象越多,命中率越高
- 缓存对象的生存时间
- TTL(Time to live)
- 原始数据被修改、缓存数据失效等导致缓存命中率降低
- 缓存的键集合大小
- 命中率
- 代理缓存
- 正向代理
- 代理用户上网的服务器,通过代理服务器去访问用户想要访问的资源
- 用户不知道
- 反向代理
- 缓存目标服务器的输出,当用户访问过来时,先看缓存中有没有需要的内容,有的话直接返回,没有再去访问目标资源
- restful 通过url访问,反向代理服务器更容易以url作为key缓存内容。所以说,对restful的支持更友好
- 正向代理
- CDN
通读缓存(read-through)
- 代理缓存,反向代理缓存,CDN缓存都是通读缓存
- 客户端直接连接的是通读缓存而不是目标服务器
- 通读缓存给客户端返回缓存资源,并在请求未命中缓存时获取实际数据
- 旁路缓存(cache-aside)
- 对象缓存是一种旁路缓存,通常是一个独立的键值对存储
- 应用程序通常会询问对象缓存需要的对象是否存在,如果存在,它会获取并使用缓存对象,如果不存在或已过期,应用程序会主动连接主数据源来获取对象,并同时将其保存到对象缓存中,以供将来使用。
- 旁路缓存中的对象,一般是不更新的,而是直接删除,再用新的对象替换
本地对象缓存
- 直接存储在应用程序内存中
- 存储在共享内存中,同一台服务器的多个进程可以访问它们
- 缓存服务器作为独立应用和应用程序一起部署在同一个服务器上
分布式缓存的关键技术点
- 缓存读写的路由选择
- 余数哈希
- 一致性哈希
- 扩展性,新增或删减服务器时的适应性
技术栈各个层次的缓存
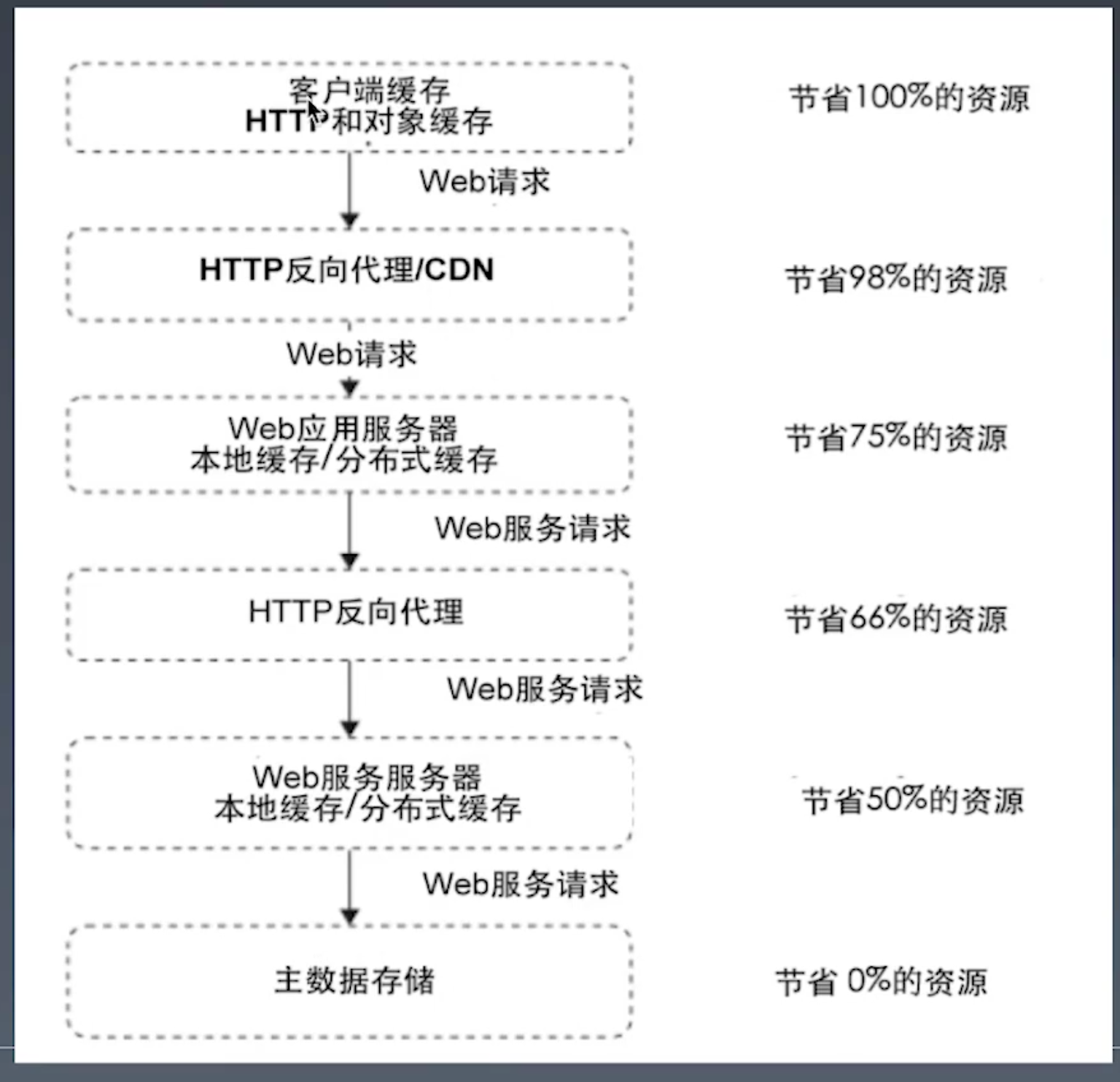
缓存为什么能显著提升性能
- 缓存数据通常来自内存,比硬盘要快
- 缓存存储的是数据是最终结果形态,不需要中间计算,减少CPU资源的消耗。
- 要么过期删除,要么新增,不要修改
- 缓存降低了数据库、磁盘、网络的负载压力,使这些设备能更好的响应
不正常的使用缓存
- 频繁修改的数据不适合使用缓存
- 应用来不及读取就已经失效或更新。一般来说,数据的读写在2:1以上,缓存才有意义。
- 简单应用缓存,用于多次读取的情况,不要更新操作,会导致缓存效率降低
- 没有热点的访问
- 缓存使用的是内存,内存资源宝贵而有限,所以不能把所有数据都缓存起来,应该只缓存热点数据
- 根据二八定律,大部分的数据访问应该集中的小部分的数据上,否则,缓存就没有意义
- 怎样知道哪些是热点数据
- LRU算法,总是把热点数据放到头部
- 数据不一致与脏读,最简单的是,应用需要容忍一段时间内的数据不一致问题。
- 缓存雪崩
- 缓存数据丢失或缓存不可用会导致数据直接从数据库获取数据
- 数据库可能因为不能完全承受缓存数据的读取压力而宕机
- 数据库宕机就会导致整个系统瘫痪
- 缓存预热
- 在缓存系统启动的时候就先把热点数据加载好。
- 对于一些源数据如城市地名列表等,可以在启动时加载数据库中所有数据到缓存中进行预热
- 目的是为了访问一进来就能访问到缓存数据
- 缓存穿透
- 如果持续高并发的请求某个不存在的数据,因为缓存中没有数据,请求就会落在数据库中,会给数据库带来很大压力,甚至崩溃。
- 一个简单的对策是,将不存在的数据也缓存起来,并设定一个较短的失效时间。
Redis VS Memcached

Redis 功能众多,更像是一个NoSql数据库。
Redis 使用的不是一致性hash
消息队列
同步调用 VS 异步调用
同步: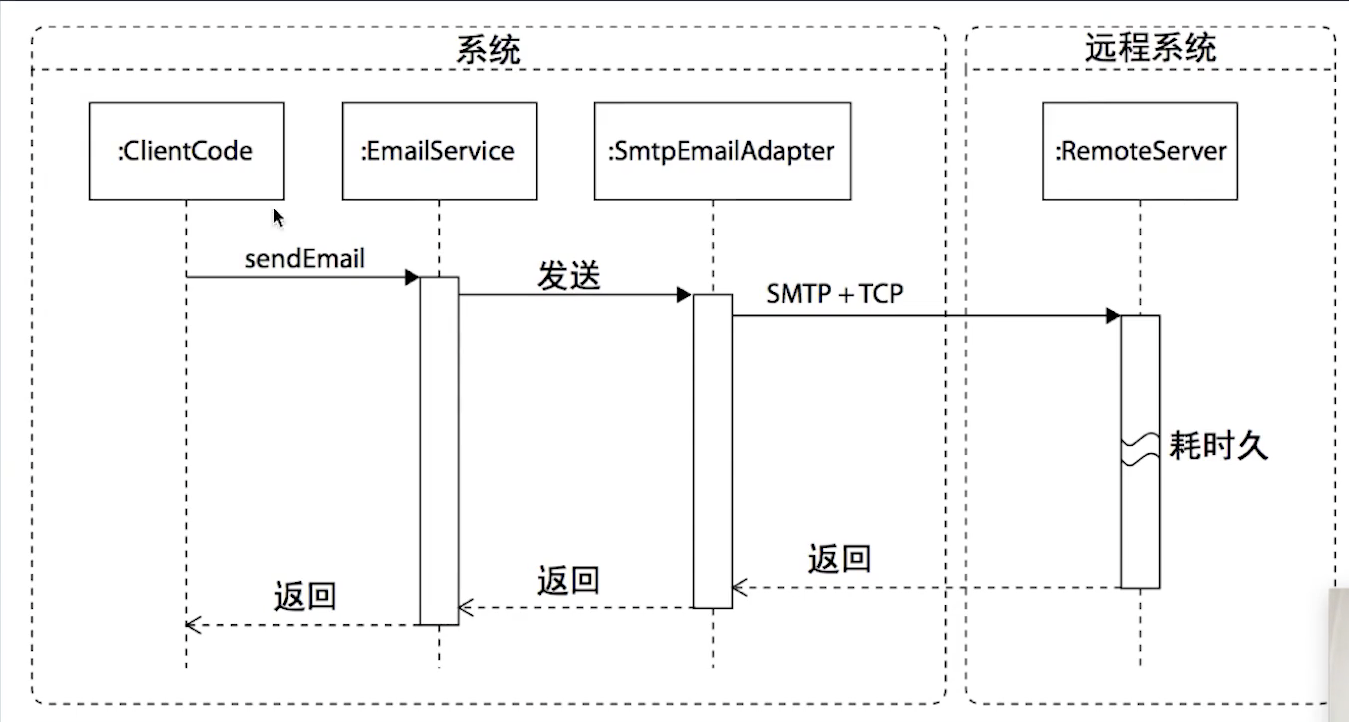
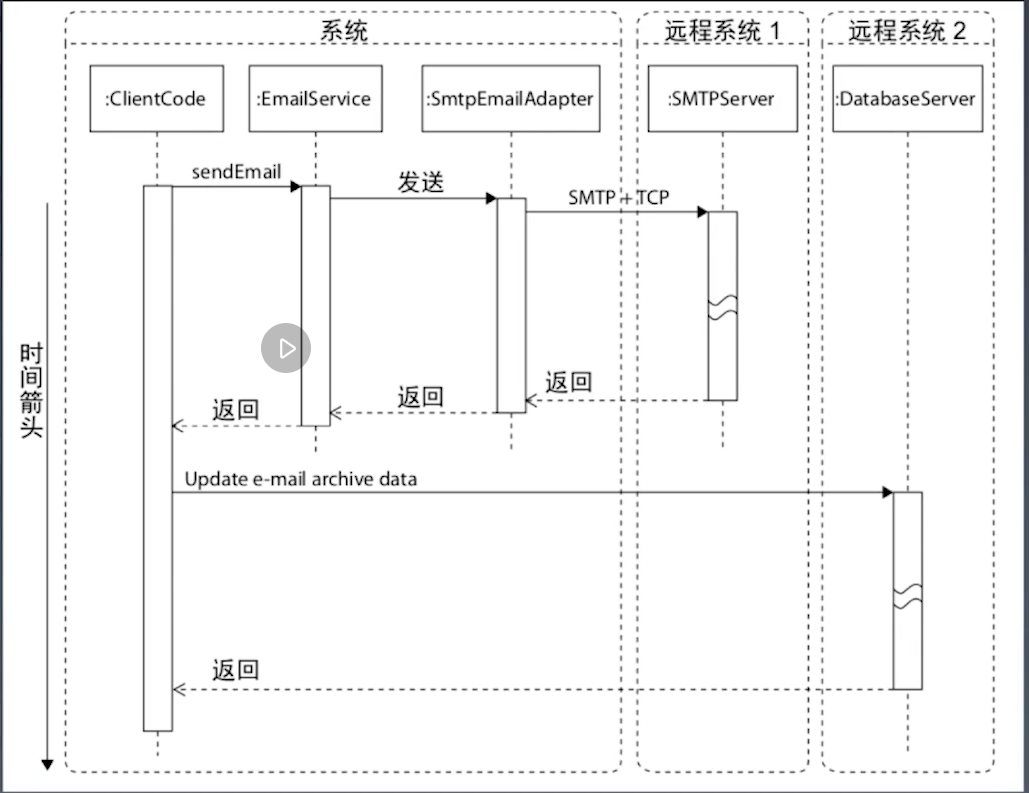
异步:
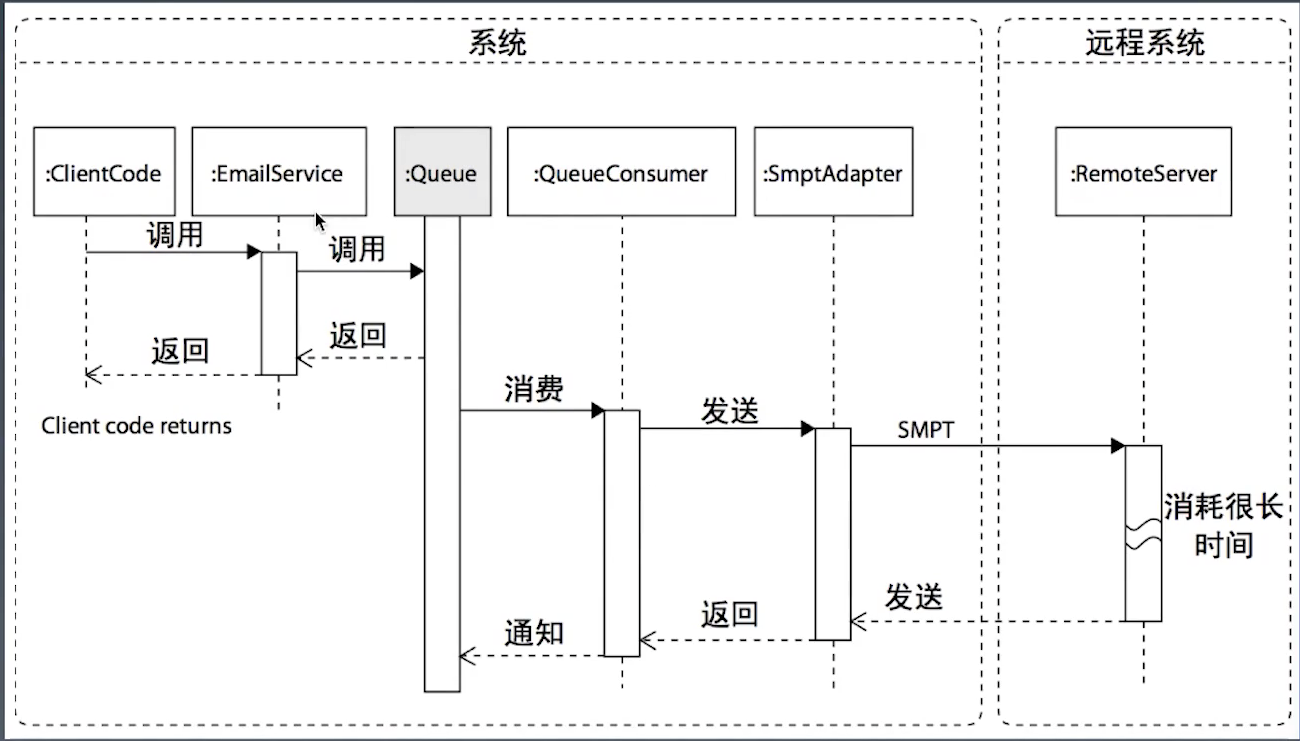
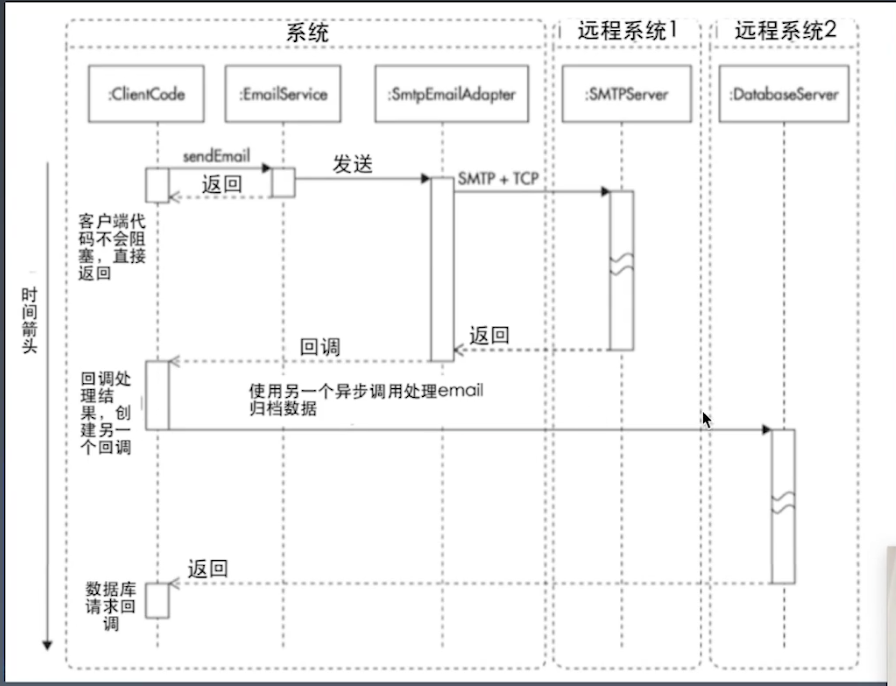
消息队列构建异步调用框架
- 生产者
- 消费者
- 消息队列
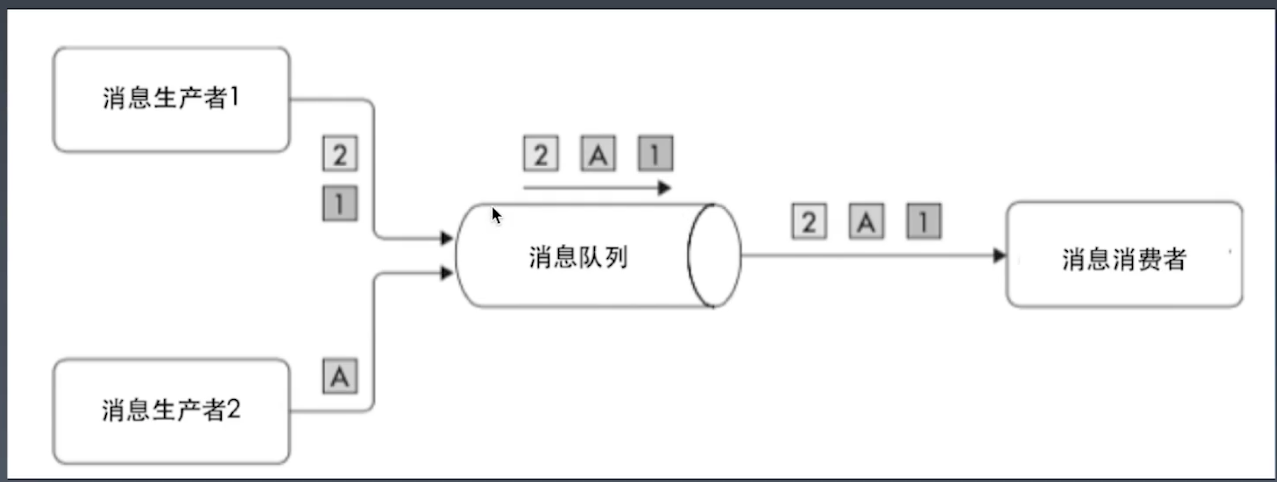
两种架构模型
- 点对点模型:
- 生产者有多个,而且是独立的;只要求有消费者能处理生产者的消息。
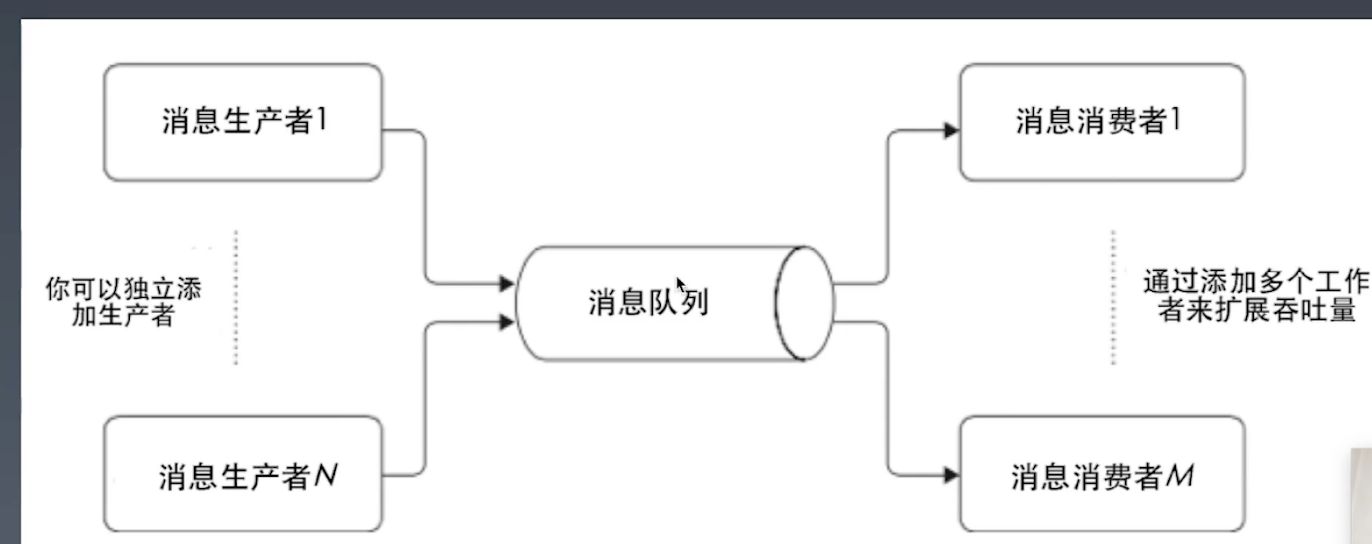
- 发布订阅
- 生产者的消息有几个消费者订阅,就会有几个消息队列
- 多个消费者之间是独立的,一个消费消息不会影响另外一个消费者
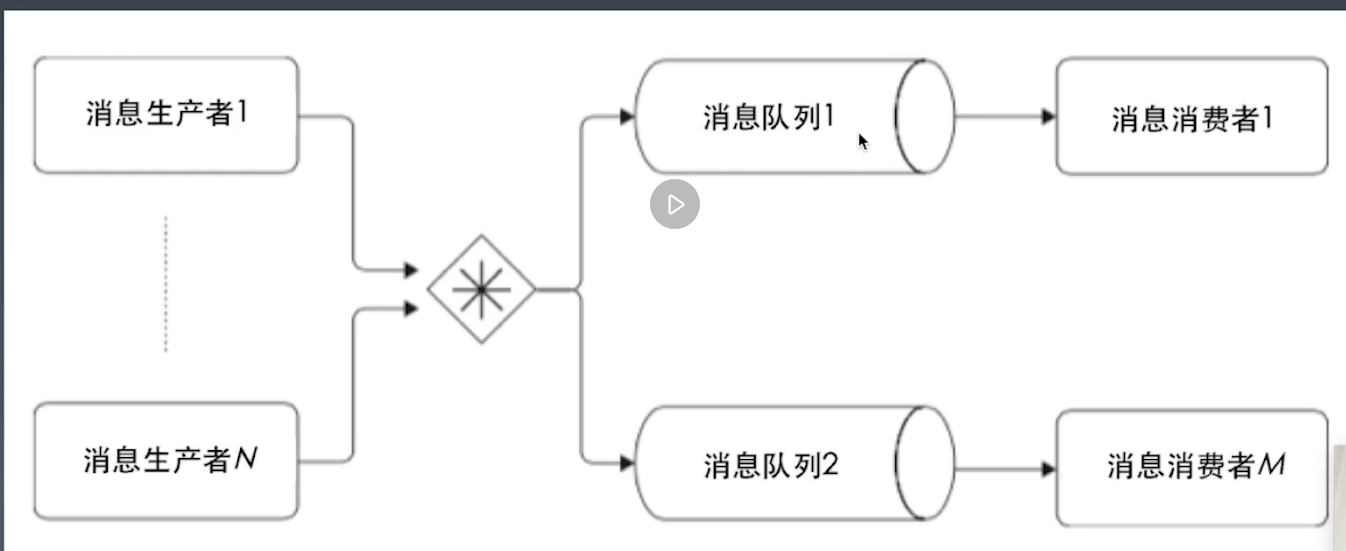
消息队列的好处
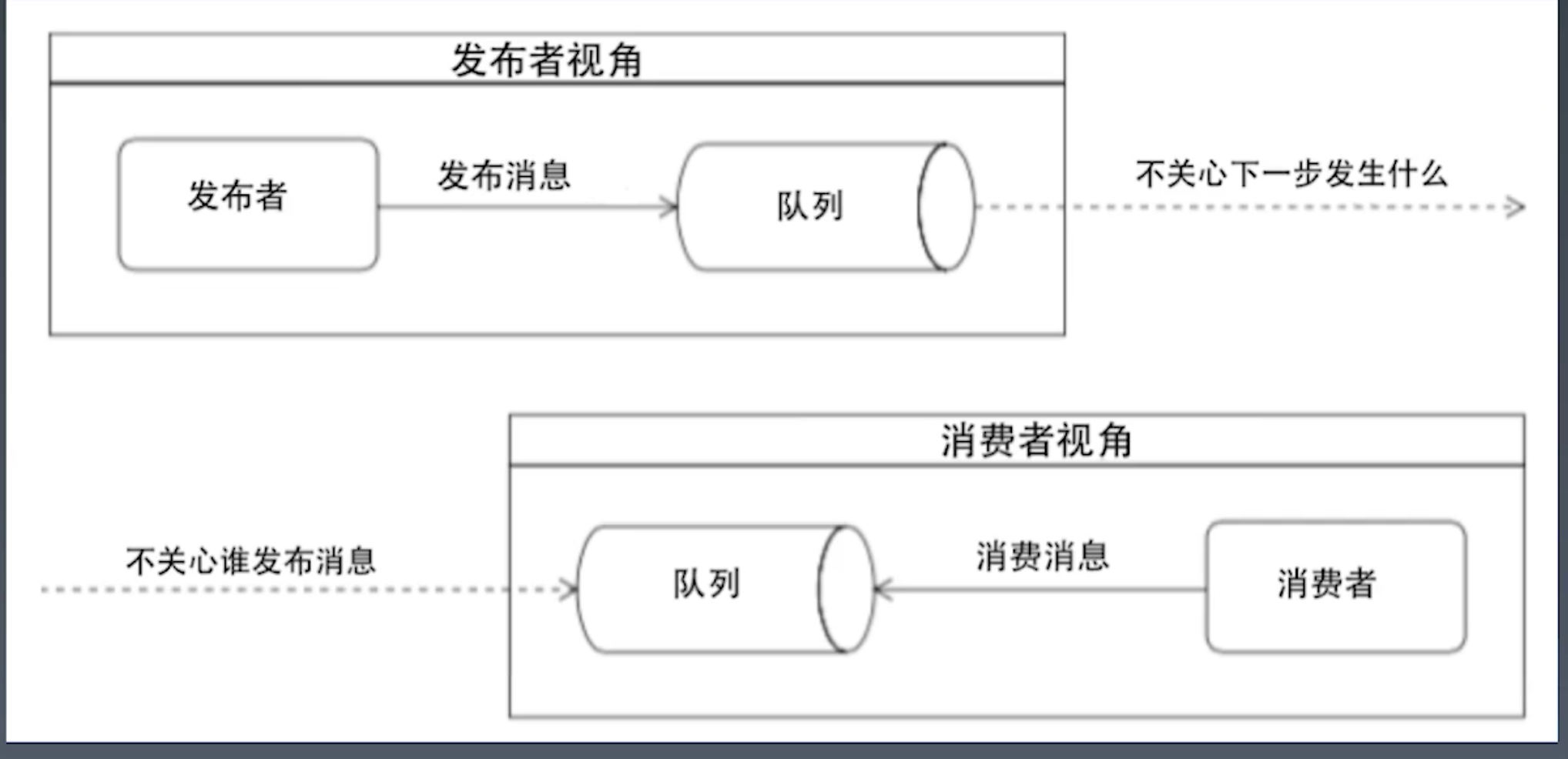
通过事件驱动下一步的动作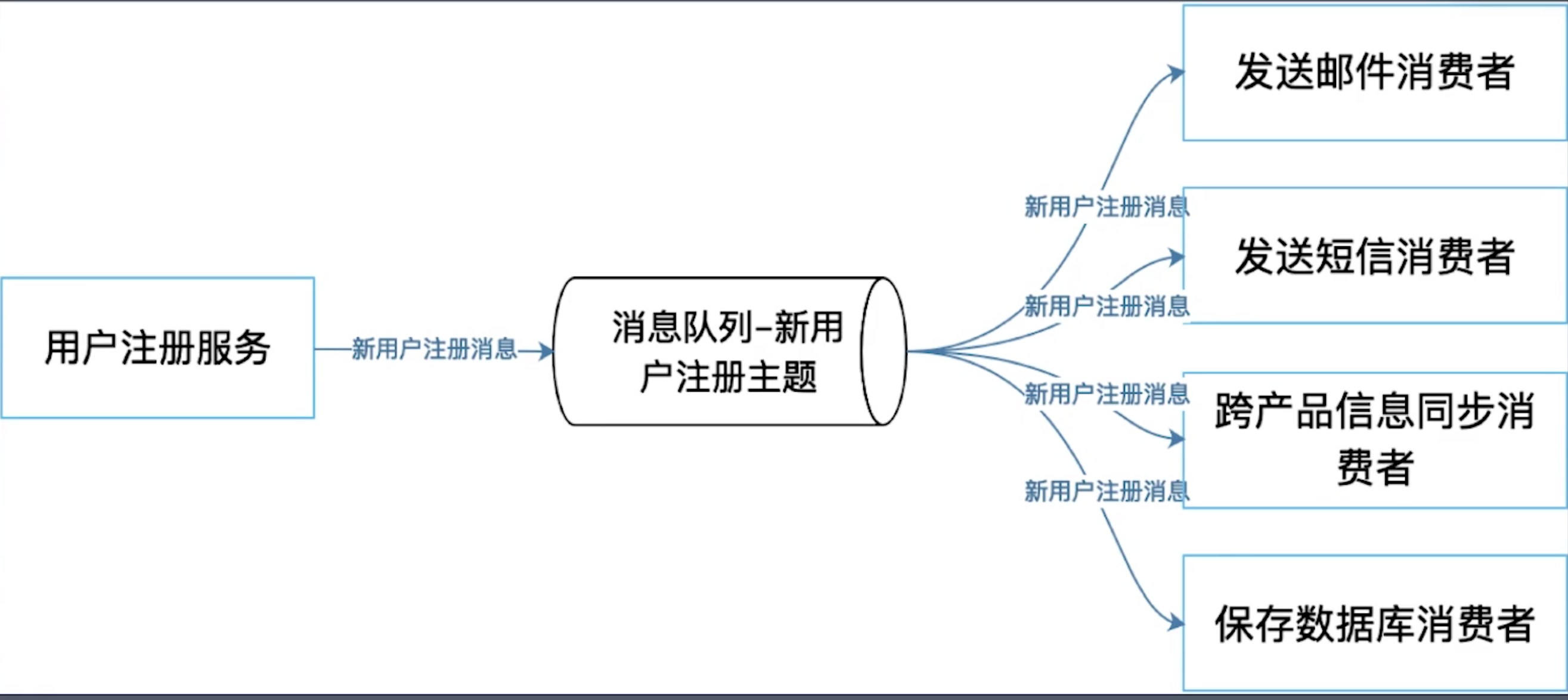
一个对比实例
主要的MQ产品
- RabbitMQ
- ActiveMQ
- RocketMQ
- Kafka
负载均衡
负载均衡的两个关注点
如何把请求发送给应用服务器
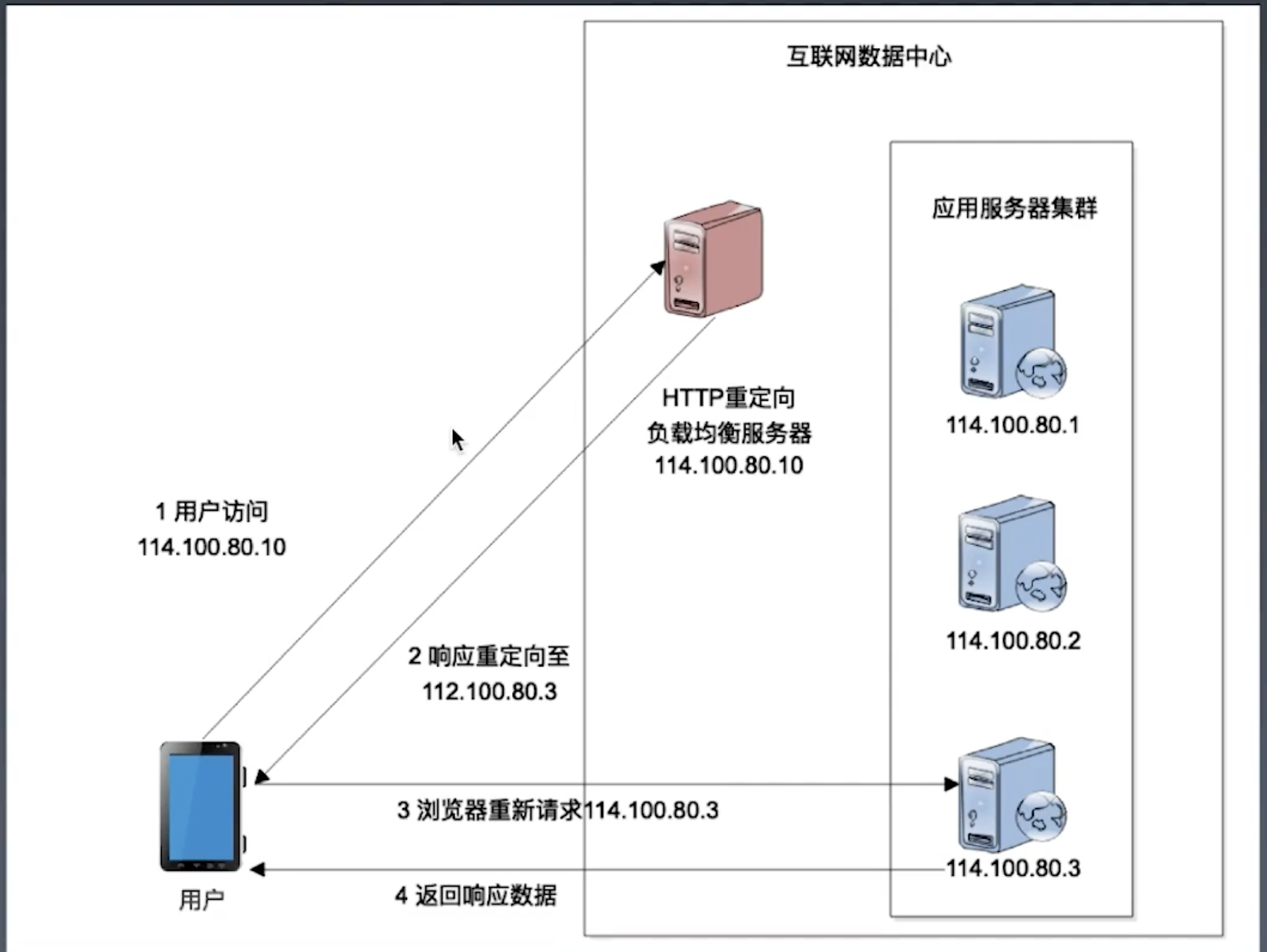
- http重定向负载均衡
通过http协议中的重定向功能,把应用服务器地址写到http header中
缺点:
- 需要两次重定向
- 客户端流量较大
- 将应用服务器直接暴露出来
- DNS负载均衡
- DNS服务器进行域名解析时,可以返回多个IP
- DNS解析的结果会缓存在本地,所以如果直接返回应用服务器的IP,将会不利于即时生效
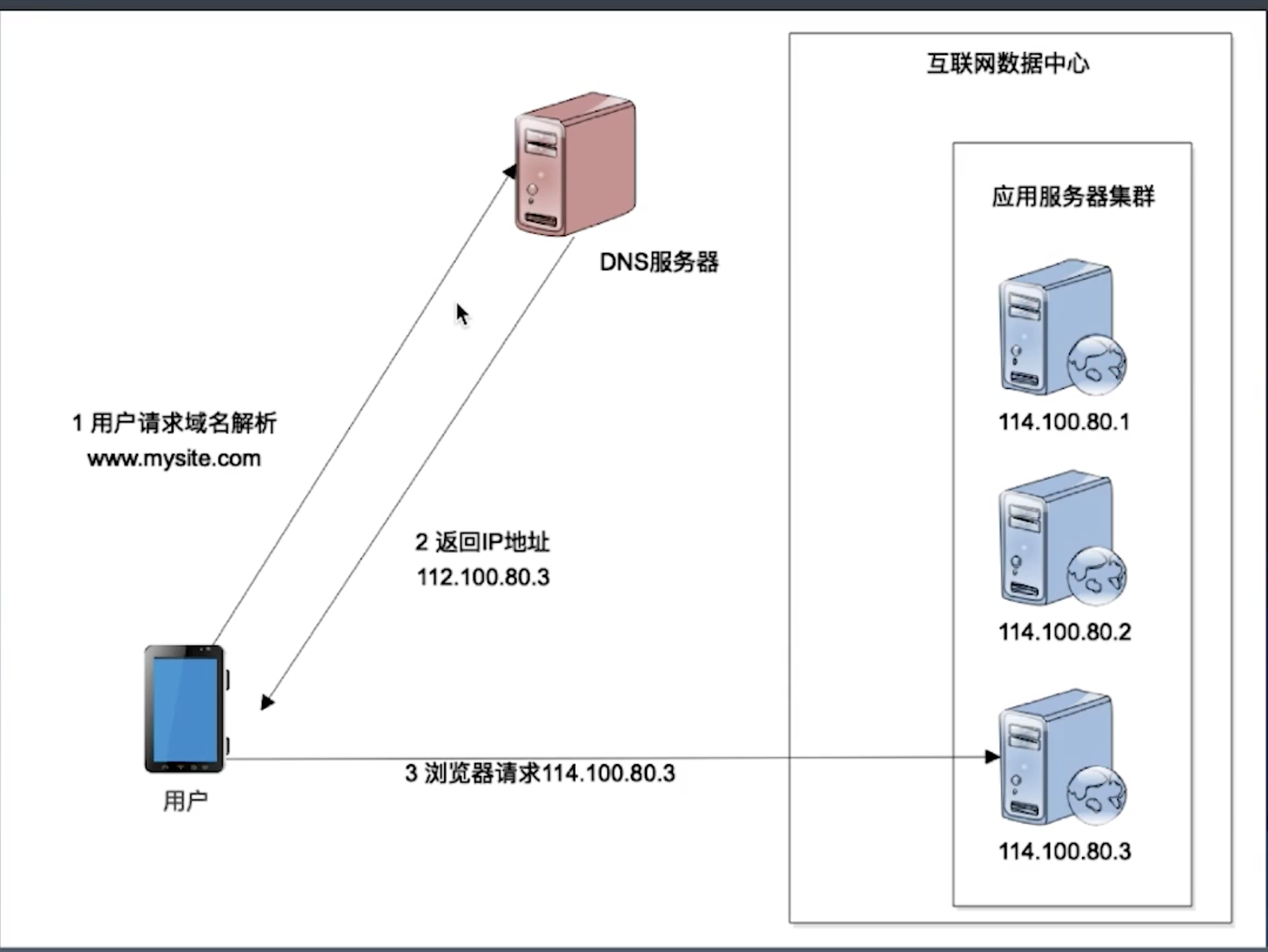
- 反向代理负载均衡
基于http协议的转发
适用于小规模服务器,服务器集群不能太多。
反向代理服务器效率就会比较低
- http协议比较重,包比较大,要拿到完整的http包才能继续,所以解析压力就大
- IP负载均衡
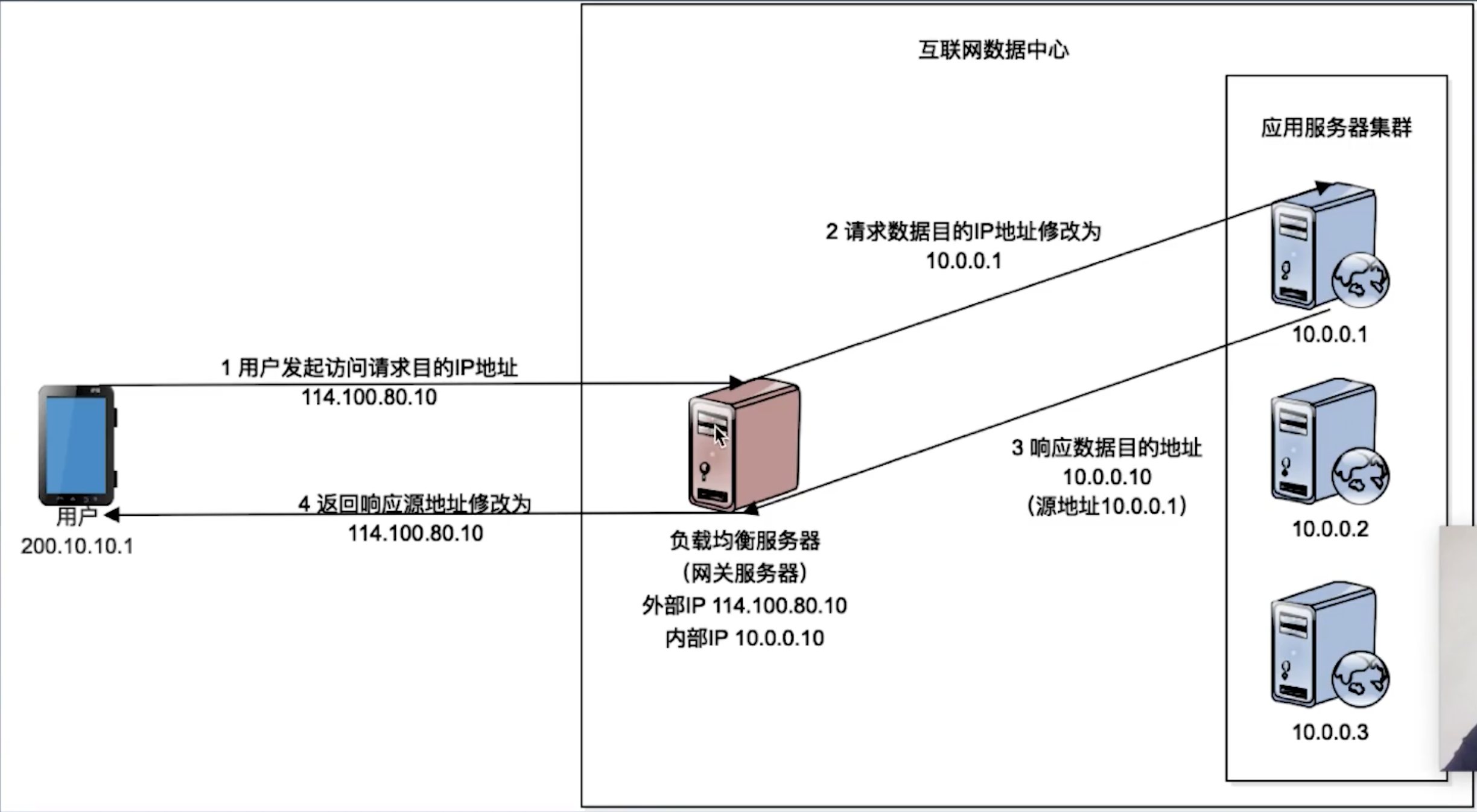
负载进化服务器不再需要拿到完整的http包,而只要拿到ip层的请求;
转发请求时,将源地址改为负载均衡服务器IP,目标地址改为应用服务器IP
- 数据链路层负载均衡
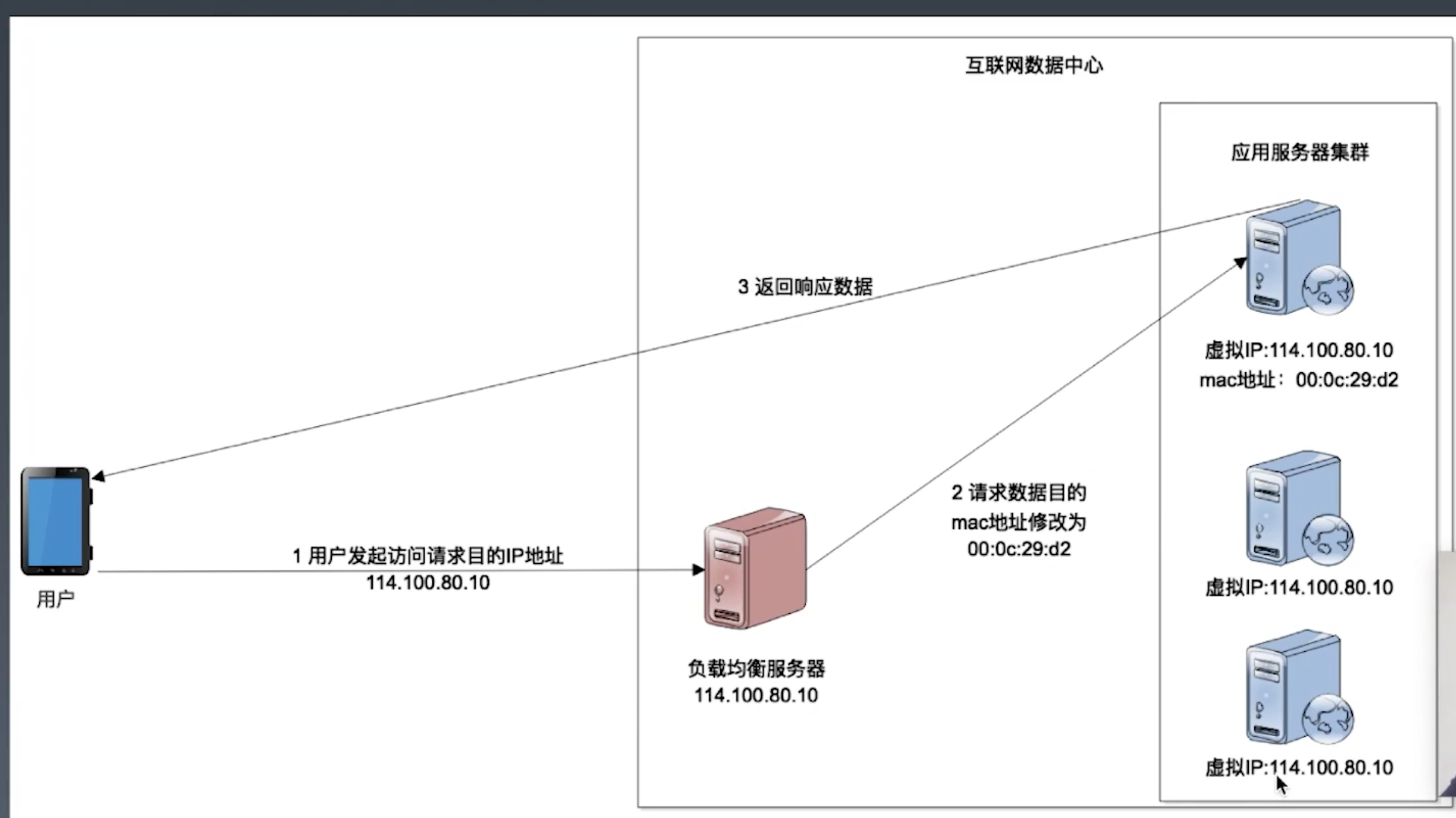
负载均衡的算法:请求应用服务器的路由选择
- 轮询
- 加权轮询
- 随机
- 加权随机
- 最少连接
- 原地址散列
扩展
Redis分桶原理
关于hashCode
hashCode()方法的存在是为了减少equals()的调用;当调用equals()时,先判断hashCode是否相等,如果不等,那两个对象肯定不相等,equals() 直接返回false;只有当hashCode()返回为true时,才需要再通过equals() 判断。
String类在重写equals()时,也重写了hashCode()。
public int hashCode() {int h = hash;if (h == 0 && value.length > 0) {char val[] = value;for (int i = 0; i < value.length; i++) {h = 31 * h + val[i];}hash = h;}return h;}
和equals()的逻辑是一致的。在object类中,hashcode()方法是本地方法,返回的是对象的地址值,而object类中的equals()方法比较的也是两个对象的地址值。
String的 equals 判断的逻辑是判断字符串中每个字符是否相等,hashCode的逻辑则是按照某种计算方法得出一个int,也就是说都是和字符串中每个字符有关的
public boolean equals(Object anObject) {if (this == anObject) {return true;}if (anObject instanceof String) {String anotherString = (String)anObject;int n = value.length;if (n == anotherString.value.length) {char v1[] = value;char v2[] = anotherString.value;int i = 0;while (n-- != 0) {if (v1[i] != v2[i])return false;i++;}return true;}}return false;}
参考

若有收获,就点个赞吧
0 人点赞
