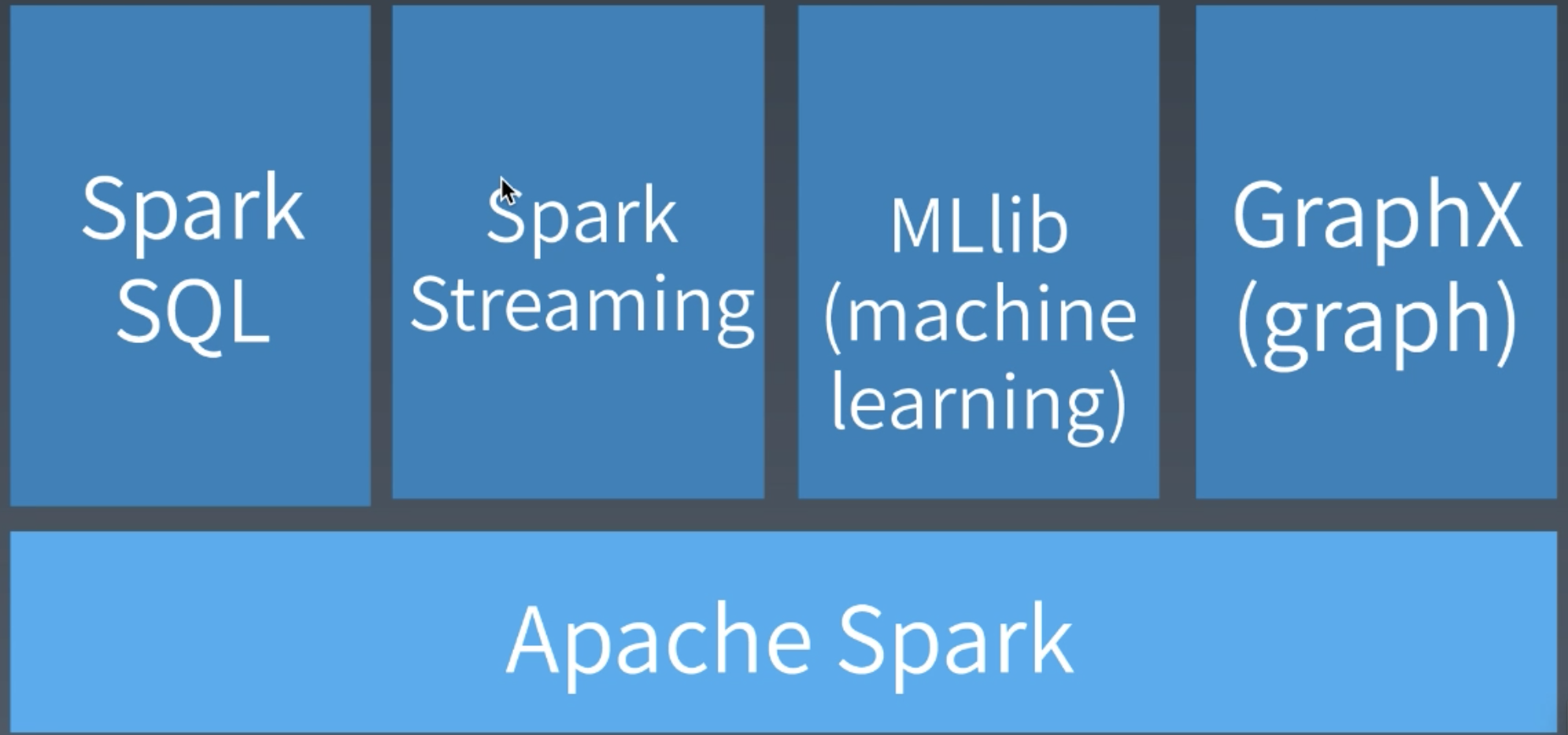
Spark
Spark VS Hadoop
Spark特点
将输入数据的每一行文本用空格拆分为单词
- 将每个单词进行转换, 生成(word,1)的结构
- 相同key进行统计, 对value求和

3: 将这个rdd保存到hdfs
示意图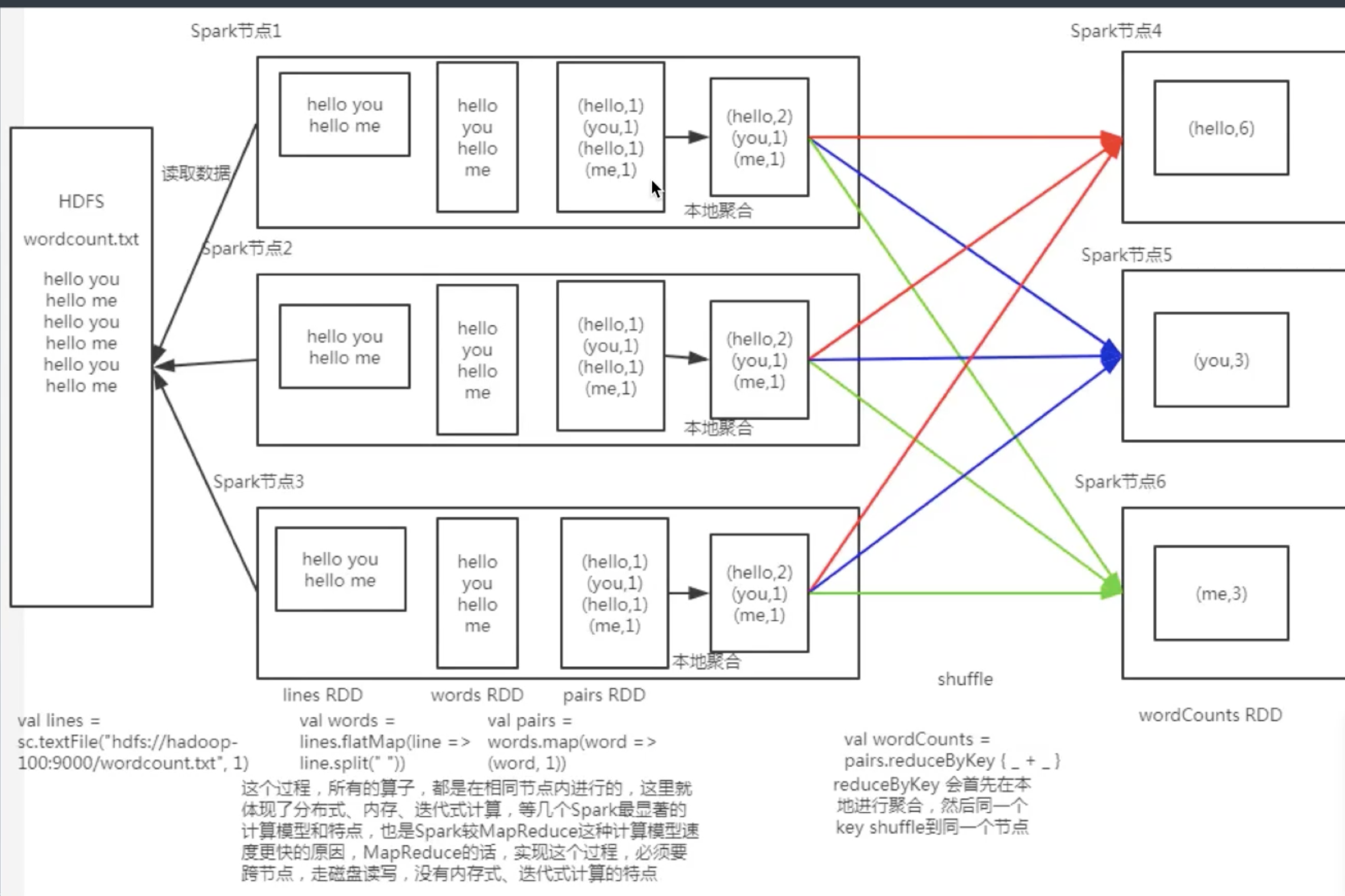
作为编程模型的RDD
RDD是Spark的核心概念, 是弹性分布式数据集的缩写.
RDD既是Spark面向开发者的编程模型, 又是Spark自身架构的核心元素.
MapReduce针对输入数据,将计算过程分为Map和Reduce两个阶段, 可以理解成 面向过程 的大数据计算, 在使用MapReduce编程时, 要考虑的是, Map和Reduce的输入和输出是什么.
Spark则直接针对数据编程, 将大规模数据集合抽象为一个RDD对象, 然后在这个RDD对象上做各种计算处理, 得到一个新的RDD对象, 然后继续计算处理, 知道得到最后的结果.所以Spark可以理解成是面向对象的大数据计算, 在使用Spark编程时, 要考虑的是, 一个RDD对象需要经过什么样的操作, 转换成另一个RDD对象, 思考的重点是在RDD上.
RDD上定义的函数分为两种:
- 转换函数
- 返回值还是RDD
- 执行函数
- 返回值不再是RDD, 比如上面的最后一行代码
作为数据分片的RDD
Spark分布式计算的数据分片, 任务调度都是以RDD为单位展开的, 每个RDD分片都会分配到一个执行过程去处理.
RDD上的转换操作有两种:
- 一种是转换操作产生的RDD, 不会出现新的分片, 结果还是在当前分片. 比如map, filter等
- 一种是会产生新的分片, 比如reduceByKey

惰性计算
也叫延迟计算, 并不是按照代码的顺序执行的. spark的计算是在将任务分发后才开始执行的.
Spark的计算阶段
和MapReduce一个应用一次只运行一个Map和一个Reduce不同. Spark可以根据应用的复杂程度, 分割成更多的计算阶段(stage), 这些计算阶段组成一个有向无环图DAG, Spark任务调度根据这个DAG的依赖关系执行计算阶段.
Spark的作业管理
- 转换函数, 调用以后得到的还是一个RDD, RDD的计算逻辑主要通过转换函数完成.
- action函数, 调用以后不再返回RDD, Spark在遇到一个action函数时, 会生成一个作业(Job).
RDD里面的每个数据分片, Spark都会创建一个计算任务区处理, 所以一个计算阶段会包含很多个计算任务(Task)
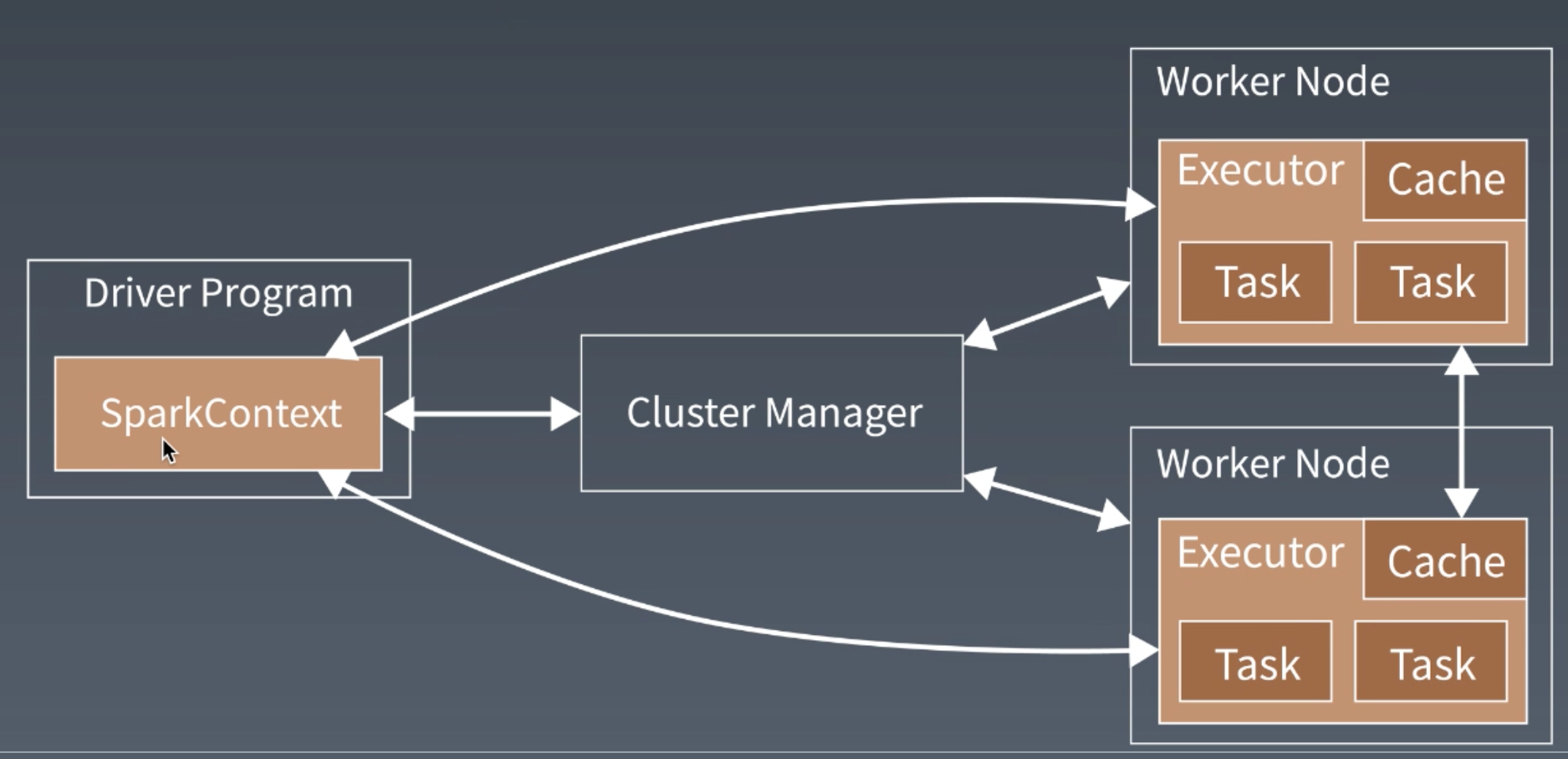
Spark的执行过程
Spark 生态体系
流计算
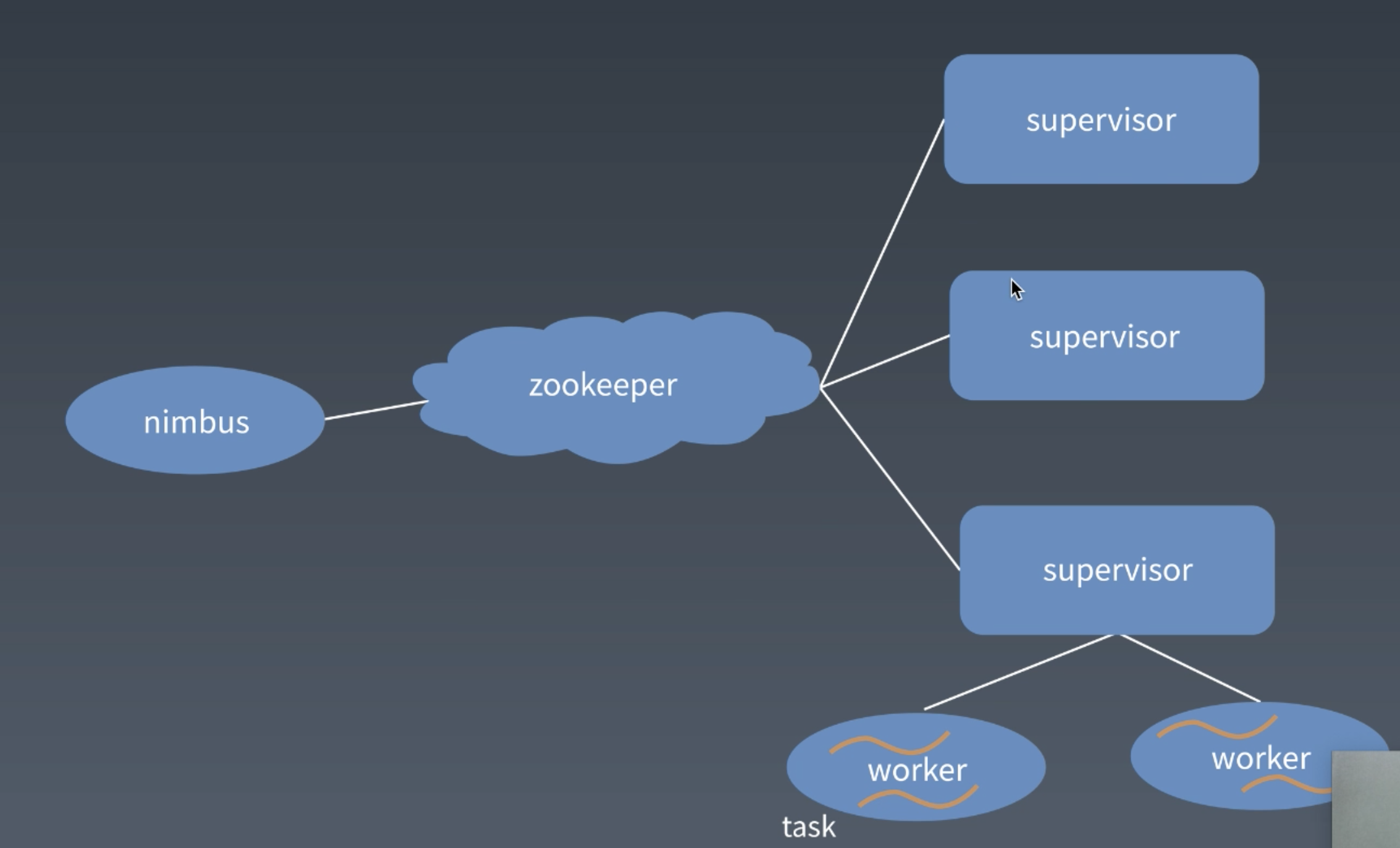
Storm
- 可以理解是实时的Hadoop

- Storm的部署图
- 所有的大数据框架部署都是类似的
Spark Streaming
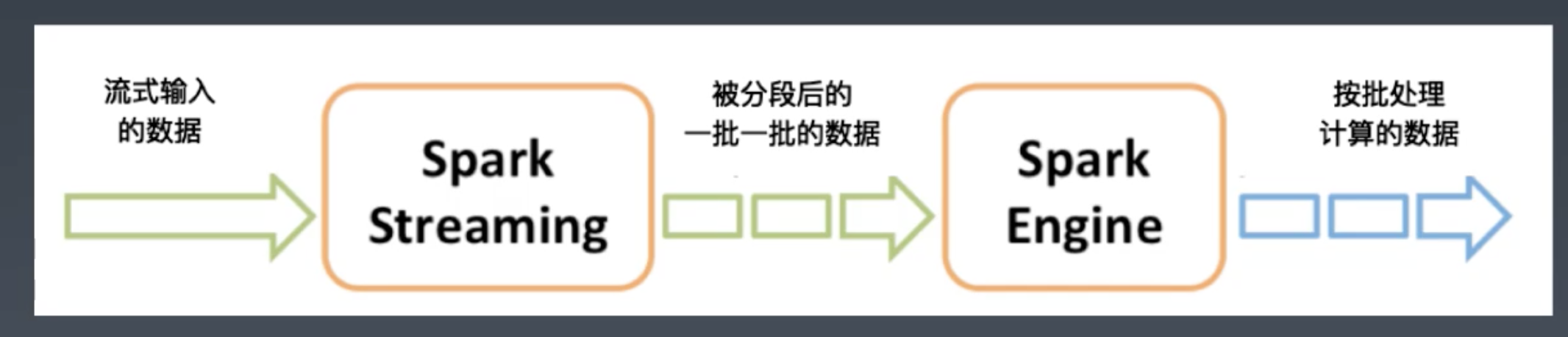
实际上批处理, 只是批处理的分片做的足够小, 就类似实现了实时的效果
Flink
支持流计算和批处理计算.
大数据可视化
解决大数据怎么用的问题
数据大屏
互联网运营常用指标
- 新增用户数
- 日新增用户数
- 周新增用户数
- 月新增用户数
- 用户留存率
- 经过一段时间依然没有流失的用户称为留存用户
- 留存用户数/当期新增用户数
- 用户流失率=1-用户留存率
- 活跃用户数
- 打开使用产品的用户数
- 日活/月活
- PV
- GMV
- 成交总额
- 配合使用的还有订单量/客单价(单个订单的平均价格)等
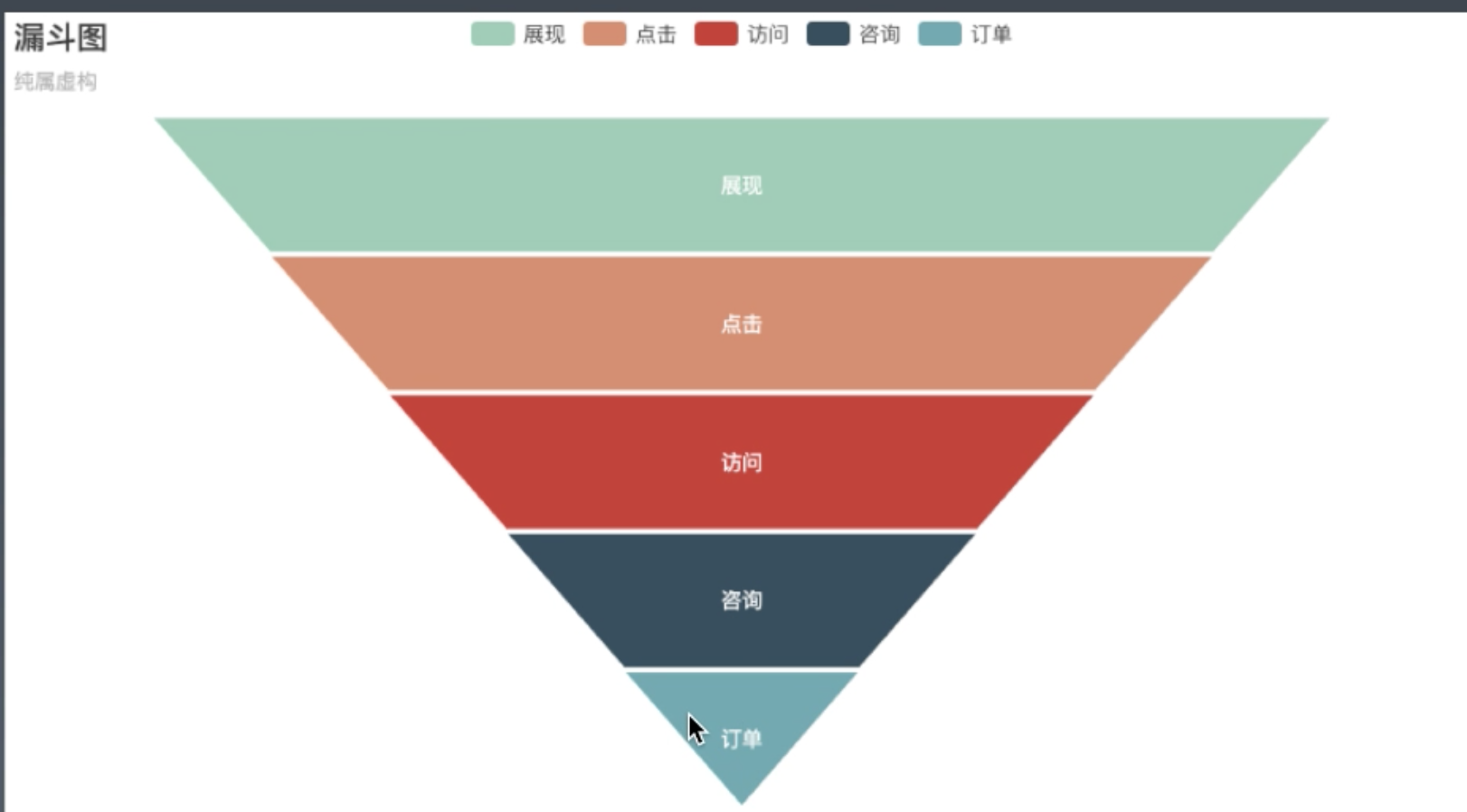
- 转化率
- 有购买行为的用户数/总访问用户数
- 漏斗图
数据分析与机器学习
- Google PageRank
- 当A页面中包含一个B页面的链接, 就表示B页面对A页面是有价值的, 也就相当于A页面为B页面投了一票
- 投票数越多的页面, PR值越高
- KNN分类算法
- 用于解决分类的问题
- 对于一个需要分类的数据, 与一组已经分类好的样本集合进行比较, 取到距离最近的K个样本, K个样本中最多归属的类别 ,就是这个数据的类别
- 数据的距离算法
- 确定特征值
- TF-IDF算法

- TF: 词频, 表示某个单词在当前文档中出现的频率
- IDF: 逆文档频率, 表示这个单词在所有文档中的稀缺程度
- 当一个词在当前文档中出现的频率很高, 但在所有文档中出现的频率很低, 说明这个词就是当前文档的特征值.
- 贝叶斯分类算法
- K-means聚类算法
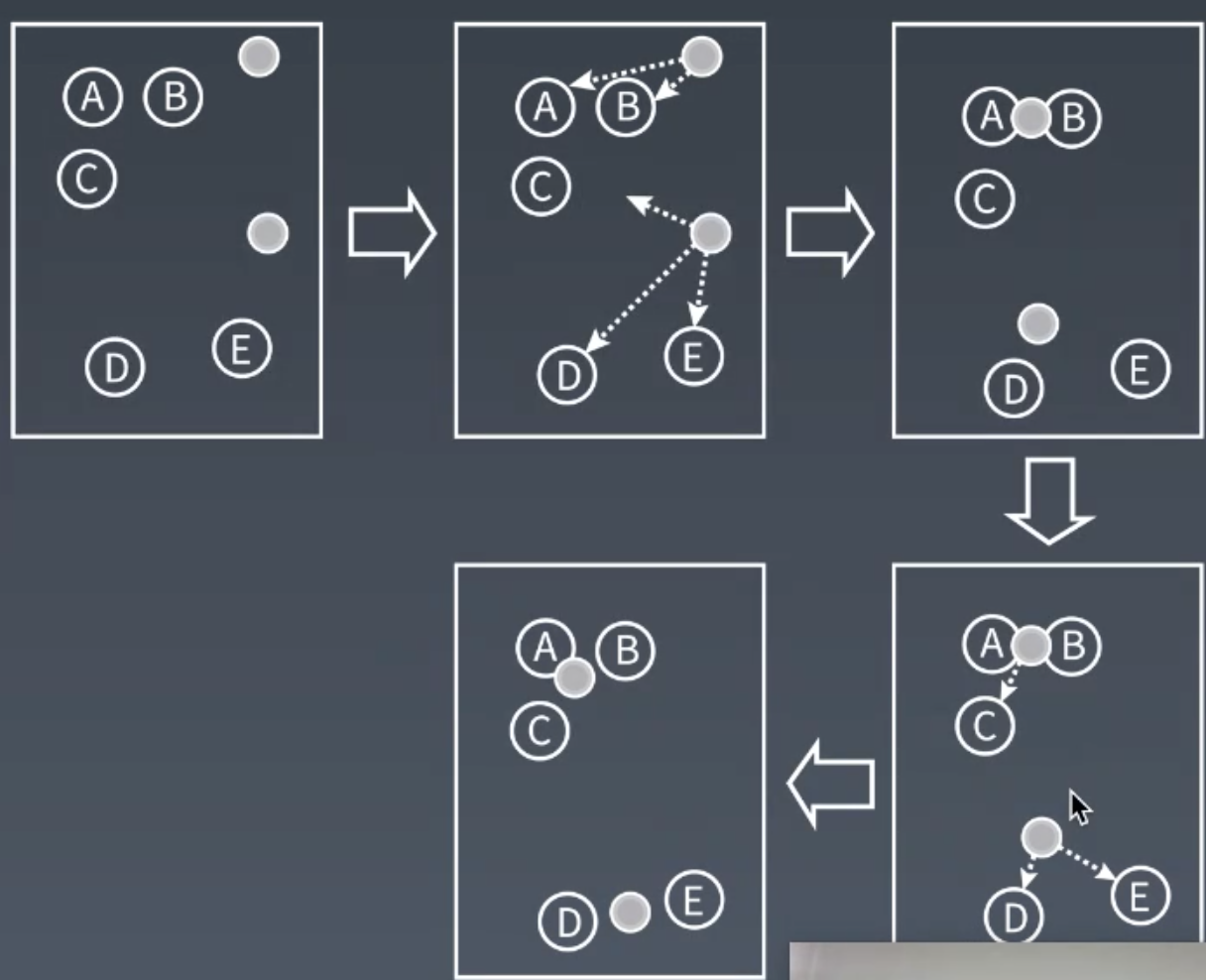
- 随机在图中取K个种子点
- 求图中所有点到这K个种子点的距离, 最终将形成K个群
- 对已经分好群的点, 求其中心点.
- 重复上面的步骤, 指到每个群的中心点不再移动. 距离每个中心点最近的点就聚为同一组数据
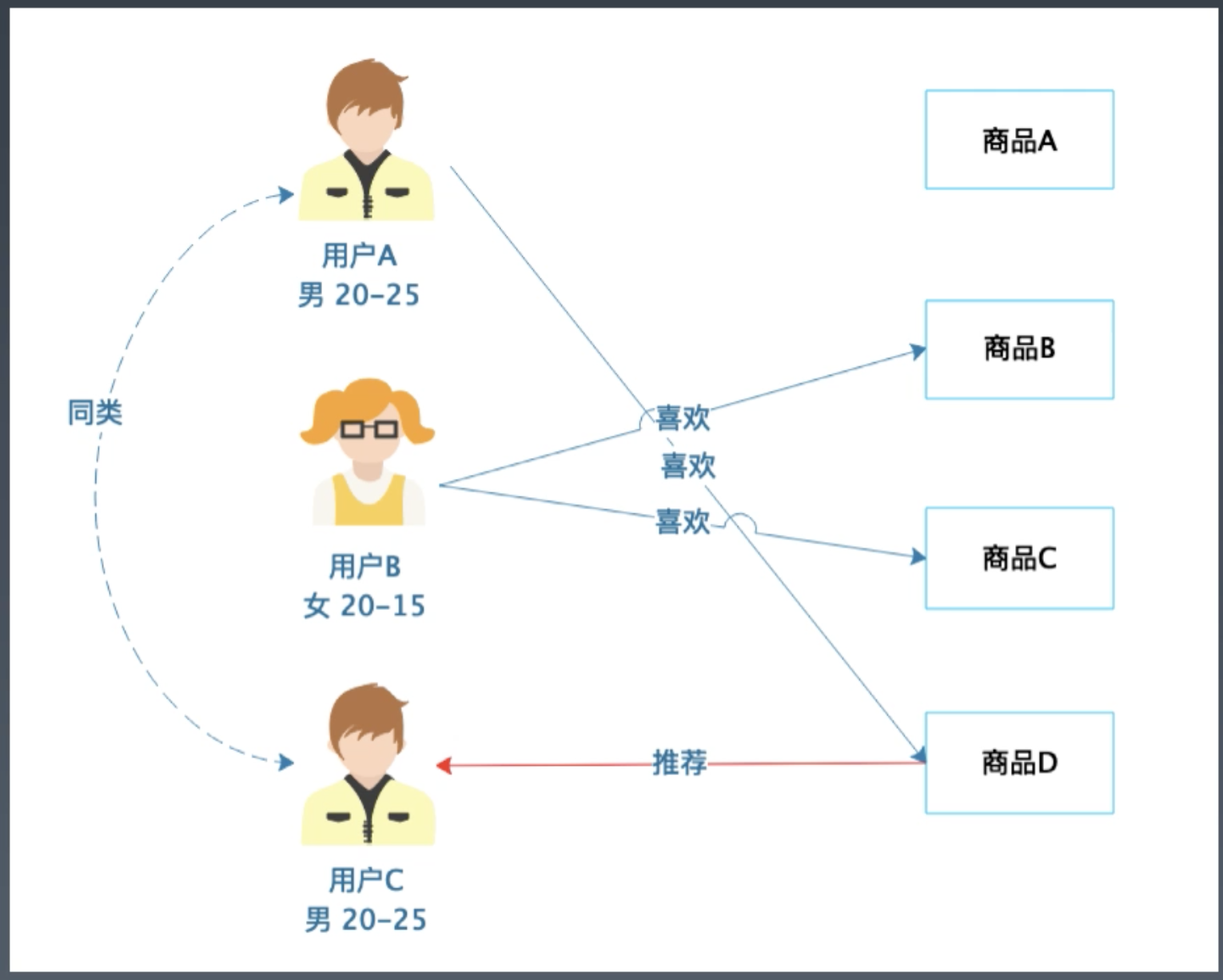
- 推荐引擎算法
- 基于人口统计的推荐, 通过用户画像找到同类用户
- 基于商品属性的推荐
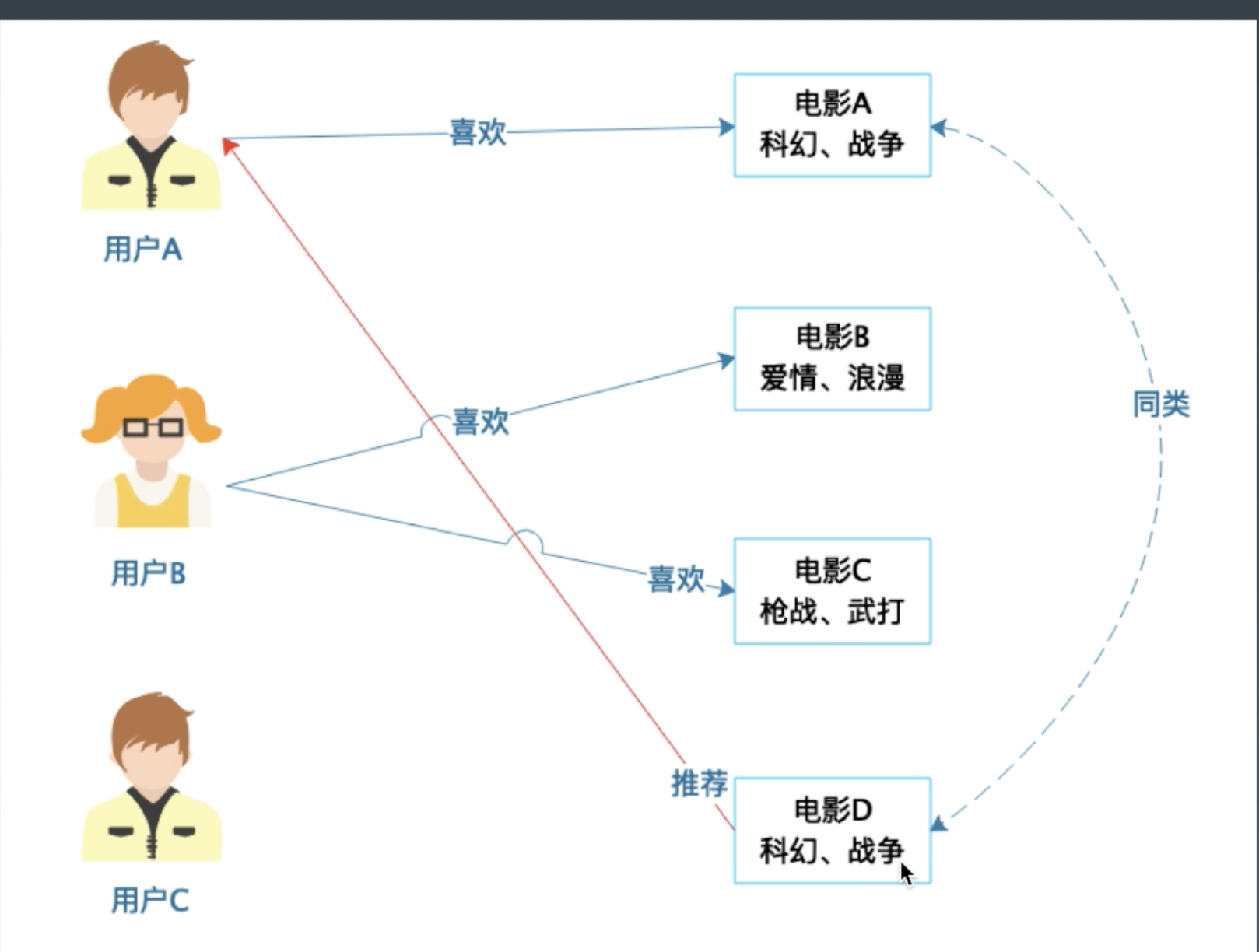
- 基于用户的协同过滤推荐
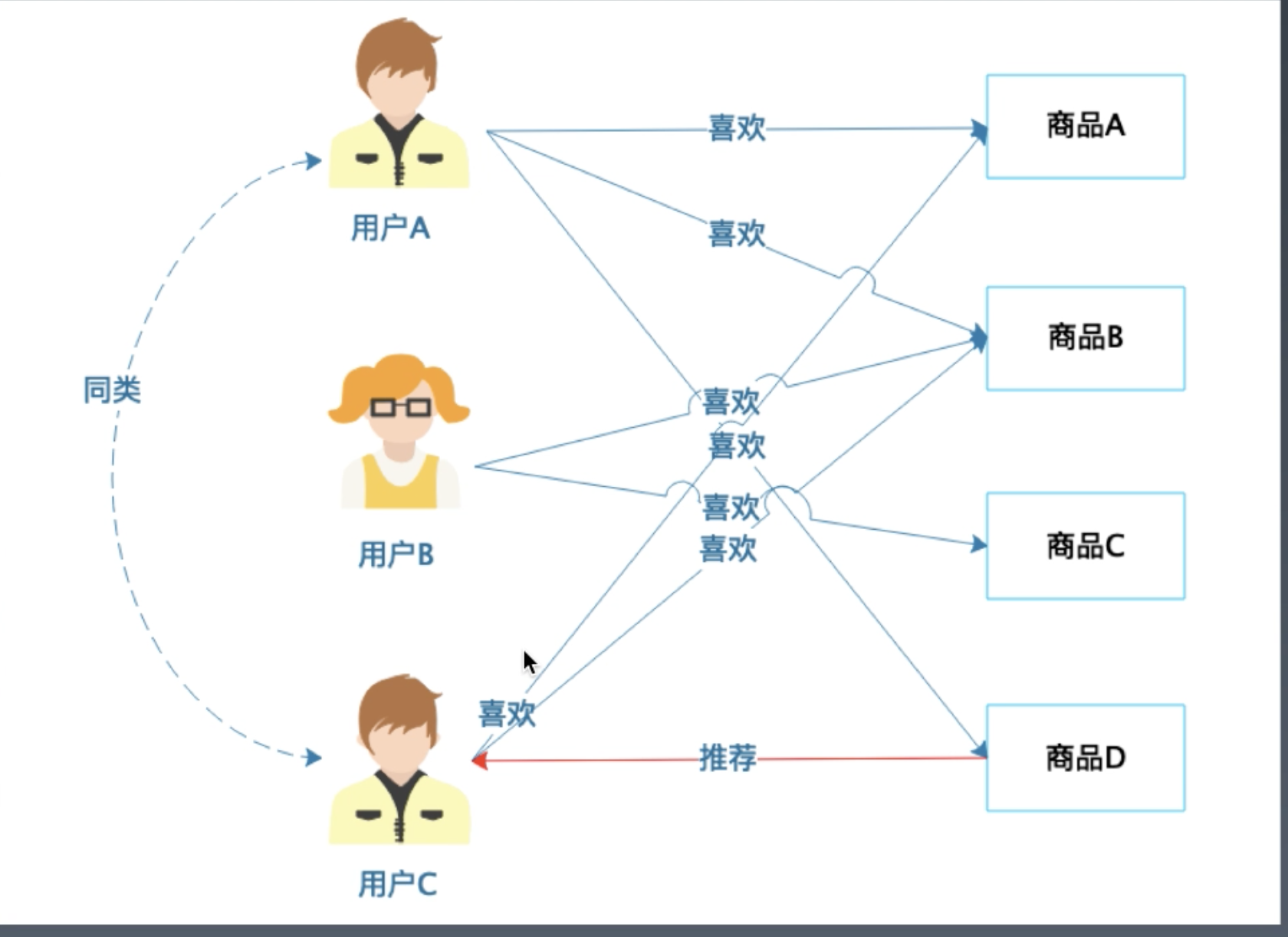
- 基于商品的协同过滤推荐

- 基于人口统计的推荐, 通过用户画像找到同类用户
- TF-IDF算法
- 欧式距离计算公式
- 余弦相似度计算公式
- 确定特征值
机器学习
系统架构
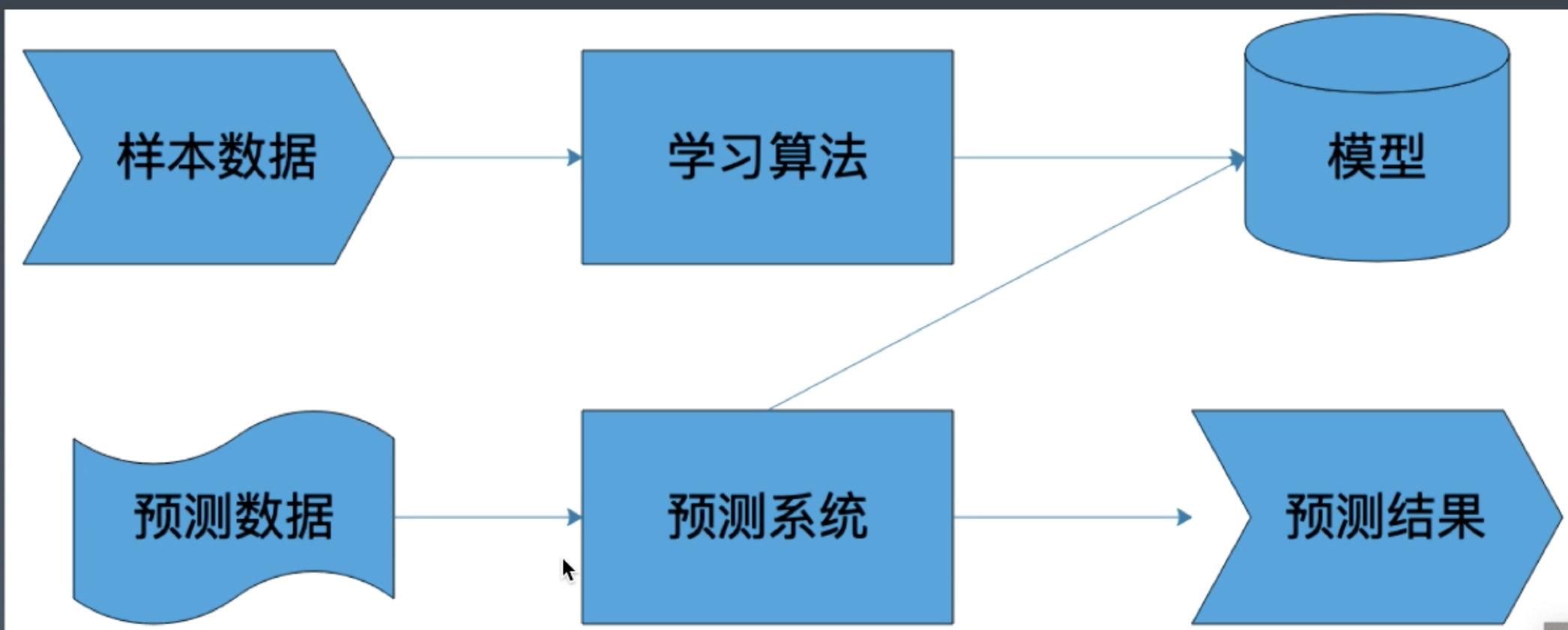
- 样本
- 包括输入和结果两部分
- 举例

- 模型
- 映射样本输入和样本结果的函数, 可能是一个条件概率分布, 也可能是一个决策函数.
- 一般先确定函数, 通过样本确定函数中的参数.
- 算法
- 算法就是要从模型的假设空间中寻找一个最优的函数, 使得样本空间的输入x经过该函数的映射得到的f(x), 和真实的Y值之间距离最小
- 如何保证f函数或者f函数的参数控件最接近最优解, 就是算法的策略
- 损失函数用来评估模型是否最接近最优解

若有收获,就点个赞吧
0 人点赞
