 数据库连接工具 选择
数据库连接工具 选择
工具1 datagrip :https://www.jetbrains.com/zh-cn/datagrip/
工具2 navicat
数据库配置文件
Linux 安装 Postgres
Linux 配置文件存放路径

数据库安装完成 修改 pg_hba.conf
配置完成后 重启 服务生效,此配置设置 所有ip地址都可以访问数据库,不配置此选项,需要在此配置文件内设置固定的 访问IP地址
host all all 0.0.0.0/0 md5
修改pg_config文件
将文件中的 对应的键替换成 如下的值,修改此参数 是为了 查询最耗时SQL用的
shared_preload_libraries = 'pg_stat_statements'pg_stat_statements.max = 1000pg_stat_statements.track = all
如果出现 获取当前时间不正确 需要配置时区
配置 postgresql.conf 找到 timezone
timezone = 'Asia/Shanghai'
安装常用扩展包
postgresql 有很多官方和第三方开源的扩展包,有很强大辅助功能,我们要解决复杂的处理,先看看网上有没有人已经提供了扩展包 无需我们自己实现
--此扩展包 固定列的交叉表转换函数create extension tablefunc;--可查询 最好是视图的扩展包create extension pg_stat_statements;
开发工具 1,连接 数据库 获取时间不正确,设置 工具的 timezone ,Asia/Shanghai
系统数据查询
查询系统配置
select * from pg_settings
查询系统配置文件路径
select * from pg_file_settings where name ='TimeZone';
查询最耗时SQL表
select * from pg_stat_statements;
查询锁表
--bs_account 你要查看锁表的 表名--查询锁表语句select * from pg_stat_activitywhere pid in ( select pid from pg_locks l join pg_class t on l.relation = t.oid and t.relkind = 'r' where t.relname = 'bs_account');--解锁select pg_cancel_backend(pid) from pg_locks ljoin pg_class t on l.relation = t.oid and t.relkind = 'r'where t.relname = 'bs_account'
查询所有表及字段
SELECT info.table_name AS "表名",CASEWHEN const.constraint_name IS NULL THEN ''::textELSE 'p'::textEND AS pk,info.column_name AS "列名",info.udt_name AS "数据类型",COALESCE(info.character_maximum_length::integer, 9999) AS "数据长度",CASEWHEN info.is_nullable::text = 'YES'::text THEN '是'::textELSE '否'::textEND AS "允许为空"FROM information_schema.columns infoLEFT JOIN information_schema.tables tables ON tables.table_name::name = info.table_name::nameLEFT JOIN information_schema.constraint_column_usage constON const.table_name::name = tables.table_name::name AND const.column_name::name = info.column_name::nameWHERE tables.table_type::text = 'BASE TABLE'::textORDER BY info.table_name;
存储过程和函数
postgresql 在 13 以前没有存储过程,所有统一使用函数,13的以后的存储过程 和 函数基本一样
所以我们项目还是 统一将 存储过程也创建成函数,plv8 和 python 用存储过程
oracle 和 pg 语法区别
查询虚拟表
--Oracleselect 1 from dual ;-- postgresqlselect 1 ;
数据类型
| oracle类型 | pg数据类型 | 备注 |
|---|---|---|
| varchar2,nvarchar2 | varchar | |
| clob | text | text 和 varchar没有存储限制上没有区别,建议使用 varchar 不给长度 |
| char(1) | boolean,bool | |
| date | date 或 timestamp | date:值存储到日期 timestamp: 存储到时间 |
| number | numeric | |
| integer | integer |
数据类型一致性
oracle中可能出现 同样是字符,出现字符集不相等的时候,通常我们会将2边的 字段都用 to_char 转换类型,
pgsql 就不要这么操作,如果在字符上使用to_char,pg将会出现错误。to_char 在pg中也是用来做日期格式化的
函数不同
| oracle函数 | postgresql函数 | 备注 |
|---|---|---|
| instr | position | |
| substr | substr | pg的下标从1开始 |
| nvl | coalesce | 特别注意oracle nvl 的返回值是任意类型,但是pg的返回值,必须第一个参数的字段类型一致, 我自己封装了一个 nvl 函数仅限于字符类型和数字类型使用,正常情况下 不需要用我写的 |
| sysdate | now() | |
| listagg | string_agg |
代码块 begin end;
oracle 的代码块是 declare begin end;
postgresql 的代码块如下
do$do$declarebeginend;$do$;
字符串拼接
在 Oracle 拼接字符串,遇到字符串单带单引号的,拼接起来需要 将2两边的单引号 对上,异常麻烦 在 postgresql 中 提供了 符号,被 包裹的 单引号 只是作为字符使用
--其他数据库拼接单引号。此SQL的单引号异常复杂select 'to_char(now(),''' || 'yyyy-dd-mm' || ''')' ;--postgresql 的拼接单引号,postgresql 也支持 上面的SQL语句select $$to_char(now(),'$$ ||$$yyyy-dd-mm$$|| $$')$$;
文本输出语句
--% 固定写法 str 是要输出的变量raise notice '%',str;
常用函数
所有函数查看 官方文档 :
| 返回非空值 | coalesce | coalesce(A,B) | 当参数A为Null返回参数B | 当A |
|---|---|---|---|---|
| nullif | nullif(A,B) | 当A和B相等返回A | ||
| 全球唯一码 | gen_random_uuid | 生成全球唯一码 | ||
| 替换指定位置字符 | overlay | select overlay(A placing B from 开始下标 for 结束下标); | 将 A 字符串 开始位置 到 结束位置 替换成B字符串 | |
| 替换指定字符 | replace | replace(‘abcdefabcdef’, ‘cd’, ‘XX’) | 将字符串中的cd 替换成 xx | |
| 返回字符长度 | length | length(A) | ||
| 分割字符串 | split_part | select split_part(A, B, 下标) ; | 将A字符 按B字符进行分割,返回执行下标的字符串 | |
| 正则表达分割字符串 | regexp_split_to_table | select regexp_split_to_table(A,B) | 将A字符 按B字符进行分割,返回表 ,此函数 B 参数支持正则表达式 regexp_split_to_array 这个函数返回数组, |
|
| 返回行号 | row_number | rownumber() over() | 返回行号 | |
| 提取日期 | date_part | date_part(A,B) 例子: date_part(‘hour’,now()) |
A 参数是要提取的 类型 有:year month,day hour 等 B 要提取的日期 |
|
| 截取日期 | date_trunc | date_trunc(A,B) 例子: date_part(‘hour’,now()) |
hour以后的日期,将被替换成默认值 | |
| 提取interva日期 | extract | extract(type from interval) | type 参数是要提取的类型 有:year month,day hour 等, interval 要提取的 interval 类型的时间值 |
|
自定义函数模板
调用函数
select return_basic() ; --返回字段select * from return_basic() ; --返回表
返回基本类型
create function return_basic()returns integeras$function$declareout integer;beginout := 1;return out;end;$function$ language plpgsql;
返回自定义类型
--创建自定义类型create type type_person as(iid varchar(100),cname varchar(200));
--模板1create function return_type() returnsSETOF type_personlanguage plpgsqlas$function$declarerow type_person;cur cursor for select iid,cname from as_person;beginfor row in cur loopreturn next row;end loop;return ;end;$function$;--模板1-1create function return_type() returnsSETOF type_personlanguage plpgsqlas$function$declarerow type_person;cur cursor for select iid,cname from as_person;beginfor row in cur loopif row.iid <> '1' thenreturn query execute 'select '||$$''$$ || '::varchar(100) as iid,' ||$$'测试'::varchar(200) as cname $$ ;row.cname := 'xx';return next row;elsereturn query execute 'select '||$$'1'$$ || '::varchar(100) as iid,' ||$$'测试'::varchar(200) as cname $$ ;end if;end loop;return ;end$function$;
--模板2 动态SQLcreate function return_type()returns SETOF 你的自定义类型as$function$declarecsql text;begincsql := '你的SQL';return query execute csql;return ;end;$function$ language plpgsql;
返回游标
create function return_cursor(OUT curs refcursor )returns refcursoras$$declarebeginopen curs for execute '你的SQL';end$$ language plpgsql;
小技巧
日期加减
postgresql 有一个数据类型 interval 时间间隔,利用这个 类型可以轻松进行 日期的操作
select now() - '1 year'::interval ;select now() - '1 day 23 hour'::interval;
类型转换
可以使用 :: 符号进行类型转换
--函数显示转换select cast(now() as varchar(10));--::快捷转换 建议用这个select now()::varchar(10);
返回询前N行
row_number() 函数
返回行号
select * from (select row_number() over () as row_num,cname from aa_data) as a where row_num <= 5
limit 关键字
提取前N行数据
select cname from aa_data limit 5;
分页
分页功能 用到 limit 和 offset 2个关键字组合使用 limit 已做过讲解,offset 作用是从第几行开始返回数据
do$$declarepage_count int; --每页行数current_page int; --当前页page_star_row int; --当前页起始行beginpage_star_row := page_count * current_page;select cname from aa_data limit page_count offset page_star_row;end;$$;
实现分组小计
通过 grouping sets 或者 rollup
grouping sets
-- 特别注意空的()意思是,将所有行进行汇总,最后一行总合计--(科目)是一个小分组条件,(科目,人员)又是一个分组条件,以此类推with tem as (select '科目1' as "科目", '张三' as "人员", 10 as "分数"union allselect '科目2' as "科目", '张三' as "人员", 40 as "分数"union allselect '科目3' as "科目", '张三' as "人员", 20 as "分数"union allselect '科目1' as "科目", '李四' as "人员", 20 as "分数"union allselect '科目2' as "科目", '李四' as "人员", 30 as "分数"union allselect '科目3' as "科目", '李四' as "人员", 50 as "分数")select "科目", "人员", sum("分数") from temgroup by grouping sets (("科目"),("科目","人员"),())order by 科目;
效果: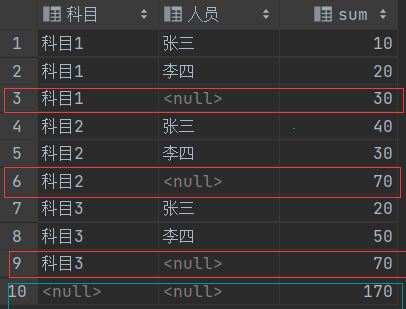
rollup 效果同上是一样的
with tem as (select '科目1' as "科目", '张三' as "人员", 10 as "分数"union allselect '科目2' as "科目", '张三' as "人员", 40 as "分数"union allselect '科目3' as "科目", '张三' as "人员", 20 as "分数"union allselect '科目1' as "科目", '李四' as "人员", 20 as "分数"union allselect '科目2' as "科目", '李四' as "人员", 30 as "分数"union allselect '科目3' as "科目", '李四' as "人员", 50 as "分数")select "科目", "人员", sum("分数") from temgroup by rollup (("科目"),("科目","人员"))order by 科目;
Filter 代替 case when then
filter 在聚合统计的时候 ,在数据量大的情况下,比case的效率高 filter 和 函数组合使用
-- 等价下面语句,filter 效率会更快,语法也更好理解-- sum(case temp.class when '二班' then temp.score else null end ) as "二班分数",with temp as (select '一班' as class , 10 scoreunion allselect '一班' as class , 20 scoreunion allselect '二班' as class , 3 scoreunion allselect '二班' as class , 20 score) select class,sum(score) filter ( where class = '二班') as "二班分数",sum(score) filter ( where class = '一班') as "一班分数" from tempgroup by class;
递归截取字符串
已逗号分隔 截取字符串,返回结果集
WITH RECURSIVE t AS (SELECT 1 as count, substring('a,b,c' from '[^,]+') as ss FROM dualunion allSELECT t.count + 1 as count, substring( substr('a,b,c',position(ss in 'a,b,c') + 1,length('a,b,c')) from '[^,]+') as ss FROM twhere t.count < ( length('a,b,c') - length(replace('a,b,c',',',''))+1 ))SELECT ss FROM t;
获取动态SQL的列名
实现思路:将结果集转换成JSON,JSON的键值就是SQL中查询的列名
do$$declarecol_name varchar;user_sql varchar;exec_sql varchar;begin--用户的SQLuser_sql := 'select 1 as id,2 as name';--获取JSON的键值exec_sql := 'select json_object_keys(a.js) from (select row_to_json(t.*) as js from ('||user_sql||' ) as t limit 1) as a';--循环查询列表名for col_name in execute exec_sql loopraise NOTICE '%',col_name;end loop;end;$$;
数据库备份及还原
全库备份
cmd 进入到postgresql安装目录 bin文件夹 执行 如下语句 pg_dump —hellp 可以查看更多备份 参数 -v 这个参数是,在控制台总输出 备份的明细
- 7全库备份 不建议使用,这将备份 系统库 和 系统用户等信息
1、--全库备份pg_dumpall --host=127.0.0.1 --username=cqpt --port=5432 -v --file=D:\PostgreSQL\backup.sql
备份指定库
- 建议使用 指定备份数据库,注意 2 备份出来的 没有用户和对应的数据库,还原时需要手动创建好用户和,同名的空数据库,在进行还原
2、--备份指定 数据库pg_dump --host 127.0.0.1 --port 5432 --username cqpt --file D:\Temp\backup --format p -v cqpt_database
还原数据库
还原数据库 cqpt_database 最后一个参数 还原到 cqpt_database这个数据库
--还原数据 到指定 用户 指定 数据库psql --username cqpt --set ON_ERROR_STOP=on --file D:\PostgreSQL\backup cqpt_database

若有收获,就点个赞吧
0 人点赞
