CAP 分布式系统定理
一致性 Consistency
可用性 Availability
分区容错性 Partition tolerance
遇到单点故障时,允许系统冗余部署,把系统分成多个分区,这样就能实现容错的效果,当A系统不可用时,B系统仍然是可运行的,通过这样仍然可以对外提供 一致性 和 可用性的服务
- CAP 定理统一时间只能满足2种条件
- zookeeper 是满足 cp 的分布式协调组件
当zk 单点故障时,会进行首领选举, 在首领选取期间,服务是不可用的,所以一不满足A的可用性
zookeeper 官方下载地址
linux 安装 zookeeper
解压zookeeper
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz
配置zoo.cfg
在安装路径下 **/apache-zookeeper-3.7.0-bin/conf 新建zoo.cfg文件,可参考此目录下的 zoo.sample.cfg创建
zoo.cfg
# The number of milliseconds of each tick# zookeeper中的时间基本单位(ms)毫毛tickTime=2000# The number of ticks that the initial# synchronization phase can take#允许follower(从节点)初始化连接到leader最大时常,ticks基本时间单位的倍数(tickTime * initLimit)initLimit=10# The number of ticks that can pass between# sending a request and getting an acknowledgement#允许从节点和主节点数据同步的最大时常 ,(tickTime * syncLimit)syncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just# example sakes.#zookeeper 数据存储目录及日志存储目录(如果没执行dataLogDir则日志数据也存储到此为止)dataDir=/tmp/zookeeper/datadataLogDir=/tmp/zookeeper/log# the port at which the clients will connect# 对客户端提供的端口clientPort=2181# the maximum number of client connections.# increase this if you need to handle more clients# 单个客户端与zookeeper并发连接数量maxClientCnxns=60## Be sure to read the maintenance section of the# administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir# 保存数据快照的数量autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature# 自动清除数据的时间间隔 小时为单位 ,设置为“0”可禁用自动清除功能autopurge.purgeInterval=2
bin 文件列表

# zk启动脚本zkServer.sh# zk 客户端脚本zkCli.sh
zookeeper服务器操作的基本命令
启动服务
./zkServer start ./conf/zoo.cfg
查看服务状态
./zkServer status ./conf/zoo.cfg
停止服务
./zkServer stop ./conf/zoo.cfg
zookeeper 数据结构

zookeeper 数据结构是树形接口,已 / 为起始点,操作节点其实也就是寻址的过程
节点操作命令
# 查看所有一级节点ls /# 查询这个节点下 所有的节点,递归查询# /test# /test/node1# /test/node/child1ls -R /test# 创建节点# 创建的是持久化节点create# 创建序列持久化节点# 创建出来的节点是有顺序的create -s /node#创建临时节点命令create -e /node# 获取节点数据 查询数据必须 已/开头get# 查看节点信息get -s#[zk: localhost:2181(CONNECTED) 20] get /test1/node3 -snull#创建节点的事务id#cZxid = 0x7#节点创建时间#ctime = Wed Jan 12 03:58:14 UTC 2022#修改节点的事务id#mZxid = 0x7#节点修改时间#mtime = Wed Jan 12 03:58:14 UTC 2022#添加和删除子节点的事务id#pZxid = 0x7#cversion = 0#节点内数据的本本,每次更新都会加1#dataVersion = 0#aclVersion = 0# 0x0 标识持久化节点 否则是临时节点#ephemeralOwner = 0x100008ed3470000#节点内数据的长度#dataLength = 0#numChildren = 0#删除节点,如果当前节点下又子节点将会报错delete /test1#删除当前节点 及所有的子节点deleteall /test1#乐观锁删除 删除版为0的数据,当同时编辑此节点数据时,会删除失败,应为当前版本号 +1delete -v 0 /test1
zookeeper 节点类型
持久化节点
临时节点
临时化节点: 创建完成的节点,在客户端会话与zk服务器断开连接后,zk服务器会在一定时间内自动清除此节点,每个客户端session都有一个过期时间,正常和zk服务器保持连接时,zk服务器会自动续约过期时间,
zookeeper 当做注册中心时 就是使用的临时节点
contaner 节点
container 节点下没有 任何子节点,一定时间后将自动清理
zookeeper 存储方式
zookeeper是内存存储机制,数据容易丢失,为此zookeeper提供了2种数据存储方式
2种存储方式是同时开启的,应为这样还原数据的速度会比较快,先恢复快照,然后对日志进行增量恢复
事务持久化
将zookeeper 执行的每条命令结果,已日志方式存储起来。(指定dataLogDir就保存在指定的路径内,否则保存在dataDir)
快照持久化
zookeeper 权限控制
给当前会话添加用户
c : 创建权限
d : 删除权限
r : 读取权限
w : 删除权限
a : 可以设置权限
# 用户名:密码addauth digest admin:admin# 创建有权限的节点# 前半段正常创建语句create /root_auth my_data 后半段添加权限 auth:admin:admin:cdrwacreate /root_auth my_data auth:admin:admin:cdrwa

zookeeper 监听 watch
watch的作用:
可以监听zookeeper中 节点的变化,包括节点的增减 、值的变更等
cli常用命令
//监听node 值的变化get -w /node//ls -w /node
Curator实现监听
@Testpublic void addNodeListener()throws Exception{TreeCache cache = TreeCache.newBuilder(curatorFramework, "/node-lock").setCacheData(false).build();cache.getListenable().addListener((c, event) -> {if ( event.getData() != null ){System.out.println("type=" + event.getType() + " path=" + event.getData().getPath());}else{System.out.println("type=" + event.getType());}});cache.start();BufferedReader in = new BufferedReader(new InputStreamReader(System.in));in.readLine();}
zookeeper 分布式锁
解决什么样的问题
解决类似库存超量的问题, A服务去 扣减库存,B服务也扣减库存,这样库存就扣减成负数了,在分布式场景下,jvm自身加锁 还是会存在,库存超量的问题,所以需要分布式锁来进行控制,这种分布式锁适用于 并发量不大情况,只是可以解决某些类似的问题
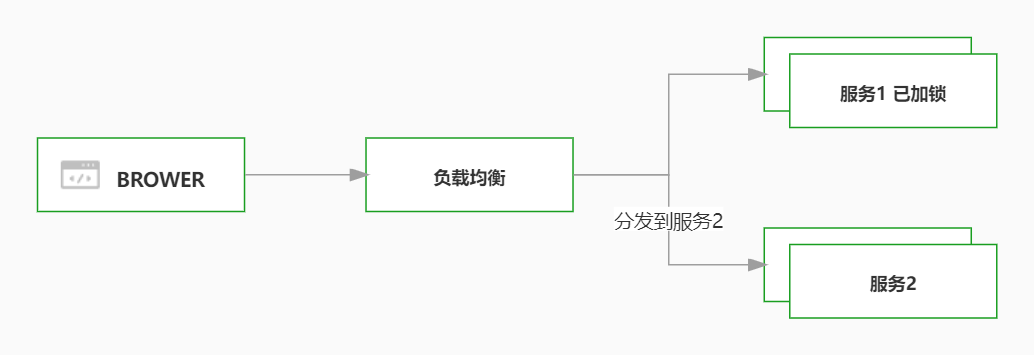
上图就是一个典型的错误,服务器1通过java 进行了加锁,但是现在的请求分配到了服务2,
解决的办法:乐观锁,悲观锁,redis原子性
读锁
读锁(共享锁 / S锁)概念:
若有一个事务对【数据A】,其他事务可以读取数据A 但是不能 对数据A进行【除了读以外的操作】
zookeeper 如何上读锁
1、创建临时序号节点,节点的数据是read 表示读锁
2、查询出比自己节点小的所有节点
3、判断最小节点是否读锁
如果不是读锁,则上锁失败,对最小节点进行监听watch ,当最小节点产生变化,当前节点会接受到通知,接受到通知后在去判断是否是写锁,不是写锁 则上锁成功。
curator 实现
@Testpublic void getReadLock() throws Exception{InterProcessReadWriteLock readWriteLock = new InterProcessReadWriteLock(curatorFramework,"/lock-node");InterProcessLock lock = readWriteLock.readLock();System.out.println("等待获取读锁");//获取锁lock.acquire();for(int i = 0 ; i < 100; i++){Thread.sleep(3000);System.out.println("处理业务逻辑中"+i);}//释放锁lock.release();System.out.println("等待释放锁!");}
写锁
写锁(排它锁 / X锁)概念:
若一个事务对【数据A】进行操作,则其他事务必须等所有事务释放才能继续操作数据A
zookeeper 如何上写锁
临时序号节点,当前会话断开,自动销毁。
1、创建临时序号节点,节点的数据是write 表示写锁
2、查询所有子节点
3、判断自己是否是最小节点
如果是则上锁成功
如果不是,说明其他节点还有锁,则上锁失败,监听最小节点,如最小节点变化,则回到第3步
curator 实现
@Testpublic void getWriteLock() throws Exception{InterProcessReadWriteLock writeLock = new InterProcessReadWriteLock(curatorFramework,"/lock-node");InterProcessLock lock = writeLock.writeLock();System.out.println("等待获取写锁");//获取锁lock.acquire();for(int i = 0 ; i < 100; i++){Thread.sleep(3000);System.out.println("处理业务逻辑中"+i);}//释放锁lock.release();System.out.println("等待释放锁!");}
乐观锁
实现方式简述
版本号控制: 不给数据加真实锁,而 给某行数据一个版本号, 有N个线程在 操作 同一行数据,
所有线程都会拿到当前版本号值 并去 验证这个版本号 是否变化了,如果没变化,就说明其他线程还未操作成功,则可以直接更新值,如其他线程发现,行版本号变了,,则当前线程内的版本号++ 并 从新取值,在新值的基础上进行 数据处理直到成功,不成功则版本号一直增加并取最新值
zookeeper 集群
集群角色
zookeeper 有三种集群节点
- Leader: 处理集群的所有事务请求,集群只能有一个首领节点
- Follower: 这种节点只能读数据,可以参与Leader选举
- Observer: 这种节点只能读数据,不可以参与Leader选举
普通集群:
创建节点数据文件夹
step1: 在/usr/local/zookeeper建立节点数据存储目录
mkdir /usr/local/zookeeper/data/node1
step2: 在node1下建立myid文件,并写入节点id 从 1 - 255
echo 1 > myid
zoo.cfg 配置
server.1 ,server.2 点后面的数字对应myid 文件里的数字
node1 IP 替换成每个 服务器的ip地址
tickTime=2000initLimit=10syncLimit=5dataDir=/usr/local/zookeeper/data/node1dataLogDir=/usr/local/zookeeper/log/node1_logclientPort=2181#集群配置#第一组端口用于数据同步,第二组端口用于 leader 选举server.1=node1 IP:2001:3001server.2=node2 IP.168.0.99:2002:3002server.3=node3 IP:2003:3003server.4=node4 IP:2004:3004:observer
启动集群节点
zookeeper 客户端集群访问时,用的是clientport 并不是集群配置中设置的 ip
./zkCli.sh -server 192.168.0.99:2181,192.168.0.99:2181,192.168.0.99:2181,192.168.0.99:2181
docker 集群
使用 docker-compose 搭建集群环境
zookeeper 官方镜像中 只暴露了4个端口
- 2888 数据同步端口
- 3888 选举端口
- 8080 AdminServer端口
- 2181 客户端端口
hostname
网络模式 已host的模式 使容器间进行通讯,
统一机器虚拟集群用 hostname,
正常应该使用桥接模式
环境变量
- ZOO_MY_ID : 对应裸机配置中的myid文件内容
- ZOO_SERVERS :对应裸机环境中zoo.cfg 中的集群配置 ```dockerfile version: ‘3.1’
services: zoo1: image: zookeeper restart: always hostname: zoo1 ports:
- 2181:2181environment:ZOO_MY_ID: 1ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
zoo2: image: zookeeper restart: always hostname: zoo2 ports:
- 2182:2181environment:ZOO_MY_ID: 2ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
zoo3: image: zookeeper restart: always hostname: zoo3 ports:
- 2183:2181environment:ZOO_MY_ID: 3ZOO_SERVERS: server.1=zoo1:2888:3888;2181 server.2=zoo2:2888:3888;2181 server.3=zoo3:2888:3888;2181
<a name="e2H6u"></a>#### 连接进集群节点```dockerfiledocker exec -it docker-zookeeper-zoo2-1 /bin/bash
ZAB协议概述
zookeeper 是一个分布式协调系统,在集群环境中zk使用了,ZBA (zookeeper atomic broadcast) 原子广播协议,解决了崩溃回复和主从数据同步问题
ZAB 协议核心功能
发现
zookeeper 要进行选举,必须选择出一个Leader节点,及Follower 节点列表,告知leader和那些节点进行通信
同步
Leader 节点负责将数据与 Follower节点进行数据同步,保证数据的一致性,
广播
leader 节点接收客户端的新的请求,负责广播到 所有Follower节点
ZAB协议的 四种节点状态
集群启动时,节点会进入 选举状态进行节点的选举,选举完成各个节点的角色对应剩下3个状态
- Looking : 选举状态
- Leading : 首领节点所处的状态
- Following : 从节点所处的状态
-
选举过程
第一步:集群节点启动时,每个节点创建自身的 选票
- 第二步:将自身的选票投给对方,
- 第三步: myid + zxid 大的一方 的选票进入票池
- 第四步: 选票未过半,没有产生Leader 进入下次选举
- 第五步: 将第一轮选票大的 给对方
第七步: 产生Leader选举结束,以后加入的 节点都是Follower节点
选票总数量 来自于 zoo.cfg 中配置的集群数量,这样来计算票数是否过半

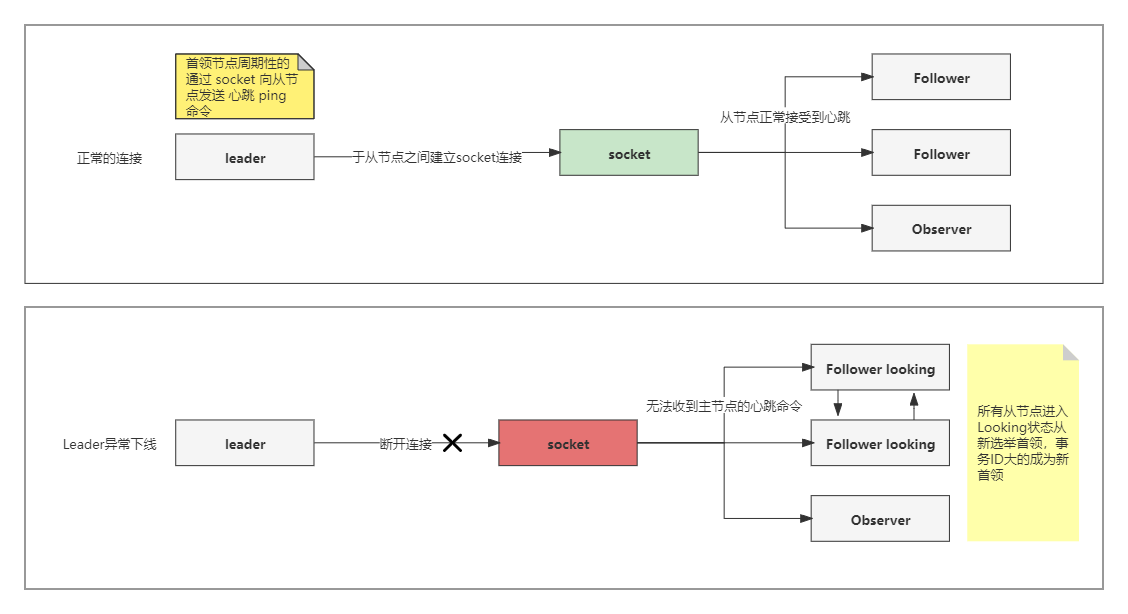
节点的崩溃恢复过程
主从节点之间建立socket连接,主节点发送 Ping 命令格式的 心跳到从节点,如果 从Follower节点一段时间没收到首领的心跳 Follower 节点报错 Leader 下线,Follower重新进入 Looking 选举状态,从新选举首领Leader
其他
Curator连接Zookeeper错误
SASL错误

解决方案
设置zookeeper.sasl.client为false ,关闭SASL认证#@Bean(initMethod = "start")public CuratorFramework curatorFramework(){//如果zeekeeper 服务器SASL认证 ,则客户端需要设置此参数 为false 否则连接时会出现 SASL 连接错误信息System.setProperty("zookeeper.sasl.client", "false");//创建客户端return CuratorFrameworkFactory.newClient(wrapperZK.getConnectString(),wrapperZK.getSessionTimeoutMs(),wrapperZK.getConnectionTimeoutMs(),new RetryNTimes(wrapperZK.getRetryCount(),wrapperZK.getElapsedTimeMs()));}

若有收获,就点个赞吧
0 人点赞
