概述
倒排索引
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
| keyword | id |
|---|---|
| name | 1001, 1002 |
| zhang | 1001 |
将内容value进行分词作为key,id为该词的value<br />由文档找词变成词找文档
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
每个文档的content域拆分成单独的词(词条或tokens ),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档
索引
- 创建
-PUT [http://127.0.0.1:9200/shopping](http://127.0.0.1:9200/shopping)
- 查询
-GET [http://127.0.0.1:9200/shopping](http://127.0.0.1:9200/shopping)
- 删除
-DELETE [http://127.0.0.1:9200/shopping](http://127.0.0.1:9200/shopping)
- 文档
- 创建
-PUT [http://127.0.0.1:9200/shopping](http://127.0.0.1:9200/shopping)/_doc/{id}
- 查询
-GET [http://127.0.0.1:9200/shopping](http://127.0.0.1:9200/shopping)/_doc/{id}-GET [http://127.0.0.1:9200/shopping/_search](http://127.0.0.1:9200/shopping/_search)
- 删除
-DELETE [http://127.0.0.1:9200/shopping](http://127.0.0.1:9200/shopping)/_doc/{id}
- 修改
-POST [http://127.0.0.1:9200/shopping](http://127.0.0.1:9200/shopping)/_doc/{id}需带json内容
查询
条件查询
- 带参数
-GET [http://127.0.0.1:9200/shopping/_search?q=category:](http://127.0.0.1:9200/shopping/_search?q=category:)小米
- 带请求体
-GET [http://127.0.0.1:9200/shopping/_search](http://127.0.0.1:9200/shopping/_search)```json //查询 { “query”:{ “match”:{
} } } 、、查全部 { “query”:{ “match_all”:{} } }"category":"小米"
//查指定字段 { “query”:{ “match_all”:{} }, “_source”:[“title”] }
<a name="KxGWY"></a>
### 分页查询
```json
{
"query":{
"match_all":{}
},
"from":0,
"size":2
}
查询排序
{
"query":{
"match_all":{}
},
"sort":{
"price":{
"order":"desc"
}
}
}
多条件查询
// must == and
{
"query":{
"bool":{
"must":[{
"match":{
"category":"小米"
}
},{
"match":{
"price":3999.00
}
}]
}
}
}
//should == or
{
"query":{
"bool":{
"should":[{
"match":{
"category":"小米"
}
},{
"match":{
"category":"华为"
}
}]
},
"filter":{
"range":{
"price":{
"gt":2000
}
}
}
}
}
范围查询
//filter 选择范围
{
"query":{
"bool":{
"should":[{
"match":{
"category":"小米"
}
},{
"match":{
"category":"华为"
}
}],
"filter":{
"range":{
"price":{
"gt":2000
}
}
}
}
}
}
检索匹配
// 有分词器 小米、华为都能找到
{
"query":{
"match":{
"category" : "小华"
}
}
}
//match_phrase 完全匹配
{
"query":{
"match_phrase":{
"category" : "为"
}
}
}
聚合
{
"aggs":{//聚合操作
"price_group":{//名称,随意起名
"terms":{//分组
"field":"price"//分组字段
}
}
},
"size":0 //不带原始数据
}
{
"aggs":{
"price_avg":{//名称,随意起名
"avg":{//求平均
"field":"price"
}
}
},
"size":0
}
映射关系
// 映射关系 == 设置主键的属性
// text 可分词 keyword不可分词(需全匹配才有结果 == match_all)
// index false 不能通过这个查询
{
"user": {
"mappings": {
"properties": {
"name": {
"type": "text"
},
"sex": {
"type": "keyword"
},
"tel": {
"type": "keyword",
"index": false
}
}
}
}
}
核心概念
| 索引 | 拥有相似特征文档的集合 | |
|---|---|---|
| 文档 | 可被索引的基础信息单元 | |
| 字段 | 文档数据的分词 | |
| 映射 | 字段的特殊属性 | (数据类型、默认值、分析器、是否被索引) |
| 分片 | 将索引划分成多份 | 大索引变小索引 |
架构

故障转移
- 分片+副本
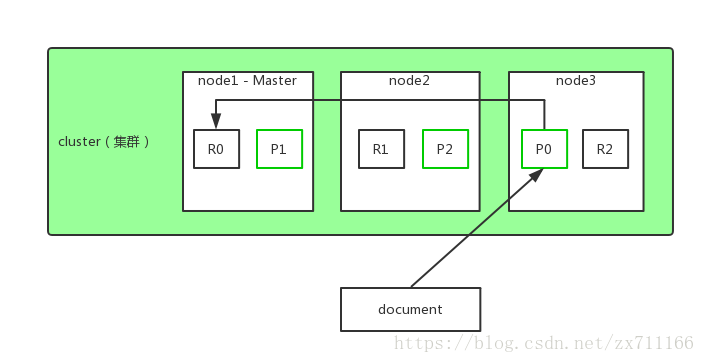
路由计算&分片控制
- 文档要选择哪个分片进行储存
shard = hash(routing) % number_of_primary_shards
- 该到哪个节点去取文档
请求发到任意节点,转发请求即可
数据写流程

- 任意节点,转发请求后,主分片完成写入、复制到相关副本分片,返回
consistency 参数的值可以设为(一致性):
发送请求到协调节点,计算分片共和副本位置,轮询节点,转发请求,节点返回

文档搜索
- 倒排索引不可改
- 落盘
- 如何动态更新呢?
- 拆分成段(部分倒排索引)!!
- 新文档被收集到内存做索引缓存
- 不时形成段,追加倒排索引,落盘,清空缓存,开启收集下一个段


文档刷新
- 文档写入有延时??如何?
- 加Cache


近实时搜索



- 一个文档被索引之后,被添加到内存缓冲区写入段,段打开,可被搜索
- 追加 translog
- tranlog足够大或者半小时 flush(执行一个提交写入磁盘并且截断translog)
段合并
段多了开销大??如何解决?

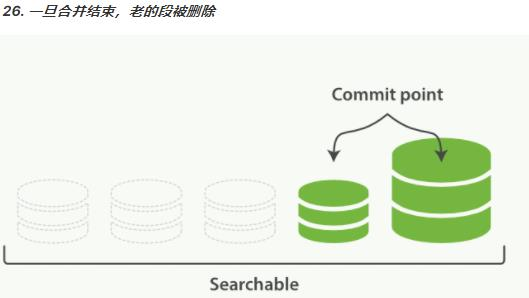
- 新的段被刷新(flush)到了磁盘。
- 写入一个包含新段且排除旧的和较小的段的新提交点。
- 新的段被打开用来搜索。老的段被删除。
文档分析
词条需要怎么分??
词条分析包括一下三个功能
| 字符过滤器 | (转换 & 转成 and ) | |
|---|---|---|
| 分词器 | ||
| Token过滤器 | The a 不要 |
-GET [http://localhost:9200/_analyze](http://localhost:9200/_analyze)

若有收获,就点个赞吧
0 人点赞
