最近无意中在stackoverflow中发现一个很有意思的问题 Why UTF-8 is used in class file and UTF-16 in in runtime? 然后发现自己对编码这方面知识比较欠缺,所以有了这篇文章。
文章作用
- 编码基础: ASCII、Unicode、UTF-8、UTF-16、MUTF-8
- 了解 Java 的内码与外码
- class 文件中的 char 类型(UTF-16)与 CONSTANT_Utf8_info 结构
1. 浅谈字符集与编码
1.1 字符集
很多人容易都把字符集和编码搞混,字符集本质是个密码表,只有映射关系并没有‘编’的过程
下面会介绍两个 Java 常用到的字符集 ASCII 和 Unicode
1.1.1 ASCII 字符集
ASCII 的全称是 American Standard Code for Information Interchange,美国信息交换标准代码,使用了一个字节来对应了 128 个字符,字节的取值范围是 0000 0000 ~ 0111 1111 ,可以看到首位固定是 0,只用了剩下 7 bit 的内容
在主流编程世界里 80%以上的代码都是由这 128 个字符组成
下面这个表是我在维基百科上找到的1968年版 ASCII 编码速见表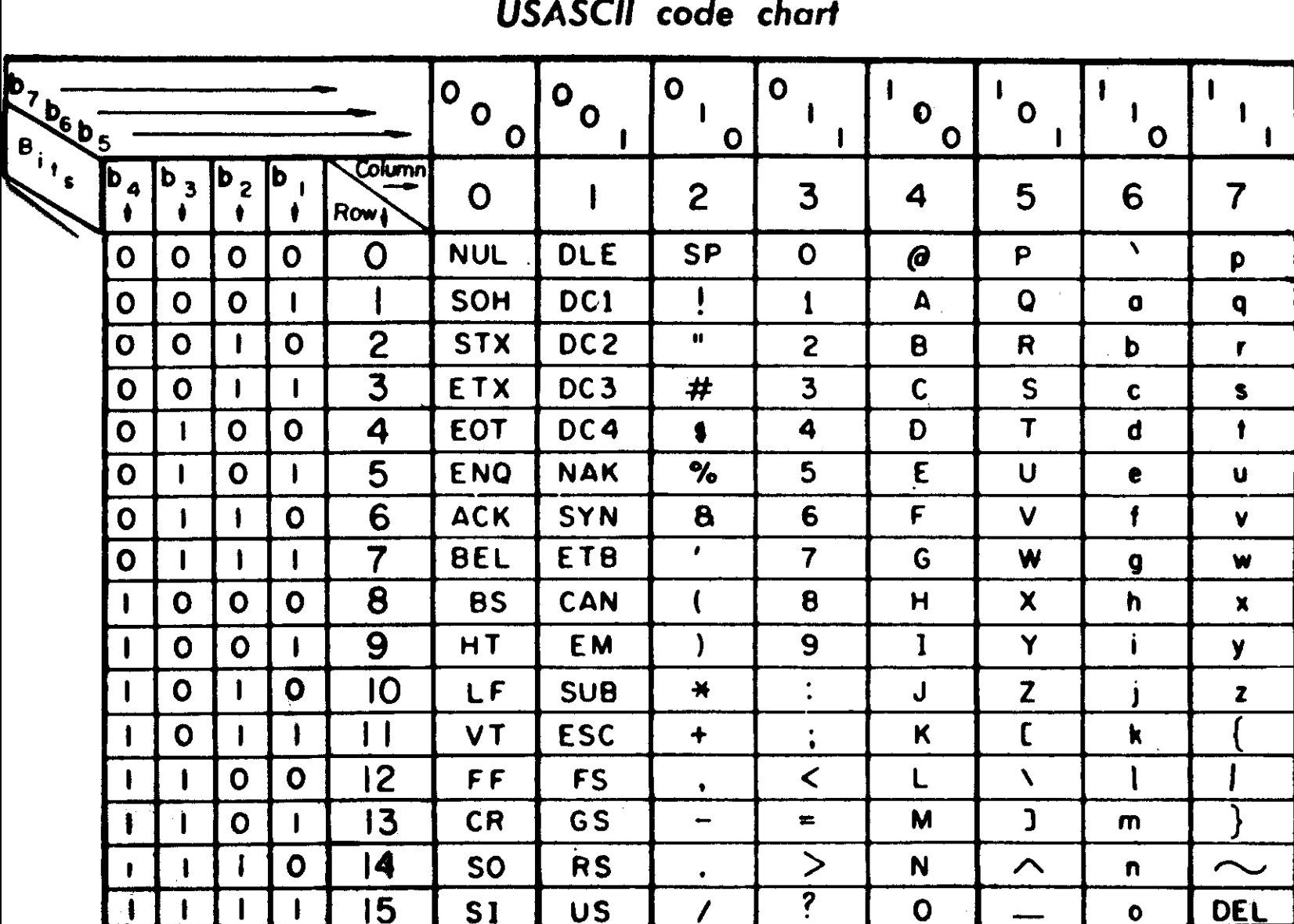
举个例子
想要知道字符 ‘A’ 的 ASCII 码
查表得出:100 0001,再将首位字节补 0 得出 0100 0001 也就是 16 进制的 0x41
1.1.2 Unicode 字符集
由于 ASCII 只映射了 128 个字符,远远达不到全球对字符集的需求,而鉴于互联网要趋于大同的方向下,Unicode 扛起了统一字符集的重任,它完全兼容了 ASCII 并且对此做出了大量扩展
Unicode 最初只支持 0~0xFFFF 的范围,从 2.0开始(到现在)就扩展成了0x0~0x10FFFF
Unicode 从 2.0 开始把编码空间划分为 17 个平面(U+xxFFFF~U+xxFFFF,xx 表示[0x00~0x10]之间)。第一个平面(也就是 0~0xFFFF 之间)称为基本多语言平面(BMP),其他平面为辅助平面
下面是我从 Unicode 官网里列出了一些重要版本更新
可以看到从 1.0.1 版本开始支持中文,从 2.0 版本扩大了容量,4.0 版本扩展了大量偏僻中文(其实从 3.0 版本已经开始扩展了)
| 版本 | 年份 | 范围 | 汉字数量 |
|---|---|---|---|
| 1.0 | 1991 | 0~0xFFFF | 0 |
| 1.0.1 | 1992 | 0~0xFFFF | 21204 |
| 2.0 | 1996 | 0~0x10FFFF | 21204 |
| 4.0 | 2003 | 0~0x10FFFF | 71098 |
| 13.0(最新) | 2020 | 0~0x10FFFF | 93858 |
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符,例如 😁 字符就表示为 U+1F601,可以通过此网站去查询对应的 Unicode 对应码
1.2 编码
由于 ASCII 是固定的 1 字节长度,读取大小是已知的,所以只需使用映射的字节值即可
而 Unicode 是变长的 可以有 1~4 字节长度,程序并不知道该如何截取断意
例如:
字符 ‘浦’ 的 Unicode 编号是 U+6D6E 二进制为 0110 1101 0110 0110
字符 ‘m’ 的 Unicode 编号是 U+006D 二进制为 0110 1101
字符 ‘f’ 的 Unicode 编号是 U+006E 二进制为 0110 0110
那么程序在读到0110 1101 1110 0110这个二进制时,该理解成一个字符 ‘浦’ 还是两个字符 ‘m’ 与 ‘f’ 呢?这个时候就需要编码的协助了
下面列举的几种编码都是针对于 Unicode 字符集的
其中 UTF 系列的全称叫做 Unicode Transformation Formats(Unicode 转换格式)而后面的数字则代表它最低所需占用的 bit 数量
1.2.1 UTF-32 编码
UTF-32 是固定的 4 字节长度编码,它固定了每个 Unicode 的长度,并且以此做了 一一对应
例如:
字符 😁 的 Unicode 码是 U+1F601 那么对应的 UTF-32 的编码为 0x0001F601
字符 ‘a’ 的 Unicode 码是 U+0061 那么对应的 UTF-32 的编码为 0x00000061
此编码的优缺点都很明显
- 优点:就是直译不需要转码,理论上速度会快的
- 缺点:用此编码的程序会变大 1.25~4 倍之间,鉴于大部分程序都使用的 1 字节的 ASCII 字符编写,那么你所编写的程序就会变大 4 倍,这个是绝对不能忍受的。不兼容 ASCII
1.2.2 UTF-16 编码 1.5 及以上版本 java 内码
UTF-16 是变长编码,由 2 个字节或者是 4 个字节表示
其中 2 个字节表示的是 Unicode 码 U+0000~U+FFFF(BMP)并且是一一对应的关系(并不严谨,不过满足绝大部分情况)
而 4 个字节比较复杂,需要进行转换运算,步骤如下
- 将 Unicode 值减去 0x10000,得到 20bit 长的值
- 将上一步得到的值分为高 10 位和低 10 位
- 将高 10 位的值加上 0xD800
- 将低 10 位的值加上 0xDC00
这个说起来有点抽象,下面举个例子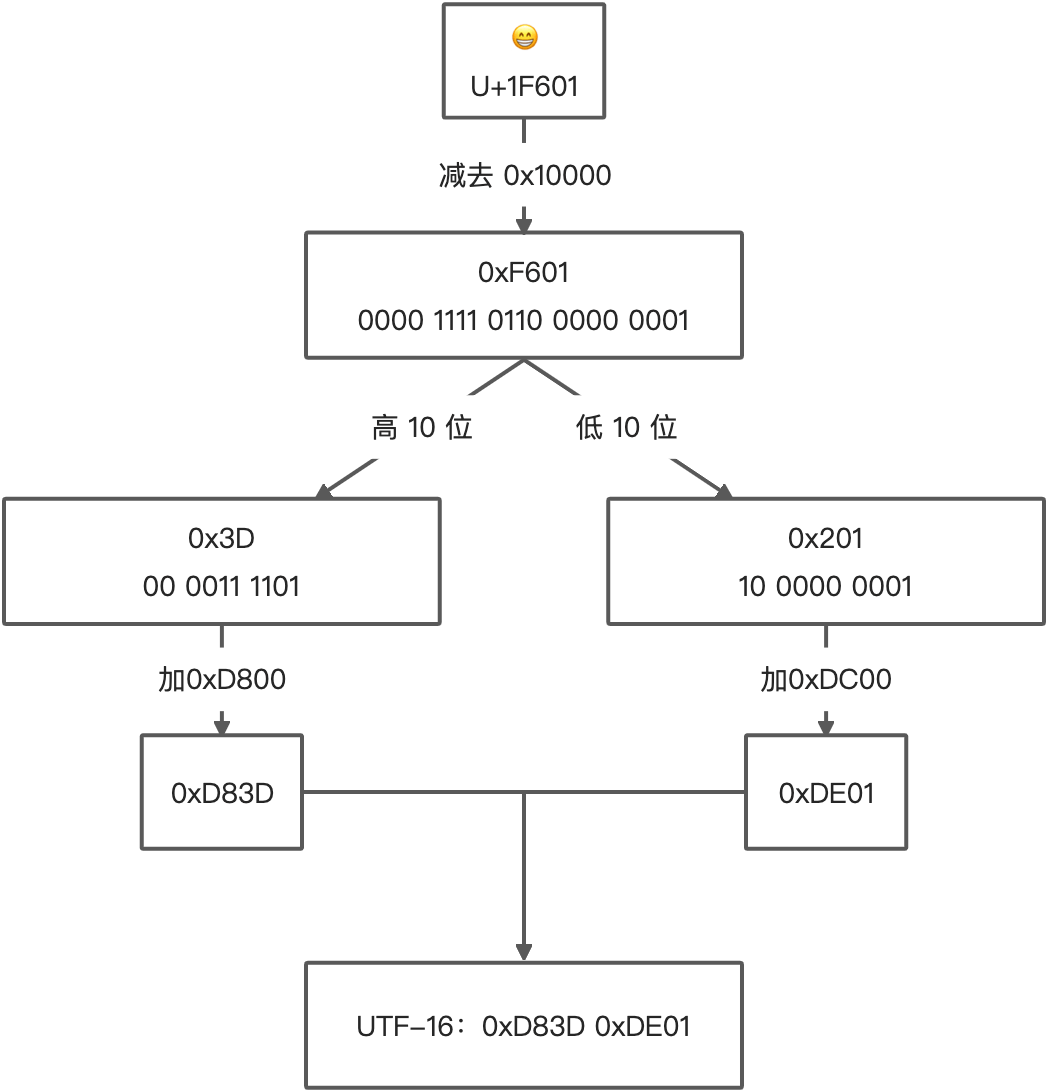
原理:
- Unicode 标准规定了 U+D800~U+DFFF 的值不对应任何字符,而 UTF-16 就利用了这个区间的值
- 高位在加上 0xD800 后,范围在 0xD800(1101 1000 0000 0000)~0xDBFF(1101 1011 1111 1111) 之间
- 低位在加上 0xDC00 后,范围在 0xDC00(1101 1100 0000 0000)~0xDFFF(1101 1111 1111 1111) 之间
- 这样就形成了高位、低位、基本多语言平面(BMP)三者互不重叠,从而达成字符的唯一性
优缺点说明:
- 优点:与 UCS-2 兼容
- 缺点:
- UTF-16 能表示的字符有 6 万多,而 Unicode 最新版本已经到 8 万多的数量
- 因为最低要占两个字节,所以不兼容 ASCII
- 存在大小端问题
- 变长编码,搜索效率变低
1.2.3 UTF-8 编码
UTF-8 是变长编码,由 1 个字节到 6 个字节表示,其中 1 个字节的情况是与 ASCII 编码相同
下图是 Unicode 和 UTF-8 之间的转换关系表 ( 字符表示码点占据的位 )**x**
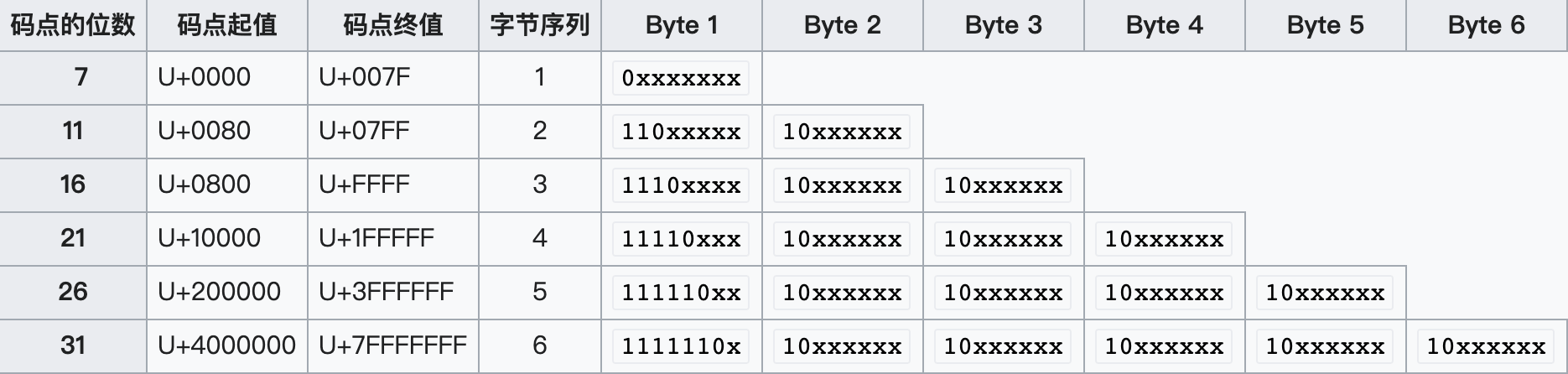
例子: 😁 转 UTF-8
- 😁 的 Unicode 码是 U+1F601,二进制为 0001 1111 0110 0000 0001
- 😁 的范围在 U+100000~U+1FFFFF 之间,那么查表可知它的 UTF-8 编码是占用了 4 个字节
- 由低字节向高字节补位后二进制为 11110000 10011111 10011000 10000001
- 转成十六进制后 0xF0 0x9F 0x98 0x81 也就是对应的 UTF-8 的编码值
优缺点说明:
- 优点:兼容 ASCII 码,没有大小端问题
- 缺点:变长编码,搜索效率变低
1.2.4 MUTF-8 编码 java 外码
MUTF-8 是变体的 UTF-8 (Modified UTF-8),它的特性如下
- 对于 U+0000(null),MUTF-8 会使用两个字符 0xC080 表示
- 在 0x0001~0xFFFF( 除了 U+0000 的 BMP) 之内的字符,使用的 UTF-8 编码
- 对于大于 0xFFFF 的 Unicode 码处理如下
- 第一步转成 UTF-16
- 分别对高位和低位进行 UTF-8 转码
下面还是举个 😁 的例子,至于正确与否则会在外码章节阐述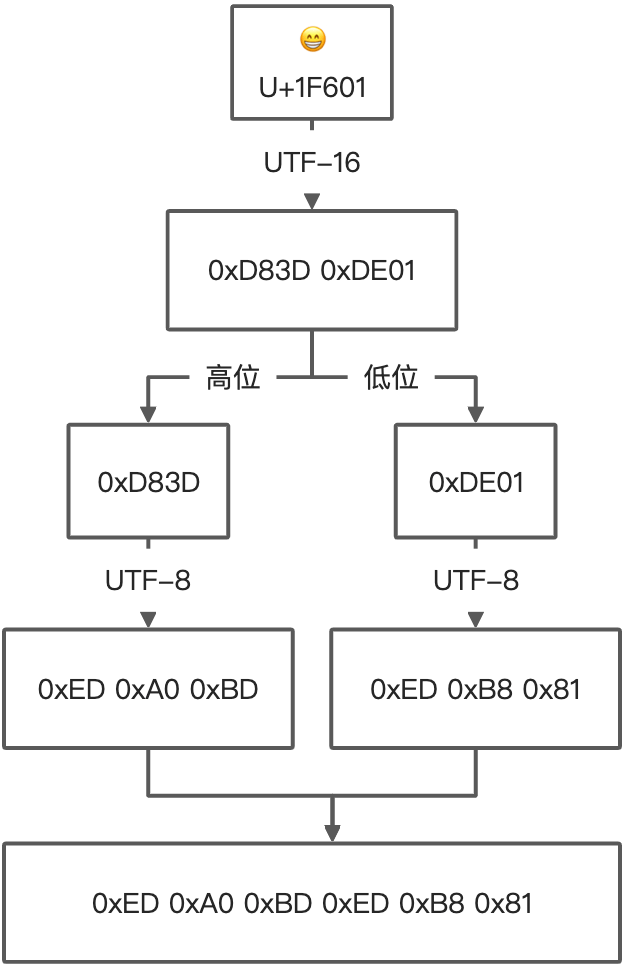
这个编码是针对于 JVM 的,所以关于它的优点也会放到外码那一章节
2. Java 的外码与内码
- 外码:class 文件的编码格式
- 内码:JVM 运行时的编码
2.1 外码
外码是 class 文件的编码格式,其使用的是特有的 MUTF-8 编码格式。
Java 的字符串常量都是以 CONSTANT_Utf8_info 类型存在常量池中,class 文件的编码是 MUTF-8,所以 CONSTANT_Utf8_info 一般是存储 MUTF-8 字节
下面会去验证这个,不过首先先要了解下 CONSTANT_Utf8_info 的结构
2.1.1 CONSTANT_Utf8_info 结构
此段摘于《 Java虚拟机规范 第8版 》4 章 4.4.7节
CONSTANT_Utf8_info 结构用于表示字符常量的值:
CONSTANT_Utf8_info {u1 tag;u2 length;u1 bytes[length];}
- tag:CONSTANT_Utf8_info结构的 tag 项值为 1
- length:length 项的值指明了 bytes[ ] 数组长度,CONSTANT_Utf8_info 结构中的内容以 length 属性来确定长度,而不以 null 作字符串的终止符
- bytes[ ]:bytes[ ]是表示字符串值的 byte 数组,bytes[ ] 中每个成员的 byte 值都不会是 0,也不在 0xf0~0xff 范围内
2.1.2 分析 class 文件中编码
首先编写一个用来生成 .class 文件的类,如下
public class Foo {String nullStr = null;String MUTF8ShortTest = "a";String MUTF8LongTest = "😁";}
然后通过 javac 生成 .class 文件,我是用的 vscode 的 Hexdump for VSCode 插件来看的 16 进制的,分析的结果如下: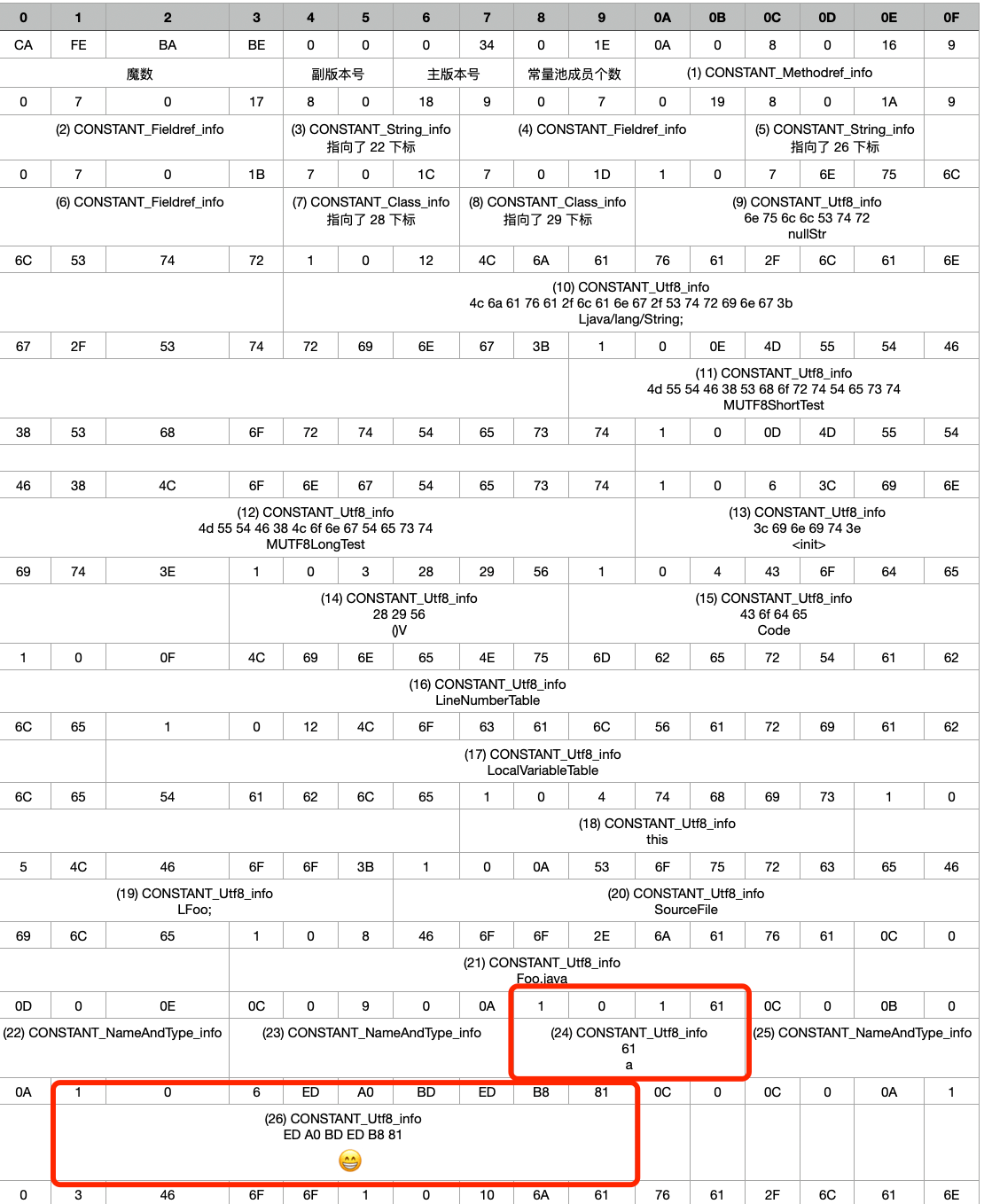
如上两个红框中就是代码中第 4 行与第 6 行定义的字符串常量
这里测试是 BMP 内和 BMP 外两种情况
可以看出
字符 ‘a’ 的 MUTF-8 的编码是 0x61
字符 ‘😁’ 的 MUTF-8 的编码是 0xED 0xA0 0xBD 0xED 0xB8 0x81 (与编码—MUTF-8那一节的结果相同)
2.2 内码
Java 的内码JVM 运行时的编码,使用 UTF-16 编码
证明一下:
public class Foo {String testStr = "淦";public void test() {System.out.println((Integer.toHexString(testStr.charAt(0))));}}
上边程序列举‘淦’这个字符,它的外码是 0xE6 0xB7 0xA6
CONSTANT_Utf8_info
| 01 | 00 | 03 | E6 | B7 | A6 |
|---|---|---|---|---|---|
执行 test() 方法后 则输出了 6de6 这个字符的 UTF-16 的编码格式

若有收获,就点个赞吧
0 人点赞
