索引失效
如果使用explain分析SQL的执行计划时发现访问类型type为ALL或实际使用到的索引key为NULL,则说明该查询没有利用索引而导致了全表扫描,这是我们需要避免的。以下总结了利用索引的一些原则:
1、全值匹配我最爱
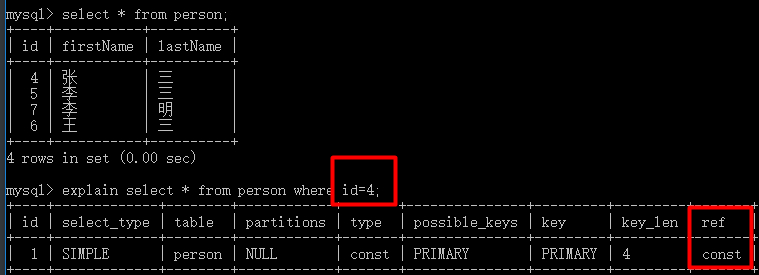
2、最佳左前缀法则
对于复合索引检索时一定要遵循左前缀列在前的原则。
| 123 | mysql> alter table test add c5 varchar(10) default null, add c6 varchar(10) default null, add c7 varchar(10) default null;mysql> create index idx_c5_c6_c7 on test(c5,c6,c7); |
|---|---|
如果没有左前缀列则不会利用索引:
| 1234567891011121314151617181920212223242526272829 | mysql> explain select from test where c6=’’\G** 1. row * id: 1 select_type: SIMPLE table: test partitions: NULL type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1 filtered: 100.00 Extra: Using wheremysql> explain select from test where c6=’’ and c7=’’\G** 1. row * id: 1 select_type: SIMPLE table: test partitions: NULL type: ALLpossible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1 filtered: 100.00 Extra: Using where |
|---|---|
而只要最左前缀列在前,其他列可以不按顺序也可以不要,但最好不要那么做(按照定义复合索引时的列顺序能达到最佳效率):
| 12345678910111213141516171819202122232425262728293031 | mysql> explain select from test where c5=’’ and c7=’’\G** 1. row * id: 1 select_type: SIMPLE table: test partitions: NULL type: refpossible_keys: idx_c5_c6_c7 key: idx_c5_c6_c7 key_len: 33 ref: const rows: 1 filtered: 100.00 Extra: Using index condition1 row in set, 1 warning (0.00 sec)mysql> explain select from test where c5=’’ and c7=’’ and c6=’’\G** 1. row * id: 1 select_type: SIMPLE table: test partitions: NULL type: refpossible_keys: idx_c5_c6_c7 key: idx_c5_c6_c7 key_len: 99 ref: const,const,const rows: 1 filtered: 100.00 Extra: NULL1 row in set, 1 warning (0.00 sec) |
|---|---|
最优的做法是:
| 12345 | mysql> explain select from test where c5=’’\Gmysql> explain select from test where c5=’’ and c6=’’\Gmysql> explain select * from test where c5=’’ and c6=’’ and c7=’’\G |
|---|---|
3、不在列名上添加任何操作
有时我们会在列名上进行计算、函数运算、自动/手动类型转换,这会直接导致索引失效。
| 1234567891011121314151617181920212223242526272829 | mysql> explain select from person where left(firstName,1)=’张’\G** 1. row * id: 1 select_type: SIMPLE table: person partitions: NULL type: indexpossible_keys: NULL key: idx_name key_len: 186 ref: NULL rows: 4 filtered: 100.00 Extra: Using where; Using indexmysql> explain select from person where firstName=’张’\G** 1. row * id: 1 select_type: SIMPLE table: person partitions: NULL type: refpossible_keys: idx_name key: idx_name key_len: 93 ref: const rows: 1 filtered: 100.00 Extra: Using index |
|---|---|
上面两条SQL同样是实现查找姓张的人,但在列名firstName上使用了left函数使得访问类型type从ref(非唯一性索引扫描)降低到了index(全索引扫描)
4、存储引擎无法使用索引中范围条件右边的列

由上图可知c6 > ‘a’右侧的列c7虽然也在复合索引idx_c5_c6_c7中,但由key_len:66可知其并未被利用上。通常索引利用率越高,查找效率越高。
5、尽量使用索引覆盖
尽量使查询列和索引列保持一致,这样就能避免访问数据行而直接返回索引数据。避免使用select *除非表数据很少,因为select *很大概率访问数据行。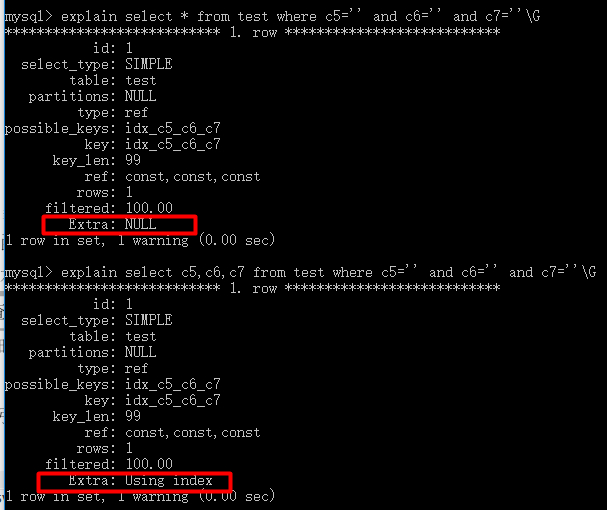
Using index表示发生了索引覆盖
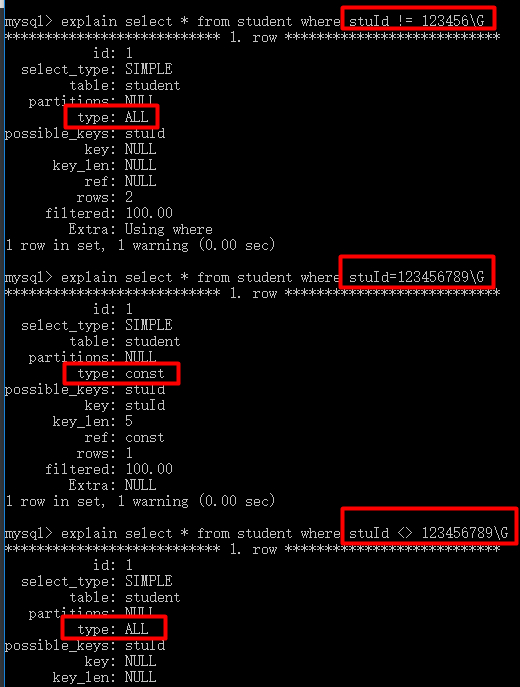
6、使用 != 或 <> 时可能会导致索引失效
7、not null对索引也有影响
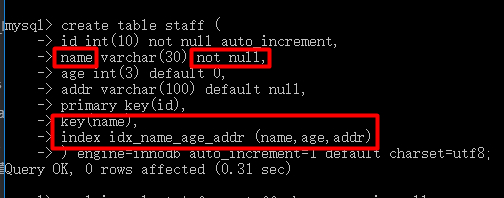
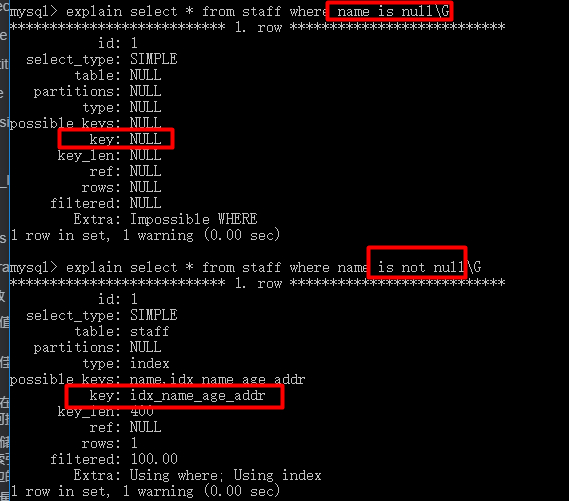
若name的定义不是not null则不会有索引未利用的情况。
8、like以通配符开头会导致索引失效
like语句以通配符%开头无法利用索引会导致全索引扫描,而只以通配符结尾则不会。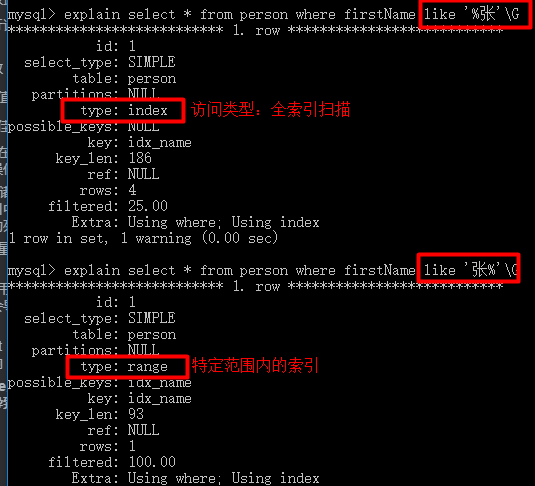
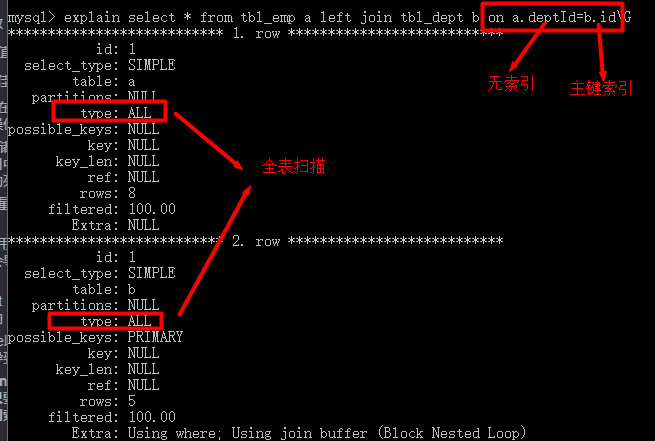
9、join on的列只要有一个没索引则全表扫描
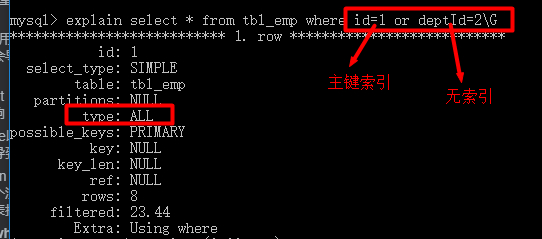
10、or两侧的列只要有一个没索引则全表扫描
11、字符串不加单引号索引失效
| 1 | mysql> explain select * from staff where name=123; |
|---|---|
打油诗: 全值匹配我最爱,最左前缀要遵循。 带头大哥不能死,中间兄弟不能断。 索引列上少计算,范围之后全失效。 LIKE百分比最右,覆盖索引不写
*。 不等空值还有OR,ON的右侧要注意。 VAR引号不能丢,SQL优化有诀窍。
————————————————

若有收获,就点个赞吧
0 人点赞
