在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问Mysql等数据库。这样可以大大缓解数据库的压力。Redis缓存数据的加载可以分为懒加载和主动加载两种模式,下面分别介绍在这两种模式下的数据一致性如何处理。
懒加载
读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存和数据库间的数据一致性问题。不管是先写数据库,再删除缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。举个例子:
- 如果删除了缓存Redis,还没有来得及写库MySQL,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。
- 如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题。如何解决?
所以结合前面例子的两种删除情况,我们就考虑前后双删加懒加载模式。那么什么是懒加载?就是当业务读取数据的时候再从存储层加载的模式,而不是更新后主动刷新,它涉及的业务流程如下如所示: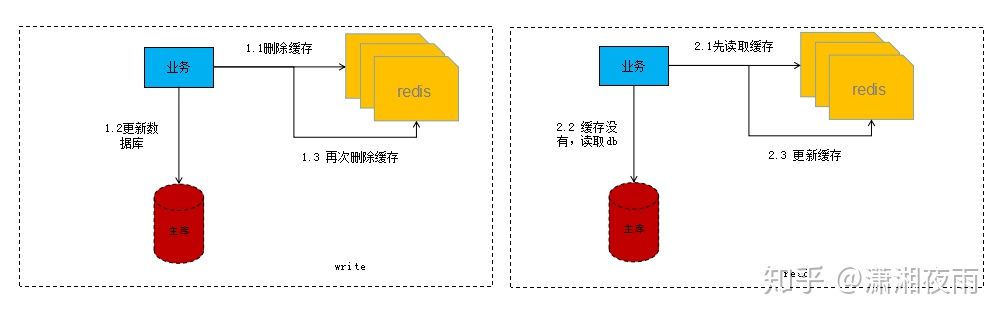
理解了懒加载机制后,结合上面的业务流程图,我们讲解下前后双删如何做?
延迟双删
在写库前后都进行redis.del(key)操作,并且第二次删除通过延迟的方式进行。
方案一(一种思路,不严谨)具体步骤是:
1)先删除缓存;
2)再写数据库;
3)休眠500毫秒(根据具体的业务时间来定);
4)再次删除缓存。
那么,这个500毫秒怎么确定的,具体该休眠多久呢?
需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
当然,这种策略还要考虑 redis 和数据库主从同步的耗时。最后的写数据的休眠时间:则在读数据业务逻辑的耗时的基础上,加上几百ms即可。比如:休眠1秒。
方案二,异步延迟删除:
1)先删除缓存;
2)再写数据库;
3)触发异步写人串行化mq(也可以采取一种key+version的分布式锁);
4)mq接受再次删除缓存。
异步删除对线上业务无影响,串行化处理保障并发情况下正确删除。
为什么要双删?
- db更新分为两个阶段,更新前及更新后,更新前的删除很容易理解,在db更新的过程中由于读取的操作存在并发可能,会出现缓存重新写入数据,这时就需要更新后的删除。
双删失败如何处理?
1、设置缓存过期时间
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
结合双删策略+缓存超时设置,这样最差的情况就是在超时时间内数据存在不一致。
2、重试方案
重试方案有两种实现,一种在业务层做,另外一种实现中间件负责处理。
业务层实现重试如下: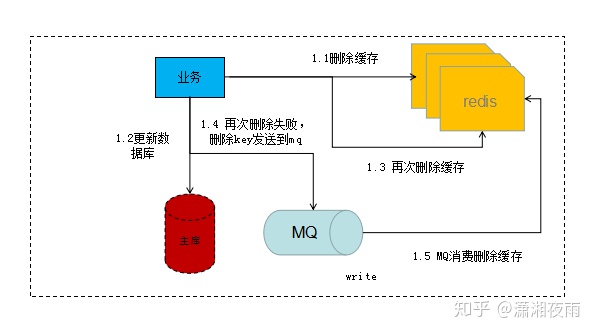
1)更新数据库数据;
2)缓存因为种种问题删除失败;
3)将需要删除的key发送至消息队列;
4)自己消费消息,获得需要删除的key;
5)继续重试删除操作,直到成功。
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
中间件实现重试如下: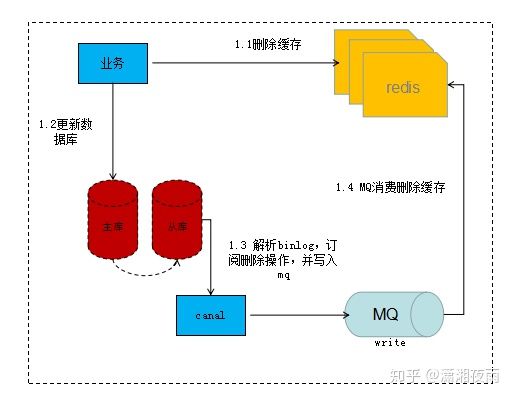
流程说明:
1)更新数据库数据;
2)数据库会将操作信息写入binlog日志当中;
3)订阅程序提取出所需要的数据以及key;
4)另起一段非业务代码,获得该信息;
5)尝试删除缓存操作,发现删除失败;
6)将这些信息发送至消息队列;
7)重新从消息队列中获得该数据,重试操作。
主动加载
主动加载模式就是在db更新的时候同步或者异步进行缓存更新,常见的模式如下: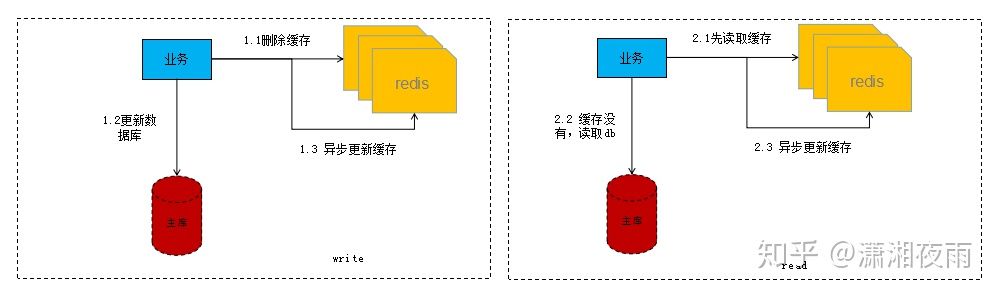
写流程:
第一步先删除缓存,删除之后再更新DB,之后再异步将数据刷回缓存。
读流程:
第一步先读缓存,如果缓存没读到,则去读DB,之后再异步将数据刷回缓存。
这种模式简单易用,但是它有一个致命的缺点就是并发会出现脏数据。
试想一下,同时有多个服务器的多个线程进行’步骤1.2更新DB’,更新DB完成之后,它们就要进行异步刷缓存,我们都知道多服务器的异步操作,是无法保证顺序的,所以后面的刷新操作存在相互覆盖的并发问题,也就是说,存在先更新的DB操作,反而很晚才去刷新缓存,那这个时候,数据也是错的。
读写并发:再试想一下,服务器A在进行’读操作’,在A服务器刚完成2.2时,服务器B在进行’写操作’,假设B服务器1.3完成之后,服务器A的2.3才被执行,这个时候就相当于更新前的老数据写入缓存,最终数据还是错的。
而对于这种脏数据的产生归其原因还是在于这种模式的主动刷新缓存属于非幂等操作,那么要解决这个问题怎么办?
- 前面介绍的双删操作方案,因为删除每次操作都是无状态的,所以是幂等的。
- 将刷新操作串行处理。
这里把基于串行处理的刷新操作方案介绍一下: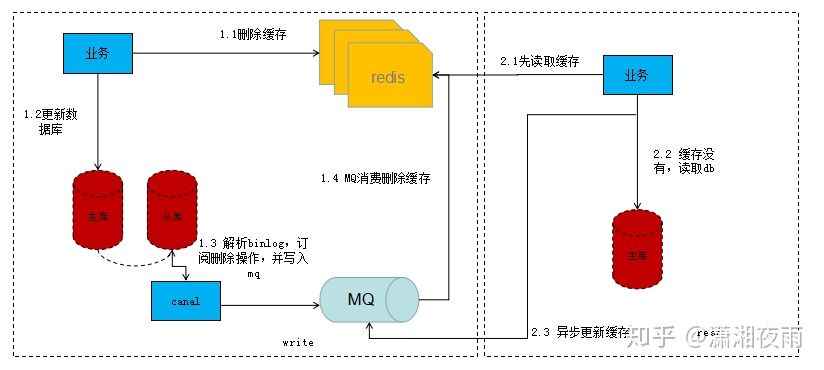
写流程:
第一步先删除缓存,删除之后再更新DB,我们监听从库(资源少的话主库也ok)的binlog,通过分析binlog我们解析出需要需要刷新的数据标识,然后将数据标识写入MQ,接下来就消费MQ,解析MQ消息来读库获取相应的数据刷新缓存。
关于MQ串行化,大家可以去了解一下 Kafka partition 机制 ,这里就不详述了。
读流程:
第一步先读缓存,如果缓存没读到,则去读DB,之后再异步将数据标识写入MQ(这里MQ与写流程的MQ是同一个),接下来就消费MQ,解析MQ消息来读库获取相应的数据刷新缓存。
总结
- 懒加载模式缓存可采取双删+TTL失效来实现;
- 双删失败情况下可采取重试措施,重试有业务通过mq重试以及组件消费mysql的binlog再写入mq重试两种方式;
- 主动加载由于操作本身不具有幂等性,所以需要考虑加载的有序性问题,采取mq的分区机制实现串行化处理,实现缓存和mysql数据的最终一致,此时读和写操作的缓存加载事件是走的同一个mq。

若有收获,就点个赞吧
0 人点赞
