欠拟合
含义
模拟欠拟合
1、数据集-见多层神经网络一节
2、创建模型
import * as tf from '@tensorflow/tfjs';import * as tfvis from '@tensorflow/tfjs-vis';import { getData } from '../xor/data';window.onload = async () => {const data = getData(200);tfvis.render.scatterplot({ name: '训练数据' },{values: [data.filter(p => p.label === 1),data.filter(p => p.label === 0),]})const model = tf.sequential()model.add(tf.layers.dense({units: 1,activation: 'sigmoid',inputShape: [2]}))model.compile({loss: tf.losses.logLoss,optimizer: tf.train.adam(0.1)})const inputs = tf.tensor(data.map(p => [p.x, p.y]));const labels = tf.tensor(data.map(p => p.label));await model.fit(inputs, labels, {validationSplit: 0.2,epochs: 200,callbacks: tfvis.show.fitCallbacks({ name: '训练效果'},['loss', 'val_loss'],{ callbacks: ['onEpochEnd'] })})};
3、效果
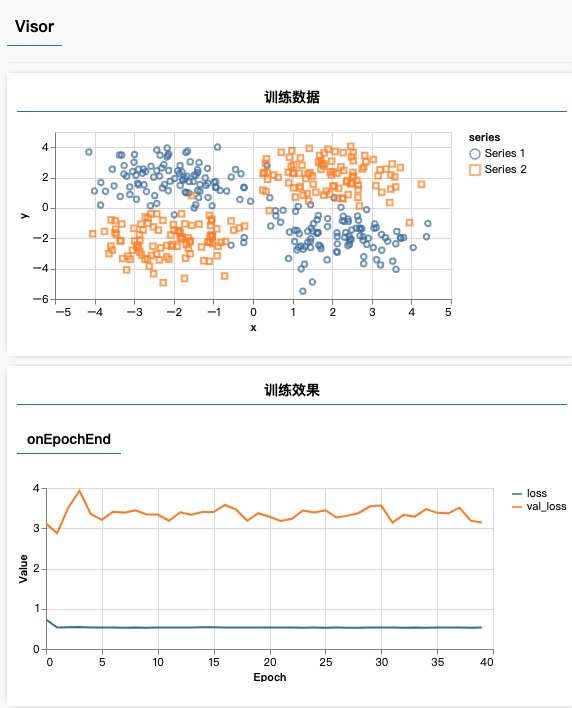
4、分析
可以看到,验证集训练损失一直没有下降,这是明显的欠拟合现象
可以通过添加神经元、添加层等增加模型复杂度的方式解决
过拟合
含义
模拟过拟合
1、加载带有噪音的二分类数据集(训练集和验证集)
2、使用多层神经网络
3、效果
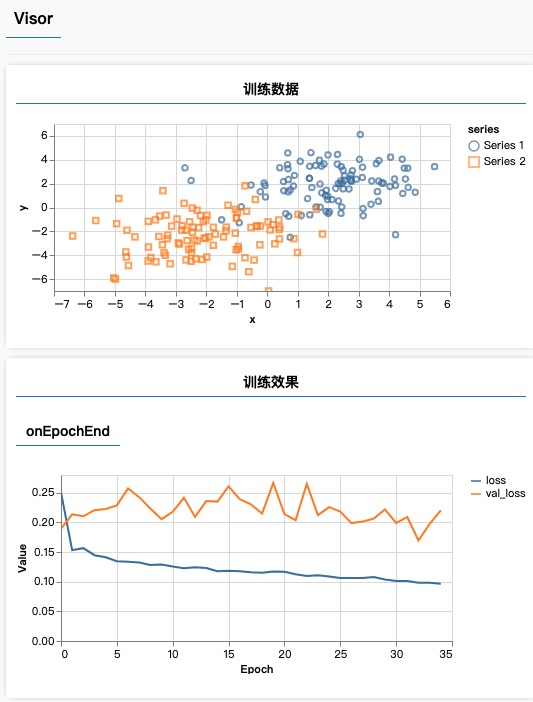
4、分析
训练集损失越来越小,但测试集损失越来越大,这是过拟合现象
过拟合应对法:早停法、权重衰减、丢弃法
权重衰减
设置l2正则化
model.add(tf.layers.dense({units: 10,inputShape: [2],activation: "tanh",kernelRegularizer: tf.regularizers.l2({ l2 : 1 }) // 权重衰减法:设置l2正则化}));
丢弃法
添加丢弃层随机丢弃,使模型变得简单
model.add(tf.layers.dense({units: 10,inputShape: [2],activation: "tanh",// kernelRegularizer: tf.regularizers.l2({ l2 : 1 }) // 权重衰减法:设置l2正则化}));model.add(tf.layers.dropout({rate: 0.9})) // 丢弃法,随机设置丢弃率,10个中随机选9个丢弃

若有收获,就点个赞吧
0 人点赞
