- 《Making Data Visual》
- Ch 1. Getting to an effective visualization
- Ch 2. From questions to tasks**
- Ch 3:counseling, exploration and prototyping
- Ch 4:Components of a visualization
- Ch 5. Single Views
- Day 22:
- Day 23:
- Day 24:Overall Perceptual Concerns
- Day 25:回顾整个脑图
- Day 26:Question: How Is a Measure Distributed?
- Day 27:Question: How Do Groups Differ from Each Other?
- Day 28:Question: Do Individual Items Fall into Groups? Is There a Relationship Between Attributes of Items?
- Day 29:Question: How Does an Attribute Vary Continuously?
- Day 30:How Are Objects Related to Each Other in a Network or Hierarchy?
- Day 30:Question: Where Are Objects Located?
- Day 31:第五章总结
- Day 32:
- Chapter 6. Multiple and Coordinated Views(MLVs)
- Chapter 7. Case Study 1: Visualizing Telemetry to Improve Software
- Chapter 8. Case Study 2: Visualizing Biological Data
《Making Data Visual》
Ch 1. Getting to an effective visualization
Day 1:Getting to Insight
段落大意
客户最常提出的一个问题是,他们有想要可视化的数据,该如何去绘制?他们期望能够有一个现成的可视化可以直接使用,稍微调整一下就可以很完美。但若继续追问他们期望看到什么、想要绘制数据的哪一部分、如何定义问题所关联的数据维度等问题时,会发现客户并没有可视化的问题,他们的问题来源于他们不清楚数据哪一个维度是重要的,且这些维度彼此之间是如何关联。当客户可以描述数据的维度是如何关联他们的问题,要找到一个合适的可视化就变得简单许多。
多年来,我们已经了解到设计有效的可视化来理解数据并不是一门艺术,而是一个系统的、不断重复的过程。(这个表述需要改写一下)这个过程可以分成如下可重复、清楚的步骤:数据、任务、利益相关者、可视化。
数据–
- 什么数据是可取得的?具有什么含义?
- 数据看起来如何?最重要的部分有哪些?
- 数据来源于哪里,如何被搜集的?
任务–
- 需要用数据做什么?(What need to happen with data?)
- 能支持高级任务的低级问题与任务是什么?(What are the low-level questions and tasks that will support high-level goals?)
利益相关者–
- 谁参与到了数据、问题、目标?
- 他们可以说些关于问题的什么,来帮助设计有效的可视化?
- 谁会看最终的可视化,以及我们期望他们从中学到些什么?
- 他们能带来哪些的领域知识?
- 什么答案会让他们感到满意?
可视化–
- 如何一起理解数据、任务与利益关系者?(How does the understanding of data, tasks, and stakeholders come together?)
- 数据如何呈现能够满足使用者的任务需求?
个人感想
在握有数据时,人们容易想要直接从可视化清单表上去找一个最合适的可视化,而没有先想数据与问题。一个多样的、可供选择的图表常常很受欢迎,但人也容易被这个图表选项所限制思路:1.只想找合适的可视化样式,而忘了考虑到要解决的问题与图表的受众;2.图表具有千变万化的样式,基础图表之间可以继续有机结合,产生新的图表,若只从基础的固定样式从选择,会丧失可视化的展现弹性,进而无法针对数据、问题、读者去设计出比较有效的可视化样式。
Day 2:Hotmap:Making decisions with data**
以一个可视化为例,可以用来较好地找出问题:Hotmap。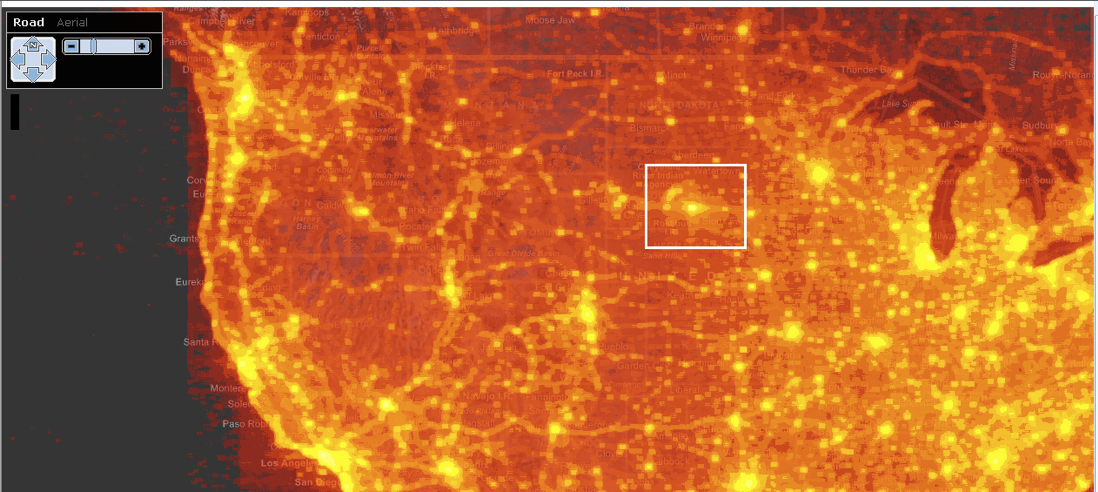

,2006年微软推出了一个名为 Virtual Earth 的工具,这个系统记录了使用者的位置信息,名为Hotmap。将这些信息展示出来后有两个地方较为奇怪。一个是在美国中央,另外一个是非洲旁边。这两个地方都是人烟稀少,但可视化的结果却是异常明亮。这个可视化帮助工程师找出了系统的 bug。从这个例子也可以发现,大部分的可视化最有趣的洞见,对使用者而言都是意想不到的发现。
Ch 2. From questions to tasks**
所有的可视化来源于对数据的疑问。例如”高收入的员工是否比低收入的员工较为多产?“,这个问题需要去定义”高收入“与”多产“,以及需要思考哪个可视化可以展示两者的关系。这个拆解问题到可以从数据中被计算出来的过程,是迭代的、不断探索的,以及有时候是充满惊喜的。
Day 3:Example: Identifying Good Movie Directors**
以电影数据为例,提出一个问题:”谁是最佳电影导演?“这个问题具有模糊的特性,每个人对最佳导演的定义不同,例如电影系的学生会认为有影响力的导演是最佳的。操作化(operationalization)的目的是去精炼且澄清问题,知道分析师可以在数据与他们想回答的问题之间建立明确的联系。数据集与操作化的选择本质上是对于问题的特定观点,他们代表分析师希望理解的内容。(The choice of dataset and operationalization is fundamentally a specific perspective on a problem; they stand in for what the analyst wishes to understand.)对于模糊定义的问题,是让可视化如此重要的原因,可视化让分析师将他们的经验与知识直接在最终展示的数据上呈现。在解决抽象的问题,分析师的经验具有重要的作用。
Day 4:Making a question concrete**
操作化(operationalization)的过程是从比较泛的问题,到具体的任务,再到基于数据可以支持任务的可视化。为了达成目标,需要找到”代理“(proxy)。代理指的是可以部分代表抽象的事物,例如电影评价可以是”最佳的“电影的代表(电影评分是具象的,最佳的电影是抽象的)。
Proxy 可以分成两类:
- proxy task:较为具体,跟数据会比较相关,例如可以透过统计值、可视化来完成;
- proxy value:较为抽象,
Day 5:A concrete movie question**
如何拆解high level的问题,是这一段主要讨论的部分。继续以”谁是最佳导演?“为例,数据集是导演与电影的名单。在选择”代理“时,对分析师而言,是一个对数据以及”代理“本身质量的一个不断迭代的过程。
Day 6:Breaking down a task - part 1**
在”操作化“的过程中,我们需要去识别一个问题或是任务的哪一个部分需要有更精确的“代理”。系统性地进行这一个过程,可以让验证这些决策变得比较简易,并且进而产生过程的路线图。一旦获得对问题更好的理解,这能让分析师有效地重新审视决策。
分析师在提炼任务时,可以分成四个部分(以电影数据为例):
- objects:例如导演、电影,或是使用者、销售物品、单一物件等。通常objects为数据表的一个维度。
- measures:例如导演的数量、使用者的开心程度、一家店的销售额。通常可以从数据里面计算得到。
- groupings (or partitions):例如销售区域、年度销售额,由数据的属性或特征切割出来的数据分组。
- actions:例如比较、识别,具有针对数据要进行的动作,且以文字方式出现。actions能指引找到合适的可视化。
Day 7:Breaking down a task - part 2**
一个不断迭代的过程:
- 将问题提炼成数个任务,这些任务可以各自或者结合起来回答比较广泛的问题
- 对每一个任务:
a. 确定任务的组成部分
b. 找出还比较模糊的任务(还不能够被数据直接描述的任务)
c. 对这些模糊的任务,找出相对应的、能够描述任务的代理,并回到第一步(是1还是a?)
d. 直到所有任务的组成都不模糊后,就可以用数据可视化或是其他计算方式来描述
(可视化在这个迭代的过程里,有时候不只是结果,而是可以辅助这个过程顺利进行的工具)
Day 8:Returning to the Example: Exploring Different Definitions**
这一段以详细的例子来阐述具体的分析思路,但较为琐碎,也比较没有值得记录下来的重点。在章节结尾,提到了几篇延伸阅读,或许值得一看:
- 关于 Goal, Question, Metric (GQM)。此章节提到的分析过程,与GQM较为类似,可以从下篇文章获取更多思路:Basili, Victor, Gianluigi Caldiera, and Dieter Rombach. “The Goal Question Metric Approach.”
- 关于可视化如何完成特定的任务,分成两个角度:
a. high-level tasks: Amar, Robert and John Stasko. “A Knowledge Task-Based Framework for the Design and Evaluation of Information Visualizations.”
b. low-level tasks: Brehmer, Mathew and Tamara Munzner. “A Multi-Level Typology of Abstract Visualization Tasks.”
Ch 3:counseling, exploration and prototyping
Day 9:
这一章节讨论不同种类的技术,这些技术透过与利益关系者共事与迭代可视化原型来获得理解。这一个合作的过程称为数据咨询(data counseling)。数据咨询师探索数据、开发可视化、从初步结果中搜集反馈的交织。
数据咨询是可视化一个很重要的部分,如同前述,数据可视化若要落地需要有多年的领域知识,但有多年领域知识的人常常不懂数据可视化,因此懂数据可视化的人可以在其中担任咨询的角色。
Day 10:Technique 1: Data Counseling
数据咨询是将领域知识带入”操作化“过程中、用可视化来揭示洞见的技术。数据咨询最困难的部分是找出谁是利益关系者(who is stakeholder)以及可以问他们什么问题(what questions to ask)
Day 11:Identifying stakeholders
不同类型的利益关系者:
- Analyst:直接与数据打交道的人,他们最可能是使用可视化来解决问题
- Data producer:搜集、生产数据的人,在数据搜集方法有比较多的了解
- Gatekeeper:项目的把关者,他们的观点在了解较高层级问题与潜在的影响有帮助
- Decision maker:想要从数据中获取洞见以进行决策者,是数据分析师的顾客;跟距离数据较靠近的人相比,他们通常对目标与问题有不同的见解
- Connector:在数据与问题上没有直接参与,但可以明确需要交谈的人,他们可以将不同的观点融合起来,并判断需要进行什么分析
Day 12:Conducting interviews
举几个值得在访谈时问的问题:
- 这个项目的目标是什么?这些目标如何符合公司的需求?
- 谁会根据这些结果去行动?他们在寻求什么决策?
- 什么问题可以被数据回答?
- 你对数据有什么既有认知?你还期待发现其他什么东西?
- 对于目前无法获得的数据,你想对它做什么?
Day 13:
开始梳理脑图,帮助理解书籍架构。
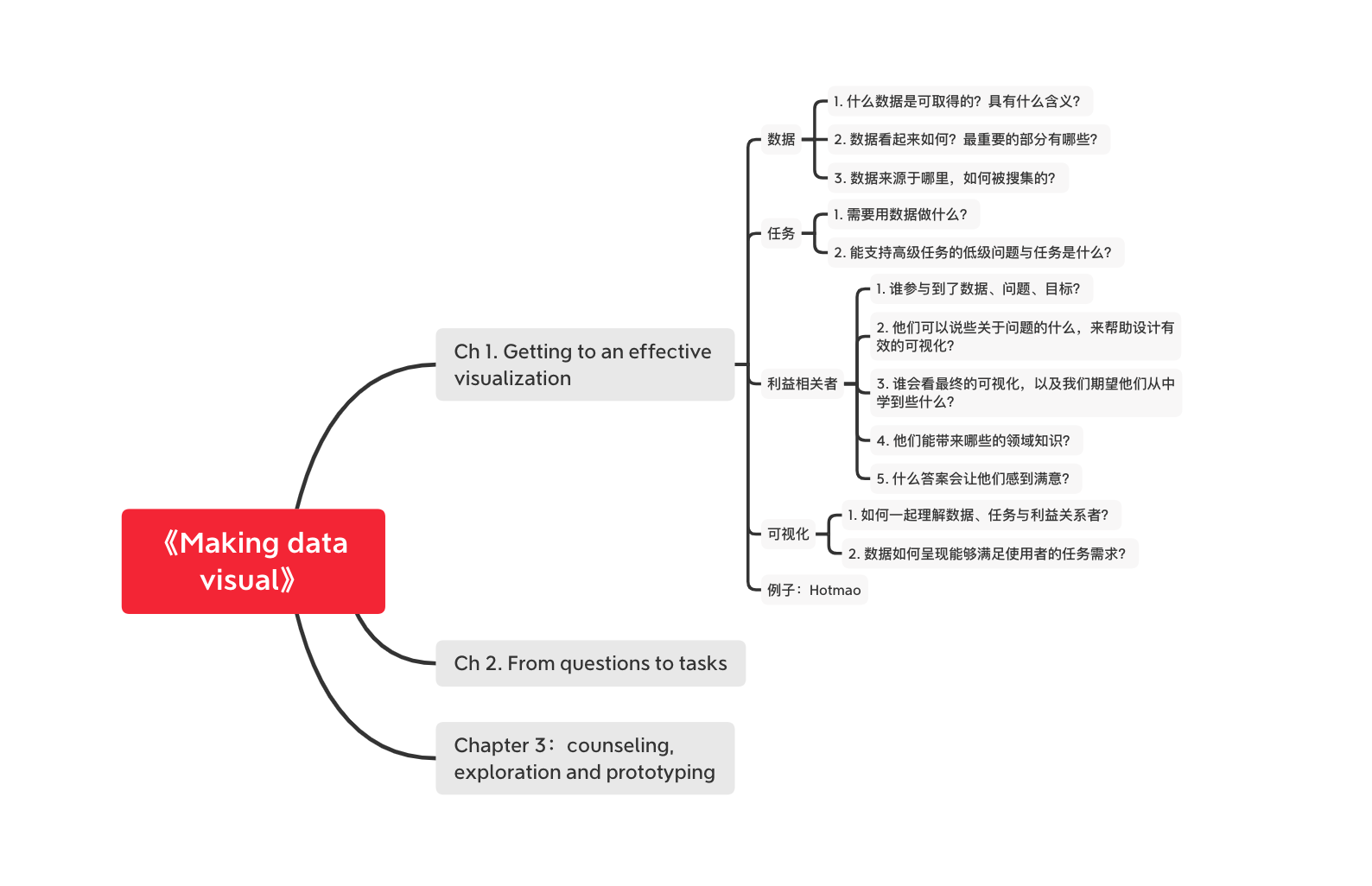
Day 14:Making questions specific
在访谈过程中,需要特别留意被访谈者的用词,例如当他们使用到了“选择”(select)、“识别”(identity)、“分组”(group),都可以进一步去问更具体的过程;这些用词可以直接在可视化工具里被使用。另外,“形状”(shape)、“结构“(structure)、”体型“(size)可以帮助了解有哪些视觉编码可以使用,或是利益关系者对哪些数据特征比较感兴趣看到。
语境访谈(contextual interview):
- 你目前工作的过程是如何?会使用哪些工具?
- 当分析数据时,你会遇到什么问题?
- 系统是否有限制?如何解决?
- 是否知道数据背后有任何的系统?或是有任何的算法运用其中?是否是黑箱?

Day 15:Technique 2: Exploring the Data
虽然访谈利益关系者很重要,但对数据探索的重要性是不可取的的,作者建议对数据的探索尽早进行。这一段讲了一些比较基础的常识,内容也不多。
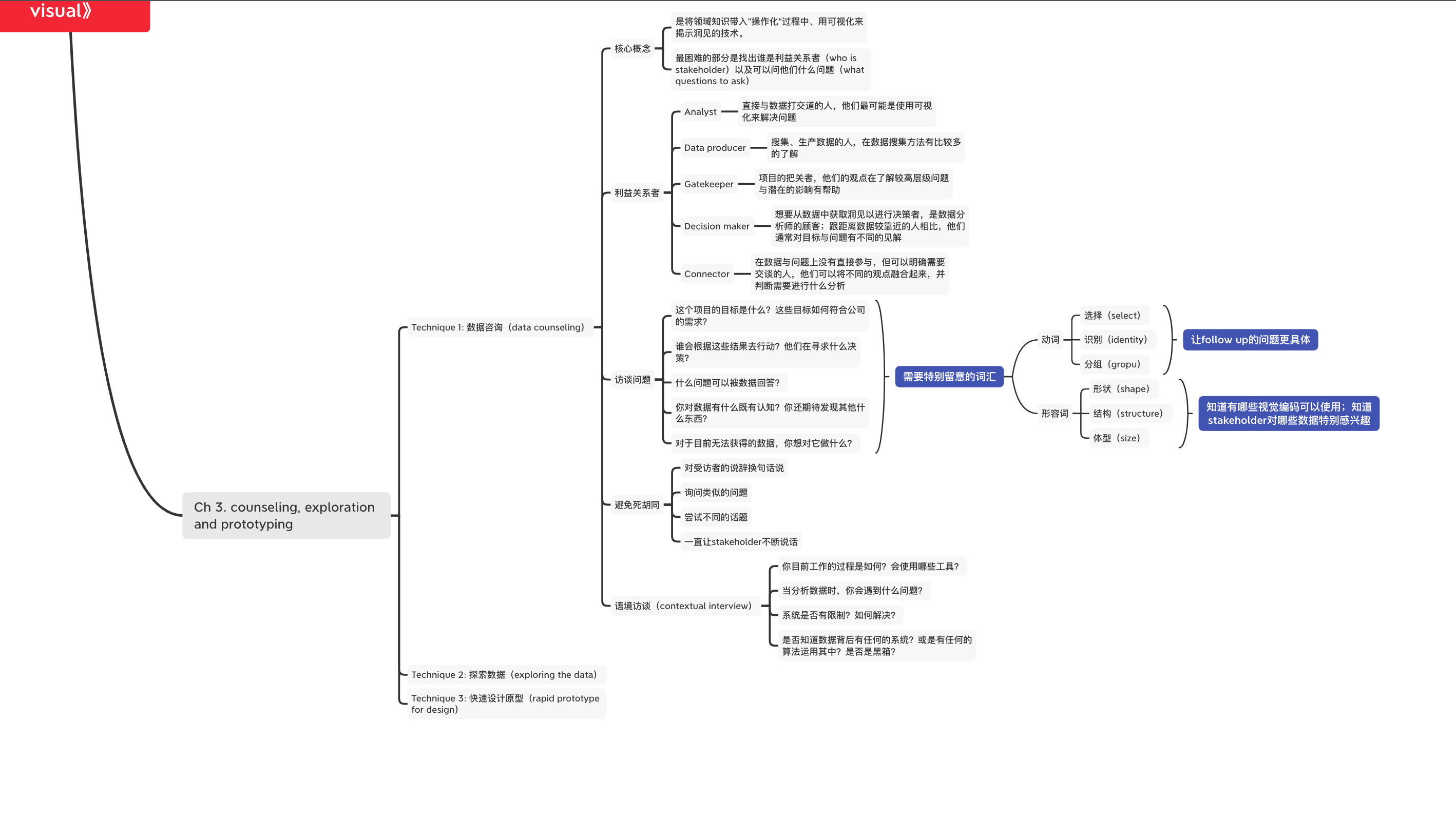
Day 16:conclusion
这三个技术:数据咨询、探索数据、快速设计原型,都是用来支撑问题的操作化。虽然他们个别就很好用,但整合使用这三个技术可以带来非常有利的帮助。

Ch 4:Components of a visualization
Day 17:dimensions and measures
维度(dimensions):对数据进行分组、分隔、筛选的属性(attributes)。
测量(measures):阐述感兴趣的问题的属性,且在不同的维度会有变化。
指标(metrics):有时候是用来描述代表代理的测量。

Day 18:dimensions
以一家卖冰激凌企业的例子来说明dimension跟measure。对这家企业而言,dimensions是产品、温度、时间、地点,而measure是利润。根据这些数据字段,他们又分成不同的数据类型:连续型、排序型、类别型、时序、地理位置、关系。

Day 19:
整理下脑图,调整了脑图的结构。
Day 20:Transforming Between Dimension Types
不同的数据类型要使用到特定的数据可视化有时候比较困难,此时可以对数据进行转换,让数据比较好能够接入数据可视化。数据的转换方式有如下几种:

Day 21:第四章总结
第四章最后一部分讨论了用户的看数行为,先从数据维度的转换再导引到可以分成简单与复杂的看数行为。整体第四章的架构上较为杂乱一些,之后需要回来重新梳理一下。这一章节挺重要的。

Ch 5. Single Views
Day 22:
这个章节主要针对不同的可视化类型进行介绍,从问题出发,来一一对应较为合适的可视化类型。
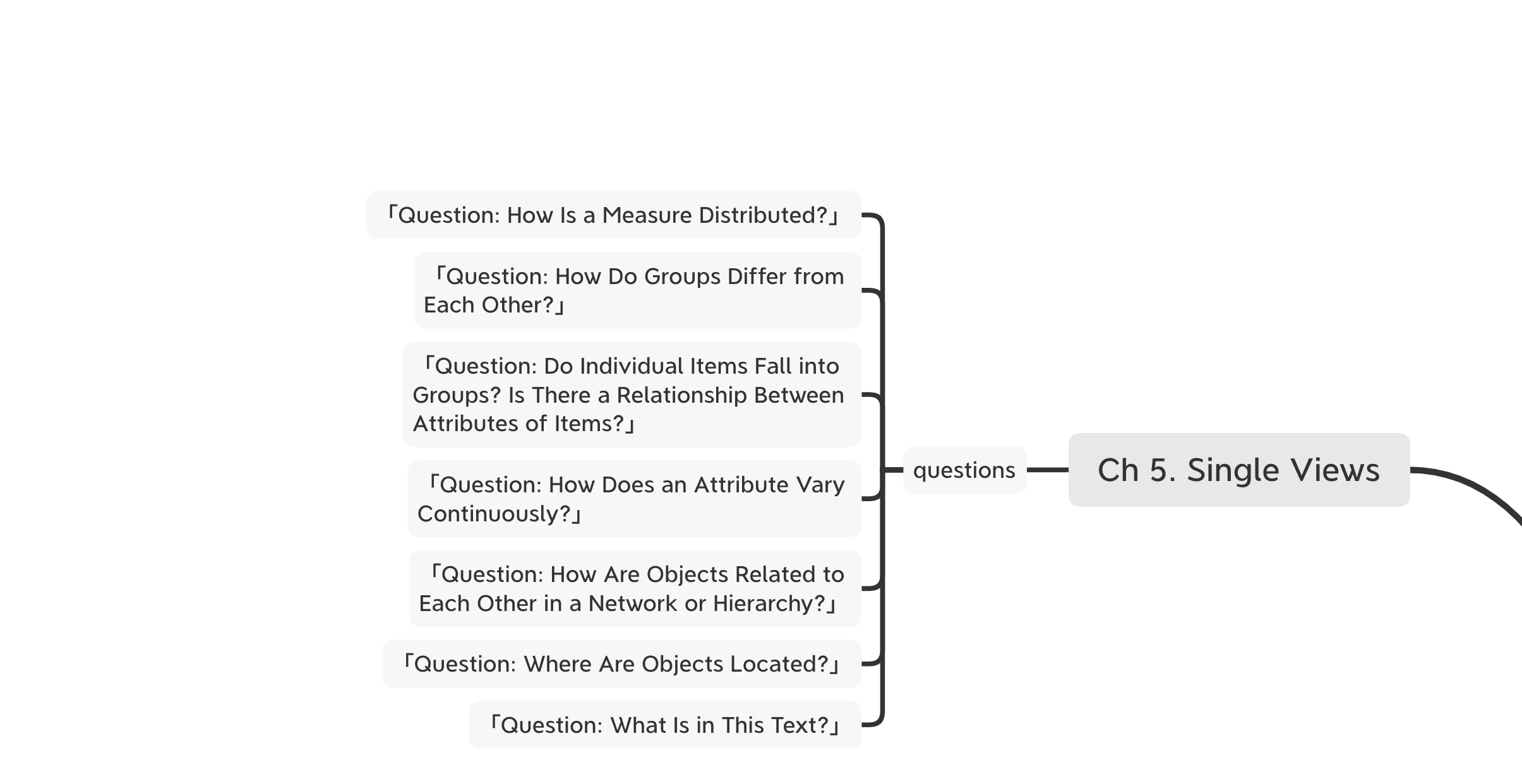
Day 23:
针对这几个问题,去匹配特定的可视化样式,但可以知道,这些问题与匹配的样式较为粗略,后续可以自行细化。

Day 24:Overall Perceptual Concerns
人类认知的优缺点促使数据可视化的设计。编码通道(encodding channels)代表一个attribute在可视化展现。比较优先级:长度、角度、面积、颜色、密度。例如颜色的缺点是,当颜色变多时较难辨认,但颜色可以叠加在不同维度上,可以承载较多信息。

Day 25:回顾整个脑图
今天较为忙碌,没有读新的篇章,复习了下之前阅读的内容。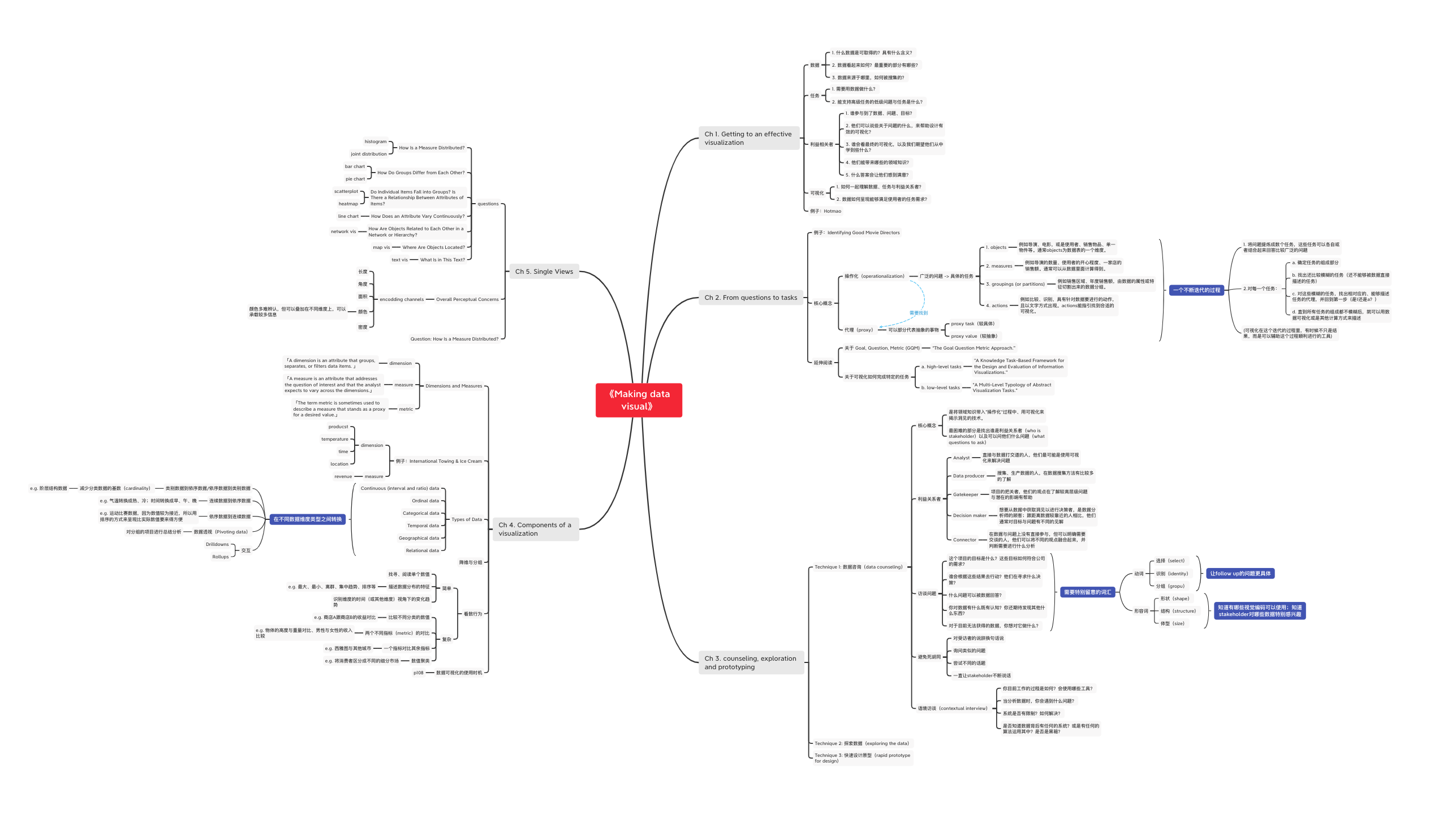
Day 26:Question: How Is a Measure Distributed?
这里提出一个问题:数据是如何分布的,并给了几个可以展示数据分布情况的数据图表。Histogram是最常见的,这里分成三类:categorical、quantitative、smoothed。另外还有box plot 与 热力图。都是较为常见的可视化图表。

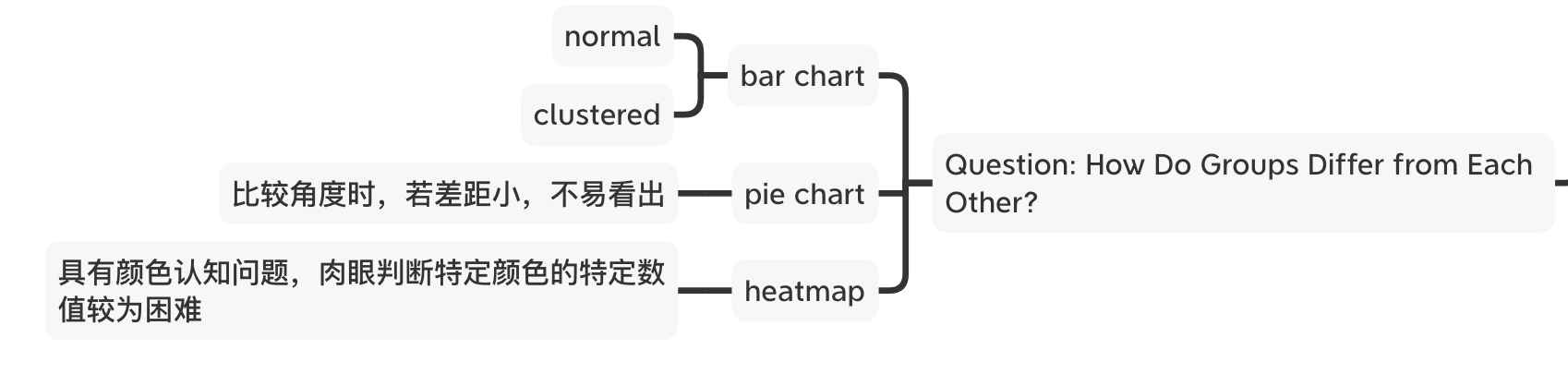
Day 27:Question: How Do Groups Differ from Each Other?
提出第二个问题:比较不同的群体,并提出了相对应的三类可视化图表。1 长条图,最为常见的样式,又可以区分为一般长条图与分组长条图。2 饼图,在比较相近数值时较为困难。3 热力图,在对应颜色与数值时也会产生理解成本。
Day 28:Question: Do Individual Items Fall into Groups? Is There a Relationship Between Attributes of Items?
第三个问题:如何知道个别项目是否属于某个群体,以及这些数据维度之间是否有关联。这时候可以使用散点图来看数据维度的关系,以及各个数据点的分布情况,但散点图会有彼此遮挡的问题。

Day 29:Question: How Does an Attribute Vary Continuously?
第四个问题:数据是如何连续变化。很直观的知道,回答这类问题可以用折线图或面积图。继续第五个问题:How Are Objects Related to Each Other in a Network or Hierarchy?。问的是数据之间的关系。关系图最常见的是点线连接的样式,另外基于这个基础之上还有许多不同的布局。

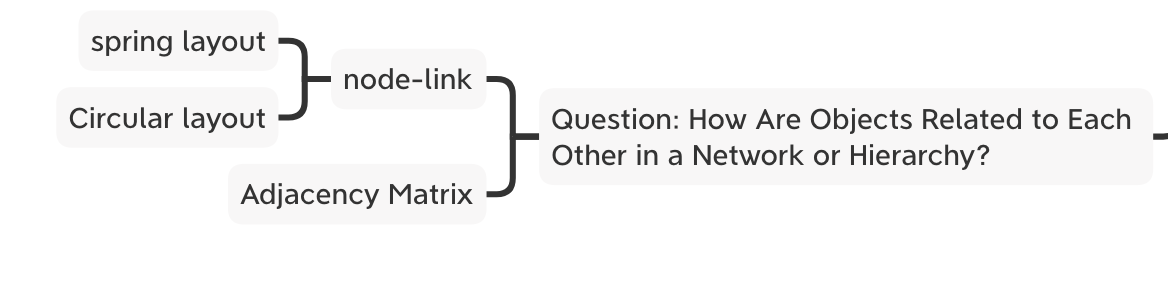
Day 30:How Are Objects Related to Each Other in a Network or Hierarchy?
延续上次的问题,除了 node-link样式外,还讨论了 adjacency matrix、tree、treemap&sunburst这3种样式来展示关系型数据。Adjacency matrix 以热力图的方式来展示数据两两之间的关系。Node-link 适用于少量且密度不高的数据,对于需要借由顺序来判断数据之间的关系,可以使用 matrix,有些科学家会手动调整数据顺序来观察数据的关系,但 matrix的缺点是占空间。Tree的缺点一样是容易占空间,可以用交互的方式来改善。Sunburst用到了角度,要判断数值大小不容易,但可以很好的看出数据的深度。
Day 30:Question: Where Are Objects Located?
地图应该是最让人熟悉的可视化类型了,许多人在小时候就接触地图相关书籍,然后才接触饼折柱这类图表。这里举例了两个典型的地图可视化类型: choropleth 与 dotplot,但地图可视化是一个专门的知识领域,这两个类型只是其中的例子。Choropleth的缺点是,居住在该地区的人口数量与该地区的地图面积没有关系,但在视觉上区域面积大的地方(虽然人口不一定多),往往容易获得较多的关注。对于 dotplot 也有同样的缺点,不论是关注哪一类型的数据,东海岸的点一定比内陆多,如何体现更深层的差异,需要有其他可视化样式的设计。此外,地图占据了两个较为重要的视觉通道:位置、大小,导致其他的视觉通道较难体现其价值。

Day 31:第五章总结
第五章的内容告一段落,重新梳理第五章的脑图。第五章的内容主要的介绍了视觉映射通道及其原理,然后提出了数个数据分析的问题,每个问题有各自匹配的可视化图表类型,并讲述了其优缺点。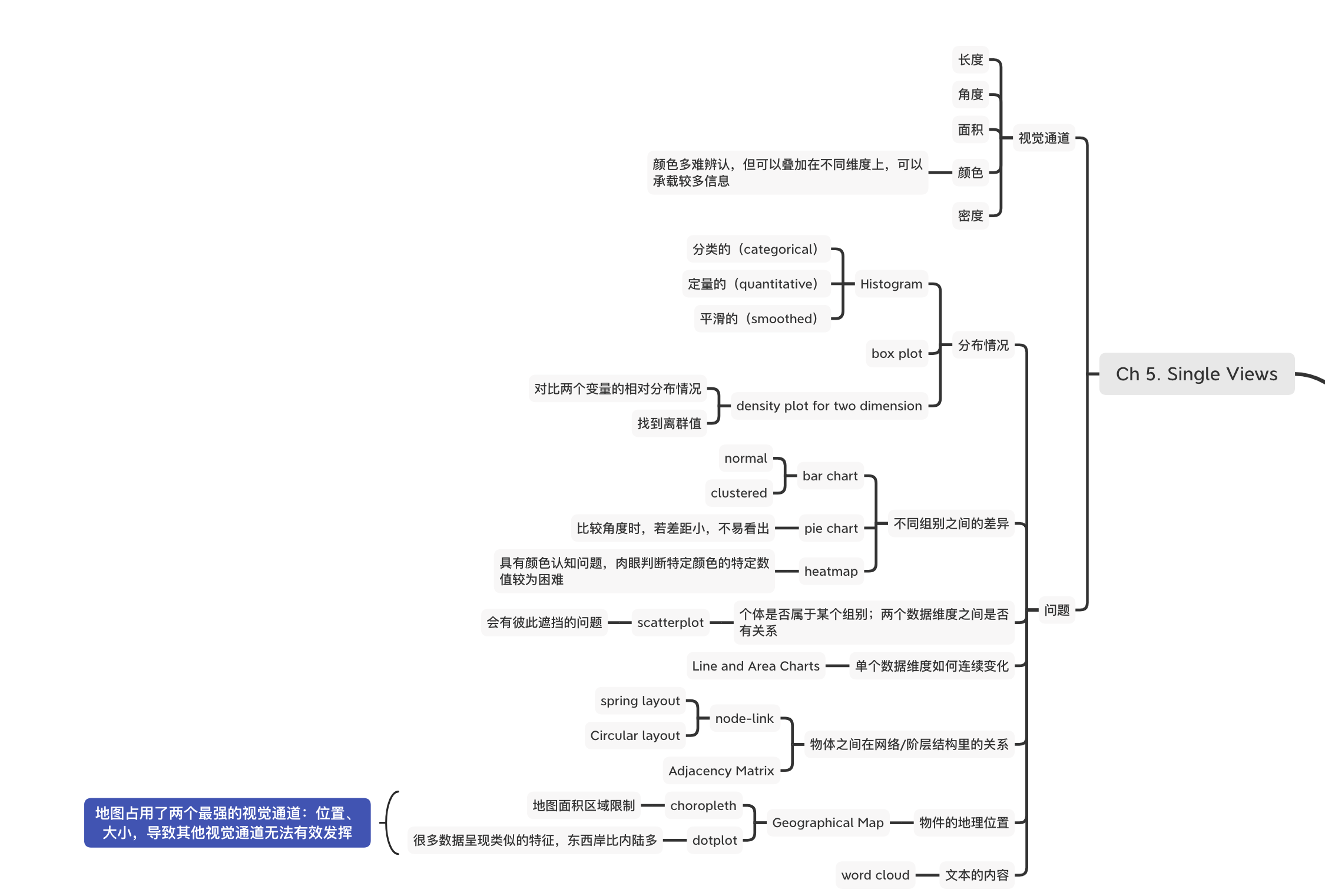
Day 32:
Chapter 6. Multiple and Coordinated Views(MLVs)
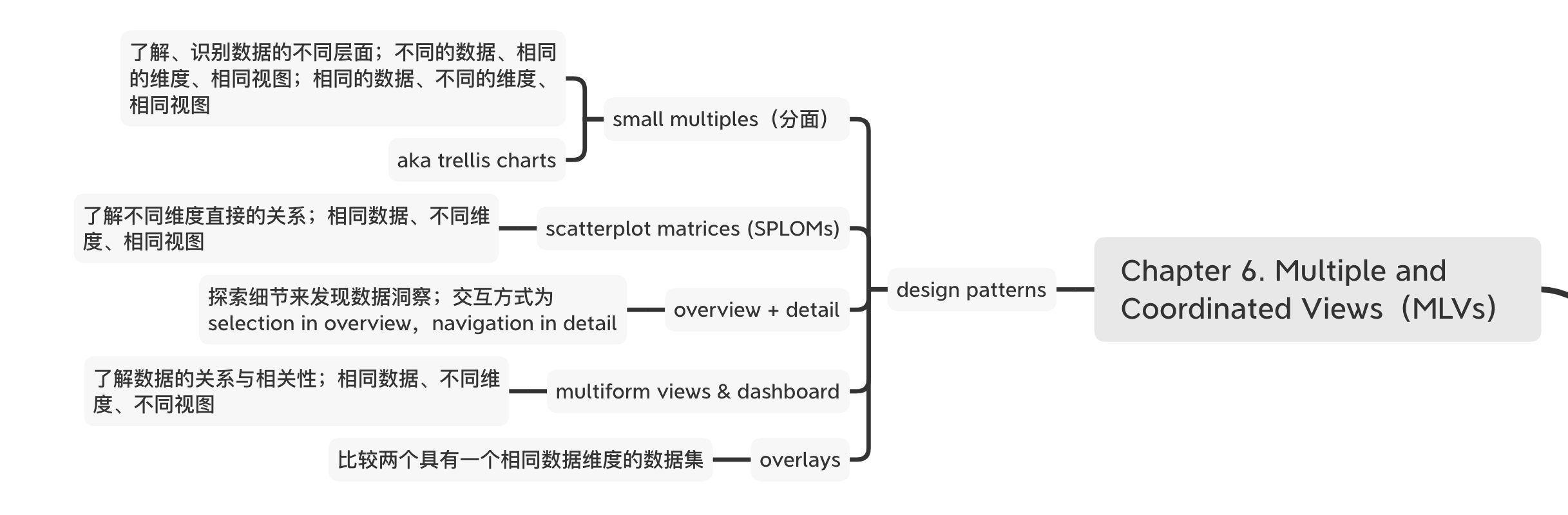
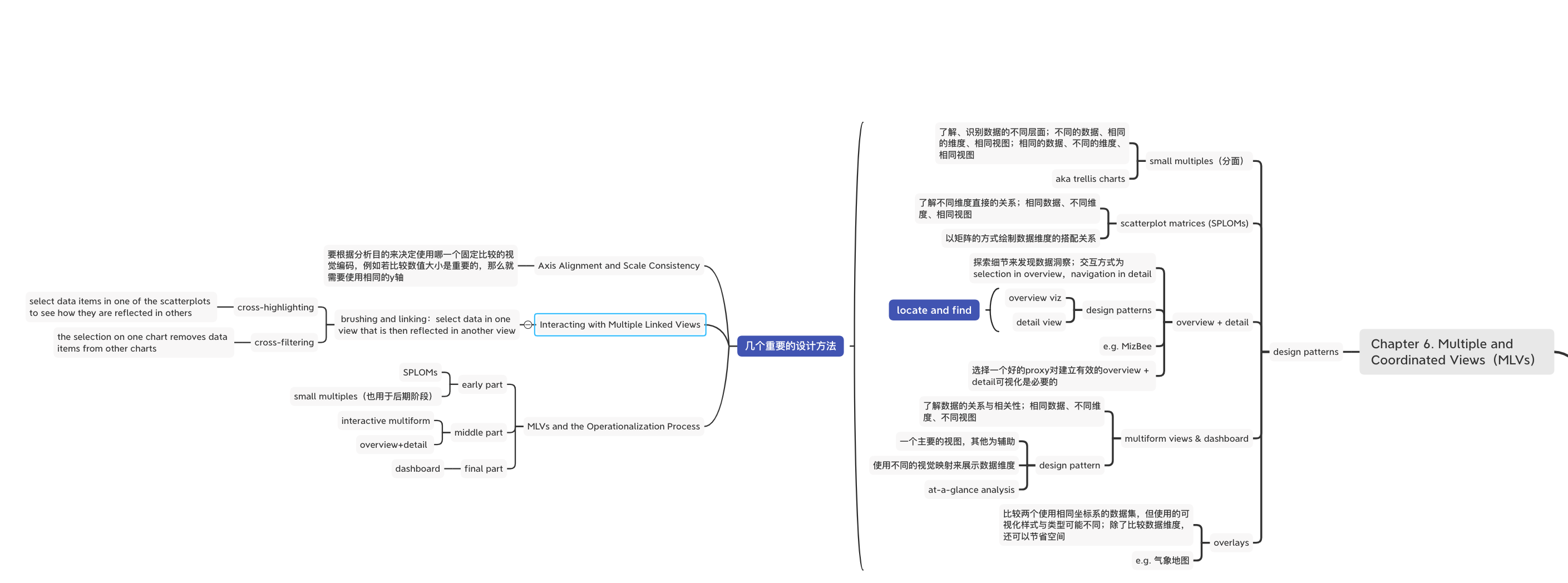
将不同的可视化以交互的方式串联起来,即MLVs。MLVs对了解大量复杂的数据是非常重要的。本章提出了5个设计MLVs的设计模式:small multiples、scatterplot matrices(SPLOMs)、overview+detail、multiform views & dashboard、overlays。

Day 33:Small multiples
又名为 trellis charts(格子图),天气预报常使用此类图表(?)。使用small multiples需要特别注意一致性,因为需要比较多个图表,保持一致性能够帮助理解图表。在比较数据子集但不同维度时,此类图表会特别有用。或是在探索式数据分析的前面阶段,可以用来帮助理解数据。
Day 34:Scatterplot Matrices
Scatterplot matrices(SPLOM)展示数据切片的样式,跟small multiples不一样的地方在于 SPLOM 以矩阵的方式绘制了数据的所有维度,而small multiples则不一定需要绘制。跟small multiples一样的地方在于,SPLOM适用于在探索性数据分析的前期阶段,用来更快速的了解数据的样貌。

Day 35:Overview+Detail
适用于探索一个完整的大量数据,用来定位、找到有意思的数据项,对于使用者,可以帮助他们建立对数据集有意思的部分、数据集可以继续探索的部分建立心智模型。设计模式为一个overview加上一个detail view,且可以总结为 locate·and find 的执行任务。选择一个好的proxy对建立有效的overview + detail可视化是必要的,overview需要被设计成可以展示多种不同的metrics,这样使用者才能够动态切换。最后,这类可视化需要大量的编程,所以通常是在可视化最后阶段,作为工具的最后样貌,而不适合作为EAD的探索工具。

Day 36:Multiform Views and Dashboards
可以展示多个数据维度,设计模式通常是一个主要的视图,其他视图为辅助。使用这个方式,通常为展示多个数据维度,但单个视图无法容纳;或是以不同的方式来展示数据,不同的视图使用不同的视觉编码,来展示数据的不同模式(例如一张图用颜色、一张图用高度)。

Day 37:第六章总结
第六章介绍了5个常见的使用数个视图的样式。在一个系统,通常不会只有一个视图,需要多个视图来拼凑出一个完整的数据分析思路。这些多个视图有哪些常见的类别,以及这些视图的设计模式是如何,在第六章有比较基础的介绍。在章节最后一部分,介绍了3个设计方法,针对这些具有多视图的可视化样式:1.对齐坐标轴与刻度一致:因为使用到了多个视图且这些视图之间须有可以比较的基准,坐标轴以及刻度是让这些视图可以横向比较的重点;2.多个视图的交互:分成两个,cross-highlighting与cross-filtering,简而言之是筛选数据或是突出数据;3.操作化阶段:这些样式分别会在操作化的不同阶段,有些是前期探索,有些则是用于中后期的系统设计,区别在于,前期探索式尽量展示数据的样貌,而中后期的探索则是更注重系统的交互完整性。
Chapter 7. Case Study 1: Visualizing Telemetry to Improve Software
Day 38:Data
剩下的两章会分别详细介绍一个例子。第七章是关于遥测数据的例子。会具体运用到前面几章的分析思路。以一个然人为例,先从任务拆解开始,拆解成行动、目标、测量方法、群组。

Day 39:Determining How to Compare Builds
将任务拆解后,仍是较大,还不知道如何比较两个不同分组的区间数据。客户对目前的可视化样式不满意,目前的可视化使用了三个符合与颜色,分别代表三个情况,但在不同的时间,无法看出数据的细致变化,例如近几年的数据都是黄色,但具体数据是如何变化的无法得知。使用histogram就能够解决这个问题。

Day 40:Comparing Distributions to Understand “Better”
上一部分对图表进行转换,使用histogram来绘制数据的分布情况,发现数据呈现两个高峰,看到这个现象后stakeholders对比较两个群组的数据感兴趣。因此,在此部分将朝这个方向进行设计。设计师提出了两种可视化类型:分组柱状图、对比柱状图。但让stakeholder进来讨论后,发现使用多条折线图会更合适,可以看到多条分组数据的分布情况。
在看到多个分组数据后,需要继续问一个问题:哪一个分组数据值得继续探索?

Day 41:Multiple Scenarios
针对release manager的需求,定义了两个分析任务:1. 需要看全局,找出表现最佳与最差的数据;2.针对特定数据,具体找出有问题的部分。
Sketching Dashboards
绘制原型阶段,数个团队分别绘制可能的原型,借此作为信息呈现与设计的考量基础。

Day 42:Turning Back to the Data
Sketch很重要,但仍需回归到数据本身。借由加入数据,可以看到在sketching阶段看不到的问题。
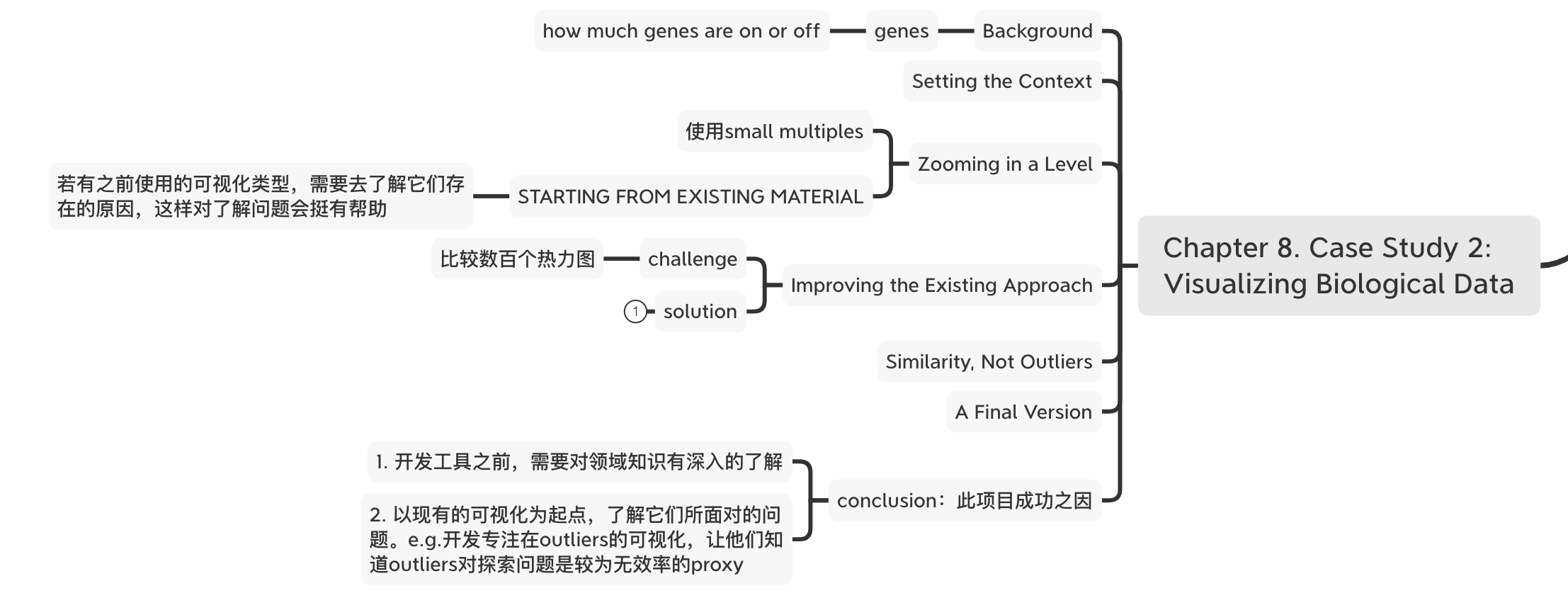
Chapter 8. Case Study 2: Visualizing Biological Data
此章节的例子较复杂,是科学可视化领域。
Zooming in a Level
– STARTING FROM EXISTING MATERIAL
若有之前使用的可视化类型,需要去了解它们存在的原因,这样对了解问题会挺有帮助。
在此章节最后,作者总结了这个项目得以成功的原因,有几点:1. 开发工具之前,需要对领域知识有深入的了解;2. 以现有的可视化为起点,了解它们所面对的问题。e.g.开发专注在outliers的可视化,让他们知道outliers对探索问题是较为无效率的proxy。
Day 43:总结 - part 1
对这本书进行总结梳理,希望找出一个链路,对整个分析过程进行拆解与定义。这一个多月累积了一个整本书的思维脑图,但是根据章节拆分,应该是要以一个连贯的方式来理解。目前只梳理出一个简要的流程。还需要继续优化。

Day 44:总结 - part 2
数据与问题的关系在书中没有很明确的被定义或是阐述,但两者应该是具有互相促进的关系,数据可以产生问题,或是从问题去思考有哪些关联的数据。论文,从问题到任务,操作化扮演重要的角色。

DayDa 45:总结 - part 3
需要理解这个流程图是基于谁的视角,不同角色会有不同的需求。数据如何跟问题关联,是一个比较重要的问题,这会决定是否需要使用可视化,或是用统计值,或是用AI算法等方式。需要对数据可视化的最佳使用场景去定义运用范围。

Day 46:总结 - part 4
数据跟问题应该不是双向的关系,应该是数据到问题需要被明确的单向过程;若问题没有明确的话,数据无法直接导向任务。操作化的过程是基于ojbect、measure、grouping、action的一个迭代的过程,具体执行方面是将大的、不明确的问题拆解成小的、明确的问题。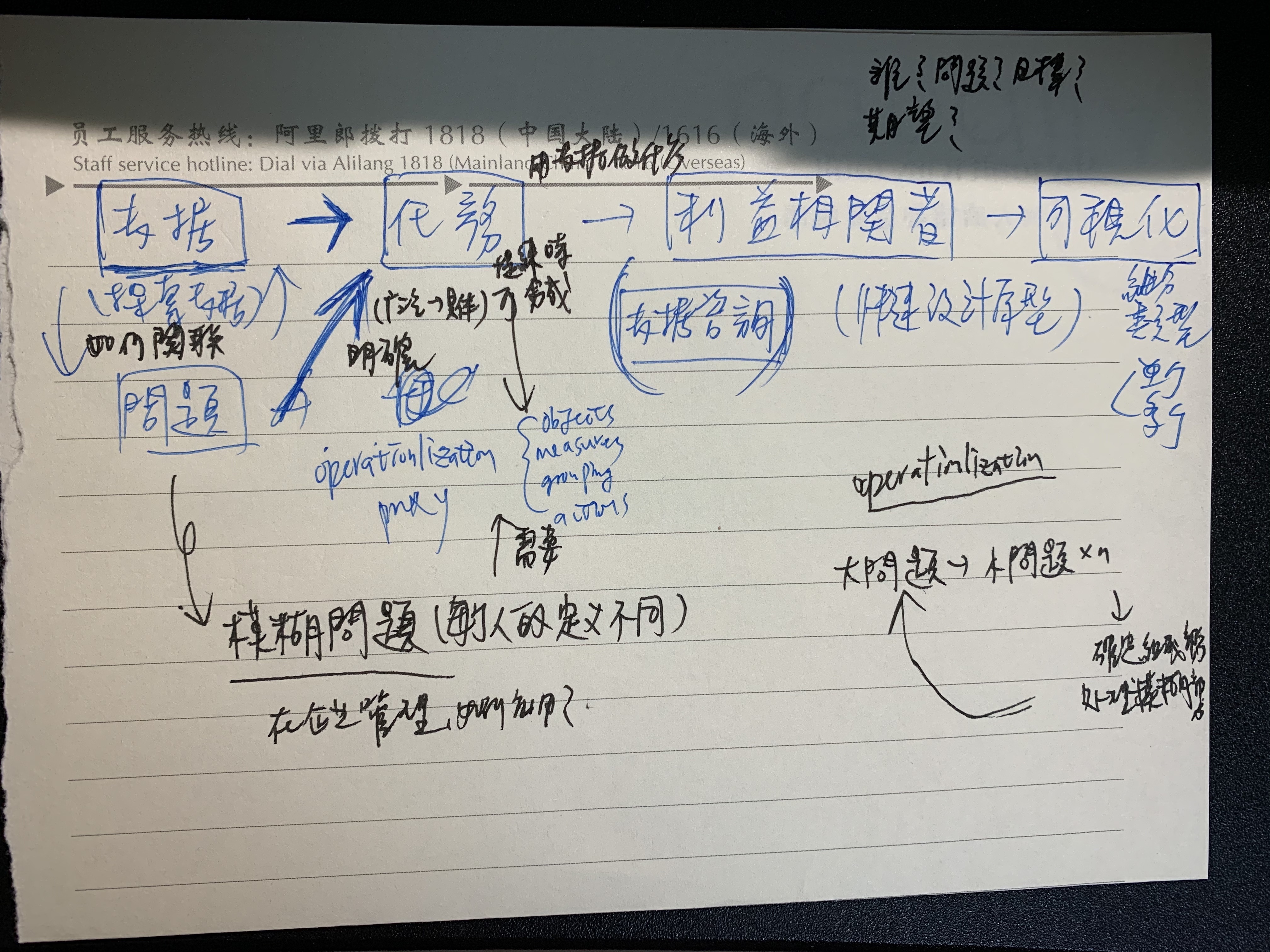
Day 47:总结 - part 5
预计明天将这本书结束掉。需要针对第四章与第23、32天的内容再一次的阅读,并整合到思维脑图里。
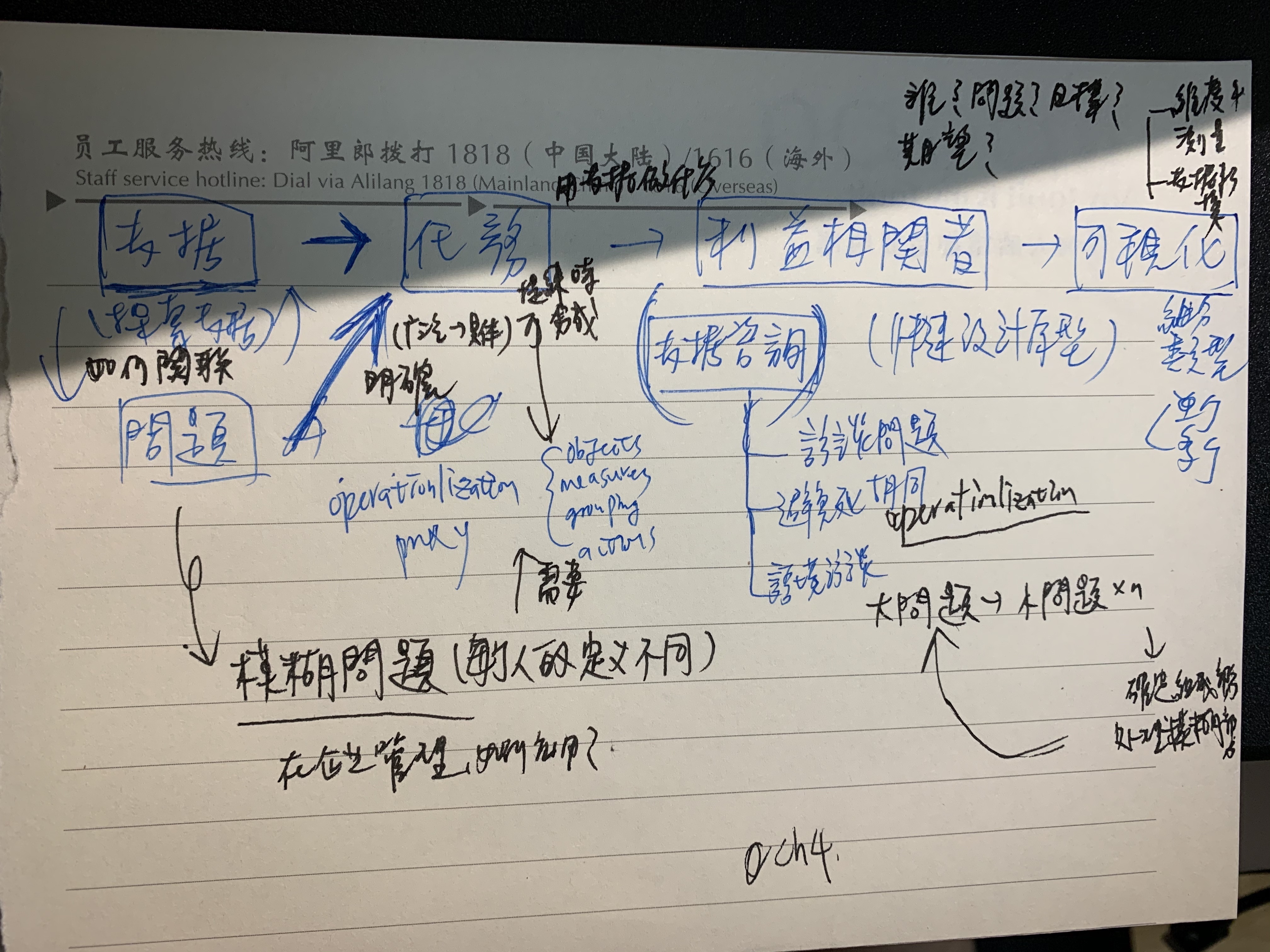
Day 48:总结 - part 6
对脑图重新拆解,才发现自己在整个框架上的理解并没有很清楚。Operationalization跟data counseling之间是什么关系?整本书讲的是Operationalization还是data counseling?这个需要去明确。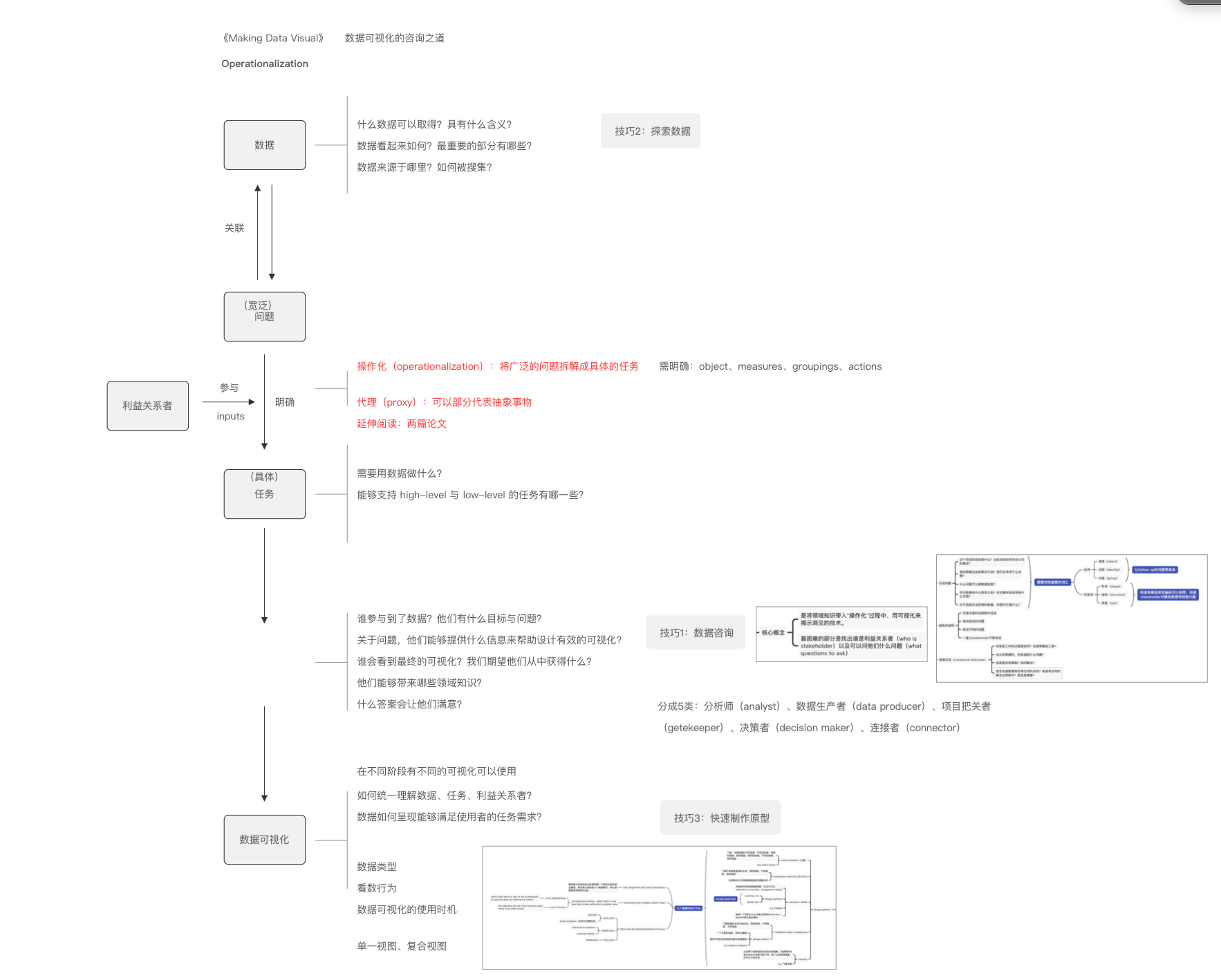
Day 49:总结 - part 7
整个过程明确为4个步骤:数据、问题、任务、数据可视化。利益关系者是在从宽泛问题到具体任务需要去咨询的人,从他们那边获取洞见、领域知识、项目背景等信息。
Day 50:总结 - part 8
继续梳理脑图样式,简化部分的信息展示,对于操作化需要明确的4个部分,缩略了解释部分。剩余利益关系者与数据可视化。

Day 51:总结 - part 9
整理好了简化版的脑图,现在回顾这本书,觉得有许多部分讲得比较浅,但提供了一个挺好的框架。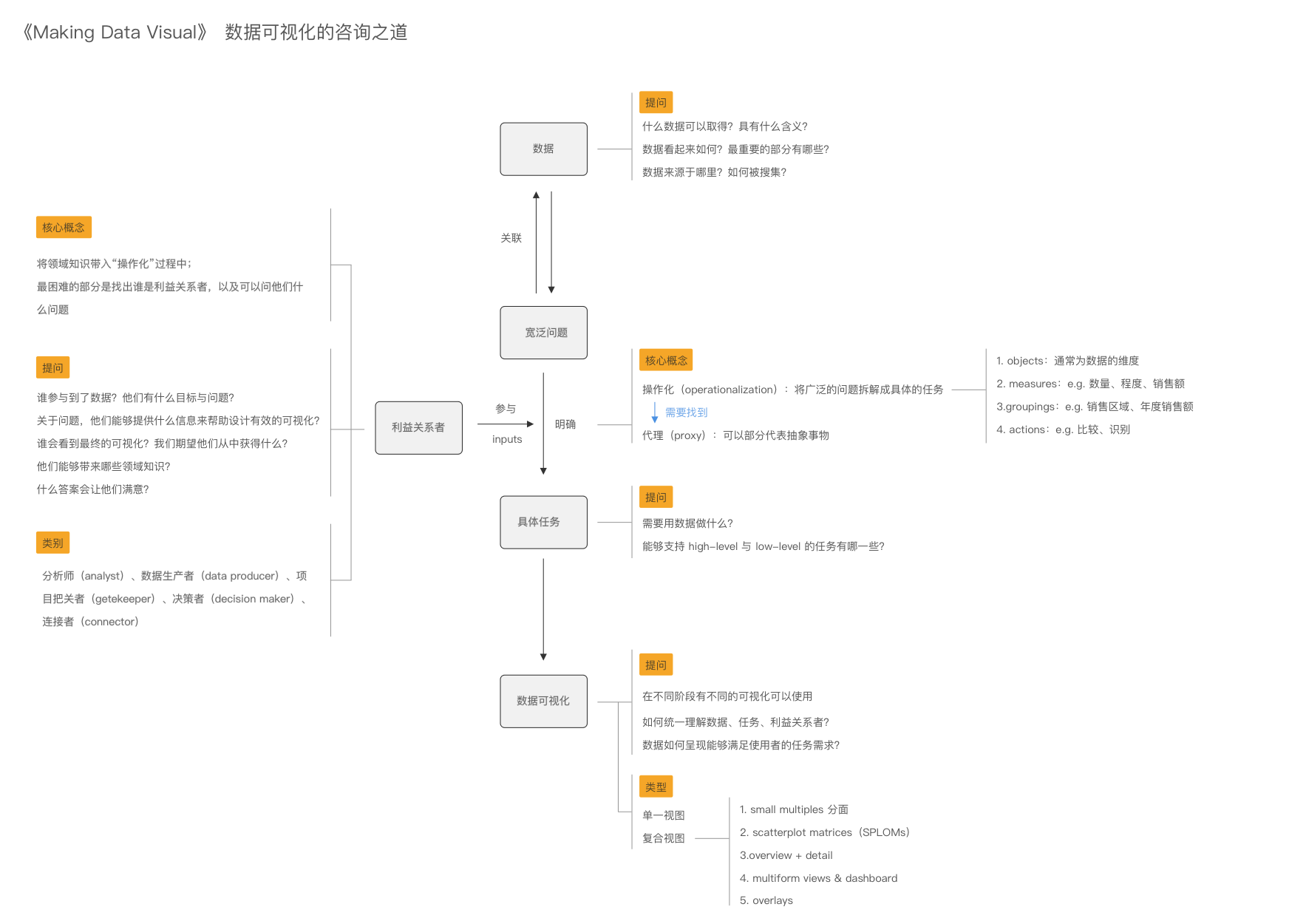
Day 51:撰写文章 - part 1
接下来几天针对之前读的书进行文章的撰写。梳理了大致的结构:前言、关于作者、总览、数据可视化有用之处、proxy、数据咨询、结语。

Day 52:撰写文章 - part 2
完成了前言的部分。
Day 53:撰写文章 - part 3
完成作者部分,但可能后续要修改。

Day 54:撰写文章 - part 4
完成总览部分。
Day 55:撰写文章 - part 5
完成”什么时候该使用可视化?“章节。
————

若有收获,就点个赞吧
0 人点赞
