HA故障切换功能测试
背景
一、NameNode 保存了整个 HDFS 的元数据信息,一旦 NameNode 挂掉,整个 HDFS 就无法访问,为了解决namanode单点的问题,hadoop2.X通过配置active/stanby两个namenode,进而实现namenode的热备。 二、ResourceManager 可以启动多台,只有其中一台是 active 状态的,其他都处于待命状态。这台 active 状态的 ResourceManager 执行的时候会向 ZooKeeper 集群写入它的状态,当它故障的时候这些 RM 首先选举出另外一台 leader 变为 active 状态,然后从 ZooKeeper 集群加载 ResourceManager 的状态。在转移的过程中它不接收新的 Job,转移完成后才接收新 Job。基础信息
hadoop版本 3.3.1 内网 网络信息服务器信息IP |
操作系统 | CPU |
内存 | 磁盘空间 | 顺序读 | 顺序写 |
|---|---|---|---|---|---|---|
10.241.80.131 |
CentOS Linux release 7.6.1810 | 8 |
16 |
200G |
235MB/s |
107MB/s |
10.241.80.147 |
CentOS Linux release 7.6.1810 | 8 |
16 |
200G |
237MB/s |
102MB/s |
10.241.80.148 |
CentOS Linux release 7.6.1810 | 8 |
16 |
200G |
283MB/s |
113MB/s |
一、namenode主备切换
主备切换机制
要完成HA,除了元数据同步外,还得有一个完备的主备切换机制,Hadoop的主备选举依赖于ZooKeeper 主备切换状态图: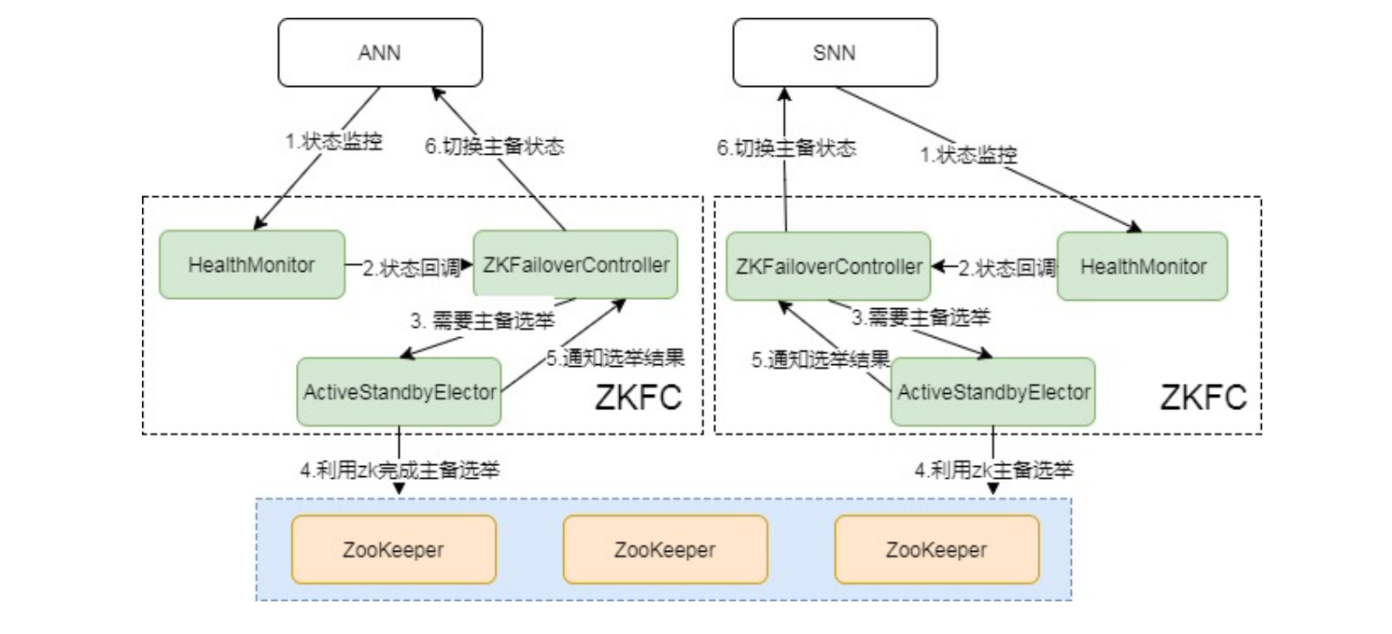
Hadoop 2.x元数据
Hadoop的元数据主要作用是维护HDFS文件系统中文件和目录相关信息。元数据的存储形式主要有3类:内存镜像、磁盘镜像(FSImage)、日志(EditLog)。在Namenode启动时,会加载磁盘镜像到内存中以进行元数据的管理,存储在NameNode内存;磁盘镜像是某一时刻HDFS的元数据信息的快照,包含所有相关Datanode节点文件块映射关系和命名空间(Namespace)信息,存储在NameNode本地文件系统;日志文件记录client发起的每一次操作信息,即保存所有对文件系统的修改操作,用于定期和磁盘镜像合并成最新镜像,保证NameNode元数据信息的完整,存储在NameNode本地和共享存储系统(QJM)中。 如下所示为NameNode本地的EditLog和FSImage文件格式,EditLog文件有两种状态: inprocess和finalized, inprocess表示正在写的日志文件,文件名形式:editsinprocess[start-txid],finalized表示已经写完的日志文件,文件名形式:edits[start-txid][end-txid]; FSImage文件也有两种状态, finalized和checkpoint, finalized表示已经持久化磁盘的文件,文件名形式: fsimage_[end-txid], checkpoint表示合并中的fsimage, 2.x版本checkpoint过程在Standby Namenode(SNN)上进行,SNN会定期将本地FSImage和从QJM上拉回的ANN的EditLog进行合并,合并完后再通过RPC传回ANN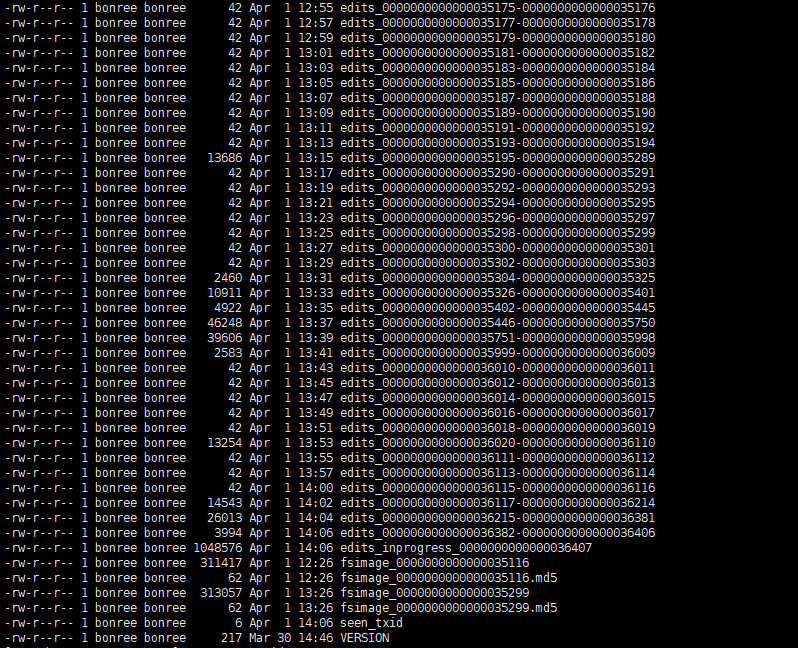
QJM 写过程
NameNode会把EditLog同时写到本地和JournalNode。写本地由配置中参数dfs.namenode.name.dir控制,写JN由参数dfs.namenode.shared.edits.dir控制,在写EditLog时会由两个不同的输出流来控制日志的写过程,分别为:EditLogFileOutputStream(本地输出流)和QuorumOutputStream(JN输出流)。写EditLog也不是直接写到磁盘中,为保证高吞吐,NameNode会分别为EditLogFileOutputStream和QuorumOutputStream定义两个同等大小的Buffer,大小大概是512KB,一个写Buffer(buffCurrent),一个同步Buffer(buffReady),这样可以一边写一边同步,所以EditLog是一个异步写过程,同时也是一个批量同步的过程,避免每写一笔就同步一次日志隔离
在ANN每次同步EditLog到JN时,先要保证不会有两个NN同时向JN同步日志。这个隔离是怎么做的。这里面涉及一个很重要的概念Epoch Numbers,很多分布式系统都会用到。Epoch有如下几个特性: 1、当NN成为活动结点时,其会被赋予一个EpochNumber 2、每个EpochNumber是惟一的,不会有相同的EpochNumber出现 3、EpochNumber有严格顺序保证,每次NN切换后其EpochNumber都会自增1,后面生成的EpochNumber都会大于前面的EpochNumber QJM是怎么保证上面特性的呢,主要有以下几点: 这样就能保证主备NN发生切换时,就算同时向JN同步日志,也能保证日志不会写乱,因为发生切换后,原ANN的EpochNumber肯定是小于新ANN的EpochNumber,所以原ANN向JN的发起的所有同步请求都会拒绝,实现隔离功能,防止了脑裂。 1、在对EditLog作任何修改前,QuorumJournalManager(NameNode上)必须被赋予一个EpochNumber 2、QJM把自己的EpochNumber通过newEpoch(N)的方式发送给所有JN结点 3、 当JN收到newEpoch请求后,会把QJM的EpochNumber保存到一个lastPromisedEpoch变量中并持久化到本地磁盘 4、 ANN同步日志到JN的任何RPC请求(如logEdits(),startLogSegment()等),都必须包含ANN的EpochNumber 5、JN在收到RPC请求后,会将之与lastPromisedEpoch对比,如果请求的EpochNumber小于lastPromisedEpoch,将会拒绝同步请求,反之,会接受同步请求并将请求的EpochNumber保存在lastPromisedEpoch场景一
activenamenode宕机自动切换 切换前检查: 131为active

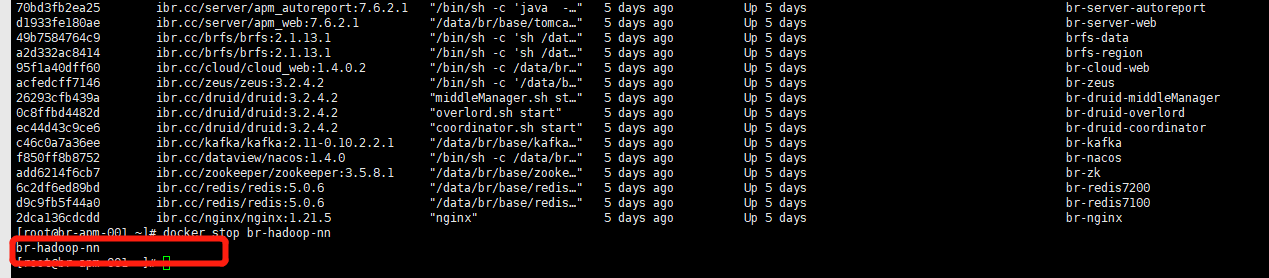

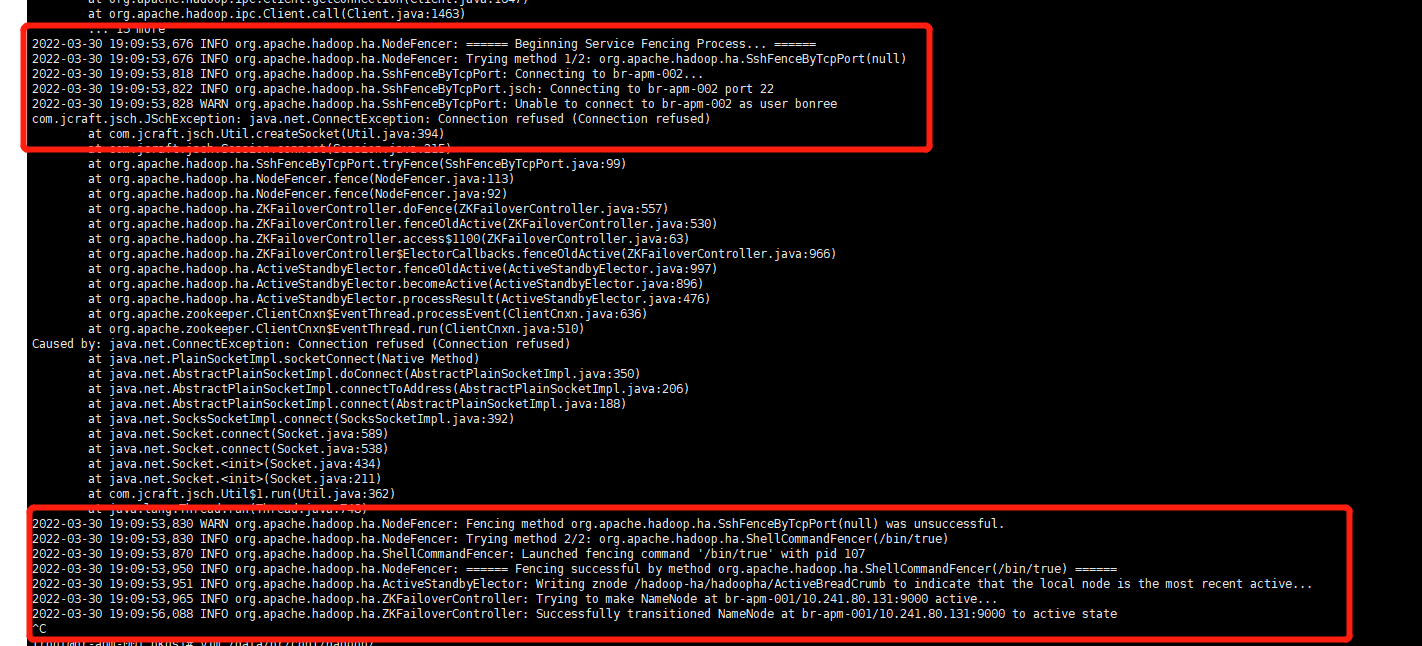
场景二
ZKFC崩溃自动切换 切换前检查: 131为active

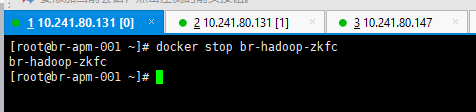
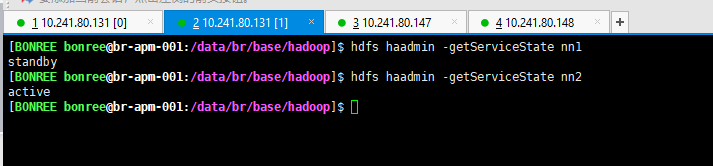
场景三
zookeeper崩溃 切换前检查: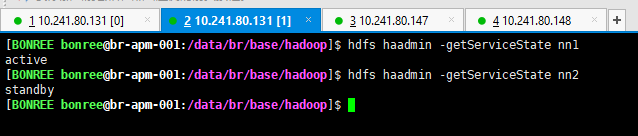



场景四
上传大文件,发生主备切换,文件能否继续上传&&发生故障切换时,客户端连接现象 测试前检查: 147为active,131为standby
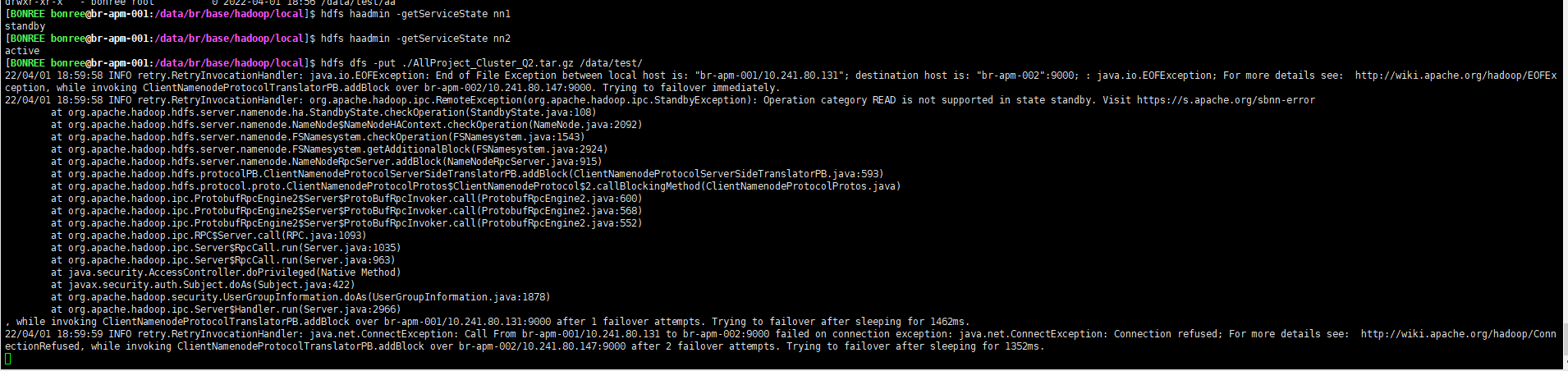






二、YARN-RM主备切换
切换前检查: 148为active,147为standby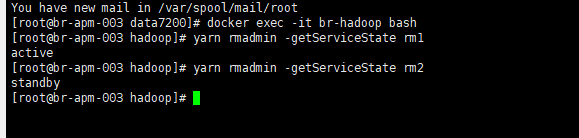 故障模拟:
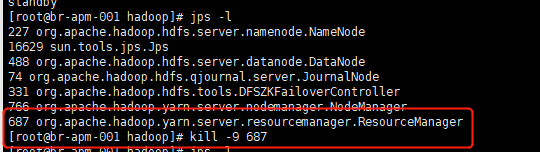
把131上RM停掉
故障模拟:
把131上RM停掉


若有收获,就点个赞吧
0 人点赞
