一、 Hadoop 集群部署
此次部署的组件包为 hadoop- 3.3.2.tar.gz , apache-zookeeper- 3.8.0-bin.tar.gz , jdk1.8.0_171.tar.gz 。
jdk 为 hadoop 提供 jre 环境, zk 为hadoop 提供高可用,本次集群节点为三台。
1、配置免密和主机名
配置主机名
三台机器上分别执行如下命令,修改主机名。修改完毕后,通过 bash命令刷新窗口。
hostname-ctl hostname-ctl hostname-ctl
set-hostname set-hostname set-hostname
zhjiann01
zhjiann02
zhjiann03
将以下内容,拷贝到每台服务器的 /etc/hosts 目录下, ip 和 主机名需要根据实际情况更新。如果通 过 ping zhjiann01 可以正常连通,则证明配置修改已完成。
10.241.80.117 zhjiann01
10.241.80.116 zhjiann02
10.241.80.115 zhjiann03

配置免密
方法一
 在每个主机上,生成公钥和私钥,然后拷贝到 authorized_keys 中,对于提示, 一路回车即可
在每个主机上,生成公钥和私钥,然后拷贝到 authorized_keys 中,对于提示, 一路回车即可
将三台服务器上的 ~/.ssh/id_rsa.pub 文件中内容,分别拷贝到每台服务器的 ~/.ssh/authorized_keys 中,没有此文件则新建。
 通过 ssh zhjiann01 命令能够跳转且无需输入密码,则证明免密配置成功。
通过 ssh zhjiann01 命令能够跳转且无需输入密码,则证明免密配置成功。
方法二
 在每个主机上,生成公钥和私钥,然后拷贝到 authorized_keys 中,对于提示, 一路回车即可
在每个主机上,生成公钥和私钥,然后拷贝到 authorized_keys 中,对于提示, 一路回车即可
 此方法需要知道每台服务器的密码,在此前提下,可通过 ssh-copy-id 命令来完成免密操作。
此方法需要知道每台服务器的密码,在此前提下,可通过 ssh-copy-id 命令来完成免密操作。

三台服务器上,分别执行以下操作,中途需要输入密码来进行初次校验。
# -p 指定端口,不指定则默认为 22
# -i 指定公钥文件位置,不配置则默认为 ~/.ssh/id_rsa.pub
# @ 前为用户名,不指定则默认为当前窗口的所登陆的用户
# @ 后为服务器ip或者主机名
ssh-copy-id -p 2226 -i ~/.ssh/id_rsa.pub root@zhjiann01
ssh-copy-id -p 2226 -i ~/.ssh/id_rsa.pub root@zhjiann02
ssh-copy-id -p 2226 -i ~/.ssh/id_rsa.pub root@zhjiann03 |
|
 通过 ssh zhjiann01 命令能够跳转且无需输入密码,则证明免密配置成功。
通过 ssh zhjiann01 命令能够跳转且无需输入密码,则证明免密配置成功。
2、配置JDK环境
以下操作在三台服务器上分别执行。解压 jdk 压缩包至指定目录
tar zxvf jdk1.8.0_171.tar.gz -C /data/br/base/
# 为了便于维护,可增加软连接
ln -s /data/br/base/jdk_1.8.0_171 jdk |
|
在 /etc/profile 中追加如下内容
export JAVA_HOME=/data/br/base/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar |
|
通过 source /etc/profile 刷新 profile ,并通过 java -version 命令来验证,有如下输出则证明配 置完成。

3、搭建Zookeeper集群
部署步骤
以下操作在三台服务器上均需要进行操作。
解压 zookeeper 压缩包,并设置软链接,方便后续维护和管理。
tar zxvf apache-zookeeper-3.8.0.tar.gz -C /data/br/base/
ln -s /data/br/base/apache-zookeeper-3.8.0 /data/br/base/zookeeper
将 zookeeper 路径配置到 /etc/profile 中,方便后续的 zookeeper操作。修改完成后,通过 source /etc/profile 来刷新配置
# 追加如下内容
export ZOOKEEPER_HOME=/data/br/base/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin |
|
修改 zookeeper 配置文件
cd /data/br/base/zookeeper/conf
cp -a zoo_sample.cfg zoo.cfg
参考如下内容,修改配置文件 zoo.cfg
# 心跳间隔,单位ms
tickTime=6000
initLimit=10
syncLimit=5
clientPort=2181
admin.serverPort=18080
admin.enableServer=false
# 数据存放目录
dataDir=/data/br/base/zookeeper/data
# 日志存放目录
dataLogDir=/data/br/base/zookeeper/logs
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
maxClientCnxns=500
# 每个服务节点的id,server后面的id需要和myid文件中的一致
server.117=br-apm-001:3524:4524
server.116=br-apm-002:3524:4524
server.115=br-apm-003:3524:4524
在 /data/br/base/zookeeper/data 中,新建 myid文件,并在文件中追加 zoo.cfg 中配置的节点 ID,此文档中分别为117,116,115 。
常见问题
 包下载错误
包下载错误
启动zk时,发现如下报错
Error:Could not find or Load main class
org.apache.zookeeper.server.quorum.QuorumPeerMain
原因为,下载的包为未进行编译的zk包,重新下载带bin的包后解决
 myid 文件缺失
myid 文件缺失
启动zk时,提示找不到 myid文件
| Caused by: java.lang.IllegalArgumentException: …myid file is missing |
|
根据配置文件中配置的 dataDir 目录,发现缺失 myid 文件。构造 myid 文件,并将对应的 serverid 写入。
4、搭建Hadoop集群
此次 hadoop各组件分配如下
| zhjiann01 |
namenode,zkfc,resourceManager |
|
|
|
|
| zhjiann02 |
|
|
|
|
|
| zhjiann03 |
|
|
|
|
4.1 部署步骤
三台服务器分别解压文件到指定目录
tar zxvf hadoop-3.3.2.tar.gz -C /data/br/base/
mv hadoop-3.3.2 hadoop
4.1.1 修改 hadoop-env.sh
# 配置 jdk 路径
export JAVA_HOME=/data/br/base/jdk
# 配置 hadoop 路径
export HADOOP_HOME=/data/br/base/hadoop/
# hadoop 各组件守护进程的堆内存,默认 1000MB
export HADOOP_HEAPSIZE_MAX=512
export HADOOP_HEAPSIZE_MIN=256
# hadoop 各守护进程的 pid 目录
export HADOOP_PID_DIR=/data/br/base/hadoop/data/tmp/pids
export HADOOP_SECURE_PID_DIR=${HADOOP_PID_DIR}
# 配置各组件的默认启动用户
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# 配置ssh端口
export HADOOP_SSH_OPTS=“-p 2226” |
|
4.1.2 修改 core-site.xml
fs.defaultFS
hdfs://hadoopha
ha.zookeeper.quorum
zhjiann01:2181,zhjiann02:2181,zhjiann03:2181
ha.zookeeper.session-timeout.ms
60000
hadoop.tmp.dir
file:/data/br/base/hadoop/tmp
io.compression.codecs
org.apache.hadoop.io.compress.SnappyCodec
4.1.3 修改 yarn-site.xml
yarn.application.classpath
/data/br/base/hadoop/etc/hadoop,
/data/br/base/hadoop/share/hadoop/common/*,
/data/br/base/hadoop/share/hadoop/common/lib/*,
/data/br/base/hadoop/share/hadoop/hdfs/*,
/data/br/base/hadoop/share/hadoop/hdfs/lib/*,
/data/br/base/hadoop/share/hadoop/mapreduce/*,
/data/br/base/hadoop/share/hadoop/mapreduce/lib/*,
/data/br/base/hadoop/share/hadoop/yarn/*,
/data/br/base/hadoop/share/hadoop/yarn/lib/*
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.cluster-id
yarnha
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.zk-timeout-ms
60000
yarn.resourcemanager.hostname.rm1
br-apm-001
yarn.resourcemanager.webapp.address.rm1
br-apm-001:8088
yarn.resourcemanager.hostname.rm2
br-apm-002
yarn.resourcemanager.webapp.address.rm2
br-apm-002:8088
yarn.resourcemanager.zk-address
br-apm-001:2181,br-apm-002:2181,br-apm-003:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce_shuffle.class org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.local-dirs
/data/br/base/hadoop/local/yarn/local
yarn.nodemanager.log-dirs
/data/br/base/hadoop/local/yarn/logs
yarn.nodemanager.remote-app-log-dir
hdfs://hadoopha/var/log/hadoop-yarn/apps
yarn.nodemanager.resource.memory-mb
8192
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairSchedul
er
yarn.scheduler.minimum-allocation-mb
512
yarn.scheduler.maximum-allocation-mb
8192
yarn.scheduler.maximum-allocation-vcores
8
8cores
Number of CPU cores that can be allocated for containers.
yarn.nodemanager.resource.cpu-vcores
16
yarn.nodemanager.vmem-check-enabled
false
yarn.resourcemanager.max-completed-applications
200
mapred.map.output.compress.codec
org.apache.hadoop.io.compress.SnappyCodec
mapreduce.map.output.compress
true
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
86400
yarn.log.server.url
http://br-apm-001:40024/jobhistory/logs
yarn.nodemanager.vmem-pmem-ratio
4
Ratio between virtual memory to physical memory when setting memory limits for containers
4.1.4 修改 hdfs-site.xml
dfs.namenode.name.dir
file:///data/br/base/hadoop/local/hdfs/namenode
dfs.datanode.data.dir
file:///data/br/base/hadoop/local/hdfs/datanode
dfs.replication
2
dfs.permissions.enabled
false
dfs.webhdfs.enabled
true
dfs.permissions.superusergroup
root
dfs.nameservices
hadoopha
dfs.ha.namenodes.hadoopha
nn1,nn2
dfs.namenode.rpc-address.hadoopha.nn1
br-apm-001:9000
dfs.namenode.http-address.hadoopha.nn1
br-apm-001:50070
dfs.namenode.rpc-address.hadoopha.nn2
br-apm-002:9000
dfs.namenode.http-address.hadoopha.nn2
br-apm-002:50070
dfs.ha.automatic-failover.enabled.hadoopha
true
dfs.namenode.shared.edits.dir
qjournal://br-apm-001:8485;br-apm-002:8485;br-apm-
003:8485/hadoopha
dfs.client.failover.proxy.provider.hadoopha
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
<!—发生failover时,Standby的节点要执行一系列方法把原来那个Active节点中不健康的NameNode 服务给杀掉,
这个叫做fence过程。sshfence会通过ssh远程调用fuser命令去找到Active节点的NameNode服务并杀 死它—>
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.journalnode.edits.dir
/data/br/base/hadoop/tmp/journal
dfs.qjournal.write-txns.timeout.ms
60000
4.1.5 修改 mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.application.classpath
/data/br/base/hadoop/etc/hadoop:/data/br/base/hadoop/share/hadoop/common/ lib/:/data/br/base/hadoop/share/hadoop/common/:/data/br/base/hadoop/share/hado op/hdfs:/data/br/base/hadoop/share/hadoop/hdfs/lib/:/data/br/base/hadoop/share/ hadoop/hdfs/:/data/br/base/hadoop/share/hadoop/yarn/lib/:/data/br/base/hadoop/ share/hadoop/yarn/:/data/br/base/hadoop/share/hadoop/mapreduce/lib/:/data/br/b ase/hadoop/share/hadoop/mapreduce/:/data/br/base/hadoop/contrib/capacity-
scheduler/*.jar
mapred.job.tracker
hdfs://br-apm-001:40020/
mapred.job.tracker.http.address
0.0.0.0:40021
mapred.task.tracker.http.address
0.0.0.0:40022
mapreduce.jobhistory.address
0.0.0.0:40023
mapreduce.jobhistory.webapp.address
0.0.0.0:40024
mapreduce.shuffle.port
40025
按如下命令进行启动
hadoop-daemon.sh start hdfs zkfc -formatZK
hadoop-daemon.sh start hadoop-daemon.sh start hadoop-daemon.sh start
journalnode
namenode
datanode
zkfc
yarn-daemon.sh start resoucemanager
yarn-daemon.sh start nodemanager
二、 Hadoop 数据备份与迁移
2.1 namenode 本地备份与还原
2.2 namenode 迁移
目标:
原配置
nn1 10.241.80.117
nn2 10.241.80.116
新配置
nn1 10.241.80.115
nn2 10.241.80.120
将两个 namenode迁移到其他机器,在不停机的情况下,利用hadoop的ha机制,切换namenode。
步骤:
在集群A上上传文件。

集群A上停掉 nn2 和对应的 zkfc 服务,再次向 hdfs 中传入一个文件,模拟迁移过程中数据持续写入。


将 nn2 的数据目录拷贝到新的服务器(120)上,修改所有的 hdfs-site.xml 文件,将 nn2 的相关信息 修改为 br-hadoop-003 。

dfs.namenode.rpc-address.hadoopha.nn2
br-hadoop-003:9000
dfs.namenode.http-address.hadoopha.nn2
br-hadoop-003:50070
|
|
在 br-hadoop-003 上通过 hdfs —daemon start namenode 命令启动后,查看日志,服务正常启动。
再启动 hdfs —daemon start zkfc ,保证nn2的主从切换。再重启所有的 datanode 服务。
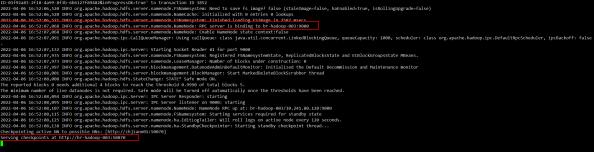
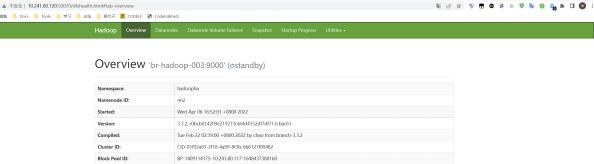
停掉NN1节点后,也可以自动切换active,且数据都在。
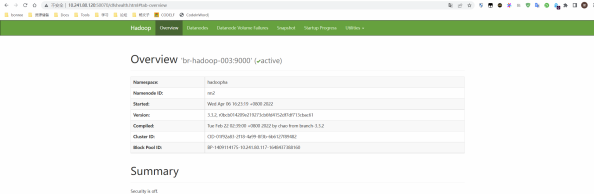
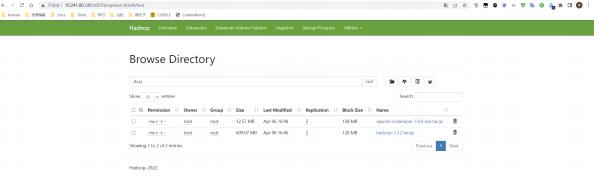
此时,如法炮制,将原先NN1的数据拷贝到115上,修改hdfs-site配置文件,将nn1的地址进行修改,分 发到集群的所有机器上。
scp -P 2226 -r /data/br/base/hadoop/local/hdfs/namenode/current
zhjiann03:/data/br/base/hadoop/local/hdfs/namenode/ |
|
dfs.namenode.rpc-address.hadoopha.nn2
zhjiann01:9000
dfs.namenode.http-address.hadoopha.nn2
zhjiann01:50070
|
|
在115上启动namenode后,服务正常,且可自动切换主从。
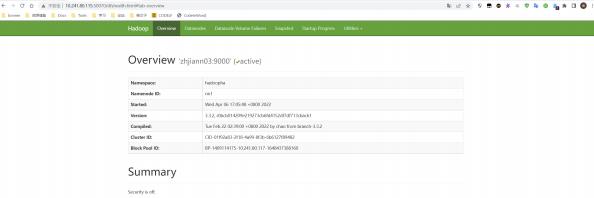
2.3 journalnode 迁移
目标:
原配置
journalnode 10.241.80.115-117
新配置
journalnode 10.241.80.120, 10.241.80.127, 10.241.80.128
步骤:
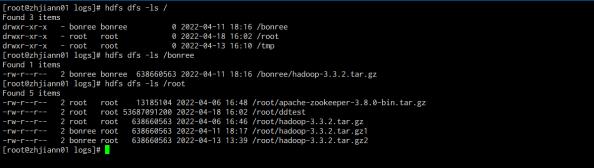
截图迁移前的集群数据信息。

通过命令 stop-dfs.sh 来停止 hdfs ,将三台 journalnode 的数据目录分别拷贝到对应的机器,并修 改 hdfs-site.xml 中 journalnode 的配置。
scp -P 2226 -r /data/br/base/hadoop/tmp/ br-hadoop-001:/data/br/base/hadoop/
scp -P 2226 -r /data/br/base/hadoop/tmp/ br-hadoop-002:/data/br/base/hadoop/
scp -P 2226 -r /data/br/base/hadoop/tmp/ br-hadoop-003:/data/br/base/hadoop/ |
|
dfs.namenode.shared.edits.dir
<!—
qjournal://zhjiann01:8485;zhjiann02:8485;zhjiann03:8485/hadoopha - ->
qjournal://br-hadoop-001:8485;br-hadoop-002:8485;br-hadoop-
003:8485/hadoopha
|
|
迁移后,通过命令 start-dfs.sh 来启动 hdfs ,观察集群数据信息。数据一致
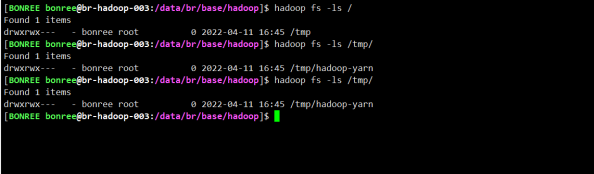
2.4 hadoop 数据迁移
数据迁移之前原有文件大小和属组。
通过自带的distcp 命令进行数据迁移
[root@zhjiann01 hadoop]# hadoop distcp
usage: distcp OPTIONS [source_path…]
OPTIONS
-append Reuse existing data in target files and
append new data to them if possible
-async Should distcp execution be blocking
-atomic Commit all changes or none
-bandwidth
-blocksperchunk
Size of the copy buffer to use. By default is 8192B.
Delete from target, files missing in
source. Delete is applicable only with update or overwrite options
Use snapshot diff report to identify the difference between source and target
Write files directly to the target
location, avoiding temporary file rename. List of files that need to be copied
(Deprecated!) Limit number of files copied to <= n
The path to a file containing a list of
strings for paths to be excluded from the copy.
Ignore failures during copy
Folder on DFS where distcp execution logs are saved
Max number of concurrent maps to use for copy
Number of threads to use for building file
listing (max 40).
Choose to overwrite target files
unconditionally, even if they exist.
preserve status (rbugpcaxt)(replication,
Specify bandwidth per map in MB, accepts bandwidth as a fraction.
If set to a positive value, fileswith more blocks than this value will be split into
chunks of blocks to be
transferred in parallel, and reassembled on the destination. By default,
is 0 and the files will be
transmitted in their entirety without
splitting. This switch is only applicable when the source file system implements
getBlockLocations method and the target file system implements concat method
-i
-log
-m
-numListstatusThreads
-overwrite
-p
-diff
-direct
-f
-filelimit
-filters
-copybuffersize
-delete
|
block-size, user, group, permission,
checksum-type, ACL, XATTR, timestamps). If
-p is specified with no , then
preserves replication, block size, user, group, permission, checksum type and
timestamps. raw. xattrs are preserved when both the source and destination paths are
in the /.reserved/raw hierarchy (HDFS
only). raw. xattrpreservation is
independent of the -p flag. Refer to the DistCp documentation for more details. |
| -rdiff |
Use target snapshot diff report to identify changes made on target |
| -sizelimit |
(Deprecated!) Limit number of files copied to <= n bytes |
| -skipcrccheck |
Whether to skip CRC checks between source and target paths. |
| -strategy |
Copy strategy to use. Default is dividing work based on file sizes |
| -tmp |
Intermediate work path to be used for atomic commit |
| -update |
Update target, copying only missing files or directories |
| -useiterator |
Use single threaded list status iterator to build the listing to save the memory
utilisation at the client |
| -v |
Log additional info (path, size) in the SKIP/COPY log |
| -xtrack |
Save information about missing source files to the specified directory |
全量拷贝数据
场景1 不带参数
| hadoop distcp hdfs://zhjiann01:9000/bonree/ hdfs:/br-hadoop-001:9000/ |
|
该情况下,迁移过后,发现有如下报错

通过增加如下参数解决
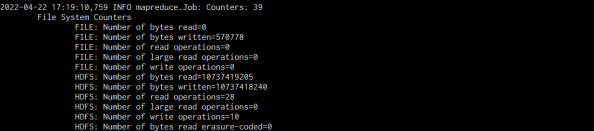
hadoop distcp -Dmapred.job.queue.name=bonree.default
hdfs://zhjiann01:9000/bonree/ hdfs://br-apm-002:9000/
迁移结束后,截图如下。可以发现数据文件属性变成了我们任务提交的用户,用户组
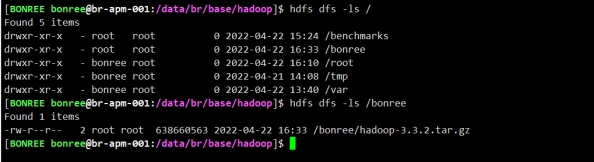
问题2 文件的属组发生变更
如果不想更改文件的用户和用户组属性,需要增加 -p 参数。
hadoop distcp -Dmapred.job.queue.name=root.default -p
hdfs://zhjiann01:9000/bonree/ hdfs://br-apm-002:9000/ |
|

结论:
-p 参数可以保留文件的属性,用户和用户组
问题3 带宽的影响
| -bandwidth Specify bandwidth per map in MB, accepts |
|
 带宽设置为 10M
带宽设置为 10M
| hadoop distcp -Dmapred.job.queue.name=root.default -p -bandwidth 10 hdfs://zhjiann01:9000/test_to_move hdfs://br-apm-002:9000/ |
|
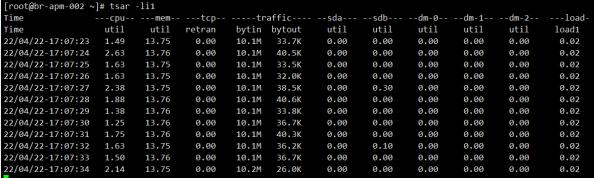
可以看到,服务器的流入流量稳定在10M多点,符合预期。整个过程的持续时间约18分钟,和预期也比 较一致。

 带宽设置为20M
带宽设置为20M
hadoop distcp -Dmapred.job.queue.name=root.default -p -bandwidth 20 hdfs://zhjiann01:9000/test_to_move hdfs://br-apm-002:9000/
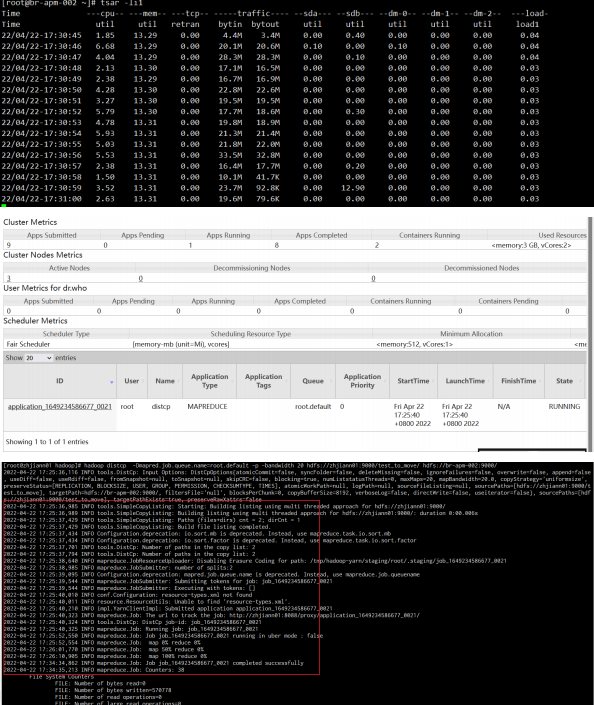
结论:
带宽和迁移速度总体成正比关系,在网络带宽允许的情况下,该参数越大,迁移的速度越快
问题4 map个数对迁移的影响
| hadoop distcp -Dmapred.job.queue.name=root.default -p -m 2 -bandwidth 10 hdfs://10.241.80.117:9000/test_to_move hdfs://10.241.80.119:9000/ |
|

虽然起了2个mapreduce进程,但是传输速度未收影响。
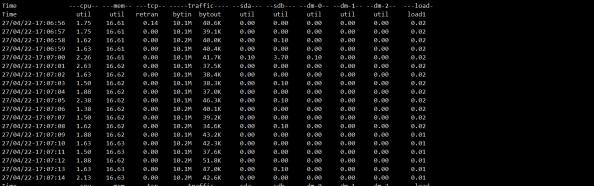
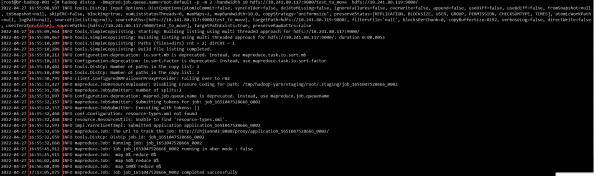
耗时约 18分钟,和单 mapreduce 的情况下基本一致。
结论:
map 的个数并未对传输的总带宽生成影响
问题5 迁移后数据的副本数
数据源集群副本

目标集群副本

client 端副本

观察迁移后的数据,发现只有一个副本。
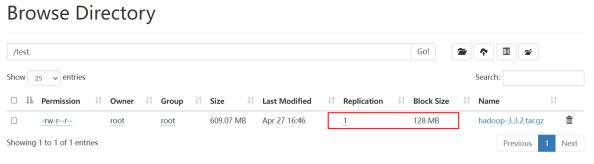
结论:
迁移后数据的副本数由client端控制
问题5 参数 -append
先通过命令,进行数据的部分传输,通过日志,可以发现默认的append参数是为 false
hadoop distcp -Dmapred.job.queue.name=bonree.default -p
hdfs://10.241.80.117:9000/test_to_move hdfs://10.241.80.119:9000/
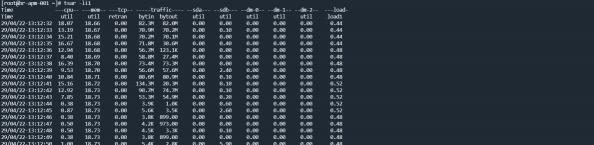

传输完成后,通过脚本,向该文件中追加部分数据后,重新传入hdfs中。
#!/bin/bash
for (( i=1; i<=512; i++ ))
do
# echo ‘this is file for test’ >> test_1k
# cat data_2m >> data_1g
echo ‘this is hello world’ >> data_1g
done |
|
增加 append 参数,进行二次传输,失败。
hadoop distcp -Dmapred.job.queue.name=bonree.default -p -append
hdfs://10.241.80.117:9000/test_to_move hdfs://10.241.80.119:9000/

经过查询,需要配合 update 参数一起使用。
对具体文件进行追加传输,命令如下
hadoop distcp -Dmapred.job.queue.name=bonree.default -update -append -p hdfs://10.241.80.117:9000/test_to_move/data_1g
hdfs://10.241.80.119:9000/test_to_move/data_1g |
|
通过日志,得知append参数已生效,但是还是进行了全量拷贝


变更为目录拷贝后,生效。
hadoop distcp -Dmapred.job.queue.name=bonree.default -update -append -p
hdfs://10.241.80.117:9000/test_to_move hdfs://10.241.80.119:9000/test_to_move |
|


2.5 hadoop 数据恢复
数据备份通过 distcp 命令,向新的 hadoop 集群(集群2)中进行拷贝。
数据恢复通过 distcp 命令,从集群2中向原有集群拷贝。

