- 1.3.1KNN实战之随机数据
- 导入常用库
- X为样本特征,Y为样本类别输出, 共1000个样本,每个样本2个特征,输出有3个类别,没有冗余特征,每个类别一个簇
- 这里导入最近邻对象,并简化分类器函数为clf
- 后面都可以通过clf.fit调用KNN分类器,使用fit进行拟合
- 确认训练集的边界
- 生成随机数据来做测试集,然后作预测
- #np.c是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等#np.c是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等; np.r是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等np.r是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等
- 画出测试集数据
- 也画出所有的训练集数据
1.3.1KNN实战之随机数据
构造随机数据
导入常用库
import numpy as np import matplotlib.pyplot as plt %matplotlib inline # 使得调用plot()进行画图或者直接输入Figure的实例对象的时候,会自动的显示并把figure嵌入到console中,即不加plt.show()也可以显示图片
from sklearn.datasets.samples_generator import make_classificationX为样本特征,Y为样本类别输出, 共1000个样本,每个样本2个特征,输出有3个类别,没有冗余特征,每个类别一个簇
X, Y = makeclassification(_n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, n_classes=3) plt.scatter(X[:, 0], X[:, 1], marker=’o’, c=Y) #plt.scatter参数:s:shape, c:color, marker:markerstyle, norm: normalize, vmin, vmax, alpha, linewidths plt.show()
这里我们通过sklearn的samples_generator创建了1000个样本的随机数,Y为这些样本的特征,为0,1, 2。并用散点图表示出来,可以很清楚的看到数据根据样本特征分为三类。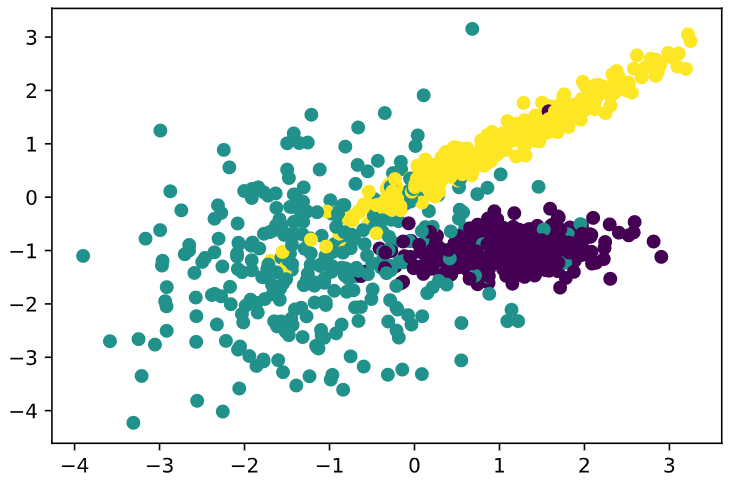
KNN分类器参数的解释
from sklearn import neighbors
这里导入最近邻对象,并简化分类器函数为clf
clf = neighbors.KNeighborsClassifier(n_neighbors = 15 , weights=’distance’)
后面都可以通过clf.fit调用KNN分类器,使用fit进行拟合
clf.fit(X, Y)
相关参数的说明:neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30, p=2, metric=’minkowski’, metric_params=None, n-jobs=1)
- n_neighbors 就是 kNN 里的 k,就是在做分类时,我们选取问题点最近的多少个最近邻;
- weights 是在进行分类判断时给最近邻附上的加权,默认的 ‘uniform’ 是等权加权,还有 ‘distance’ 选项是按照距离的倒数进行加权,也可以自定义加权方法;
- algorithm 是分类时采取的算法,有 ‘brute(蛮力)’、’kd_tree’ 和 ‘ball_tree’,’auto’自动选择三种中的一种算法;
- leaf_size 是 kd_tree 或 ball_tree 生成的树的树叶(树叶就是二叉树中没有分枝的节点)的大小;
- metric 和 p,是距离函数的选项,一般来讲,默认的 metric=’minkowski’(默认)和 p=2(默认)就可以满足大部分需求;
- metric_params 是一些特殊 metric 选项需要的特定参数,默认是 None;
n_jobs 是并行计算的线程数量,默认是 1,输入 -1 则设为 CPU 的内核数;
输入数据的要求
X 是一个 list 或 array 的数据,每一组数据可以是 tuple 也可以是 list 或者一维 array,但要注意所有数据的长度必须一样(等同于特征的数量)。当然,也可以把 X 理解为一个矩阵,其中每一横行是一个样本的特征数据。
- y 是一个和 X 长度相同的 list 或 array,其中每个元素是 X 中相对应的数据的分类标签。
使用模型预测
from matplotlib.colors import ListedColormap # plt.get_cmap(‘Spectral’)得到一系列的颜色值
cmap_light = ListedColormap([‘#FFAAAA’, ‘#AAFFAA’, ‘#AAAAFF’])
cmap_bold = ListedColormap([‘#FF0000’, ‘#00FF00’, ‘#0000FF’])
确认训练集的边界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
print(x_min,x_max)
生成随机数据来做测试集,然后作预测
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), # meshgrid函数用两个坐标轴上的点在平面上画网格
np.arange(y_min, y_max, 0.02))Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # ravel将多维数组转换为一维数组
#np.c是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等#np.c是按行连接两个矩阵,就是把两矩阵左右相加,要求行数相等; np.r是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等np.r是按列连接两个矩阵,就是把两矩阵上下相加,要求列数相等
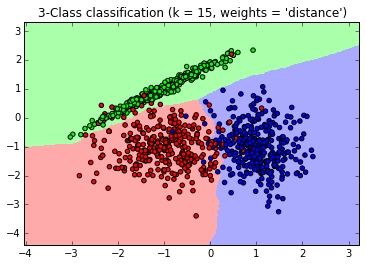
画出测试集数据
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
也画出所有的训练集数据
plt.scatter(X[:, 0], X[:, 1], c=Y, cmap=cmap_bold)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title(“3-Class classification (k = 15, weights = ‘distance’)” )
plt.show()
参考:

若有收获,就点个赞吧
0 人点赞
