k近邻法(k-nearest neighbor, k-NN)字面意思就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻居来代表。其核心思想是如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。K指的是通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。用一张图来解释: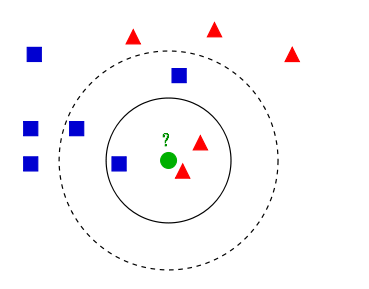
图中有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
这里面有两个重要的问题需要解决:1.K值怎么选择?2.点到点的距离怎么计算,即如何来判断最近邻?下面我们分别来看下这两个方面。
1.K值怎么选择?
**
首先如果我们选取较小的k值,那么就会意味着我们的整体模型会变得复杂,容易发生过拟合!如果我们选取较大的k值,我们的模型又会变得简单,预测也容易出错,真的好难!
比如K=1时,我们能够看出来五边形离黑色的圆点最近,k又等于1,我们最终判定待分类点是黑色的圆点。实际上我们可以看出这个是噪音点。
如果k等于8,把长方形都包括进来,我们很容易得到我们正确的分类应该是蓝色的长方形!如下图:
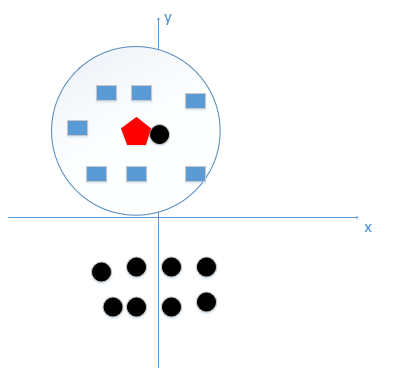
所谓的过拟合就是在训练集上准确率非常高,而在测试集上准确率低,经过上例,我们可以看到k太小会导致过拟合,很容易将一些噪声(如上图离五边形很近的黑色圆点)学习到模型中,而忽略了数据真实的分布!
如果我们选取较大的k值,就相当于用较大邻域中的训练数据进行预测,这时与输入实例较远的(不相似)训练实例也会对预测起作用,使预测发生错误,k值的增大意味着整体模型变得简单。
一个极端情况是,如果k=N(N为训练样本的个数),那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类。这时,模型是不是非常简单,这相当于你压根就没有训练模型呀!直接拿训练数据统计了一下各个数据的类别,找最大的而已!如下图所示:
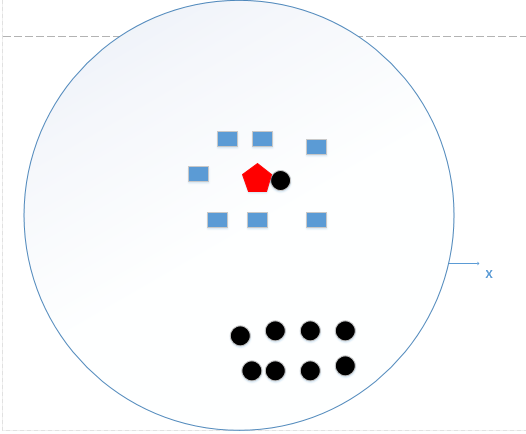
可以统计出黑色圆形是8个,长方形个数是7个,如果k=N,就可以得出结论,红色五边形是属于黑色圆形的(明显是错误的!)
这个时候,模型过于简单,完全忽略训练数据实例中的大量有用信息,是不可取的。
可以看到k值既不能过大,也不能过小,在这个例子中,我们k值的选择,在下图红色圆边界之间这个范围是最好的,如下图(真实例子中不可能只有二维特征,但是原理是一样的,我们就是想找到较好的k值大小):
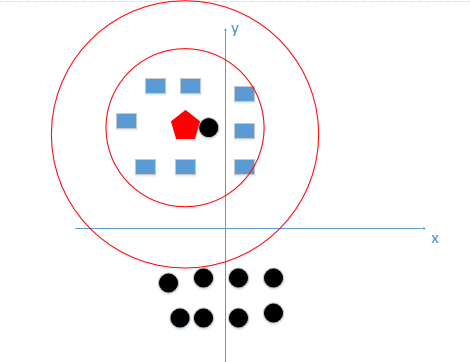
那么K值一般怎么选取呢?一般选取一个较小的数值,通常采取交叉验证法来选取最优的k值。(也就是说,选取k值很重要的关键是实验调参,类似于神经网络选取多少层这种,通过调整超参数来得到一个较好的结果)。
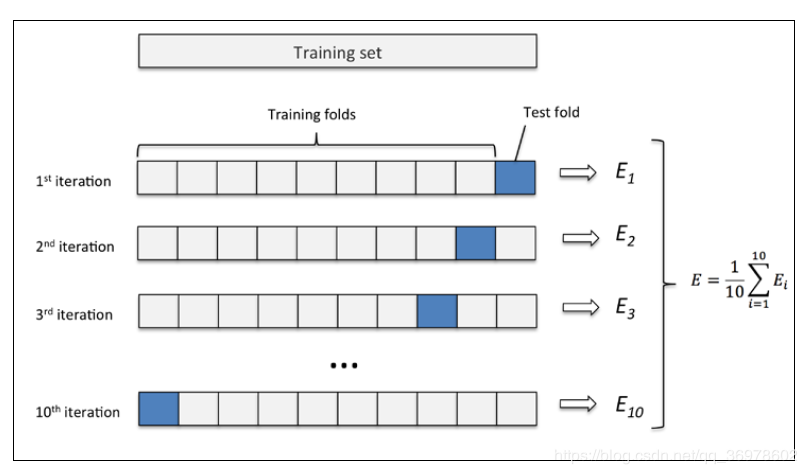
所谓K折交叉验证(K-fold cross validation),其过程如下:
(1) 将全部训练集S分成K个不相交的子集,假设S中的训练样例个数为m,那么每一个子集有m/k个训练样例。
(2) 每次从分好的子集中,选出一个作为测试集,另外k-1个作为训练集。
(3) 根据训练集得到模型。
(4) 根据模型对测试集进行测试,得到分类率。
(5) 计算k次求得的分类率的平均值,作为模型的最终分类率。
2.如何来判断最近邻?
k-近邻算法步骤如下:
- 计算已知类别数据集中的点与当前点之间的距离;
- 按照距离递增次序排序;
- 选取与当前点距离最小的k个点(k 一般小于等于 20 );
- 确定前k个点所在类别的出现频率;
- 返回前k个点所出现频率最高的类别作为当前点的预测分类。
用一句话解释这个过程就是:
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的 k 个实例,这 k 个实例的多数属于某个类,就把该输入实例分为这个类。
那么最邻近是如何度量呢?我们怎么知道谁跟测试点最邻近呢?
度量俩个点之间距离最常用的方法当然是我们高中学过的欧氏距离Euclidean Distance法啦!大家还记得公式怎么写的吗?
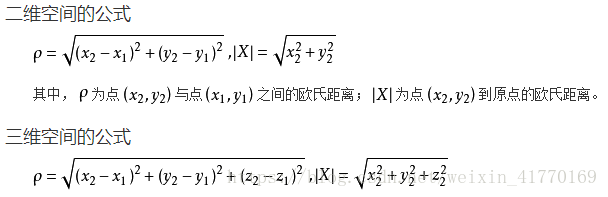
其他还有:
曼哈顿距离,就是把√——拿掉啦:L1(xi,xj)=∑nl=1|x(l)i−x(l)j|
Mahalanobis距离(马氏距离):

可以看出,马氏距离与欧氏距离的差别是马氏距离加入了一个协方差,用于表征客观上的偏差;就好像是有了人类的感情倾向,使得模式识别更加“人性化”也更加“视觉直观”。
另外要注意的一点是在计算距离度量之前,我们需要对特征进行归一化。
举个栗子,假设有5个人的身高(cm)与脚码(尺码)大小的数据来作为特征值,类别为男性或者女性:
A [(179,42),男], B [(178,43),男], C [(165,36)女], D [(177,42),男], E [(160,35),女]
然后我们有一个测试样本 F(167,43),用来预测他是男性还是女性,采取k=3来预测。
下面我们用欧式距离分别算出F离训练样本的欧式距离,然后选取最近的3个,多数类别就是我们最终的结果,计算如下: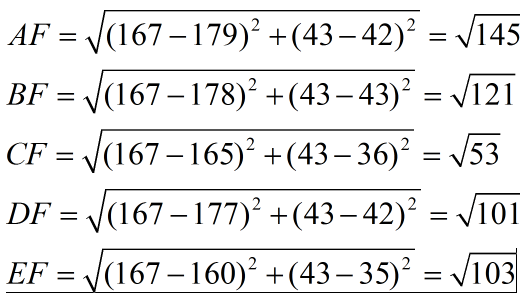
由计算可以得到,最近的前三个分别是C,D,E三个样本,那么由C,E为女性,D为男性,女性多于男性得到我们要预测的结果为女性。
这样问题就来了,一个女性的脚43码的可能性,远远小于男性脚43码的可能性,那么为什么算法还是会预测F为女性呢?那是因为由于各个特征量纲的不同,在这里导致了身高的重要性已经远远大于脚码了,这是不客观的。所以我们应该让每个特征都是同等重要的!这也是我们要归一化的原因!
归一化方式一:最值归一化
**
把所有的数据映射到0~1之间
适用于有明显的边界,受outlier极端值影响较大,比如收入的分布
#归一化方式二:均值-方差归一化
把所有数据归一到均值为0方差为1的分布中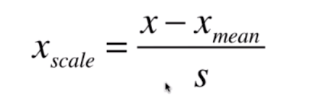
总结一下KNN的核心思想:
1.k近邻算法,即是来了一个新的输入实例,我们算出该实例与每一个训练点的距离,然后找到前k个,这k个哪个类别数最多,我们就判断新的输入实例就是哪类!
2.与该实例最近邻的k个实例,这个最近邻的定义是通过不同距离函数来定义,我们最常用的是欧式距离**。
3.为了保证每个特征同等重要性,我们这里对每个特征进行归一化。
4.k值的选取,既不能太大,也不能太小,何值为最好,需要实验调整参数确定!
参考:1. 算法(八):图解KNN算法

若有收获,就点个赞吧
0 人点赞
