关于GBDT及XGBoost详细理解
1、先理解树
对于一颗决策树(回归树),要确定的是树的结构(分割点),叶节点及叶节点的参数
上诉右图中,height为叶节点的参数,竖线代表分割点,点代表实际样本;
2、GBDT
1)GBDT是CART tree的集合,基分类器是CART Tree;
在这里拟合残差这个说法比较狭隘,不具备一般性,准确来说应该描述成拟合梯度;推导如下:
2)GBDT提升过程:
3)GBDT跟adaboost异同:
同:表达式是相同的,都是boosting思想;
异:adaboost每个决策树是独立的,即每个决策树的损失函数、优化目标是独立的,变的是样本的权重及该决策树的比重;GBDT的决策树不是独立的,拟合的前面的梯度。
3、XGBoost
XGBoost 思想是跟GBDT一样,只是在实现上进行了改进;
具体如下:
1)目标函数
XGboost不仅仅是实现回归任务,还可以实现分类任务,关键看损失函数怎么去定义;
目标函数=损失函数(模型拟合训练集的能力)+正则项(模型的复杂度,模型越sample,方差越小,越不可能过拟合)
2)我们要得到什么?
我们要得到的是 ,表现为树结构(分割节点)、叶节点参数这些;因此我们是要得到分割节点+叶节点参数;
,表现为树结构(分割节点)、叶节点参数这些;因此我们是要得到分割节点+叶节点参数;
3)我们怎么得到?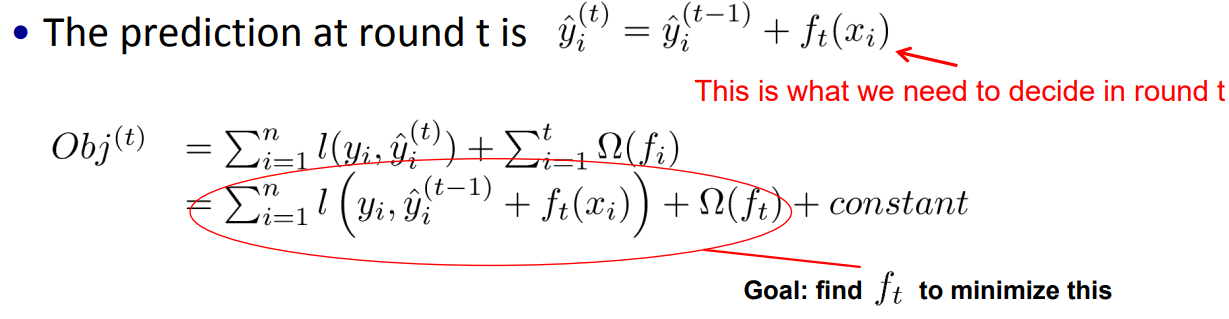
我们的目标是得到一个只关于 的函数,因此要对上诉式子进行变形(泰勒展开);
的函数,因此要对上诉式子进行变形(泰勒展开);

 、
、 是已知的,所以现在具体表示出
是已知的,所以现在具体表示出 ;
;
其中,q代表第几个叶节点,w代表叶节点的参数;
正则项表示为叶节点的数目及叶节点的参数;
将目标函数变成与叶节点相关的函数:
即可得: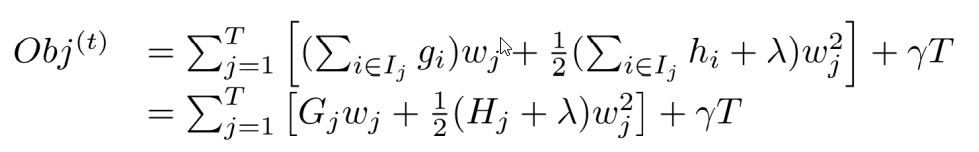
求得最优解:
4)怎么利用最优解去构建树?
在3)中我们可以知道一个树结构怎么去求取最优解,但是一棵树的构建有很多种树结构,怎么去构建树结构呢?
xgboost采用增益作为指标!!!
即求出原节点的最优目标函数值—(左节点最优目标函数值+右节点最优目标函数值)作为gain
4、XGBoost跟GBDT区别(非常重要!!!)
1)xgboost的基分类器既可以是CART Tree,也可以是LR,可以实现分类、回归任务,主要看目标函数怎么设计;
2)xgboost目标函数是泰勒展开到二阶导,而GBDT是一阶,二阶相比一阶优化速度更快,更容易得到最优解,一阶是反映梯度变化大小,二阶反映梯度变化大小的快慢;
3)xgboost加了正则项,将叶节点的个数及参数作为模型复杂度的评判指标;
4)列采样,即随机森林的思想,构建树的时候只使用一部分特征;
5)对缺失值不敏感,能够自动学习出缺失值默认分支;
6)并行化,这个并行化不是构建树之间的并行化,而是对树结构划分最优分割点的时候的并行化;
5、关于并行化说明
在得到最佳分割节点时候,
1)for(所有特征):
2)对每个特征的特征值sort,因为每个特征计算最佳分割点时,都要计算多次,这样可以直接将sort好的特征存在block,不用重新计算、导入内存,方便重复使用;
3)对每个特征计算最佳分割点(gain最大时),可以并行化计算,加快速度。
注:假设特征维度为k,如果使用遍历,要遍历k次,为了进一步加快,可以采取一些方法比如设置步长为2等。
6、怎么防止过拟合
- 目标函数中增加了正则项:使用叶子结点的数目和叶子结点权重的
模的平方,控制树的复杂度。
- 设置目标函数的增益阈值:如果分裂后目标函数的增益小于该阈值,则不分裂。
- 设置最小样本权重和的阈值:当引入一次分裂后,重新计算新生成的左、右两个叶子结点的样本权重和。如果任一个叶子结点的样本权重低于某一个阈值(最小样本权重和),也会放弃此次分裂。
- 设置树的最大深度:
先从顶到底建立树直到最大深度,再从底到顶反向检查是否有不满足分裂条件的结点,进行剪枝。
- shrinkage: 可以叫学习率或步长,为了给后面的训练留出更多的学习空间
- 子采样:每轮计算可以不使用全部样本,使算法更加保守
- 列抽样:训练的时候只用一部分特征(不考虑剩余的block块即可)

若有收获,就点个赞吧
0 人点赞
