1、分类跟回归常见的损失函数?(别以为你看懂了就懂了!!!手写能写出来吗?)
交叉熵损失函数




均方差损失函数
损失函数:

对损失函数求导可得:

由于激活函数的原因,对激活函数的求导近乎等于0,因此梯度更新很慢甚至不更新。
KL散度(KL散度不是损失函数,但是我经常将它与交叉熵损失函数弄混,放一起吧)

KL散度近似理解为信息熵减去交叉熵,衡量两个数据分布差异的情况,KL散度越小,数据分布越接近。
2、关于LR回归的详细理解
1、LR回归是一个分类模型,不是一个回归模型;LR回归模型是参数模型,即数据分布为logistic分布,logistic分布可近似成sigmoid分布;
2、由于是参数模型,所以是要最大似然估计;最大似然估计的最大化等价于损失函数的最小化,因此损失函数是采用交叉熵损失函数;

3、LR回归相当于在一个线性分类(可近似成感知器)上面加了一个sigmoid函数;LR回归先求出一个分类决策面,再将分类决策面与分类概率结合起来,从而得到分类概率;
4、LR优点:
1)LR是假设数据是符合logistic分布的,直接对模型进行参数估计即可;
2)LR回归的损失函数是一个凸函数,任意阶可导,可以求出最优解;
3)不仅能得到分类类别,还能得到概率。
5、一些额外的知识补充。为什么LR回归时连续特征要离散化?
1)离散化特征维度变低,计算量变小,模型收敛更快;
2)离散化特征可以引入鲁棒性,防止模型过拟合;
3)离散化特征引入了非线性,可以进行特征组合;
4)离散化特征让模型更稳定。
3、关于SVM的详细理解
感知器:只需要分类误差最小,分类超平面有无数个解;
支持向量机SVM:分类正确的情况下要使得间隔最大,即对于每个样本足够大的确信度;
线性可分支持向量机(硬间隔)
1)点到超平面距离(间隔)可以理解为:
其中前一项是表示分类的正确性,后一项表示确信度。
2)因此问题可以转化为:
其中 代表到超平面最近的点的距离;
代表到超平面最近的点的距离;
3)由于 值大小不影响最优化问题,因此
值大小不影响最优化问题,因此 取1,得到优化问题为:
取1,得到优化问题为:
4)直接对上述优化问题求解复杂,因此通过拉格朗日对偶性将问题转化成对偶问题: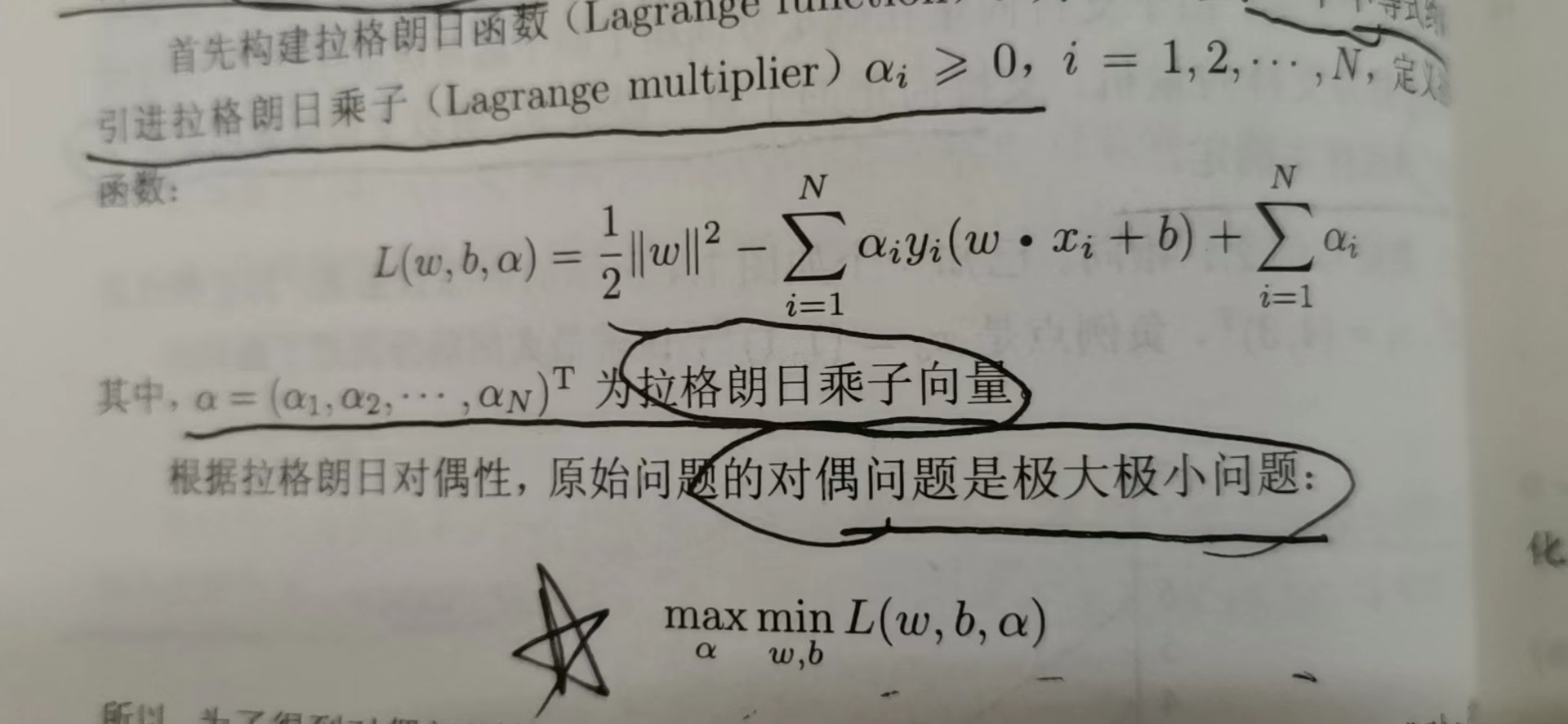
5)对于极小问题,对w、b分别求偏导得: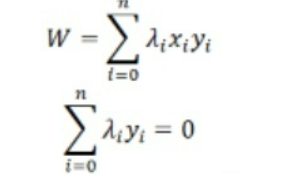

6)将上诉求的式子带回去求极大值问题得到对偶问题:
线性近似可分支持向量机(软间隔)
1)对于不满足间隔大于1的点,引入松弛变量,因此优化问题变成:
其中C代表惩罚系数,C越大,对分类错误的惩罚越大。
2)引入拉格朗日算子,得:
3)对极小问题求偏导,得: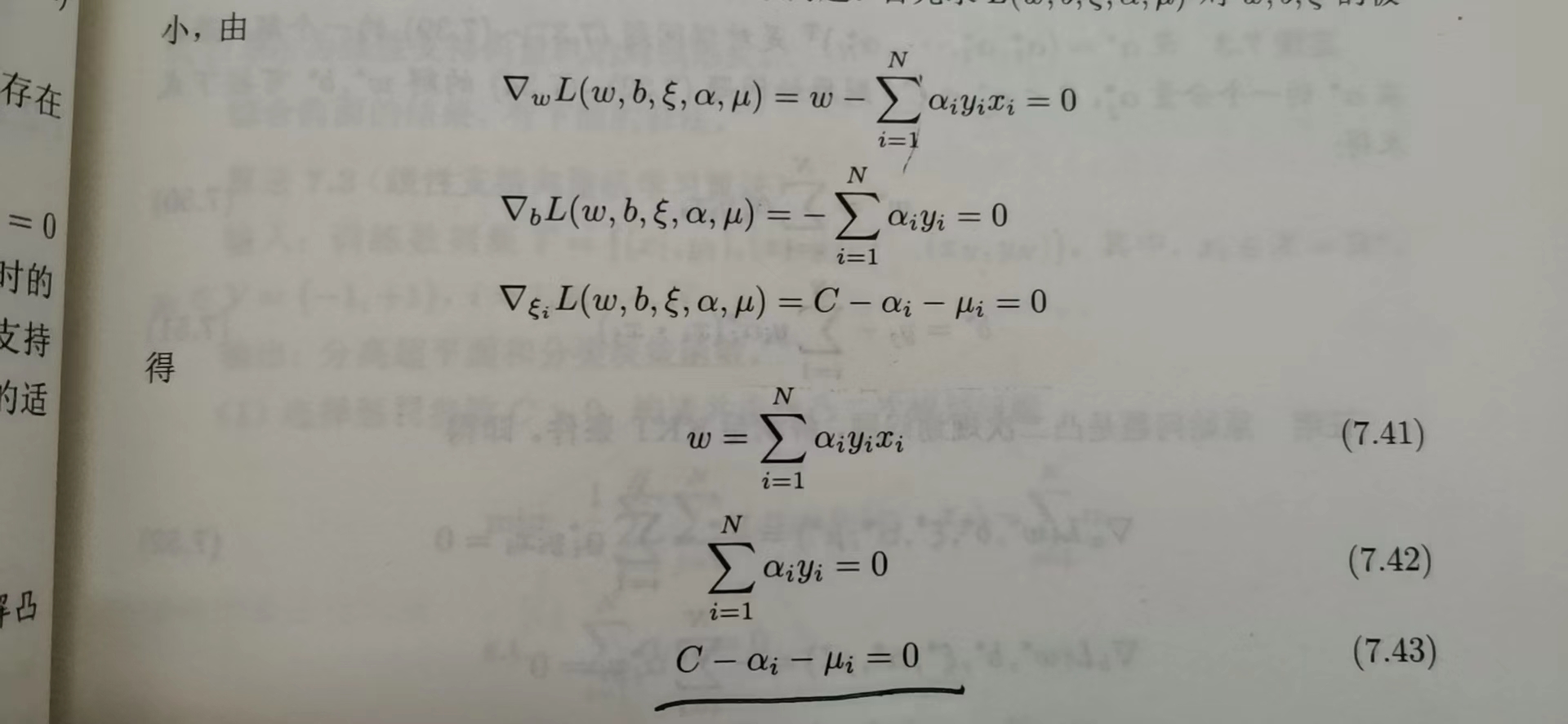
4)得到对偶问题(极大值问题):
!!!可以发现软间隔只是在硬间隔基础上加多一个限制条件!!!
凸二次规划求解算法——SMO算法
上诉转化成为对偶问题后,需要求 的最优解。直接求解非常复杂;
的最优解。直接求解非常复杂;
SMO算法原理:只要变量满足KKT条件,则是最优解(充分必要条件)
因此,上诉凸二次优化问题可以转化成子问题的优化,转化成多个两个变量的二次优化问题(其他变量保持不变)
核函数
对于线性不可分的情况,需要做一个投影,将向量投影到高维空间,做软间隔支持向量机
由于 投影到高维空间是
投影到高维空间是 ,如果直接根据投影函数来求取投影后向量,再求内积,计算量很大,因此引入核函数直接表示投影后的关系;
,如果直接根据投影函数来求取投影后向量,再求内积,计算量很大,因此引入核函数直接表示投影后的关系;
核函数类型:线性核、高斯核、多项式核
核函数的选用问题:
1、feature维度比较大、样本数目比较多,选用线性核,因为高斯核计算量大;
2、feature维度比较小,样本数目没那么大,先用高斯核;

若有收获,就点个赞吧
0 人点赞
