1.写入原理
mysql对于一个基于硬盘读取的关系型数据库,与其他硬盘数据库例如MongoDB、ElasticSearch一样,写入过程可以大致分为两步
以下写入过程都是基于InnoDB引擎来说的
存储位置
在了解写入过程之前,先了解下写过过程涉及到的存储位置
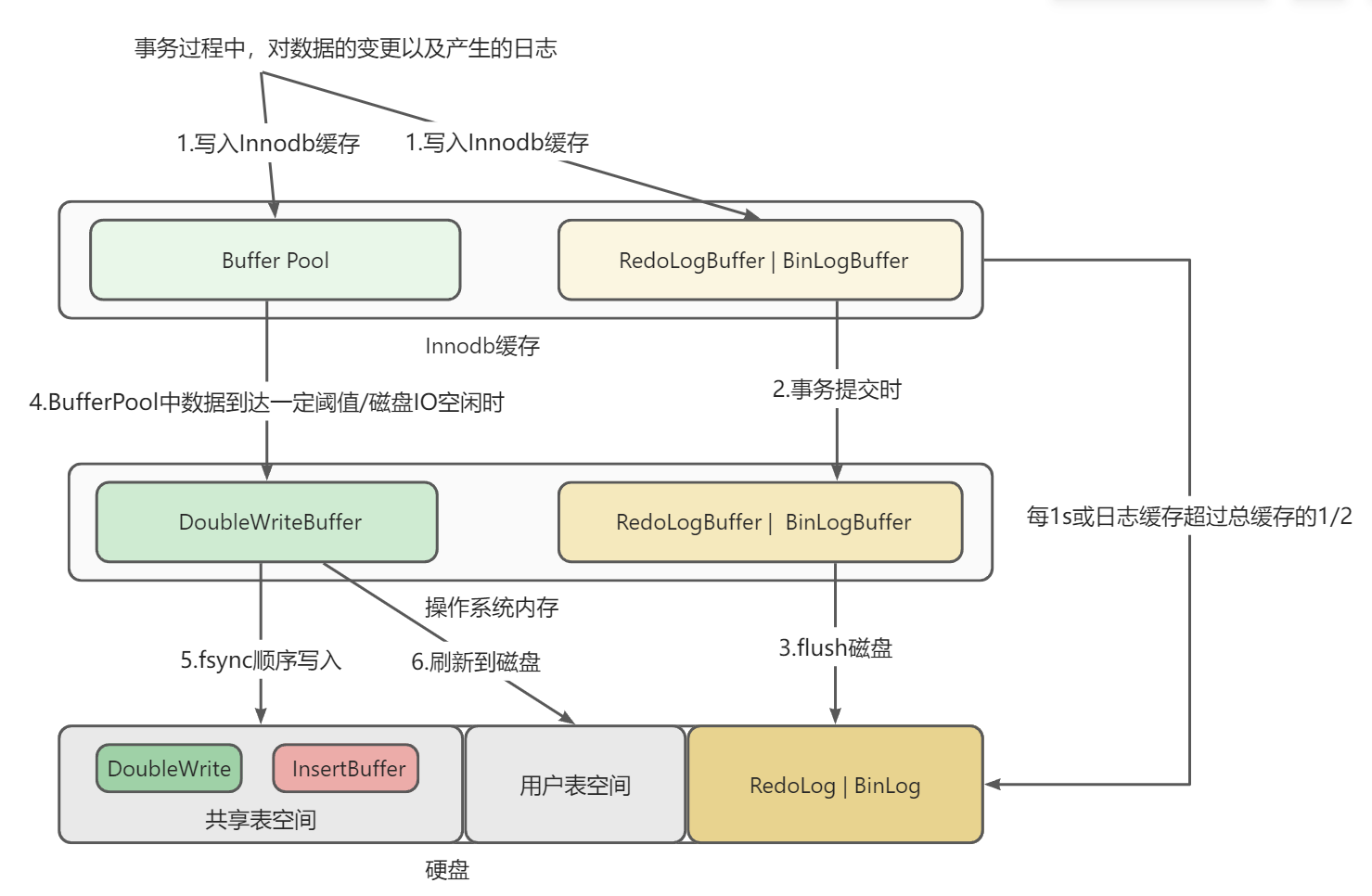
- InnoDB缓存:数据在进行写入时,任何的变更以及日志的记录都会先记录到InnoDB缓存中。其中包括BufferPool,redoLogBuffer、binLogBuffer等区域
- 操作系统内存:相当于磁盘和InnoDB缓存的中间区域。其中包括DoubleWriteBuffer以及InsertBuffer等区域
磁盘:最终数据存储的区域。大致可分为两大部分:共享表空间以及系统表|用户表空间。共享表空间包括DoubleWrite区域、系统表|用户表空间包括具体的数据文件
RedoLog
日志格式
redolog并不是一个单纯的物理日志,而是物理+逻辑日志。也就是说,没有办法只根据redolog进行数据的容灾恢复
因为innodb引擎是基于数据页进行数据的变更,因此redolog日志记录的是当前数据页的偏移量对应的修改内容。每条redo记录由“表空间号+数据页号+偏移量+修改数据长度+具体修改的数据”组成
也就是说,一旦数据页发生了页断裂的情况,redolog日志将无法进行数据的恢复。这也是为什么会存在double write的原因刷盘策略
作为InnoDB引擎中的数据容灾日志,redolog的写入通过innodb_flush_log_at_trx_commit来控制,包括以下三种策略
innodb_flush_log_at_trx_commit=0:每次事务提交时,将日志写入innodb缓存,后续刷新到磁盘。这种策略写入性能高,但会造成数据的丢失
- innodb_flush_log_at_trx_commit=1:每次事务提交时,直接将日志刷新到硬盘。这种策略写入性能略低,但是数据安全性很高,理论上不会造成数据的丢失
innodb_flush_log_at_trx_commit=2:每次事务提交时,将日志写入操作系统内存,后续刷新到磁盘。这种策略写入性能居中,Mysql宕机不会造成数据丢失,但是如果服务器宕机或者断电等操作,会造成数据的丢失
后台刷盘策略
后台线程每秒1次将redolog日志写入操作系统内存,并调用fsync刷新到磁盘
当redo log buffer占用的空间即将达到innodb_log_buffer_size一半的时候,后台线程将redolog日志写入操作系统内存,并调用fsync刷新到磁盘
写入过程
内存写入
首先,在写入到server层之前,对于插入语句会进行相应的校验和检查
- 将数据变更写入缓存。InnoDB引擎会将磁盘数据页缓存在内存(BufferPool)当中,对数据存在变更时,会优先在内存(BufferPool)中对数据基于页进行修改
- 假定当前redolog策略为1,在事务过程中产生的redolog日志,在事务提交时刷新到硬盘
- 如果为主从复制服务集群,那么同样将写入数据写入到binlog日志,在事务提交时刷新到硬盘
经过上述步骤,数据的变更已经写入到了内存当中,并且相对应的容灾日志也已经写入到了硬盘当中。但是毕竟内存空间是有限的,而且Mysql是一个基于硬盘进行读写的关系型数据库,因此,就需要第二步,将数据刷新到磁盘
刷新到磁盘
页断裂
首先需要先了解下页断裂的概念。众所周知,Innodb引擎是基于页进行数据的读写。但是对于硬盘和innodb引擎,页的大小是不一样的。
innodb引擎数据页大小为16kb,而硬盘数据页的大小为4kb甚至更小,因此当缓存数据刷新到硬盘时,
可能会发生写入了4kb的数据后服务器宕机,因此再次重启后硬盘数据页的数据就是不完整的数据。这种现象称为页断裂
DoubleWrite
为了解决页断裂的情况,innodb引擎引入了double write策略。在硬盘的共享表空间中,开辟了一块连续的存储空间,大小为128页,每个页大小16kb,分为两个区,总大小为2M。因为是连续的存储空间,因此对于该空间的写入为顺序写。这片空间,即为double write空间。
innodb内存数据在刷新到磁盘之前,会先写入到double write操作系统内存空间,然后再顺序写入到double write空间内,最后再刷新到磁盘。这样即使发生了页断裂的情况,也可以根据double write的页内容进行页的修复,然后再根据redolog进行数据的恢复
过程
- 当BufferPool中的数据达到一定的数据量,或当前数据库IO处于空闲状态时,就会触发数据的刷盘操作
- buffer pool中的数据会先被写入到位于操作系统内存的DoubleWriteBuffer中
- 然后将DoubleWriteBuffer中的数据顺序写入到位于磁盘共享表空间的DoubleWrite区域中
- 之后调用fsync,再将DoubleWriteBuffer中的数据写入到用户表空间的具体数据文件中
写入之后清空redolog,binlog,因为此时数据已经写入到了磁盘,无需再通过日志进行数据容灾恢复
图示
2.读取原理
图示
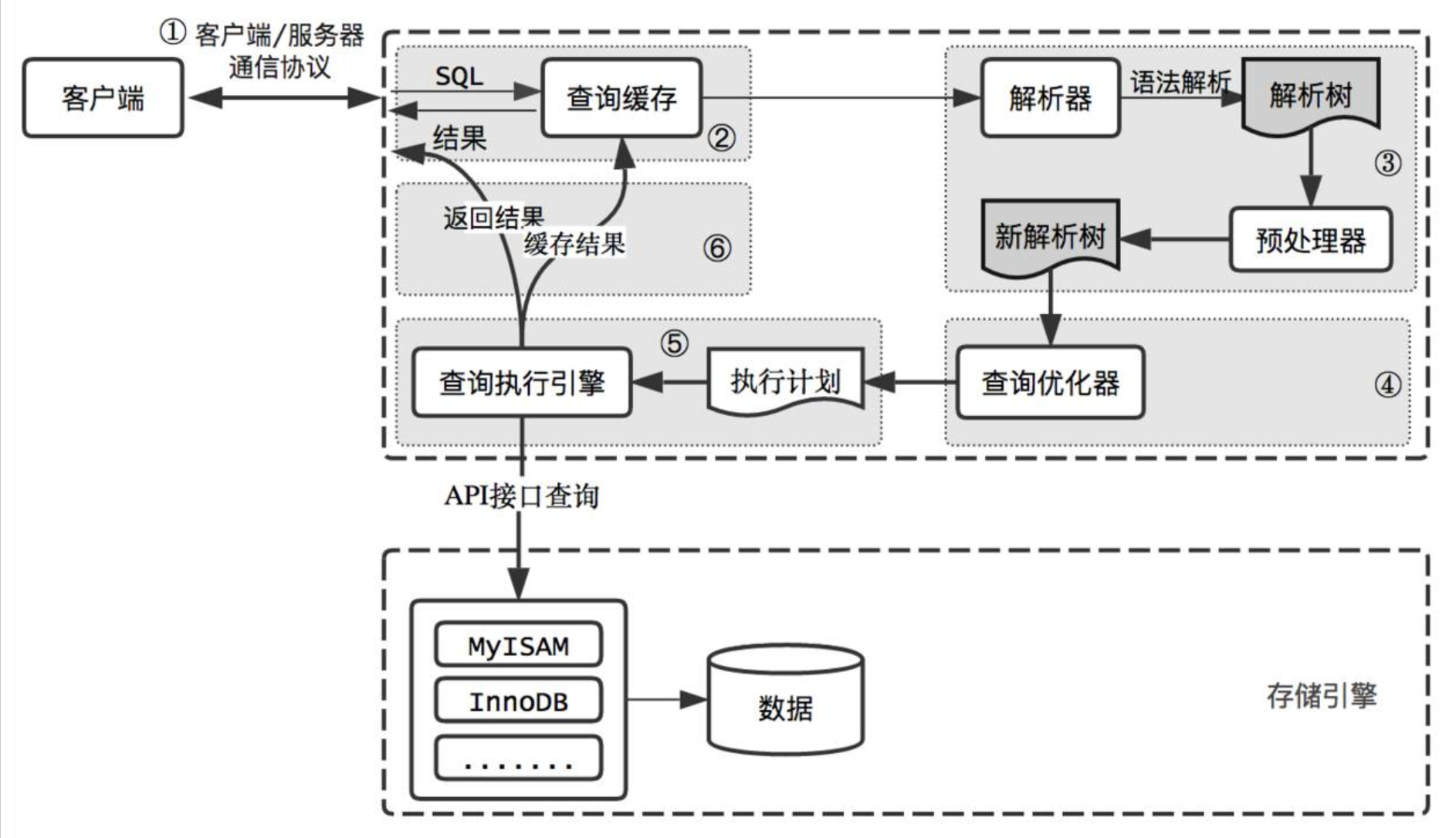
大致步骤:客户端向MySQL服务器发送一条查询请求
- 服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段
- 服务器通过解析器进行SQL校验、SQL解析、预处理
- 服务器通过查询优化器生成查询语句的最优执行计划
- 服务器根据执行计划,调用存储引擎的API来执行查询
- 存储引擎将数据从磁盘读取到内存中,在从内存中找到对应的数据
-
通信协议
MySQL客户端/服务端通信协议是“半双工”的。在任一时刻,要么是服务器向客户端发送数据,要么是客户端向服务器发送数据,这两个动作不能同时发生。一旦一端开始发送消息,另一端要接收完整个消息才能响应,所以无法将一个消息切成小块独立发送,也没有办法进行流量控制。
客户端用一个单独的数据包将查询请求发送给服务器,所以当查询语句很长的时候,需要设置max_allowed_packet参数。但是需要注意的是,如果查询实在是太大,服务端会拒绝接收更多数据并抛出异常。
与之相反的是,服务器响应给用户的数据通常会很多,由多个数据包组成。但是当服务器响应客户端请求时,客户端必须完整的接收整个返回结果,而不能简单的只取前面几条结果,然后让服务器停止发送。因而在实际开发中,尽量保持查询简单且只返回必需的数据,减小通信间数据包的大小和数量是一个非常好的习惯,这也是查询中尽量避免使用SELECT *以及加上LIMIT限制的原因之一。
查询缓存
在解析一个查询语句前,如果查询缓存是打开的,那么MySQL会检查这个查询语句是否命中查询缓存中的数据。如果当前查询恰好命中查询缓存,在检查一次用户权限后直接返回缓存中的结果。这种情况下,查询不会被解析,也不会生成执行计划,更不会执行。
MySQL将缓存存放在一个引用表(可以认为是类似于HashMap的数据结构),通过一个哈希值索引,这个哈希值通过查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同(例如:空格、注释),都会导致缓存不会命中。
如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL库中的系统表,其查询结果都不会被缓存。比如函数NOW()或者CURRENT_DATE()会因为不同的查询时间,返回不同的查询结果,再比如包含CURRENT_USER或者CONNECION_ID()的查询语句会因为不同的用户而返回不同的结果,将这样的查询结果缓存起来没有任何的意义。
既然是缓存,就会失效,那查询缓存何时失效呢?MySQL的查询缓存系统会跟踪查询中涉及的每个表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。正因为如此,在任何的写操作时,MySQL必须将对应表的所有缓存都设置为失效。如果查询缓存非常大或者碎片很多,这个操作就可能带来很大的系统消耗,甚至导致系统僵死一会儿。而且查询缓存对系统的额外消耗也不仅仅在写操作,读操作也不例外:任何的查询语句在开始之前都必须经过检查,即使这条SQL语句永远不会命中缓存
- 如果查询结果可以被缓存,那么执行完成后,会将结果存入缓存,也会带来额外的系统消耗
通常来说,不建议开启Mysql缓存,尤其是密集型写入数据库。如果一定要做缓存,那还是基于应用层面实现缓存吧
解析器
主要功能验证当前sql是否合法。
解析器:MySQL通过关键字将SQL语句进行解析,并生成一颗对应的解析树。这个过程解析器主要通过语法规则来验证和解析。比如SQL中是否使用了错误的关键字或者关键字的顺序是否正确等等。
预处理器:会根据MySQL规则进一步检查解析树是否合法。比如检查要查询的数据表和数据列是否存在等。
查询优化器
对于解析好的查询语句进行分析,获取其对应的全部查询计划(通常来说一个查询语句会对应多个查询计划)。然后比较每个查询计划的执行效率,获取其中的最优解,交给查询引擎进行查询。这也就是为什么当数据量较少时,即使建立索引也不会触发索引查询的原因
优化器常见的处理策略如下:
- 重新定义表的关联顺序
- 优化MIN()和MAX()函数
- 提前终止查询(比如:使用Limit时,查找到满足数量的结果集后会立即终止查询)
- 优化排序
查询执行引擎
在完成解析和优化阶段以后,MySQL会生成对应的执行计划,查询执行引擎根据执行计划给出的指令逐步执行得出结果。整个执行过程的大部分操作均是通过调用存储引擎实现的接口来完成,这些接口被称为handler API。
存储引擎接口提供了非常丰富的功能,但其底层仅有几十个接口,这些接口像搭积木一样完成了一次查询的大部分操作。(这种代码模式我觉得是最帅的!!!!!)

若有收获,就点个赞吧
0 人点赞
