Schedule,调度器。怎么去调度一个类的执行(调度间隔,重复次数)。
ScheduleBuilder,调度器构造器。构造出一个trigger触发器。
SimpleScheduleBuilder,ScheduleBuilder的实现类。
SchedulerFactory,调度程序工厂。创建调度程序,并根据调度程序,去调度任务。
Scheduler,调度程序接口。
StdScheduler,调度程序的实现。
SchedulerRepository,调度程序仓库。使用HashMap数据结构,持有调度程序的引用。
userTXLocation,
CascadingClassLoadHelper,
JobFactory,创建任务的工厂。
idleWaitTime,
dbFailureRetry,
ThreadPool,线程池。默认实现是SimpleThreadPool。
ThreadExecutor,线程执行器,封装了线程的执行。
DBConnectionManager,数据库连接管理器。每个数据源名称都对应一个连接提供者,使用HashMap存储。
ConnectionProvider,连接提供者
instanceIdGeneratorClass,id生成器class。
Properties,属性文件。
SchedulerSignaler接口
Support抽象类,好像是对应listener接口的空实现抽象类,对应一种设计模式。
怎么将线程跟任务关联起来,怎么调度,怎么抢占锁。
常用注解
- PersistJobDataAfterExecution,在执行后持久化存储jobDetail的jobDataMap数据。
- DisallowConcurrentExecution,不允许并发执行任务
- ExecuteInJTATransaction,在事务中执行任务
Job
Job,不具备打断能力的job接口。被执行的任务(通常指业务类) 需要实现这个接口。
InterruptableJob,可以被打断的Job。被执行的任务需要实现被打断的接口(interrupt方法)。
JobDetail,任务明细接口,包含了被执行的类,执行类的key,执行类描述,执行类需要的数据,是否允许并发执行(isConcurrentExecutionDisallowed)。JobDetail接口没有setter方法。
JobDetailImpl,任务明细的实现。
- JobKey,job的唯一标识。包含name和group分组。
- JobDataMap,如果任务不是无状态的,就可能需要从JobDataMap中读取和存储数据。
- isDurable,是否需要持久化存储。如果不是持久化存储,job没有对应的trigger关联时,job会被移除。
JobBuilder,任务构造器。用于构建需要被调度的Job。
JobStore
JobStore,任务存储。默认实现是RAMJobStore,也就是将trigger和job存储在内存中,使用hashMap存储。
RAMJobStore
lock,操作jobStore中的数据时,先要获取到锁,比如操作job或者trigger的数据。
timeTriggers,可以被获取的trigger,此时trigger状态为waiting。
pausedTriggerGroups,被暂停的触发器分组。
pausedJobGroups,被暂停的job分组。
blockjobs,job不允许并发执行时,会被加入到blockJobs中。
对象比较器,ObjectComparator。
属性比较器,ObjectPropertityComparator。
JdbcJobStore
- 基于jdbc存储的JobStore,需要对应的表结构。表结构可以在quartz的github仓库中查找。它提供了基于各种数据源的sql脚本。
- 现有的可视化界面 => 好像没有官方的界面。
- 集群模式下的jobStore,获取到一个trigger之后会分配到不同的实例上。如果此时触发间隔时间到了,上一个任务还没有执行完成,则看任务上是否待有DisallowConcurrentExecution注解。
jdbcStore的配置文件
org.quartz.scheduler.instanceName: DefaultQuartzSchedulerorg.quartz.scheduler.rmi.export: falseorg.quartz.scheduler.rmi.proxy: falseorg.quartz.scheduler.wrapJobExecutionInUserTransaction: falseorg.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPoolorg.quartz.threadPool.threadCount: 10org.quartz.threadPool.threadPriority: 5org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true#是否使用集群(如果项目只部署到 一台服务器,就不用了)#org.quartz.jobStore.isClustered = true#org.quartz.jobStore.clusterCheckinInterval = 20000org.quartz.jobStore.misfireThreshold = 60000# 持久化配置(存储方式使用JobStoreTX,也就是数据库)org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX# 驱动器方言 数据库平台org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate#数据库中quartz表的表名前缀org.quartz.jobStore.tablePrefix = QRTZ_org.quartz.dataSource.test.driver = com.mysql.jdbc.Driverorg.quartz.dataSource.test.URL = jdbc:mysql://127.0.0.1:3306/quartz?useUnicode=true&characterEncoding=utf8org.quartz.dataSource.test.user = rootorg.quartz.dataSource.test.password = 123456org.quartz.dataSource.test.maxConnections = 10#数据库别名 随便取org.quartz.jobStore.dataSource = test
获取可以被触发的触发器
总体来说,quartzSchedulerThread有设置idlewaitime时间。idlewaitime时间就是在这个空闲时间内如果没有接收到调度器发生变化的信号(sigLock锁的notify),它就会阻塞对应的时间(sigLock的wait(idlewaitime)方法)。因此quartzSchedulerThread需要提前获取到这个(now + idlewaitime)时间点内的trigger,否则会造成触发器失火的情况,并且它会一次性获取当前可用空闲线程个数的trigger。
acquireNextTriggers方法逻辑:
- 先获取到lock锁,防止此时的job和trigger放生变化。
- 如果timeTriggers的集合为空,那么直接返回。
- while循环获取triggerWrapper,从timetriggers中获取第一个triggerWrapper。因为timeTriggers是有序的triggerWrapper集合(按照触发时间和优先级排序),接着从timeTriggers中移除triggerWrapper。
- 如果trigger的下一次触发时间为空,则重新获取triggerWrapper。
- 如果trigger的下一次触发时间大于需要获取的时间点,则跳出循环(因为timeTrigger是有序的,第一个时间都不满足了,就不用再继续循环了),然后返回获取到的trigger集合。
- 接着判断该trigger是否失火,失火的条件为:当前时间小于这个(now-misfireTime)的时间点 并且失火策略为不能忽略(Trigger.MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY)。
- 通知triggerListener该trigger发生失火
- 接着调用trigger的updateAfterMisfire方法
- 最后进行下一次触发时间的判断,如果下一次触发时间为空,那么就说明trigger已经完成,从timeTriggers中移除自己
- 如果处理后的trigger的下一次执行时间跟之前的执行时间不一样的话,则需要重新加入timeTrigger计算触发顺序。
- 判断该trigger对应的job是否禁止并发执行,如果禁止,则需要将该job对应的其它trigger暂时从timeTriggers中移除。
- 设置triggerWrapper的状态为ACQUIRED,设置本次触发的triggerInstanceId。
- 如果获取到的trigger数量等于需要获取的数量,则可以跳出循环。
- 结束循环后需要判断是否有被临时移除的trigger,有的话,需要将triggerWrapper放回timeTriggers。
释放获取到的trigger
在JobStore中调用triggerWrapper相关的方法时(如triggersFired方法),如果发生了异常,起会调用该方法,将其重新放入timeTriggers中。
releaseAcquiredTrigger方法逻辑:
1. 先获取到lock锁。
2. 判断triggerWrapper的状态是否为已获取状态。
3. 如果是已获取状态,则将其重新加入到timeTriggers中。
触发器被触发
- 先获取到lock锁。
- 循环进行处理firedTriggers集合,每次从firedTriggers集合获取triggerWrapper。
- 判断triggerWrapper的状态是否为ACQUIRED状态,不是的话则continue。
- 调用trigger对应的triggered方法,更新trigger内部的属性。
- 计算下一次执行时间
- 已执行的次数
- 存储上一次执行时间
- 设置triggerWrapper的状态为WAITING(之前是ACQUIRED状态)
- 判断对应的job是否允许并发执行
- 如果不允许的话,则将该job对应的所有triggerWrapper改为加锁状态(BLOCKED)
- 如果允许的话,判断下一次执行时间是否为null,不为null的话,重新加入timeTriggers中。
- 返回触发器触发执行结果(TriggerFiredResult)。
job执行完毕
正常情况下,Job被执行完毕的时候,会通知JobStore执行该方法。
- 先获取到lock锁
- 根据isPersistJobDataAfterExecution判断需要是否持久化存储jobDataMap
- 根据isConcurrentExectionDisallowed判断job是否不允许并发执行
- 如果不允许并发执行,需要从blockJobs中移除该job,解除对应trigger的锁定状态。如果解除状态后的trigger状态为WAITING状态,则将trigger放入到timeTriggers结合中。
- 根据完成策略CompletedExecutionInstruction对triggerWrapper进行处理
- 如果CompletedExecutionInstruction默认值是NOOP,什么都不做。
- 如果值是DELETE_TRIGGER,则需要删除对应的trigger。
- …
JobRunShell
封装了运行任务的一些信息,实现了runnable方法。
initialize
初始化方法。会使用jobFactory实例化出对应jobClass的对象,会设置这个对象的其它属性。并构造出jobExecutionContext。
run
- 任务即将开始执行
- 触发对应的trigger监听器
- 触发对应的job监听器
- 会调用job的execute方法,并传入jobExecutionContext实例
- 任务执行结束
Trigger,触发器接口。父接口,定义了触发器通用的元素。trigger需要跟job进行关联,一个trigger对应一个job,一个job可以被多个trigger对应。
MutableTrigger。触发器可变接口,具有set方法,而Trigger只有get方法。
OperableTrigger。可操作的触发器接口,如计算下次触发时间,调用触发器的触发方法。
TriggerBuilder,触发器的构造器。构造出trigger(如simpleTrigger)。
- TriggerKey,trigger的唯一标识。包含了name和group俩个属性。
- StartTime,开始触发时间。
- endTime。结束触发时间。
- scheduleBuilder
ScheduleBuilder,周期表构建器接口,构造出对应的MutableTrigger。
- SimpleScheduleBuilder,构造出SimpleTriggerImpl。
- interval,间隔时间
- repeatCount,重复次数
- misfireInstruction,失火次数。
- CronScheduleBuilder,构造出CronTrigger。
TriggerWrapper
trigger的包装类,具有运行时的一些信息,如trigger的状态。
- waitting,等待状态。
- acquired,被scheduler获取到时的状态。
- complete,完成状态。
- paused,暂停状态,从waiting状态变化过来
- blocked,锁住状态
- 如果job被锁住了,对应的trigger会被锁住
- 如果trigger被触发了,该trigger对应的job的其它trigger会被锁住
- paused_blocked,暂停加锁住状态
triggered
- 累加触发器执行次数
- 将当前的下一次触发事件赋值给上一次触发时间
- 重新计算下一次执行时间
executionComplete
MisfireInStruction
失火策略,也就是任务没有在应该执行的时机执行时,需要根据这个策略进行处理。
MISFIRE_INSTRUCTION_SMART_POLICY
- 聪明的失火策略,由每个触发器自己决定。
QuartzScheduler
start
quartzSchedulerThread调用start方法后,会处于暂停状态(paused=true)。quartzScheduler调用start方法会将quartzSchedulerThread的paused状态设置为false,此时quartzSchedulerThread才会进行下一步处理。
shutdown
QuartzSchedulerResources
QuartzScheduler相关的资源
QuartzSchedulerThread
idleWaitTime,空闲等待时间。调度器会提前获取空闲等待时间的触发器,如果这个时间调度器没有发生变化(比如这时候调度器没有接收到需要调度的任务)那么就等待空闲的时间。
sigLock,信号锁。
其它属性
- executingJobsManager,正在执行的任务管理器,实现了jobListener接口,会在任务被执行时增加任务执行总数。在任务被触发的时候,将job添加到executingJobs中,在任务执行完之后。
- errLogger,在调度器调度失败的时候,会打印日志。
- SchedulerSignalerImpl,持有schedule和scheduleThread的引用,在某些事件产生的时候,可以调用schedule对应的方法来通知schedule。
- updateTimer,新版本更新检查定时器。
ThreadPool
成员变量
- 线程池名称
- 线程个数
- 线程的优先级
- 创建的线程是否为守护线程
- 当前线程所在的线程组
- availWorkers,空闲线程。
- busyWorkers,繁忙线程。
- nextRunnableLock,下一个可以运行的任务锁
初始化逻辑
根据资源文件的配置,创建工作者线程(传递的参数有 线程名称,线程优先级,线程池引用,线程组,是否后台线程等),并添加到workers和availWorkers中,并且循环调用每个workThread的start方法。
获取空闲线程数
先获取到下一次运行的任务锁(nextRunnableLock),防止这时候的空闲线程集合availWorkers发生变化。循环判断如果此时的availWorkers小于1,或者此时有任务进行等待分配(handoffPending为true),并且此时线程池没有关闭(isShutdown为false),那么就进行等待(wait 500),直到前面的条件都不满足为止才退出循环。
如果此时获取到的空闲线程数大于等于1,则说明现在可以把对应个数的任务交给线程池进行分配执行。
分配任务
先获取到可以允许下一个任务的锁(nextRunnableLock),设置handoffPending为true,handoffPending表示当前有任务在等待线程池分配任务。接着阻塞判断是否存在空闲线程可以获取(一般情况下,繁忙线程执行完后会将自己添加到空闲线程集合中)或者 线程池是否将要被关闭(isShutdown为false)。
如果没有关闭线程池的情况下,直接从空闲线程集合中拿到第一个线程,并把它从空闲集合中移除。然后将这个空闲线程添加到繁忙线程集合中,接着执行workThread的投递方法(run方法)。
如果关闭线程池将要被关闭的情况下,直接new出一个线程(此时这个WorkThread的runOnce属性为true)去执行这个任务,不再等待有空闲线程去执行,这样可以减少线程池的shutdown时间。并将此线程添加到繁忙线程集合中,添加到工作者集合中。
最后通知等待下一次允许任务锁的线程,设置handoffPending为false。
关闭线程池
整体来说,我们关闭线程池时,一个需要停止上游线程(quartzScheduleThread)给他(thradPool)分配任务,另一个需要关闭掉工作池中现有的任务。关闭线程池的方法有一个waitForJobsToComplete的属性,waitForJobsToComplete表示线程池关闭是否需要等到运行中的任务执行完毕。
先获取nextRunnableLock,设置线程池为关闭状态(shutdown),并循环调用workers集合中thread的shutdown方法(不让工作者线程再循环执行),然后移除availWorkers中的线程。通知阻塞在nextRunnableLock锁上的所有线程。
如果waitForJobsToComplete为true,那么会循环判断busyWorkers的元素个数是否大于0(一般情况下,繁忙集合中的线程结束任务后,会将自己从繁忙集合中移除),如果busyWorkers的元素个数大于0的,调用nextRunnableLock的阻塞方法,让其它方法有时间处理(比如如果此时有任务需要进行分配,可以让线程池把任务分配好)。最后循环调用每个workers中thread的join方法,等待thread死亡。
如果waitForJobsToComplete为false,那么会直接返回。
WorkThread
工作者线程。重写了Thread类的run方法,在调用run方法的时候,先去获取内部lock对象的锁,然后判断runnable接口是否为空。如果为空,则进行有超时间件的等待(调用的object.wait(500),等待0.5秒,避免无效的死循环判断,造成CPU资源的浪费)。结束等待后,判断runnable接口是否为空,不为空的话就去执行。执行完后,先获取内部lock对象的锁,然后设置runnable接口为空。如果只运行一次的话,设置死循环标志run为false,然后从simpleThreadPool中的busyWorkers中移除自己。如果运行多次的话,那么就从busyWorkers中移除自己,然后如果线程池没有被关闭的话。则将自己添加到avaliWorkers中。
一次性任务
一次性任务在线程迟将要关闭,此时又有带切换的任务需要执行,这时候不会放在线程迟中的线程执行,而是直接new一个workThread出来执行。
- 直接调用WorkThread的构造函数,并且此时runnable接口不为空。
执行逻辑
工作者线程启动之后,在一个while循环里面执行业务逻辑。while循环的退出条件是线程是否关闭(run == false)。先去获取任务锁(lock对象),如果没有关闭且当前runnale方法为空,说明此时没有需要执行的任务。线程会在这里等待500毫秒(wait 500)。当有任务投递给当前线程时,才会唤醒工作者线程,继续执行当前方法。
如果任务不为空的话,执行runnable接口。执行完之后获取lock锁,防止并发冲突。获取到锁之后,设置runnable接口为null。如果只是只执行一次的任务,通过持有的threadPool引用,去获取下一次任务允许的锁,获取到下一次任务允许的锁之后,那么就将自己从busyWorks中移除。否则就从busyWorkers中移除,然后添加到avaliableWorkers。
投递任务
内部的run(Runnable newRunnable)方法:先去获取内部对象lock的锁,获取成功后先判断内部的runnable是否为空。如果不为空的话说明该线程还是处于繁忙状态,抛出异常。如果为空的话,则设置为传递进来的newRunnable,并且唤醒所有lock等待队列中的对象(提前让这些对象结束等待,提高工作线程的响应速度)。
关闭线程
设置内部成员变量run为false,也就是任务执行完之后不再循环等待下一个可以运行的任务,结束线程的run方法后,线程会进入terminate状态。
SchedulerPlugin,调度器的插件。
jobListener,作业监听器。
triggerListener,触发器监听器。
设计模式
创建型模式:关注对象怎么创建。
- 单例模式,SchedulerRepository类。
- 简单工厂,一个工厂负责多个相同类型的对象创建
- 工厂方法模式,一个工厂只负责相同类型产品中一个产品的创建。StdSchedulerFactory类。
- 抽象工厂方法模式,一个抽象工厂可以创建多种类型产品。
- 建造者模式,不会让对象的构建处于中间状态,构造出的对象是不可变对象。相同的构造流程会有不同的表示。
- 原型模式
结构型模式:关注类和对象怎么组织,侧重于结构上。
- 代理模式,对被访问的对象进行权限控制,不能直接访问被代理对象,并且能够访问的接口受到限制。
- 跟装饰模式的区别是不会增强被代理对象的功能,装饰模式是增强代理对象的原有功能
- 适配器模式,将一个类的接口转换成客户希望的另外一个接口。
- 类的适配器,类去继承原对象,实现目标接口
- 对象的适配器,类引用源对象,实现目标接口
- 接口的适配器,抽象类去实现接口的方法,具体的实现类只需要实现自己特定的方法。适配器模式,比如SchedulerListenerSupport。
- 桥接模式。将抽象与实现分离,使它们可以独立变化。它是用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。
- 装饰模式,对被访问对象的功能进行加强,如Java中的字节流,字符流。
- 门面模式,门面类内部组合了非常多的对象,对外来说只需要访问这个门面类的方法,不用关心内部的对象和流程。
- 享元模式,运用共享技术来有效地支持大量细粒度对象的复用。与单例模式的区别是,可以进行一个类多种类型实例的复用。
- 组合模式,介绍:将对象组合成树形结构以表示‘部分-整体’的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
行为型模式:关注运行时复杂的流程控制,它涉及算法与对象间职责的分配。分为类行为模式和对象行为模式。
- 模板方法模式,定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。它是一种类行为型模式
- 策略模式,
- 模板模式
- 桥接模式
- 观察者模式
- 责任链模式。为了避免请求发送者与多个请求处理者耦合在一起,于是将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
每个重要的对象都会具有Initialize方法
Matcher
matcher是比较器,可以进行对应值的比较。
StringMatcher
- getValue接口,该接口是抽象接口,对应的自类需要实现这个接口。
Wrapper
多线程
- 用到了线程池技术。
- 用到了原子类atomic,保证操作原子性。
- 用到了volatile,保证了内存可见性。
- 用到了syncronized锁。
用到了wait和notify模式,来完成生产者和消费者功能。
深拷贝和浅拷贝,体现在JobDetailImpl重新了Clone方法。
- JobDetail和JobTrigger的JobDataMap
源码分析
- 通过schedulerFactory工厂类来获取scheduler对象。
- 如果没初始化配置文件,则初始化schedulerFactory里的配置文件,根据配置规则来查找配置文件
- 看是否系统属性中指定了配置文件名,没有指定的话,使用默认文件名。
- 尝试在程序的启动目录下查找。
- 尝试在程序的class目录下。
- 如果还没有加载到配置文件,就加载quartz包里的默认配置文件,得到properties对象。
- 使用系统属性覆盖之前的加载的配置属性。
- 看是否系统属性中指定了配置文件名,没有指定的话,使用默认文件名。
- 根据properties对象,创建propertiesParser资源解析器。
- 从schedulerRepository中根据名称拿secheduler,quartz支持一个程序里面存在多个scheduler调度器。
- 如果没有创建过scheduler,则创建scheduler。
- 如果创建过scheduler,则直接返回scheduler。
结合Springboot
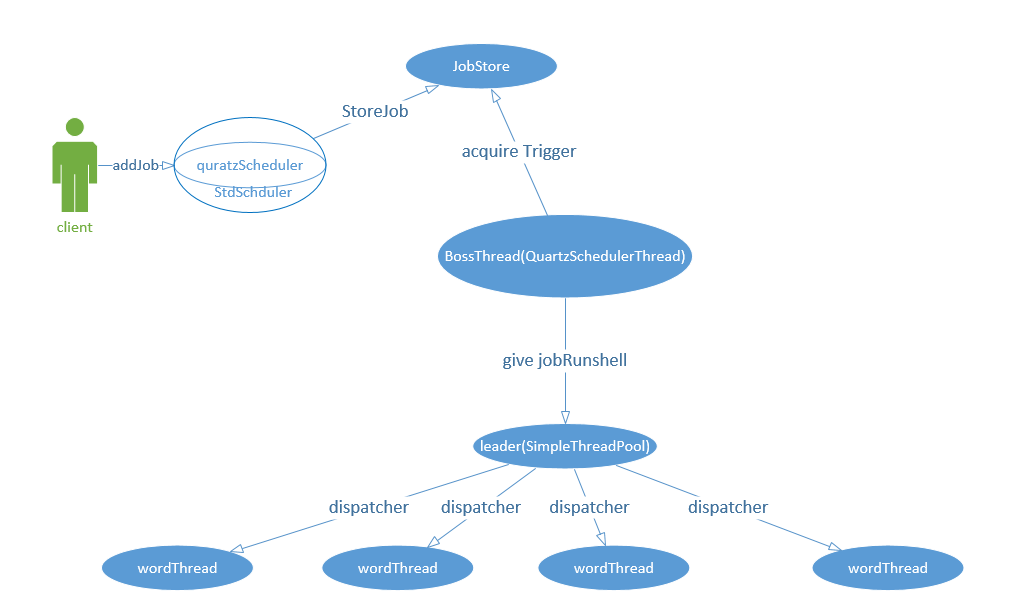
架构图

若有收获,就点个赞吧
0 人点赞
