分布式ID。使用项目一个是UGC(全称为User Generated Content,也就是用户生成内容,比如微信朋友圈和微博等都属于UGC);另一个是课程订单号的生成。这两个项目中的分布式ID生成策略,是在借鉴雪花算法(SnowFlake)的基础上,做了很多有特色的设计,从而使得生产出来的分布式ID贴合业务,同时带来了更多的附加收益。
分布式唯一ID生成方案选型
业务发展初期,单库单表的服务可以依赖数据库的自增主键实现;随着服务的发展,存储被拆分到多处,再使用数据库的自增主键就会导致主键重复。
单独单独的自增数据表的自增数据
CREATE TABLE IF NOT EXISTS `generate_unique_id`(`unique_id` INT UNSIGNED AUTO_INCREMENT,PRIMARY KEY (`unique_id`))ENGINE=InnoDB DEFAULT CHARSET=utf8;
每次需要生成唯一ID时,就去这张数据表里新增一条记录,使用返回的自增主键作为业务ID。
高级玩法:每次设置ID的值就使用LAST_INSERT_ID来设置(UPDATE table SET value=LAST_INSERT_ID() WHERE name=’user’)
这个方案使用简单,问题也很明显:
- 性能无法保证 : 数据库常见架构是一主多从+读写分离,生成自增ID是写请求
- 存在单点故障 ,数据库主库的写性能决定ID的生成性能上限,并且难以扩展
对于单点故障问题,可以启用多台数据库服务器来生成ID,通过区分auto_increment的起始值和步长生成不同ID,起始值和步长可以添加到配置文件,例如:
TicketServer1:auto-increment-step = 2auto-increment-offset = 1TicketServer2:auto-increment-step = 2auto-increment-offset = 2
对于性能问题,可以使用Redis的自增指令incr代替mysql的插入。
考虑多加架构层级问题:引入Redis后会存在数据持久化问题,假如Redis 宕机重启会生成重复的ID该怎么办?
增量取模持久化
每次redis执行自增后对返回值进行判断,如果取模128等于0,就做一次持久化,当redis发生宕机重启时,从数据库中捞出持久化的值,再增加128添加到redis中作为初始自增值。
当然除了持久化问题,这种方案同样也存在单点故障问题,redis高可用的解决方案可以使用哨兵和集群,但这会使得整个服务依赖很重,成本增加。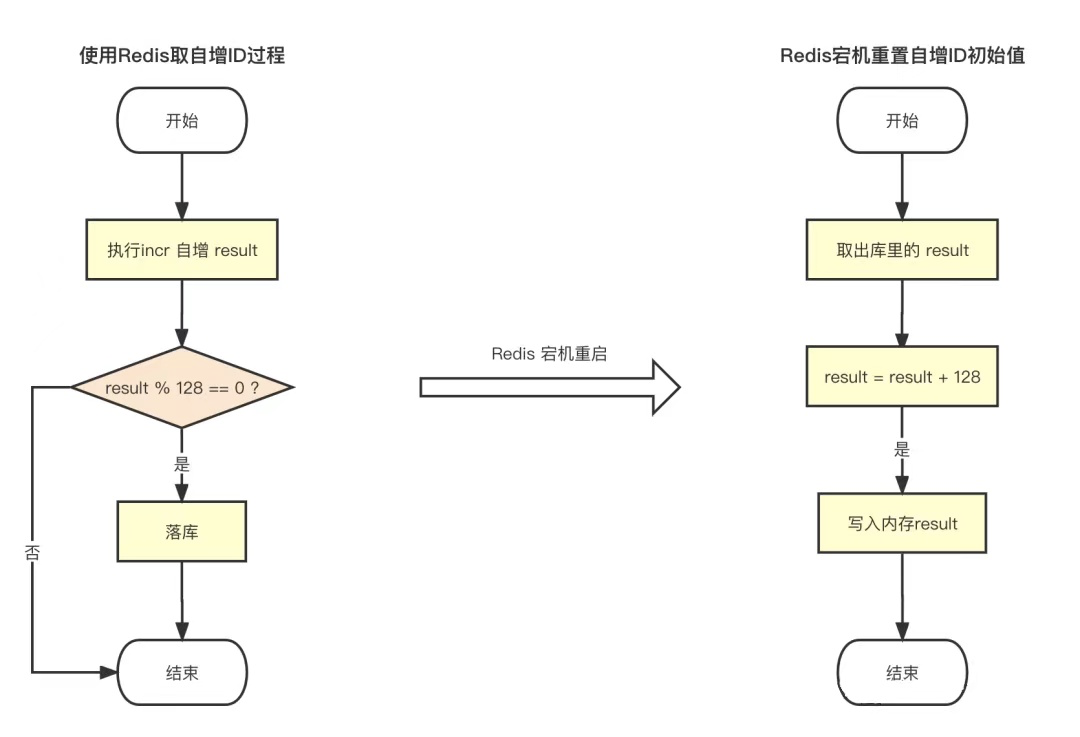
UUID
数据库的唯一主键和redis的自增指令生产出来的唯一ID都是自增数字型的,如果仅从唯一性的角度考虑,UUID也能很好的满足这一要求,而且UUID在各种高级编程语言中(java、go、php等)都有实现。 我们输出一个UUID观察一下:
295c8922-bf20-46d3-1126-19ba588554e8
一个36位的字符串,如果作为数据库的索引可行,不过没有int数字型的索引值高效。而且UUID的一串字符并没有什么规律可言,对于要求根据时间严格自增或者局部自增的需求来讲,是不可取的(比如有排序需求就GG)。
SnowFlake 算法
能满足的需求:时间自增、int 型、性能好、高可用
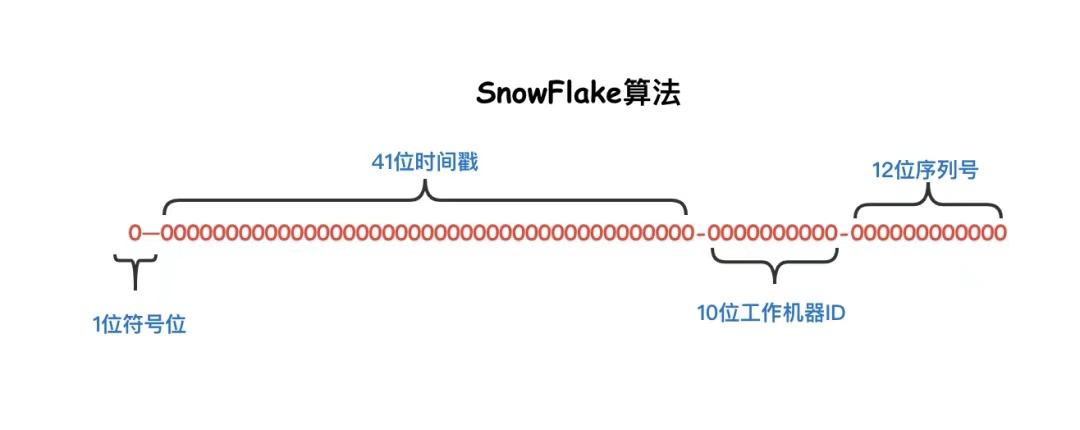
snowflake是twitter开源的分布式ID生成算法,其核心思想为,一个long型的ID:
- 41bit作为毫秒数
- 10bit作为机器编号
- 12bit作为毫秒内序列号
其中:
- 第一位默认不使用,作为符号位,总是0,保证数值是正数;也正因如此,像php、js这种弱类型语言,整数设计为8字节,也可以很容易的接纳雪花算法生成的唯一ID而不出现溢出的问题。
- 41位时间戳,表示毫秒数,我们计算一下,41位数字可以表示的毫秒换算成年,结果是69年多一点,一般来说,这个数字在业务中使用是没什么问题的。
- 10位工作机器ID,也就是支持1024个节点。
- 12位序列号,作为时间戳和机器下的流水号,每个节点每毫秒内支持0-4095的区间,也就是4096个ID,换算成秒,相当于可以允许409万的QPS,如果这个区间内超过了4096,则等待至下一毫秒计算。
算法单机每秒内理论上最多可以生成1000*(2^12),也就是400W的ID,完全能满足业务的需求。
SnowFlake算法可以作为一个单独的服务,部署在多台机器上,产生的ID是随时间趋势递增的,不需要依赖数据库等第三方系统,并且性能特别高。SnowFlake 算法优点很多,但有一个不足,那就是存在时钟回拨问题,因为服务器的本地时钟并不是绝对准确的,在一些业务场景中,为了防止不同用户访问的服务器时间不同,则需要保持服务器时间的同步,为了确保时间准确,会通过NTP的机制 (内网时间定时同步)进行校对,如果服务器在同步NTP时出现不一致,出现时钟回拨,那么SnowFlake在计算中可能出现重复ID。除了NTP同步,闰秒也会导致服务器出现时钟回拨,不过时钟回拨是特别小概率事件,在并发低的情况下可以忽略。解决时钟回拨问题也有很多方案:延迟等待、时钟上报同步等。
内存维护区间分配
内存维护区间分配,借鉴了淘宝的TDDL数据库中间件的主键生成策略。使用这种方案需要在数据库中先建立一张 sequence表,其中每一行用于记录某个业务主键当前已经被占用的ID区间的最大值。
接下来插入一行记录,当需要获取主键时,每台服务器主机从数据表中获取对应的ID区间缓存在本地,同时更新 sequence 表中的value 最大值记录。
CREATE TABLE `sequence` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Id',`name` varchar(64) NOT NULL COMMENT 'sequence name',`value` bigint(32) NOT NULL COMMENT 'sequence current value 号段的布长',`version` int(20) NOT NULL COMMENT '版本号',PRIMARY KEY (`id`),UNIQUE KEY `unique_name` (`name`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;// value :代表号段的长度// version :是一个乐观锁,每次都更新version,保证并发时数据的正确性
比如设置一条order 更新的规则,插入一行记录如下:
INSERT INTO sequence (name,value) values(‘order_sequence’,1000);
当服务器在获取主键增长区段时,首先访问对应数据库的sequence表,更新对应的记录,占用一个对应的区间。比如我们这里设置步长为200,原来的value值为1000,更新后的value就变成了1200。
取到对应的ID区间后,在服务器内部进行分配,涉及的并发问题可以依赖乐观锁机制解决。有了对应的ID增长区间,在服务内部就可以使用atomic原子操作进行ID分配了。
不同的机器在相同时间内分配出来的ID可能不同,这种方式生成的唯一ID,不保证严格的时间序递增,但是可以保证整体的趋势递增,在实际的生产应用中也比较多。为了防止单点故障,可以给sequence表所在的数据库配置多个从库,实现高可用。
除了上面的几种方案,实际开发中也可以借鉴其他成熟的分布式ID生成方案,比如美团的Leaf算法。
分布式唯一ID设计
基于位运算的分段配置
雪花算法生成的是一个8字节的ID,8字节是64个bit位,其中41个bit位给了毫秒时间戳,对于秒杀场景而言,雪花算法也是非常合适的,但是对大多数业务而言,比如一个普通的小流量订单系统,对于性能和时间的精确度并没有“毫秒”那么高。
我们可以对雪花算法的64个比特位进行分段配置,首先考虑业务中时间相关的因素。那时间用秒还是毫秒呢?其实不用毫秒的时候就可以把空出来的10bit 送给 sequence,但是整个ID的精度就下降了,峰值速度是更现实的考虑。sequence的空间决定了峰值的速度,而峰值也就意味着持续的时间不会太久。这方面,每秒100万比每毫秒1000限制更小。
其实我们也没必要非将64bit都用满,比如微博(weibo) 使用的也是改进后的唯一ID生成算法,使用30bit表示时间,单位是秒;4bit来区分IDC;2bit区分业务;15bit给 sequence。理论上限3.2w/s的速度。因为发号服务是机房中心式的,使用1bit来区分热备。最终只使用了53bit。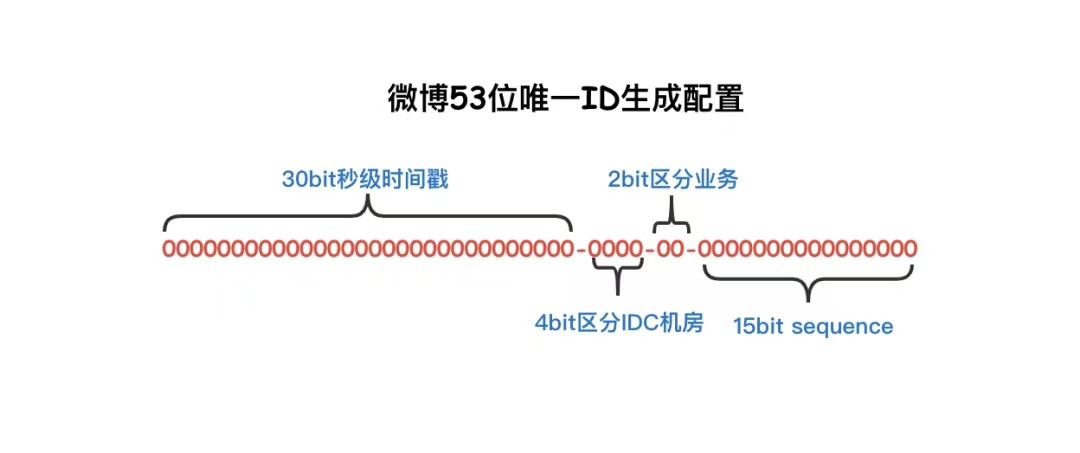
针对机器位:理论上时间戳会有一个参照时间,都放在最高位,后边的位还能再压缩压缩,只要能保证唯一就行。比如机器数量就用32台理论上也是够的
为什么考虑用53bit
有序集合中的每个元素都由一个成员和一个与成员相关联的分值组成,其中成员以字符串方式存储,而分值则以64位双精度浮点数格式存储,表示为一个IEEE 754 floating point number,它能包括的整数范围是-(2^53) 到 +(2^53)。
example:
有序集合中的每个成员都是独一无二, 按照它们各自的分值大小进行排序,分值相同时根据字典序进行排列;这样就可以利用滑动窗口缓存。
为了更好使用缓存,在唯一ID方案设计之初,就已经考虑到了要生成一个53位的唯一ID了。
基因注入的唯一ID
我们拿到一个唯一ID,就可以通过程序反向计算出这个订单是什么时间产生的,属于哪条业务线,并且我们还知道要到哪个分表中查找这个订单的详细信息,是不是特别神奇!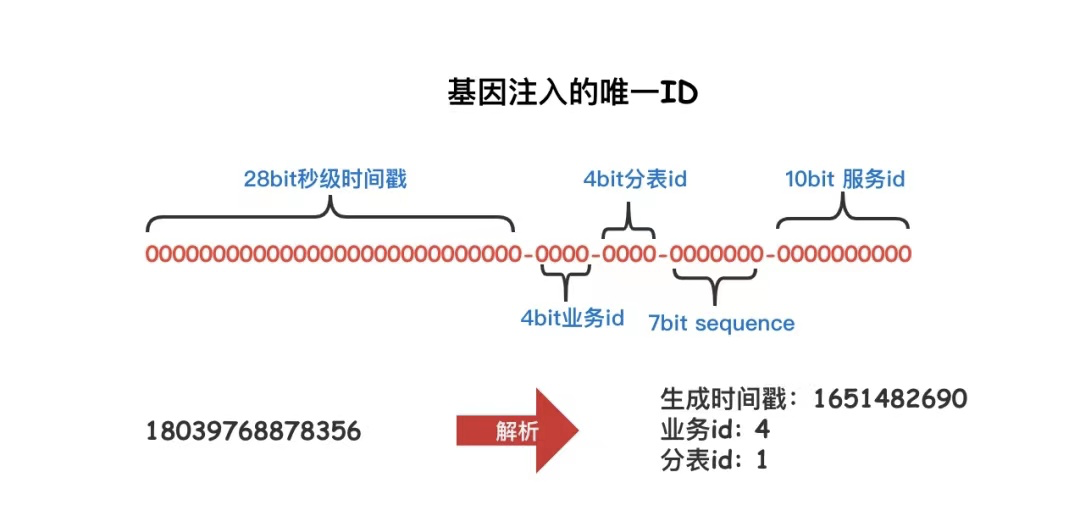
去中心化服务ID
雪花算法中,我们总会留一些bit位给服务ID,这些服务ID通常是用来标识服务节点所在的机房以及服务器的相关信息的。因为我们的服务要生成分布式的唯一ID,不同的服务器之间又是无状态的,所以只有区分了服务器,才能保证唯一。常用的做法是建立一个映射表:将服务器的mac地址与一个唯一的id做映射(或者ip地址与唯一id做映射),这样每台服务器产生的id就是唯一的了;这种方案存在一个致命缺点,那就是当服务动态变化时,我们需要动态维护这张映射表。这里笔者给出另外一种比较优雅的解决方案:服务启动分配服务ID法。
像Go、Java这种常驻进程的编译型语言,在服务启动时,我们就可以给服务分配一个唯一的服务ID,这个服务ID是可以在下次循环使用的,比如一次服务部署我们在K8S上启动了100个服务节点,我们分配10个位(最多支持1024个服务节点)给唯一ID生成器,那么我们每次只需要从0到1023中分配100个服务号给每个服务节点就可以了,当节点中出现宕机重启时,会从剩下的服务号中再取一个,在一定程度上实现了高可用。这种去中心化的服务ID不需要配置映射表,维护起来就方便了很多。
可能会有读者问了,服务启动时怎样分配服务ID呢?我们前边提到了使用redis的自增命令得到唯一ID,我们对结果取模,就得到了这个服务的唯一ID了!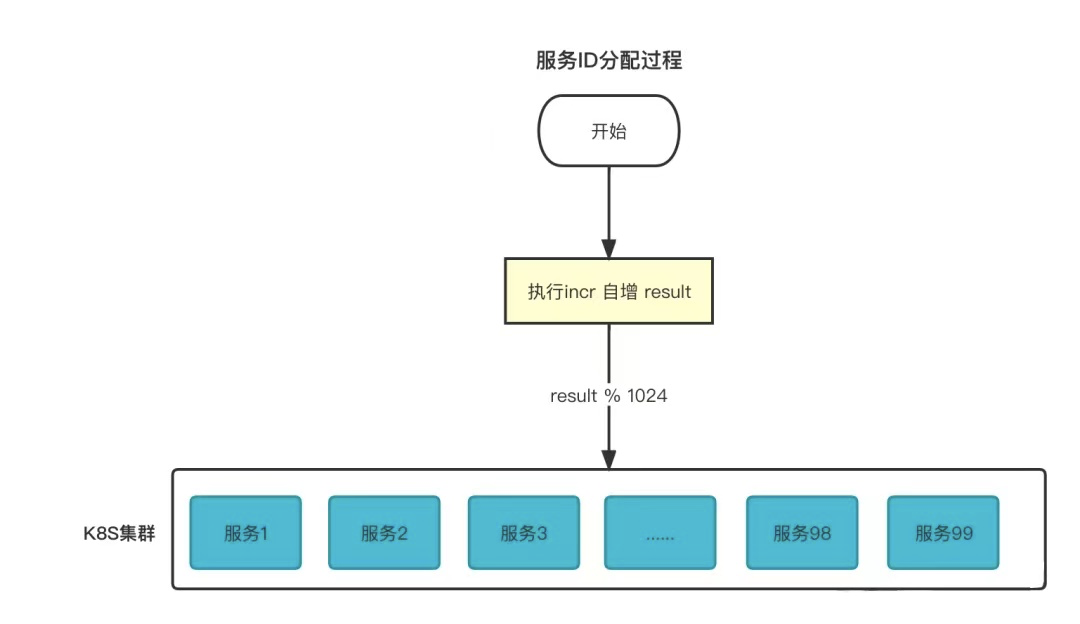
总结
雪花算法是业务中最常用的唯一ID生成策略,很多大公司都是在其基础上做了改造来迎合自己的业务,本文主要介绍了三种改造思想:
- 配置化分段bit位使得唯一ID生成更加灵活,比如生成53位的唯一id来使用redis的有序集合做缓存。
- 使用基因注入法在唯一ID中添加更多有用的信息,比如分表ID、业务ID等,这样我们就可以拿到ID反向解出这些信息,在业务中使用它们。
- 最后介绍了使用争抢服务ID的去中心配置化实现,对于Go、Java这种常驻内存的服务比较适用
雪花算法的代码使用了大量位运算,需要有一定的代码功底,最后笔者给出本文提到的基因注入案例中配置的生成53位唯一订单ID的算法,感兴趣的读者可以在业务中改造后使用。

若有收获,就点个赞吧
0 人点赞
