高可用
系统设计
- failover(故障转移)
- 对等节点之间做故障转移,
- 例子:nginx可以配置某一个tomcat出现大于500请求,重新请求另一个节点,热备(同样在线提供服务的备用节点),也可以是冷备(只作为备份使用);
- 故障检测机制是「心跳」。你可以在客户端上定期地向主节点发送心跳包,也可以从备份节点上定期发送心跳包。当一段时间内未收到心跳包,就可以认为主节点已经发生故障,可以触发选主的操作。
- 选主分布式一致性算法,比方说 Paxos,Raft
- 调用超时控制
- 收集系统之间的调用日志,统计比如说 99% 的响应时间是怎样的,然后依据这个时间来指定超时时间
- 超时控制实际上就是不让请求一直保持,而是在经过一定时间之后让请求失败,释放资源给接下来的请求使用
- 降级
- 降级是为了保证核心服务的稳定而牺牲非核心服务的做法(比方说我们发一条微博会先经过反垃圾服务检测,检测内容是否是广告,通过后才会完成诸如写数据库等逻辑。降级会直接发微博,去掉其他流程)
- 限流
- 灰度发布(金丝雀发布)
-
数据库
池化技术 (数据库连接池)
它的核心思想是空间换时间,期望使用预先创建好的对象来减少频繁创建对象的性能开销,同时还可以对对象进行统一的管理,降低了对象的使用的成本
对象没有被频繁使用,就会造成内存上的浪费主从分离
一般建议 一个主库带三个从库 最多5个;log dump线程也是一种损耗;
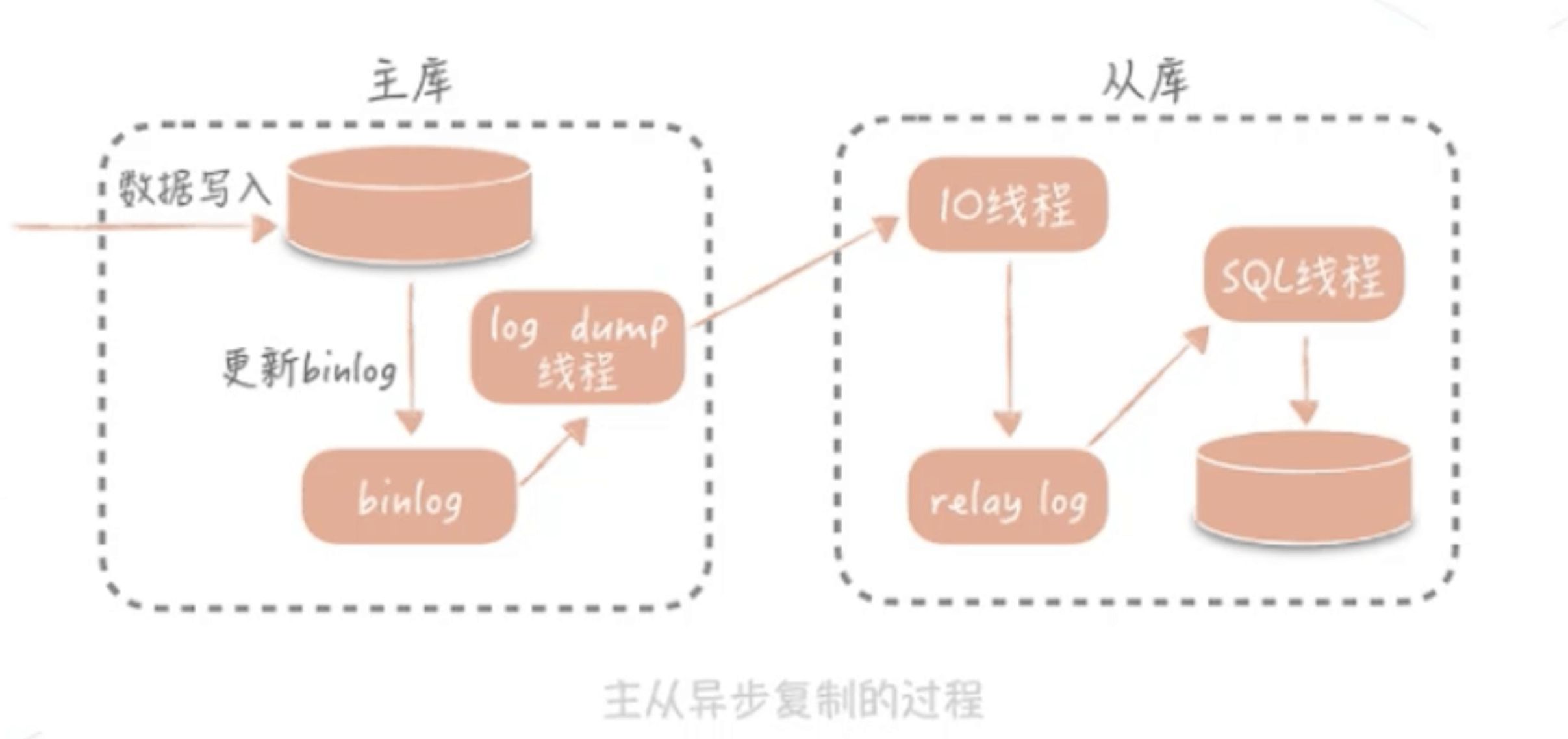
一般会优先考虑性能而不是数据的强一致性就会有主从数据一致性问题;主从数据一致性问题解决
读主库(但是原则是尽量不走主库)
数据的冗余,页面给过来数据尽量给全部,减少查询
使用缓存,写的时候缓存也写一份,查询先走缓存分库分表
1.垂直拆分
专库专用,例子(将羽绒服、毛衣、T 恤分别放在不同的格子里)把不同的业务的数据分拆到不同的数据库节点上,这样一旦数据库发生故障时只会影响到某一个模块的功能,不会影响到整体功能,从而实现了数据层面的故障隔离。
2.水平拆分
hash取模
实体表的 ID 字段来拆分。比如说我们想把用户表拆分成 16 个库,64 张表,那么可以先对用户 ID 做哈希,哈希的目的是将 ID 尽量打散,然后再对 16 取余,这样就得到了分库后的索引值;对 64 取余,就得到了分表后的索引值
根据时间纬度
**先确认数据在哪一个库表中,再到那个库表中查询数据;**
发号器
分库分表后,使用自增字段就无法保证 ID 的全局唯一性了,需要发号器;
如果主键用身份证,手机号等,但是如果数据脱敏会有影响。
雪花发号器(雪花算法):缺点是用时间戳生成的(系统时间不准,就有可能生成重复的 ID)
滴滴和美团都有提出基于数据库生成 ID 的方案Nosql互补
- Redis、LevelDB 这样的 KV 存储。这类存储相比于传统的数据库的优势是极高的读写性能,一般对性能有比较高的要求的场景会使用。
- Hbase、Cassandra 这样的 列式存储数据库。这种数据库的特点是数据不像传统数据库以行为单位来存储,而是以列来存储,适用于一些离线数据统计的场景。
- 像 MongoDB、CouchDB 这样的文档型数据库。这种数据库的特点是 Schema Free(模式自由),数据表中的字段可以任意扩展,比如说电商系统中的商品有非常多的字段,并且不同品类的商品的字段也都不尽相同,使用关系型数据库就需要不断增加字段支持,而用文档型数据库就简单很多了。
- Elasticsearch 来支持搜索的请求,它本身是基于“倒排索引”来实现的
NoSQL 数据库写入性能高的原因
使用的 基于 LSM 树的存储引擎;LSM 树(Log-Structured Merge Tree)牺牲了一定的读性能来换取写入数据的高性能,Hbase、Cassandra、LevelDB 都是用这种算法作为存储的引擎。
数据首先会写入到一个叫做 MemTable 的内存结构中,在 MemTable 中数据是按照写入的 Key 来排序的。为了防止 MemTable 里面的数据因为机器掉电或者重启而丢失,一般会通过写 Write Ahead Log 的方式将数据备份在磁盘上。
MemTable 在累积到一定规模时,它会被刷新生成一个新的文件,我们把这个文件叫做 SSTable(Sorted String Table)。当 SSTable 达到一定数量时,我们会将这些 SSTable 合并,减少文件的数量,因为 SSTable 都是有序的,所以合并的速度也很快。
当从 LSM 树里面读数据时,我们首先从 MemTable 中查找数据,如果数据没有找到,再从 SSTable 中查找数据。因为存储的数据都是有序的,所以查找的效率是很高的,只是因为数据被拆分成多个 SSTable,所以读取的效率会低于 B+ 树索引。Elasticsearch倒排索引呢
基于分词,然后建立起分词和数据 ID 的对应关系缓存
分类
静态缓存(CMS网站生产html文件),分布式缓存(redis),热点本地缓存(FPM,Swoole 有hash table)动态查询
缓存更新策略
旁路缓存策略:先更新数据再删除缓存;读数据先读缓存,不存在时set缓存
读穿/写穿策略
写回策略:缓存高可用
客户端方案:memcache
服务端方案:redis
中间代理层方案:mysql 主从读写分离。缓存穿透
回填空值,需要注意将空值设置过期时间很短。
布隆过滤器,
狗庄效应:静态资源
消息队列
削峰填谷
消息幂等性
消息延迟
数据一致性
分布式服务
服务拆分
服务改造
RPC
服务发现链路追踪
负载均衡
网关

若有收获,就点个赞吧
0 人点赞
