1. HashMap(精确)
对于海量数据,会造成占用内存过高,虽然能够提供最精确的计算,但是只适用于小数据量。
2. 布隆过滤器(近似)
布隆过滤器是一个长度为 m 比特的位图数组和 k 个哈希函数组成的数据结构,初始时所有的数组位都是 0。
当插入数据时,将数据分别输入到 k 个哈希函数中,产生 k 个哈希值,对应 k 个位图数组的下标,将这 k 个对应的数组比特位设置为 1。
当查询时,如果经过哈希计算出的 k 个bit位都为 1,那么表明数据 可能 已经存在集合中,如果任一位置为 0,则必定不在集合中。
优点:实现简单
缺点:1. 不能保证数据绝对的准确性;2. 当数据量很大时,位图数组可能要很大
这其实是 BitMap 的应用,因为 BitMap 要求只能存入整型数据,所以对于非整型数据需要使用哈希函数形成映射。为了降低哈希冲突的概率,因此使用多个哈希函数一起计算的形式
3. HyperLogLog(近似)
能够以很小的精确度误差统计数据,空间复杂度很低(log(log(n))),几乎不随存储集合的大小而变化,在 redis 中,一个 HyperLogLog 只占 12KB。
HyperLogLog支持各种数据类型,因为采用了哈希函数,将输入值映射成一个二进制字节,然后对这个二进制字节进行分桶以及再判断其首个 1 出现的最后位置,来估计目前桶中有多少个不同的值。由于使用的是哈希函数,因此数据存在一定的误差,基本有 1% 的误差率。
使用 redis 的 PFADD 命令,如果成功插入(即第一次出现)那么返回 true,否则返回 false
4. BitMap(精确)
如果存储的数据只是整型数据,那么可以使用 BitMap 数据对数据形成映射,相比较于原始数据可以极大的节省内存空间,但是如果数据不够密集,那么会浪费需要内存空间。
4. Roaring BitMap(精确)
如果说数据是 int / long 类型,那么可以直接使用 BitMap 数组。
如果说使用 BitMap 数组依然超过了内存限制,那么久需要使用 Roaring BitMap 了,即经过数据压缩的 BitMap
算法的思想是:
- 我们将 32-bit 的范围 ([0, n)) 划分为 2^16 个桶,每一个桶有一个 Container 来存放一个数值的低16位;
- 在存储和查询数值的时候,我们将一个数值 k 划分为高 16 位(k % 2^16)和低 16 位(k mod 2^16),取高 16 位找到对应的桶,然后在低 16 位存放在相应的 Container 中;
- 根据数据容器Container存放的数据量,分为:Array Container 和 Bitmap Container。Array Container 存放稀疏的数据(即直接存放数据值),Bitmap Container 存放稠密的数据(存放经过映射的数据)。即,若一个 Container 里面的 Integer 数量小于 4096,就用 Short 类型的有序数组来存储值。若大于 4096,就用 Bitmap 来存储值。
以存放两个数据为例: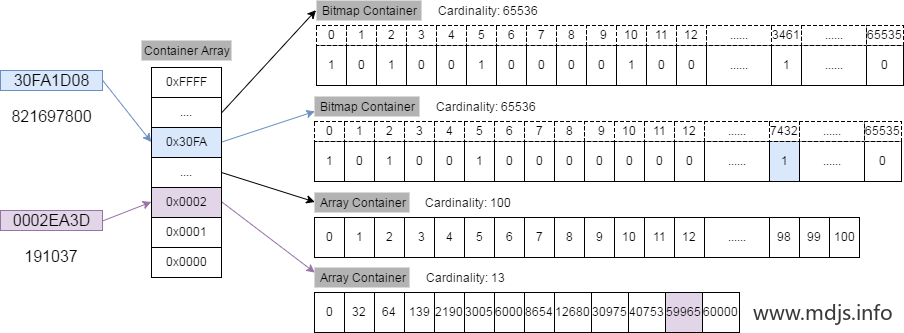

若有收获,就点个赞吧
0 人点赞
