- Jvm的五大内存模型(1.8前)
- 1.5 GC的常用回收算法
- 1.6 类的加载过程
- 1.7 双亲委派模型
- 1.8 内存泄漏和内存溢出
- 1.9 GC怎么判断对象是否可回收
- 1.10 GC在堆内存的工作过程
- 1.11 CMS和G1的区别
1.12 final、finally与finalize的区别?- 1.13 装箱和拆箱
- 1.14 jvm常用的调优参数
-Xmx 堆内存最大值 -Xmx2g 默认是系统内存的1/4
-Xms 堆内存最小值 -Xms2g
一般情况下最小堆内存和最大堆内存大小设置一样,每一次扩容都会进行一次full gc,减少full gc次数。
-Xmn 设置新生代的大小 默认是堆的1/3
-Xss 设置线程栈空间大小 -Xss256k
1.14.1 JVM相关的命令-调优
在Java应用和服务出现莫名的卡顿、CPU飙升等问题时总是要分析一下对应进程的JVM状态以定位问题和解决问题并作出相应的优化,在这过程中Java自带的一些状态监控命令和图形化工具就非常方便了。本文总结了最常用的命令行工具及其常用参数解释,图形化监控工具的用法,仅供参考。 - 15884 interned Strings occupying 2075304 bytes.
1 jmap -histo:live 11666 | more
输出存活对象统计信息
输出:
num #instances #bytes class name - 1.15 你知道哪几种垃圾收集器,各自的优缺点,重点讲下cms
- 1.16 方法的重载
- 1.17 方法的重写
- 1.18 深拷贝和浅拷贝
- 2 锁
- springmvc的作用
- 一级和二级缓存
- mybatis的作用和特点
- mybatis的$和#区别和用法
- 是占位符, 会对SQL进行预编译,相当于?; $是做sql拼接, 有SQL注入的隐患 2. #不需要关注数据类型, MyBatis自动实现数据类型转换; ${} 必须自己判断数据类型
两者都支持@param注解, 指定参数名称, 获取参数值. 推荐这种方式
一般做参数传递,都会使用#{}
如果不是做预编译,而是做拼接sql, 会使用${}, 例如表名称的变化,或者用在其他配置文件中 - 谈谈数据库事务的理解
- 聊聊涨读,幻读,不可重复读
- spring创建Bean的几种方式
- restful接口规范
- 聊聊面向对象的特征的理理
- 面向对象中的各种关键字
- 抽象类和接口的区别?
- mybatis的动态sql
- springmvc如何实现json数据交互?
- mybatis的多参数处理
- mybatis的一级和二级缓存
- 二级缓存:
- 谈谈Hashmap的扩容原理
- 聊聊Hashmap的底层结构区分1.7和1.8
- 为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键
- HashMap 中的 key若 Object类型, 则需实现哪些方法?
- 聊聊concurrenthashmap怎么实现线程安全
- 聊聊arraylist的初始容量和扩容机制
Jvm的五大内存模型(1.8前)
方法区和堆是线程共享的,在jdk1.8以后,元数据区取代了永久代,元空间的本质和永久代类似,都是对JVM规范中方法区的实现,不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存
1.4.1 方法区:
也叫元空间,线程共享,用来储存类的信息,方法,方法名,返回值,常量等,当常量池无法再申请到内存时会抛出OutOfMemoryError(内存溢出)异常
1.4.2 堆:
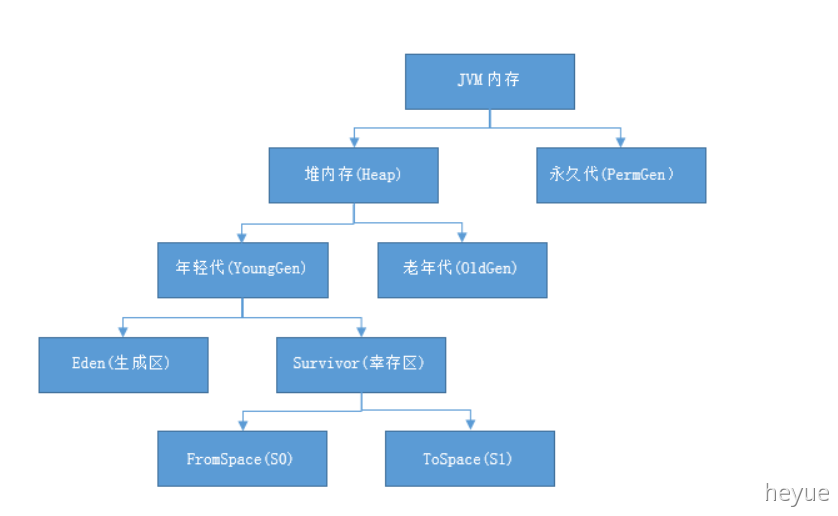
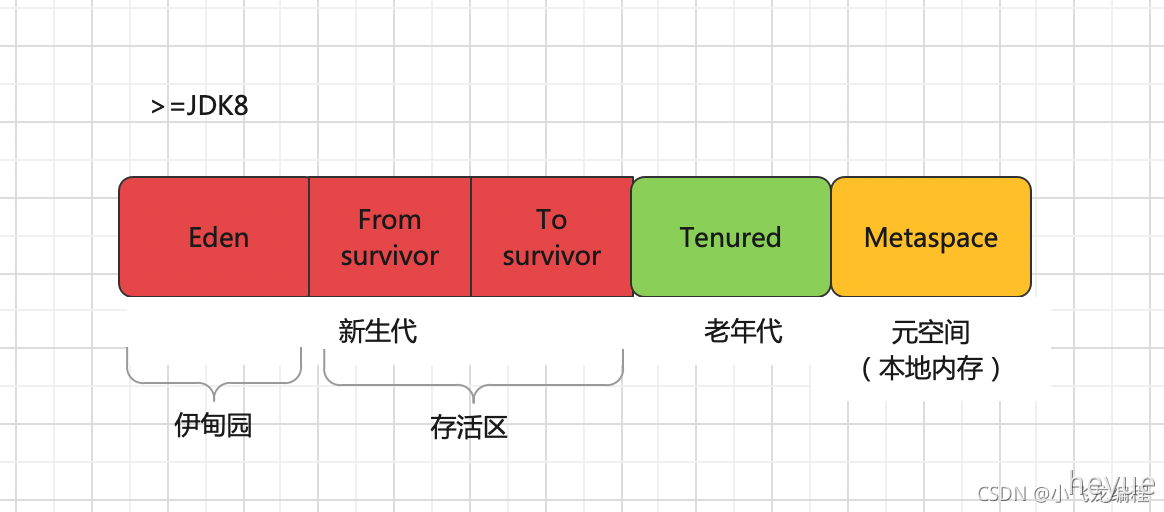
jdk1.8前的模型,java内存划分为堆内存和非堆内存,堆内存分为年轻代、老年代,非堆内存就是一个永久代。1.8以后,废弃了永久代,元空间替代,元空间处于本地内存,永久代处于虚拟机中。
堆内存用途:存放的是对象,垃圾收集器就是收集这些对象,然后根据GC算法回收。
年轻代又分为Eden和Survivor区。Survivor区由FromSpace和ToSpace组成。Eden区占大容量,Survivor两个区占小容量,默认为8:1:1
- MetaspaceSize :初始化元空间大小,控制发生GC阈值
- MaxMetaspaceSize : 限制元空间大小上限,防止异常占用过多物理内存
为什么移除永久代?
移除永久代原因:为融合HotSpot JVM与JRockit VM(新JVM技术)而做出的改变,因为JRockit没有永久代。有了元空间就不再会出现永久代OOM问题了!
HotSpot:大概就是把一个class文件通过类加载器加载进系统,然后放到不同的区域,通过编译器译。
HotSpot包括一个解释器和两个编译器(client和server,二选一),解释与编译混合执行模式,默认启动解释执行,
解释器: 解释器用来解释class文件(字节码),java是解释语言(书上这么说的)。
server启动慢,占用内存多,执行效率高,适用于服务器端应用;
client启动快,占用内存小,执行效率没有server快,默认情况下不进行动态编译,适用于桌面应用程序。
存放new出来的对象信息,全局变量,线程共享
在java中,堆被划分成两个不同的区域:新生代、老年代,这样划分的目的是为了JVM能够更好的管理堆内存中的对象,包括内存的分配以及回收。java堆是java虚拟机管理的内存中最大的一块,堆唯一的目的就是存放实例对象,
java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们磁盘空间一样。(不过在实现中既可以大小固定,也可以是可扩展,通过-Xmx 和-Xms控制)如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常
分代收集算法
经过分代之后,垃圾回收可以分成以下几类:
- 新生代回收(Minor GC | Young GC)
- 老年代回收(Major GC)
- 清理整个堆(Full GC)
由于执行Major GC的时候,也会伴随着一次Minor GC,可以认为,Major GC ≈ Full GC
下面我们来看一下对象是怎么分配到堆内存的。
对象在创建的时候,会先存放到伊甸园。当伊甸园满了之后,就会触发垃圾回收。这个回收的过程是:把伊甸园中的对象拷贝到From survivor或者是To survivor里面去。
比如说,第一次回收把对象拷贝到From survior里了,那么下一次回收就会把存活的对象从From survior拷贝到To survior,再下一次就会把To survior里的对象拷贝到From surivor,周而复始。那么不难发现,这个过程使用了复制算法,这也就是为什么新生代要有两个survior的原因。
那么对象每经历一次垃圾回收之后,那么还存活的话,他的年龄就会加一。当对象的年龄达到阈值的话(默认是15),就会晋升到老年代,老年代里的对象存活率是比较高的。
老年代一般是采用标记清除或者标记整理的思想进行回收。
注意
这里需要说明一下,这里的过程只是一个典型的分配流程。实际情况是存在例外的:
- 新建的对象不一定会分配到伊甸园,也有可能直接分配到老年代
这里主要分为两种场景:
- 对象大于-XX:PretenureSizeThreshold(默认是0),就会直接分配到老年代
- 新生代空间不够
如果你的对象非常的大,比如是一个超大数组,新生代的空间根本不够,那么这个时候也会直接放 到老年代。因为新生代采用的是复制算法,在伊甸园分配大对象的话将会导致伊甸园和两个survior 区大量的内存拷贝。
- 对象不一定要达到年龄才进入老年代
虚拟机有一个动态年龄的概念,如果Survior空间中所有相同年龄大小的总和大于Survivor空间的一半,那么年龄大于等于该年龄的对象就可以直接进老年代。
垃圾回收的触发条件
新生代(Minor GC)触发条件
伊甸园空间不足,就会进行Minor GC回收新生代
老年代(Full GC)触发条件
老年代空间不足
元空间不足
要晋升老年代的对象所占用的空间大于老年代的剩余空间。
显式调用System.gc()
建议垃圾回收器执行垃圾回收
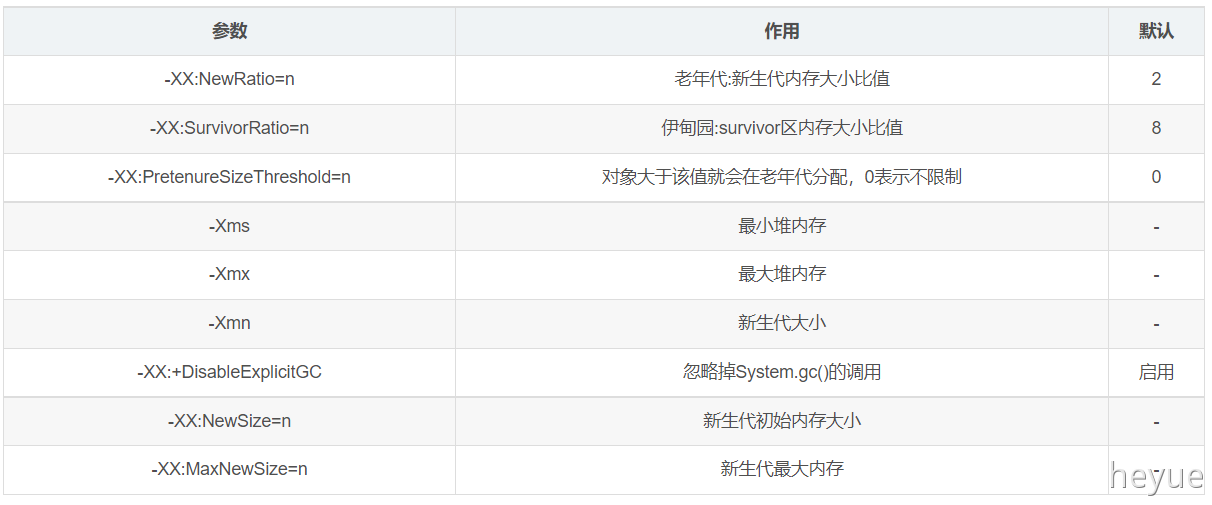
-XX: +DisableExplicitGC 参数,忽略掉System.gc()的调用
总结
分代收集算法是根据对象的生命周期,把内存作分代,然后在分配对象的时候,不同生命周期的对象放在不同的代里面,不同的代上使用合适的回收算法进行回收,比方说,新生代里面的对象存活周期一般都比较短,每次垃圾回收的时候都会发现有大量的对象死去,所以新生代可以使用复制算法来完成垃圾收集。而老年代里的对象存活率比较高,所以就采用标记清除或者标记整理进行回收。
那么相比单纯的标记清除、标记整理、复制算法,分代带来了什么好处呢?
- 分代可以更有效的清除不需要的对象。
- 提升了垃圾回收的效率
最后,我们来总结一下分代收集算法的调优原则:
- 合理设置Survivor区域大小,避免内存浪费
因为Survivor区对内存的利用率不高,如果配置过大,内存浪费就会比较严重。
- 让GC尽量发生在新生代,尽量减少Full GC的发生
1.4.3 程序计数器:
1、是一块较小的内存空间,可以看做是指向当前线程所执行的字节码的行号指示器,在虚拟机的概念模型里(仅是概念模型,各种的虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值,来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程回复等基础功能,都需要依赖计数器来完成
2、线程私有,指向当前线程正在执行的行号,用来保证线程切换时回到程序调用的位置,(例如:在a方法里面调用了b方法,代码从上往下执行,执行到调用b方法的那行时,指针会记录下这个位置,然后执行b方法里面的逻辑,b方法正常执行完成或异常退出,指针都会回到a方法里面)
3、为什么程序计数器是线程私有的?
由于java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器都只会执行一条线程中的指令,为了线程切换后能恢复到正常的执行位置,每条线程都需要一个独立的程序计数器,
4.如果线程正在执行的是一个java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Native方法,这个计数器的值则为空(Undefined)。此内存区域是唯一一个在java虚拟机规范中没有规定任何OutOfMemoryError情况的区域
1.4.4 虚拟机栈:
1.描述的是线程进出栈的过程,线程结束内存自动释放。它用来存储当前线程运行方法所需要的数据、指令、返回地址(即局部变量和正在调用的方法)。方法被调用时会在栈中开辟一块叫栈帧的空间,方法运行在栈帧空间中,栈帧出栈后,里面的局部变量就从内存里面清理掉了。
2.也是线程私有的,生命周期和线程保持一致,他是储存当前线程运行方法时所需要的数据、指令、返回地址。在每个方法执行时,虚拟机栈都会创建一个栈帧(Stack Frame),用于存储:局部变量表(基本数据类型,引用数据类型)、操作数栈、动态链接、方法出口等信息。
3.局部变量的存储空间是32位,刚好可以放一个int类型,所以长度为64位的long和double类型的数据会占用
两个局部变量空间,局部变量表的大小在编译器就已经确定了
4.在java虚拟机规范中,对java虚拟机栈规定了两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将会抛出StackOverflowError(栈溢出);如果虚拟机栈可以动态拓展(当前大部分虚拟机都可以动态拓展,只不过java虚拟机规范中也允许固定长度的虚拟机栈),拓展时无法申请到足够的内存,就会抛出OutOfMemoryError异常
1.4.5 本地方法栈:
描述的是为虚拟机用到的native方法出栈和入栈的过程
- java虚拟机栈为虚拟机执行java方法(也就是字节码)服务
- 本地方法栈为虚拟机使用到的Native方法服务
native本地方法栈中的方法
(IO流、read write、hashcode、clone)
1.4.6 jvm运行时数据区域有哪几部分组成,各自作用
1 线程共享
堆:new出来的对象放在堆中,(对象可能会有栈上分配(内存逃逸分析))
方法区(元空间):静态变量,常量,class对象
2 线程独占
栈:栈的内部由栈帧组成 先进后出;栈帧(局部变量表、操作数栈、动态链接、返回地址)
PC寄存器(程序计数器):指向当前线程执行到哪里
1.5 GC的常用回收算法
1.5.1 引用计数法:
假设有一个对象A,任何对A进行引用,那么对象A的引用计数器+1,当引用失效时,对象A的引用计数器-1,当对象A的引用计数器为0时,就说明对象A没有被引用,那么就可以进行回收
1.5.2 标记清除法:
是将垃圾回收分为两个阶段,分为标记和清除
标记:从根节点开始标记引用的对象
清除:未被标记引用的对象就是垃圾对象,可以清理掉
适用场景
适用于对象存活率高的场景。
缺陷
会产生大量的内存碎片,每次清除原有对象的同时,就会把原有对象占用的内存空间给腾出来。
仅仅只是将空间腾出来的话,就可能会导致内存的不连续,从而产生大量的内存碎片。
当程序中有一个较大的对象想要放入内存时,需要占用一大段连续内存,这时候的内存中因为都是碎片,没有连续的内存,就会导致程序再去调用算法进行垃圾回收。
1.5.3 标记压缩算法:
在标记清除算法上进行了优化,标记阶段是一样的,在清理阶段不是直接清理标记对象,而是将存活对象压缩到内存的一端,然后清理边界以外的垃圾,从而解决碎片化问题
适用场景
中规中矩,均可。
缺陷
并没有非常明显的缺点,主要还是因为解决碎片化和内存消耗过大的问题衍生出来的。
相对于标记清除算法,该算法不会产生大量碎片,是标记清除算法的改良版。
相对于复制算法,该算法不会无端占用过多的内存。
1.5.4 复制算法:
复制算法的核心就是,将原有的内存空间一分为二,每次都只使用其中的一块,在垃圾回收时将正在使用的对象复制到另一个内存空间中,然后将内存空间清空,交换两个内存角色完成垃圾回收
适用场景
适用于对象存活率低的场景,只有存活率够低,复制的时候所消耗的性能则会越低。
缺陷
缺点就是必须要有两块内存,这样就会导致本来可以任其获取的内存目前缩水了一半,这也是复制算法不能全部应用在虚拟机内存的原因。
移动的时候也会消耗一定的性能。
因为是复制+移动,所以不会留下内存碎片。
1.6 类的加载过程
加载—>链接(验证+准备+解析)—>初始化(使用前的准备)—>使用—>卸载
- 加载:加载到内存中
- 链接:
- 校验:检查字节码是否符合规范
- 准备:空间
- 解析:类变量
- 初始化:数据的初始化
- 使用
- 卸载
实例化子类,会不会产生父类对象
(1)变量是静态绑定 ,方法是动态绑定。 这里面变量在编译期间实现了变量调用语句与变量定义赋值语句的绑定,绑定的自然是父类的,因为调用时类型是父类的,所以值是父类中定义的值 。
(2)其实可以这么理解,创建了一个子类对象时,在子类对象内存中,有两份这个变量,一份继承自父类,一份子类。
(3)绝对不会产生父类对象,父类中的成员被继承到子类对象中,用指向子类对象的父类引用调用父类成员,只不过是从 子类对象内存空间中找到那个被继承来的父类成员,也就是说实质是用子类对象调用变量a,这样就可以解释成员必须通过对象调用的规定,只不过这时调用的是子类对象中的继承自父类的a(子类对象中有两个a,一个继承自父类,一个属于自己)。
class A {public int a = 0;public void test() {System.err.println(true);}public void test1() {System.err.println(this.a);this.test();System.err.println("this:" + this);}}class B extends A {public int a = 1;@Overridepublic void test() {System.err.println(false);}public static void main(String[] args) {B b = new B();System.err.println("B:" + b);System.err.println("B:" + b.a);b.test();b.test1();A a = new B();System.err.println("A:" + a);System.err.println("A:" + a.a);a.test();a.test1();}}
输出结果: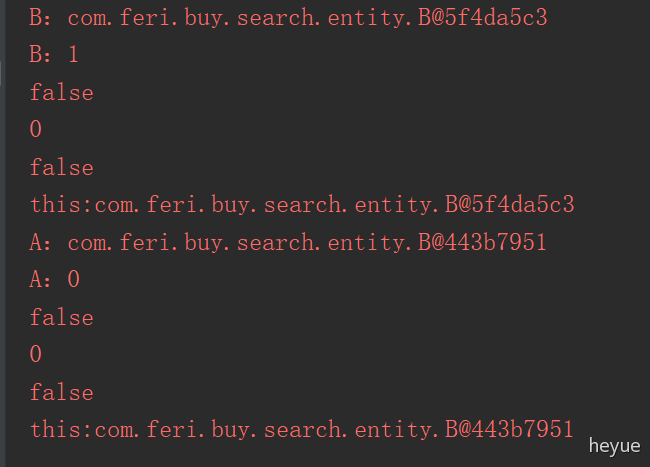
https://blog.csdn.net/qq_23401185/article/details/115002062
1.7 双亲委派模型
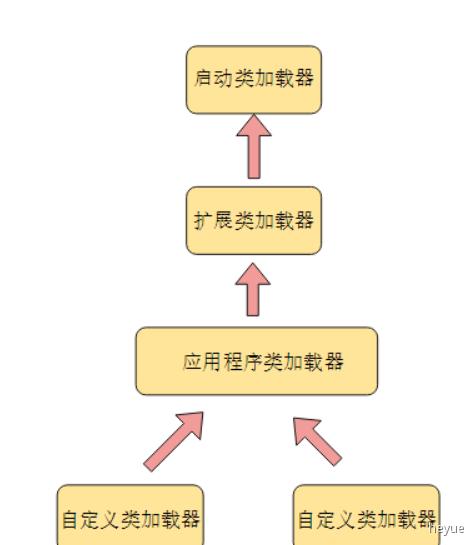
如果一个类加载器收到了类加载的请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果最终的父类加载器可以完成类加载的任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式
1.7.1 为什么要用双亲委派模型
确保类的全局唯一性
如果你自己写的一个类与核心类库中的类重名,会发现这个类可以被正常编译,但永远无法被加载运行。因为你写的这个类不会被应用类加载器加载,而是被委托到顶层,被启动类加载器在核心类库中找到了。如果没有双亲委托机制来确保类的全局唯一性,谁都可以编写一个java.lang.Object类放在classpath下,那应用程序就乱套了。
从安全的角度讲,通过双亲委托机制,Java虚拟机总是先从最可信的Java核心API查找类型,可以防止不可信的类假扮被信任的类对系统造成危害。
1.7.2 双亲委派模型打破机制
1.重写loaderClass方法
2.热部署
3.JDBC4.0以后,开始支持使用spi的方式来注册这个Driver


1.7.3 类加载器是干什么的
通过类的全限定名获取描述类的二进制字节流,这件事放在虚拟机外部,由应用程序自己决定如何实现
1.7.4 类加载器有哪些
jdk自带的有三个类加载器:bootstrapClassLoader、ExtClassLoader、AppClassLoader
bootstrapClassLoader:启动类加载器,默认负责加载%JAVA_HOME%/lib下面jar包和class文件,加载java核心类库,虚拟机识别的库,用户无法直接使用(底层为C++),其他类加载器为底层为java
rt.jar JAVA基础类库,比如Object
charset.jar java字符集类库
加载器的原理
启动类加载器的入口是callRunners方法,将实现ApplicationRunner接口的类实例增加到runners列表中,将实现CommandLineRunner接口的类实例增加到runners列表中,然后进行排序AnnotationAwareOrderComparator.sort(runners),排序完毕后,依次调用callRunner方法
ExtClassLoader:拓展类加载器,负责加载%JAVA_HOME%/lib/ext文件夹下的jar包和class类,用户可以直接使用
AppClassLoader:应用程序类加载器,负责加载classpath下的类文件(系统默认类加载器,平时开发中所写的java文件以及引入的jar包都是由此类加载器加载,不仅仅是系统类加载器,还是线程上下文加载器),用户可以直接使用
自定义类加载器:用户自己定义的类加载器
1.7.5 双亲委派模式优势
1.8 内存泄漏和内存溢出
1.8.1 内存泄漏
就是申请了内存,但是没有释放,导致内存空间浪费。通俗点就是占着茅坑不拉屎
1.8.2 内存溢出
内存溢出就是申请内存时,JVM没有足够的内存空间。通俗点就是蹲坑发现坑位满了
分为栈溢出和堆溢出
堆溢出:就是创建对象多了,并且没有回收释放空间,导致堆内存满了
栈溢出:栈太小,或者栈帧太大
1.8.3 如何判断是否有内存泄露
内存泄漏特点:因为对象不能被gc回收就会导致内存泄漏,jstack 看看经过gc之后的老年代对象是否被回收。
eg:第一次gc后老年代大小200m,第二次gc 300M,第三次gc350M,基本可以确定产生内存泄漏问题。
服务不可用,jstack 看到fgc执行次数远远大于ygc,产生内存泄漏问题。
1.8.4 OOM说一下?怎么排查?哪些会导致OOM? OOM出现在什么时候
标准的内存溢出:如后台没写分页(前端做的分页),数据量很大报内存溢出错误,报错后对象就会被回收;
内存泄漏产生的内存溢出:泄漏的对象不会被回收掉,直到对象把堆内存占满导致整个服务不可用。
定位:打印dump文件去用jvisualvm工具去查找大对象。
1.9 GC怎么判断对象是否可回收
1.引用计数器:每个对象都有一个引用属性,新增一个引用,值就加一,引用释放,值就减一,当计数为0的时候可以回收
2.可达性分析:通过一个系列名为“GC Roots”的对象作为起始点,从这个节点开始向下搜索,从而形成许多引用路径链,当一个对象没有任何一条引用链可以达到起始点时,则说明次对象已经不会再被引用,则可以回收
1.9.1 GC Roots
可作为GC Roots对象包括一下几种:
1.虚拟机栈中引用对象(栈帧中的本地变量表)
2.方法区中的类静态属性引用的对象
3.方法区中的变量引用的对象
4.本地方法栈中JNI(即一般说的Native方法)引用的对象
1.9.2 对象引用类型
强引用
- (不会回收)
类似于“Person p = new Person()”这类的引用;垃圾收集器不会回收掉被强引用的对象。
软引用
- (缓存内存快溢出时回收)
有用但非必须的对象,jdk中提供SoftReference类来实现软引用;系统在发生内存溢出异常之前,会把只被软引用的对象进行回收。用途是可以做缓存。
弱引用
- (WeakReference类都会回收)
非必须的对象,jdk中提供了WeakReference类来实现软引用,比软引用弱一些;垃圾回收不论内存是否不足都会回收只被弱引用关联的对象。弱引用类型的对象只能生存到下一次垃圾收集发生之前。一般配合引用队列
虚引用
- (PhantomReference类回收时通知)
对被引用对象的生存时间不影响;无法通过虚引用来取得一个对象实例;为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知;jdk提供PhantomReference类来实现虚引用。监听GC
1.10 GC在堆内存的工作过程
首先一个对象创建以后,首先放到年轻代中的Eden内存中, 如果存活期超过几个Survivor之后就会被转移到老年代内存中。
年轻代将内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性复制到另一块Survivor空间上,最后清理掉Eden和刚才使用过的Survivor空间。
HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是说,每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有10%的空间会被浪费
MinorGC发生在新生代的GC中,由于对象回收概率大,GC频繁且回收速度较快,采用的是复制算法
FullGC是发生在老年代的GC动作,当前主要采用的是标记-清除/整理算法,老年代里面的对象较少,且不会那么容易死掉,因此FullGC发生的次数不会那么频繁,并且一次FullGC比一次MinorGC的时间长
标记:(标记活着的对象)采用对象引用遍历,从一组GC Root对象开始(GC Root包括局部变量,静态变量及线程对象),沿着整个对象图上的每条链接,递归确定可到达(reachable)的对象。如果某对象不能从这些根对象的一个(至少一个)到达,则将它作为垃圾收集。在对象遍历阶段,GC必须记住哪些对象可以到达,以便删除不可到达的对象;
清除:GC删除不可到达的对象。删除时,有些GC只是简单的扫描堆栈,删除未标记的未标记的对象,并释放它们的内存以生成新的对象。
压缩/整理:这种方法的问题在于内存会分成好多小段,而它们不足以用于新的对象,但是可以将其组合起来。因此,许多GC可以重新组织内存中的对象,并进行压缩(compact),形成可利用的空间。
1.10.1 jvm中一次完整的GC流程(从ygc到fgc)是怎样的,重点讲讲对象如何晋升到老年代
正常流程:
经过15次的ygc(复制算法)移入老年代
大对象直接回进入老年代
非正常:
动态年龄:S区50%以上的对象年龄>S区的平均值就会进入老年代(老年代不足发生full gc)
空间分配担保:s0或者s1放不下这些对象,进行一次空间分配担保(老年代剩余空间大于历代s区进阶的平均值)担保成功,失败发生full gc
方法区不足也会发生full gc/手动执行System.gc()也会触发full gc
1.11 CMS和G1的区别
1.11.1 Stop the world
不管选择哪种GC算法,stop-the-world都是不可避免的。Stop-the-world意味着从应用中停下来并进入到GC执行过程中去。一旦Stop-the-world发生,除了GC所需的线程外,其他线程都将停止工作,中断了的线程直到GC任务结束才继续它们的任务。GC调优通常就是为了改善stop-the-world的时间。
1.11.2 CMS:
以获取最短回收停顿为目标的收集器,基于并发“标记清理”实现,采用的是标记-清理算法,标记出垃圾对象,清理垃圾对象,算法是基于老年代执行的,因为新生代产生无法接受该算法的产生的碎片垃圾
过程:
1.初始标记:独占PUC,仅标记GCroots能直接关联的对象。会让线程全部停止,也就是Stop the World状态
2.并发标记:对所有的对象进行追踪,这个阶段最耗费时间,但是这个阶段和系统并发执行,对不会系统运行造次影响
3.重新标记阶段:由于第二阶段是并发执行的,一边标记垃圾对象,一边创建新对象,老对象会变成垃圾对象。所以第三阶段也会进入Stop the world状态,并且重新标记,标记的是第二阶段中变动过的少数对象,运行速度很快
4.并发清理阶段:这个阶段也是很耗费时间的,但是由于并发运行,所以不会对系统运行造成很大的影响
1.11.1 优缺点
优点:并发收集,低停顿
缺点:1.无法处理浮动垃圾,并发收集会造成内存碎片过多
2.由于并发标记和并发清理阶段都是并发执行,所以会额外消耗CPU资源
1.11.3 G1
- 初始标记(stop the world事件 CPU停顿只处理垃圾);
- 并发标记(与用户线程并发执行);
- 最终标记(stop the world事件 ,CPU停顿处理垃圾);
- 筛选回收(stop the world事件 根据用户期望的GC停顿时间回收)
Garbage First,是Java虚拟机的垃圾收集器理论进一步发展的产物,它与前面的CMS收集器相比有两个显著的改进:一是G1收集器是基于“标记-整理”算法实现的收集器,也就是说它不会产生空间碎片,这对于长时间运行的应用系统来说非常重要。二是它可以非常精确地控制停顿,既能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒,具备了一些实时Java(RTSJ)的垃圾收集器的特征。
1.12 final、finally与finalize的区别?
1.12.1 final
是java中的关键字,用于声明属性,方法和类,分别表示属性不可交变,方法不可覆盖,类不可继承。
1.12.2 finally
1.12.3 finalize
是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,供垃圾收集时的其他资源回收,例如关闭文件等。
1.13 装箱和拆箱
装箱:就是自动将基本数据类型转换为包装器类型
拆箱:就是自动将包装器类型转换为基本数据类型
装箱过程就是通过调用包装器的valueOf方法实现的,而拆箱过程是通过调用包装器的xxxValue方法实现的(xxx代表对应的基本数据类型)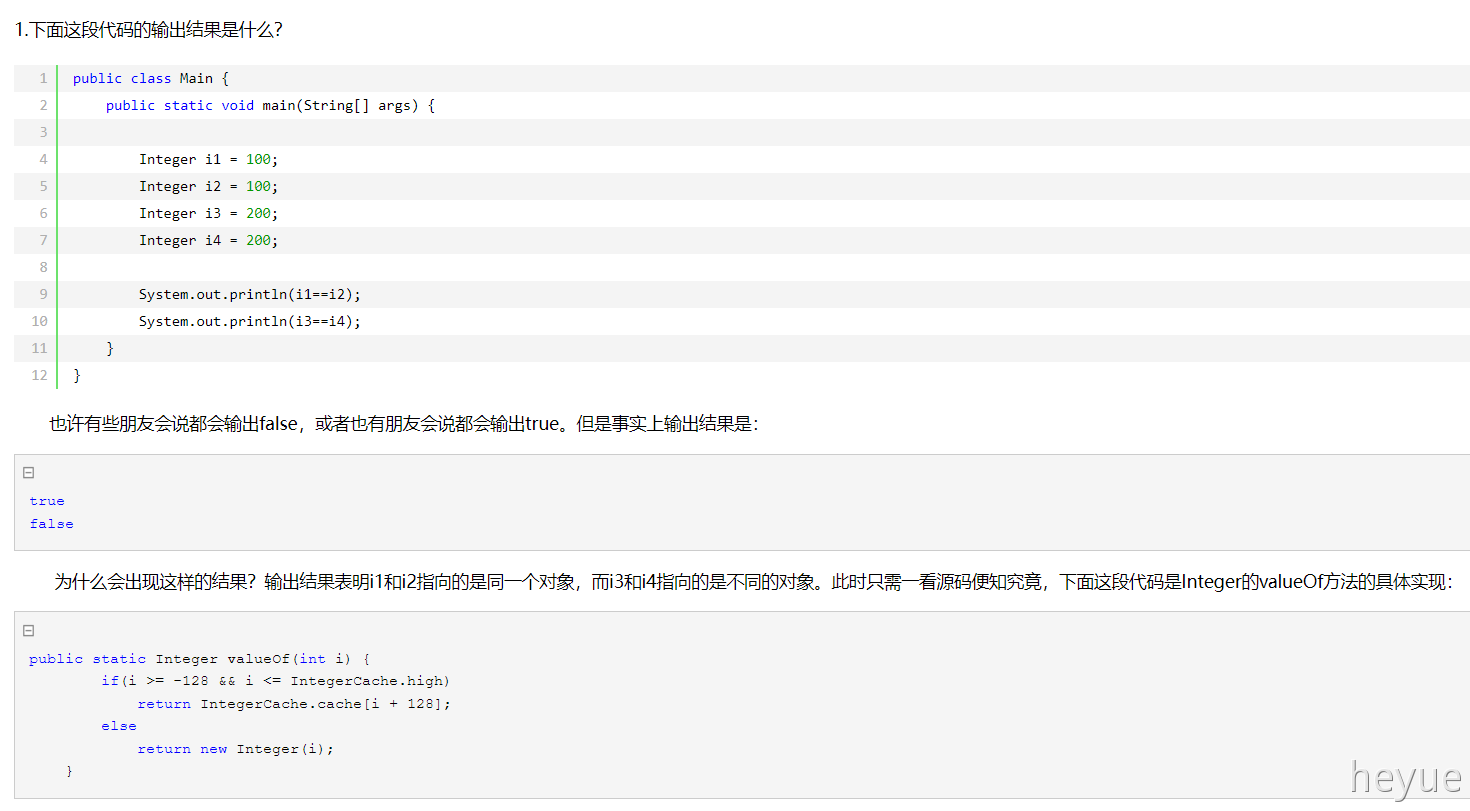
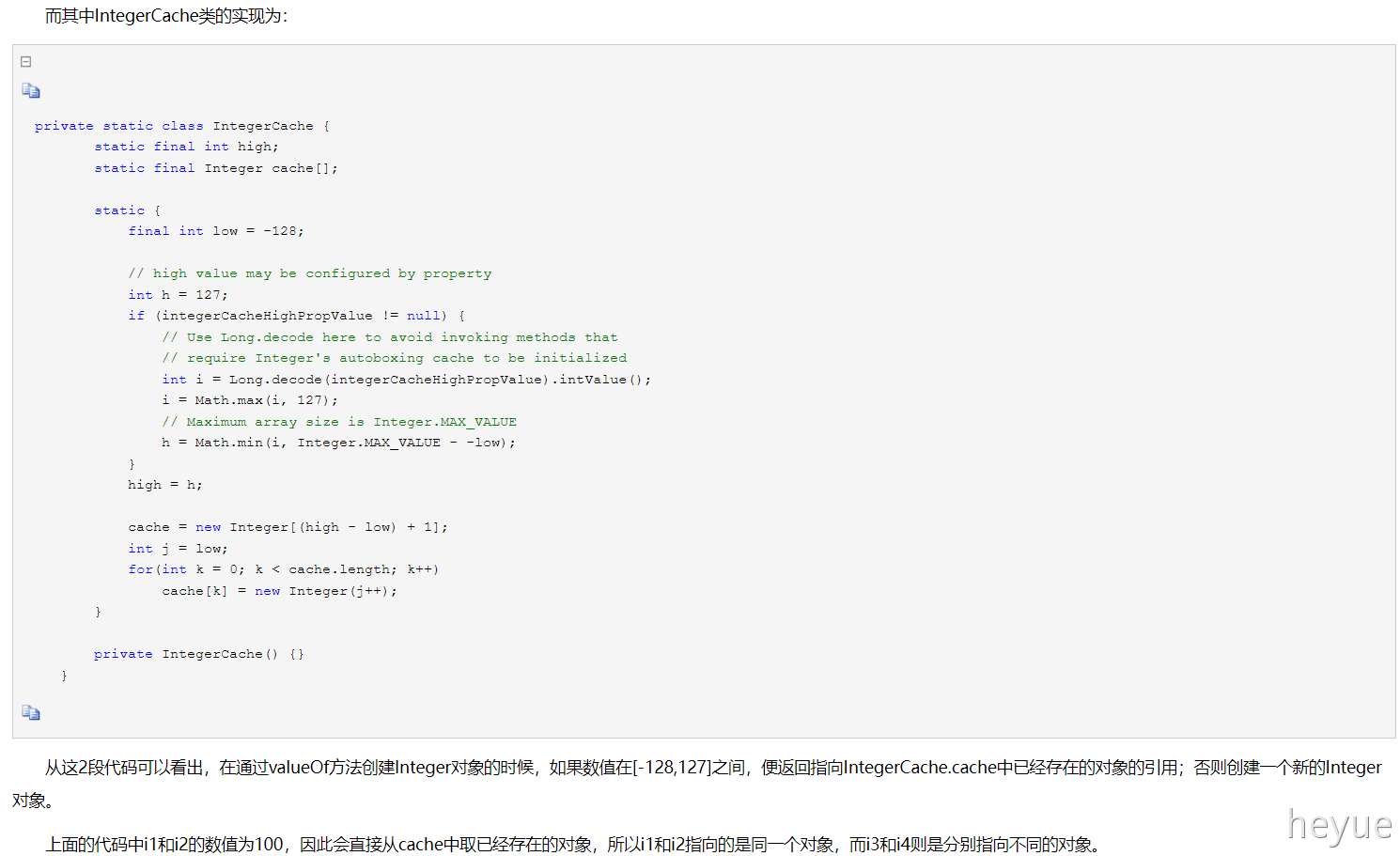
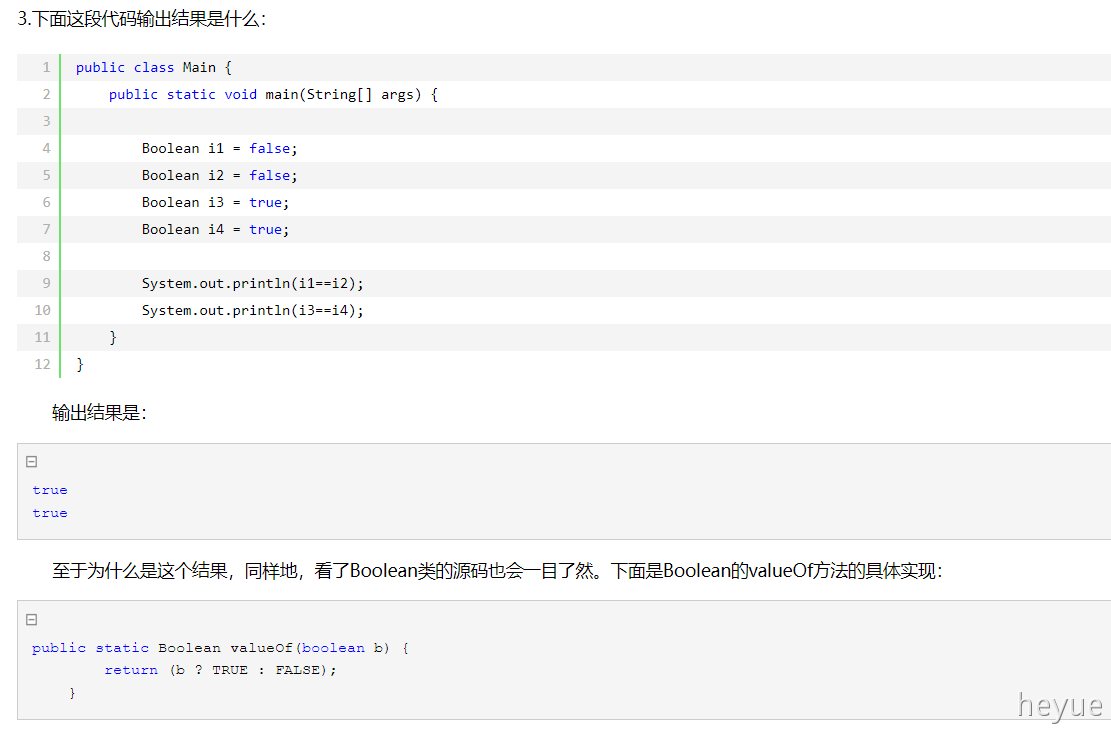
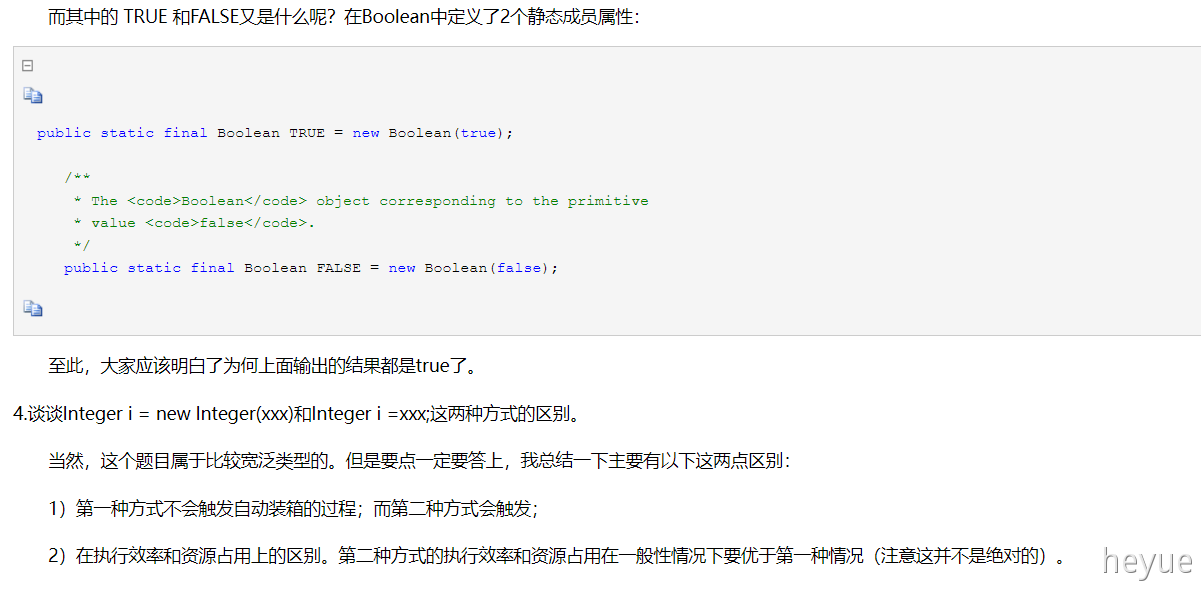
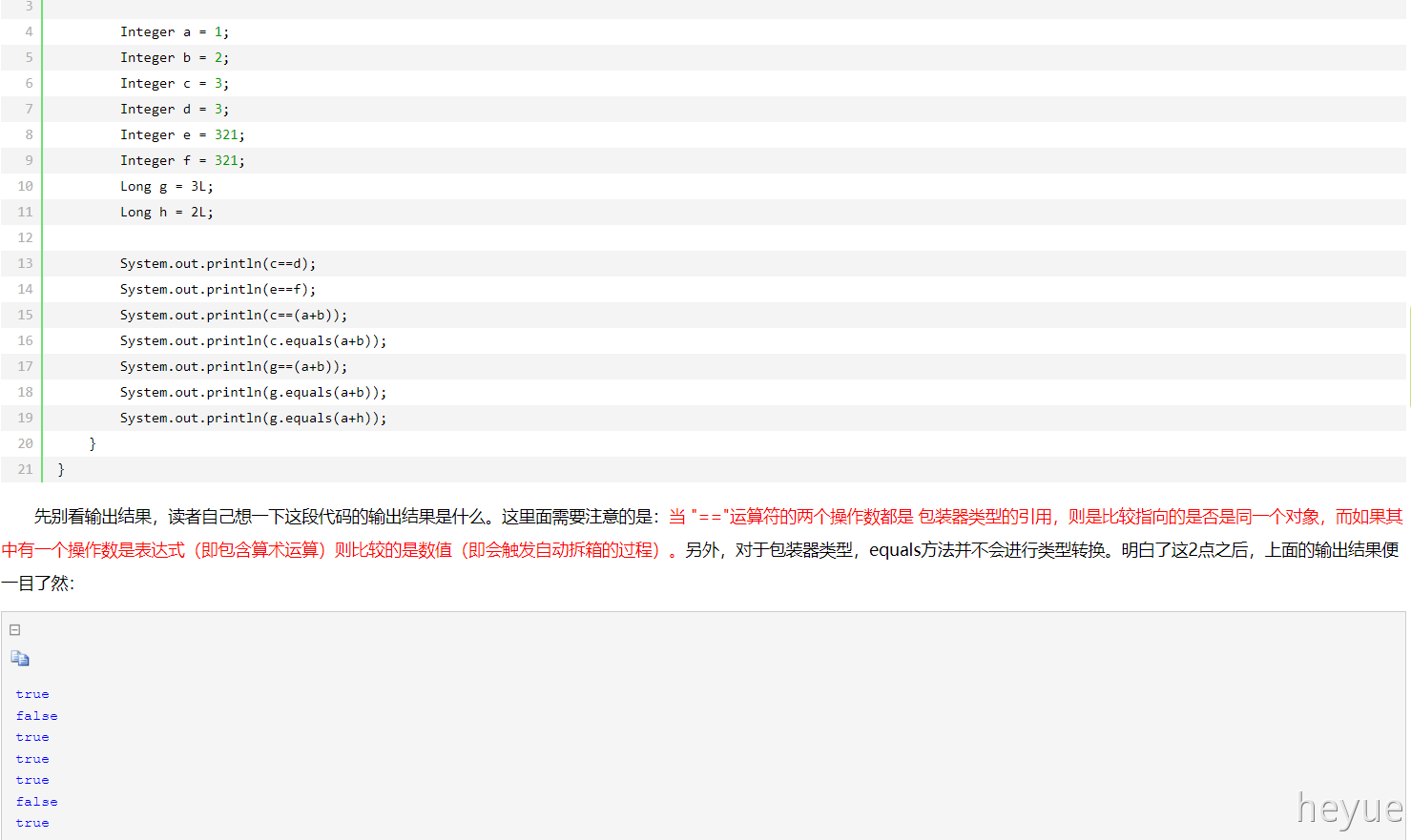

当 “==”运算符的两个操作数都是 包装器类型的引用,则是比较指向的是否是同一个对象,而如果其中有一个操作数是表达式(即包含算术运算)则比较的是数值(即会触发自动拆箱的过程)。另外,对于包装器类型,equals方法并不会进行类型转换
1.14 jvm常用的调优参数
-Xmx 堆内存最大值 -Xmx2g 默认是系统内存的1/4
-Xms 堆内存最小值 -Xms2g
一般情况下最小堆内存和最大堆内存大小设置一样,每一次扩容都会进行一次full gc,减少full gc次数。
-Xmn 设置新生代的大小 默认是堆的1/3
-Xss 设置线程栈空间大小 -Xss256k
1.14.1 JVM相关的命令-调优
在Java应用和服务出现莫名的卡顿、CPU飙升等问题时总是要分析一下对应进程的JVM状态以定位问题和解决问题并作出相应的优化,在这过程中Java自带的一些状态监控命令和图形化工具就非常方便了。本文总结了最常用的命令行工具及其常用参数解释,图形化监控工具的用法,仅供参考。
- jsp:
Java版的ps命令,查看java进程及其相关的信息,如果你想找到一个java进程的pid,那可以用jps命令替代linux中的ps命令了,简单而方便。
命令格式:
jps [options] [hostid]
options参数解释:
● -l : 输出主类全名或jar路径
● -q : 只输出LVMID
● -m : 输出JVM启动时传递给main()的参数
● -v : 输出JVM启动时显示指定的JVM参数
最常用示例:
1
2
3 jps -l 输出jar包路径,类全名
jps -m 输出main参数
jps -v 输出JVM参数 - jstack:
jstack是用来查看JVM线程快照的命令,线程快照是当前JVM线程正在执行的方法堆栈集合。使用jstack命令可以定位线程出现长时间卡顿的原因,例如死锁,死循环等。jstack还可以查看程序崩溃时生成的core文件中的stack信息。
命令格式:
jstack [-l] (连接运行中的进程)
jstack -F [-m] [-l] (连接挂起的进程)
jstack [-m] [-l] (连接core文件)
jstack [-m] [-l] [server_id@] (连接远程debug服务器)
option参数解释:
● -F 当使用jstack 无响应时,强制输出线程堆栈。
● -m 同时输出java和本地堆栈(混合模式)
● -l 额外显示锁信息
常用示例:
1 jstack -l 11666 | more
输出信息:
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.25-b02 mixed mode):
“Attach Listener” #25525 daemon prio=9 os_prio=0 tid=0x00007fd374002000 nid=0x70e8 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
Locked ownable synchronizers:
- None
……
具体的输出解释比较多,后续会有一篇博客来解释。现在想要学习的话请参考这篇博客。
- jstat
jstat命令是使用频率比较高的命令,主要用来查看JVM运行时的状态信息,包括内存状态、垃圾回收等。
命令格式:
jstat [option] LVMID [interval] [count]
其中LVMID是进程id,interval是打印间隔时间(毫秒),count是打印次数(默认一直打印)
option参数解释:
● -class class loader的行为统计
● -compiler HotSpt JIT编译器行为统计
● -gc 垃圾回收堆的行为统计
● -gccapacity 各个垃圾回收代容量(young,old,perm)和他们相应的空间统计
● -gcutil 垃圾回收统计概述
● -gccause 垃圾收集统计概述(同-gcutil),附加最近两次垃圾回收事件的原因
● -gcnew 新生代行为统计
● -gcnewcapacity 新生代与其相应的内存空间的统计
● -gcold 年老代和永生代行为统计
● -gcoldcapacity 年老代行为统计
● -gcpermcapacity 永生代行为统计
● -printcompilation HotSpot编译方法统计
常用示例及打印字段解释:
1 jstat -gcutil 11666 1000 3
11666为pid,每隔1000毫秒打印一次,打印3次
输出:
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
6.17 0.00 6.39 33.72 93.42 90.57 976 57.014 68 53.153 110.168
6.17 0.00 6.39 33.72 93.42 90.57 976 57.014 68 53.153 110.168
6.17 0.00 6.39 33.72 93.42 90.57 976 57.014 68 53.153 110.168
字段解释:
● S0 survivor0使用百分比
● S1 survivor1使用百分比
● E Eden区使用百分比
● O 老年代使用百分比
● M 元数据区使用百分比
● CCS 压缩使用百分比
● YGC 年轻代垃圾回收次数
● YGCT 年轻代垃圾回收消耗时间
● FGC 老年代垃圾回收次数
● FGCT 老年代垃圾回收消耗时间
● GCT 垃圾回收消耗总时间
1 jstat -gc 11666 1000 3
-gc和-gcutil参数类似,只不过输出字段不是百分比,而是实际的值。
输出:
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
25600.0 25600.0 0.0 1450.0 204800.0 97460.7 512000.0 172668.8 345736.0 322997.7 48812.0 44209.0 977 57.040 68 53.153 110.193
25600.0 25600.0 0.0 1450.0 204800.0 97460.7 512000.0 172668.8 345736.0 322997.7 48812.0 44209.0 977 57.040 68 53.153 110.193
25600.0 25600.0 0.0 1450.0 204800.0 97460.7 512000.0 172668.8 345736.0 322997.7 48812.0 44209.0 977 57.040 68 53.153 110.193
字段解释:
● S0C survivor0大小
● S1C survivor1大小
● S0U survivor0已使用大小
● S1U survivor1已使用大小
● EC Eden区大小
● EU Eden区已使用大小
● OC 老年代大小
● OU 老年代已使用大小
● MC 方法区大小
● MU 方法区已使用大小
● CCSC 压缩类空间大小
● CCSU 压缩类空间已使用大小
● YGC 年轻代垃圾回收次数
● YGCT 年轻代垃圾回收消耗时间
● FGC 老年代垃圾回收次数
● FGCT 老年代垃圾回收消耗时间
● GCT 垃圾回收消耗总时间 - jinfo:
jinfo是用来查看JVM参数和动态修改部分JVM参数的命令
命令格式:
jinfo [option]
options参数解释:
● -flag 打印指定名称的参数
● -flag [+|-] 打开或关闭参数
● -flag = 设置参数
● -flags 打印所有参数
● -sysprops 打印系统配置
● 打印上面两个选项
最常用示例:
其中11666为pid
查看JVM参数和系统配置
1
2
3 jinfo 11666
jinfo -flags 11666
jinfo -sysprops 11666
查看打印GC日志参数
1
2 jinfo -flag PrintGC 11666
jinfo -flag PrintGCDetails 11666
打开GC日志参数
1
2 jinfo -flag +PrintGC 11666
jinfo -flag +PrintGCDetails 11666
关闭GC日志参数
1
2 jinfo -flag -PrintGC 11666
jinfo -flag -PrintGCDetails 11666
还可以使用下面的命令查看那些参数可以使用jinfo命令来管理:
1 java -XX:+PrintFlagsFinal -version | grep manageable
常用JVM参数:
-Xms:初始堆大小,默认为物理内存的1/64(<1GB);默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制
-Xmx:最大堆大小,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制
-Xmn:新生代的内存空间大小,注意:此处的大小是(eden+ 2 survivor space)。与jmap -heap中显示的New gen是不同的。整个堆大小=新生代大小 + 老生代大小 + 永久代大小。
在保证堆大小不变的情况下,增大新生代后,将会减小老生代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-XX:SurvivorRatio:新生代中Eden区域与Survivor区域的容量比值,默认值为8。两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10。
-Xss:每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。应根据应用的线程所需内存大小进行适当调整。在相同物理内存下,
减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。一般小的应用, 如果栈不是很深, 应该是128k够用的,
大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。和threadstacksize选项解释很类似,官方文档似乎没有解释,
在论坛中有这样一句话:”-Xss is translated in a VM flag named ThreadStackSize”一般设置这个值就可以了。
-XX:PermSize:设置永久代(perm gen)初始值。默认值为物理内存的1/64。
-XX:MaxPermSize:设置持久代最大值。物理内存的1/4。 - jmap:
jmap是用来生成堆dump文件和查看堆相关的各类信息的命令,例如查看finalize执行队列,heap的详细信息和使用情况。
命令格式:
jmap [option] (连接正在执行的进程)
jmap [option]jmap [option] [server_id@] (链接远程服务器)
option参数解释:
● to print same info as Solaris pmap
● -heap 打印java heap摘要
● -histo[:live] 打印堆中的java对象统计信息
● -clstats 打印类加载器统计信息
● -finalizerinfo 打印在f-queue中等待执行finalizer方法的对象
● -dump: 生成java堆的dump文件
dump-options:
live 只转储存活的对象,如果没有指定则转储所有对象
format=b 二进制格式
file= 转储文件到
● -F 强制选项
常用示例:
1 jmap -dump:live,format=b,file=dump.hprof 11666
输出:
1
2 Dumping heap to /dump.hprof …
Heap dump file created
这个命令是要把java堆中的存活对象信息转储到dump.hprof文件
1 jmap -finalizerinfo 11666
输出:
1
2
3
4
5 Attaching to process ID 11666, please wait…
Debugger attached successfully.
Server compiler detected.
JVM version is 24.71-b01
Number of objects pending for finalization: 0
输出结果的含义为当前没有在等待执行finalizer方法的对象
1 jmap -heap 11666
输出堆的详细信息
输出:
Attaching to process ID 11666, please wait…
Debugger attached successfully.
Server compiler detected.
JVM version is 25.25-b02
using thread-local object allocation.
Parallel GC with 4 thread(s)
Heap Configuration: //堆内存初始化配置
MinHeapFreeRatio = 0 //对应jvm启动参数-XX:MinHeapFreeRatio设置JVM堆最小空闲比率(default 40)
MaxHeapFreeRatio = 100 //对应jvm启动参数 -XX:MaxHeapFreeRatio设置JVM堆最大空闲比率(default 70)
MaxHeapSize = 1073741824 (1024.0MB) //对应jvm启动参数-XX:MaxHeapSize=设置JVM堆的最大大小
NewSize = 22020096 (21.0MB) //对应jvm启动参数-XX:NewSize=设置JVM堆的新生代的默认大小
MaxNewSize = 357564416 (341.0MB) //对应jvm启动参数-XX:MaxNewSize=设置JVM堆的新生代的最大大小
OldSize = 45088768 (43.0MB) //对应jvm启动参数-XX:OldSize=:设置JVM堆的老年代的大小
NewRatio = 2 //对应jvm启动参数-XX:NewRatio=:新生代和老生代的大小比率
SurvivorRatio = 8 //对应jvm启动参数-XX:SurvivorRatio=设置新生代中Eden区与Survivor区的大小比值
MetaspaceSize = 21807104 (20.796875MB) // 元数据区大小
CompressedClassSpaceSize = 1073741824 (1024.0MB) //类压缩空间大小
MaxMetaspaceSize = 17592186044415 MB //元数据区最大大小
G1HeapRegionSize = 0 (0.0MB) //G1垃圾收集器每个Region大小
Heap Usage: //堆内存使用情况
PS Young Generation
Eden Space: //Eden区内存分布
capacity = 17825792 (17.0MB) //Eden区总容量
used = 12704088 (12.115562438964844MB) //Eden区已使用
free = 5121704 (4.884437561035156MB) //Eden区剩余容量
71.26801434685203% used //Eden区使用比率
From Space: //其中一个Survivor区的内存分布
capacity = 2097152 (2.0MB)
used = 1703936 (1.625MB)
free = 393216 (0.375MB)
81.25% used
To Space: //另一个Survivor区的内存分布
capacity = 2097152 (2.0MB)
used = 0 (0.0MB)
free = 2097152 (2.0MB)
0.0% used
PS Old Generation
capacity = 52428800 (50.0MB) //老年代容量
used = 28325712 (27.013504028320312MB) //老年代已使用
free = 24103088 (22.986495971679688MB) //老年代空闲
54.027008056640625% used //老年代使用比率
15884 interned Strings occupying 2075304 bytes.
1 jmap -histo:live 11666 | more
输出存活对象统计信息
输出:
num #instances #bytes class name
1: 46608 1111232 java.lang.String
2: 6919 734516 java.lang.Class
3: 4787 536164 java.net.SocksSocketImpl
4: 15935 497100 java.util.concurrent.ConcurrentHashMap$Node
5: 28561 436016 java.lang.Object
- jhat:
jhat是用来分析jmap生成dump文件的命令,jhat内置了应用服务器,可以通过网页查看dump文件分析结果,jhat一般是用在离线分析上。
命令格式:
1 jhat [option] [dumpfile]
option参数解释:
● -stack false: 关闭对象分配调用堆栈的跟踪
● -refs false: 关闭对象引用的跟踪
● -port : HTTP服务器端口,默认是7000
● -debug : debug级别
0: 无debug输出
1: Debug hprof file parsing
2: Debug hprof file parsing, no server
● -version 分析报告版本
常用示例:
1 jhat dump.hprof
- top:
多核 cpu 显示每核信息,在上面基础上按 1 即可。
1.15 你知道哪几种垃圾收集器,各自的优缺点,重点讲下cms

Serial:单线程收集 非单核服务STW比较长
ParNew:多核情况下执行速度比较快(和cms一起使用)
Ps:重点在吞吐量:(用户线程执行时间)/(用户线程执行时间+gc执行时间)
CMS大体分为4部分
CMS收集器:Mostly-Concurrent收集器,也称并发标记清除收集器(Concurrent Mark-Sweep GC,CMS收集器),它管理新生代的方式与Parallel收集器和Serial收集器相同,而在老年代则是尽可能得并发执行,每个垃圾收集器周期只有2次短停顿。
初始标记:标记老年代直接与gc root相关连的对象 (STW)
并发标记:上面标记的gcroot对象下关联的对象(非直接),用户线程会和gc一起执行
重新标记:标记那些新生代可达却引用到老年代的对象,还有一些刚进来老年代的对象(STW)
并发清除:清除老年代没有做标记的对象(和用户线程一起执行)
1.15.1 SWT
Java中Stop-The-World机制简称STW,是在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起(除了垃圾收集帮助器之外)。Java中一种全局暂停现象,全局停顿,所有Java代码停止,native代码可以执行,但不能与JVM交互;这些现象多半是由于gc引起。
GC时的Stop the World(STW)是大家最大的敌人。但可能很多人还不清楚,除了GC,JVM下还会发生停顿现象。
JVM里有一条特殊的线程--VM Threads,专门用来执行一些特殊的VM Operation,比如分派GC,thread dump等,这些任务,都需要整个Heap,以及所有线程的状态是静止的,一致的才能进行。所以JVM引入了安全点(Safe Point)的概念,想办法在需要进行VM Operation时,通知所有的线程进入一个静止的安全点。
除了GC,其他触发安全点的VM Operation包括:
- JIT相关,比如Code deoptimization, Flushing code cache ;
- Class redefinition (e.g. javaagent,AOP代码植入的产生的instrumentation) ;
- Biased lock revocation 取消偏向锁 ;
- Various debug operation (e.g. thread dump or deadlock check);
监控安全点看看JVM到底发生了什么?
最简单的做法,在JVM启动参数的GC参数里,多加一句:
-XX:+PrintGCApplicationStoppedTime
它就会把全部的JVM停顿时间(不只是GC),打印在GC日志里。
2016-08-22T00:19:49.559+0800: 219.140: Total time for which application threads were stopped: 0.0053630 seconds
这是个很有用的必配参数,可以打出几乎一切的停顿……
但是,在JDK1.7.40以前的版本,它居然没有打印时间戳,所以只能知道JVM停了多久,但不知道什么时候停的。此时一个土办法就是加多一句“ -XX:+PrintGCApplicationConcurrentTime”,打印JVM在两次停顿之间的正常运行时间(同样没有时间戳),但好歹能配合有时间戳的GC日志,反推出Stop发生的时间了。
2016-08-22T00:19:50.183+0800: 219.764: Application time: 5.6240430 seconds
如何打印出事哪种原因导致的停顿呢?
再多加两个参数:-XX:+PrintSafepointStatistics -XX: PrintSafepointStatisticsCount=1
此时,在stdout中会打出类似的内容
vmop [threads: total initially_running wait_to_block]1913.425: GenCollectForAllocation [ 55 2 0 ] [time: spin block sync cleanup vmop] page_trap_count[ 0 0 0 0 6 ] 0
此日志分两段,第一段是时间戳,VM Operation的类型,以及线程概况
total: 安全点里的总线程数
initially_running: 安全点时开始时正在运行状态的线程数
wait_to_block: 在VM Operation开始前需要等待其暂停的线程数
第二行是到达安全点时的各个阶段以及执行操作所花的时间,其中最重要的是vmop
spin: 等待线程响应
safepoint号召的时间
block: 暂停所有线程所用的时间
sync: 等于 spin+block,这是从开始到进入安全点所耗的时间,可用于判断进入安全点耗时
cleanup: 清理所用时间
vmop: 真正执行VM Operation的时间
可见,那些很多但又很短的安全点,全都是RevokeBias,详见 偏向锁实现原理, 高并发的应用一般会干脆在启动参数里加一句”-XX:-UseBiasedLocking”取消掉它。另外还看到有些类型是no vm operation, 文档上说是保证每秒都有一次进入安全点(如果这秒已经GC过就不用了),给一些需要在安全点里进行,又非紧急的操作使用,比如一些采样型的Profiler工具,可用-DGuaranteedSafepointInterval来调整,不过实际看它并不是每秒都会发生,时间不定。
在实战中,我们利用安全点日志,发现过有程序定时调用Thread Dump等等情况。不过因为安全点日志默认输出到stdout,因为性能及stdout日志的整洁性等原因,我们平时默认没有开启它。只有在需要时才打开。
再再增加下面三个参数,可以知道更多VM里发生的事情。可惜JVM不会因为设了这三个参数,就把安全点日志转移到vm.log里面来,而是白白打印了两次。
-XX:+UnlockDiagnosticVMOptions -XX:+LogVMOutput -XX:LogFile=/dev/shm/vm.log
1.16 方法的重载
方法名一致,参数列表中参数的顺序,类型,个数不同。
重载与方法的返回值无关,存在于父类和子类,同类中。
可以抛出不同的异常,可以有不同修饰符。
1.17 方法的重写
父类private方法不能被重写
参数列表、方法名、返回值类型必须完全一致,构造方法不能被重写;声明为 final 的方法
不能被重写;声明为 static 的方法不存在重写(重写和多态联合才有意义);访问权限不能比
父类更低;重写之后的方法不能抛出更宽泛的异常
1.18 创建对象的五种方式

1.18 深拷贝和浅拷贝
深拷贝
package com.ys.test;public class Person implements Cloneable{public String pname;public int page;public Address address;public Person() {}public Person(String pname,int page){this.pname = pname;this.page = page;this.address = new Address();}@Overrideprotected Object clone() throws CloneNotSupportedException {return super.clone();}public void setAddress(String provices,String city ){address.setAddress(provices, city);}public void display(String name){System.out.println(name+":"+"pname=" + pname + ", page=" + page +","+ address);}public String getPname() {return pname;}public void setPname(String pname) {this.pname = pname;}public int getPage() {return page;}public void setPage(int page) {this.page = page;}}
package com.ys.test;public class Address {private String provices;private String city;public void setAddress(String provices,String city){this.provices = provices;this.city = city;}@Overridepublic String toString() {return "Address [provices=" + provices + ", city=" + city + "]";}}
这是一个我们要进行赋值的原始类 Person。下面我们产生一个 Person 对象,并调用其 clone 方法复制一个新的对象。
注意:调用对象的 clone 方法,必须要让类实现 Cloneable 接口,并且覆写 clone 方法。
测试:
@Testpublic void testShallowClone() throws Exception{Person p1 = new Person("zhangsan",21);p1.setAddress("湖北省", "武汉市");Person p2 = (Person) p1.clone();System.out.println("p1:"+p1);System.out.println("p1.getPname:"+p1.getPname().hashCode());System.out.println("p2:"+p2);System.out.println("p2.getPname:"+p2.getPname().hashCode());p1.display("p1");p2.display("p2");p2.setAddress("湖北省", "荆州市");System.out.println("将复制之后的对象地址修改:");p1.display("p1");p2.display("p2");}
打印结果为: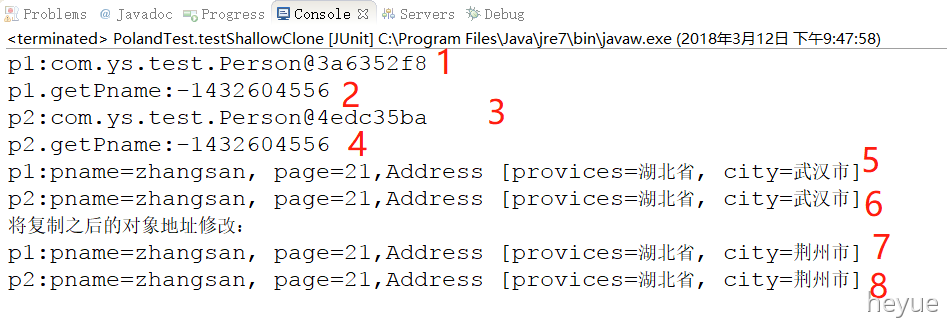
首先看原始类 Person 实现 Cloneable 接口,并且覆写 clone 方法,它还有三个属性,一个引用类型 String定义的 pname,一个基本类型 int定义的 page,还有一个引用类型 Address ,这是一个自定义类,这个类也包含两个属性 pprovices 和 city 。
接着看测试内容,首先我们创建一个Person 类的对象 p1,其pname 为zhangsan,page为21,地址类 Address 两个属性为 湖北省和武汉市。接着我们调用 clone() 方法复制另一个对象 p2,接着打印这两个对象的内容。
从第 1 行和第 3 行打印结果:
p1:com.ys.test.Person@349319f9
p2:com.ys.test.Person@258e4566
可以看出这是两个不同的对象。
从第 5 行和第 6 行打印的对象内容看,原对象 p1 和克隆出来的对象 p2 内容完全相同。
代码中我们只是更改了克隆对象 p2 的属性 Address 为湖北省荆州市(原对象 p1 是湖北省武汉市) ,但是从第 7 行和第 8 行打印结果来看,原对象 p1 和克隆对象 p2 的 Address 属性都被修改了。
也就是说对象 Person 的属性 Address,经过 clone 之后,其实只是复制了其引用,他们指向的还是同一块堆内存空间,当修改其中一个对象的属性 Address,另一个也会跟着变化。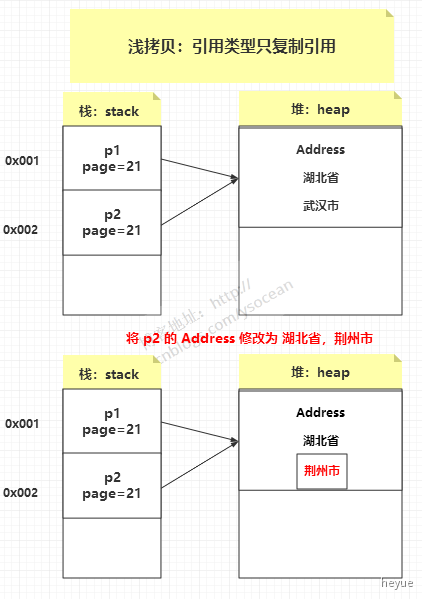
浅拷贝:创建一个新对象,然后将当前对象的非静态字段复制到该新对象,如果字段是值类型的,那么对该字段执行复制;如果该字段是引用类型的话,则复制引用但不复制引用的对象。因此,原始对象及其副本引用同一个对象。
浅拷贝
弄清楚了浅拷贝,那么深拷贝就很容易理解了。
深拷贝:创建一个新对象,然后将当前对象的非静态字段复制到该新对象,无论该字段是值类型的还是引用类型,都复制独立的一份。当你修改其中一个对象的任何内容时,都不会影响另一个对象的内容。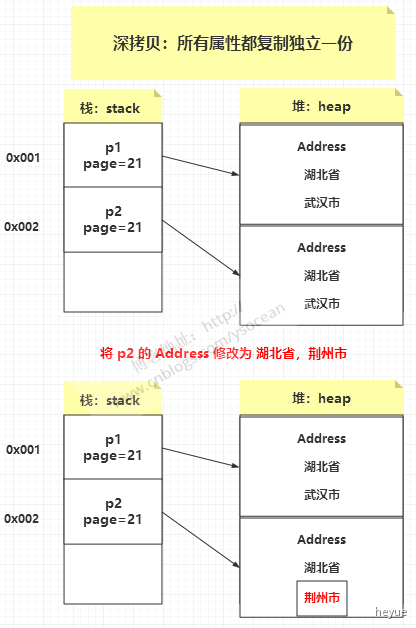
那么该如何实现深拷贝呢?Object 类提供的 clone 是只能实现 浅拷贝的。
如何实现深拷贝
深拷贝的原理我们知道了,就是要让原始对象和克隆之后的对象所具有的引用类型属性不是指向同一块堆内存,这里有三种实现思路。
①、让每个引用类型属性内部都重写clone() 方法
既然引用类型不能实现深拷贝,那么我们将每个引用类型都拆分为基本类型,分别进行浅拷贝。比如上面的例子,Person 类有一个引用类型 Address(其实String 也是引用类型,但是String类型有点特殊,后面会详细讲解),我们在 Address 类内部也重写 clone 方法。如下:
Address.class:
package com.ys.test;public class Address implements Cloneable{private String provices;private String city;public void setAddress(String provices,String city){this.provices = provices;this.city = city;}@Overridepublic String toString() {return "Address [provices=" + provices + ", city=" + city + "]";}@Overrideprotected Object clone() throws CloneNotSupportedException {return super.clone();}}
Person.class 的 clone() 方法:
@Overrideprotected Object clone() throws CloneNotSupportedException {Person p = (Person) super.clone();p.address = (Address) address.clone();return p;}
测试还是和上面一样,我们会发现更改了p2对象的Address属性,p1 对象的 Address 属性并没有变化。
但是这种做法有个弊端,这里我们Person 类只有一个 Address 引用类型,而 Address 类没有,所以我们只用重写 Address 类的clone 方法,但是如果 Address 类也存在一个引用类型,那么我们也要重写其clone 方法,这样下去,有多少个引用类型,我们就要重写多少次,如果存在很多引用类型,那么代码量显然会很大,所以这种方法不太合适。
②、利用序列化
序列化是将对象写到流中便于传输,而反序列化则是把对象从流中读取出来。这里写到流中的对象则是原始对象的一个拷贝,因为原始对象还存在 JVM 中,所以我们可以利用对象的序列化产生克隆对象,然后通过反序列化获取这个对象。
注意每个需要序列化的类都要实现 Serializable 接口,如果有某个属性不需要序列化,可以将其声明为 transient,即将其排除在克隆属性之外。
//深度拷贝public Object deepClone() throws Exception{// 序列化ByteArrayOutputStream bos = new ByteArrayOutputStream();ObjectOutputStream oos = new ObjectOutputStream(bos);oos.writeObject(this);// 反序列化ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());ObjectInputStream ois = new ObjectInputStream(bis);return ois.readObject();}
因为序列化产生的是两个完全独立的对象,所有无论嵌套多少个引用类型,序列化都是能实现深拷贝的。
2 锁
2.1 谈谈CAS和ABA,
与synchronzied修饰方法(静态代码、实例方法)、静态代码块不同的是,CAS使用compareAndSwap()保证无锁执行线程安全。
synchronzied是悲观锁,悲观认为程序中的并发问题十分严重,所以严防死守,只让一个线程操作该代码块
CAS属于乐观锁,乐观锁认为程序中的并发问题不那么严重,所以让线程不断的去尝试更新
Compare(V E N)方法,
V:表示以前记录要更新的变量的值,
E:表示内存中的值
N:表示要更新的新的值
ABA问题:多个线程同时使用CAS操作一个变量的时候,如果要更新的变量的值和当前内存中的值不一样,表示当前变量已经被某线程执行了修改操作并刷新到了内存中,此时更新新值失败,更新失败可以重新进行更新,也可以放弃更新,如果要更新的变量的值和当前的内存中的值是一样的,表示没有其他线程修改了该值(也可能是修改了,但是又重新改了过来,这就是ABA问题)
通过CAS的方式能够实现多个线程无锁并发执行,多个线程操作一个变量的时候只能有一个线程胜出,其他线程可以继续尝试或者放弃,CAS不会出现死锁状态



ABA问题如下:





2.1.1 添加版本号解决ABA问题


2.2 对象的锁升级过程(无锁、偏向锁、轻量级锁、重量级锁)?
锁的状态一共有四种:无锁、偏向锁、轻量级锁、重量级锁,在JDK1.6以前,synchronize还是一个重量级锁
四种状态随着竞争的情况逐渐升级,不可逆的过程,锁只能升级(由低级到高级),不能降级(由高级到低级)
Synchronize最初的实现方式:阻塞或唤醒一个java线程需要操作系统切换CPU状态来完成,这种状态切换需要耗费处理器时间,如果同步代码块中内容过于简单,这种切换的时间可能比用户代码执行的时间还长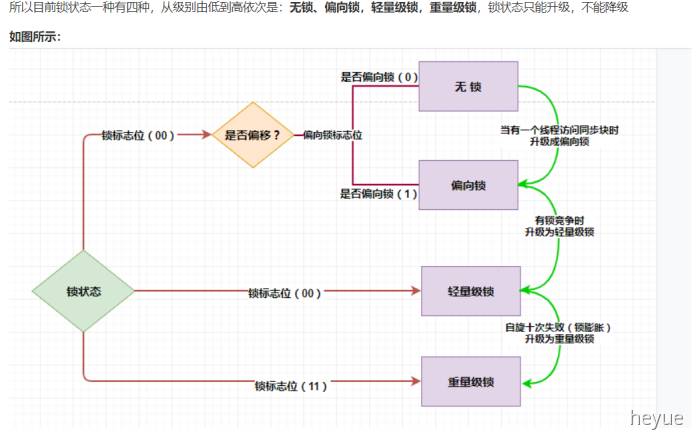
锁是如何存储的
我们每个人在学习java中接触到的最多的一句话之一我想肯定是:一切皆对象。锁就是一个对象,那么这个对象里面的结构是怎么样的呢,锁对象里面都保存了哪些信息呢?
在Hotspot 虚拟机中,对象在内存中的存储布局,可以分为三个区域:对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)。synchronized用的锁是存在Java对象头里的,Java对象头里面包含两部分信息:
第一部分官方称之为“Mark Word” ,用于存储自身的运行时数据,如:HashCode,GC分代年龄,锁标记、偏向锁线程ID等;第二部分是类型指针,即对象指向它的类元信息,虚拟机通过这个指针来确定这个对象是哪个类的实例(如果java对象是一个数组,那么对象头中还必须有一块用于记录数组长度的数据)
Mark Word 记录了对象和锁有关的信息。Mark Word 在 64 位 JVM 中的长度是 64bit,我们可以一起看下 64 位 JVM 的存储结构是怎么样的。如下图所示: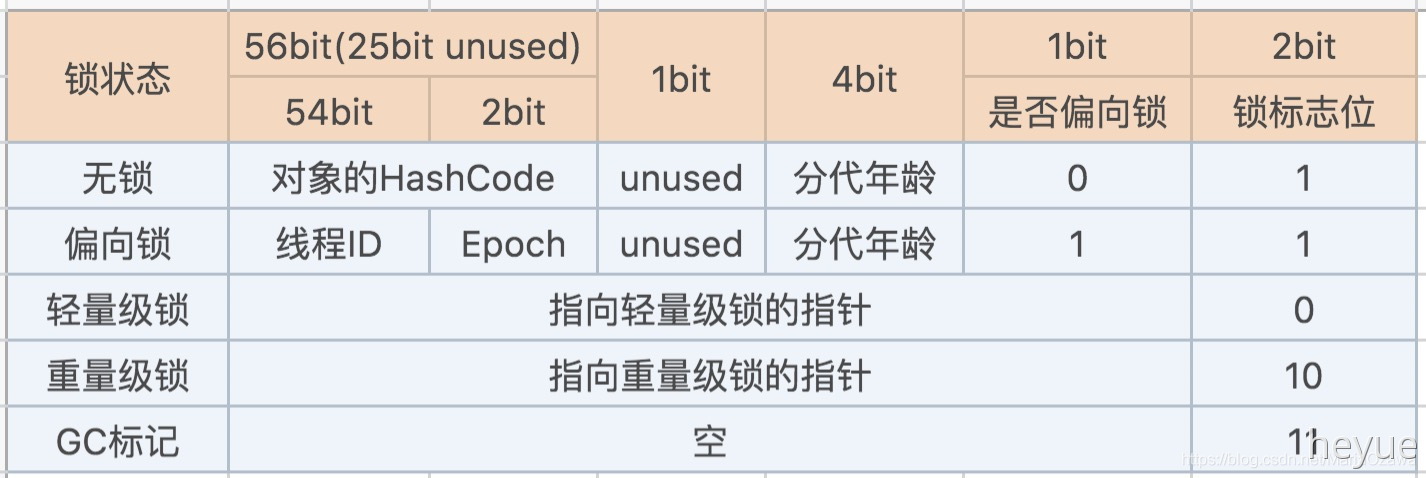
synchronized 锁升级
在多线程并发编程中synchronized 一直是元老级角色,很多人都会称呼它为重量级锁。但是随着Java SE 1.6 对synchronized 进行了各种优化之后,有些情况下它就并不那么重,Java SE 1.6 中为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁。
在Java SE 1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率
偏向锁
HotSpot的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,所以为了让线程获得锁的代价更低而引入了偏向锁。
当一个线程访问加了同步锁的代码块时,会在对象头中存储当前线程的 ID,后续这个线程进入和退出这段加了同步锁的代码块时,不需要再次加锁和释放锁。而是直接比较对象头里面是否存储了指向当前线程的线程ID。如果相等表示偏向锁是偏向于当前线程的,就不需要再尝试获得锁了。
偏向锁的获取
1、首先获取锁对象头中的 Mark Word,判断当前对象是否处于可偏向状态(即当前没有对象获得偏向锁)。
2、如果是可偏向状态,则通过CAS原子操作,把当前线程的ID
写入到 MarkWord,如果CAS成功,表示获得偏向锁成功,会将偏向锁标记设置为1,且将当前线程的ID写入Mark Word;如果CAS失败则说明当前有其他线程获得了偏向锁,同时也说明当前环境存在锁竞争,这时候就需要将已获得偏向锁的线程中的偏向锁撤销掉,并升级为轻量级锁(偏向锁的撤销,需要等待全局安全点,即在这个时间点上没有正在执行的字节码)。
3、如果当前线程是已偏向状态,需要检查Mark Word中的ThreadID是否和自己相等,如果相等则不需要再次获得锁,可以直接执行同步代码块,如果不相等,说明当前偏向的是其他线程,需要撤销偏向锁并升级到轻量级锁
偏向锁的撤销
偏向锁的撤销并不是把对象恢复到无锁可偏向状态(因为偏向锁并不存在锁释放的概念),而是在获取偏向锁的过程中,发现CAS失败也就是存在线程竞争时,直接把被偏向的锁对象升级到被加了轻量级锁的状态。对原持有偏向锁的线程进行撤销时,原获得偏向锁的线程
有两种情况:
原获得偏向锁的线程如果已经退出了临界区,也就是同步代码块执行完了,那么这个时候会把对象头设置成无锁状态,同时正在争抢锁的线程可以基于 CAS 重新偏向当前线程。
如果原获得偏向锁的线程的同步代码块还没执行完,处于临界区之内,这个时候会把原获得偏向锁的线程升级为轻量级锁后继续执行同步代码块。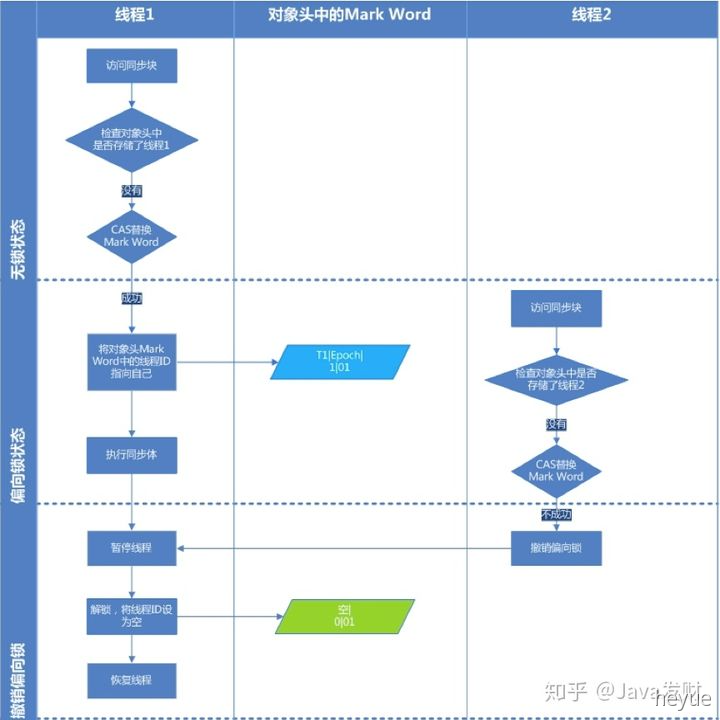
偏向锁注意事项
偏向锁在Java SE 1.6和Java SE 1.7里是默认启用的,但是它在应用程序启动几秒钟之后才激活,如有必要可以使用JVM参数来关闭延迟:-XX:BiasedLockingStartupDelay=0。如果你确定应用程序里所有的锁通常情况下都处于竞争状态,可以通过JVM参数关闭偏向锁:-XX:- UseBiasedLocking=false,那么程序默认会进入轻量级锁状态。
如果我们的应用中大多数情况存在线程竞争,那么建议是关闭偏向锁,因为开启反而会因为偏向锁撤销操作而引起更多的资源消耗。
轻量级锁
轻量级锁,一般用于两个线程在交替使用锁的时候,由于没有同时抢锁,属于一种比较和谐的状态,就可以使用轻量级锁。
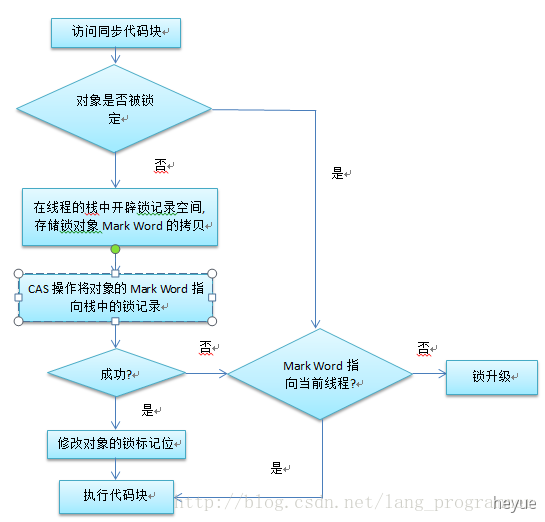
轻量级锁加锁
线程在执行同步代码块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用 CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
轻量级锁解锁
轻量级解锁时,会使用原子的CAS操作将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁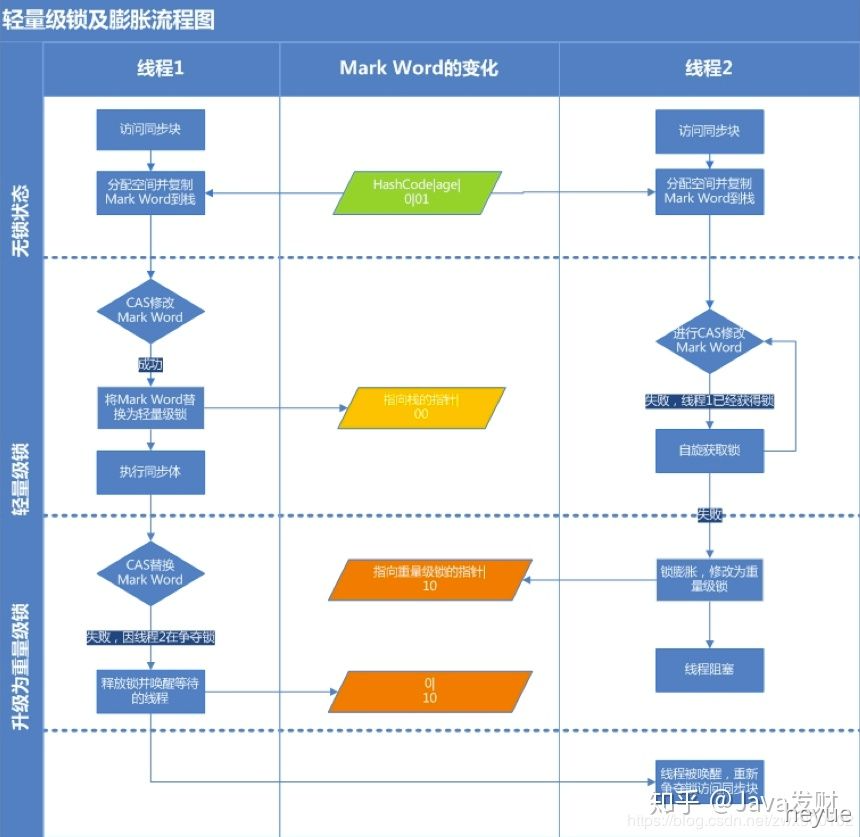
自旋锁
轻量级锁在加锁过程中,用到了自旋锁。所谓自旋,就是指当有另外一个线程来竞争锁时,这个线程会在原地循环等待,而不是把该线程给阻塞,直到那个获得锁的线程释放锁之后,这个线程就可以马上获得锁的。
为什么要采用自旋等待呢?
因为绝大多数情况下线程获得锁和释放锁的过程都是非常短暂的,自旋一定次数之后极有可能碰到获得锁的线程释放锁,所以,轻量级锁适用于那些同步代码块执行很快的场景,这样,线程原地等待很短的时间就能够获得锁了。
注意:锁在原地循环等待的时候,是会消耗CPU资源的。所以自旋必须要有一定的条件控制,否则如果一个线程执行同步代码块的时间很长,那么等待锁的线程会不断的循环反而会消耗CPU资源。默认情况下锁自旋的次数是 10 次,可以使用-XX:PreBlockSpin参数来设置自旋锁等待的次数。
自适应自旋
在 JDK1.7 开始,引入了自适应自旋锁,修改自旋锁次数的JVM参数被取消,虚拟机不再支持由用户配置自旋锁次数,而是由虚拟机自动调整。自适应意味着自旋的次数不是固定不变的,而是根据前一次在同一个锁上自旋的时间以及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源
重量级锁
当轻量级锁膨胀到重量级锁之后,意味着线程只能被挂起阻塞来等待唤醒了。每一个对象中都有一个Monitor监视器,而Monitor依赖操作系统的 MutexLock(互斥锁)来实现的, 线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能。
monitorenter指令是在编译后插入到同步代码块的开始位置,而monitorexit是插入到方法结束处和异常处,JVM要保证每个monitorenter必须有对应的monitorexit与之配对。而且当一个monitor被持有后,它将处于锁定状态。线程执行到monitorenter指令时,将会尝试获取对象所对应的monitor的所有权,即尝试获得对象的锁。我们可以简单的理解为,在加重量级锁的时候会执行monitorenter指令,解锁时会执行monitorexit指令。
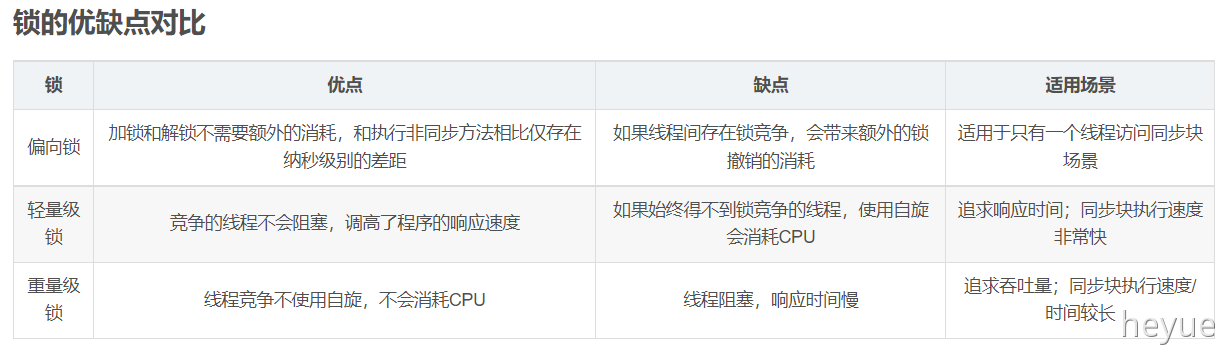
锁的优缺点对比
动态编译实现锁消除 / 锁粗化
除了锁升级优化,Java 还使用了编译器对锁进行优化。JIT 编译器在动态编译同步块的时候,借助了一种被称为逃逸分析的技术,来判断同步块使用的锁对象是否只能够被一个线程访问,而没有被发布到其它线程。
确认是的话,那么 JIT 编译器在编译这个同步块的时候不会生成 synchronized 所表示的锁的申请与释放的机器码,即消除了锁的使用。在 Java7 之后的版本就不需要手动配置了,该操作可以自动实现。
锁粗化同理,就是在 JIT 编译器动态编译时,如果发现几个相邻的同步块使用的是同一个锁实例,那么 JIT 编译器将会把这几个同步块合并为一个大的同步块,从而避免一个线程“反复申请、释放同一个锁”所带来的性能开销。
减小锁粒度
除了锁内部优化和编译器优化之外,我们还可以通过代码层来实现锁优化,减小锁粒度就是一种惯用的方法。
当我们的锁对象是一个数组或队列时,集中竞争一个对象的话会非常激烈,锁也会升级为重量级锁。我们可以考虑将一个数组和队列对象拆成多个小对象,来降低锁竞争,提升并行度。
Q&A
Q:当对象加了偏向锁后,原来的哈希值放到哪里去了?
A:被覆盖了,回到无锁状态会再添加
Q:synchronized锁只会升级,不会降级。如果系统只在某段时间高并发,升级到了重量级锁,然后系统变成低并发了,那还是重量锁,那岂不是很影响性能。
A:不应该叫锁降级,只是在垃圾回收阶段,即STW时,没有Java线程竞争锁的情况下,会将锁状态重置。
2.3 锁的相关分类:乐观|悲观、公平|非公平、可重入|不可重入、共享|排他?
公平锁 / 非公平锁
公平锁
- 公平锁是指多个线程按照申请锁的顺序来获取锁。
非公平锁
- 非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能,会造成优先级反转或者饥饿现象。
对于Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在于吞吐量比公平锁大。
对于Synchronized而言,也是一种非公平锁。由于其并不像ReentrantLock是通过AQS的来实现线程调度,所以并没有任何办法使其变成公平锁。
可重入锁 / 不可重入锁
可重入锁
广义上的可重入锁指的是可重复可递归调用的锁,在外层使用锁之后,在内层仍然可以使用,并且不发生死锁(前提得是同一个对象或者class),这样的锁就叫做可重入锁。ReentrantLock和synchronized都是可重入锁
synchronized void setA() throws Exception{Thread.sleep(1000);setB();}synchronized void setB() throws Exception{Thread.sleep(1000);}
上面的代码就是一个可重入锁的一个特点,如果不是可重入锁的话,setB可能不会被当前线程执行,可能造成死锁。
不可重入锁
不可重入锁,与可重入锁相反,不可递归调用,递归调用就发生死锁。看到一个经典的讲解,使用自旋锁来模拟一个不可重入锁,代码如下
import java.util.concurrent.atomic.AtomicReference;public class UnreentrantLock {private AtomicReference<Thread> owner = new AtomicReference<Thread>();public void lock() {Thread current = Thread.currentThread();//这句是很经典的“自旋”语法,AtomicInteger中也有for (;;) {if (!owner.compareAndSet(null, current)) {return;}}}public void unlock() {Thread current = Thread.currentThread();owner.compareAndSet(current, null);}}
代码也比较简单,使用原子引用来存放线程,同一线程两次调用lock()方法,如果不执行unlock()释放锁的话,第二次调用自旋的时候就会产生死锁,这个锁就不是可重入的,而实际上同一个线程不必每次都去释放锁再来获取锁,这样的调度切换是很耗资源的。
import java.util.concurrent.atomic.AtomicReference;public class UnreentrantLock {private AtomicReference<Thread> owner = new AtomicReference<Thread>();private int state = 0;public void lock() {Thread current = Thread.currentThread();if (current == owner.get()) {state++;return;}//这句是很经典的“自旋”式语法,AtomicInteger中也有for (;;) {if (!owner.compareAndSet(null, current)) {return;}}}public void unlock() {Thread current = Thread.currentThread();if (current == owner.get()) {if (state != 0) {state--;} else {owner.compareAndSet(current, null);}}}}
在执行每次操作之前,判断当前锁持有者是否是当前对象,采用state计数,不用每次去释放锁。
ReentrantLock中可重入锁实现
这里看非公平锁的锁获取方法:
final boolean nonfairTryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}//就是这里else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0) // overflowthrow new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}
在AQS中维护了一个private volatile int state来计数重入次数,避免了频繁的持有释放操作,这样既提升了效率,又避免了死锁。
独享锁 / 共享锁
独享锁和共享锁在你去读C.U.T包下的ReentrantLock和ReentrantReadWriteLock你就会发现,它俩一个是独享一个是共享锁。
- 独享锁:该锁每一次只能被一个线程所持有。
- 共享锁:该锁可被多个线程共有,典型的就是ReentrantReadWriteLock里的读锁,它的读锁是可以被共享的,但是它的写锁确每次只能被独占。
另外读锁的共享可保证并发读是非常高效的,但是读写和写写,写读都是互斥的。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
对于Synchronized而言,当然是独享锁。
互斥锁 / 读写锁
互斥锁
在访问共享资源之前对进行加锁操作,在访问完成之后进行解锁操作。 加锁后,任何其他试图再次加锁的线程会被阻塞,直到当前进程解锁。
如果解锁时有一个以上的线程阻塞,那么所有该锁上的线程都被编程就绪状态, 第一个变为就绪状态的线程又执行加锁操作,那么其他的线程又会进入等待。 在这种方式下,只有一个线程能够访问被互斥锁保护的资源
读写锁
读写锁既是互斥锁,又是共享锁,read模式是共享,write是互斥(排它锁)的。
读写锁有三种状态:读加锁状态、写加锁状态和不加锁状态
读写锁在Java中的具体实现就是ReadWriteLock
一次只有一个线程可以占有写模式的读写锁,但是多个线程可以同时占有读模式的读写锁。
只有一个线程可以占有写状态的锁,但可以有多个线程同时占有读状态锁,这也是它可以实现高并发的原因。当其处于写状态锁下,任何想要尝试获得锁的线程都会被阻塞,直到写状态锁被释放;如果是处于读状态锁下,允许其它线程获得它的读状态锁,但是不允许获得它的写状态锁,直到所有线程的读状态锁被释放;为了避免想要尝试写操作的线程一直得不到写状态锁,当读写锁感知到有线程想要获得写状态锁时,便会阻塞其后所有想要获得读状态锁的线程。所以读写锁非常适合资源的读操作远多于写操作的情况。
乐观锁 / 悲观锁
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。
并发容器类的加锁机制是基于粒度更小的分段锁,分段锁也是提升多并发程序性能的重要手段之一。
在并发程序中,串行操作是会降低可伸缩性,并且上下文切换也会减低性能。在锁上发生竞争时将通水导致这两种问题,使用独占锁时保护受限资源的时候,基本上是采用串行方式—-每次只能有一个线程能访问它。所以对于可伸缩性来说最大的威胁就是独占锁。
我们一般有三种方式降低锁的竞争程度:
1、减少锁的持有时间
2、降低锁的请求频率
3、使用带有协调机制的独占锁,这些机制允许更高的并发性。
在某些情况下我们可以将锁分解技术进一步扩展为一组独立对象上的锁进行分解,这成为分段锁。
其实说的简单一点就是:
容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
比如:在ConcurrentHashMap中使用了一个包含16个锁的数组,每个锁保护所有散列桶的1/16,其中第N个散列桶由第(N mod 16)个锁来保护。假设使用合理的散列算法使关键字能够均匀的分部,那么这大约能使对锁的请求减少到原来的1/16。也正是这项技术使得ConcurrentHashMap支持多达16个并发的写入线程。
偏向锁 / 轻量级锁 / 重量级锁
锁的状态:
- 无锁状态
- 偏向锁状态
- 轻量级锁状态
- 重量级锁状态
锁的状态是通过对象监视器在对象头中的字段来表明的。
四种状态会随着竞争的情况逐渐升级,而且是不可逆的过程,即不可降级。
这四种状态都不是Java语言中的锁,而是Jvm为了提高锁的获取与释放效率而做的优化(使用synchronized时)。
偏向锁
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
轻量级
轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
重量级锁
重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。
自旋锁
我们知道CAS算法是乐观锁的一种实现方式,CAS算法中又涉及到自旋锁,所以这里给大家讲一下什么是自旋锁。
简单回顾一下CAS算法
CAS是英文单词Compare and Swap(比较并交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。CAS算法涉及到三个操作数需要读写的内存值 V
- 进行比较的值 A
- 拟写入的新值 B
更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B,否则不会执行任何操作。一般情况下是一个自旋操作,即不断的重试。
什么是自旋锁?
自旋锁(spinlock):是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。
它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,”自旋”一词就是因此而得名。
Java如何实现自旋锁?
下面是个简单的例子:
public class SpinLock {private AtomicReference<Thread> cas = new AtomicReference<Thread>();public void lock() {Thread current = Thread.currentThread();// 利用CASwhile (!cas.compareAndSet(null, current)) {// DO nothing}}public void unlock() {Thread current = Thread.currentThread();cas.compareAndSet(current, null);}}
lock()方法利用的CAS,当第一个线程A获取锁的时候,能够成功获取到,不会进入while循环,如果此时线程A没有释放锁,另一个线程B又来获取锁,此时由于不满足CAS,所以就会进入while循环,不断判断是否满足CAS,直到A线程调用unlock方法释放了该锁。
自旋锁存在的问题
1、如果某个线程持有锁的时间过长,就会导致其它等待获取锁的线程进入循环等待,消耗CPU。使用不当会造成CPU使用率极高。
2、上面Java实现的自旋锁不是公平的,即无法满足等待时间最长的线程优先获取锁。不公平的锁就会存在“线程饥饿”问题。
自旋锁的优点
1、自旋锁不会使线程状态发生切换,一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换,执行速度快
2、非自旋锁在获取不到锁的时候会进入阻塞状态,从而进入内核态,当获取到锁的时候需要从内核态恢复,需要线程上下文切换。 (线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能)
可重入的自旋锁和不可重入的自旋锁
文章开始的时候的那段代码,仔细分析一下就可以看出,它是不支持重入的,即当一个线程第一次已经获取到了该锁,在锁释放之前又一次重新获取该锁,第二次就不能成功获取到。由于不满足CAS,所以第二次获取会进入while循环等待,而如果是可重入锁,第二次也是应该能够成功获取到的。
而且,即使第二次能够成功获取,那么当第一次释放锁的时候,第二次获取到的锁也会被释放,而这是不合理的。
为了实现可重入锁,我们需要引入一个计数器,用来记录获取锁的线程数。
public class ReentrantSpinLock {private AtomicReference<Thread> cas = new AtomicReference<Thread>();private int count;public void lock() {Thread current = Thread.currentThread();if (current == cas.get()) { // 如果当前线程已经获取到了锁,线程数增加一,然后返回count++;return;}// 如果没获取到锁,则通过CAS自旋while (!cas.compareAndSet(null, current)) {// DO nothing}}public void unlock() {Thread cur = Thread.currentThread();if (cur == cas.get()) {if (count > 0) {// 如果大于0,表示当前线程多次获取了该锁,释放锁通过count减一来模拟count--;} else {// 如果count==0,可以将锁释放,这样就能保证获取锁的次数与释放锁的次数是一致的了。cas.compareAndSet(cur, null);}}}}
自旋锁与互斥锁
- 自旋锁与互斥锁都是为了实现保护资源共享的机制。
- 无论是自旋锁还是互斥锁,在任意时刻,都最多只能有一个保持者。
获取互斥锁的线程,如果锁已经被占用,则该线程将进入睡眠状态;获取自旋锁的线程则不会睡眠,而是一直循环等待锁释放。
自旋锁总结
自旋锁:线程获取锁的时候,如果锁被其他线程持有,则当前线程将循环等待,直到获取到锁。
- 自旋锁等待期间,线程的状态不会改变,线程一直是用户态并且是活动的(active)。
- 自旋锁如果持有锁的时间太长,则会导致其它等待获取锁的线程耗尽CPU。
- 自旋锁本身无法保证公平性,同时也无法保证可重入性。
- 基于自旋锁,可以实现具备公平性和可重入性质的锁。
2.4 synchronized的三种用法和区别?修饰方法
Synchronized修饰一个方法很简单,就是在方法的前面加synchronized,synchronized修饰方法和修饰一个代码块类似,只是作用范围不一样,修饰代码块是大括号括起来的范围,而修饰方法范围是整个函数。
例如:
方法一
方法二public synchronized void method(){// todo}
写法一修饰的是一个方法,写法二修饰的是一个代码块,但写法一与写法二是等价的,都是锁定了整个方法时的内容。public void method(){synchronized(this) {// todo}}
synchronized关键字不能继承。
虽然可以使用synchronized来定义方法,但synchronized并不属于方法定义的一部分,因此,synchronized关键字不能被继承。如果在父类中的某个方法使用了synchronized关键字,而在子类中覆盖了这个方法,在子类中的这个方法默认情况下并不是同步的,而必须显式地在子类的这个方法中加上synchronized关键字才可以。当然,还可以在子类方法中调用父类中相应的方法,这样虽然子类中的方法不是同步的,但子类调用了父类的同步方法,因此,子类的方法也就相当于同步了。这两种方式的例子代码如下:
在子类方法中加上synchronized关键字
在子类方法中调用父类的同步方法class Parent {public synchronized void method() { }}class Child extends Parent {public synchronized void method() { }}
class Parent {public synchronized void method() { }}class Child extends Parent {public void method() { super.method(); }}
- 在定义接口方法时不能使用synchronized关键字。
构造方法不能使用synchronized关键字,但可以使用synchronized代码块来进行同步。
修饰一个代码块
1)一个线程访问一个对象中的synchronized(this)同步代码块时,其他试图访问该对象的线程将被阻塞
注意下面两个程序的区别 ```java class SyncThread implements Runnable {private static int count;public SyncThread() {count = 0;}public void run() {synchronized(this) {for (int i = 0; i < 5; i++) {try {System.out.println(Thread.currentThread().getName() + ":" + (count++));Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}}public int getCount() {return count;}
}
public class Demo00 {
public static void main(String args[]){
//test01
//SyncThread s1 = new SyncThread();
//SyncThread s2 = new SyncThread();
//Thread t1 = new Thread(s1);
//Thread t2 = new Thread(s2);
//test02
SyncThread s = new SyncThread();
Thread t1 = new Thread(s);
Thread t2 = new Thread(s);
t1.start();t2.start();}
}
test01的运行结果<br /><br />test02的运行结果<br /><br />当两个并发线程(thread1和thread2)访问同一个对象(syncThread)中的synchronized代码块时,在同一时刻只能有一个线程得到执行,另一个线程受阻塞,必须等待当前线程执行完这个代码块以后才能执行该代码块。Thread1和thread2是互斥的,因为在执行synchronized代码块时会锁定当前的对象,只有执行完该代码块才能释放该对象锁,下一个线程才能执行并锁定该对象<br />为什么上面的例子中thread1和thread2同时在执行。这是因为synchronized只锁定对象,每个对象只有一个锁(lock)与之相关联。```javaclass Counter implements Runnable{private int count;public Counter() {count = 0;}public void countAdd() {synchronized(this) {for (int i = 0; i < 5; i ++) {try {System.out.println(Thread.currentThread().getName() + ":" + (count++));Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}}//非synchronized代码块,未对count进行读写操作,所以可以不用synchronizedpublic void printCount() {for (int i = 0; i < 5; i ++) {try {System.out.println(Thread.currentThread().getName() + " count:" + count);Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}public void run() {String threadName = Thread.currentThread().getName();if (threadName.equals("A")) {countAdd();} else if (threadName.equals("B")) {printCount();}}}public class Demo00{public static void main(String args[]){Counter counter = new Counter();Thread thread1 = new Thread(counter, "A");Thread thread2 = new Thread(counter, "B");thread1.start();thread2.start();}}

可以看见B线程的调用是非synchronized,并不影响A线程对synchronized部分的调用。从上面的结果中可以看出一个线程访问一个对象的synchronized代码块时,别的线程可以访问该对象的非synchronized代码块而不受阻塞。
3)指定要给某个对象加锁
/*** 银行账户类*/class Account {String name;float amount;public Account(String name, float amount) {this.name = name;this.amount = amount;}//存钱public void deposit(float amt) {amount += amt;try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}//取钱public void withdraw(float amt) {amount -= amt;try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}public float getBalance() {return amount;}}/*** 账户操作类*/class AccountOperator implements Runnable{private Account account;public AccountOperator(Account account) {this.account = account;}public void run() {synchronized (account) {account.deposit(500);account.withdraw(500);System.out.println(Thread.currentThread().getName() + ":" + account.getBalance());}}}public class Demo00{//public static final Object signal = new Object(); // 线程间通信变量//将account改为Demo00.signal也能实现线程同步public static void main(String args[]){Account account = new Account("zhang san", 10000.0f);AccountOperator accountOperator = new AccountOperator(account);final int THREAD_NUM = 5;Thread threads[] = new Thread[THREAD_NUM];for (int i = 0; i < THREAD_NUM; i ++) {threads[i] = new Thread(accountOperator, "Thread" + i);threads[i].start();}}}

在AccountOperator 类中的run方法里,我们用synchronized 给account对象加了锁。这时,当一个线程访问account对象时,其他试图访问account对象的线程将会阻塞,直到该线程访问account对象结束。也就是说谁拿到那个锁谁就可以运行它所控制的那段代码。
当有一个明确的对象作为锁时,就可以用类似下面这样的方式写程序。
public void method3(SomeObject obj){//obj 锁定的对象synchronized(obj){// todo}}
当没有明确的对象作为锁,只是想让一段代码同步时,可以创建一个特殊的对象来充当锁:
class Test implements Runnable{private byte[] lock = new byte[0]; // 特殊的instance变量public void method(){synchronized(lock) {// todo 同步代码块}}public void run() {}}
修饰一个静态的方法
public synchronized static void method() {// todo}
静态方法是属于类的而不属于对象的。同样的,synchronized修饰的静态方法锁定的是这个类的所有对象。
/*** 同步线程*/class SyncThread implements Runnable {private static int count;public SyncThread() {count = 0;}public synchronized static void method() {for (int i = 0; i < 5; i ++) {try {System.out.println(Thread.currentThread().getName() + ":" + (count++));Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}public synchronized void run() {method();}}public class Demo00{public static void main(String args[]){SyncThread syncThread1 = new SyncThread();SyncThread syncThread2 = new SyncThread();Thread thread1 = new Thread(syncThread1, "SyncThread1");Thread thread2 = new Thread(syncThread2, "SyncThread2");thread1.start();thread2.start();}}
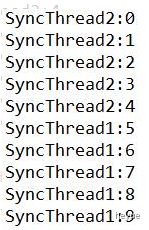
syncThread1和syncThread2是SyncThread的两个对象,但在thread1和thread2并发执行时却保持了线程同步。这是因为run中调用了静态方法method,而静态方法是属于类的,所以syncThread1和syncThread2相当于用了同一把锁。
修饰一个类
class ClassName {public void method() {synchronized(ClassName.class) {// todo}}}
/*** 同步线程*/class SyncThread implements Runnable {private static int count;public SyncThread() {count = 0;}public static void method() {synchronized(SyncThread.class) {for (int i = 0; i < 5; i ++) {try {System.out.println(Thread.currentThread().getName() + ":" + (count++));Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}}public synchronized void run() {method();}}
本例的的给class加锁和上例的给静态方法加锁是一样的,所有对象公用一把锁
总结
A. 无论synchronized关键字加在方法上还是对象上,如果它作用的对象是非静态的,则它取得的锁是对象;如果synchronized作用的对象是一个静态方法或一个类,则它取得的锁是对类,该类所有的对象同一把锁。
B. 每个对象只有一个锁(lock)与之相关联,谁拿到这个锁谁就可以运行它所控制的那段代码。
C. 实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
2.5 synchronized的实现原理?
一、Java中synchronized关键字的作用
总所周知,在并发环境中多个线程对同一个资源进行访问很可能出现脏读等一系列线程安全问题。这时我们可以用加锁的方式对访问共享资源的代码块进行加锁,以确保同一时间段内只能有一个线对资源进行访问,在它释放锁之前其他竞争锁的线程只能等待。而synchronized关键字是加锁的一种方式。
举个通俗易懂的例子:比如你上厕所之后,你要锁门,此时其他人只能在外面等待,直到你出来后,下一个人才能进去。这就是现实中一个加锁和释放锁的例子。
二、Java中synchronized关键字的运用
synchronized关键字的运用主要包括三方面:
- 锁代码块(锁对象可指定,可为this、XXX.class、全局变量)
- 锁普通方法(锁对象是this,即该类实例本身)
- 锁静态方法(锁对象是该类,即XXX.class)
1、锁代码块
代码:
public class Sync{private int a = 0;public void add(){synchronized(this){System.out.println("a values " + ++a);}}}
反编译结果: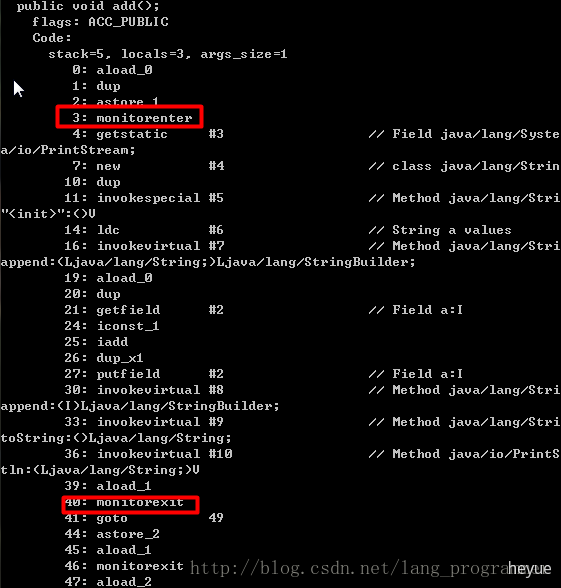
由反编译结果可以看出:synchronized代码块主要是靠monitorenter和monitorexit这两个原语来实现同步的。当线程进入monitorenter获得执行代码的权利时,其他线程就不能执行里面的代码,直到锁Owner线程执行monitorexit释放锁后,其他线程才可以竞争获取锁。
在这里,我们先阐释一下Java虚拟机规范中相关内容:
(1)、monitorenter
每个对象有一个监视器锁(monitor)。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
- 如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
- 如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
- 如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
上述第2点就涉及到了可重入锁,意思就是说当一个线程已经获取一个锁时,它可以再获取无数次,从代码的角度上将就是有无数个相同的synchronized语句块嵌套在一起。在进入时,monitor的进入数+1;退出时就-1,直到为0的时候才可以被其他线程竞争获取。
(2)、monitorexit
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。
2、锁普通方法
代码:
public class Sync{private int a = 0;public synchronized void add(){System.out.println("a values " + ++a);}}
反编译结果: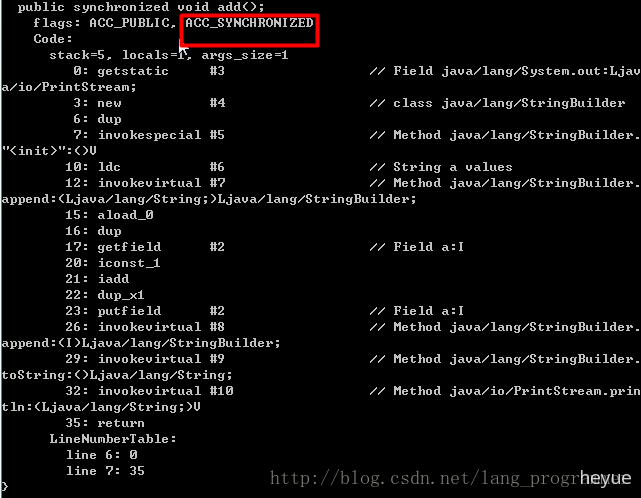
从上图可以看出,这里并没有monitorenter和monitorexit,但是常量池中多了ACC_SYNCHRONIZED标示符。JVM就是根据该标示符来实现方法的同步的:当方法调用时会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。这种方式与语句块没什么本质区别,都是通过竞争monitor的方式实现的。只不过这种方式是隐式的实现方法。
在这里,我们将以上两种方法进行一下说明:
首先是代码块,当程序运行到monitorenter时,竞争monitor,成功后继续运行后续代码,直到monitorexit才释放monitor;而ACC_SYNCHRONIZED则是通过标志位来提示线程去竞争monitor。也就是说,monitorenter和ACC_SYNCHRONIZED只是起标志作用,并无实质操作。
3、锁静态方法
代码:
public class Sync{private static int a = 0;public synchronized static void add(){System.out.println("a values " + ++a);}}
反编译结果: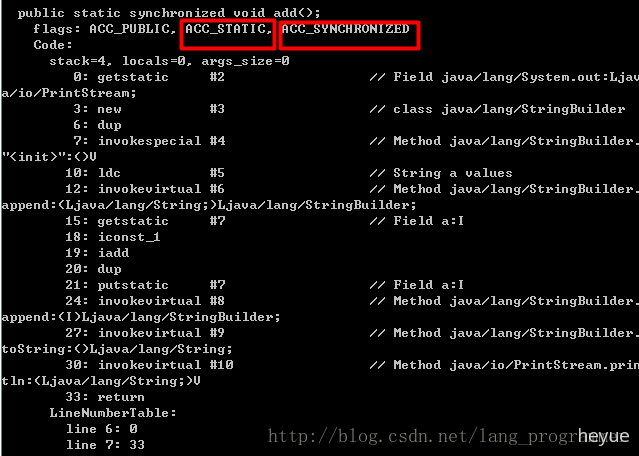
常量池中用ACC_STATIC标志了这是一个静态方法,然后用ACC_SYNCHRONIZED标志位提醒线程去竞争monitor。由于静态方法是属于类级别的方法(即不用创建对象就可以被调用),所以这是一个类级别(XXX.class)的锁,即竞争某个类的monitor。
三、锁的竞争过程
上面只是阐述了如何提醒线程去争夺锁,所以接下来我们阐述一下线程是怎样竞争锁的。其实总的来说,JVM中是通过队列来控制线程去竞争锁的。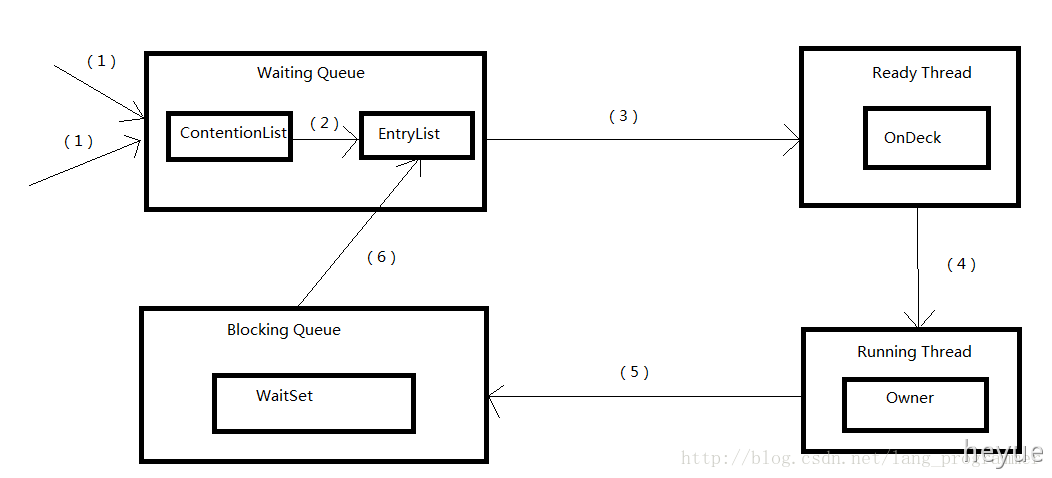
- (1)、多个线程请求锁,首先进入Contention List,它可以接纳所有请求线程,而且是一个后进先出(LIFO)的虚拟队列,通过结点Node和next指针构造。
- (2)(3)、ContentionList会被线程并发访问,EntryList为了降低线程对ContentionList队尾的争用而构造出来。当Owner释放锁时,会从ContentionList中迁移线程到EntryList,并会指定EntryList中的某个线程(一般为Head结点)为Ready Thread,也就是说某个时刻最多只有一个线程正在竞争锁。
- (4)、Owner并不是直接把锁交给OnDeck线程,而是将竞争锁的权利交给OnDeck(将锁释放了),然后让OnDeck自己去竞争。竞争成功后,OnDeck线程就变成Owner;否则继续留在EntryList的队头。
- (5)(6)、当线程调用wait方法被阻塞时,进入WaitSet;当其他线程调用notifyAll()(notify())方法后,阻塞队列的(某个)线程就会进入EntryList中。
处于ContetionList、EntryList、WaitSet的线程均处于阻塞状态。而线程被阻塞涉及到用户态与内核态的切换(Liunx),系统切换严重影响锁的性能。解决这个问题的办法就是自旋。自旋就是线程不断进行内部循环,即for循环什么也不做,防止线程wait()阻塞,在自旋过程中不断尝试获取锁,如果自旋期间,Owner刚好释放锁,此时自旋线程就可以去竞争锁。如果自旋了一段时间还没获取到锁,那没办法,只能调用wait()阻塞了。
为什么自旋了一段时间后又调用wait()方法呢?因为自旋是要消耗CPU的,而且还有线程上下文切换,因为CPU还可以调度线程,只不过执行的是空的for循环罢了。
对自旋锁周期的选择上,HotSpot认为最佳时间应是一个线程上下文切换的时间,但目前并没有做到。
所以,synchronized是什么时候进行自旋的?答案是在进入ContetionList之前,因为它自旋一定时间后还没获取锁,最后它只好在ContetionList中阻塞等待了。
四、通过JVM了解synchronized
把锁说得那么玄乎,到底锁是何方神圣呢?首先,我们来了解一下对象头。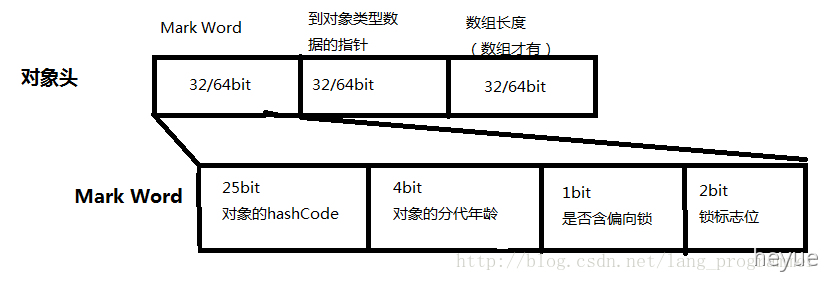
从图中可以看到,Java对象Mark Word中的是否含偏向锁、锁标志位都与锁有关。是否含偏向锁很明显与偏向锁有关,而锁标记位指的是用了什么锁。接下来用一张图表示不同状态的锁下各个部分的含义。
为了减少锁释放带来的消耗,锁有一个升级的机制,从轻到重依次是:无锁状态 ——> 偏向锁 ——> 轻量级锁 ——>重量级锁。
1、偏向锁
(1)、运行原理
重量级锁使用互斥量实现同步;轻量级锁使用CAS操作,避免重量级锁的互斥量;而偏向锁则是在无竞争条件下把整个同步都删除掉,连CAS都不用做了(在设置偏向锁的时候只需要一步CAS操作)。
偏向锁,在无其它线程与它竞争的情况下,持有偏向锁的线程永远也不需要同步。它的加锁过程很简单:线程访问同步代码块时检查偏向锁中线程ID是否指向自己,如果是表明该线程已获得锁;否则,检测偏向锁标记是否为1,不是的话则CAS竞争锁,如果是就将对象头中线程ID指向自己。
当存在线程竞争锁时,偏向锁才会撤销,转而升级为轻量级锁。而这个撤销过程则需要有一个全局安全点(即这个时间点上没有正在执行的字节码)。过程如下: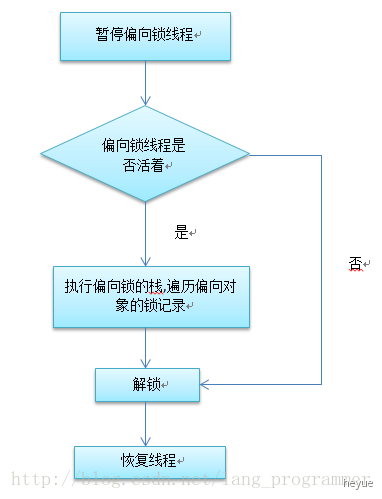
在撤销锁的时候,栈中对象头的Mark Word要么偏向于其他线程,要么恢复到无锁或者轻量级锁。
(2)、分析
- 优点:加锁和解锁无需额外消耗
- 缺点:锁进化时会带来额外锁撤销的消耗
-
3、轻量级锁
(1)、运行原理
(2)、分析
优点:竞争的线程不阻塞,也就是不涉及到用户态与内核态的切换(Liunx),减少系统切换锁带来的开销
- 缺点:如果长时间竞争不到锁,自旋会消耗CPU
-
3、重量级锁
它是传统意义上的锁,通过互斥量来实现同步,线程阻塞,等待Owner释放锁唤醒。
(2)、分析
优点:线程竞争不自旋,不消耗CPU
- 缺点:线程阻塞,响应时间慢
- 适用场景:追求吞吐量、同步块执行时间较长
补充:
重量级锁和轻量级锁
重量级锁
是基于操作系统的互斥量(Mutex Lock)而实现的锁,会导致进程在用户态和内核态之间切换,相对开销较大。
synchronized在内部基于监视器锁(monitor)实现,监视器锁基于底层的操作系统的Mutex Lock实现,因此synchronized属于重量级锁,重量级锁需要在用户态和核心态之间做转换,所以synchronized的运行效率不高。
jdk在1.6版本之后,为了减少获取锁和释放锁所带来的性能消耗及提高性能,引入了轻量级锁和偏向锁。
ps: 了解一下关于用户态和内核态概念
操作系统用户态和内核态之间的切换过程
对于Unix/Linux来说,只使用了0级特权级和3级特权级。也就是说在Unix/Linux系统中,一条工作在0级特权级的指令具有了CPU能提供的最高权力,而一条工作在3级特权级的指令具有CPU提供的最低或者说最基本权力。
现在我们从特权级的调度来理解用户态和内核态就比较好理解了,当程序运行在3级特权级上时,就可以称之为运行在用户态,因为这是最低特权级,是普通的用户进程运行的特权级,大部分用户直接面对的程序都是运行在用户态;反之,当程序运行在0级特权级上时,就可以称之为运行在内核态。
虽然用户态下和内核态下工作的程序有很多差别,但最重要的差别就在于特权级的不同,即权力的不同。运行在用户态下的程序不能直接访问操作系统内核数据结构和程序,比如上面例子中的testfork()就不能直接调用sys_fork(),因为前者是工作在用户态,属于用户态程序,而sys_fork()是工作在内核态,属于内核态程序。
当我们在系统中执行一个程序时,大部分时间是运行在用户态下的,在其需要操作系统帮助完成某些它没有权力和能力完成的工作时就会切换到内核态,比如testfork()最初运行在用户态进程下,当它调用fork()最终触发sys_fork()的执行时,就切换到了内核态。
轻量级锁
是相对与重量级锁而言的,轻量级锁的核心设计实在没有多线程竞争的前提下,减少重量级锁的使用以提高系统性能。轻量级锁适用于线程交替执行同步代码块的情况(既互斥操作),如果同一时刻与多个线程访问同一个锁,则将会导致轻量级锁膨胀为重量级锁。
偏向锁
主要目的实在同一个线程多次获取某个锁的情况下尽量减少轻量级锁的执行路径。因为轻量级锁的获取及释放需要多次CAS(Compare and Swap)原子操作,而偏向锁只需要在切换ThreadId时执行一次CAS原子操作,一次可以提高锁的运行效率。
在出现多线程竞争锁的情况时,JVM会自动撤销偏向锁,因此偏向锁的撤销操作耗时必须少于节省下来的CAS原子操作的耗时。
五、总结
Java的synchronized关键字可实现同步功能,在多个线程请求统一资源时,可以只允许一个线程访问,在Owner释放锁之前其他线程都不能访问。
synchronized的同步机制是通过竞争monitor实现的,多个竞争线程可通过队列来协调。
每个Java对象的头部都有关于锁的标志位,这里存放了锁的有关信息。为了提高效率,锁有一个粗话过程,从轻到重依次是:无锁状态 ——> 偏向锁 ——> 轻量级锁 ——>重量级锁。
2.6 synchronized和Lock(JUC)区别
面试题:Synchronized 和 Lock 有什么区别? 用新的 Lock 有什么好处?你举例说说。
1,原始构成
synchronized
是关键字属于JVM层面,
monitorenter 底层是通过 monitorenter 对象来完成,其实 wait/notify 等方法也依赖于 monitor 对象只有在同步块或方法中才能调 wait/notify 等方法
monitorexit 退出,下图中有两个 monitorexit,第一个是正常退出,第二个是即使报错了也可以退出。
Lock
是具体的类(java.util.concurrent.locks.lock) 是 api 层面的锁
2,使用方法
synchronized
不需要用户去手动释放锁,当 synchronized 代码块执行完后系统会自动让线程释放对锁的占用
ReentractLock
需要用户去手动释放锁,若没有主动释放锁,就有可能导致出现死锁现象。
需要lock() 和 unLock() 方法配合 try/finally 语句块来完成
3,等待是否可中断
synchronized
不可中断,除非抛出异常或者正常运行完成
ReenterantLock
可中断:
1,设置超时方法 tryLock(long timeout,TimeUnit unit)
2,lockInterruptibly() 放代码块中,调用 interrupt() 方法可中断
4,加锁是否公平
synchronized
非公平锁
ReenterantLock
两者都可以,默认非公平锁,构造方法可以传入 boolean 值,true 为公平锁,false 为非公平锁。
5,锁绑定多个条件 condition
synchronized
不支持
ReenterantLock
用来实现分组唤醒需要唤醒的线程们,可以精确唤醒,而不是像 synchronized 要么随机唤醒一个线程,要么唤醒全部线程。
2.7 CAS(三个问题)、ABA、自旋、原子操作
在Java并发包中有一些并发框架也使用了自旋CAS的方式来实现原子性,比如LinkTransferQueue类的Xfer方法。CAS虽然很高效 的解决了原子操作,但是CAS仍然存在三大问题:ABA问题,循环时间开销大,以及只能保证一个共享变量的原子操作。
(1)ABA问题
因为CAS需要在操作值的时候,检查值有么有发生变化,如没有发生变化则更新,但是如果原来的一个值是A,变成了B,又变成了A,那么使用CAS进行检查的时候,会发现他的值没有发生变化,但是实际上却发生了变化。ABA问题的解决思路就是使用版本号。在变量前面追加版本号,每次变量更新的时候把版本号加1,那么A->B->A就变成了1A->2B->3A。在Java1.5开始,JDK的Atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法的作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果全部等于,则以原子方式将该引用和该标志的值设置为给定的更新值。
public boolean compareAndSet(v expectedReference, //预期引用V newReference, //更新后的引用int expectedStamp, //预期标志int newStamp //更新后的标志)
(2) 循环时间开销大
自旋CAS如果长时间不动,会给CPU带来非常大的执行开销,如果JVM能支持处理器提供的pause指令,那么效率会有一定的提升。pause指令有两个作用:第一,它可以延迟流水线执行指令,是CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零;第二,它可以避免在退出循环的时候因内存顺序冲突而引起的CPU流水线被清空,从而提高内存CPU的执行效率。
(3)只能保证一个共享变量的原子性
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。还有一个取巧的方法,就是把多个共享变量合并成一个共享变量来操作,比如,有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作。
2.8 AQS的原理和资源的共享方式(独占、共享)
一、概述
谈到并发,不得不谈ReentrantLock;而谈到ReentrantLock,不得不谈AbstractQueuedSynchronizer(AQS)!
类如其名,抽象的队列式的同步器,AQS定义了一套多线程访问共享资源的同步器框架,许多同步类实现都依赖于它,如常用的ReentrantLock/Semaphore/CountDownLatch…。
请尊重作者劳动成果,转载请标明原文链接:http://www.cnblogs.com/waterystone/p/4920797.html
手机版可访问:https://mp.weixin.qq.com/s/eyZyzk8ZzjwzZYN4a4H5YA
二、框架
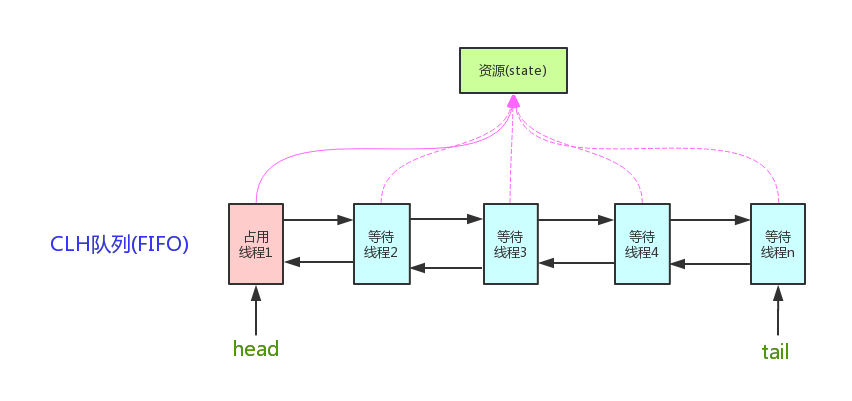
它维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)。这里volatile是核心关键词,具体volatile的语义,在此不述。state的访问方式有三种:
- getState()
- setState()
- compareAndSetState()
AQS定义两种资源共享方式:Exclusive(独占,只有一个线程能执行,如ReentrantLock)和Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)。
记忆spring的常用注解
1、声明bean的注解:
@Component:组件,没有明确的角色
@Service:在业务逻辑层使用(service层)
@Repository:在数据访问层使用(dao层)
@Controller:在展现层使用,控制器的声明(Controller)
2、注入bean的注解:
@Autowired:由Spring提供,按类型注入,如果一个接口有多个实现,需要和@Qualifier配合使用
@Inject:由JSR-330提供
@Resource:由JSR-250提供,按名称注入
都可以注解在set方法和属性上,推荐注解在属性上。
3、java配置类相关注解:
@Bean 注解在方法上,声明当前方法的返回值为一个bean,如果使用第三方工具,就需要使用@Bean进行装配,否则使用xml形式
@Configuration 声明当前类为配置类,其中内部组合了@Component注解,表明这个类是一个bean
@ComponentScan 用于对Component进行扫描
@WishlyConfiguration 为@Configuration与@ComponentScan的组合注解,可以替代这两个注解
4、切面(AOP)相关注解:
Spring支持AspectJ的注解式切面编程。
@Aspect 声明一个切面
使用@After、@Before、@Around定义建言(advice),可直接将拦截规则(切点)作为参数。
@After 在方法执行之后执行(方法上)
@Before 在方法执行之前执行(方法上)
@Around 在方法执行之前与之后执行(方法上)
@PointCut 声明切点
在java配置类中使用@EnableAspectJAutoProxy注解开启Spring对AspectJ代理的支持(类上)
springmvc的作用
谈到这个问题,我们不得不提提之前Model1和Model2这两个没有Spring MVC的时代。
Model1时代:很多学Java比较晚的后端程序员可能并没有接触过Model1模式下的JavaWeb应用开发。在Model1模式下,整个Web应用几乎全部用JSP页面组成,只用少量的JavaBean来处理数据库连接,访问等操作。这个模式下JSP即是控制层又是表现层。显而易见,这种模式存在很多问题。比如将控制逻辑和表现逻辑混杂在一起,导致代码重用率极低;又比如前端和后端相互依赖,难以进行测试并且开发效率极低。
Model2时代:学过Servlet并做过相关Demo的朋友应该了解Java Bean(Model)+JSP(View)+Servlet(Controller)这种开发模式,这就是早期的Java Web MVC开发模式。Model是系统中涉及的数据,也就是dao和bean;View是用来展示模型中的数据,只是用来展示;Controller是将用户请求都发送给Servlet做处理,返回数据给JSP并展示给用户。
Model2模式下还存在很多问题,Model2的抽象和封装程度还远远不够,使用Model2进行开发时不可避免地会重复造轮子,这就大大降低了程序的可维护性和可复用性。于是很多Java Web开发相关的MVC框架应运而生,比如Struts2,但是由于Struts2比较笨重,随着Spring轻量级开发框架的流行,Spring生态圈出现了Spring MVC框架。Spring MVC是当前最优秀的MVC框架,相比于Struts2,Spring MVC使用更加简单和方便,开发效率更高,并且Spring MVC运行速度更快。
MVC是一种设计模式,Spring MVC是一款很优秀的MVC框架。Spring MVC可以帮助我们进行更简洁的Web层的开发,并且它天生与Spring框架集成。Spring MVC下我们一般把后端项目分为Service层(处理业务)、Dao层(数据库操作)、Entity层(实体类)、Controller层(控制层,返回数据给前台页面)。
一级和二级缓存
mybatis一级缓存和二级缓存的区别:
1)一级缓存 Mybatis的一级缓存是指SQLSession,一级缓存的作用域是SQlSession, Mabits默认开启一级缓存。 在同一个SqlSession中,执行相同的SQL查询时;第一次会去查询数据库,并写在缓存中,第二次会直接从缓存中取。 当执行SQL时候两次查询中间发生了增删改的操作,则SQLSession的缓存会被清空。
每次查询会先去缓存中找,如果找不到,再去数据库查询,然后把结果写到缓存中。 Mybatis的内部缓存使用一个HashMap,key为hashcode+statementId+sql语句。Value为查询出来的结果集映射成的java对象。 SqlSession执行insert、update、delete等操作commit后会清空该SQLSession缓存。
2)二级缓存 二级缓存是mapper级别的,Mybatis默认是没有开启二级缓存的。 第一次调用mapper下的SQL去查询用户的信息,查询到的信息会存放代该mapper对应的二级缓存区域。 第二次调用namespace下的mapper映射文件中,相同的sql去查询用户信息,会去对应的二级缓存内取结果
mybatis的作用和特点
作用:
Mybatis原名iBatis,是一款支持普通SQL语句查询,存储过程和高级映射的优秀持久层框架,其本身内封装了JDBC。Mybatis消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。Mybatis可以使用简单的XML或注解用于配置和原始映射,将接口和JAVA的普通java对象映射成数据库中的记录。
特点:
简单易学。本身就很小且简单;
灵活。Mybatis不会对应用程序或数据库的现有设计强加影响。sql语句写在xml里面,便于统一管理和优化。
提供映射标签,支持对象与数据库的orm字段关系映射;
解除SQL与程序代码的偶合。通过提供DAO层,将业务逻辑和数据访问逻辑分离,使系统的设计更清晰,更易维护,更易单元测试。sql和代码的分离,提高了可维护性。
提供对象关系映射标签,支持对象关系组建维护;
提供xml标签,支持编写动态SQL语句。
mybatis的$和#区别和用法
是占位符, 会对SQL进行预编译,相当于?; $是做sql拼接, 有SQL注入的隐患 2. #不需要关注数据类型, MyBatis自动实现数据类型转换; ${} 必须自己判断数据类型
两者都支持@param注解, 指定参数名称, 获取参数值. 推荐这种方式
一般做参数传递,都会使用#{}
如果不是做预编译,而是做拼接sql, 会使用${}, 例如表名称的变化,或者用在其他配置文件中
sql语句的分类和对应的关键字
DDL(Data Definition Language,数据定义语言)
DDL用来创建或者删除存储数据用的数据库以及数据库中的表等对象。DDL 包含以下几种指令。
CREATE:创建数据库和表等对象
DROP: 删除数据库和表等对象 — 表删除之后无法恢复。
ALTER: 修改数据库和表等对象的结构 — 表定义变更之后无法恢复。
DML(Data Manipulation Language,数据操纵语言)
DML用来查询或者变更表中的记录。DML 包含以下几种指令。
SELECT:查询表中的数据
INSERT:向表中插入新数据
UPDATE:更新表中的数据
DELETE:删除表中的数据
DCL(Data Control Language,数据控制语言)
DCL 用来确认或者取消对数据库中的数据进行的变更。除此之外,还可以对 RDBMS 的用户是否有权限操作数据库中的对象(数据库表等)进行设定。DCL 包含以下几种指令。
COMMIT: 确认对数据库中的数据进行的变更
ROLLBACK:取消对数据库中的数据进行的变更
GRANT: 赋予用户操作权限
REVOKE: 取消用户的操作权限
1. 查看表结构
SQL>DESC emp;
2. 查询所有列
SQL>SELECT * FROM emp;
3. 查询指定列
SQL>SELECT empmo, ename, mgr FROM emp;
SQL>SELECT DISTINCT mgr FROM emp; 只显示结果不同的项
4. 查询指定行
SQL>SELECT * FROM emp WHERE job=’CLERK’;
5. 使用算术表达式
SQL>SELECT ename, sal*13+nvl(comm,0) FROM emp;
nvl(comm,1)的意思是,如果comm中有值,则nvl(comm,1)=comm; comm中无值,则nvl(comm,1)=0。
SQL>SELECT ename, sal13+nvl(comm,0) year_sal FROM emp; (year_sal为别名,可按别名排序)
SQL>SELECT FROM emp WHERE hiredate>’01-1月-82’;
6. 使用like操作符(%,_)
%表示一个或多个字符,_表示一个字符,[charlist]表示字符列中的任何单一字符,[^charlist]或者[!charlist]不在字符列中的任何单一字符。
SQL>SELECT * FROM emp WHERE ename like ‘S__T%’;
7. 在where条件中使用In
SQL>SELECT * FROM emp WHERE job IN (‘CLERK’,’ANALYST’);
8. 查询字段内容为空/非空的语句
SQL>SELECT * FROM emp WHERE mgr IS/IS NOT NULL;
9. 使用逻辑操作符号
SQL>SELECT * FROM emp WHERE (sal>500 or job=’MANAGE’) and ename like ‘J%’;
10. 将查询结果按字段的值进行排序
SQL>SELECT * FROM emp ORDER BY deptno, sal DESC; (按部门升序,并按薪酬降序)
二、复杂查询
1. 数据分组(max,min,avg,sum,count)
SQL>SELECT MAX(sal),MIN(age),AVG(sal),SUM(sal) from emp;
SQL>SELECT FROM emp where sal=(SELECT MAX(sal) from emp));
SQL>SELEC COUNT() FROM emp;
2. group by(用于对查询结果的分组统计) 和 having子句(用于限制分组显示结果)
SQL>SELECT deptno,MAX(sal),AVG(sal) FROM emp GROUP BY deptno;
SQL>SELECT deptno, job, AVG(sal),MIN(sal) FROM emp group by deptno,job having AVG(sal)<2000;
对于数据分组的总结:
a. 分组函数只能出现在选择列表、having、order by子句中(不能出现在where中)
b. 如果select语句中同时包含有group by, having, order by,那么它们的顺序是group by, having, order by。
c. 在选择列中如果有列、表达式和分组函数,那么这些列和表达式必须出现在group by子句中,否则就是会出错。
使用group by不是使用having的前提条件。
3. 多表查询
SQL>SELECT e.name,e.sal,d.dname FROM emp e, dept d WHERE e.deptno=d.deptno order by d.deptno;
SQL>SELECT e.ename,e.sal,s.grade FROM emp e,salgrade s WHER e.sal BETWEEN s.losal AND s.hisal;
4. 自连接(指同一张表的连接查询)
SQL>SELECT er.ename, ee.ename mgr_name from emp er, emp ee where er.mgr=ee.empno;
5. 子查询(嵌入到其他sql语句中的select语句,也叫嵌套查询)
5.1 单行子查询
SQL>SELECT ename FROM emp WHERE deptno=(SELECT deptno FROM emp where ename=’SMITH’);查询表中与smith同部门的人员名字。因为返回结果只有一行,所以用“=”连接子查询语句
5.2 多行子查询
SQL>SELECT ename,job,sal,deptno from emp WHERE job IN (SELECT DISTINCT job FROM emp WHERE deptno=10);查询表中与部门号为10的工作相同的员工的姓名、工作、薪水、部门号。因为返回结果有多行,所以用“IN”连接子查询语句。
in与exists的区别: exists() 后面的子查询被称做相关子查询,它是不返回列表的值的。只是返回一个ture或false的结果,其运行方式是先运行主查询一次,再去子查询里查询与其对 应的结果。如果是ture则输出,反之则不输出。再根据主查询中的每一行去子查询里去查询。in()后面的子查询,是返回结果集的,换句话说执行次序和 exists()不一样。子查询先产生结果集,然后主查询再去结果集里去找符合要求的字段列表去。符合要求的输出,反之则不输出。
5.3 使用ALL
SQL>SELECT ename,sal,deptno FROM emp WHERE sal> ALL (SELECT sal FROM emp WHERE deptno=30);或SQL>SELECT ename,sal,deptno FROM emp WHERE sal> (SELECT MAX(sal) FROM emp WHERE deptno=30);查询工资比部门号为30号的所有员工工资都高的员工的姓名、薪水和部门号。以上两个语句在功能上是一样的,但执行效率上,函数会高 得多。
5.4 使用ANY
SQL>SELECT ename,sal,deptno FROM emp WHERE sal> ANY (SELECT sal FROM emp WHERE deptno=30);或SQL>SELECT ename,sal,deptno FROM emp WHERE sal> (SELECT MIN(sal) FROM emp WHERE deptno=30);查询工资比部门号为30号的任意一个员工工资高(只要比某一员工工资高即可)的员工的姓名、薪水和部门号。以上两个语句在功能上是 一样的,但执行效率上,函数会高得多。
5.5 多列子查询
SQL>SELECT FROM emp WHERE (job, deptno)=(SELECT job, deptno FROM emp WHERE ename=’SMITH’);
5.6 在from子句中使用子查询
SQL>SELECT emp.deptno,emp.ename,emp.sal,t_avgsal.avgsal FROM emp,(SELECT emp.deptno,avg(emp.sal) avgsal FROM emp GROUP BY emp.deptno) t_avgsal where emp.deptno=t_avgsal.deptno AND emp.sal>t_avgsal.avgsal ORDER BY emp.deptno;
5.7 分页查询
数据库的每行数据都有一个对应的行号,称为rownum.
SQL>SELECT a2. FROM (SELECT a1., ROWNUM rn FROM (SELECT FROM emp ORDER BY sal) a1 WHERE ROWNUM<=10) a2 WHERE rn>=6;
指定查询列、查询结果排序等,都只需要修改最里层的子查询即可。
5.8 用查询结果创建新表
SQL>CREATE TABLE mytable (id,name,sal,job,deptno) AS SELECT empno,ename,sal,job,deptno FROM emp;
5.9 合并查询(union 并集, intersect 交集, union all 并集+交集, minus差集)
SQL>SELECT ename, sal, job FROM emp WHERE sal>2500 UNION(INTERSECT/UNION ALL/MINUS) SELECT ename, sal, job FROM emp WHERE job=’MANAGER’;
合并查询的执行效率远高于and,or等逻辑查询。
5.10 使用子查询插入数据
SQL>CREATE TABLE myEmp(empID number(4), name varchar2(20), sal number(6), job varchar2(10), dept number(2)); 先建一张空表;
SQL>INSERT INTO myEmp(empID, name, sal, job, dept) SELECT empno, ename, sal, job, deptno FROM emp WHERE deptno=10; 再将emp表中部门号为10的数据插入到新表myEmp中,实现数据的批量查询。
5.11 使用了查询更新表中的数据
SQL>UPDATE emp SET(job, sal, comm)=(SELECT job, sal, comm FROM emp where ename=’SMITH’) WHERE ename=’SCOTT’;
谈谈数据库事务的理解
1.什么事务?
是指作为单个逻辑工作单元执行的一系列操纵,要么完全地执行,要么完全地不执行。通俗来讲,比如完成一件事分为4个步骤 A,B,C,D; 每个步骤都是一个逻辑单元,完成一件事就是一个事务,这件事要么按顺序一起完成,要么完全的不执行。因此保持操纵的完整性。
2. 事务的四个特性:
(1)原子性Atomic)(Atomicity)
事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。通常,与某个事务关联的操作具有共同的目标,并且是相互依赖的。如果系统只执行这些操作的一个子集,则可能会破坏事务的总体目标。原子性消除了系统处理操作子集的可能性。
(2) 一致性(Consistent)(Consistency)<br /> 事务在完成时,必须使所有的数据都保持一致状态。在相关数据库中,所有规 则都必须应用于事务的修改,以保持所有数据的完整性。事务结束时,所有的内部数据结构(如 B 树索引或双向链表)都必须是正确的。某些维护一致性的责任由应用程序开发人员承担,他们必须确保应用程序已强制所有已知的完整性约束。例如,当开发用于转 帐的应用程序时,应避免在转帐过程中任意移动小数点。(3) 隔离性(Insulation)(Isolation)<br /> 由并发事务所作的修改必须与任何其它并发事务所作的修改隔离。事务查看数 据时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。这称为隔离性,因为它能够重新 装载起始数据,并且重播一系列事务,以使数据结束时的状态与原始事务执行的状态相同。当事务可序列化时将获得最高的[隔离级别](http://baike.baidu.com/view/687862.htm)。在此级别上,从一组可并行执行的事务获得的结果与通过连续运行每个事务所获得的结果相同。由于高度隔离会限制可并行执行的事务数,所以一些应用程序降低隔离级别以换取更大的吞吐量。(4) 持久性(Duration)(Durability)<br /> 事务完成之后,它对于系统的影响是永久性的。该修改即使出现致命的系统故障也将一直保持。
3.事务并发控制。
事务是并发控制的基本单位,保证事务ACID的特性是事务处理的重要任务,而并发操作有可能会破坏其ACID特性。
事务并发可能会引发的问题,多个用户同时访问一个数据库,则当他们的事务同时使用相同的数据时可能会发生问题。由于并发操作带来的数据不一致性包括:丢失数据修改、读”脏”数据(脏读)、不可重复读、产生幽灵数据。
(1)丢失数据修改
当两个或多个事务选择同一行,然 后基于最初选定的值更新该行时,会发生丢失更新问题。每个事务都不知道其它事务的存在。最后的更新将重写由其它事务所做的更新,这将导致数据丢失。如上例。
再例如,两个编辑人员制作了同一文档的电子复本。每个编辑人员独立地更改其复本,然后保存更改后的复本,这样就覆盖了原始文档。最后保存其更改复本的编辑人员覆盖了第一个编辑人员所做的更改。如果在第一个编辑人员完成之后第二个编辑人员才能进行更改,则可以避免该问题。
(2)读“脏”数据(脏读)
读“脏”数据是指事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被除撤消,而此时T1把已修改过的数据又恢复原值,T2读到的数据与数据库的数据不一致,则T2读到的数据就为“脏”数据,即不正确的数据。
例如:一个编辑人员正在更改电子文档。在更改过程中,另一个编辑人员复制 了该文档(该复本包含到目前为止所做的全部更改)并将其分发给预期的用户。此后,第一个编辑人员认为所做的更改是错误的,于是删除了所做的编辑并保存了文 档。分发给用户的文档包含不再存在的编辑内容,并且这些编辑内容应认为从未存在过。如果在第一个编辑人员确定最终更改前任何人都不能读取更改的文档,则可 以避免该问题。
(3)不可重复读
指事务T1读取数据后,事务T2执行更新操作,使T1无法读取前一次结果。不可重复读包括三种情况:
事务T1读取某一数据后,T2对其做了修改,当T1再次读该数据后,得到与前一不同的值。
(4)产生幽灵数据
按一定条件从数据库中读取了某些记录后,T2删除了其中部分记录,当T1再次按相同条件读取数据时,发现某些记录消失
T1按一定条件从数据库中读取某些数据记录后,T2插入了一些记录,当T1再次按相同条件读取数据时,发现多了一些记录
聊聊涨读,幻读,不可重复读
(1)丢失数据修改
当两个或多个事务选择同一行,然 后基于最初选定的值更新该行时,会发生丢失更新问题。每个事务都不知道其它事务的存在。最后的更新将重写由其它事务所做的更新,这将导致数据丢失。如上例。<br />再例如,两个编辑人员制作了同一文档的电子复本。每个编辑人员独立地更改其复本,然后保存更改后的复本,这样就覆盖了原始文档。最后保存其更改复本的编辑人员覆盖了第一个编辑人员所做的更改。如果在第一个编辑人员完成之后第二个编辑人员才能进行更改,则可以避免该问题。
(2)读“脏”数据(脏读)
读“脏”数据是指事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被除撤消,而此时T1把已修改过的数据又恢复原值,T2读到的数据与数据库的数据不一致,则T2读到的数据就为“脏”数据,即不正确的数据。<br />例如:一个编辑人员正在更改电子文档。在更改过程中,另一个编辑人员复制 了该文档(该复本包含到目前为止所做的全部更改)并将其分发给预期的用户。此后,第一个编辑人员认为所做的更改是错误的,于是删除了所做的编辑并保存了文 档。分发给用户的文档包含不再存在的编辑内容,并且这些编辑内容应认为从未存在过。如果在第一个编辑人员确定最终更改前任何人都不能读取更改的文档,则可 以避免该问题。
(3)不可重复读
指事务T1读取数据后,事务T2执行更新操作,使T1无法读取前一次结果。不可重复读包括三种情况:<br />事务T1读取某一数据后,T2对其做了修改,当T1再次读该数据后,得到与前一不同的值。
(4)产生幽灵数据
按一定条件从数据库中读取了某些记录后,T2删除了其中部分记录,当T1再次按相同条件读取数据时,发现某些记录消失<br />T1按一定条件从数据库中读取某些数据记录后,T2插入了一些记录,当T1再次按相同条件读取数据时,发现多了一些记录
spring创建Bean的几种方式
1:调用构造器创建Bean
2:调用静态工厂方法创建Bean
3:调用实例工厂方法创建Bean
一:调用构造方法创建Bean
调用构造方法创建Bean是最常用的一种情况Spring容器通过new关键字调用构造器来创建Bean实例,通过class属性指定Bean实例的实现类,也就是说,如果使用构造器创建Bean方法,则
二:配置文件beans.xml
配置文件中,通过
二:调用静态工厂方法创建Bean
把创建Bean的任务交给了静态工厂,而不是构造函数,这个静态工厂就是一个Java类,那么使用静态工厂创建Bean咱们又需要在
class:指定静态工厂的实现类,告诉Spring该Bean实例应该由哪个静态工厂创建(指定工厂地址)
factory-method:指定由静态工厂的哪个方法创建该Bean实例(指定由工厂的哪个车间创建Bean)
如果静态工厂方法需要参数,则使用
三:调用实例工厂方法创建Bean
静态工厂通过class指定静态工厂实现类然后通过相应的方法创建即可,调用实例工厂则需要先创建该工厂的Bean实例,然后引用该实例工厂Bean的id创建其他Bean,在实例工厂中通过factory-bean指定工厂Bean的实例,在调用实例化工厂方法中,不用在
factory-bean :该属性指定工厂Bean的id
factory-method:该属性指定实例工厂的工厂方法
restful接口规范
聊聊面向对象的特征的理理
1、封装:
封装是把过程和数据包围起来,对数据的访问只能通过已定义的界面。面向对象计算始于这个基本概念,即现实世界可以被描绘成一系列完全自治、封装的对象,这些对象通过一个受保护的接口访问其他对象。
2、继承:
继承是一种联结类的层次模型,并且允许和鼓励类的重用,它提供了一种明确表述共性的方法。对象的一个新类可以从现有的类中派生,这个过程称为类继承。新类继承了原始类的特性,新类称为原始类的派生类(子类),而原始类称为新类的基类(父类)。
3、多态性:
多态性是指允许不同类的对象对同一消息作出响应。比如同样的加法,把两个时间加在一起和把两个整数加在一起肯定完全不同。多态性语言具有灵活、抽象、行为共享、代码共享的优势,很好的解决了应用程序函数同名问题
多态
说到重载和重写,大家可能都知道。它们都是多态性的体现,那么说什么是多态呢?多态是指允许不同子类型的对象对同一行为作出不同的响应。例如在生活中,比如跑的动作,小猫、小狗和大象,跑起来是不一样的。再比如飞的动作,昆虫、鸟类和飞机,飞起来也 是不一样的。可见,同一行为,通过不同的事物,可以体现出来的不同的形态。多态描述的就是这样的状态。
多态性分为编译时的多态性和运行时的多态性。方法重载(overload)实现的是编译时的多态性(也称为前绑定),而方法重写(override)实现的是运行时的多态性(也称为后绑定)。运行时的多态是面向对象最精髓的东西,要实现运行时多态需要做以下两件事情:
- 方法重写(子类继承父类并重写父类中已有的或抽象的方法);
- 对象造型(用父类型引用引用子类型对象,这样同样的引用调用同样的方法就会根据子类对象的不同而表现出不同的行为)。
3.两种多态形式的区别.
那么到底如何判定是编译时多态还是运行时多态呢?它们之间的区别到底是什么呢?如果在编译时能够确定执行多态方法中的哪一个,称为编译时多态,否则称为运行时多态。下面我们就从重载和重写两方面来认识一下这两种多态机制。
编译时多态:
1.方法重载:
方法重载就是在同一个类中,出现了多个同名的方法,他们的参数列表(方法签名)不同 (参数列表的个数不同,参数列表的数据类型不同,参数列表的顺序不同)。根据实际参数的数据类型、个数和次序,Java在编译时能够确定执行重载方法中的哪一个。
2.方法重写时的编译时多态:
除了重载,重写也表现出两种多态性。当一个对象的引用指向的是当前对象所属类的对象时,为编译时多态.其他则为运行时多态。如下:
public class Father {
public void say() {System.out.println("我是爸爸");}
}
public class Sun extends Father{
public void say() {System.out.println("我是儿子");}public static void main(String[] args) {Sun sun = new Sun();Father father = new Father();sun.say();father.say();}
}
如main方法中所书写的那样,sun的引用指向的就是Sun类的对象,故在编译时期就可以确定要执行sun类中的say()方法,故属于编译时多态。
运行时多态:
运行时多态一个最显著的例子就是子类的上转型对象,即父类引用指向之类对象,调用的方法只能是父类下包含的方法(指向子类的那个父类引用),执行的结果是子类重写以后的。例如:
public class Father {
public void say() {System.out.println("我是爸爸");}
}
public class Sun extends Father{
public void say() {System.out.println("我是儿子");}public static void main(String[] args) {Father father = new Sun();father.say();}
}
执行结果为:
从程序的运行结果我们可以发现,它执行的是子类的方法。为什么呢?这是因为Java支持运行时多态,当执行father,say()时,在编译时期,首先会去查看father类里面有没有这个方法,如果没有的话向上继续查找,直到找到Object类如果还没有的话就报错,如果有的话,到运行阶段,再去看一下子类中有没有覆盖该方法,如果覆盖了,则执行子类覆盖的方法。如果没有则执行父类中原本的方法。
运行时多态的陷阱
1.子类新增加的方法通过多态可以执行吗?
看下面代码:
public class Father {
public void say() {System.out.println("我是爸爸");}
}
public class Sun extends Father{
public void say() {System.out.println("我是儿子");}public void write() {System.out.println("我是子类新增的方法");}public static void main(String[] args) {Father father = new Sun();father.say();///编译时报错The method write() is undefined for the type Fatherfather.write();}
}
在编译father.write();这行时,编译时报错The method write() is undefined for the type Father因此,当父类引用指向子类对象时候,父类只能执行那些在父类中声明、被子类覆盖了的子类方法(如上文中的say()),而不能执行子类增加的成员方法。
2.如果父类中的属性被子类覆盖,会显示哪个属性的值呢?
public class Father {
String str = “father”;
public void say() {
System.out.println(“我是爸爸”);
}
}
public class Sun extends Father{
String str = “sun”;
public void say() {
System.out.println(“我是儿子”);
}
public static void main(String[] args) {Father father = new Sun();System.out.println(father.str);}
}
运行结果如下图所示
所以,当子类和父类有相同属性时,父类还是会执行自己所拥有的属性,若父类中没有的属性子类中有,当父类对象指向子类引用时(向上转型),在编译时期就会报错
3.如果父类中的static方法被子类覆盖呢?会执行哪个?
看下面代码:
public class Father {
public static void say() {
System.out.println(“我是爸爸”);
}
}
public class Sun extends Father{
public static void say() {
System.out.println(“我是儿子”);
}
public static void main(String[] args) {Father father = new Sun();father.say();}
}
执行结果如下
从上图的程序运行结果我们可以看到,father.say()语句执行的是Father类中的say方法。所以对于static方法还是会执行父类中的方法
这是由于在运行时,虚拟机已经认定static方法属于哪个类。“重写”只能适用于实例方法,不能用于静态方法。对于静态方法,只能隐藏,重载,继承。
子类会将父类静态方法的隐藏(hide),但子类的静态方法完全体现不了多态,就像子类属性隐藏父类属性一样,在利用引用访问对象的属性或静态方法时,是引用类型决定了实际上访问的是哪个属性,而非当前引\用实际代表的是哪个类。因此,子类静态方法不能覆盖父类的静态方法。 而fafther的引用类型为Father,因此会执行Father的静态方法。
总结
(1)多态是指不同子类型的对象对同一行为作出不同的响应。
(2)多态性分为编译时的多态性和运行时的多态性。方法重载实现的是编译时的多态性,而方法重写(实现的是运行时的多态性。
(3)对于运行时多态,特别注意,父类引用指向子类对象,在调用实例方法时,调用的是子类重写之后的,并且不能调用子类新增的方法,对于属性和static方法来说,还是执行父类原有的。
面向对象中的各种关键字
This:
1、代表当前对象本身
2、在构造器中可以使用this([参数])调用本类的其他构造器
3、有时候需要把当前调用对象进行传递,那么就可以使用this替代当前调用对象
Super:
1、指代父类
2、super() 调用父类的构造器
3、super()如果放在子类构造器中调用,只能放在子类构造器代码的第一行
4、使用super.xxx()可以在子类中调用父类中的方法
Static:
1.静态的属性和静态的方法属于整个类,不是属于某个对象的
2.静态的值只有一个(基本数据类型可以看出此特点)
3.静态的值只会初始化一次(引用数据类型)
4.静态属性,方法或者静态块会在jvm加载的时候就加载
5.一般情况下,静态的常量属性,我们一般写为 public static final 数据类型 大写常量名 = 值
6、静态方法下不能用this
执行顺序:static(静态的)—静态块{}—构造器
Javabean:
1、所有的属性都是private(私有的)
2、为每个属性建立setter和getter方法
3、为了以后装数据用的一个类
New:
1、注意:一个问题.不要觉得有时候参数需要一个对象,就直接new 一个对象传过去
2、只要使用new关键字,就是创建一个新的对象
Instanceof(目的:转型):
判断某个对象是不是某一个类型(子类是父类的对象,但父类不一定是子类的)
Object:
所有类的父类
final
1.可以用来修饰变量,如果修饰变量,这个变量我们就称之为常量,值不能被修改,而且常量必须赋初始值,一般情况下,常量我们会定义为 public static final 数据类型 大写常量名 = 值
2.如果final修饰方法,表示这个方法不能被重写(实现)
3.如果final修饰类,表示这个类不能被继承
抽象类和接口的区别?
1.接口中所有的方法隐含的都是抽象的(jdk1.8以前),而抽象类可以同时包含抽象方法和非抽象方法
2.类可以实现多个接口,但是只能继承一个类
3.类如果要实现一个接口,它必须要实现接口声明的所有方法(jdk1.8以前),但是类可以不用实现抽象类声明的非抽象方法,
4.抽象类可以在不提供接口方法实现的情况下实现接口
5.java接口中的成员变量默认是final的,抽象类可以包含非final的成员变量
6.java接口中的成员函数默认只能是public的,抽象类的成员函数可以是private。protected或者是public的
7.接口是绝对抽象的,不能被实例化(java8支持在接口内实现默认的方法),抽象类也不能被实例化,但是,如果它包含main方法的话是可以被调用的
mybatis的动态sql
在mapper配置文件中,有时需要根据查询条件选择不同的SQL语句,或者将一些使用频率高的SQL语句单独配置,在需要使用的地方引用。Mybatis的一个特性:动态SQL,来解决这个问题。
mybatis动态sql语句是基于OGNL表达式的,主要有以下几类:
1. if 语句 (简单的条件判断)
2. choose (when,otherwize) ,相当于java 语言中的 switch ,与 jstl 中的choose 很类似
3. trim (对包含的内容加上 prefix,或者 suffix 等,前缀,后缀)
4. where (主要是用来简化sql语句中where条件判断的,能智能的处理 and or ,不必担心多余导致语法错误)、
5. set (主要用于更新时)
6. foreach (在实现 mybatis in 语句查询时特别有用)
springmvc如何实现json数据交互?
@RequestBody
作用:
@RequestBody注解用于读取http请求的内容(字符串),通过springmvc提供的HttpMessageConverter接口将读到的内容(json数据)转换为java对象并绑定到Controller方法的参数上
@ResponseBody
作用:
@ResponseBody注解用于将Controller的方法返回的对象,通过springmvc提供的HttpMessageConverter接口转换为指定格式的数据如:json,xml等,通过Response响应给客户端。
mybatis的多参数处理
1.1使用@Param注解
MyBatis 允许在mapper 接口中使用@Param注解来处理多个参数。
1.2使用Map封装多个参数
MyBatis 允许使用Map来封装需要在SQL 中传入的参数。
1.3使用#{param1 … n}参数
如果我们既不用@Param也不使用map,那么可以在编写SQL 语句的时候,使用#{param1 … n}来代表需要传递的参数
mybatis的一级和二级缓存
一级缓存
Mybatis对缓存提供支持,但是在没有配置的默认情况下,它只开启一级缓存,一级缓存只是相对于同一个SqlSession而言。所以在参数和SQL完全一样的情况下,我们使用同一个SqlSession对象调用一个Mapper方法,往往只执行一次SQL,因为使用SelSession第一次查询后,MyBatis会将其放在缓存中,以后再查询的时候,如果没有声明需要刷新,并且缓存没有超时的情况下,SqlSession都会取出当前缓存的数据,而不会再次发送SQL到数据库。
怎么判断某两次查询是完全相同的查询?
mybatis认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询。
2.1 传入的statementId
2.2 查询时要求的结果集中的结果范围
2.3. 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() )
2.4传递给java.sql.Statement要设置的参数值
二级缓存:
MyBatis的二级缓存是Application级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。
SqlSessionFactory层面上的二级缓存默认是不开启的,二级缓存的开席需要进行配置,实现二级缓存的时候,MyBatis要求返回的POJO必须是可序列化的。 也就是要求实现Serializable接口,配置方法很简单,只需要在映射XML文件配置就可以开启缓存了
映射语句文件中的所有select语句将会被缓存。
映射语句文件中的所欲insert、update和delete语句会刷新缓存。
缓存会使用默认的Least Recently Used(LRU,最近最少使用的)算法来收回。
根据时间表,比如No Flush Interval,(CNFI没有刷新间隔),缓存不会以任何时间顺序来刷新。
缓存会存储列表集合或对象(无论查询方法返回什么)的1024个引用
缓存会被视为是read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全的被调用者修改,不干扰其他调用者或线程所做的潜在修改。
谈谈Hashmap的扩容原理
- capacity 即容量,默认16。
- loadFactor 加载因子,默认是0.75
- threshold 阈值。阈值=容量*加载因子。默认12。当元素数量超过阈值时便会触发扩容。
什么时候触发扩容?
一般情况下,当元素数量超过阈值时便会触发扩容。每次扩容的容量都是之前容量的2倍。
HashMap的容量是有上限的,必须小于1<<30,即1073741824。如果容量超出了这个数,则不再增长,且阈值会被设置为Integer.MAX_VALUE(  ,即永远不会超出阈值了)。
,即永远不会超出阈值了)。
JDK7中的扩容机制
JDK7的扩容机制相对简单,有以下特性:
- 空参数的构造函数:以默认容量、默认负载因子、默认阈值初始化数组。内部数组是空数组。
- 有参构造函数:根据参数确定容量、负载因子、阈值等。
- 第一次put时会初始化数组,其容量变为不小于指定容量的2的幂数。然后根据负载因子确定阈值。
- 如果不是第一次扩容,则
 ,
,  。
。
JDK8的扩容机制
JDK8的扩容做了许多调整。
HashMap的容量变化通常存在以下几种情况:
- 空参数的构造函数:实例化的HashMap默认内部数组是null,即没有实例化。第一次调用put方法时,则会开始第一次初始化扩容,长度为16。
- 有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让
 。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!)
。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!) - 如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,负载因子还是不变)
此外还有几个细节需要注意:
- 首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;
- 不是首次put,则不再初始化,直接存入数据,然后判断是否需要扩容;
- JDK7的元素迁移
JDK7中,HashMap的内部数据保存的都是链表。因此逻辑相对简单:在准备好新的数组后,map会遍历数组的每个“桶”,然后遍历桶中的每个Entity,重新计算其hash值(也有可能不计算),找到新数组中的对应位置,以头插法插入新的链表。
这里有几个注意点:
- 是否要重新计算hash值的条件这里不深入讨论,读者可自行查阅源码。
- 因为是头插法,因此新旧链表的元素位置会发生转置现象。
- 元素迁移的过程中在多线程情境下有可能会触发死循环(无限进行链表反转)。
JDK8的元素迁移
JDK8则因为巧妙的设计,性能有了大大的提升:由于数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在原长度+原位置的位置。原因如下图: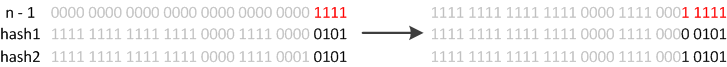
数组长度变为原来的2倍,表现在二进制上就是多了一个高位参与数组下标确定。此时,一个元素通过hash转换坐标的方法计算后,恰好出现一个现象:最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标”。如下图: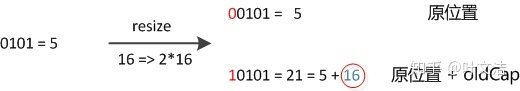
因此,在扩容时,不需要重新计算元素的hash了,只需要判断最高位是1还是0就好了。
JDK8的HashMap还有以下细节:
JDK8在迁移元素时是正序的,不会出现链表转置的发生。
如果某个桶内的元素超过8个,则会将链表转化成红黑树,加快数据查询效率。
聊聊Hashmap的底层结构区分1.7和1.8
JDK1.7中的HashMap是一个数据与链表的结合体。底层是一个数组结构,数组中的每一项都是一个链表,当新建一个HashMap的时候,就会初始化一个数组。
hashmap的成员变量
1.DEFAULT_INITIAL_CAPACITY = 1 << 4;:初始桶(数组)大小为16,因为底层是数组,所以也是数组大小
2.MAXIMUM_CAPACITY = 1 << 30:桶最大值,2的30次方
3.DEFAULT_LOAD_FACTOR = 0.75f;默认的负载因子0.75
4.table:真正存放数据的数组
5. size:map中存放的键值对的数量。
6. threshold:resize扩容时的阈值
7. loadFactor:负载因子,可在初始化时显式指定。
在不设置初始化map大小的时候,默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,扩容是成倍的扩容,乘以就是32,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
在1.7中添加元素的put过程如下
1、先判断key是否为null,如果是null则会插入头结点table[0]的位置
2、key不为null,计算key的hashCode,对数组的大小取模,hash & (length-1),得到在数组中的位置,如果数组上已经有元素了,那么遍历该位置上的元素,如果存在hash、key都相等,那么说明是同一个key,则将原来的值覆盖,并且返回原来的值oldValue。如果这个元素上找不到要添加的key,说明是一个新值,则使用头插法,插入元素链表的头部
3、如果数组上没有元素,当前位置没有数据插入,那么会新增一个entry写入当前位置。
当调用addentry的时候,就会判断是否需要扩容,如果需要扩容,就重新计算hashcode,同时也需要重新定位元素的位置,扩容的时候会将旧数组中的元素迁移到新数组中
get 方法
先判断key的hashcode,定位到在数组的具体位置中
判断该位置是否是链表,如果是就遍历链表,直到找到key和hashcode相等的。不是链表就直接 key、key 的 hashcode 是否相等来返回值。啥都没有就返回空…
JDK1.7中并发场景下出现死循环
多线程同时put的时候,如果同时调用了resize操作,可能会导致循环链表的产生,进而使得后面get的时候,会死循环,数组扩容的时候将调用transfer函数将旧数组中的元素迁移到新的数组,这里会重新计算hashcode,使用是头插法方式。
假设有两个线程T1,和T2,HashMap的容量为2,T1线程存入key A B C D E 。T1线程中计算A B C的hash值相同,于是形成一个链接,假设 A->C->B,而D,E的hash值不同,于是容量不足,需要扩容把老的hash表中的数组迁移到新的hash表中(refresh)。这时T2线程进来,T1暂时挂起,T2也准备放入新的Key,这时也发现容量不足,需要扩容,也refresh一下,假设原来的链表结构为C->A,之后T1继续执行,链表结构为A->C,这时就形成了A.next=B,B.next=A的环形链表,一旦取值进入就会陷入死循环
JDK1.8中的HashMap
数据结构
JDK1.8中的HashMap底层使用的是数组+链表,链表过长会转为红黑树,链表长度超过8转为红黑树,低于6转为链表。
1.8中put方法:
1.对key求哈希值然后计算下标
2.如果没有哈希碰撞直接放入槽中(没有哈希碰撞说明当前位置没有内容)
3.如果发生碰撞了就以链表的形式放到后面
4.如果链表长度超过阈值,就把链表转为红黑树
5.如果节点已经存在就替换旧值
6.如果槽满了就需要扩容
1.8扩容过程
1.根据新的容量(2倍)新建一个数组,保存旧的数组
2.遍历旧数组的每一个数据,重新计算每个数据在新数组中的存储位置。(要么是原位置,要么是原位置+旧容量),将旧数组中的每个数据转移到新的数组中,使用尾插法。
1.8扩容和1.7扩容的区别
1.转移数组方式不同,1.7中是头插法,1.8中是尾插法
2.位置的计算方式不同,1.8中容量扩充为原来的2倍,扩容后的位置要么等于原位置,要么等于原位置+旧容量。1.7中是全部按照原来方法计算,全部重新计算一次hashcode
新数据的插入时机不同,1.8中是扩容前插入,转移数据时统一计算插入位置。1.7中的新数据是扩容后插入,插入位置也是转移老数据之后,再单独计算的。
JDK7是每拿到一个Node就直接插入到newTable,而JDK8是先插入到高低链表中,然后再一次性插入到newTable
哈希冲突有哪些解决方法?
1.开放地址法(开辟一个新的空间地址存储),
2,链地址法(在已有的链表上新增一个节点存储)。
1.8中发生了哈希冲突,就是使用了链接地址法+尾插法+红黑树 1.7中使用了链接地址法+头插法
为什么在JDK1.8中进行对HashMap优化的时候,把链表转化为红黑树的阈值是8,而不是7或者不是20呢?
节点分布在hash桶中的频率遵循泊松分布,桶的长度超过8的概率非常小,所以坐着根据概率统计选择了8,链表小于等于6树还原转为链表,大于等于8转为树,中间有个差值7可以有效防止链表和树频繁转换。
总结
1.数据结构
Java 7及以前是数组+链表、Java 8及以后是数组+链表+红黑树。
1.8中,当链表长度到达8的时候,会转化成红黑树。
2.插入链表的方式
1.7是头插法,1.8是尾插法
3.扩容时,调整数据的方式
1.7其实就是根据hash值重新计算索引位置,然后将数据重新放到应该在的位置。
1.8中按扩容后的位置要么等于原位置,要么等于原位置+旧容量
4.hash值的计算方式不同
jdk1.7获取hash值是9次扰动处理=4次位运算+5次异或,而JDK1.8只用了2次扰动处理=1次位运算+1次异或。
jdk1.8获取hash值,是将高16位和低16位进行异或就得到了。
5.新数据的插入时机不同
1.8中是扩容前插入,转移数据时统一计算插入位置。1.7中的新数据是扩容后插入,插入位置也是转移老数据之后,再单独计算的。
为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键
String Integer等包装类,内部已经重写了hashcode和equals方法,保证了Hash值的不可更改性,计算准确性,而且又是final类型,保证了key的不可更改性
HashMap 中的 key若 Object类型, 则需实现哪些方法?
需要实现hashcode和equals方法
hashcode,计算需要存储数据的位置
equals:判断存储位置上是否已经存在当前Key,保证key在hash表中的唯一性
[
](https://blog.csdn.net/a718515028/article/details/108265496)
聊聊concurrenthashmap怎么实现线程安全
在jdk1.7中是采用Segment + HashEntry + ReentrantLock的方式进行实现的,而1.8中放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现。
- JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
- JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
- JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档。而Node的val和next都使用volatile修饰,保证可见性(替换、查找、赋值操作使用CAS,而扩容和Hash冲突使用Synchronized)
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量的缓存行无效,所以线程1再次读取变量的值时会去主存读取。
总结
在1.8中ConcurrentHashMap的get操作全程不需要加锁,这也是它比其他并发集合比如hashtable、用Collections.synchronizedMap()包装的hashmap;安全效率高的原因之一。
get操作全程不需要加锁是因为Node的成员val是用volatile修饰的和数组用volatile修饰没有关系。
数组用volatile修饰主要是保证在数组扩容的时候保证可见性
聊聊arraylist的初始容量和扩容机制
1.servlet的生命周期
2.jvm的五大内存模型
3.GC的常用回收算法
4.类的加载过程
5.双亲委派模型
1.线程的创建方式
2.谈谈CAS和ABA
3.聊聊对象的锁升级过程
面试宝典1-6页内容
【问答】谈谈对Vue-router的理解
2. 【问答】聊聊对Mybatis-Plus的理解
3. 【问答】说出Redis的数据类型和特点
1.内存模型(1.7 和1.8),每个模型做什么?
2.堆内存组成(新生代和老年代)怎么?
3.Java中类的加载过程?
1.类加载器有哪些?
2.双亲委派模型?如何打破?
3.内存溢出和内存泄漏?
1.GC怎么判断对象是否可回收
2.GC常用算法
3.GC在堆内存的工作过程
1.GC的回收器(CMS和G1)?
2.Java中4种引用及区别?
3.final、finally与finalize的区别?
4.哪些可以作为GC ROOTS?
1.面向对象的认知?
2.面向对象的特征以及理解?
3.this和super?
4.抽象类和接口(1.7和1.8)的区别?
5.各种关键字:static final instanceof?
6.装箱和拆箱?
1.排序算法(冒泡、快排)
2.查找算法(二分)
3.数组元素去重算法
4.ArrayList底层,初始容量,扩容
1.HashMap底层结构1.7和1.8
2.HashMap的头插法和尾插法3.HashMap的put源码过程
4.ConCurrentHashMap底层1.7和1.8 安全(JUC)
今日晨读内容:1.排序算法(冒泡、快排)
2.查找算法(二分)
3.数组元素去重算法
4.ArrayList底层,初始容量,扩容
线程的创建方式(4种)
线程的生命周期(状态)
sleep和wait
线程调度方法:join、notify
1.线程池的五大状态
2.线程池的七大参数:核心线程,阻塞队列,最大线程,拒接策略
3.线程池的工作原理
4.线程池的线程增长和回收策略
1.锁的相关分类:乐观|悲观、公平|非公平、可重入|不可重入、共享|排他?
2.对象的锁升级过程(无锁、偏向锁、轻量级锁、重量级锁)?
3.synchronized的三种用法和区别?
4.synchronized的实现原理?
1.谈谈Spring的IOC和DI的理解?
2.聊聊Spring的声明式事务?
3.聊聊Spring循环依赖的原因和解决方案?
4.写出你常用的Spring注解和作用?
1.SpringMVC常用注解并解释
2.Mybatis的缓存策略的理解
3.Mybatis的$和#的区别和使用场景?
4.Mybatis的动态SQL和作用
5.SpringMVC的拦截器和过滤器的区别?
晨读必会内容springboot相关内容,特别是自动装配原理。
1.SpringBoot项目中常用的注解并解释?
2.SpringBoot的自动装配原理?
3.聊聊yaml和properties的区别?
4.谈谈对SpringBoot的约定大于配置的理解?
1.SpringCloud的常用组件并解释?
2.聊聊Gateway的作用和核心内容?
3.谈谈事务的作用?
4.写出事务的四大特性?
5.写出涨读、幻读、不可重复读?
1.谈谈存储引擎的差异,innodb和myisma
2.聊聊函数和存储过程的理解
3.谈谈索引的认知
4.请写出sql语句分类
5.谈谈sql优化
1.Redis的数据类型和特点?
2.Redis的持久化和区别?
3.Redis的过期策略?
4.聊聊Redis的淘汰机制的理解?
5.Redis的事务是什么?
redis剩余面试题,击穿,血崩,穿透,倾斜,分布式锁的实现。
1.写出Lambda表达式的理解
2.synchronized和lock的区别
3.synchronized实现原理
4.voliate关键字用法
5.写出JUC的认知
1.hashmap如何遍历元素有几种?
2.Hasmap的底层和红黑树的转换?
3.HashMap的扩容原理?
4.HashMap和HashTable的区别?
1.如何保证消息的幂等性?
2.RabbitMQ消息如何防止丢失
3.RabbitMQ如何防止消息重复消费?
4.RabbitMQ的exchange的类型和区别
5.一般你是如何使用RabbitMQ?

若有收获,就点个赞吧
0 人点赞
