- 大纲梳理
- 一、JVM&GC
- 双亲委派模式优势
- 二、语法&OOP
- 2.6 抽象类&接口
- 2.7 this&super
- 2.8 访问修饰符
- 2.9 Object
- 2.10 Java中4种引用
- 三、数组&集合
- 3.2 查找算法(手写)
- 7.7 SpringMVC的运行流程
- 7.8 拦截器
- 7.9 RestFul
- 7.10 SpringMVC常用注解
- 7.11 Mybatis实现原理
- 7.12 Mybats缓存机制
- 7.13 Mybatis的多表关系
- 7.14 Mybatis动态SQL
- 7.15 Mybais
- :默认,可以防止SQL注入(关键字格式化),但是只能传递数据
- 八、工具(Git Maven)
- 九、微服务(SpringBoot、SpringCloud)
- 十、中间件(RabbitMQ、Elasticsearch)
- 十一、Mysql
- 十二、Redis
- 十四、前端(Html、Css、Js、Vue)
大纲梳理
一、JVM&GC
1.1 JDK&JRE
JDK:Java Development Kit,软件开发工具包,包含jre
JRE:Java Runtime Environment,运行环境
常用的命令:
javac
java
javap
1.2 配置JDK
1.3 JVM的内存模型
堆:引用类型真正存储数据的地方,组成:新生代(伊甸区:幸存者区1:幸存者区2)、老年代
虚拟机栈:记录方法运行时,所需要的内容
本地方法栈:native 修饰的方法,方法的实现是由第三方语言(C或者C++)实现
程序计数器:记录线程的执行情况
方法区|元空间:记录定义、常量、静态
1.7 方法区 1.8 元空间
1.4 类的加载过程
- 一般来说,我们把 Java 的类加载过程分为三个主要步骤:加载、链接、初始化,具体行为在Java 虚拟机规范里有非常详细的定义。
- 首先是加载阶段(Loading),它是 Java 将字节码数据从不同的数据源读取到 JVM 中,并映射为 JVM 认可的数据结构(Class 对象),这里的数据源可能是各种各样的形态,如 jar 文件、class 文件,甚至是网络数据源等;如果输入数据不是 ClassFile 的结构,则会抛出 ClassFormatError。
- 加载阶段是用户参与的阶段,我们可以自定义类加载器,去实现自己的类加载过程。
- 第二阶段是链接(Linking),这是核心的步骤,简单说是把原始的类定义信息平滑地转化入 JVM 运行的过程中。这里可进一步细分为三个步骤:
- 验证(Verification),这是虚拟机安全的重要保障,JVM 需要核验字节信息是符合 Java 虚拟机规范的,否则就被认为是 VerifyError,这样就防止了恶意信息或者不合规的信息危害 JVM 的运行,验证阶段有可能触发更多 class 的加载。
- 准备(Preparation),创建类或接口中的静态变量,并初始化静态变量的初始值。但这里的“初始化”和下面的显式初始化阶段是有区别的,侧重点在于分配所需要的内存空间,不会去执行更进一步的 JVM 指令。
- 解析(Resolution),在这一步会将常量池中的符号引用(symbolic reference)替换为直接引用。在Java 虚拟机规范中,详细介绍了类、接口、方法和字段等各个方面的解析。
- 最后是初始化阶段(initialization),这一步真正去执行类初始化的代码逻辑,包括静态字段赋值的动作,以及执行类定义中的静态初始化块内的逻辑,编译器在编译阶段就会把这部分逻辑整理好,父类型的初始化逻辑优先于当前类型的逻辑。
1.5 双亲委派模型
- (现象:创建对象的时候,会优先使用父级加载器,如果不存在就以此往下推
- 目的:提高效率,保证安全
- 再来谈谈双亲委派模型,简单说就是当类加载器(Class-Loader)试图加载某个类型的时候,除非父加载器找不到相应类型,否则尽量将这个任务代理给当前加载器的父加载器去做。使用委派模型的目的是避免重复加载 Java 类型。)
双亲委派模式是在Java 1.2后引入的,其工作原理的是,如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式
双亲委派模式优势
- 采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。
- 其次是考虑到安全因素,java核心api中定义类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。
1.6 GC验证对象是否回收
JVM GC回收哪个区域内的垃圾?
需要注意的是,JVM GC只回收堆区和方法区内的对象。而栈区的数据,在超出作用域后会被JVM自动释放掉,所以其不在JVM GC的管理范围内。
JVM GC怎么判断对象可以被回收了?
· 对象没有引用
· 作用域发生未捕获异常
· 程序在作用域正常执行完毕
· 程序执行了System.exit()
· 程序发生意外终止(被杀线程等)
JVM GC什么时候执行?
eden区空间不够存放新对象的时候,执行Minro GC。升到老年代的对象大于老年代剩余空间的时候执行Full GC,或者小于的时候被HandlePromotionFailure 参数强制Full GC 。调优主要是减少 Full GC 的触发次数,可以通过 NewRatio 控制新生代转老年代的比例,通过MaxTenuringThreshold 设置对象进入老年代的年龄阀值(后面会介绍到)。
新生代(Young generation):绝大多数最新被创建的对象都会被分配到这里,由于大部分在创建后很快变得不可达,很多对象被创建在新生代,然后“消失”。对象从这个区域“消失”的过程我们称之为:Minor GC 。
老年代(Old generation):对象没有变得不可达,并且从新生代周期中存活了下来,会被拷贝到这里。其区域分配的空间要比新生代多。也正由于其相对大的空间,发生在老年代的GC次数要比新生代少得多。对象从老年代中消失的过程,称之为:Major GC 或者 Full GC。
持久代(Permanent generation)也称之为 方法区(Method area):用于保存类常量以及字符串常量。注意,这个区域不是用于存储那些从老年代存活下来的对象,这个区域也可能发生GC。发生在这个区域的GC事件也被算为 Major GC 。只不过在这个区域发生GC的条件非常严苛,必须符合以下三种条件才会被回收:
1、所有实例被回收
2、加载该类的ClassLoader 被回收
3、Class 对象无法通过任何途径访问(包括反射)
如果老年代的对象需要引用新生代的对象,会发生什么呢?
为了解决这个问题,老年代中存在一个 card table ,它是一个512byte大小的块。所有老年代的对象指向新生代对象的引用都会被记录在这个表中。当针对新生代执行GC的时候,只需要查询 card table 来决定是否可以被回收,而不用查询整个老年代。这个 card table 由一个write barrier 来管理。write barrier给GC带来了很大的性能提升,虽然由此可能带来一些开销,但完全是值得的。
新生代空间的构成与逻辑
为了更好的理解GC,我们来学习新生代的构成,它用来保存那些第一次被创建的对象,它被分成三个空间:
· 一个伊甸园空间(Eden)
· 两个幸存者空间(Fron Survivor、To Survivor)
默认新生代空间的分配:Eden : Fron : To = 8 : 1 : 1
每个空间的执行顺序如下:
1、绝大多数刚刚被创建的对象会存放在伊甸园空间(Eden)。
2、在伊甸园空间执行第一次GC(Minor GC)之后,存活的对象被移动到其中一个幸存者空间(Survivor)。
3、此后,每次伊甸园空间执行GC后,存活的对象会被堆积在同一个幸存者空间。
4、当一个幸存者空间饱和,还在存活的对象会被移动到另一个幸存者空间。然后会清空已经饱和的哪个幸存者空间。
5、在以上步骤中重复N次(N = MaxTenuringThreshold(年龄阀值设定,默认15))依然存活的对象,就会被移动到老年代。
从上面的步骤可以发现,两个幸存者空间,必须有一个是保持空的
1.引用计数法
根据对象的引用数量,如果为0则回收
2.可达性分析算法
通过GC ROOT 进行可达性分析,不可达回收
引入:哪些可以作为GC ROOT对象
1.7 GC算法
- 标记清除算法:标记-清除算法采用从根集合进行扫描,对所有需要回收对象进行标记,标记完成后进行统一回收。标记-清除算法不需要进行对象的移动,由于标记-清除算法直接回收不存活的对象,并没有对还存活的对象进行整理,因此会导致内存碎片。
- 标记复制算法:复制算法将内存划分为两个区间,使用此算法时,所有动态分配的对象都只能分配在其中一个区间(活动区间),而另外一个区间(空间区间)则是空闲的。复制算法采用从根集合扫描,将存活的对象复制到空闲区间,当扫描完毕活动区间后,会的将活动区间一次性全部回收。此时原本的空闲区间变成了活动区间。下次GC时候又会重复刚才的操作,以此循环。复制算法在存活对象比较少的时候,极为高效,但是带来的成本是牺牲一半的内存空间用于进行对象的移动。所以复制算法的使用场景,必须是对象的存活率非常低才行,而且最重要的是,我们需要克服50%内存的浪费。
- 标记整理(压缩)算法:标记-整理算法采用 标记-清除 算法一样的方式进行对象的标记、清除,但在回收不存活的对象占用的空间后,会将所有存活的对象往左端空闲空间移动,并更新对应的指针。标记-整理 算法是在标记-清除 算法之上,又进行了对象的移动排序整理,因此成本更高,但却解决了内存碎片的问题。JVM为了优化内存的回收,使用了分代回收的方式,对于新生代内存的回收(Minor GC)主要采用复制算法。而对于老年代的回收(Major GC),大多采用标记-整理算法。https://zhuanlan.zhihu.com/p/25539690
- 分代算法:分代算法的核心思想是同时发挥”标记整理算法”和”复制算法”的优点, 让他们分别去处理自己最适合处理的场景:
- 分代算法为每个可回收的堆内存对象记录年龄(每个对象在被创建时初始年龄为0, 之后每经历一次GC, 如果未被回收掉就把它的年龄加1).
- 对于年龄小于某个固定值(JAVA中默认是15岁, 不是现实中成年人的18岁哈)的对象被认为是属于年轻代(Young). 对于年轻代内的对象使用复制算法进行内存回收, 这里有个假设是年轻代的对象一般非常不稳定, 每次GC都能回收掉其中的决大部分, 根据经验这个假设在现实生活中基本是成立的.
- 对于年龄高过这个固定值的对象被认为是属于老年代(Old). 对于老年代的对象使用标记整理算法, 这里也有个假设是老年代的对象一般比较稳定, 内存空间紧张, 这个假设也基本是成立的.分代算法为年轻代和老年代分别配置了独立的内存区域, 当年轻代内存空间满时就触发年轻代GC(也叫Minor GC), 当老年代内存空间满时就触发老年代GC(也叫FullGC). 正常情况下, 应该是每次年轻代GC发生后, 会有部分对象进入老年代, 年轻代GC发生若干次后, 老年代空间被占满了, 开始进行老年代GC.https://zhuanlan.zhihu.com/p/84942585
1.8 GC的回收器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,基于并发“标记清理”实现,在标记清理过程中不会导致用户线程无法定位引用对象。仅作用于老年代收集。它的步骤如下:
- 初始标记(CMS initial mark):独占CPU,stop-the-world, 仅标记GCroots能直接关联的对象,速度比较快;
- 并发标记(CMS concurrent mark):可以和用户线程并发执行,通过GCRoots Tracing 标记所有可达对象;
- 重新标记(CMS remark):独占CPU,stop-the-world, 对并发标记阶段用户线程运行产生的垃圾对象进行标记修正,以及更新逃逸对象;
- 并发清理(CMS concurrent sweep):可以和用户线程并发执行,清理在重复标记中被标记为可回收的对象。
优缺点
CMS的优点:
- 支持并发收集.
低停顿,因为CMS可以控制将耗时的两个stop-the-world操作保持与用户线程恰当的时机并发执行,并且能保证在短时间执行完成,这样就达到了近似并发的目的.
CMS的缺点:
CMS收集器对CPU资源非常敏感,在并发阶段虽然不会导致用户线程停顿,但是会因为占用了一部分CPU资源,如果在CPU资源不足的情况下应用会有明显的卡顿。
- 无法处理浮动垃圾:在执行‘并发清理’步骤时,用户线程也会同时产生一部分可回收对象,但是这部分可回收对象只能在下次执行清理是才会被回收。如果在清理过程中预留给用户线程的内存不足就会出现‘Concurrent Mode Failure’,一旦出现此错误时便会切换到SerialOld收集方式。
- CMS清理后会产生大量的内存碎片,当有不足以提供整块连续的空间给新对象/晋升为老年代对象时又会触发FullGC。且在1.9后将其废除。
使用场景
它关注的是垃圾回收最短的停顿时间(低停顿),在老年代并不频繁GC的场景下,是比较适用的。G1收集器
G1收集器的内存结构完全区别去CMS,弱化了CMS原有的分代模型(分代可以是不连续的空间),将堆内存划分成一个个Region(1MB~32MB, 默认2048个分区),这么做的目的是在进行收集时不必在全堆范围内进行。它主要特点在于达到可控的停顿时间,用户可以指定收集操作在多长时间内完成,即G1提供了接近实时的收集特性。它的步骤如下:
- 初始标记(Initial Marking):标记一下GC Roots能直接关联到的对象,伴随着一次普通的Young GC发生,并修改NTAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可用的Region中创建新对象,此阶段是stop-the-world操作。
- 根区间扫描,标记所有幸存者区间的对象引用,扫描 Survivor到老年代的引用,该阶段必须在下一次Young GC 发生前结束。
- 并发标记(Concurrent Marking):是从GC Roots开始堆中对象进行可达性分析,找出存活的对象,这阶段耗时较长,但可与用户程序并发执行,该阶段可以被Young GC中断。
- 最终标记(Final Marking):是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,此阶段是stop-the-world操作,使用snapshot-at-the-beginning (SATB) 算法。
- 筛选回收(Live Data Counting and Evacuation):首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划,回收没有存活对象的Region并加入可用Region队列。这个阶段也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅提高收集效率。
G1的特点
- 并行与并发:G1充分发挥多核性能,使用多CPU来缩短Stop-The-world的时间,
- 分代收集:G1能够自己管理不同分代内已创建对象和新对象的收集。
- 空间整合:G1从整体上来看是基于‘标记-整理’算法实现,从局部(相关的两块Region)上来看是基于‘复制’算法实现,这两种算法都不会产生内存空间碎片。
可预测的停顿:它可以自定义停顿时间模型,可以指定一段时间内消耗在垃圾回收商的时间不大于预期设定值。
使用场景
G1 GC切分堆内存为多个区间(Region),从而避免很多GC操作在整个Java堆或者整个年轻代进行。G1 GC只关注你有没有存货对象,都会被回收并放入可用的Region队列。G1 GC是基于Region的GC,适用于大内存机器。即使内存很大,Region扫描,性能还是很高的。
Remembered Set
1.9 GC在堆中的工作机制
新生代:标记-复制算法(幸存者区2个)
老年代:标记-清除算法+标记-整理算法(压缩)1.10 JVM调优&GC调优
二、语法&OOP
2.1 数据类型
基本类型:八种,栈内存存储的是值
概念
byte8位、有符号的以二进制补码表示的整数
- min : -128(-2^7)
- max: 127(2^7-1)
- default: 0
- 对应包装类:Byte
short
- 16位、有符号的以二进制补码表示的整数
- min : -32768(-2^15)
- max: 32767(2^15 - 1)
- default: 0
- 对应包装类:Short
int
- 32位、有符号的以二进制补码表示的整数
- min : -2,147,483,648(-2^31)
- max: 2,147,483,647(2^31 - 1)
- default: 0
- 对应包装类:Integer
long
- 64位、有符号的以二进制补码表示的整数
- min : -9,223,372,036,854,775,808(-2^63)
- max: 9,223,372,036,854,775,807(2^63 -1)
- default: 0
- 对应的包装类:Long
float
- 单精度、32位、符合IEEE 754标准的浮点数
- float 在储存大型浮点数组的时候可节省内存空间
- 浮点数不能用来表示精确的值,如货币
- default: 0.0f
- 对应的包装类:Float
double
- 双精度、64位、符合IEEE 754标准的浮点数
- 浮点数的默认类型为double类型
- double类型同样不能表示精确的值,如货币
- default: 0.0d
- 对应的包装类:Double
char
- char类型是一个单一的 16 位 Unicode 字符
- 最小值是 \u0000(即为0)
- 最大值是 \uffff(即为65,535)
- char 数据类型可以储存任何字符
- 对应的包装类:Character
**boolean
- boolean数据类型表示一位的信息
- 只有两个取值:true 和 false
- 这种类型只作为一种标志来记录 true/false 情况
- 对应的包装类:Boolean
引用类型:栈内存存储的是引用地址
小心:
1、基本类型的转换,表示的数据范围
2、byte、short、char 参与运算会变为int类型
2.2 运算符
赋值:= += -=
比较:> <
算术:+ - ++ —
位运算符:^ | & << >>>
三目:X?Y:Z
逻辑:|| &&
字符连接运算符:+
……
引入:
1.变量:先声明,再使用
2.表达式:结果类型
3.进制转换:二进制和十进制
2.3 分支(条件)
程序的结构:
1.顺序结构:从上往下
2.分支结构:有选择的执行
3.循环结构:重复执行
分支结构:1.if 2.switch
if(布尔类型表达式){
}else if(布尔类型表达式){
}else{
}
switch(变量){
case 值:{}break;
……
default:{}break;
}
2.4 循环
2.5 OOP的特征
封装:类的创建(属性、方法)、属性私有
继承:实现传递,父类中非私有的,被继承。唯一,传递性
多态:同一个东西,具备多种形态。编译时多态:重载,运行时多态:重写、造型
抽象:定义
目的:消除重复代码
1、封装性:在面向对象技术的相关原理以及程序语言中,封装的最基本单位是对象,而使得软件结构的相关部件的实现“高内聚、低耦合”的“最佳状态”便是面向对象技术的封装性所需要实现的最基本的目标。
2、继承性:继承性是面向对象技术中的另外一个重要特点,其主要指的是两种或者两种以上的类之间的联系与区别。继承是后者延续前者的某些方面的特点,而在面向对象技术则是指一个对象针对于另一个对象的某些独有的特点、能力进行复制或者延续。
3、多态性:从宏观的角度来讲,多态性是指在面向对象技术中,当不同的多个对象同时接收到同一个完全相同的消息之后,所表现出来的动作是各不相同的;从微观的角度来讲,多态性是指在一组对象的一个类中,面向对象技术可以使用相同的调用方式来对相同的函数名进行调用。
OOP的主要特点:
1、对象唯一性。每个对象都有自身唯一的标识,通过这种标识,可找到相应的对象。在对象的整个生命期中,它的标识都不改变,不同的对象不能有相同的标识。
2、抽象性。一个类就是这样一种抽象,它反映了与应用有关的重要性质,而忽略其他一些无关内容。任何类的划分都是主观的,但必须与具体的应用有关。
3、多形性。多形性是指相同的操作或函数、过程可作用于多种类型的对象上并获得不同的结果。不同的对象,收到同一消息可以产生不同的结果,这种现象称为多形性。
2.6 抽象类&接口
共同点:不能实例化
不同点:
抽象类:1.继承 2.可以实例方法
接口:1.实现 2.不能实例方法,(1.8之后,可以有默认方法)
面向接口编程
抽象类和接口的区别:
A:成员区别 抽象类: 成员变量:可以变量,也可以常量 构造方法:有 成员方法:可以抽象,也可以非抽象 接口: 成员变量:只可以常量 成员方法:只可以抽象
B:关系区别 类与类 继承,单继承 类与接口 实现,单实现,多实现 接口与接口 继承,单继承,多继承
C:设计理念区别 抽象类 被继承体现的是:”is a”的关系。抽象类中定义的是该继承体系的共性功能。 接口 被实现体现的是:”like a”的关系。接口中定义的是该继承体系的扩展功能。
2.7 this&super
this:当前类对象的引用
1.访问当前类的成员方法
2.访问当前类的成员属性
3.访问当前类的构造方法
4.不能在静态方法中使用
super:父类对象的引用
1.访问父类的成员方法
2.访问父类的成员属性
3.访问父类的构造方法
4.不能在静态方法中使用
2.8 访问修饰符
public:公共的,最广泛
protect:受保护的,继承关系
private:私有的,本类中使用
三个访问修饰符,四种访问权限
重写:方法的访问修饰权限不能比父类更严格
一、private(当前类访问权限)
如果类里的一个成员(包括成员变量、方法和构造器等)使用private访问控制符来修饰,则这个成员只能在「当前类的内部」被访问。很显然,个访问控制符用于修饰成员变量最合适,使用它来修饰成员变量就可以把成员变量隐藏在该类的内部。
这里尤其要提一下的是,在子类中我们不能通过第二种方式直接访问父类的private修饰成员变量或者方法,这也就是私有成员不能被继承的由来。
本类中:直接通过成员变量名访问
子类中:不能直接通过两种方式中的任意一种访问
不同包的类中:不能直接通过两种方式中的任意一种访问
二、default(包访问权限)
如果类里的一个成员(包括成员变量、方法和构造器等)或者一个外部类不使用任何访控制符修饰,就称它是包访问权限的。
default 访问控制的成员或外部类可以被相同包下的其他类访问。
本类中:直接通过成员变量名访问
同包的子类中:直接通过成员变量名访问
同包的其他类:可以通过第二种方式访问
不同包的类(包括子类)中:不能直接通过两种方式中的任意一种访问
三、protected(子类访问权限)
如果一个成员(包括成员变量、方法和构造器等)使用protected访问控制符修饰,那么这个成员既可以被同一个包中的其他类访问,也可以被不同包中的子类访问。
在通常情况下,如果使用protected来修饰一个方法,通常是希望其子类来重写这个方法。
本类中:直接通过成员变量名访问
同包的子类中:直接通过成员变量名访问
同包的其他类:可以通过第二种方式访问
不同包的子类:直接通过成员变量名访问
不同包的类中:不能直接通过两种方式中的任意一种访问
四、public(公共访问权限)
这是一个最宽松的访问控制级别,如果一个成员(包括成员变量、方法和构造器等)或者一个外部类使用public访问控制符修饰,那么这个成员或外部类就可以被所有类访问,不管访问类和被访问类是否处于同一个包中,是否具有父子继承关系。
2.9 Object
所有类的根类,方法
概述:
1. Object类是所有其他类的父类
2. Object类只有一个构造方法,这也是为什么所有子类在调用构造方法时都会默认先调用父类的无参构造方法
3. Object类没有成员变量
方法:
1. public int hashCode()
2. public final Class getClass()
3. public String toString()
4. public boolean equals(Object obj)
5. protected void finalize()
6. protected Object clone()
具体方法:
- public int hashCode():
返回此对象的哈希码值(散列码),支持此方法是为了提高哈希表(例如 java.util.Hashtable 提供的哈希表)的性能。
hashCode 的常规协定是:
1. 一致性:在 Java 应用程序执行期间,在对同一对象多次调用 hashCode 方法时,必须一致地返回相同的整数,前提是将对象进行 equals 比较时所用的信息没有被修改。从某一应用程序的一次执行到同一应用程序的另一次执行,该整数无需保持一致。
2. 如果根据 equals(Object) 方法,两个对象是相等的,那么对这两个对象中的每个对象调用 hashCode 方法都必须生成相同的整数结果。 如果重写了equals()方法,一定也要重写hashCode()方法
3. 如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么对这两个对象中的任一对象上调用 hashCode 方法不要求一定生成不同的整数结果。但是,程序员应该意识到,为不相等的对象生成不同整数结果可以提高哈希表的性能。
重写:
int result = c;
//根据每一个关键域的hashcode去生成
31 i == ( i << 5 ) - i ;
result = 31 field.hashCode + result ;
…
return result;
实际上,由 Object 类定义的 hashCode 方法确实会针对不同的对象返回不同的整数。(这一般是通过将该对象的内部地址转换成一个整数来实现的,但是 JavaTM 编程语言不需要这种实现技巧。)
- public final Class getClass()
返回此 Object 的运行时类。
Class:类类型,用来描述该类型的类
String getName():返回该类的全限定名
注意事项:
a) 返回的是运行时类
b) 用final修饰,所有对象该方法的行为一致
返回的 Class 对象是由所表示类的 static synchronized 方法锁定的对象。实际结果类型是 Class<? extends |X|>,其中 |X| 表示清除表达式中的静态类型,该表达式调用 getClass。
- public String toString()
返回该对象的字符串表示。通常,toString 方法会返回一个“以文本方式表示”此对象的字符串。结果应是一个简明但易于读懂的信息表达式。建议所有子类都重写此方法。
Object中toString的默认实现是返回一个字符串,该字符串由类名(对象是该类的一个实例)、at 标记符“@”和此对象哈希码的无符号十六进制表示组成。
getClass().getName() + “@” + Integer.toHexString(hashCode())
默认实现不能很好的体现对象,所以推荐子类都重写toString()
重写方式:
1. 根据关键域去重写
2. 快捷键生成
- public boolean equals(Object obj)
指示其他某个对象是否与此对象“相等”。
equals 方法在非空对象引用上实现相等关系:
默认实现:
return this == obj ;
针对不同的类:
实体类:不同对象代表不同实体,采用默认实现即可
值类:关键域相等,就认为两个对象相等,需要重写equals方法
1. 自反性:对于任何非空引用值 x,x.equals(x) 都应返回 true。
2. 对称性:对于任何非空引用值 x 和 y,当且仅当 y.equals(x) 返回 true 时,x.equals(y) 才应返回 true。
3. 传递性:对于任何非空引用值 x、y 和 z,如果 x.equals(y) 返回 true,并且 y.equals(z) 返回 true,那么 x.equals(z) 应返回 true。
4. 一致性:对于任何非空引用值 x 和 y,多次调用 x.equals(y) 始终返回 true 或始终返回 false,前提是对象上 equals 比较中所用的信息没有被修改。
5. 非空性:对于任何非空引用值 x,x.equals(null) 都应返回 false。
(Java语法没有强制要求严格遵循这些原则,但是违反可能会对程序造成灾难性的后果)
重写:
a) 子类没有新的要比较的属性,就用instanceof进行判断
Demo:
public boolean equals(Object obj) {
if(obj instanceof Demo) {
Demo demo = (Demo) obj ;
//用关键属性进行比较
}
return false;
}
里氏替换原则
b) 子类有新的要比较的属性,就用getClass()方法进行判断
Demo:
public boolean equals(Object obj) {
if(obj == null || obj.getClass() != getClass() {
return false ;
}
Demo demo = (Demo) obj;
//用关键属性进行比较
}
没有遵循里氏替换原则
c) 快捷键生成
“==“ 和 equals 的区别
==:
a) 如果比较的是基本数据类型,判断他们的值是否相等
b) 如果比较的是引用数据类型,判断他们是否是同一个对象
equals:
a) 不能比较基本数据类型
b) 比较引用数据类型,如果没有重写Object的equals(),默认判断是否是同一个对象
c) 如果重写了,一般是根据对象的值进行判断
Object 类的 equals 方法实现对象上差别可能性最大的相等关系;即,对于任何非空引用值 x 和 y,当且仅当 x 和 y 引用同一个对象时,此方法才返回 true(x == y 具有值 true)。
注意:当此方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。
- protected void finalize()
垃圾回收器回收该对象之前,会调用该方法
作用:可以释放系统资源
注意事项:
a) 如果直接调用,相当于普通方法的调用,并不会回收该对象
b) 释放系统资源最好不要放在该方法里面,推荐使用try…catch…finally
当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。
子类重写 finalize 方法,以配置系统资源或执行其他清除。
finalize 的常规协定是:当 JavaTM 虚拟机已确定尚未终止的任何线程无法再通过任何方法访问此对象时,将调用此方法,除非由于准备终止的其他某个对象或类的终结操作执行了某个操作。finalize 方法可以采取任何操作,其中包括再次使此对象对其他线程可用;不过,finalize 的主要目的是在不可撤消地丢弃对象之前执行清除操作。例如,表示输入/输出连接的对象的 finalize 方法可执行显式 I/O 事务,以便在永久丢弃对象之前中断连接。
Object 类的 finalize 方法执行非特殊性操作;它仅执行一些常规返回。Object 的子类可以重写此定义。
Java 编程语言不保证哪个线程将调用某个给定对象的 finalize 方法。但可以保证在调用 finalize 时,调用 finalize 的线程将不会持有任何用户可见的同步锁定。如果 finalize 方法抛出未捕获的异常,那么该异常将被忽略,并且该对象的终结操作将终止。
在启用某个对象的 finalize 方法后,将不会执行进一步操作,直到 Java 虚拟机再次确定尚未终止的任何线程无法再通过任何方法访问此对象,其中包括由准备终止的其他对象或类执行的可能操作,在执行该操作时,对象可能被丢弃。
对于任何给定对象,Java 虚拟机最多只调用一次 finalize 方法。
finalize 方法抛出的任何异常都会导致此对象的终结操作停止,但可以通过其他方法忽略它
- protected Object clone()
创建并返回此对象的一个副本。“副本”的准确含义可能依赖于对象的类。
默认:浅拷贝
如何实现深拷贝:
a) 实现Cloneable接口
b) 调用super.clone(),完成基本数据类型的拷贝
c) 对所有的引用数据类型完成深拷贝(下一级也应该实现深拷贝)
这样做的目的是,对于任何对象 x,表达式:
x.clone() != x为 true,表达式:
x.clone().getClass() == x.getClass()也为 true,但这些并非必须要满足的要求。一般情况下:
x.clone().equals(x)为 true,但这并非必须要满足的要求。
按照惯例,返回的对象应该通过调用 super.clone 获得。如果一个类及其所有的超类(Object 除外)都遵守此约定,则 x.clone().getClass() == x.getClass()。
按照惯例,此方法返回的对象应该独立于该对象(正被复制的对象)。要获得此独立性,在 super.clone 返回对象之前,有必要对该对象的一个或多个字段进行修改。这通常意味着要复制包含正在被复制对象的内部“深层结构”的所有可变对象,并使用对副本的引用替换对这些对象的引用。如果一个类只包含基本字段或对不变对象的引用,那么通常不需要修改 super.clone 返回的对象中的字段。
Object 类的 clone 方法执行特定的复制操作。首先,如果此对象的类不能实现接口 Cloneable,则会抛出 CloneNotSupportedException。注意,所有的数组都被视为实现接口 Cloneable。否则,此方法会创建此对象的类的一个新实例,并像通过分配那样,严格使用此对象相应字段的内容初始化该对象的所有字段;这些字段的内容没有被自我复制。所以,此方法执行的是该对象的“浅表复制”,而不“深层复制”操作。
Object 类本身不实现接口 Cloneable,所以在类为 Object 的对象上调用 clone 方法将会导致在运行时抛出异常。
2.10 Java中4种引用
一、引用的历史
在Java中,我们的垃圾回收机制回收垃圾对象的时候就会依据对象的引用。比如说通过不同的垃圾回收算法,这里有两种:引用计数法和可达性分析法
1、引用计数法:为每个对象添加一个引用计数器,每当有一个引用指向它时,计数器就加1,当引用失效时,计数器就减1,当计数器为0时,则认为该对象可以被回收。
2、可达性分析算法:从一个被称为 GC Roots 的对象开始向下搜索,如果一个对象到GC Roots没有任何引用链相连时,则说明此对象不可用。
JDK.1.2 之后
1、强引用
如果一个对象具有强引用,它就不会被垃圾回收器回收。即使当前内存空间不足,JVM也不会回收它,而是抛出 OutOfMemoryError 错误,使程序异常终止。比如String str = “hello”这时候str就是一个强引用。当然我们也可以使用str=null取消一个强引用。
2、软引用:SoftReference
如果一个对象具有软引用,它就不会被垃圾回收器回收。只有在内存空间不足时,软引用才会被垃圾回收器回收。这种引用常常被用来实现缓存技术。因为缓存区里面的东西,之后在内存不足的时候才会被清空。
当内存足够大时可以把数组存入软引用,取数据时就可从内存里取数据,提高运行效率
软引用在实际中有重要的应用,例如浏览器的后退按钮,这个后退时显示的网页内容可以重新进行请求或者从缓存中取出:
(1)如果一个网页在浏览结束时就进行内容的回收,则按后退查看前面浏览过的页面时,需要重新构建
(2)如果将浏览过的网页存储到内存中会造成内存的大量浪费,甚至会造成内存溢出这时候就可以使用软引用
3、弱引用:WeakReference
如果一个对象具有弱引用,在垃圾回收时候,一旦发现弱引用对象,无论当前内存空间是否充足,都会将弱引用回收。不过由于垃圾回收器是一个优先级较低的线程,所以并不一定能迅速发现弱引用对象。所以被软引用关联的对象只有在内存不足时才会被回收,而被弱引用关联的对象在JVM进行垃圾回收时总会被回收。
应用场景:如果一个对象是偶尔的使用,并且希望在使用时随时就能获取到,但又不想影响此对象的垃圾收集,那么应该用 Weak Reference 来记住此对象。或者想引用一个对象,但是这个对象有自己的生命周期,你不想介入这个对象的生命周期,这时候就应该用弱引用,这个引用不会在对象的垃圾回收判断中产生任何附加的影响。
4、虚引用:监听GC
如果一个对象具有弱引用,就相当于没有引用,在任何时候都有可能被回收。虚引用是使用PhantomReference创建的引用,虚引用也称为幽灵引用或者幻影引用,是所有引用类型中最弱的一个。一个对象是否有虚引用的存在,完全不会对其生命周期构成影响,也无法通过虚引用获得一个对象实例。
使用虚引用的目的就是为了得知对象被GC的时机,所以可以利用虚引用来进行销毁前的一些操作,比如说资源释放等。这个虚引用对于对象而言完全是无感知的,有没有完全一样,但是对于虚引用的使用者而言,就像是待观察的对象的把脉线,可以通过它来观察对象是否已经被回收,从而进行相应的处理。
三、数组&集合
3.1 数组
实例化:数据类型[] 变量名
下标
多维数组(二维、三维、四维)
我们先来说说数组结构,什么是数组?数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
- 线性表数据结构:就是数据排列像一条线一样的结构,只有前后的方向,
- 连续的内存空间:就是存储数据在内存中的地址是连续的,例如存储一个长度为3的整数int[3]数组,int类型数据在内存中占4个字节,所以数组的起止地址为1000~1003,1004~1007,1008~1010是连续的。
数组优点:
- 随机访问,通过索引访问数组数据,由于是连续的内存空间,所以支持随机访问,通过下标随机访问的时间复杂度是O(1)。
- 查找快,可以通过数组的所以快速定位到要查找的数据
- 支持动态扩容,当我们开始预定义数组的长度是10,当数组存储了10个数据后,我们继续添加第11个数据的时候,我们就需要重新分配一块更大的空间,将原来的数据复制过去,然后再将新的数据插入
数组缺点:
- 插入、删除数据慢,因为数组连续的内存空间,所以在插入一个数据的时候会使插入位置后面的每个数据都向后位移一个位置,所以比较低效,删除同理,会使删除位置之后的每个数据向前位移一个。
- 操作不当会引起数组的访问越界问题,比如我定义的数组长度是10,索引长度从0~9,但是当我访问位置10的时候,超过数组长度,所以会发生越界问题
- 查询某个元素是否存在时需要遍历整个数组,耗费 O(n) 的时间。
-
链表
相比数组,链表是有一系列不必在内存中连续的结构组成,是一种稍微复杂一点的数据结构。但是他和数组都是面试中经常出现的,先来说说什么是链表?与数组相比,数组需要一块连续的内存空间来存储,假如申请100MB大小的数组,但是连续内存空间不够,就无法创建数组,但是链表并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以如果我们申请 100MB内存空间如果不是连续的内存空间,就是可以的。
所以链表是通过指针将一组零散的内存块串联在一起的一种数据结构,链表又分为:单链表、双向链表和循环链表。
单链表优点: 插入和删除快,和数组相比,链表的插入和删除不需要其他的节点的位移,我们只需要修改节点之间的next指针指向,就可以完成插入和删除,时间复杂度已经是 O(1)
- 链表能灵活地分配内存空间。
单链表缺点:
- 查询相比数组低效,因为链表的内存地址不是连续的,所以不能像数组一样通过索引随机访问,所以链表在查找某个节点时候只能通过从头遍历链表节点来查找。
- 查询第 n 个元素需要 O(n) 时间
双向链表结构:
与单点链表相比,双向链表增加了一个指向前面节点的pre指针,同事需要额外的一个空间来存储前驱结点的地址。所以,如果存储同样多的数据,双向链表要比单链表占用更多的内存空间,:双向链表优点:
- 支持双向遍历,双向链表增加了操作的灵活性
循环链表结构:
单链表的循环链表结构就是在单链表的基础上将尾节点的next指针指向头节点
单链表和双向链表的对比:
- 查询对比:查询某个元素的时间复杂度都是O(n),都需要从头或者从尾开始遍历链表。
- 删除某个元素的时候,单链表第一次查询找到该元素,但是他不能控制前一个节点的next的指向,例如删除q节点,为了找到前驱结点,我们还是要从头结点开始遍历链表,直到 p->next=q,然后通过修改p节点的next指针指向被删除节点q的next指针指向的节点。然而双向链表中的结点已经保存了前驱结点的指针,不需要像单链表那样遍历,单链表删除操作需要 O(n) 的时间复杂度,而双向链表只需要在 O(1) 的时间复杂度内就可以搞定,插入操作同理,单链表时间复杂度是O(n),双链表是O(1)。
如果都是有序的链表查找,就查找速率而言,双向链表也比但链表要高,因为双向链表可以记录上次的查询值,通过对比值的大小,通过前驱指针和后驱指针双向遍历,但是单链表只能从头遍历。
3.2 查找算法(手写)
顺序查找 O(n)
从下标0开始,逐个比较
``` public class ShunXuChaZhao { public static void main(String[] args) {int arr[] = { 1, 9, 11, -1, 34, 89 };int test = test(arr, 11);if (test == -1) {System.out.println("没有找到该数");} else {System.out.println("当前数组下标为:" + test);}
} public static int test(int[] arrs, int a) {
//线性查找for (int i = 0; i < arrs.length; i++) {if (arrs[i] == a) {return i;}}return -1;
}
}
<a name="YxtYQ"></a>### 二分查找(折半查找)O(log n)对有序数组,每次比较中间的值,不断的缩小范围
- 二分法查找代码的实现
注意:使用二分查找的前提是 该数组是有序的. */ public class ErFenChaZhao { public static void main(String[] args) {
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 , 11, 12, 13,14,15,16,17,17,17,17,17,17,18,19,20 };List<Integer> test = test(arr, 0, arr.length - 1, 21);System.out.println(test);
}
/**
- @param arrs 数组
- @param left 左边的索引
- @param right 右边的索引
- @param value 要寻找的值
@return */ public static List
test(int[] arrs, int left, int right, int value) { if (right < left) { return new ArrayList<Integer>();
} int mid = (left + right)/2; int midValue = arrs[mid]; //向右递归 if (value > midValue) {
return test(arrs, mid +1, right, value);
} else if (value < midValue) {
//向左递归return test(arrs, left, mid -1, value);
} else {
ArrayList<Integer> integers = new ArrayList<>();//向mid 索引值的左边扫描,将所有满足的元素的下标,加入到集合ArrayListint temp = mid - 1;while(true) {if (temp < 0 || arrs[temp] != value) {break;}//否则,就temp 放入到 resIndexlistintegers.add(temp);//temp左移temp -= 1;}integers.add(mid);//向mid 索引值的右边扫描,将所有满足的元素的下标,加入到集合ArrayListtemp = mid + 1;while(true) {if (temp > arrs.length - 1 || arrs[temp] != value) {break;}//否则,就temp 放入到 resIndexlistintegers.add(temp);//temp右移temp += 1;}return integers;
} } }
<a name="KxHjM"></a>## 3.3 排序算法(手写)- **比较类排序**:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。- **非比较类排序**:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。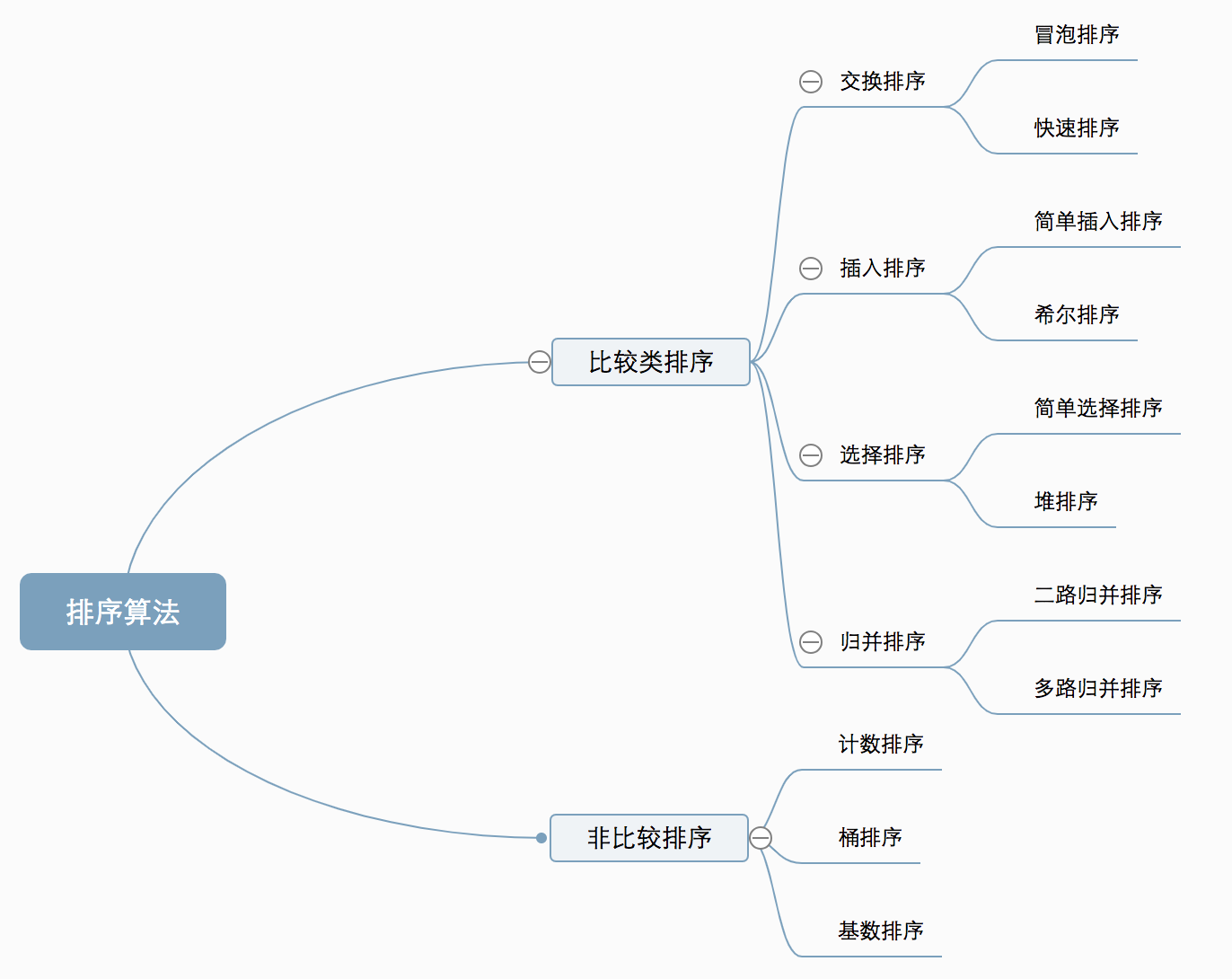<a name="P7iB7"></a>#### 0.2 算法复杂度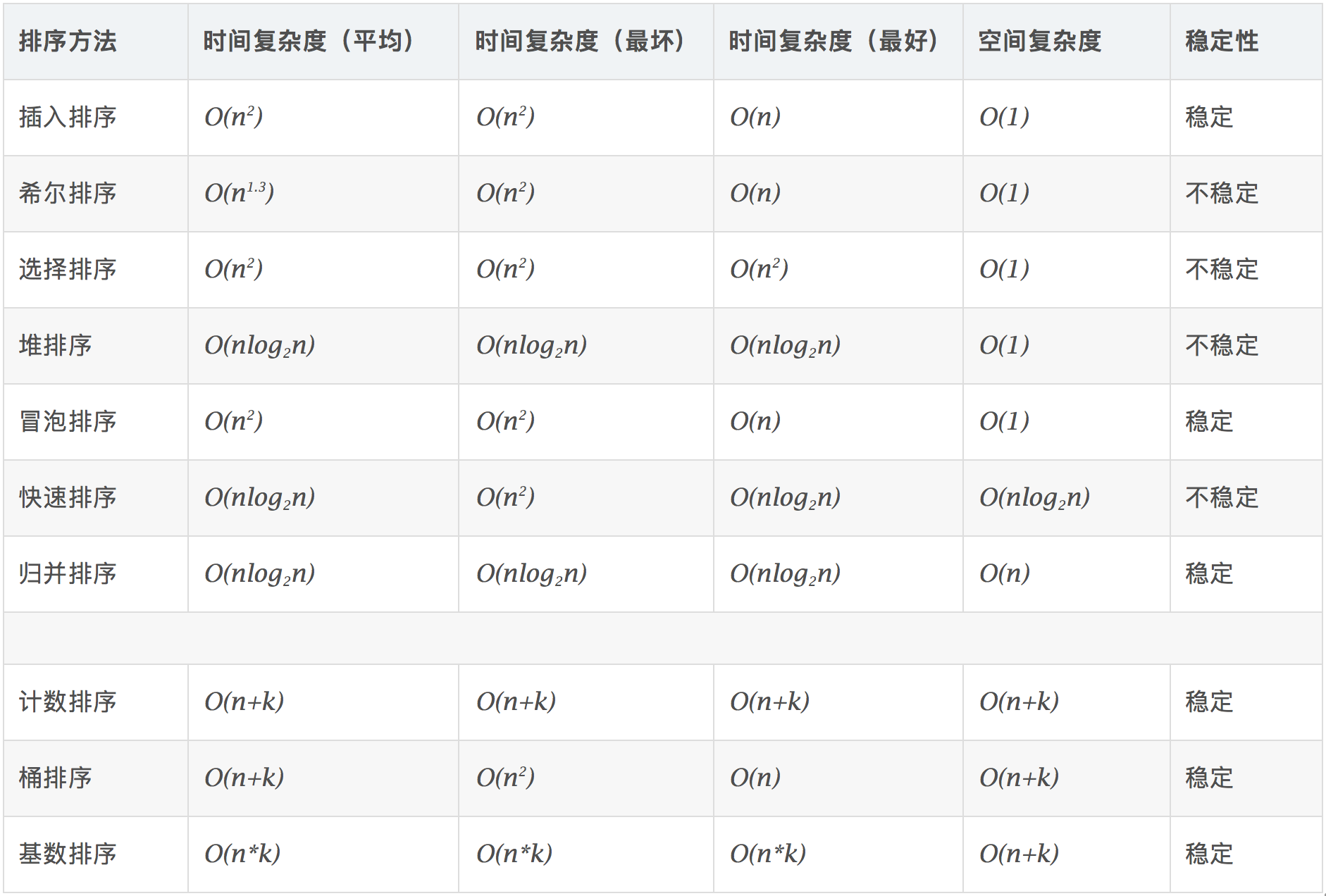<br />**0.3 相关概念**- **稳定**:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。- **不稳定**:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。- **时间复杂度**:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。- **空间复杂度:**是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。<a name="h72bt"></a>### 1、冒泡排序(Bubble Sort)冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。<a name="Kvz8r"></a>#### 1.1 算法描述- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;- 针对所有的元素重复以上的步骤,除了最后一个;- 重复步骤1~3,直到排序完成。**1.2 动图演示**<br /><a name="W3ceV"></a>#### 1.3 代码实现| function bubbleSort(arr) {<br /> var len = arr.length;<br /> for (var i = 0; i < len - 1; i++) {<br /> for (var j = 0; j < len - 1 - i; j++) {<br /> if (arr[j] > arr[j+1]) { // 相邻元素两两对比<br /> var temp = arr[j+1]; // 元素交换<br /> arr[j+1] = arr[j];<br /> arr[j] = temp;<br /> }<br /> }<br /> }<br /> return arr;<br />} || --- |<a name="zqpB2"></a>### 2、选择排序(Selection Sort)选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。<a name="f0yXo"></a>#### 2.1 算法描述n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。具体算法描述如下:- 初始状态:无序区为R[1..n],有序区为空;- 第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1..i-1]和R(i..n)。该趟排序从当前无序区中-选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1..i]和R[i+1..n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区;- n-1趟结束,数组有序化了。<a name="Z9TVa"></a>#### **2.2 动图演示**<a name="vhwXy"></a>#### 2.3 代码实现| function selectionSort(arr) {<br />var len = arr.length;<br /> var minIndex, temp;<br /> for (var i = 0; i < len - 1; i++) {<br /> minIndex = i;<br /> for (var j = i + 1; j < len; j++) {<br /> if (arr[j] < arr[minIndex]) { // 寻找最小的数<br /> minIndex = j; // 将最小数的索引保存<br /> }<br /> }<br /> temp = arr[i];<br /> arr[i] = arr[minIndex];<br /> arr[minIndex] = temp;<br /> }<br /> return arr;<br />} || --- |<a name="FpZnL"></a>#### 2.4 算法分析表现最稳定的排序算法之一,因为无论什么数据进去都是O(n2)的时间复杂度,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。理论上讲,选择排序可能也是平时排序一般人想到的最多的排序方法了吧。<a name="Sr0xm"></a>### 3、插入排序(Insertion Sort)插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。<a name="WCKuQ"></a>#### 3.1 算法描述一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:- 从第一个元素开始,该元素可以认为已经被排序;- 取出下一个元素,在已经排序的元素序列中从后向前扫描;- 如果该元素(已排序)大于新元素,将该元素移到下一位置;- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;- 将新元素插入到该位置后;- 重复步骤2~5。<a name="beGNR"></a>#### 3.2 动图演示<a name="zOiHx"></a>#### 3.2 代码实现| function insertionSort(arr) {<br /> var len = arr.length;<br /> var preIndex, current;<br /> for (var i = 1; i < len; i++) {<br /> preIndex = i - 1;<br /> current = arr[i];<br /> while (preIndex >= 0 && arr[preIndex] > current) {<br /> arr[preIndex + 1] = arr[preIndex];<br /> preIndex--;<br /> }<br /> arr[preIndex + 1] = current;<br /> }<br /> return arr;<br />} || --- |<a name="HDbLH"></a>#### 3.4 算法分析插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。<a name="vEQdE"></a>### 4、希尔排序(Shell Sort)1959年Shell发明,第一个突破O(n2)的排序算法,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫**缩小增量排序**。<a name="oZwMf"></a>#### 4.1 算法描述先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,具体算法描述:- 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;- 按增量序列个数k,对序列进行k 趟排序;- 每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。<a name="y3kB9"></a>#### 4.2 动图演示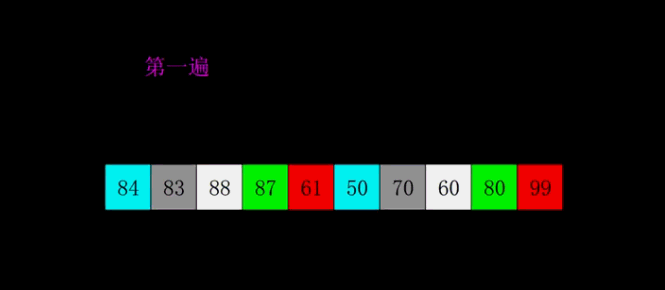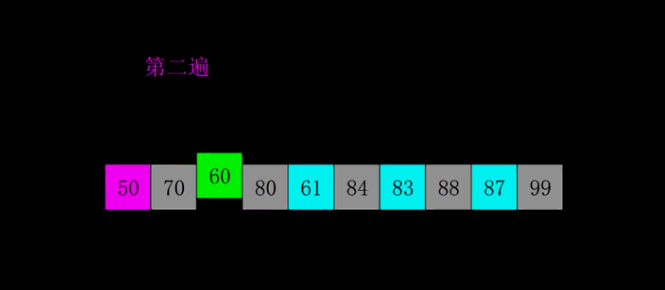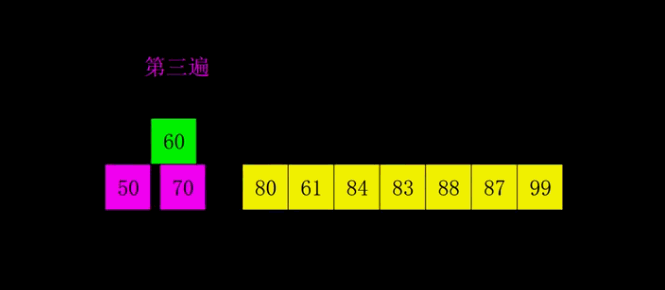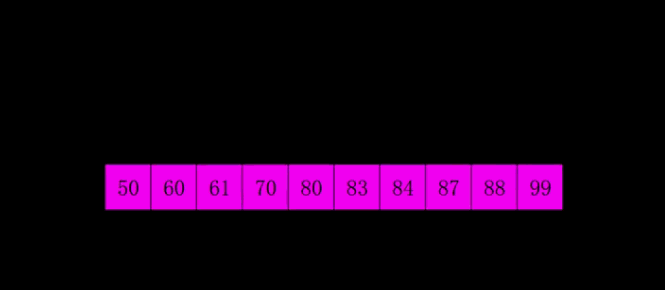<a name="XHPYJ"></a>#### 4.3 代码实现| function shellSort(arr) {<br /> var len = arr.length;<br /> for (var gap = Math.floor(len / 2); gap > 0; gap = Math.floor(gap / 2)) {<br /> // 注意:这里和动图演示的不一样,动图是分组执行,实际操作是多个分组交替执行<br /> for (var i = gap; i < len; i++) {<br /> var j = i;<br /> var current = arr[i];<br /> while (j - gap >= 0 && current < arr[j - gap]) {<br /> arr[j] = arr[j - gap];<br /> j = j - gap;<br /> }<br /> arr[j] = current;<br /> }<br /> }<br /> return arr;<br />} || --- |<a name="BdiIT"></a>#### 4.4 算法分析希尔排序的核心在于间隔序列的设定。既可以提前设定好间隔序列,也可以动态的定义间隔序列。动态定义间隔序列的算法是《算法(第4版)》的合著者Robert Sedgewick提出的。<a name="ro26m"></a>### 5、归并排序(Merge Sort)归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。<a name="joBOW"></a>#### 5.1 算法描述- 把长度为n的输入序列分成两个长度为n/2的子序列;- 对这两个子序列分别采用归并排序;- 将两个排序好的子序列合并成一个最终的排序序列。<a name="lOLkO"></a>#### 5.2 动图演示<a name="Fk129"></a>#### 5.3 代码实现| function mergeSort(arr) {<br /> var len = arr.length;<br /> if (len < 2) {<br /> return arr;<br /> }<br /> var middle = Math.floor(len / 2),<br /> left = arr.slice(0, middle),<br /> right = arr.slice(middle);<br /> return merge(mergeSort(left), mergeSort(right));<br />}<br /> <br />function merge(left, right) {<br /> var result = [];<br /> <br /> while (left.length>0 && right.length>0) {<br /> if (left[0] <= right[0]) {<br /> result.push(left.shift());<br /> } else {<br /> result.push(right.shift());<br /> }<br /> }<br /> <br /> while (left.length)<br /> result.push(left.shift());<br /> <br /> while (right.length)<br /> result.push(right.shift());<br /> <br /> return result;<br />} || --- |<a name="CrpKL"></a>#### 5.4 算法分析归并排序是一种稳定的排序方法。和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(nlogn)的时间复杂度。代价是需要额外的内存空间。<a name="SfdkH"></a>### 6、快速排序(Quick Sort)快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。<a name="V1uj0"></a>#### 6.1 算法描述快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:- 从数列中挑出一个元素,称为 “基准”(pivot);- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。<a name="IdpEU"></a>#### 6.2 动图演示<a name="hWpi4"></a>#### 6.3 代码实现| function quickSort(arr, left, right) {<br /> var len = arr.length,<br /> partitionIndex,<br /> left = typeof left != 'number' ? 0 : left,<br /> right = typeof right != 'number' ? len - 1 : right;<br /> <br /> if (left < right) {<br /> partitionIndex = partition(arr, left, right);<br /> quickSort(arr, left, partitionIndex-1);<br /> quickSort(arr, partitionIndex+1, right);<br /> }<br /> return arr;<br />}<br /> <br />function partition(arr, left ,right) { // 分区操作<br /> var pivot = left, // 设定基准值(pivot)<br /> index = pivot + 1;<br /> for (var i = index; i <= right; i++) {<br /> if (arr[i] < arr[pivot]) {<br /> swap(arr, i, index);<br /> index++;<br /> } <br /> }<br /> swap(arr, pivot, index - 1);<br /> return index-1;<br />}<br /> <br />function swap(arr, i, j) {<br /> var temp = arr[i];<br /> arr[i] = arr[j];<br /> arr[j] = temp;<br />} || --- |<a name="Djkia"></a>### 7、堆排序(Heap Sort)堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。<a name="rhTiy"></a>#### 7.1 算法描述- 将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;- 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];- 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。<a name="R0Ve0"></a>#### 7.2 动图演示<a name="xpz2x"></a>#### 7.3 代码实现| var len; // 因为声明的多个函数都需要数据长度,所以把len设置成为全局变量<br />function buildMaxHeap(arr) { // 建立大顶堆<br /> len = arr.length;<br /> for (var i = Math.floor(len/2); i >= 0; i--) {<br /> heapify(arr, i);<br /> }<br />}<br /> <br />function heapify(arr, i) { // 堆调整<br /> var left = 2 * i + 1,<br /> right = 2 * i + 2,<br /> largest = i;<br /> <br /> if (left < len && arr[left] > arr[largest]) {<br /> largest = left;<br /> }<br /> <br /> if (right < len && arr[right] > arr[largest]) {<br /> largest = right;<br /> }<br /> <br /> if (largest != i) {<br /> swap(arr, i, largest);<br /> heapify(arr, largest);<br /> }<br />}<br /> <br />function swap(arr, i, j) {<br /> var temp = arr[i];<br /> arr[i] = arr[j];<br /> arr[j] = temp;<br />}<br /> <br />function heapSort(arr) {<br /> buildMaxHeap(arr);<br /> <br /> for (var i = arr.length - 1; i > 0; i--) {<br /> swap(arr, 0, i);<br /> len--;<br /> heapify(arr, 0);<br /> }<br /> return arr;<br />} || --- |<a name="XeNhO"></a>### 8、计数排序(Counting Sort)计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。<a name="CLHfA"></a>#### 8.1 算法描述- 找出待排序的数组中最大和最小的元素;- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项;- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。<a name="ZPEep"></a>#### 8.2 动图演示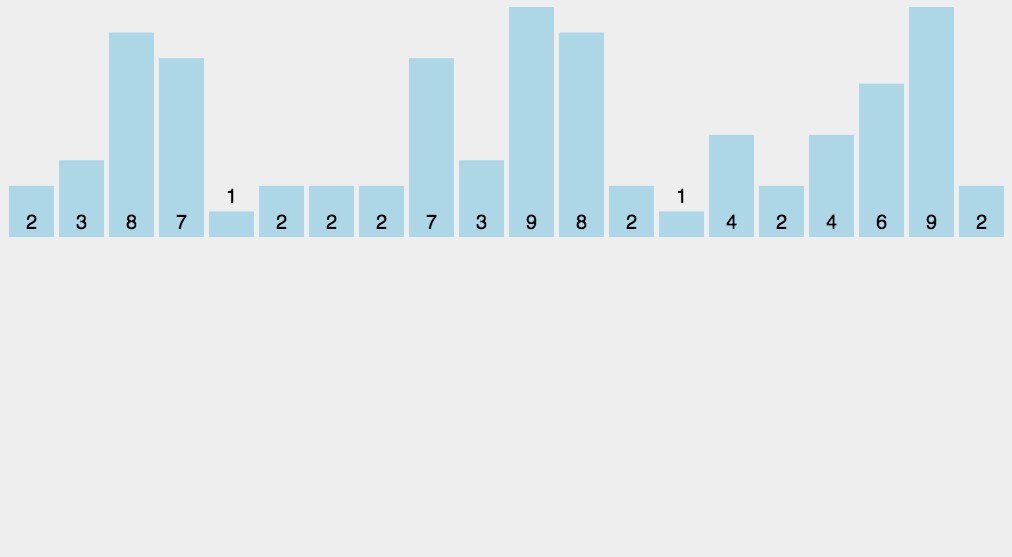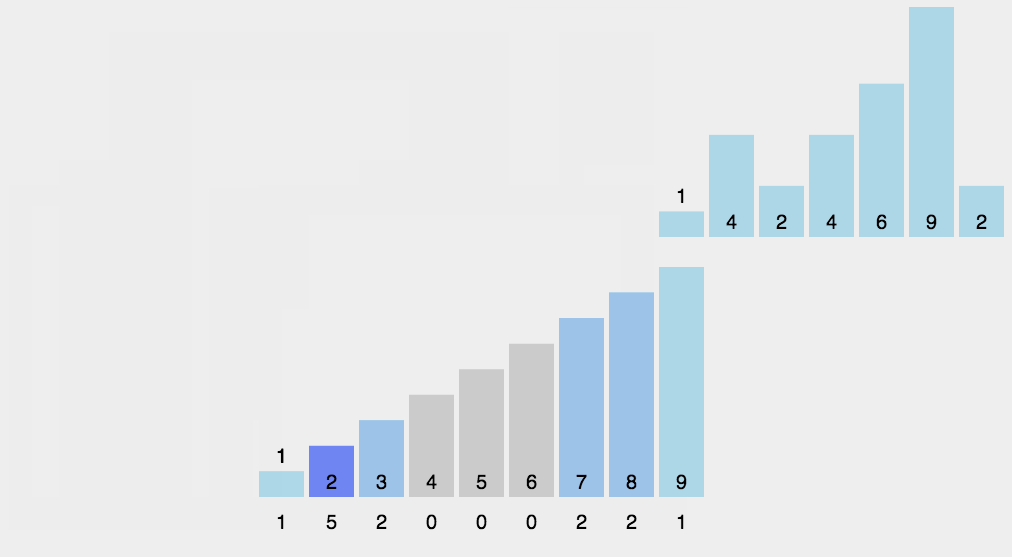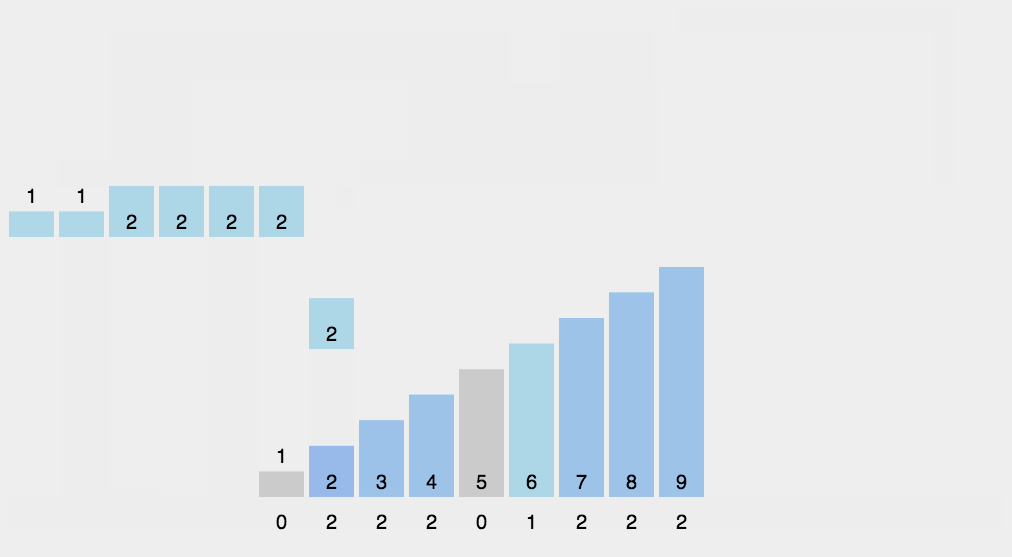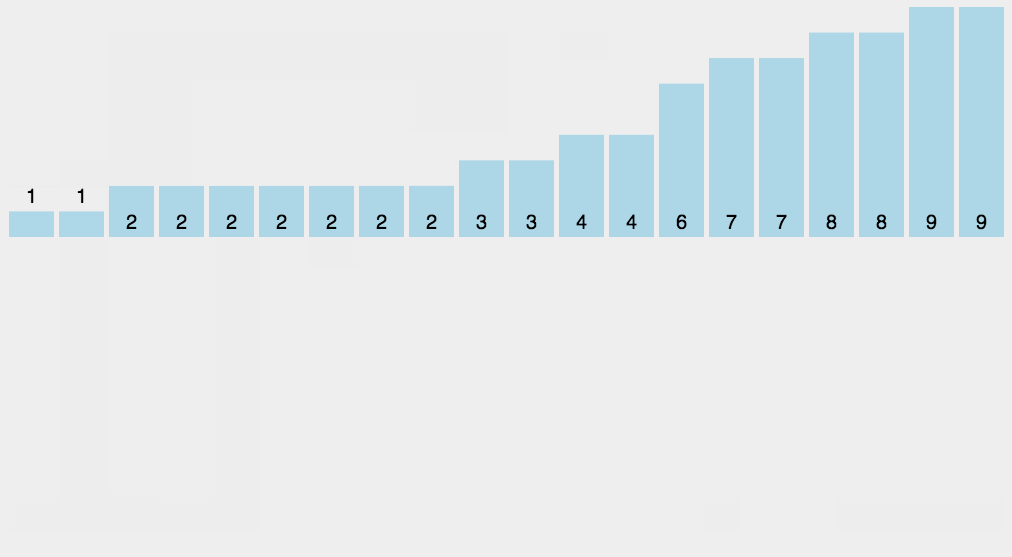<a name="cEose"></a>#### 8.3 代码实现| function countingSort(arr, maxValue) {<br /> var bucket = new Array(maxValue + 1),<br /> sortedIndex = 0;<br /> arrLen = arr.length,<br /> bucketLen = maxValue + 1;<br /> <br /> for (var i = 0; i < arrLen; i++) {<br /> if (!bucket[arr[i]]) {<br /> bucket[arr[i]] = 0;<br /> }<br /> bucket[arr[i]]++;<br /> }<br /> <br /> for (var j = 0; j < bucketLen; j++) {<br /> while(bucket[j] > 0) {<br /> arr[sortedIndex++] = j;<br /> bucket[j]--;<br /> }<br /> }<br /> <br /> return arr;<br />} || --- |<a name="TzEFQ"></a>#### 8.4 算法分析计数排序是一个稳定的排序算法。当输入的元素是 n 个 0到 k 之间的整数时,时间复杂度是O(n+k),空间复杂度也是O(n+k),其排序速度快于任何比较排序算法。当k不是很大并且序列比较集中时,计数排序是一个很有效的排序算法。<a name="kcVEt"></a>### 9、桶排序(Bucket Sort)桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。<a name="qjvIi"></a>#### 9.1 算法描述- 设置一个定量的数组当作空桶;- 遍历输入数据,并且把数据一个一个放到对应的桶里去;- 对每个不是空的桶进行排序;- 从不是空的桶里把排好序的数据拼接起来。<a name="Yo3Gq"></a>#### 9.2 图片演示<a name="WQ0Us"></a>#### 9.3 代码实现| function bucketSort(arr, bucketSize) {<br /> if (arr.length === 0) {<br /> return arr;<br /> }<br /> <br /> var i;<br /> var minValue = arr[0];<br /> var maxValue = arr[0];<br /> for (i = 1; i < arr.length; i++) {<br /> if (arr[i] < minValue) {<br /> minValue = arr[i]; // 输入数据的最小值<br /> } else if (arr[i] > maxValue) {<br /> maxValue = arr[i]; // 输入数据的最大值<br /> }<br /> }<br /> <br /> // 桶的初始化<br /> var DEFAULT_BUCKET_SIZE = 5; // 设置桶的默认数量为5<br /> bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;<br /> var bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1; <br /> var buckets = new Array(bucketCount);<br /> for (i = 0; i < buckets.length; i++) {<br /> buckets[i] = [];<br /> }<br /> <br /> // 利用映射函数将数据分配到各个桶中<br /> for (i = 0; i < arr.length; i++) {<br /> buckets[Math.floor((arr[i] - minValue) / bucketSize)].push(arr[i]);<br /> }<br /> <br /> arr.length = 0;<br /> for (i = 0; i < buckets.length; i++) {<br /> insertionSort(buckets[i]); // 对每个桶进行排序,这里使用了插入排序<br /> for (var j = 0; j < buckets[i].length; j++) {<br /> arr.push(buckets[i][j]); <br /> }<br /> }<br /> <br /> return arr;<br />} || --- |<a name="OiRum"></a>#### 9.4 算法分析桶排序最好情况下使用线性时间O(n),桶排序的时间复杂度,取决与对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为O(n)。很显然,桶划分的越小,各个桶之间的数据越少,排序所用的时间也会越少。但相应的空间消耗就会增大。<a name="G4JuQ"></a>### 10、基数排序(Radix Sort)基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。<a name="n77S0"></a>#### 10.1 算法描述- 取得数组中的最大数,并取得位数;- arr为原始数组,从最低位开始取每个位组成radix数组;- 对radix进行计数排序(利用计数排序适用于小范围数的特点);<a name="Xc9hd"></a>#### 10.2 动图演示<a name="C1gQP"></a>#### 10.3 代码实现| var counter = [];<br />function radixSort(arr, maxDigit) {<br /> var mod = 10;<br /> var dev = 1;<br /> for (var i = 0; i < maxDigit; i++, dev *= 10, mod *= 10) {<br /> for(var j = 0; j < arr.length; j++) {<br /> var bucket = parseInt((arr[j] % mod) / dev);<br /> if(counter[bucket]==null) {<br /> counter[bucket] = [];<br /> }<br /> counter[bucket].push(arr[j]);<br /> }<br /> var pos = 0;<br /> for(var j = 0; j < counter.length; j++) {<br /> var value = null;<br /> if(counter[j]!=null) {<br /> while ((value = counter[j].shift()) != null) {<br /> arr[pos++] = value;<br /> }<br /> }<br /> }<br /> }<br /> return arr;<br />} || --- |<a name="oVjgY"></a>#### 10.4 算法分析基数排序基于分别排序,分别收集,所以是稳定的。但基数排序的性能比桶排序要略差,每一次关键字的桶分配都需要O(n)的时间复杂度,而且分配之后得到新的关键字序列又需要O(n)的时间复杂度。假如待排数据可以分为d个关键字,则基数排序的时间复杂度将是O(d*2n) ,当然d要远远小于n,因此基本上还是线性级别的。<br />基数排序的空间复杂度为O(n+k),其中k为桶的数量。一般来说n>>k,因此额外空间需要大概n个左右。<a name="EvCfG"></a>## 3.4 集合泛型:引用类型的占位符,一般用大写字母表示,可以避免类型转换<br />排序接口:1.Compareable 2.Comparetor<br />Collection<E>:单泛型存储:1. List<E>:有序,可重复1. ArrayList<E>:1. LinkedList<E>:2. Set<E>:无序,不可重复1. HashSet<E>:必须hash值,一样再比较equals1. TreeSet<E>:红黑二叉树,要求元素可排序Map<K,V>:键值对,双泛型1. HashMap1. TreeMap1. LinkedHashMap1. ConcurrentHashMap(JUC)<a name="EIVDs"></a>## 3.5 ArrayList初始容量(1.7 10,1.8 0)<br />扩容原理(达到上限,实现扩容,参考扩容因子,创建新的数组)<br />可变数组<a name="kUAgU"></a>## 3.6 HashMap底层结构(1.7 和1.8)<br />红黑二叉树的转换<br />扩容<br />Hash冲突<br />头插法和尾插法<a name="Xo2cq"></a>## 3.7 ConcurrentHashMap实现线程安全的方式(1.7 分段式锁 1.8 CAS+synchronized)<br />扩容<br />引入-JUC<a name="YgH22"></a># 四、线程&锁<a name="e4eSK"></a>## 4.1 线程进程(运行的程序)&线程(程序中,运行代码的结构)<br />优先级(概率)<br />分类(用户和守护(后台))<a name="rPbzB"></a>## 4.2 线程的创建方式继承Thread<br />实现Runnable<br />实现Future(带返回值)<br />线程池<a name="hehgP"></a>### 方式一:继承Thread类1.自定义类MyThread继承Thread类。<br />2.MyThread类里面重写run()方法。<br />3.创建线程对象。4.启动线程。<br />注意:1、启动线程使用的是start()方法而不是run()方法<br />2、线程不能多次启动,只能执行一次<a name="M1ObT"></a>### 方式二:实现Runnable接口1.自定义类MyRunnable实现Runnable接口<br />2.重写run()方法<br />3.创建MyRunnable类的对象<br />4.创建Thread类的对象,并把步骤3创建的对象作为构造参数传递<br />5.启动线程<a name="u2q3F"></a>### 方式三:使用Callable和Future创建线程和Runnable接口不一样,Callable接口提供了一个call()方法作为线程执行体,call()方法比run()方法功能要强大。<br />1.call()方法可以有返回值<br />2.call()方法可以声明抛出异常<a name="SYKI4"></a>### 方式四:使用线程池创建线程 例如用Executor框架或者ThreadPoolExecutor<a name="CsinW"></a>## Java 线程池**1. newSingleThreadExecutor**<br />创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。<br />**2.newFixedThreadPool**<br />创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。<br />**3. newCachedThreadPool**<br />创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,<br />那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。<br />**4.newScheduledThreadPool**<br />创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。<a name="jH4Fd"></a>## newSingleThreadExecutor
private void TextnewSingleThreadExecutor(){ ExecutorService pool = Executors. newSingleThreadExecutor();
MyTask1 task1 = new MyTask1();MyTask2 task2 = new MyTask2();MyTask3 task3 = new MyTask3();
// pool.execute(task1);// pool.execute(task2);// pool.execute(task3); new Thread(task1).start(); new Thread(task2).start(); new Thread(task3).start(); }
private class MyTask1 implements Runnable{@Override public void run() {//循环输出 for(int i = 0; i < 100; i++){System.out.print("A"+i+"\t");}}}private class MyTask2 implements Runnable{@Override public void run() {// try {// Thread.sleep(1000);// } catch (InterruptedException e) {// e.printStackTrace();// } //循环输出 for(int i = 0; i < 100; i++){System.out.print("B"+i+"\t");}}}private class MyTask3 implements Runnable{@Override public void run() {//循环输出 for(int i = 0; i < 100; i++){System.out.print("C"+i+"\t");}}}
<a name="VuFPN"></a>## ScheduledExecutorService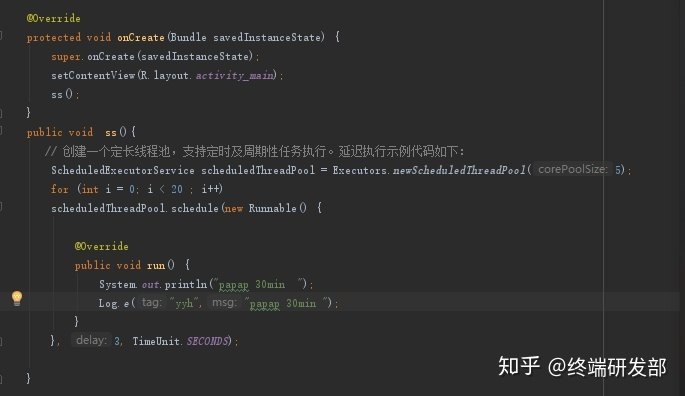<a name="j1EwS"></a>## newFixedThreadPool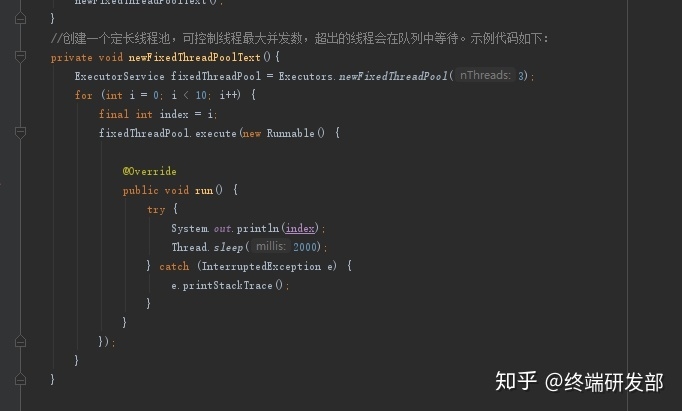<a name="cZuCn"></a>## newCachedThreadPool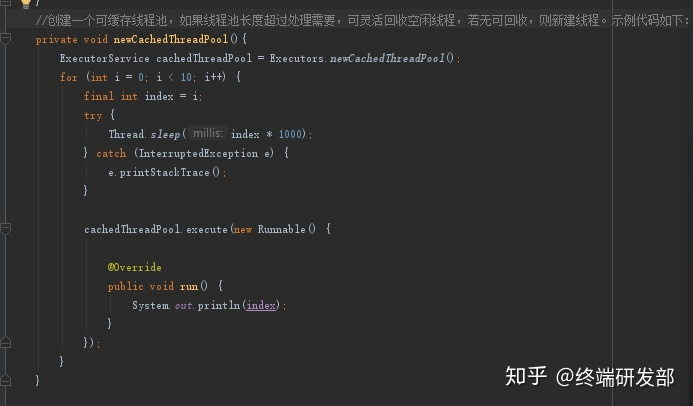<a name="KVxD6"></a>## 4.3 线程的生命周期新建<br />就绪-<br />运行-<br />阻塞-(等待)<br />销毁<br />程序结束运行的标识:所有线程都销毁了<br />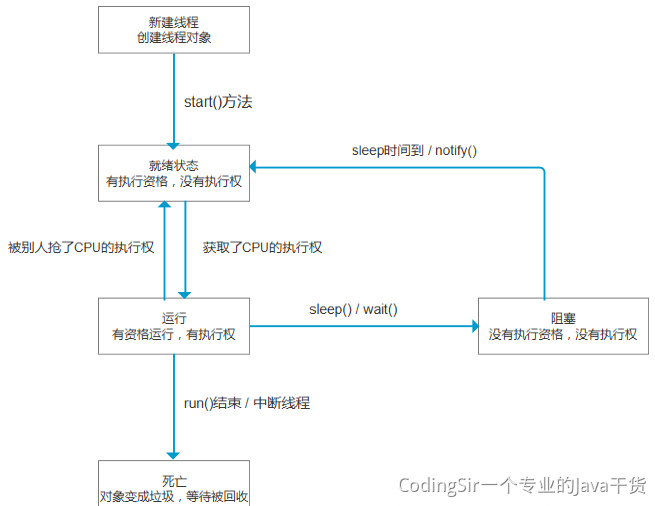<a name="OdgT2"></a>## 4.4 线程安全多个线程,操作同一资源,可能会出现不好的现象<br />锁:可以解决线程安全1. synchronized1. Lock<a name="r4DGK"></a>## 4.5 死锁多个线程因为彼此拥有对方所需的锁,而陷入等待,导致程序无法正常运行<br />原因:锁的滥用<br />合理把控锁的粒度<a name="VySWK"></a>## 4.6 ThreadLocal线程副本(变量),类似Map<Thread,Object>,键存储的是当前线程对象<br />Key的存储采用弱引用<br />防止内存泄漏,用完切记删除<a name="QADk4"></a>## 4.7 voliate内存可见性<br />防止指令重排<br />内存屏障<br />JUC(原子类)<a name="BMy9c"></a>## 4.8 线程池原生创建方式:七大参数1. 核心线程数1. 最大线程数:队列存储满的时候,才会触发最大线程数1. 空闲时间单位1. 空闲时间1. 阻塞队列:存储超过核心线程数的任务对象1. 线程工厂1. 拒绝策略:存储超过最大线程数的任务对象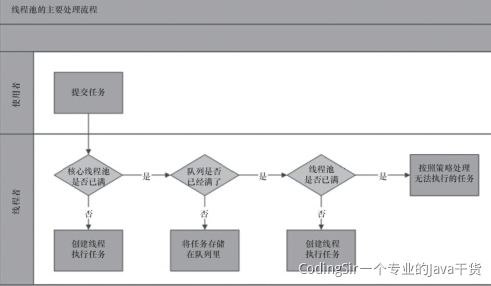<a name="x09cu"></a>## 4.9 线程池的五大状态线程池的5种状态:Running、ShutDown、Stop、Tidying、Terminated<br />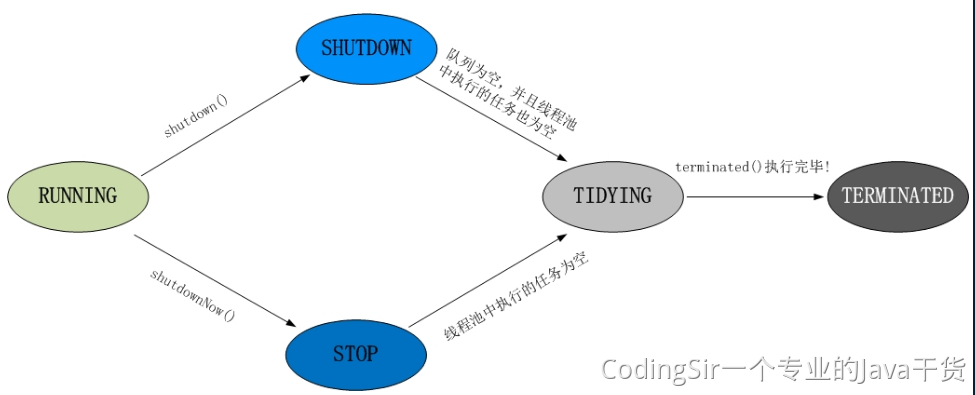<a name="rS3rD"></a>## 4.10 synchronized实现原理对象头的结构<br />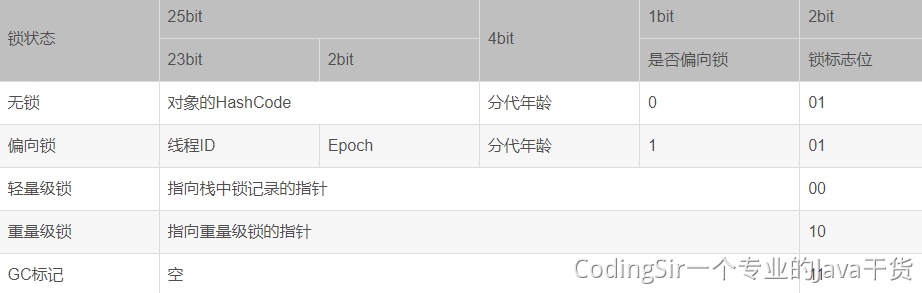<br />对象监视器:记录锁的获取和锁的离开<a name="UbWJf"></a>## 4.11 锁的升级过程锁有四种状态:无锁状态、偏向锁、轻量级锁、重量级锁<br />随着锁的竞争,锁的状态会从偏向锁到轻量级锁,再到重量级锁。而且锁的状态只有升级,没有降级。<br />也就是只有偏向锁->轻量级锁->重量级锁,没有重量级锁->轻量级锁->偏向锁。<br />锁状态的改变是根据竞争激烈程度进行的,在几乎无竞争的条件下,会使用偏向锁,在轻度竞争的条件下,会由偏向锁升级为轻量级锁, 在重度竞争的情况下,会升级到重量级锁。| **锁名称** | **描述** | **应用场景** || --- | --- | --- || 偏向锁 | 线程在大多数情况下并不存在竞争条件,使用同步会消耗性能,而偏向锁是对锁的优化,可以消除同步,提升性能。<br />当一个线程获得锁,会将对象头的锁标志位设为01,进入偏向模式.<br />偏向锁可以在让一个线程一直持有锁,在其他线程需要竞争锁的时候,再释放锁。 | 只有一个线程进入临界区 || 轻量级锁 | 当线程A获得偏向锁后,线程B进入竞争状态,需要获得线程A持有的锁,那么线程A撤销偏向锁,进入无锁状态。<br />线程A和线程B交替进入临界区,偏向锁无法满足,膨胀到轻量级锁,锁标志位设为00。 | 多个线程交替进入临界区 || 重量级锁 | 当多线程交替进入临界区,轻量级锁hold得住。<br />但如果多个线程同时进入临界区,hold不住了,膨胀到重量级锁 | 多个线程同时进入临界区 |**无锁 -> 偏向锁**<br />偏向锁的获取方式是将对象头的 MarkWord 部分中, 标记上线程ID, 以表示哪一个线程获得了偏向锁。 具体的赋值逻辑如下:<br />首先读取目标对象的 MarkWord, 判断是否处于可偏向的状态<br /><br />如果为**可偏向状态**, 则尝试用 CAS 操作, 将自己的线程 ID 写入MarkWord- 如果 CAS 操作成功(状态转变为下图)- 则认为已经获取到该对象的偏向锁, 执行同步块代码 。 注意, age 后面的标志位中的值并没有变化, 这点之后会用到如果是**已偏向状态**, 则检测 MarkWord 中存储的 thread ID 是否等于当前 thread ID- 如果相等, 则证明本线程已经获取到偏向锁,可以直接继续执行同步代码块- 如果不等, 则证明该对象目前偏向于其他线程, 需要撤销偏向锁偏向锁的撤销(revoke)是一个很特殊的操作, 为了执行撤销操作, 需要等待全局安全点(Safe Point), 此时间点所有的工作线程都停止了字节码的执行**偏向锁 -> 轻量级锁**<br />从之前的描述中可以看到, 存在超过一个线程竞争某一个对象时, 会发生偏向锁的撤销操作。 有趣的是, 偏向锁撤销后, 对象可能处于两种状态。<br />一种是不可偏向的无锁状态, 如下图(之所以不允许偏向, 是因为已经检测到了多于一个线程的竞争, 升级到了轻量级锁的机制)<br /><br />另一种是不可偏向的已锁 ( 轻量级锁) 状态<br /><br />**轻量级锁-> 重量级锁**<br />重量级锁依赖于操作系统的互斥量(mutex) 实现,该操作会导致进程从用户态与内核态之间的切换, 是一个开销较大的操作。| **锁** | **优点** | **缺点** | **适用场景** || --- | --- | --- | --- || 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距 | 如果线程间存在锁竞争,会带来额外的锁撤销的消耗 | 适用于只有一个线程访问同步块场景 || 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度 | 如果始终得不到锁竞争的线程使用自旋会消耗CPU | 追求响应时间。<br />同步块执行速度非常快 || 重量级锁 | 线程竞争不使用自旋,不会消耗CPU | 线程阻塞,响应时间缓慢 | 追求吞吐量。<br />同步块执行速度较长 |<a name="Rs2VZ"></a>## 4.12 synchronized锁优化锁消除<br />自旋<br />锁粗化<a name="Shlqm"></a>## 4.13 CAS&ABACAS:比较并替换<br />ABA:问题,CAS可能产生的现象,版本号<a name="wBq3O"></a># 五、网络&新特性<a name="s3ct3"></a>## 5.1 网络模型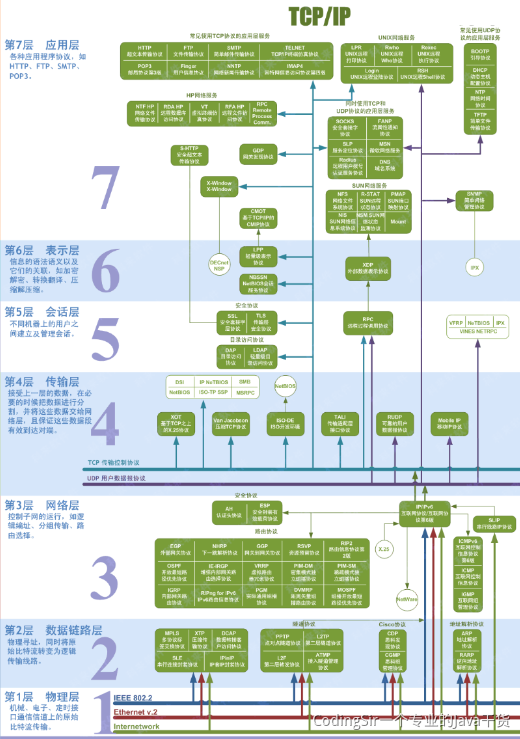<br />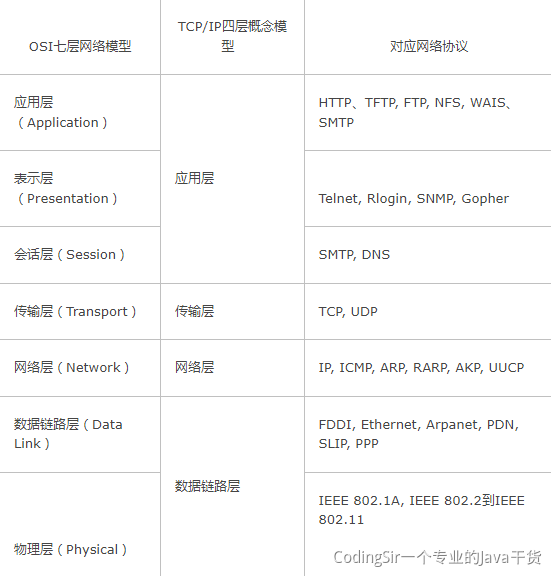<a name="ZoWqR"></a>## 5.2 TCP&UDP传输层的协议:TCP、UDP<br />TCP:面向连接,大小无限制,安全可靠,性能一般<br />UDP:面向无连接,大小限制,不是很安全,性能卓越<a name="K5yY2"></a>## 5.3 TCP的三次握手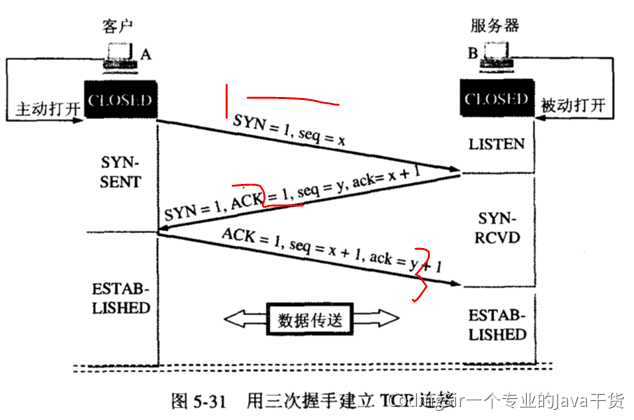<a name="QulAv"></a>## 5.4 TCP四次挥手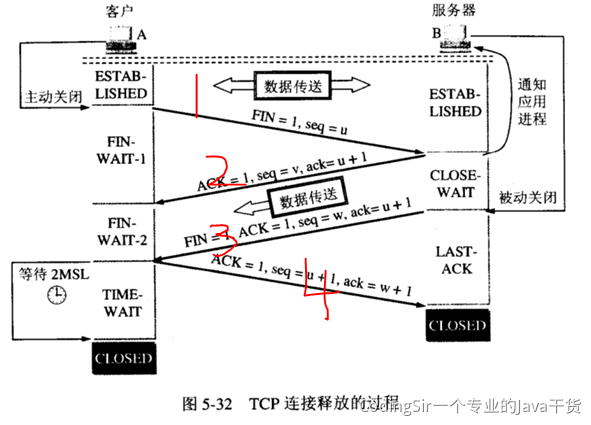<a name="VVWMB"></a>## **TCP协议与UDP协议的区别**首先咱们弄清楚,TCP协议和UDP协议与TCP/IP协议的联系,很多人犯糊涂了, 一直都是说TCP协议与UDP协议的区别,我觉得这是没有从本质上弄清楚网络通信!<br />TCP/IP协议是一个协议簇。里面包括很多协议的,UDP只是其中的一个, 之所以命名为TCP/IP协议,因为TCP、IP协议是两个很重要的协议,就用他两命名了。<br />TCP/IP协议集包括应用层,传输层,网络层,网络访问层。<a name="MG6zV"></a>## 其中应用层包括:1、超文本传输协议(HTTP):万维网的基本协议;<br />2、文件传输(TFTP简单文件传输协议);<br />3、远程登录(Telnet),提供远程访问其它主机功能, 它允许用户登录internet主机,并在这台主机上执行命令;<br />4、网络管理(SNMP简单网络管理协议),该协议提供了监控网络设备的方法, 以及配置管理,统计信息收集,性能管理及安全管理等;<br />5、域名系统(DNS),该系统用于在internet中将域名及其公共广播的网络节点转换成IP地址。<a name="bhMXm"></a>## 其次网络层包括:1、Internet协议(IP);<br />2、Internet控制信息协议(ICMP);<br />3、地址解析协议(ARP);<br />4、反向地址解析协议(RARP)。<a name="Gx37z"></a>## 最后说网络访问层:网络访问层又称作主机到网络层(host-to-network),网络访问层的功能包括IP地址与物理地址硬件的映射, 以及将IP封装成帧.基于不同硬件类型的网络接口,网络访问层定义了和物理介质的连接. 当然我这里说得不够完善,TCP/IP协议本来就是一门学问,每一个分支都是一个很复杂的流程, 但我相信每位学习软件开发的同学都有必要去仔细了解一番。<a name="xI2hA"></a>## **下面着重讲解一下TCP协议和UDP协议的区别**TCP(Transmission Control Protocol,传输控制协议)是面向连接的协议,也就是说,在收发数据前,必须和对方建立可靠的连接。 一个TCP连接必须要经过三次“对话”才能建立起来,其中的过程非常复杂, 只简单的描述下这三次对话的简单过程:1)主机A向主机B发出连接请求数据包:“我想给你发数据,可以吗?”,这是第一次对话;<br />2)主机B向主机A发送同意连接和要求同步 (同步就是两台主机一个在发送,一个在接收,协调工作)的数据包 :“可以,你什么时候发?”,这是第二次对话;<br />3)主机A再发出一个数据包确认主机B的要求同步:“我现在就发,你接着吧!”, 这是第三次对话。三次“对话”的目的是使数据包的发送和接收同步, 经过三次“对话”之后,主机A才向主机B正式发送数据。<a name="hxsyW"></a>## **TCP三次握手过程**第一次握手:主机A通过向主机B 发送一个含有同步序列号的标志位的数据段给主机B,向主机B 请求建立连接,通过这个数据段, 主机A告诉主机B 两件事:我想要和你通信;你可以用哪个序列号作为起始数据段来回应我。<br />第二次握手:主机B 收到主机A的请求后,用一个带有确认应答(ACK)和同步序列号(SYN)标志位的数据段响应主机A,也告诉主机A两件事:我已经收到你的请求了,你可以传输数据了;你要用那个序列号作为起始数据段来回应我<br />第三次握手:主机A收到这个数据段后,再发送一个确认应答,确认已收到主机B 的数据段:"我已收到回复,我现在要开始传输实际数据了,这样3次握手就完成了,主机A和主机B 就可以传输数据了。<a name="WtkLt"></a>## **3次握手的特点**没有应用层的数据 ,SYN这个标志位只有在TCP建立连接时才会被置1 ,握手完成后SYN标志位被置0。<a name="ZCOAM"></a>## **TCP建立连接要进行3次握手,而断开连接要进行4次**第一次: 当主机A完成数据传输后,将控制位FIN置1,提出停止TCP连接的请求 ;<br />第二次: 主机B收到FIN后对其作出响应,确认这一方向上的TCP连接将关闭,将ACK置1;<br />第三次: 由B 端再提出反方向的关闭请求,将FIN置1 ;<br />第四次: 主机A对主机B的请求进行确认,将ACK置1,双方向的关闭结束.。由TCP的三次握手和四次断开可以看出,TCP使用面向连接的通信方式, 大大提高了数据通信的可靠性,使发送数据端和接收端在数据正式传输前就有了交互, 为数据正式传输打下了可靠的基础。<a name="NXbkR"></a>## 名词解释1、ACK 是TCP报头的控制位之一,对数据进行确认。确认由目的端发出, 用它来告诉发送端这个序列号之前的数据段都收到了。 比如确认号为X,则表示前X-1个数据段都收到了,只有当ACK=1时,确认号才有效,当ACK=0时,确认号无效,这时会要求重传数据,保证数据的完整性。<br />2、SYN 同步序列号,TCP建立连接时将这个位置1。<br />3、FIN 发送端完成发送任务位,当TCP完成数据传输需要断开时,,提出断开连接的一方将这位置1。<a name="sSRM6"></a>## TCP的包头结构:源端口 16位;<br />目标端口 16位;<br />序列号 32位;<br />回应序号 32位;<br />TCP头长度 4位;<br />reserved 6位;<br />控制代码 6位;<br />窗口大小 16位;<br />偏移量 16位;<br />校验和 16位;<br />选项 32位(可选);这样我们得出了TCP包头的最小长度,为20字节。<a name="tOzKJ"></a>## **UDP(User Data Protocol,用户数据报协议)**1、UDP是一个非连接的协议,传输数据之前源端和终端不建立连接, 当它想传送时就简单地去抓取来自应用程序的数据,并尽可能快地把它扔到网络上。 在发送端,UDP传送数据的速度仅仅是受应用程序生成数据的速度、 计算机的能力和传输带宽的限制; 在接收端,UDP把每个消息段放在队列中,应用程序每次从队列中读一个消息段。<br />2、 由于传输数据不建立连接,因此也就不需要维护连接状态,包括收发状态等, 因此一台服务机可同时向多个客户机传输相同的消息。<br />3、UDP信息包的标题很短,只有8个字节,相对于TCP的20个字节信息包的额外开销很小。<br />4、吞吐量不受拥挤控制算法的调节,只受应用软件生成数据的速率、传输带宽、 源端和终端主机性能的限制。<br />5、UDP使用尽最大努力交付,即不保证可靠交付, 因此主机不需要维持复杂的链接状态表(这里面有许多参数)。<br />6、UDP是面向报文的。发送方的UDP对应用程序交下来的报文, 在添加首部后就向下交付给IP层。既不拆分,也不合并,而是保留这些报文的边界, 因此,应用程序需要选择合适的报文大小。我们经常使用“ping”命令来测试两台主机之间TCP/IP通信是否正常, 其实“ping”命令的原理就是向对方主机发送UDP数据包,然后对方主机确认收到数据包, 如果数据包是否到达的消息及时反馈回来,那么网络就是通的。**ping命令**是用来探测主机到主机之间是否可通信,如果不能**ping**到某台主机,表明不能和这台主机建立连接。**ping命令**是使用 IP 和网络控制信息协议 (ICMP),因而没有涉及到任何传输协议(UDP/TCP) 和应用程序。它发送icmp回送请求消息给目的主机。<br />ICMP协议规定:目的主机必须返回ICMP回送应答消息给源主机。如果源主机在一定时间内收到应答,则认为主机可达。<a name="N2C4g"></a>## **UDP的包头结构:**源端口 16位<br />目的端口 16位<br />长度 16位<br />校验和 16位<a name="IBMtE"></a>## **小结TCP与UDP的区别:**1、基于连接与无连接;<br />2、对系统资源的要求(TCP较多,UDP少);<br />3、UDP程序结构较简单;<br />4、流模式与数据报模式 ;<br />5、TCP保证数据正确性,UDP可能丢包;<br />6、TCP保证数据顺序,UDP不保证。<a name="XENZr"></a>## 5.5 BIO、NIO、AIOBIO:同步阻塞IO流:Socket<br />NIO(Netty):同步非阻塞IO流:Channel、Buffer、Selector<br />AIO:异步非阻塞IO流<a name="XUq6P"></a>## 5.6 函数式编程Lambda表达式:代替匿名内部类,简化代码,要求:接口中只能有一个方法<br />Stream,实现链式编程<br />**Function**<br />**Predicate**<br />**Consumer**<br />**Supplier**<a name="wCZvN"></a>## 5.7 JUCJUC: java.util.concurrent<br />用于定义类似于线程的自定义子系统,包括线程池、异步 IO 和轻量级任务框架。提供可调的、灵活的线程池、CountDownLatch、Lock<a name="w7sLM"></a># 六、JavaWeb<a name="pV5Fy"></a>## 6.1 数据交互格式JSON:特殊的字符串,符合一定的规则,{}:对象 []:数组 工具包:Jackson、Fastjson<br />XML:特殊的文档,自定义标签组成。<br />跨语言、跨网络、跨平台<a name="QItTo"></a>## 6.2 TomcatIO模型:默认NIO<br /><a name="wStk7"></a>## 6.3 Servlet开发接口,可以通过http协议访问<br />生命周期:初始化、服务、销毁<br />注册:1.注解 2.xml<br />Http请求方式:get post <br />重定向(2次请求)和转发(1次请求)<a name="Laeo7"></a>## 6.4 Filter过滤器,对请求进行预处理,可以拦截请求<br />生命周期:初始化、拦截、销毁<br />注册:1.注解 2.xml<a name="Ee941"></a>## 6.5 Listener监听器,监听状态<br />ServletContext(Application)<br />HttpSession<br />HttpServletRequest<br />注册:1.注解 2.xml<a name="vXdda"></a>## 6.6 Cookie&HttpSessionCookie:浏览器端存储<br />HttpSession:服务端存储<a name="haCiY"></a>## 6.7 Https安全的Http协议,SSL<br />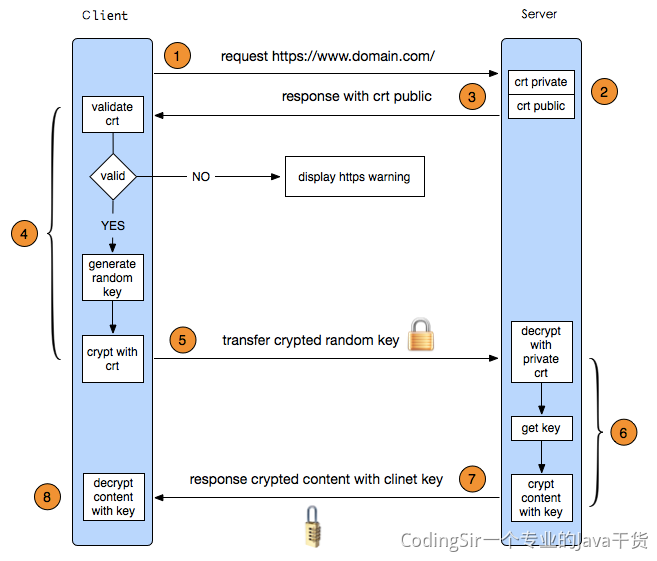<a name="qmvyg"></a># 七、框架(SSM)<a name="bpBGb"></a>## 7.1 Spring的IOC和DIIOC:控制反转,实现对象的创建,并为属性赋值<br />创建的对象的形式:1.单例(默认):唯一对象 2.多例:只要调用,就会创建新的对象<br />DI:依赖注入,某个类的中属性,依赖于其他类型,并为属性赋值的过程<a name="ENrHw"></a>## 7.2 Spring的AOPAOP:面向切面编程,只关注横切相关的内容,也就是只关心有没有包含指定的方法,对匹配的内容进行增强处理(不改变源码)<br />切入点表达式:execution * 包名.*.*(..) 匹配对应的方法<br />通知:增强处理的内容,又分为五种:1. 成功通知1. 失败通知1. 前置通知1. 环绕通知1. 后置通知某些情况下,使用AOP,很方便:<br />比如:操作日志、错误日志、性能分析等<a name="pl5fF"></a>## 7.3 Spring的循环依赖循环依赖:A类中有B,B类中有A.这样的话,创建A或者B就会失败<br />解决循环依赖:<br />1.应该从设计的角度上面,避免出现循环依赖的现象-最好的方式<br />2.三级缓存机制,解决循环依赖的问题<a name="HxzYt"></a>## 7.4 Spring Bean的生命周期1、从xml配置的Bean,@Bean注解,或者Java代码BeanDefinitionBuilder中读取Bean的定义,实例化Bean对象;<br />2、设置Bean的属性;<br />3、注入Aware的依赖(BeanNameAware,BeanFactoryAware,ApplicationContextAware);<br />4、执行通用的方法前置处理,方法: BeanPostProcessor.postProcessorBeforeInitialization()<br />5、执行 InitalizingBean.afterPropertiesSet() 方法<br />6、执行Bean自定义的初始化方法init,或者 @PostConstruct 标注的方法;<br />7、执行方法BeanPostProcessor.postProcessorAfterInitialization()<br />8、创建对象完毕;<br />9、执行 DisposableBean.destory() 方法;<br />10、执行自定义的destory方法或者 @PreDestory 标注的方法;<br />11、销毁对象完毕<br />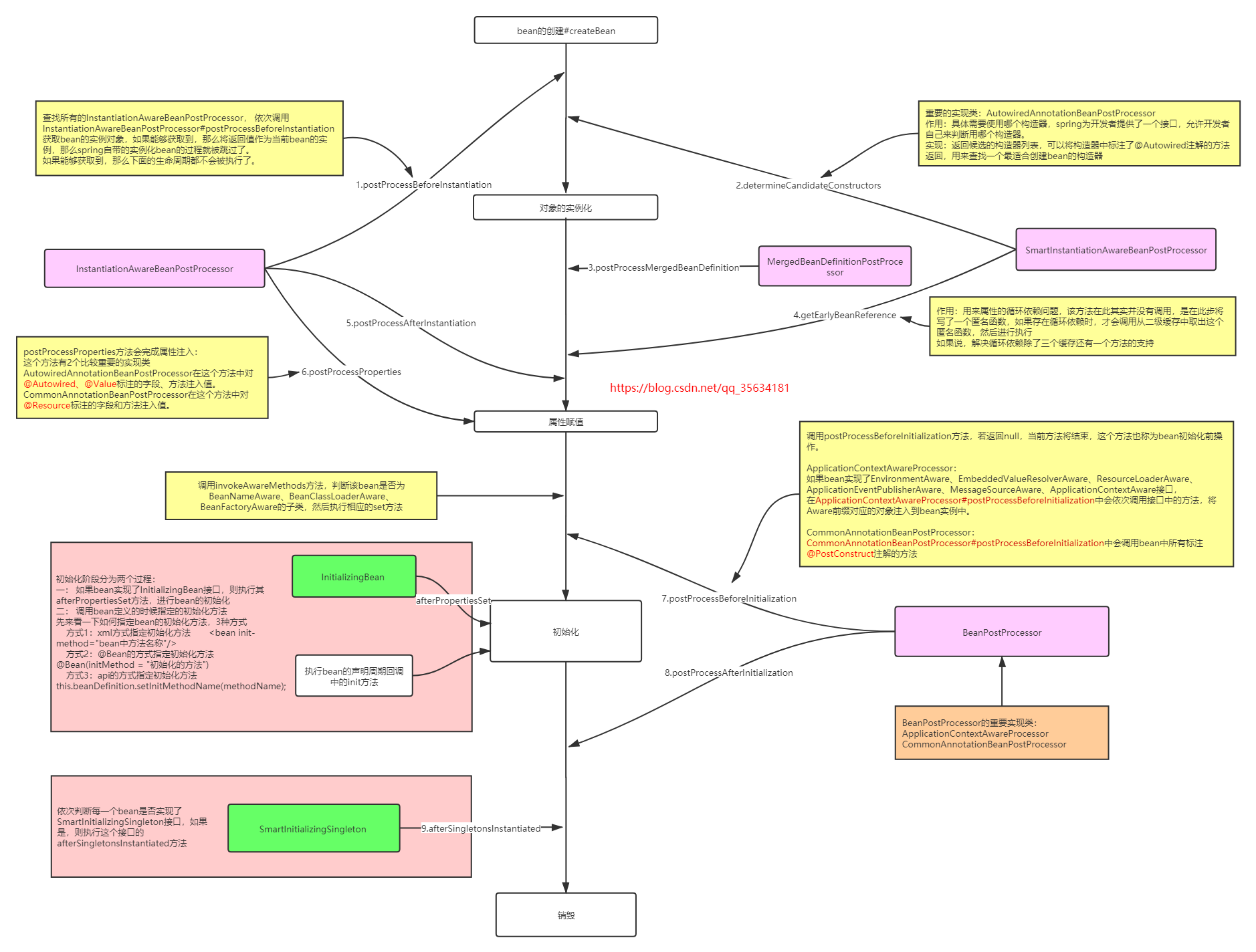<a name="VaMQ3"></a>## 7.5 Spring涉及的设计模式1. 工厂模式:BeanFactory1. 单例模式:Spring下默认的bean均为singleton,仅仅实现对象的唯一实例1. **适配器模式:**在Spring的Aop中,使用的Advice(通知)来增强被代理类的功能1. 代理模式:JdkDynamicAopProxy,Aop的实现上1. **包装器模式:**spring中用到的包装器模式在类名上有两种表现:一种是类名中含有Wrapper,另一种是类名中含有Decorator1. **模板方法模式:**JdbcTemplate1. **策略模式:**spring中在实例化对象的时候用到Strategy模式,SimpleInstantiationStrategy1. **观察者模式:**spring中Observer模式常用的地方是listener的实现。如ApplicationListener引入:设计模式的理解,一定要会手写单例模式实现<a name="UrbqK"></a>## 7.6 Spring的常用注解创建对象:```java@Component@Service@Controller@RestController@Bean
属性注入:
@Value@Autowire@Qulify
其他注解:
@Configrution@AopPoint
引入:@Autowire和@Resource
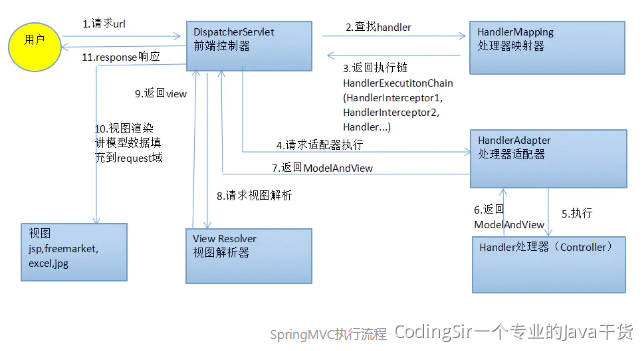
7.7 SpringMVC的运行流程
7.8 拦截器
可以对请求进行拦截处理,作用跟过滤器相似
默认三个方法:1.预处理 2.后处理 3.请求完成
引入:拦截器 VS 过滤器
7.9 RestFul
把请求的接口作为对资源的操作,对同一资源的操作,接口路径应该一样,通过请求方式,区分操作行为
- 查询:Get请求
- 新增:Post请求
- 修改:Put请求
- 删除:Delete请求
7.10 SpringMVC常用注解
请求路径,url地址:@RequestMapping@GetMapping@PostMapping@PutMapping@DeleteMapping请求参数:@RequestParam@RequestBody@PathVariable响应结果:@ResponseBody
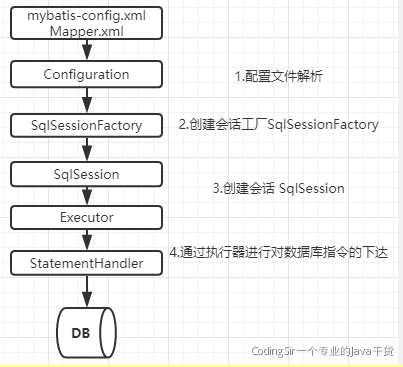
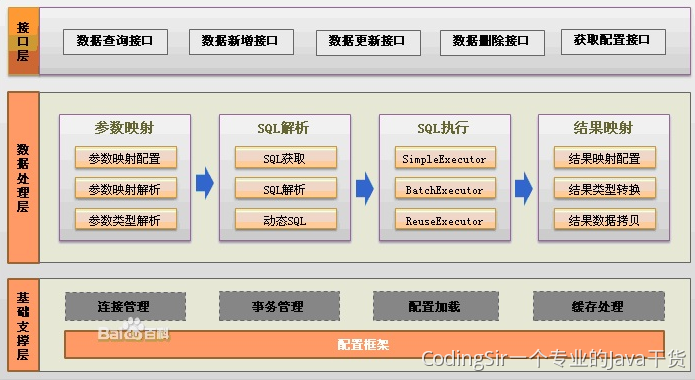
7.11 Mybatis实现原理
7.12 Mybats缓存机制
一级缓存:SqlSession,存在,只要执行DML语句就会删除一级缓存
二级缓存:SqlSessionFactory,需要手动开启,并完成配置(mapper)
缓存策略:LRU、Soft、Weak等
7.13 Mybatis的多表关系
Mybatis实现多表关系映射有多种方式:
- 写联合SQL语句,对结果封装dto类 -推荐
- 实现类的嵌套定义(聚合),编写联合sql语句,使用ResultMap中Collection
- 实现类的嵌套定义,编写单独的sql语句,采用级联查询,(懒加载机制)
常见的多表关系:
一对一、一对多、多对一、多对多
涉及:E-R图
7.14 Mybatis动态SQL
动态拼接sql语句,给定一些标签,实现动态sql
foreach
where
set
if
trim
incloud
可以借助foreach实现批处理(批量新增、批量修改、批量删除)
7.15 Mybais
ResultType和ResultMap
- ResultType:简单类型,一一对应
- ResultMap:可以应对复杂类型,比如名称不一致,嵌套对象、集合
$和#
批处理
配合Excel文件上传使用,使用foreach标签
多参数
dao层方法有多个参数,的处理方案:
- 把参数封装成类
- 使用Map代替
- 使用@Param注解
7.16 Spring的事务
声明式事务,基于AOP实现的,只需要完成配置,就可以为业务添加事务处理
事务的传播行为: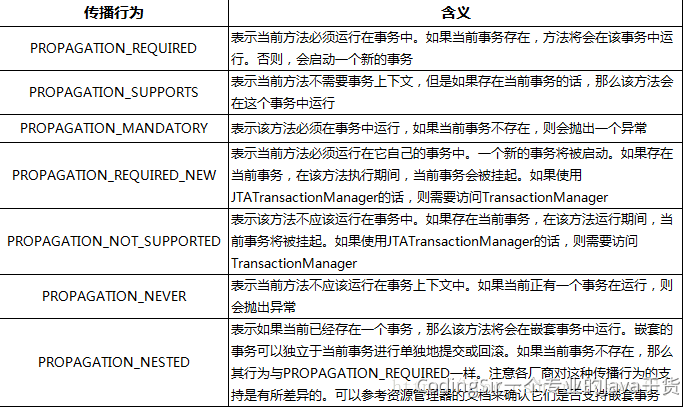
7.17 SSM整合模板
实现SSM的整合,采用Maven进行管理,源码的版本管理采用Git
整合的步骤:
1.jar依赖
2.配置文件
3.编写代码,小心包的结构
4.编写页面,采用Layui
5.运行测试
八、工具(Git Maven)
8.1 Git仓库
- 本地仓库:存储在本机
- 工作区:包含.git文件夹
- 暂存区:在.git里面,暂时存储工作区变化,只要有推、拉、提交都会清空暂存区
- 版本区:真正存储最终版本的内容,里面包含指针(Header)、对应提交的内容(包含历史)
- 远程仓库:存储在远程
目前远程仓库有三种:
- GitHub(国际)
- Gitee(码云)
- GitLab(局域网)
8.2 Git命令
git initgit clonegit loggit add 文件名或*git commit -m '注释内容'git pushgit pullgit configgit status
8.3 Git分支
分支:可以实现代码分离,根据开发进度或者清空,会划分不同的分支,来表示不同的意义
git branch 分支名称:创建分支master - 主干(默认)feature/* - 特性分支 -bugdevelop - 测试分支 -devrelease/* - 预发布版本 -testhotfix/* -紧急修复分支 -error
git checkout 分支名称:切换分支
git merge 分支1 分支2:合并分支8.4 Maven仓库
- 本地仓库
- 个人电脑上,Maven的仓库路径
- 私有仓库(私服)
- 公司内部会搭建Maven的私服-Nexus https://www.sonatype.com/
- 远程仓库
- 国内的第三方公司,阿里云、腾讯云、新浪等 镜像
- 中央仓库
- Apache提供的仓库 https://mvnrepository.com/
8.5 Maven命令
 ```shell
```shell
- Apache提供的仓库 https://mvnrepository.com/
- 创建Maven的普通java项目: mvn archetype:create -DgroupId=packageName -DartifactId=projectName
- 创建Maven的Web项目:
mvn archetype:create -DgroupId=packageName -DartifactId=webappName-DarchetypeArtifactId=maven-archetype-webapp - 编译源代码: mvn compile
- 编译测试代码:mvn test-compile
- 运行测试:mvn test
- 产生site:mvn site
- 打包:mvn package
- 在本地Repository中安装jar:mvn install
- 清除产生的项目:mvn clean
- 生成eclipse项目:mvn eclipse:eclipse
- 生成idea项目:mvn idea:idea
- 组合使用goal命令,如只打包不测试:mvn -Dtest package
- 编译测试的内容:mvn test-compile
- 只打jar包: mvn jar:jar
- 只测试而不编译,也不测试编译:mvn test -skipping compile -skipping test-compile ( -skipping 的灵活运用,当然也可以用于其他组合命令)
清除eclipse的一些系统设置:mvn eclipse:clean ```
8.6 Maven
打包方式
通过packaging设置- jar 默认
- war web类型的项目
- pom 作为父类项目
依赖范围
通过scope设置
| scope取值 | 有效范围(compile, runtime, test) | 依赖传递 | 例子 |
|---|---|---|---|
| compile | all | 是 | spring-core |
| provided | compile, test | 否 | servlet-api |
| runtime | runtime, test | 是 | JDBC驱动 |
| test | test | 否 | JUnit |
| system | compile, test | 是 |
依赖冲突
如果项目对同一个jar,依赖了多个不同的版本,可能就会出现依赖冲突,解决方案:
- 版本限定,通过dependencyManagement实现jar版本号的限定
- 通过排除不用的版本号,exclusions
可以在Idea中下载一个插件:Maven Helper 可以查看依赖树
九、微服务(SpringBoot、SpringCloud)
9.1 SpingBoot自动装配原理

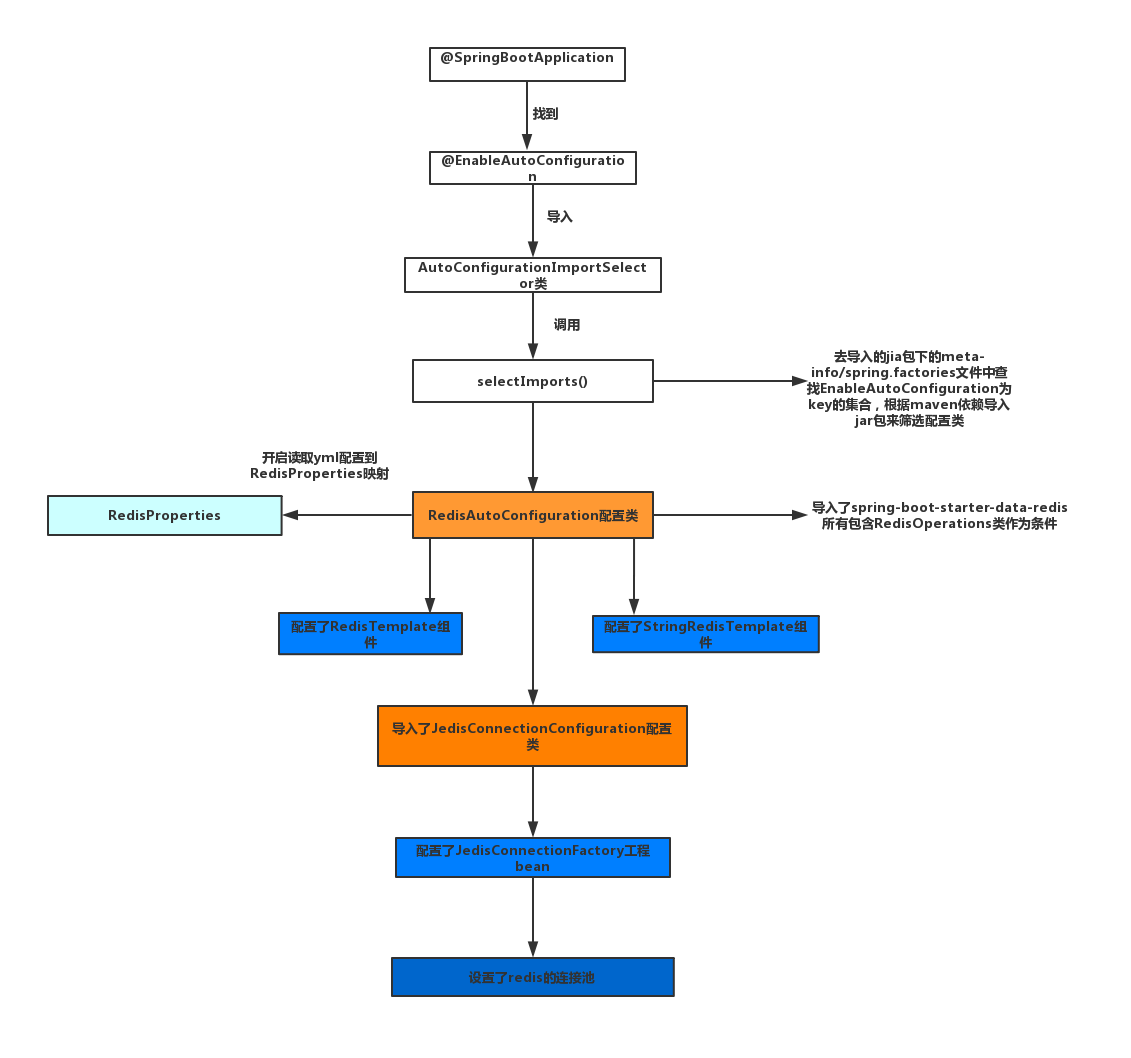
9.2 微服务
分而治之、应对三高(高并发、高扩展、高可用)、架构(https://www.yuque.com/docs/share/a6a6c246-8249-4391-a60c-7ffa491be406)
目前主流的服务划分:根据功能模块进行拆解
低耦合、高内聚
DDD:领域驱动设计
解决方案:
- Dubbo
- SpringCloud + Alibaba
9.3 Spring Cloud组件
注册中心:Nacos(阿里)
配置中心:Nacos(阿里)
服务调用:OpenFeign
网关中心:Gateway
熔断降级:Sentinel(阿里)
链路跟踪:Sleuth+Zipkin9.4 分布式锁
RedLock9.5 分布式事务
Seata(阿里)
十、中间件(RabbitMQ、Elasticsearch)
10.1 RabbitMQ消息机制
10.2 死信机制
10.3 幂等性
10.4 消息不丢失
10.5 Elasticsearch倒排索引
10.6 Elasticsearch存储过程
10.7 Elasticsearch推荐查询
十一、Mysql
11.1 Mysql存储引擎InnoDB和MyISAM
1) 事务支持
MyISAM不支持事务,而InnoDB支持。InnoDB的AUTOCOMMIT默认是打开的,即每条SQL语句会默认被封装成一个事务,自动提交,这样会影响速度,所以最好是把多条SQL语句显示放在begin和commit之间,组成一个事务去提交。
MyISAM是非事务安全型的,而InnoDB是事务安全型的,默认开启自动提交,宜合并事务,一同提交,减小数据库多次提交导致的开销,大大提高性能。
2) 存储结构
MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
3) 存储空间
MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
4) 可移植性、备份及恢复
MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。
5) 事务支持
MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。
InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
6) AUTO_INCREMENT
MyISAM:可以和其他字段一起建立联合索引。引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。
InnoDB:InnoDB中必须包含只有该字段的索引。引擎的自动增长列必须是索引,如果是组合索引也必须是组合索引的第一列。
7) 表锁差异
MyISAM:只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
MyISAM锁的粒度是表级,而InnoDB支持行级锁定。简单来说就是, InnoDB支持数据行锁定,而MyISAM不支持行锁定,只支持锁定整个表。即MyISAM同一个表上的读锁和写锁是互斥的,MyISAM并发读写时如果等待队列中既有读请求又有写请求,默认写请求的优先级高,即使读请求先到,所以MyISAM不适合于有大量查询和修改并存的情况,那样查询进程会长时间阻塞。因为MyISAM是锁表,所以某项读操作比较耗时会使其他写进程饿死。
8) 全文索引
MyISAM:支持(FULLTEXT类型的)全文索引
InnoDB:不支持(FULLTEXT类型的)全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。
11.2 Mysql的事务
现象:
- 脏读:读取到了未提交的数据(如果事务这时候回滚了,那么第二个事务就读到了脏数据)
- 幻读:当用户读取某一范围的数据行时,另一个事务又在该范围内插入(删除)了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行;新增或删除
- 不可重复读:同一个事务中,对于同一数据,执行完全相同的select语句时可能看到不一样的结果;修改
隔离级别: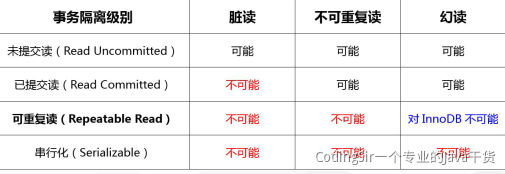
特性:ACID
- 原子性(Atomicity):是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- 一致性(Consistency):事务前后数据的完整性必须保持一致。
- 隔离性(Isolation):是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
- 持久性(Durability):是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
11.3 SQL语句
DDL
DML
DQL
TPL
CCL
DCL
联合查询:
自然查询、笛卡尔积、左外连接、右外连接、内连接、全连接(Mysql)、子查询
经典的SQl题:
1.行转列
11.4 索引
11.5 SQL优化
11.6 函数&存储过程
十二、Redis
12.1 应用场景
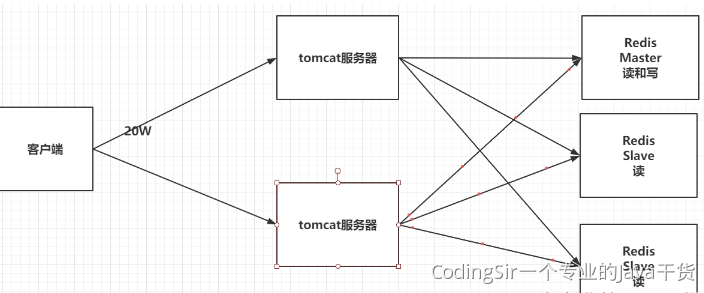
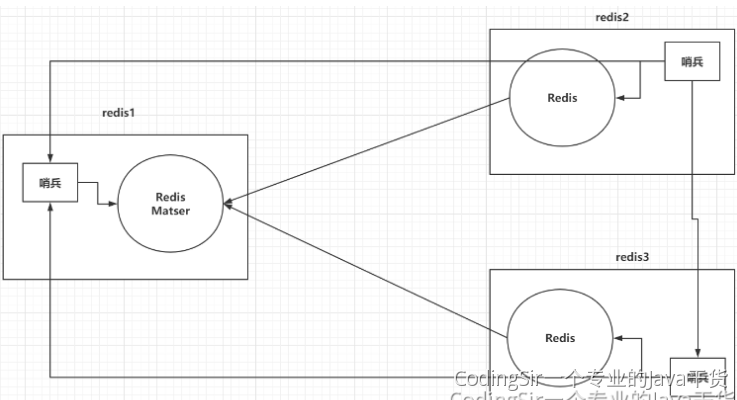
- 哨兵模式
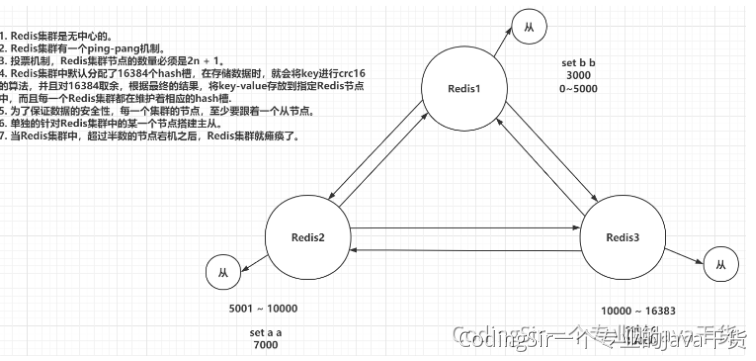
- Redis-Cluster
12.3 Redis数据类型
常用的5种数据结构:
- key-string:一个key对应一个值。
- key-hash:一个key对应一个Map。
- key-list:一个key对应一个List列表。
- key-set:一个key对应一个Set集合。
- key-zset:一个key对应一个有序的Set集合。等价于:Map
另外3种数据结构:
- HyperLogLog:计算近似值的。
- GEO:地理位置。
- BIT:一般存储的也是一个字符串,存储的是一个byte[]。
12.4 Redis持久化
持久化为了把内存数据存储到磁盘上,以防Redis服务器宕机Redis提供2种方式实现持久化:1.RDB 2.AOF
同时开启RDB和AOF的注意事项:
如果同时开启了AOF和RDB持久化,那么在Redis宕机重启之后,需要加载一个持久化文件,优先选择AOF文件。
如果先开启了RDB,再次开启AOF,如果RDB执行了持久化,那么RDB文件中的内容会被AOF覆盖掉。 ```shell RDB是Redis默认的持久化机制 RDB持久化文件,速度比较快,而且存储的是一个二进制的文件,传输起来很方便。 RDB持久化的时机: save 900 1:在900秒内,有1个key改变了,就执行RDB持久化。 save 300 10:在300秒内,有10个key改变了,就执行RDB持久化。 save 60 10000:在60秒内,有10000个key改变了,就执行RDB持久化。 RDB无法保证数据的绝对安全。 RDB存储的是数据,时间间隔无法实时持久化
AOF持久化机制默认是关闭的,Redis官方推荐同时开启RDB和AOF持久化,更安全,避免数据丢失。 AOF持久化的速度,相对RDB较慢的,存储的是一个文本文件,到了后期文件会比较大,传输困难。 AOF持久化时机。 appendfsync always:每执行一个写操作,立即持久化到AOF文件中,性能比较低。 appendfsync everysec:每秒执行一次持久化。 appendfsync no:会根据你的操作系统不同,环境的不同,在一定时间内执行一次持久化。 AOF相对RDB更安全,推荐同时开启AOF和RDB。 AOF存储的是命令(更改数据的命令),可以实时持久化
<a name="vcSdf"></a>## 12.5 Redis过期策略Redis对于设置有效期的key,会进行以下方案进行删除:1. 定期删除:Redis每隔一段时间就去会去查看Redis设置了过期时间的key,会在100ms的间隔中默认查看3个key。1. 惰性删除:如果当你去查询一个已经过了生存时间的key时,Redis会先查看当前key的生存时间,是否已经到了,直接删除当前key,并且给用户返回一个空值。引入:如果一个key有有效期,但是一直不访问,有可能失效了也会在内存占用空间<a name="MCI2a"></a>## 12.6 Redis淘汰机制如果Redis的内存占用到达最大内存要求,就会触发淘汰机制,释放内存<br />LRU:Last Recent Use1. volatile-lru:在内存不足时,Redis会在设置过了生存时间的key中干掉一个最近最少使用的key。1. allkeys-lru:在内存不足时,Redis会在全部的key中干掉一个最近最少使用的key。1. volatile-lfu:在内存不足时,Redis会在设置过了生存时间的key中干掉一个最近最少频次使用的key。1. allkeys-lfu:在内存不足时,Redis会再全部的key中干掉一个最近最少频次使用的key。1. volatile-random:在内存不足时,Redis会再设置过了生存时间的key中随机干掉一个。1. allkeys-random:在内存不足时,Redis会再全部的key中随机干掉一个。1. volatile-ttl:在内存不足时,Redis会在设置过了生存时间的key中干掉一个剩余生存时间最少的key。1. noeviction:(默认)在内存不足时,直接报错。指定淘汰机制的方式:maxmemory-policy 具体策略,设置Redis的最大内存:maxmemory 字节大小<a name="lVqBq"></a>## 12.7 Redis穿透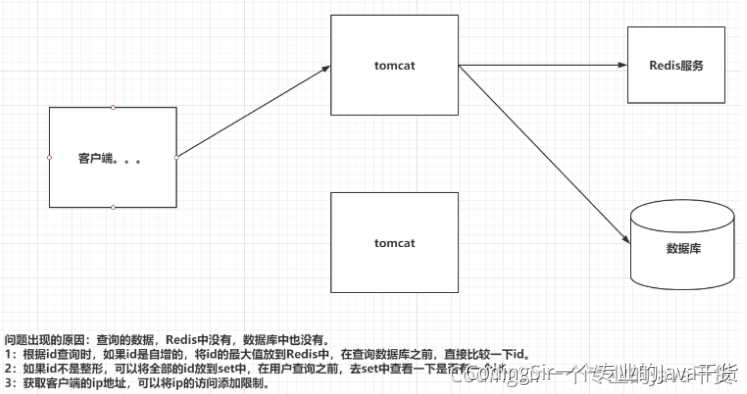<br />高并发下,同一时间,大量的请求同时访问Redis中一个不存在数据,最终导致请求落到了数据库,导致数据库宕机,这种现象穿透<br />解决方案:布隆过滤器<a name="W84cV"></a>## 12.8 Redis雪崩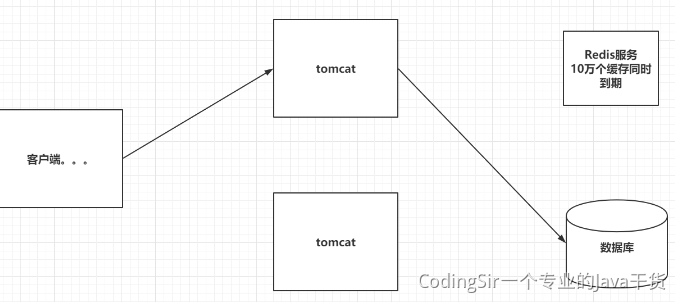<br />高并发下,同一时间,大量的请求同时访问Redis中多个过期的数据,最终导致请求落到了数据库,导致数据库宕机,这种现象雪崩<br />解决方案:不要为很多个key设置一样的失效时间,可以错峰<a name="PFJPo"></a>## 12.9 Redis击穿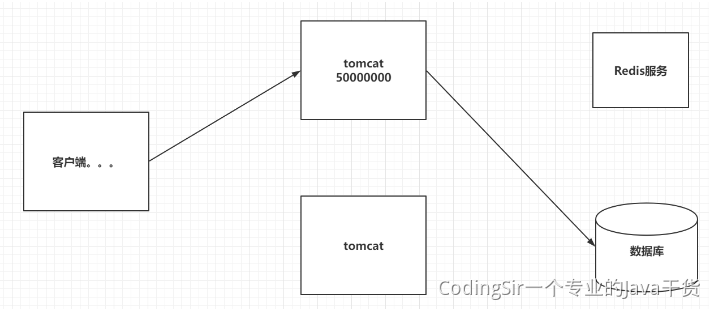高并发下,同一时间,大量的请求同时访问Redis中一个过期的数据,最终导致请求落到了数据库,导致数据库宕机,这种现象击穿<br />解决方案:热点key不设置有效期,做好数据同步<a name="YkZX8"></a>## 12.10 Redis倾斜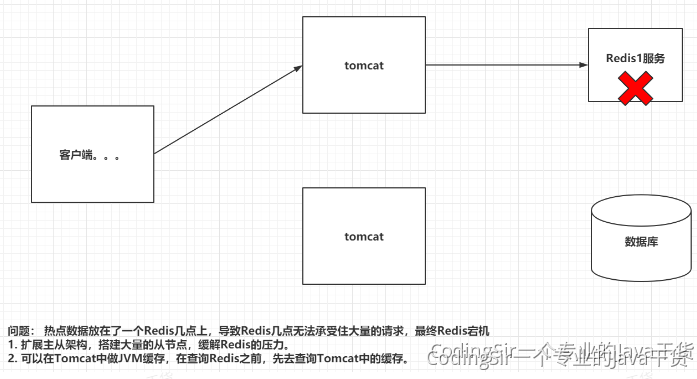<br />Redis集群中,大量的请求(高并发),同时请求一个key,结果这些请求都落在某一台服务器上,最终导致这台服务器宕机,这叫倾斜<br />解决方案:应该从设计的角度上面,避免热点key<a name="vUJNg"></a>## 12.11 Redis事务Redis的事务:一次事务操作,改成功的成功,该失败的失败。<br />先开启事务,执行一些列的命令,但是命令不会立即执行,会被放在一个队列中,如果你执行事务,那么这个队列中的命令全部执行,如果取消了事务,一个队列中的命令全部作废。<br />- 开启事务:multi<br />- 输入要执行的命令:被放入到一个队列中<br />- 执行事务:exec<br />- 取消事务:discard<br />Redis的事务想发挥功能,需要配置watch监听机制<br />在开启事务之前,先通过watch命令去监听一个或多个key,在开启事务之后,如果有其他客户端修改了我监听的key,事务会自动取消。<br />如果执行了事务,或者取消了事务,watch监听自动消除,一般不需要手动执行unwatch。<a name="MsCXL"></a>## 12.12 Redis实现分布式锁RedLock:红锁<a name="bY0hz"></a># 十三、运维(Linux、Docker)<a name="FCmTr"></a>## 13.1 Linux常用命令```shelltar -zxvf 压缩文件 解压tar -zcvf 压缩文件 生成vi|vim 文档名称 创建或编辑文档ps -ef| grep xxx 搜索运行的进程findcattailmorepskill
13.2 Linux配置环境
https://www.yuque.com/docs/share/fdeb734b-978a-4fac-86d8-cdc8287d21f4?# 《Linux你需要会的》
13.3 Docker
容器化引擎(虚拟机),可以充分利用资源,让服务器高效使用
一般都是在物理机,通过Docker(K8s)搭建私有云或者共有云
特性:
- 隔离性
- 性能高
- 一致环境
13.4 Docker常用命令
##查看docker容器版本docker version##查看docker容器信息docker info##查看docker容器帮助docker --help##列出本地imagesdocker images##含中间映像层docker images -a##搜索仓库MySQL镜像docker search mysql## --filter=stars=600:只显示 starts>=600 的镜像docker search --filter=stars=600 mysql## --no-trunc 显示镜像完整 DESCRIPTION 描述docker search --no-trunc mysql## --automated :只列出 AUTOMATED=OK 的镜像docker search --automated mysql##下载镜像docker pull 镜像名称:版本号##单个镜像删除docker rmi 镜像名称:版本号##强制删除(针对基于镜像有运行的容器进程)docker rmi -f 镜像名称:版本号##新建并运行docker run##查看容器日志,默认参数docker logs 容器名称##查看正在运行的容器docker ps##查看正在运行的容器的IDdocker ps -q##查看正在运行+历史运行过的容器docker ps -a##显示运行容器总文件大小docker ps -s
13.5 Docker-Compose
以yaml文件创建Docker容器,容器编排技术
docker创建容器的方式,有2种:
- docker 命令创建,docker run :适合单个容器
- 编写yaml文件,通过Docker-Compose创建对应的容器:适合一次性创建多个容器
安装Docker-Compose
编写对应容器的yaml文件
创建对应容器
13.6 线上问题排查
定位:
通过日志、进程查询、硬件使用率
分析:
常见的一些错误问题:内存溢出、内存泄漏、死锁、代码bug、逻辑bug、硬件、网络抖动、数据库、超时等等
解决:
根据分析的情况,给出对应的解决方案
十四、前端(Html、Css、Js、Vue)
Html
显示内容,通过标签(固定)

Css
对html标签,进行美化,实现样式的设计
选择器:
- id选择器
- class选择器
- 标签选择器
- 派生选择器
- 属性选择器
语法格式:
选择器{
样式属性名称:值
}
常用的属性:



JavaScript
编程语言,实现脚本交互,让html标签动起来
语法格式
函数
对象
Dom
Bom

jQuery
对JavaScript的封装,简化操作
$符号
Layui
专业前端封装的一些好看的标签样式和对应的js脚本
https://www.layui.site/index.htm
Ajax
网页请求后端接口的技术,常用:$.ajax或者$.get或者$.post
Vue.js
特别好用的js库,可以实现响应式
- 插值 {{属性}}
- 分支 v-if
- 循环 v-for
- 属性绑定 v-bind
- 事件绑定 v-on
- 组件-封装
VueX
状态管理,实现Vue组件的共享数据的存储
state:定义存储的数据
mutation:定义修改数据的函数
Vue-Router
路由管理组件,实现Vue组件的跳转
跳转的方式:
- 声明式 router-link
- 编程式 $route.push
跳转组件的同时还可以传递数据
Vue-cli
工具,创建Vue项目的工具,脚手架
vue create 项目名
Axios
代替Ajax,网页中实现后端接口调用 $axios.get(“”).then(function(xx){})
Vant
基于Vue封装的移动端组件库
https://vant-contrib.gitee.io/vant/#/zh-CN/home
整理:
https://zhuanlan.zhihu.com/p/97902016
- 谈谈你理解的 Hashtable,讲讲其中的 get put 过程。ConcurrentHashMap同问。
- 1.8 做了什么优化?
- 线程安全怎么做的?
- 不安全会导致哪些问题?
- 如何解决?有没有线程安全的并发容器?
- ConcurrentHashMap 是如何实现的?
- ConcurrentHashMap并发度为啥好这么多?
- 1.7、1.8 实现有何不同?为什么这么做?
- CAS是啥?
- ABA是啥?场景有哪些,怎么解决?
- synchronized底层原理是啥?
- synchronized锁升级策略
- 快速失败(fail—fast)是啥,应用场景有哪些?安全失败(fail—safe)同问

若有收获,就点个赞吧
0 人点赞
