- 1、乐观锁
- 2、悲观锁
- 3、自旋锁
- 4、可重入锁
- 5、读写锁
- 6、公平锁
- 7、非公平锁
- 8、共享锁
- 9、独占锁
- 10、重量级锁
- 11、轻量级锁
- 11.1、轻量级锁概念
- 11.2、轻量级锁过程
- 1、每次指向到synchronized代码块时,都会创建锁记录(Lock Record)对象,每个线程都会包括一个锁记录的结构,锁记录内部可以储存对象的Mark Word和对象引用reference
- 2、让锁记录中的Object reference指向对象,并且尝试用cas(compare and sweep)替换Object对象的Mark Word ,将Mark Word 的值存入锁记录中
- 3、如果cas替换成功,那么对象的对象头储存的就是锁记录的地址和状态01,如下所示
- 4、如果cas失败,有两种情况
- 5、当线程退出synchronized代码块的时候,如果获取的是取值为 null 的锁记录 ,表示有重入,这时重置锁记录,表示重入计数减1
- 6、当线程退出synchronized代码块的时候,如果获取的锁记录取值不为 null,那么使用cas将Mark Word的值恢复给对象
- 无锁状态获取锁
- 重入锁
- 非重入锁
- 非重入释放锁
- 重入释放锁
- 11.3、锁膨胀(重量级锁)
- 11.4、底层分析
- 12、偏向锁
- 13、分段锁
- 14、互斥锁
- 15、同步锁
- 16、死锁
- 17、锁粗化
- 18、锁消除
- 19、synchronized
- 20、Lock和synchronize的区别
- 21、ReentrantLock和synchronized的区别
1、乐观锁
1.1、什么是乐观锁?
乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。乐观锁适用于读多写少的场景,这样可以提高程序的吞吐量。
乐观锁采取了更加宽松的加锁机制。也是为了避免数据库幻读、业务处理时间过长等原因引起数据处理错误的一种机制,但乐观锁不会刻意使用数据库本身的锁机制,而是依据数据本身来保证数据的正确性。
1.2、乐观锁的实现:
- CAS 实现:Java 中java.util.concurrent.atomic包下面的原子变量使用了乐观锁的一种 CAS 实现方式。
- 版本号控制:一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会 +1。当线程 A 要更新数据时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值与当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
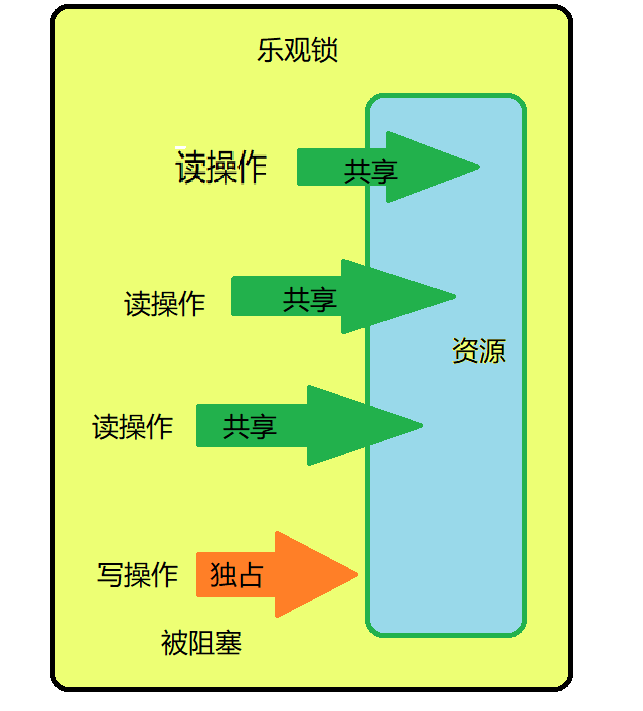
乐观锁是一种乐观思想,假定当前环境是读多写少,遇到并发写的概率比较低,读数据时认为别的线程不会正在进行修改(所以没有上锁)。写数据时,判断当前 与期望值是否相同,如果相同则进行更新(更新期间加锁,保证是原子性的)。
Java中的乐观锁:CAS,比较并替换,比较当前值(主内存中的值),与预期值(当前线程中的值,主内存中值的一份拷贝)是否一样,一样则更新,否则继续进行CAS操作。进行原子性操作是否和期望值一样,自旋操作。
如上图所示,可以同时进行读操作,读的时候其他线程不能进行写操作。
使用场景:
乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。
乐观锁应用在CAS上面:比较并交换的原子性操作上。
1.3、算法实现
介绍CAS算法:
硬件支持的原子性操作最典型的是:比较并交换(Compare-and-Swap,CAS)。 CAS 指令需要有 3 个操作数,分别是内存地址 V、旧的预期值 A 和新值 B。 当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。属于非阻塞算法的实现,轻量级锁。
//著名的CAS//var1是比较值所属的对象,var2需要比较的值(但实际是使用地址偏移量来实现的),//如果var1对象中偏移量为var2处的值等于var4,那么将该处的值设置为var5并返回true,如果不等于var4则返回false。public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);// 这里调用了本地方法 实现比较+替换方法的实现
版本控制算法:
版本控制算法就是在数据库中每个表添加一个version字段每当修改一次数据就修改version版本,修改之前修改乐观锁版本,进入的线程比较版本,不同则取消当前线程的修改。
版本实现算法:
一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version++即可。 当线程A要更新数据值时,在读取数据的同时也会读取version值, 在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新, 否则重试更新操作,直到更新成功。
举个例子:
假设数据库中帐户信息表中有一个 version 字段,并且 version=1;而当前帐户余额字段(balance)为 $100 。
操作员 A 此时将其读出 (version=1),并从其帐户余额中扣除 $50($100-$50)。
操作员 A 操作的同事,操作员B 也读入此用户信息(version=1),并从其帐户余额中扣除 $20($100-$20)。
操作员 A 完成了修改工作,version++(version=2),连同帐户扣除后余额(balance=$50),提交至数据库更新,
此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
操作员 B 完成了操作,也将版本号version++(version=2)试图向数据库提交数据(balance=$80),
但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,
不满足提交版本必须大于记录当前版本才能执行更新的乐观锁策略,因此,操作员 B 的提交被驳回。
1.4、优缺点
优点:
乐观锁机制避免了长 事务 中的数据库加锁开销(操作员 A和操作员 B 操作过程中,都没有对数据库数据加锁),大大提升了大并发量下的系统整体性能表现。
1.4.1、ABA问题
什么是ABA问题?
如果一个变量初次读取的时候是 A 值,它的值被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过。
J.U.C 包提供了一个带有标记的原子引用类 AtomicStampedReference 来解决这个问题, 它可以通过控制变量值的版本来保证 CAS 的正确性。 大部分情况下 ABA 问题不会影响程序并发的正确性, 如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更高效。
1.4.2、自旋时间长开销大
自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销。 如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用, 第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源, 延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。 第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation) 而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
解决方法:可以设置自旋次数就取消自旋
3.只能保证一个共享变量的原子操作 CAS只对单个共享变量有效,当操作涉及跨多个共享变量时CAS无效。 但是从 JDK 1.5开始,提供了AtomicReference类来保证引用对象之间的原子性, 可以把多个变量封装成对象里来进行 CAS 操作. 所以我们可以使用锁或者利用AtomicReference类把多个共享变量封装成一个共享变量来操作。
1.5、CAS与synchronized的使用场景
对于资源竞争较少(线程冲突较轻)的情况, 使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源; 而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。使用重量级锁进行阻塞线程会增加cpu的消耗,自旋会更快获取资源,提升性能。
对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大, 从而浪费更多的CPU资源,效率低于synchronized。
2、悲观锁
2.1、什么是悲观锁?
顾名思义,就是比较悲观的锁,总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。悲观锁中的共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程
当要对数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加锁以防止并发。这种借助数据库锁机制,在修改数据之前先锁定,再修改的方式被称之为悲观并发控制【Pessimistic Concurrency Control,缩写“PCC”,又名“悲观锁”】。
悲观锁,具有强烈的独占和排他特性。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度。因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
 ‘
‘
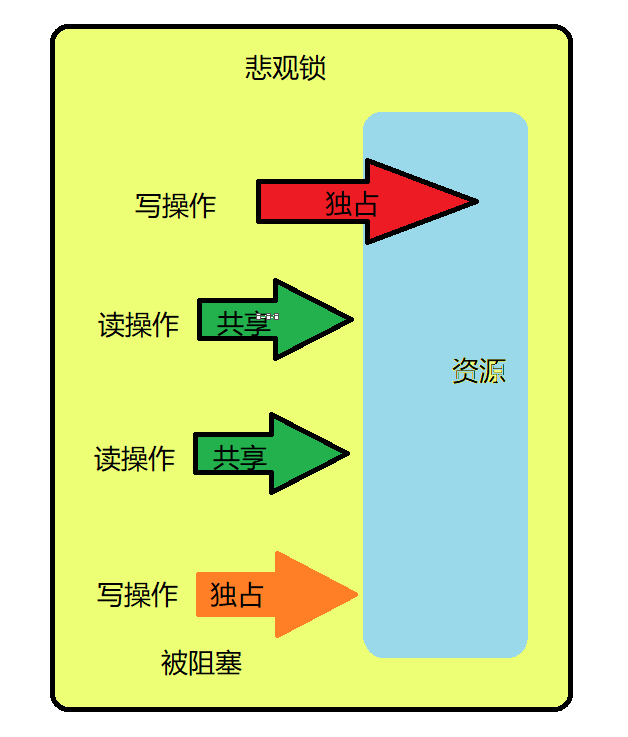
悲观锁是一种悲观思想,即认为写多读少,遇到并发写的可能性高,每次去拿数据的时候都认为其他线程会修改,所以每次读写数据都会认为其他线程会修改,所以每次读写数据时都会上锁。其他线程想要读写这个数据时,会被这个线程block,直到这个线程释放锁然后其他线程获取到锁。 就是相当于重量级锁,进行阻塞线程。
Java中的悲观锁:synchronized修饰的方法和方法块、ReentrantLock。
如上图所示,只能有一个线程进行读操作或者写操作,其他线程的读写操作均不能进行
悲观锁的使用场景:
因此一般我们可以在并发量不是很大,并且出现并发情况导致的异常用户和系统都很难以接受的情况下,会选择悲观锁进行。通常是写多读少的场景使用较多。
2.2、悲观锁分类
悲观锁主要分为共享锁和排他锁:
- 共享锁【shared locks】又称为读锁,简称 S 锁。顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
- 排他锁【exclusive locks】又称为写锁,简称 X 锁。顾名思义,排他锁就是不能与其他锁并存,如果一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁。获取排他锁的事务可以对数据行读取和修改。
2.3、算法实现
有用户A和用户B,在同一家店铺去购买同一个商品,但是商品的可购买数量只有一个
在不加锁的情况下,如果用户A和用户B同时下单,就会报错。
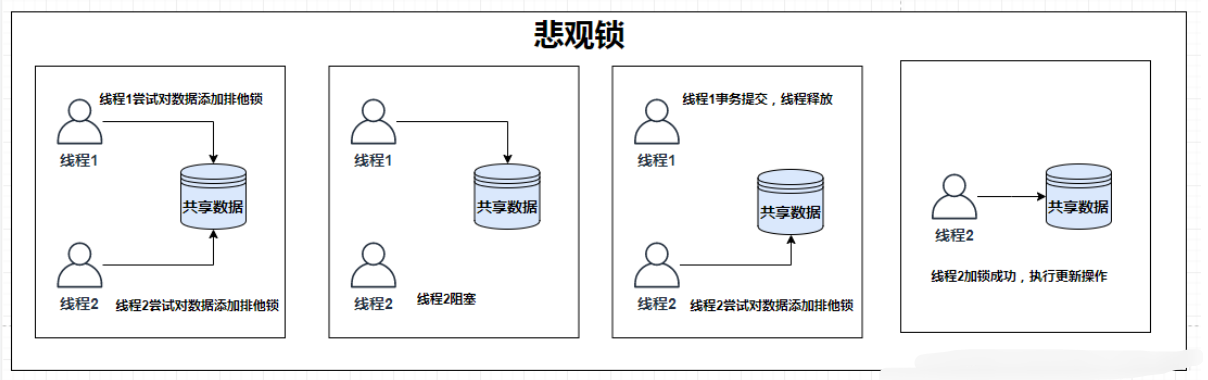
悲观锁的实现,往往依靠数据库提供的锁机制,在数据库中,我们如何用悲观锁去解决这个事情呢?
- 加入当用户A对下单购买商品(臭豆腐)的时候,先去尝试对该数据(臭豆腐)加上悲观锁
- 加锁失败:说明商品(臭豆腐)正在被其他事务进行修改,当前查询需要等待或者抛出异常,具体返回的方式需要由开发者根据具体情况去定义
- 加锁成功:对商品(臭豆腐)进行修改,也就是只有用户A能买,用户B想买(臭豆腐)就必须一直等待(阻塞)。当用户A买好后,用户B再想去买(臭豆腐)的时候会发现数量已经为0,那么B看到后就会放弃购买
- 在此期间如果有其他对该数据(臭豆腐)做修改或加锁的操作,都会等待我们解锁后或者直接抛出异常
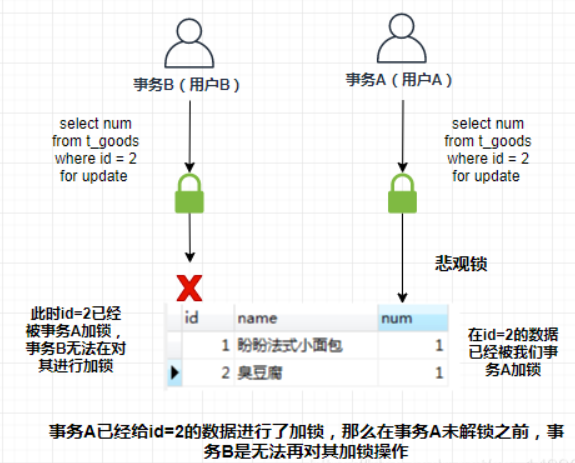
那么如何加上悲观锁呢?我们可以通过以下语句给id=2的这行数据加上悲观锁,首先关闭MySQL数据库的自动提交属性。因为MySQL默认使用autocommit模式,也就是说,当我们执行一个更新操作后,MySQL会立刻将结果进行提交,(sql语句:set autocommit=0)
悲观锁加锁sql语句: select num from t_goods where id = 2 for update
我们通过开启mysql的两个会话,也就是两个命令行来演示:
事务A:
我们可以看到数据是立刻马上就可以查询出来,num=1
事务B:
我们是可以看到,事务B会一直等待事务A释放锁。如果事务A长期不释放锁,那么最终事务B将会报错,报错如下:Lock wait timeout exceeded; try restarting transaction,表示语句已被锁住
2.4、优缺点
优点:
悲观并发控制采取的是保守策略:“先取锁,成功了才访问数据”,这保证了数据获取和修改都是有序进行的,因此适合在写多读少的环境中使用。当然使用悲观锁无法维持非常高的性能,但是在乐观锁也无法提供更好的性能前提下,悲观锁却可以做到保证数据的安全性。
缺点:
由于需要加锁,而且可能面临锁冲突甚至死锁的问题,悲观并发控制增加了系统的额外开销,降低了系统的效率,同时也会降低了系统的并行性。
2.5、应用场景实现
2.5.1、synchronized
1、内存可见性
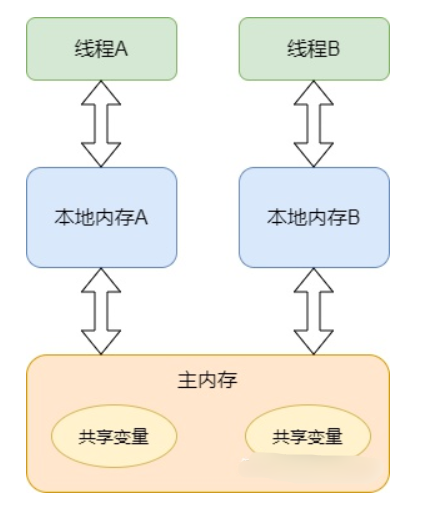
这里的本地内存并不是真实存在的,只是 Java 内存模型的一个抽象概念,它包含了控制器、运算器、缓存等。同时 Java 内存模型规定,线程对共享变量的操作必须在自己的本地内存中进行,不能直接在主内存中操作共享变量。这种内存模型会出现什么问题呢?
线程 A 获取到共享变量 X 的值,此时本地内存 A 中没有 X 的值,所以加载主内存中的 X 值并缓存到本地内存 A 中,线程 A 修改 X 的值为 1,并将 X 的值刷新到主内存中,这时主内存及本地内存中的 X 的值都为 1
线程 B 需要获取共享变量 X 的值,此时本地内存 B 中没有 X 的值,加载主内存中的 X 值并缓存到本地内存 B 中,此时 X 的值为 1。线程 B 修改 X 的值为 2,并刷新到主内存中,此时主内存及本地内存 B 中的 X 值为 2,本地内存 A 中的 X 值为 1
线程 A 再次获取共享变量 X 的值,此时本地内存中存在 X 的值,所以直接从本地内存中 A 获取到了 X 为 1 的值,但此时主内存中 X 的值为 2,到此出现了所谓内存不可见的问题
该问题 Java 内存模型是通过 synchronized 关键字和 volatile 关键字就可以解决,那么 synchronized 关键字是如何解决的呢,其实进入 synchronized 块就是把在 synchronized 块内使用到的变量从线程的本地内存中擦除,这样在 synchronized 块中再次使用到该变量就不能从本地内存中获取了,需要从主内存中获取,解决了内存不可见问题。
2、synchronized的特征
圈内经常拿 synchronized 关键字和 volatile 关键字的特性进行对比,synchronized 关键字可以保证并发编程的三大特性:原子性、可见性、有序性,而 volatile 关键字只能保证可见性和有序性,不能保证原子性,也称为是轻量级的 synchronized。
- 原子性:一个或多个操作要么全部执行成功,要么全部执行失败。synchronized 关键字可以保证只有一个线程拿到锁,访问共享资源
- 可见性:当一个线程对共享变量进行修改后,其他线程可以立刻看到。执行 synchronized 时,会对应执行 lock、unlock 原子操作,保证可见性
- 有序性:程序的执行顺序会按照代码的先后顺序执行
这里聊到了volatile关键字的使用 这里来介绍一个volatile关键字的含义
volatile是什么?
volatile在java语言中是一个关键字,用于修饰变量。被volatile修饰的变量后,表示这个变量在不同线程中是共享,编译器与运行时都会注意到这个变量是共享的,因此不会对该变量进行重排序。上面这句话可能不好理解,但是存在两个关键,共享和重排序。
变量的共享:
先来看一个被举烂了的例子:
public class VolatileTest {boolean isStop = false;public void test() {Thread t1 = new Thread() {@Overridepublic void run() {isStop = true;}};Thread t2 = new Thread() {@Overridepublic void run() {while (!isStop) {}}};t2.start();t1.start();}public static void main(String args[]) throws InterruptedException {new VolatileTest().test();}}
上面的代码是一种典型用法,检查某个标记(isStop)的状态判断是否退出循环。但是上面的代码有可能会结束,也可能永远不会结束。因为每一个线程都拥有自己的工作内存,当一个线程读取变量的时候,会把变量在自己内存中拷贝一份。之后访问该变量的时候都通过访问线程的工作内存,如果修改该变量,则将工作内存中的变量修改,然后再更新到主存上。这种机制让程序可以更快的运行,然而也会遇到像上述例子这样的情况。
存在一种情况,isStop变量被分别拷贝到t1、t2两个线程中,此时isStop为false。t2开始循环,t1修改本地isStop变量称为true,并将isStop=true回写到主存,但是isStop已经在t2线程中拷贝过一份,t2循环时候读取的是t2 工作内存中的isStop变量,而这个isStop始终是false,程序死循环。我们称t2对t1更新isStop变量的行为是不可见的。就是目前的isStop变量是之前拷贝的,另外线程修改本线程不会获取到修改后的值。
如果isStop变量通过volatile进行修饰,t2修改isStop变量后,会立即将变量回写到主存中,并将t1里的isStop失效。t1发现自己变量失效后,会重新去主存中访问isStop变量,而此时的isStop变量已经变成true。循环退出。volatile boolean isStop = false;
volatile如何使用
volatile关键字一般用于标记变量的修饰,类似上述例子。《Java并发编程实战》中说,volatile只保证可见性,而加锁机制既可以确保可见性又可以确保原子性。当且仅当满足以下条件下,才应该使用volatile变量:
1、对变量的写入操作不依赖变量的当前值,或者确保只有单个线程变更变量的值。
2、该变量不会于其他状态一起纳入不变性条件中
3、在访问变量的时候不需要加锁。
逐一分析:
第一条说明volatile不能作为多线程中的计数器,计数器的count++操作,分为三步,第一步先读取count的数值,第二步count+1,第三步将count+1的结果写入count。volatile不能保证操作的原子性。上述的三步操作中,如果有其他线程对count进行操作,就可能导致数据出错。
public class VolatileTest {private volatile int lower = 0;private volatile int upper = 5;public int getLower() {return lower;}public int getUpper() {return upper;}public void setLower(int lower) {if (lower > upper) {return;}this.lower = lower;}public void setUpper(int upper) {if (upper < lower) {return;}this.upper = upper;}}
述程序中,lower初始为0,upper初始为5,并且upper和lower都用volatile修饰。我们期望不管怎么修改upper或者lower,都能保证upper>lower恒成立。然而如果同时有两个线程,t1调用setLower,t2调用setUpper,两线程同时执行的时候。有可能会产生upper<lower这种不期望的结果。
public void test() {Thread t1 = new Thread() {@Overridepublic void run() {try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}setLower(4);}};Thread t2 = new Thread() {@Overridepublic void run() {try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}setUpper(3);}};t1.start();t2.start();while (t1.isAlive() || t2.isAlive()) {}System.out.println("(low:" + getLower() + ",upper:" + getUpper() + ")");}public static void main(String args[]) throws InterruptedException {for (int i = 0; i < 100; i++) {VolatileTest volaitil = new VolatileTest();volaitil.test();}}

此时程序一直正常运行,但是出现的结果却是我们不想要的。
第三条:当访问一个变量需要加锁时,一般认为这个变量需要保证原子性和可见性,而volatile关键字只能保证变量的可见性,无法保证原子性。
最后贴个volatile的常见例子,在单例模式双重检查中的使用:
public class Singleton {private static volatile Singleton instance=null;private Singleton(){}public static Singleton getInstance(){if(instance==null){synchronized(Singleton.class){if(instance==null){instance=new Singleton();}}}return instance;}}
new Singleton()分为三步,1、分配内存空间,2、初始化对象,3、设置instance指向被分配的地址。然而指令的重新排序,可能优化指令为1、3、2的顺序。如果是单个线程访问,不会有任何问题。但是如果两个线程同时获取getInstance,其中一个线程执行完1和3步骤,此时其他的线程可以获取到instance的地址,在进行if(instance==null)时,判断出来的结果为false,导致其他线程直接获取到了一个未进行初始化的instance,这可能导致程序的出错。所以用volatile修饰instance,禁止指令的重排序,保证程序能正常运行。(Bug很难出现,没能模拟出来)。
然而,《java并发编程实战中》中有对DCL的描述如下:”DCL的这种使用方法已经被广泛废弃了——促使该模式出现的驱动力(无竞争同步的执行速度很慢,以及JVM启动很慢)已经不复存在了,因而它不是一种高效的优化措施。延迟初始化占位类模式能带来同样的优势,并且更容易理解。”,其实我个小码畜的角度来看,服务端的单例更多时候做延迟初始化并没有很大意义,延迟初始化一般用来针对高开销的操作,并且被延迟初始化的对象都是不需要马上使用到的。然而,服务端的单例在大部分的时候,被设计为单例的类大部分都会被系统很快访问到。本篇文章只是讨论volatile,并不针对设计模式进行讨论,因此后续有时间,再补上替代上述单例的写法。
3、实现什么类型的锁
- 悲观锁:synchronized 关键字实现的是悲观锁,每次访问共享资源时都会上锁
- 非公平锁:synchronized 关键字实现的是非公平锁,即线程获取锁的顺序并不一定是按照线程阻塞的顺序
- 可重入锁:synchronized 关键字实现的是可重入锁,即已经获取锁的线程可以再次获取锁
- 独占锁或者排他锁:synchronized 关键字实现的是独占锁,即该锁只能被一个线程所持有,其他线程均被阻塞
4、底层原理
synchronized 底层原理是比较难理解的,理解 synchronized 需要一定的 Java 虚拟机的知识。
在 jdk1.6 之前,synchronized 被称为重量级锁,在 jdk1.6 中,为了减少获得锁和释放锁带来的性能开销,引入了偏向锁和轻量级锁。下面先介绍 jdk1.6 之前的 synchronized 原理。
1)、对象头
我们知道,Java 对象保存在堆内存中。一个 Java 对象包含三部分:对象头、实例数据和对齐填充。其中对象头是一个很关键的部分,因为对象头中包含锁状态标志、线程持有的锁等标志。
synchronized 是悲观锁,在操作同步资源之前需要给同步资源先加锁,这把锁就是存在 Java 对象头里的,而 Java 对象头又是什么呢?
每一个 Java 类,在被 JVM 加载的时候,JVM 会给这个类创建一个 instanceKlass,保存在方法区,用来在 JVM 层表示该 Java 类。当我们在 Java 代码中,使用 new 创建一个对象的时候,JVM 会创建一个 instanceOopDesc 对象,这个对象中包含了对象头以及实例数据。
我们以 Hotspot 虚拟机为例,Hotspot 的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)
Mark Word: 默认存储对象的 HashCode,分代年龄和锁标志位信息。Mark Word 用于存储对象自身的运行时数据,所以 Mark Word 被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间 Mark Word 里存储的数据会随着锁标志位的变化而变化。
Klass Point: 对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
重量级锁的底部实现原理是Monitor ,jdk1.6之前只能实现重量级锁,基于Monitor对象来实现重量级锁,底层原理是由C++编写。
jdk1.6之后synchronized进行优化 进行锁升级。
在 JDK1.6 中,为了减少获得锁和释放锁带来的性能消耗,引入了偏向锁和轻量级锁,锁的状态变成了四种,如下图所示。锁的状态会随着竞争激烈逐渐升级,但通常情况下,锁的状态只能升级不能降级。这种只能升级不能降级的策略是为了提高获得锁和释放锁的效率。
常见问题汇总:
1、了解锁消除吗?
锁消除是指 Java 虚拟机在即时编译时,通过对运行上下的扫描,消除那些不可能存在共享资源竞争的锁。锁消除可以节约无意义的请求锁时间。
2、了解锁粗化吗?
一般情况下,为了提高性能,总是将同步块的作用范围限制到最小,这样可以使得需要同步的操作尽可能地少。但如果一系列连续的操作一直对某个对象反复加锁和解锁,频繁地进行互斥同步操作也会引起不必要的性能消耗。
如果虚拟机检测到有一系列操作都是对某个对象反复加锁和解锁,会将加锁同步的范围粗化到整个操作序列的外部。可以看下面这个经典案例。
for(int i=0;i<n;i++){synchronized(lock){}}
这段代码会导致频繁地加锁和解锁,锁粗化后
synchronized(lock){for(int i=0;i<n;i++){}}
3、当线程 1 进入到一个对象的 synchronized 方法 A 后,线程 2 是否可以进入到此对象的 synchronized 方法 B?
不能,线程 2 只能访问该对象的非同步方法。因为执行同步方法时需要获得对象的锁,而线程 1 在进入 sychronized 修饰的方 A 时已经获取到了锁,线程 2 只能等待,无法进入到 synchronized 修饰的方法 B,但可以进入到其他非 synchronized 修饰的方法。
4、synchronized 和 volatile 的区别?
- volatile 主要是保证内存的可见性,即变量在寄存器中的内存是不确定的,需要从主存中读取。synchronized 主要是解决多个线程访问资源的同步性
- volatile 作用于变量,synchronized 作用于代码块或者方法
- volatile 仅可以保证数据的可见性,不能保证数据的原子性。synchronized 可以保证数据的可见性和原子性
- volatile 不会造成线程的阻塞,synchronized 会造成线程的阻塞
5、synchronized 和 Lock 的区别?
- Lock 是显示锁,需要手动开启和关闭。synchronized 是隐士锁,可以自动释放锁
- Lock 是一个接口,是 JDK 实现的。synchronized 是一个关键字,是依赖 JVM 实现的
- Lock 是可中断锁,synchronized 是不可中断锁,需要线程执行完才能释放锁
- 发生异常时,Lock 不会主动释放占有的锁,必须通过 unloc k进行手动释放,因此可能引发死锁。synchronized 在发生异常时会自动释放占有的锁,不会出现死锁的情况
- Lock 可以判断锁的状态,synchronized 不可以判断锁的状态
- Lock 实现锁的类型是可重入锁、公平锁。synchronized 实现锁的类型是可重入锁,非公平锁
- Lock 适用于大量同步代码块的场景,synchronized 适用于少量同步代码块的场景
2.5.2、Vector
Vector的一些方法实现了synchronized的方法实现。
这里查找一些方法
/*** 通过index获取容器中的元素(此方法用虽不会修改容器,不过还是用synchronized修饰了,同步方法,this对象锁,防止读到不是最新的数据)*/public synchronized E get(int index) {// 检查是否超出最后一个元素的边界(注意这里的边界检查并不是检查下标是否超过数组的长度)if (index >= elementCount)throw new ArrayIndexOutOfBoundsException(index);// 下标合法则调用elementData方法获取元素return elementData(index);}@SuppressWarnings("unchecked")E elementData(int index) {return (E) elementData[index];}
方法实现了synchronized的方法锁,不能同时操作,线程安全。
2.5.3、HashTable
这里直接赋值源码就可以理解
public synchronized V put(K key, V value) {// Make sure the value is not nullif (value == null) {throw new NullPointerException();}// Makes sure the key is not already in the hashtable.Entry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;@SuppressWarnings("unchecked")Entry<K,V> entry = (Entry<K,V>)tab[index];for(; entry != null ; entry = entry.next) {if ((entry.hash == hash) && entry.key.equals(key)) {V old = entry.value;entry.value = value;return old;}}addEntry(hash, key, value, index);return null;}public synchronized V get(Object key) {Entry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {if ((e.hash == hash) && e.key.equals(key)) {return (V)e.value;}}return null;}
都实现了synchronized的方法锁安全,使其线程安全。
3、自旋锁
3.1、自旋锁的概率
自旋锁(spinlock):是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。
获取锁的线程一直处于活跃状态,但是并没有执行任何有效的任务,使用这种锁会造成busy-waiting。
它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,”自旋”一词就是因此而得名。
在获取锁的过程中,线程一直处于活跃状态。因此与mutex不同,spinlock不会导致线程的状态切换(用户态->内核态),一直处于用户态,即线程一直都是active的;不会使线程进入阻塞状态,减少了不必要的上下文切换,执行速度快。
由于自旋时不释放CPU,如果持有自旋锁的线程一直不释放自旋锁,那么等待该自旋锁的线程会一直浪费CPU时间。因此,自旋锁主要适用于被持有时间短,线程不希望在重新调度上花过多时间的情况。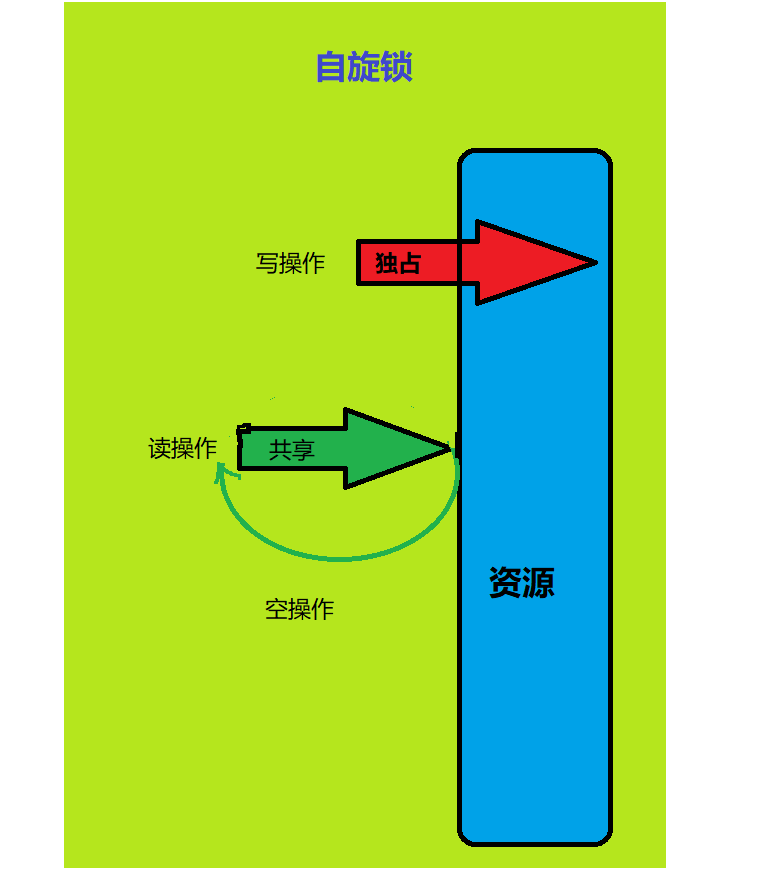
自旋锁是一种技术: 为了让线程等待,我们只须让线程执行一个忙循环(自旋)。 现在绝大多数的个人电脑和服务器都是多路(核)处理器系统,如果物理机器有一个以上的处理器或者处理器核心,能让两个或以上的线程同时并行执行,就可以让后面请求锁的那个线程“稍等一会”,但不放弃处理器的执行时间,看看持有锁的线程是否很快就会释放锁。
自旋次数默认值:10次,可以使用参数-XX:PreBlockSpin来自行更改。自适应自旋: 自适应意味着自旋的时间不再是固定的,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定的。有了自适应自旋,随着程序运行时间的增长及性能监控信息的不断完善,虚拟机对程序锁的状态预测就会越来越精准。
Java中的自旋锁: CAS操作中的比较操作失败后的自旋等待
自旋和非自旋之间获取锁的流程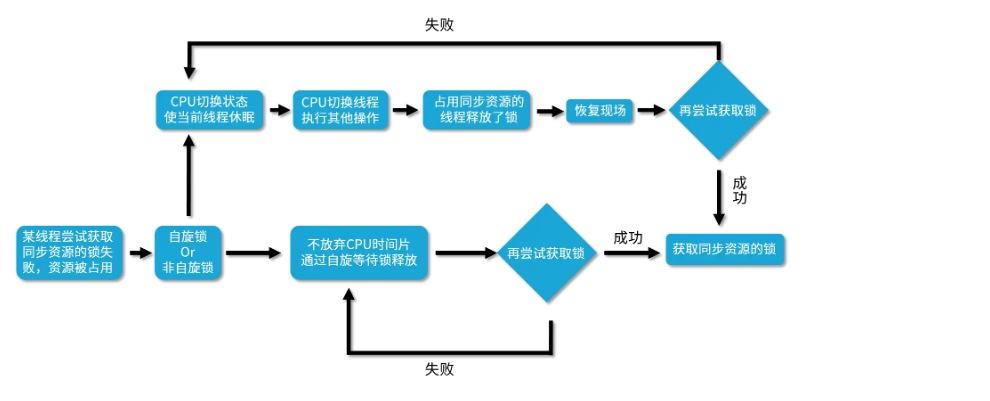
可以看出,非自旋锁和自旋锁最大的区别,就是如果它遇到拿不到锁的情况,它会把线程阻塞,直到被唤醒。而自旋锁会不停地尝试。
3.2、自旋锁的实现
根据自旋锁的原理,我们先尝试写出伪代码实现:
//循环检查锁状态,并尝试获取,直到成功while (true):locked = get_lock()if locked == false:locked = truebreak//上锁后执行相关任务do_something//执行完毕,释放锁locked = false
细心的同学可以发现上面的逻辑在并发场景会遇到问题:两个线程可能会同时进入if语句,同时获取锁,导致锁不生效。
如何解决这个问题?我们可以把查询锁(get_lock)和设置锁(locked=true)组合成一个原子操作,保证同一时间只有一个线程在执行。如下所示:get_and_set就是CAS操作。
//这里get_and_set(locked)就是一个原子操作,执行成功后把locked设置成true。while (get_and_set(locked) == false):continuedo_somethinglocked = false
如此,就实现了一个简单的自旋锁。
那么现在的问题是如何实现get_and_set(locked)这个原子操作?这里有两个常用的方法可以使用:TAS(test and set)和CAS (compare and swap)。
- TAS:一个TAS指令包括两个子步骤,把给定的内存地址设置为1,然后返回之前的旧值。
- CAS:CAS指令需要三个参数,一个内存位置(V)、一个期望旧值(A)、一个新值(B)。过程如下:a. 比较内存V的值是否与A相等?
b. 如果相等,则用新值B替换内存位置V的旧值
c. 如果不相等,不做任何操作。
d. 无论哪个情况,CAS都会把内存V原来的值返回。
很多语言都提供了封装后的TAS和CAS调用方法。
先看一个实现自旋锁的例子,java.util.concurrent包里提供了很多面向并发编程的类. 使用这些类在多核CPU的机器上会有比较好的性能.主要原因是这些类里面大多使用(失败-重试方式的)乐观锁而不是synchronized方式的悲观锁.
class spinlock {private AtomicReference<Thread> cas;spinlock(AtomicReference<Thread> cas){this.cas = cas;}public void lock() {Thread current = Thread.currentThread();// 利用CASwhile (!cas.compareAndSet(null, current)) { //为什么预期是null??// DO nothingSystem.out.println("I am spinning");}}public void unlock() {Thread current = Thread.currentThread();cas.compareAndSet(current, null);}}// 利用CAS来实现原则操作 自旋锁实现操作
lock()方法利用的CAS,当第一个线程A获取锁的时候,能够成功获取到,不会进入while循环,如果此时线程A没有释放锁,另一个线程B又来获取锁,此时由于不满足CAS,所以就会进入while循环,不断判断是否满足CAS,直到A线程调用unlock方法释放了该锁。
这里来看一个例子实现自旋锁的:
public class 自旋锁 {public static void main(String[] args) {AtomicReference<Thread> cas = new AtomicReference<Thread>();Thread thread1 = new Thread(new Task(cas));Thread thread2 = new Thread(new Task(cas));thread1.start();thread2.start();}}//自旋锁验证class Task implements Runnable {// 利用cas实现原子操作private AtomicReference<Thread> cas;// 自旋锁private spinlock slock ;public Task(AtomicReference<Thread> cas) {this.cas = cas;this.slock = new spinlock(cas);}@Overridepublic void run() {slock.lock(); //上锁for (int i = 0; i < 10; i++) {//Thread.yield();System.out.println(i);}slock.unlock();}}
/*** @discription 实现一个可重入的自旋锁*/public class ReentrantSpinLock {private AtomicReference<Thread> owner = new AtomicReference<>();// 重入次数private int count = 0;public static void main(String[] args) {ReentrantSpinLock spinLock = new ReentrantSpinLock();Runnable runnable = new Runnable() {@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + "开始尝试获取自旋锁");spinLock.lock();try{System.out.println(Thread.currentThread().getName() + "获取到了自旋锁");Thread.sleep(1);} catch (InterruptedException e) {e.printStackTrace();} finally {spinLock.unlock();System.out.println(Thread.currentThread().getName() + "释放了了自旋锁");}}};Thread thread1 = new Thread(runnable);Thread thread2 = new Thread(runnable);thread1.start();thread2.start();}public void lock(){Thread thread = Thread.currentThread();if(thread == owner.get()){++count;return;}//自旋获取锁while (!owner.compareAndSet(null,thread)){System.out.println("自旋了");}}public void unlock(){Thread thread = Thread.currentThread();//只有持有锁的线程才能解锁if(thread == owner.get()){if(count > 0){--count;}else {//此处无需CAS操作,因为没有竞争,因为只有线程持有者才能解锁owner.set(null);}}}}
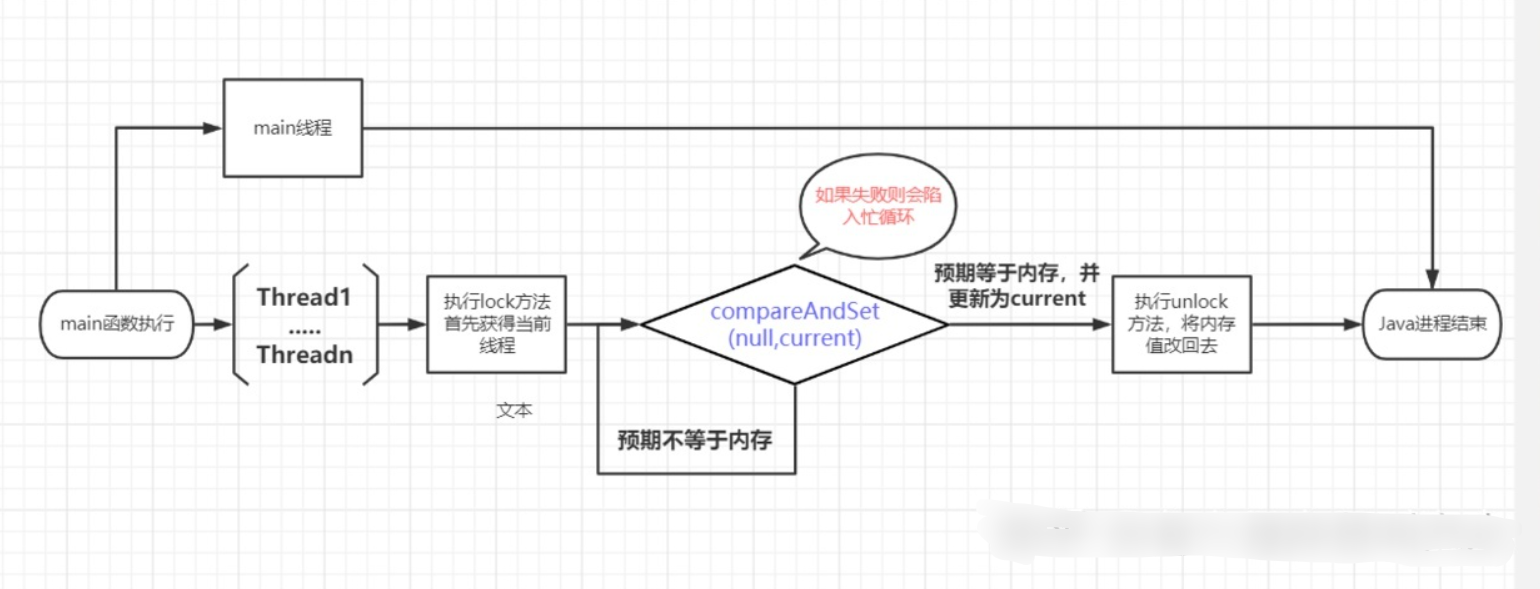
这里获取了锁另外的线程进行自旋操作,判断获取锁线程是否释放锁(主要是通过内存的不同值来实现判断)
3.3、自旋锁的优缺点
自旋锁的优点: 避免了线程切换的开销。挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作给Java虚拟机的并发性能带来了很大的压力。 线程一直是active的状态,不会使线程进入阻塞状态,不需要进入上下文的切换,执行速度快。
自旋锁的缺点: 占用处理器的时间,如果占用的时间很长,会白白消耗处理器资源,而不会做任何有价值的工作,带来性能的浪费。因此自旋等待的时间必须有一定的限度,如果自旋超过了限定的次数仍然没有成功获得锁,就应当使用传统的方式去挂起线程。 所以自旋锁一般有一个默认的自旋次数为10。
3.4、可重入的自旋锁和不可重入的自旋锁
文章开始的时候的那段代码,仔细分析一下就可以看出,它是不支持重入的,即当一个线程第一次已经获取到了该锁,在锁释放之前又一次重新获取该锁,第二次就不能成功获取到。由于不满足CAS,所以第二次获取会进入while循环等待,而如果是可重入锁,第二次也是应该能够成功获取到的。
而且,即使第二次能够成功获取,那么当第一次释放锁的时候,第二次获取到的锁也会被释放,而这是不合理的。
例如将代码改成如下:
@Overridepublic void run() {slock.lock(); //上锁slock.lock(); //再次获取自己的锁!由于不可重入,则会陷入循环for (int i = 0; i < 10; i++) {//Thread.yield();System.out.println(i);}slock.unlock();}
则运行结果将会无限打印,陷入无终止的循环!
为了实现可重入锁,我们需要引入一个计数器,用来记录获取锁的线程数。
public class ReentrantSpinLock {private AtomicReference<Thread> cas = new AtomicReference<Thread>();private int count;public void lock() {Thread current = Thread.currentThread();if (current == cas.get()) { // 如果当前线程已经获取到了锁,线程数增加一,然后返回count++;return;}// 如果没获取到锁,则通过CAS自旋while (!cas.compareAndSet(null, current)) {// DO nothing}}public void unlock() {Thread cur = Thread.currentThread();if (cur == cas.get()) {if (count > 0) {// 如果大于0,表示当前线程多次获取了该锁,释放锁通过count减一来模拟count--;} else {// 如果count==0,可以将锁释放,这样就能保证获取锁的次数与释放锁的次数是一致的了。cas.compareAndSet(cur, null);}}}}
这里就实现了可重入锁然后你加锁次数同时也需要你解锁次数。
//可重入自旋锁验证class Task1 implements Runnable{private AtomicReference<Thread> cas;private ReentrantSpinLock slock ;public Task1(AtomicReference<Thread> cas) {this.cas = cas;this.slock = new ReentrantSpinLock(cas);}@Overridepublic void run() {slock.lock(); //上锁slock.lock(); //再次获取自己的锁!没问题!for (int i = 0; i < 10; i++) {//Thread.yield();System.out.println(i);}slock.unlock(); //释放一层,但此时count为1,不为零,导致另一个线程依然处于忙循环状态,所以加锁和解锁一定要对应上,避免出现另一个线程永远拿不到锁的情况slock.unlock();}}
3.5、总结
- 自旋锁:线程获取锁的时候,如果锁被其他线程持有,则当前线程将循环等待,直到获取到锁。
- 自旋锁等待期间,线程的状态不会改变,线程一直是用户态并且是活动的(active)。
- 自旋锁如果持有锁的时间太长,则会导致其它等待获取锁的线程耗尽CPU。
- 自旋锁本身无法保证公平性,同时也无法保证可重入性。
-
4、可重入锁
4.1、什么是可重入锁?
同一个线程可以重入上锁的代码段,不同的线程则需要进行阻塞
- Java的可重入锁有:ReentrantLock(显式的可重入锁)、synchronized(隐式的可重入锁)
- 可重入锁的最大作用是避免死锁
- 同步锁可以再次进入(同一个线程)
synchronized 是隐式锁,Lock是显式锁
即synchronized 加锁解锁自动完成
Lock加锁解锁要手动完成
就比如锁方法A上锁lock而方法B也上锁lock,并且在方法A中调用方法B,不会出现死锁的情况,因为它们处于同一个线程用的是同一把锁,所以可重入锁运行再次进入。也可以叫递归锁。
可重入,即一个线程可以多次(重复)进入同类型的锁而不出现异常(死锁),这里的死锁:自己等待自己释放再获取,所以无限循环。相当于如果不同方法用同一个锁,但是线程还是同一个线程的话,会造成死锁,,如果实现可重入锁的话就不会出现死锁。只需要加锁和解锁的次数相同就行。
如:同一线程,执行逻辑中,嵌套获执行多个synchronized代码块或者嵌套执行ReentrantLock代码块。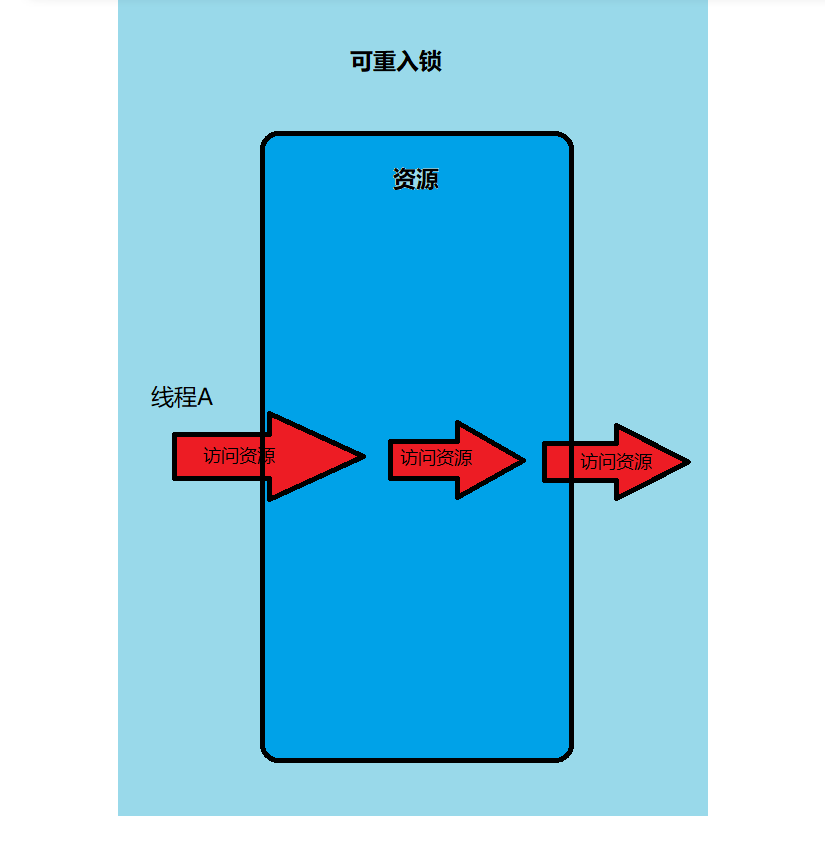
为什么需要死锁:最大程度避免死锁。
可重入锁是一种技术: 任意线程在获取到锁之后能够再次获取该锁而不会被锁所阻塞。
可重入锁的原理: 通过组合自定义同步器来实现锁的获取与释放。
再次获取锁:识别获取锁的线程是否为当前占据锁的线程,如果是,则再次成功获取。获取锁后,进行计数自增,释放锁:释放锁时,进行计数自减。
Java中的可重入锁: ReentrantLock、synchronized修饰的方法或代码段。
可重入锁的作用: 避免死锁。
4.2、可重入锁的实现
synchronized的可重入锁的实现方式。
package com.test.reen;// 演示可重入锁是什么意思,可重入,就是可以重复获取相同的锁,synchronized和ReentrantLock都是可重入的// 可重入降低了编程复杂性public class WhatReentrant {public static void main(String[] args) {new Thread(new Runnable() {@Overridepublic void run() {synchronized (this) {System.out.println("第1次获取锁,这个锁是:" + this);int index = 1;while (true) {synchronized (this) {// 进行计数System.out.println("第" + (++index) + "次获取锁,这个锁是:" + this);}if (index == 10) {break;}}}}}).start();}}
ReentrantLock锁的实现方式。
package com.test.reen;import java.util.Random;import java.util.concurrent.locks.ReentrantLock;// 演示可重入锁是什么意思public class WhatReentrant2 {public static void main(String[] args) {ReentrantLock lock = new ReentrantLock();new Thread(new Runnable() {@Overridepublic void run() {try {lock.lock();System.out.println("第1次获取锁,这个锁是:" + lock);int index = 1;while (true) {try {lock.lock();System.out.println("第" + (++index) + "次获取锁,这个锁是:" + lock);try {Thread.sleep(new Random().nextInt(200));} catch (InterruptedException e) {e.printStackTrace();}if (index == 10) {break;}} finally {lock.unlock();}}} finally {lock.unlock();}}}).start();}}
其实实现方式很相似,只不过ReentrantLock的锁方法比较多。
ReentrantLock 和 synchronized 不一样,需要手动释放锁,所以使用 ReentrantLock的时候一定要手动释放锁,并且加锁次数和释放次数要一样
以下代码演示,加锁和释放次数不一样导致的死锁
package com.test.reen;import java.util.Random;import java.util.concurrent.locks.ReentrantLock;public class WhatReentrant3 {public static void main(String[] args) {ReentrantLock lock = new ReentrantLock();new Thread(new Runnable() {@Overridepublic void run() {try {lock.lock();System.out.println("第1次获取锁,这个锁是:" + lock);int index = 1;while (true) {try {lock.lock();System.out.println("第" + (++index) + "次获取锁,这个锁是:" + lock);try {Thread.sleep(new Random().nextInt(200));} catch (InterruptedException e) {e.printStackTrace();}if (index == 10) {break;}} finally {// lock.unlock();// 这里故意注释,实现加锁次数和释放次数不一样}}} finally {lock.unlock();}}}).start();new Thread(new Runnable() {@Overridepublic void run() {try {lock.lock();for (int i = 0; i < 20; i++) {System.out.println("threadName:" + Thread.currentThread().getName());try {Thread.sleep(new Random().nextInt(200));} catch (InterruptedException e) {e.printStackTrace();}}} finally {lock.unlock();}}}).start();}}
由于加锁次数和释放次数不一样,第二个线程始终无法获取到锁,导致一直在等待。
稍微改一下,在外层的finally里头释放9次,让加锁和释放次数一样,就没问题了
非重入锁也叫自旋锁。
4.3、ReentrantLock锁
4.3.1、ReentrantLock概述
- 提供了无条件的,可轮询的,定时的以及可中断的锁获取操作
- 加锁和解锁都是显式的
ReentrantLock是Java中常用的锁,属于乐观锁类型,多线程并发情况下。能保证共享数据安全性,线程间有序性
ReentrantLock通过原子操作和阻塞实现锁原理,一般使用lock获取锁,unlock释放锁,
下面说一下锁的基本使用和底层基本实现原理,lock和unlock底层
lock的时候可能被其他线程获得所,那么此线程会阻塞自己,关键原理底层用到Unsafe类的API: CAS和park
4.3.2、底层实现原理
JAVA的java.util.concurrent框架中提供了ReentrantLock类(于JAVA SE 5.0时引入),ReentrantLock实现了lock接口,具体在JDK中的定义如下:
public class ReentrantLock implements Lock, java.io.Serializable {public ReentrantLock() {sync = new NonfairSync();}/*** Creates an instance of {@code ReentrantLock} with the* given fairness policy.** @param fair {@code true} if this lock should use a fair ordering policy*/public ReentrantLock(boolean fair) {sync = fair ? new FairSync() : new NonfairSync();}}
所以该锁可以实现公平所和非公平锁,默认是非公平锁第一步是新建锁对象。由源码可知,ReentrantLock默认情况是非公平锁,即通过NonfairSync创建非公平锁同步对象。
java.util.concurrent.locks.ReentrantLock#ReentrantLock()。
可以通过构造器实现创建公平锁的ReentrantLock可重入锁。
看到一个类首先就需要知道它的构造方法有哪些,ReentrantLock有两个构造方法,一个是无参的ReentrantLock() ;另一个含有布尔参数public ReentrantLock(boolean fair)。后面一个构造函数说明ReentrantLock可以新建公平锁;而Synchronized只能建立非公平锁。
Lock接口的方法
Lock接口中有lock和unlock方法,还有newCondition() 方法,这就是上面说的ReentrantLock里面设置内部Condititon类。由于ReentrantLock实现了Lock接口,因此它必须实现该方法,具体如下:
public Condition newCondition() {return sync.newCondition();}
ReentrantLock主要用到unsafe的CAS和park两个功能实现锁(CAS + park )
多个线程同时操作一个数N,使用原子(CAS)操作,原子操作能保证同一时间只能被一个线程修改,而修改数N成功后,返回true,其他线程修改失败,返回false,
这个原子操作可以定义线程是否拿到锁,返回true代表获取锁,返回false代表为没有拿到锁。 拿到锁的线程,自然是继续执行后续逻辑代码,而没有拿到锁的线程,则调用park,将线程(自己)阻塞。 线程阻塞需要其他线程唤醒,ReentrantLock中用到了链表用于存放等待或者阻塞的线程,每次线程阻塞,先将自己的线程信息放入链表尾部,再阻塞自己;之后需要拿到锁的线程,在调用unlock 释放锁时,从链表中获取阻塞线程,调用unpark 唤醒指定线程
底层实现的双向链表来实现阻塞线程,链表的头结点为空,就是当前获取到锁的线程结点,但是线程部分是在为空声明该线程是出队列,当前获取锁的线程,后面有个第一位排队的结点会判断prev结点是否为空,如果为空的话就会执行自旋判断是否能够获取到锁。
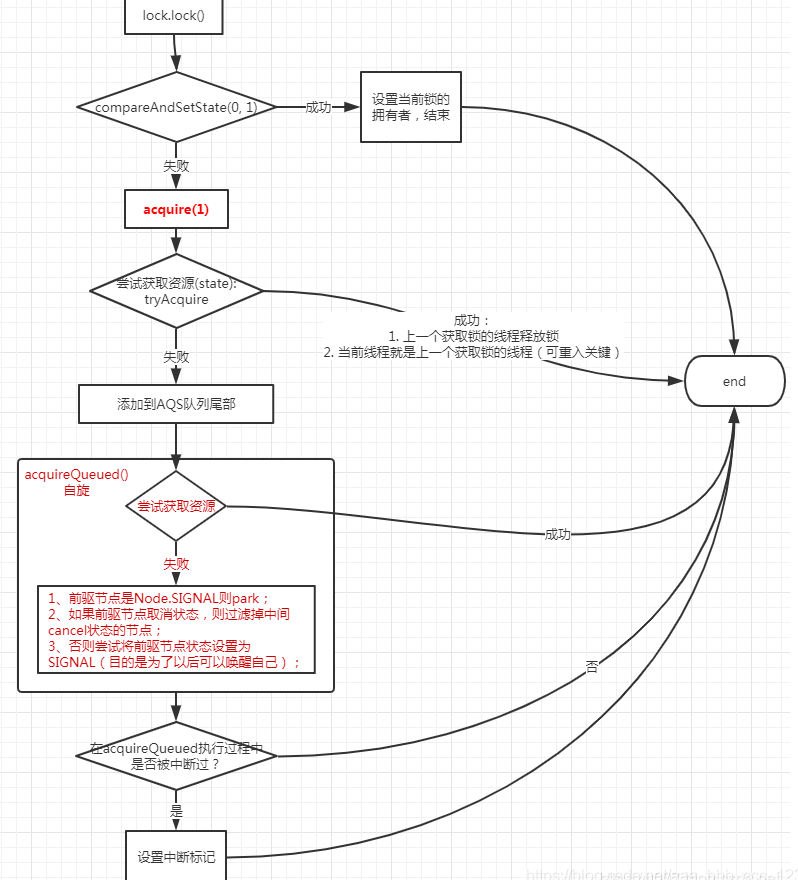
AQS队列
1、非公平锁NonfairSync
java.util.concurrent.locks.ReentrantLock.NonfairSync
通过NonfairSync创建非公平锁对象,NonfairSync继承Sync,实现lock方法,这个lock方法就是可重入锁实现可重入的入口。
由这个lock方法可知,先进入的逻辑是CAS,如果CAS失败,则执行acquire(1),这个acquire是可重入的入口,即通过acquire实现可重入。
重入过程:
(1)线程t1,第一次获取锁x.lock(),CAS成功,嵌套调用,第二次获取锁x.lock()时,CAS失败。
(2)第二次CAS失败后,会执行acquire(1),实现重入。忽略线程中断,并使当前线程持有锁的次数+1,保证逻辑正常执行。
为什么第二次CAS失败:因为第一次已经CAS了,内存数据已经发生了改变,变为1,所以第二次CAS(0,1)时,0≠1,因此失败。
接下来需要解析acquire(1)方法。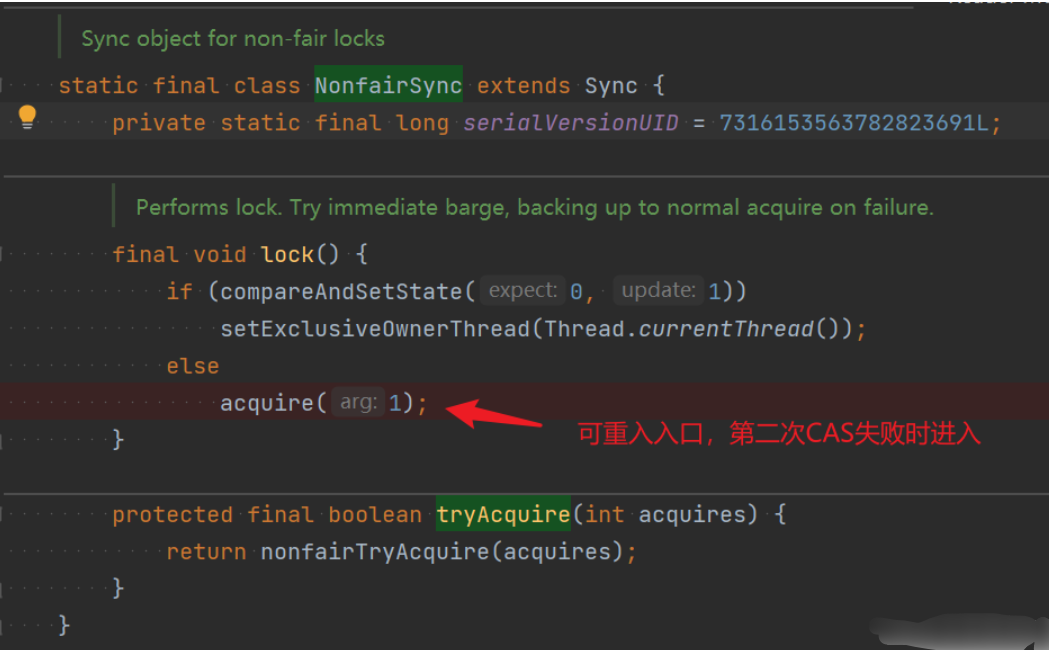
执行步骤:
- CAS原子性的修改AbstractQueuedSynchronizer#state的值,由0改为1,成功则说明当前线程加锁成功.
- 设置AbstractOwnableSynchronizer#exclusiveOwnerThread的值为当前线程,表示当前锁的拥有者是当前线程。(前两步是当前线程还未获得当前锁的时候,当前时候尝试获取锁的代码块)
- 如果1中修改失败,则进入acquire(1)。申请1个state,acquire方法中首先尝试获取锁tryAcquire(),如果获取失败,则将当前线程以独占模式Node.EXCLUSIVE加入等待队列尾部(addWaiter方法)。
- acquireQueued():以独占无中断模式获取锁,这个方法会一直无限循环,直到获取到资源或者被中断才返回。如果等待过程中被中断则返回true。这里有自旋锁的意思,加入队列中的线程,不断的重试检测是否可以执行任务。(这两个就是还未获取到锁,加入阻塞队列)
2、acquire
java.util.concurrent.locks.AbstractQueuedSynchronizer#acquire
acquire重入逻辑的入口。
在acquire中有两个过程,即tryAcquire和acquireQueued。
其中,
(1)tryAcquire是可重入的入口,实现当前线程的锁持有数自增,并且返回true,保证不会触发线程中断selfInterrupt();
(2)acquireQueued则是轮询获取已在队列中的线程,进一步判断,同一线程是否在队列,保证不会中断当前线程。返回false,保证不会触发线程中断selfInterrupt()。不过获取前,有一个入队的操作:addWaiter。
因为判断的逻辑为:if(!tryAcquire(…)&&acquireQueued(…)),所以,返回true,不会触发。
好了,下面需要进入tryAcquire看看如何实现。
这里就是实现为线程入队,插入链表的实现。
3、nonFairTryAcquire
tryAcquire的具体实现是在NonfairSync类中,然后调用其父类Sync 中的nonfairTryAcquire()方法。
java.util.concurrent.locks.ReentrantLock.Sync#nonfairTryAcquire
使当前线程持有锁的次数+1,保证逻辑正常执行。
进入该方法,可知,首先获取state,因为第一次获取锁后,state=1,
此时,会进入else if的逻辑,同一线程,则保证:current == getExclusiveOwnerThread()为true,
所以,此时,会将当前线程持有锁的次数+1,即next = c + acquires
当然了,释放锁的时候,也要逐步释放。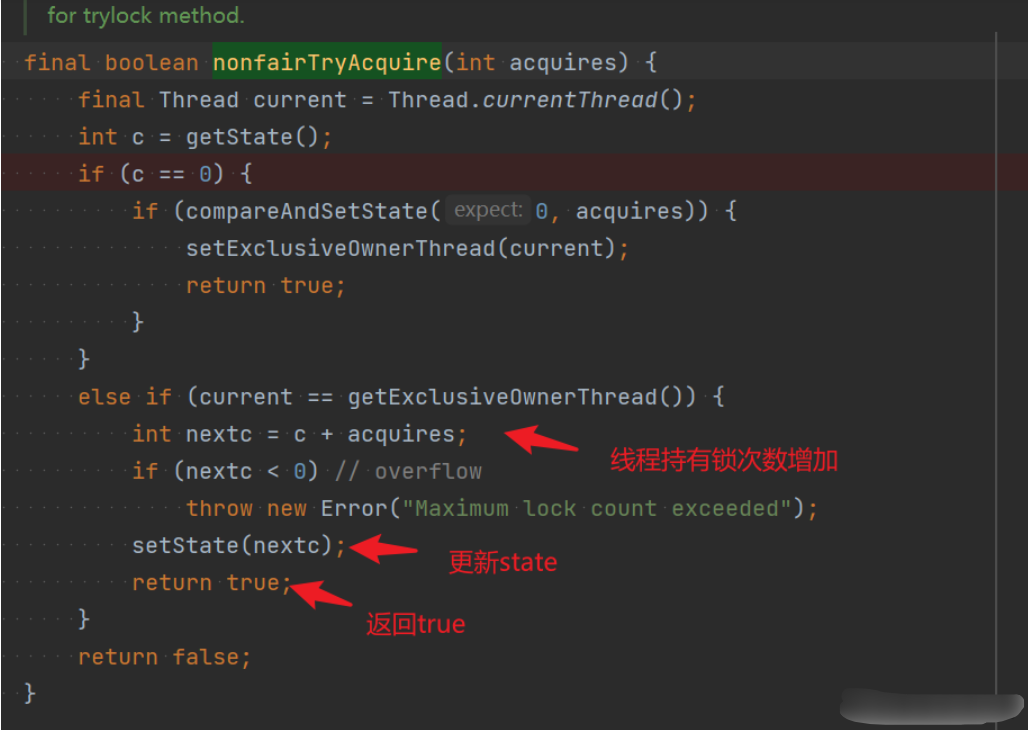
static final class NonfairSync extends Sync {protected final boolean tryAcquire(int acquires) {return nonfairTryAcquire(acquires);}}final boolean nonfairTryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();//:1、获取volatile int state的值if (c == 0) {//2:state=0表示当前可以加锁if (compareAndSetState(0, acquires)) {//CAS将state设置为acquires的值setExclusiveOwnerThread(current);//设置当前拥有锁的线程return true;}}else if (current == getExclusiveOwnerThread()) {//当前锁的拥有者线程是currentThreadint nextc = c + acquires;//将state累加上acquiresif (nextc < 0) // overflowthrow new Error("Maximum lock count exceeded");setState(nextc);//设置state的值。由于这里只有获取锁的线程才能执行,所以不会出现并发,不需要额外的加锁处理//这也是ReentrantLock为什么是可重入锁的原因,同一个线程加多次锁(lock.lock)也就是给state的值累加而已。return true;}return false;//当前锁的拥有者线程不是currentThread,直接返回false,也就是获取锁失败}
- nonfairTryAcquire的实现:如果当前没有锁,那么加锁。如果已经有了锁,那么看看当前锁的拥有者线程是不是currentThread,是则累加state的值,不是则返回失败。
- 所以,使用ReentrantLock时,线程获得锁的标记是在state上的,state=0表示没有被加锁,state=1表示加锁成功,state>1表示锁重入。
4、addWaiter
这是什么操作?
- 按照指定模式(独占还是共享)将节点添加到等待队列。
将线程放入队列。填充队列prev和tail,这里,填充了prev才能保证后面的方法acquireQueued返回true。
java.util.concurrent.locks.AbstractQueuedSynchronizer#addWaiter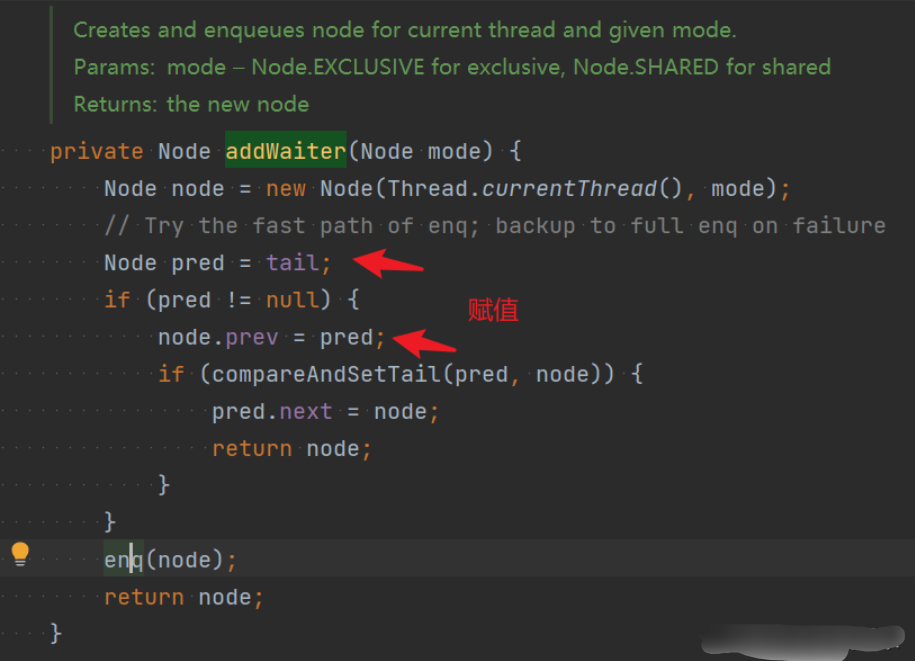
private Node addWaiter(Node mode) {Node node = new Node(Thread.currentThread(), mode);//1、首先尝试以快速方式添加到队列末尾Node pred = tail;//pred指向现有tail末尾节点if (pred != null) {//新加入节点的前一个节点是现有AQS队列的tail节点node.prev = pred;//CAS原子性的修改tail节点if (compareAndSetTail(pred, node)) {//修改成功,新节点成功加入AQS队列,pred节点的next节点指向新的节点pred.next = node;return node;}}//2、pred为空,或者修改tail节点失败,//则走enq方法将节点插入队列enq(node);return node;}private Node enq(final Node node) {for(;;) {//CASNode t = tail;if (t == null) {// 必须初始化。这里是AQS队列为空的情况。//通过CAS的方式创建head节点,并且tail和head都指向//同一个节点。if (compareAndSetHead(new Node()))//注意这里初始化head节点,并不关联任何线程!!tail = head;} else {//这里变更node节点的prev指针,并且移动tail指针指向node,//前一个节点的next指向新插入的nodenode.prev = t;if (compareAndSetTail(t, node)) {t.next = node;return t;}}}}
- addWaiter首先会以快速方式将node添加到队尾,如果失败则走enq方法。失败有两种可能,一个是tail为空,也就是AQS为空的情况下。另一是compareAndSetTail失败,也就是多线程并发添加到队尾,此时会出现CAS失败。
注意enq方法,在t==null时,首先创建空的头节点,不关联任何的线程,nextWaiter和thread变量都是null。
5、acquireQueued
tryAcquire失败没有获取到锁,addWaiter加入了AQS等待队列,进入acquireQueued方法中,acquireQueued方法以独占无中断模式获取锁,这个方法会一直无限循环,直到获取到资源或者被中断才返回。
进一步确认当前线程在队列,而不强行中断,保证线程正常执行。
java.util.concurrent.locks.AbstractQueuedSynchronizer#acquireQueued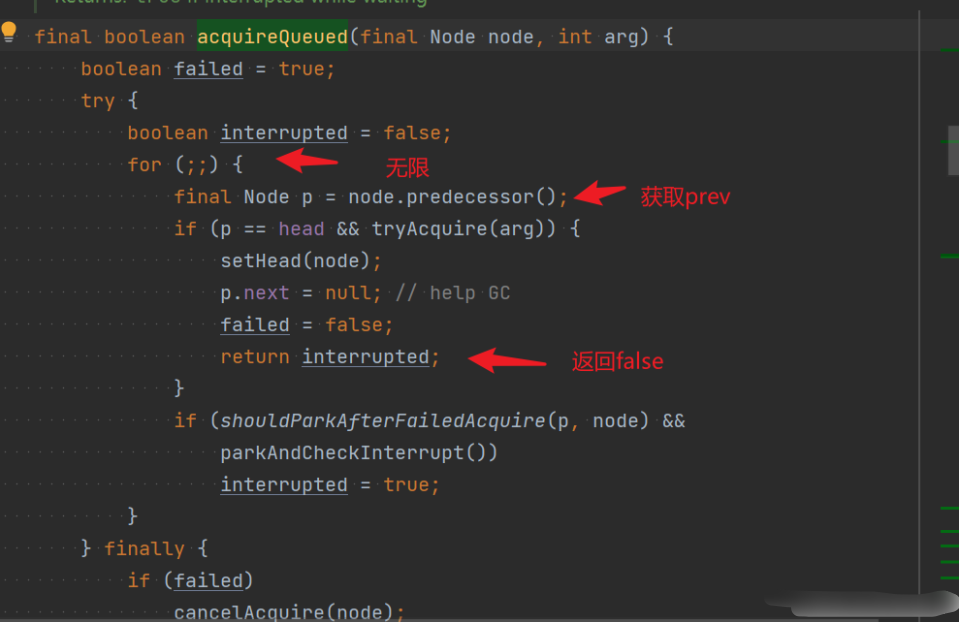
final boolean acquireQueued(final Node node, int arg) {boolean failed = true;//是否获取到资源try {boolean interrupted = false;//是否中断for (;;) {//获取前一个节点final Node p = node.predecessor();//如果当前node节点是第二个节点,紧跟在head后面,//那么tryAcquire尝试获取资源if (p == head && tryAcquire(arg)) {setHead(node);//获取锁成功,当前节点成为head节点p.next = null; // 目的:辅助GC,next为空说明当前节点出队列就可以进行gcfailed = false;return interrupted;//返回是否中断过}//当shouldParkAfterFailedAcquire返回成功,//也就是前驱节点是Node.SIGNAL状态时,//进行真正的park将当前线程挂起,并且检查中断标记,//如果是已经中断,则设置interrupted =true。//如果shouldParkAfterFailedAcquire返回false,//则重复上述过程,直到获取到资源或者被park。if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())interrupted = true;}} finally {if (failed)cancelAcquire(node);//添加AQS失败,取消任务}}//前面讲过,head节点不与任何线程关联,他的thread是null,//当然head节点的prev肯定也是nullprivate void setHead(Node node) {head = node;node.thread = null;node.prev = null;}//在Acquire失败后,是否要park中断private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {int ws= pred.waitStatus;//获取到上一个节点的waitStatusif (ws == Node.SIGNAL)//前面讲到当一个节点状态时SIGNAL时,//他有责任唤醒后面的节点。所以这里判断前驱节点是SIGNAL状态,//则可以安心的park中断了。return true;if (ws > 0) {/** 过滤掉中间cancel状态的节点* 前驱节点被取消的情况(线程允许被取消哦)。向前遍历,* 直到找到一个waitStatus大于0的(不是取消状态或初始状态)* 的节点,该节点设置为当前node的前驱节点。*/do {node.prev = pred = pred.prev;} while (pred.waitStatus > 0);pred.next = node;} else {/** 修改前驱节点的WaitStatus为Node.SIGNAL。* 明确前驱节点必须为Node.SIGNAL,当前节点才可以park* 注意,这个CAS也可能会失败,因为前驱节点的WaitStatus状态* 可能会发生变化*/compareAndSetWaitStatus(pred, ws, Node.SIGNAL);}return false;}//阻塞当前线程//park并且检查是否被中断过private final boolean parkAndCheckInterrupt() {LockSupport.park(this);return Thread.interrupted();}
4.3.3、总结
可重入,即一个线程可以多次(重复)进入同类型的锁而不出现异常(死锁);
ReentrantLock提供两类锁:公平锁和非公平锁;
可重入是因为可重锁lock中核心逻辑:如果CAS,成功,则继续执行设置独占,setExclusiveOwnerThread;CAS失败,进入可重入逻辑;
可重入执行逻辑入口:acquire(…),java.util.concurrent.locks.AbstractQueuedSynchronizer#acquire
可重入的核心三个操作:
(1)addWaiter:线程入队;
(2)acquireQueued:确认线程在队列中,不中断线程,返回false;
(3)tryAcquire:同一线程获取锁次数+1,不中断线程,返回true;
保证线程不中断:if(!tryAcquire(…)&&acquireQueued)。
4.3.4、ReentrantLock和synchronized的区别
可重入性:
从名字上理解,ReenTrantLock的字面意思就是再进入的锁,其实synchronized关键字所使用的锁也是可重入的,两者关于这个的区别不大。
两者都是同一个线程没进入一次,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
锁的实现:
Synchronized是依赖于JVM实现的,而ReenTrantLock是JDK实现的,有什么区别,说白了就类似于操作系统来控制实现和用户自己敲代码实现的区别。前者的实现是比较难见到的,后者有直接的源码可供阅读。
性能的区别:
在Synchronized优化以前,synchronized的性能是比ReenTrantLock差很多的,但是自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了。
在两种方法都可用的情况下,官方甚至建议使用synchronized,其实synchronized的优化我感觉就借鉴了ReenTrantLock中的CAS技术。都是试图在用户态就把加锁问题解决,避免进入内核态的线程阻塞。
功能区别:
便利性:很明显Synchronized的使用比较方便简洁,并且由编译器去保证锁的加锁和释放,而ReenTrantLock需要手工声明来加锁和释放锁,为了避免忘记手工释放锁造成死锁,所以最好在finally中声明释放锁。
锁的细粒度和灵活度:很明显ReenTrantLock优于Synchronized
ReenTrantLock独有的能力:
1.ReenTrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。
2.ReenTrantLock提供了一个Condition(条件)类,用来实现分组唤醒需要唤醒的线程们,而不是像synchronized要么随机唤醒一个线程要么唤醒全部线程。
3.ReenTrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly()来实现这个机制。
ReenTrantLock实现的原理:
在网上看到相关的源码分析,本来这块应该是本文的核心,但是感觉比较复杂就不一一详解了,简单来说,ReenTrantLock的实现是一种自旋锁,通过循环调用CAS操作来实现加锁。
它的性能比较好也是因为避免了使线程进入内核态的阻塞状态。想尽办法避免线程进入内核的阻塞状态是我们去分析和理解锁设计的关键钥匙。
什么情况下使用ReenTrantLock:
答案是,如果你需要实现ReenTrantLock的三个独有功能时。
面试题1: 可重入锁如果加了两把,但是只释放了一把会出现什么问题?
答:程序卡死,线程不能出来,也就是说我们申请了几把锁,就需要释放几把锁。
面试题2: 如果只加了一把锁,释放两次会出现什么问题?答:会报错,
java.lang.IllegalMonitorStateException。
5、读写锁
ReentrantReadWriteLock,CopyOnWriteArrayList、CopyOnWriteArraySet
5.1、读写锁概述
读写锁是一种技术: 通过ReentrantReadWriteLock类来实现。为了提高性能, Java提供了读写锁,在读的地方使用读锁,在写的地方使用写锁,灵活控制,如果没有写锁的情况下,读是无阻塞的,在一定程度上提高了程序的执行效率。 读写锁分为读锁和写锁,多个读锁不互斥,读锁与写锁互斥,这是由 jvm 自己控制的。
对于多个线程共享同一个资源的时候,多个线程同时对共享资源做读操作是不会发生线程安全性问题的,但是一旦有一个线程对共享数据做写操作其他的线程再来读写共享资源的话,就会发生数据安全性问题,所以出现了读写锁ReentrantReadWriteLock。读写锁允许多个线程同时获取读锁,但有一个线程获取写锁之后其他线程都会进入等待队列进行等待。
[
](https://blog.csdn.net/qq_37685457/article/details/89855519)
读锁: 允许多个线程获取读锁,同时访问同一个资源
写锁: 只允许一个线程获取写锁,不允许同时访问同一个资源。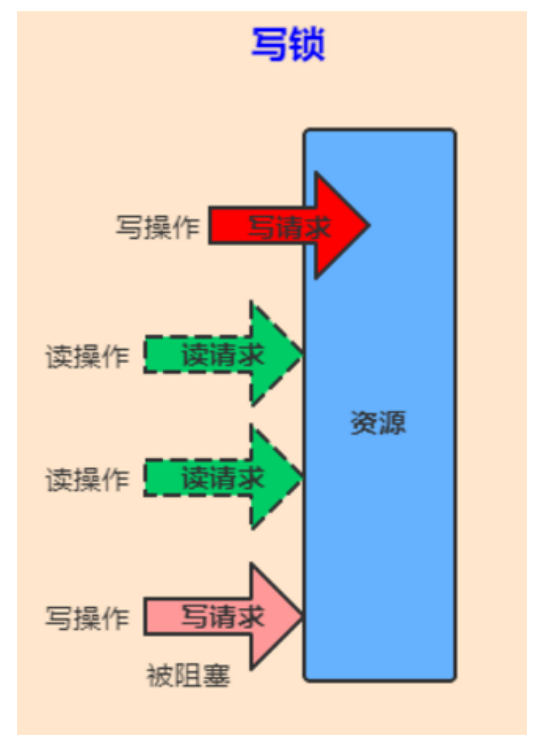
所有读写锁的实现必须确保写操作对读操作的内存影响。换句话说,一个获得了读锁的线程必须能看到前一个释放的写锁所更新的内容。
读写锁比互斥锁允许对于共享数据更大程度的并发。每次只能有一个写线程,但是同时可以有多个线程并发地读数据。ReadWriteLock适用于读多写少的并发情况。
这里读写锁实现的是ReentrantReadWriteLock
5.2、读写锁的实现
/*** 创建一个读写锁* 它是一个读写融为一体的锁,在使用的时候,需要转换*/private ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();获取读锁和释放读锁// 获取读锁rwLock.readLock().lock();// 释放读锁rwLock.readLock().unlock();获取写锁和释放写锁// 创建一个写锁rwLock.writeLock().lock();// 写锁 释放rwLock.writeLock().unlock();
Java中的读写锁:ReentrantReadWriteLock
5.3、ReentrantReadWriteLock
5.3.1、概述
ReentrantReadWriteLock是Lock的另一种实现方式,我们已经知道了ReentrantLock是一个排他锁,同一时间只允许一个线程访问,而ReentrantReadWriteLock允许多个读线程同时访问,但不允许写线程和读线程、写线程和写线程同时访问。相对于排他锁,提高了并发性。在实际应用中,大部分情况下对共享数据(如缓存)的访问都是读操作远多于写操作,这时ReentrantReadWriteLock能够提供比排他锁更好的并发性和吞吐量。
读写锁内部维护了两个锁,一个用于读操作,一个用于写操作。所有 ReadWriteLock实现都必须保证 writeLock操作的内存同步效果也要保持与相关 readLock的联系。也就是说,成功获取读锁的线程会看到写入锁之前版本所做的所有更新。
ReentrantReadWriteLock支持以下功能:
1)支持公平和非公平的获取锁的方式;
2)支持可重入。读线程在获取了读锁后还可以获取读锁;写线程在获取了写锁之后既可以再次获取写锁又可以获取读锁;
3)还允许从写入锁降级为读取锁,其实现方式是:先获取写入锁,然后获取读取锁,最后释放写入锁。但是,从读取锁升级到写入锁是不允许的;
4)读取锁和写入锁都支持锁获取期间的中断;
5)Condition支持。仅写入锁提供了一个 Conditon 实现;读取锁不支持 Conditon ,readLock().newCondition() 会抛出 UnsupportedOperationException。
5.3.2、ReentrantReadWriteLock特性
- 获取顺序
- 非公平模式(默认):当以非公平初始化时,读锁和写锁的获取的顺序是不确定的。非公平锁主张竞争获取,可能会延缓一个或多个读或写线程,但是会比公平锁有更高的吞吐量。
- 公平模式:当以公平模式初始化时,线程将会以队列的顺序获取锁。当当前线程释放锁后,等待时间最长的写锁线程就会被分配写锁;或者有一组读线程组等待时间比写线程长,那么这组读线程组将会被分配读锁。当有写线程持有写锁或者有等待的写线程时,一个尝试获取公平的读锁(非重入)的线程就会阻塞。这个线程直到等待时间最长的写锁获得锁后并释放掉锁后才能获取到读锁。
- 可重入
允许读锁可写锁可重入。写锁可以获得读锁,读锁不能获得写锁。
- 锁降级
允许写锁降低为读锁
- 中断锁的获取
在读锁和写锁的获取过程中支持中断
- 支持Condition
写锁提供Condition实现
- 监控
提供确定锁是否被持有等辅助方法
5.3.3、实现
下面一段代码展示了锁降低的操作:
class CachedData {//被缓存的具体对象Object data;//当前对象是否可用,使用volatile来保证可见性volatile boolean cacheValid;//今天的主角,ReentrantReadWriteLockfinal ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();//业务处理逻辑void processCachedData() {//要读取数据时,先加读锁,如果加成功,说明此时没有人在并发写rwl.readLock().lock();//拿到读锁后,判断当前对象是否有效if (!cacheValid) {// Must release read lock before acquiring write lock//这里的处理非常经典,当你持有读锁之后,不能直接获取写锁,//因为写锁是独占锁,如果直接获取写锁,那代码就在这里死锁了//所以必须要先释放读锁,然后手动获取写锁rwl.readLock().unlock();rwl.writeLock().lock();try {// Recheck state because another thread might have// acquired write lock and changed state before we did.//经典处理之二,在独占锁内部要处理数据时,一定要做二次校验//因为可能同时有多个线程全都在获取写锁,//当时线程1释放写锁之后,线程2马上获取到写锁,此时如果不做二次校验那可能就导致某些操作做了多次if (!cacheValid) {data = ...//当缓存对象更新成功后,重置标记为truecacheValid = true;}// Downgrade by acquiring read lock before releasing write lock//这里有一个非常神奇的锁降级操作,所谓降级是说当你持有写锁后,可以再次获取读锁//这里之所以要获取一次写锁是为了防止当前线程释放写锁之后,其他线程马上获取到写锁,改变缓存对象//因为读写互斥,所以有了这个读锁之后,在读锁释放之前,别的线程是无法修改缓存对象的rwl.readLock().lock();} finally {rwl.writeLock().unlock(); // Unlock write, still hold read}}try {use(data);} finally {rwl.readLock().unlock();}}}
5.3.4、底层实现
读写锁的读锁原理:
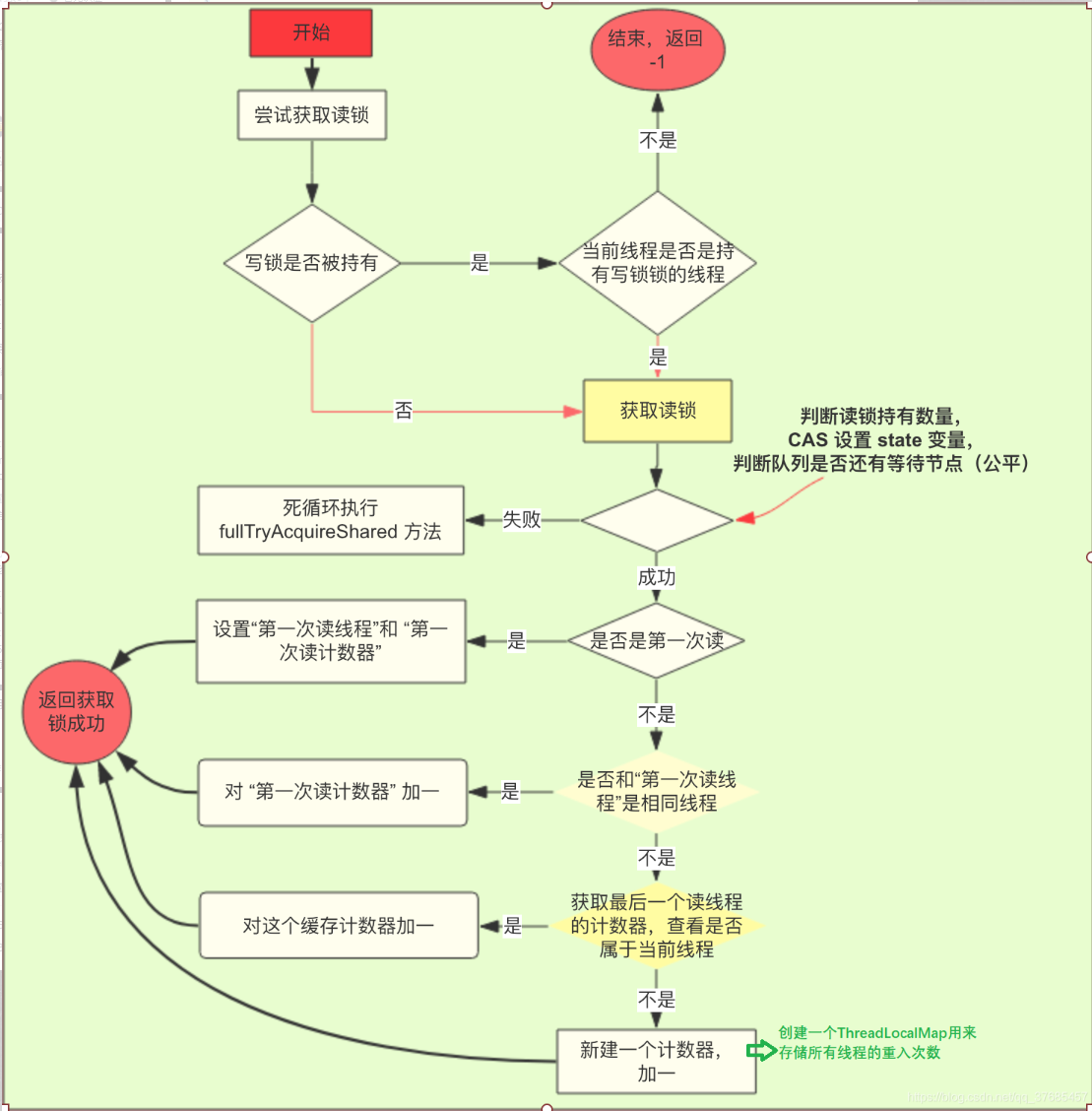
如果有线程想申请读锁的话,首先会判断写锁是否被持有,如果写锁被持有且当前线程并不是持有写锁的线程,那么就会返回-1,获取锁失败,进入到等待队列等待。如果写锁未被线程所持有或者当前线程和持有写锁的线程是同一线程的话就会开始获取读锁。线程首先会判断读锁的数量是否超过65535个,如果没超过就CAS修改state变量的高16位的值,也就是将state的值+1,如果这个步骤失败的话它会循环这个操作,直到成功为止。CAS修改成功之后,代表读锁获取成功,会判断一下当前线程是否是第一次读线程,如果是,就设置第一次多线程和第一次读计数器(为了性能和可重入)。如果不是第一次获取读锁,判断一下是否是与第一次读线程相同,如果与第一次读线程是同一线程就将第一次读计数器+1。如果也不是第一次读线程,判断一下是否是最后一次读线程,如果是就将最后一次读计数器+1。如果都不是,就新建一个计数器,设置最后一次读线程为自己本身线程,然后刷新它的读计数器。
这里哆嗦通过判断是否可以分享否则入阻塞队列
protected final int11 tryAcquireShared(int unused) {Thread current = Thread.currentThread();int c = getState();// exclusiveCount(c) != 0 ---》 用 state & 65535 得到低 16 位的值。如果不是0,说明写锁别持有了。// getExclusiveOwnerThread() != current----> 不是当前线程// 如果写锁被霸占了,且持有线程不是当前线程,返回 false,加入队列。获取写锁失败。// 反之,如果持有写锁的是当前线程,就可以继续获取读锁了。if (exclusiveCount(c) != 0 && getExclusiveOwnerThread() != current)// 获取锁失败return -1;// 如果写锁没有被霸占,则将高16位移到低16位。int r = sharedCount(c);// c >>> 16// !readerShouldBlock() 和写锁的逻辑一样(根据公平与否策略和队列是否含有等待节点)// 不能大于 65535,且 CAS 修改成功if (!readerShouldBlock() && r < 65535 && compareAndSetState(c, c + 65536)) {// 如果读锁是空闲的, 获取锁成功。if (r == 0) {// 将当前线程设置为第一个读锁线程firstReader = current;// 计数器为1firstReaderHoldCount = 1;}// 如果读锁不是空闲的,且第一个读线程是当前线程。获取锁成功。else if (firstReader == current) {//// 将计数器加一firstReaderHoldCount++;} else {// 如果不是第一个线程,获取锁成功。// cachedHoldCounter 代表的是最后一个获取读锁的线程的计数器。HoldCounter rh = cachedHoldCounter;// 如果最后一个线程计数器是 null 或者不是当前线程,那么就新建一个 HoldCounter 对象if (rh == null || rh.tid != getThreadId(current))// 给当前线程新建一个 HoldCounter ------>详见下图get方法cachedHoldCounter = rh = readHolds.get();// 如果不是 null,且 count 是 0,就将上个线程的 HoldCounter 覆盖本地的。else if (rh.count == 0)readHolds.set(rh);// 对 count 加一rh.count++;}return 1;}// 死循环获取读锁。包含锁降级策略。return fullTryAcquireShared(current);}

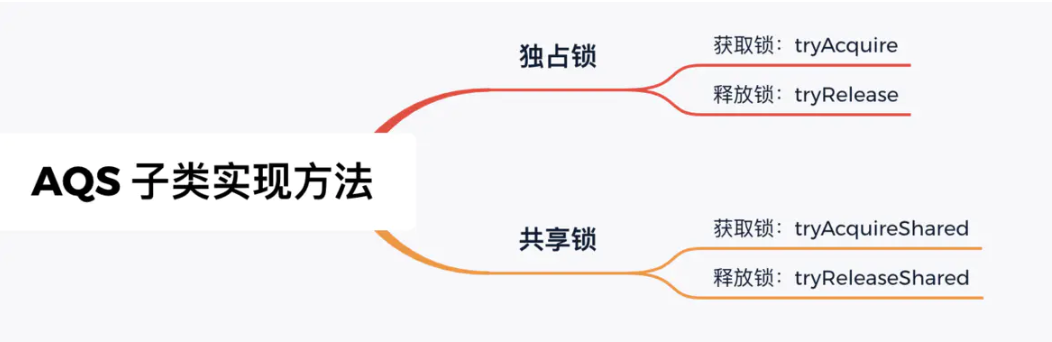
ReentrantReadWriteLock 也是基于AQS实现的,它的自定义同步器(继承AQS)需要在同步状态(一个整型变量state)上维护多个读线程和一个写线程的状态,使得该状态的设计成为读写锁实现的关键。如果在一个整型变量上维护多种状态,就一定需要“按位切割使用”这个变量,读写锁将变量切分成了两个部分,高16位表示读,低16位表示写。
ReentrantReadWriteLock含有两把锁readerLock和writerLock,其中ReadLock和WriteLock都是内部类。
/** Inner class providing readlock */private final ReentrantReadWriteLock.ReadLock readerLock;/** Inner class providing writelock */private final ReentrantReadWriteLock.WriteLock writerLock;/** Performs all synchronization mechanics */final Sync sync;
写锁的获取与释放(WriteLock)
写锁是一个可重入的独占锁,使用AQS提供的独占式获取同步状态的策略。
//获取写锁public void lock() {sync.acquire(1);}//AQS实现的独占式获取同步状态方法public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}//自定义重写的tryAcquire方法protected final boolean tryAcquire(int acquires) {/** Walkthrough:* 1. If read count nonzero or write count nonzero* and owner is a different thread, fail.* 2. If count would saturate, fail. (This can only* happen if count is already nonzero.)* 3. Otherwise, this thread is eligible for lock if* it is either a reentrant acquire or* queue policy allows it. If so, update state* and set owner.*/Thread current = Thread.currentThread();int c = getState();int w = exclusiveCount(c); //取同步状态state的低16位,写同步状态if (c != 0) {// (Note: if c != 0 and w == 0 then shared count != 0)//存在读锁或当前线程不是已获取写锁的线程,返回falseif (w == 0 || current != getExclusiveOwnerThread())return false;//判断同一线程获取写锁是否超过最大次数,支持可重入if (w + exclusiveCount(acquires) > MAX_COUNT) //throw new Error("Maximum lock count exceeded");// Reentrant acquiresetState(c + acquires);return true;}//此时c=0,读锁和写锁都没有被获取if (writerShouldBlock() ||!compareAndSetState(c, c + acquires))return false;setExclusiveOwnerThread(current);return true;}
高16位是保存读线程的数量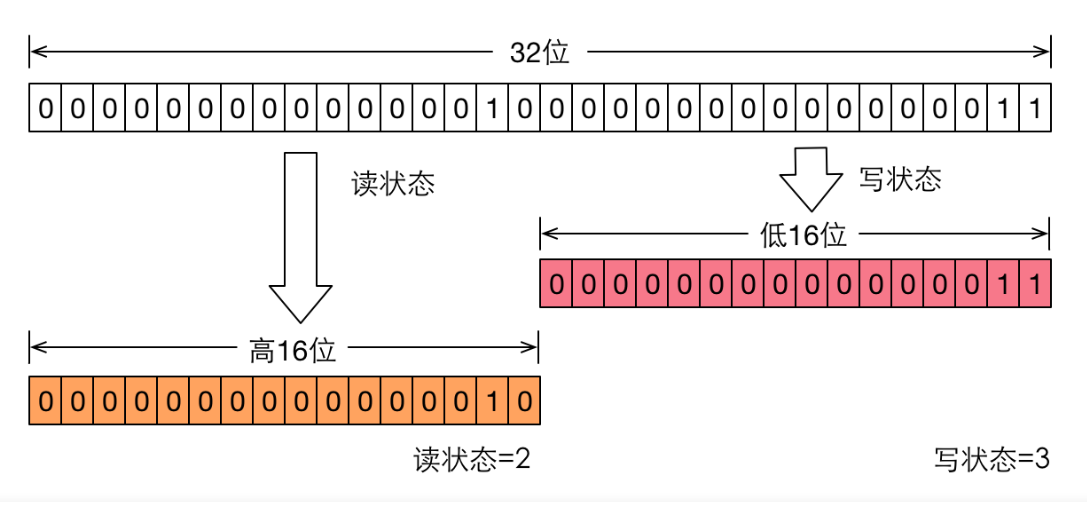
从源代码可以看出,获取写锁的步骤如下:
1)判断同步状态state是否为0。如果state!=0,说明已经有其他线程获取了读锁或写锁,执行2);否则执行5)。
2)判断同步状态state的低16位(w)是否为0。如果w=0,说明其他线程获取了读锁,返回false;如果w!=0,说明其他线程获取了写锁,执行步骤3)。
3)判断获取了写锁是否是当前线程,若不是返回false,否则执行4);
4)判断当前线程获取写锁是否超过最大次数,若超过,抛异常,反之更新同步状态(此时当前线程以获取写锁,更新是线程安全的),返回true。
5)此时读锁或写锁都没有被获取,判断是否需要阻塞(公平和非公平方式实现不同),如果不需要阻塞,则CAS更新同步状态,若CAS成功则返回true,否则返回false。如果需要阻塞则返回false。
writerShouldBlock() 表示当前线程是否应该被阻塞。NonfairSync和FairSync中有不同是实现。
//FairSync中需要判断是否有前驱节点,如果有则返回false,否则返回true。遵循FIFOfinal boolean writerShouldBlock() {// 将线程插入阻塞队列return hasQueuedPredecessors();}//NonfairSync中直接返回false,可插队。final boolean writerShouldBlock() {return false; // writers can always barge}
//写锁释放public void unlock() {sync.release(1);}//AQS提供独占式释放同步状态的方法public final boolean release(int arg) {if (tryRelease(arg)) {Node h = head;if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;}return false;}//自定义重写的tryRelease方法protected final boolean tryRelease(int releases) {if (!isHeldExclusively())throw new IllegalMonitorStateException();int nextc = getState() - releases; //同步状态减去releases//判断同步状态的低16位(写同步状态)是否为0,如果为0则返回true,否则返回false.//因为支持可重入boolean free = exclusiveCount(nextc) == 0;if (free)setExclusiveOwnerThread(null);setState(nextc); //以获取写锁,不需要其他同步措施,是线程安全的return free;}
读锁的获取与释放(ReadLock)
读锁是一个可重入的共享锁,采用AQS提供的共享式获取同步状态的策略。
public void lock() {sync.acquireShared(1);}//使用AQS提供的共享式获取同步状态的方法public final void acquireShared(int arg) {if (tryAcquireShared(arg) < 0)doAcquireShared(arg);}//自定义重写的tryAcquireShared方法,参数是unused,因为读锁的重入计数是内部维护的protected final int tryAcquireShared(int unused) {/** Walkthrough:* 1. If write lock held by another thread, fail.* 2. Otherwise, this thread is eligible for* lock wrt state, so ask if it should block* because of queue policy. If not, try* to grant by CASing state and updating count.* Note that step does not check for reentrant* acquires, which is postponed to full version* to avoid having to check hold count in* the more typical non-reentrant case.* 3. If step 2 fails either because thread* apparently not eligible or CAS fails or count* saturated, chain to version with full retry loop.*/Thread current = Thread.currentThread();int c = getState();//exclusiveCount(c)取低16位写锁。存在写锁且当前线程不是获取写锁的线程,返回-1,获取读锁失败。if (exclusiveCount(c) != 0 &&getExclusiveOwnerThread() != current)return -1;int r = sharedCount(c); //取高16位读锁,//readerShouldBlock()用来判断当前线程是否应该被阻塞if (!readerShouldBlock() &&r < MAX_COUNT && //MAX_COUNT为获取读锁的最大数量,为16位的最大值compareAndSetState(c, c + SHARED_UNIT)) {//firstReader是不会放到readHolds里的, 这样,在读锁只有一个的情况下,就避免了查找readHolds。if (r == 0) { // 是 firstReader,计数不会放入 readHolds。firstReader = current;firstReaderHoldCount = 1;} else if (firstReader == current) { //firstReader重入firstReaderHoldCount++;} else {// 非 firstReader 读锁重入计数更新HoldCounter rh = cachedHoldCounter; //读锁重入计数缓存,基于ThreadLocal实现if (rh == null || rh.tid != current.getId())cachedHoldCounter = rh = readHolds.get();else if (rh.count == 0)readHolds.set(rh);rh.count++;}return 1;}//第一次获取读锁失败,有两种情况://1)没有写锁被占用时,尝试通过一次CAS去获取锁时,更新失败(说明有其他读锁在申请)//2)当前线程占有写锁,并且有其他写锁在当前线程的下一个节点等待获取写锁,除非当前线程的下一个节点被取消,否则fullTryAcquireShared也获取不到读锁return fullTryAcquireShared(current);}
从源代码可以看出,获取读锁的大致步骤如下:
1)通过同步状态低16位判断,如果存在写锁且当前线程不是获取写锁的线程,返回-1,获取读锁失败;否则执行步骤2)。
2)通过readerShouldBlock判断当前线程是否应该被阻塞,如果不应该阻塞则尝试CAS同步状态;否则执行3)。
3)第一次获取读锁失败,通过fullTryAcquireShared再次尝试获取读锁。
readerShouldBlock方法用来判断当前线程是否应该被阻塞,NonfairSync和FairSync中有不同是实现。
//FairSync中需要判断是否有前驱节点,如果有则返回false,否则返回true。遵循FIFOfinal boolean readerShouldBlock() {return hasQueuedPredecessors();}final boolean readerShouldBlock() {return apparentlyFirstQueuedIsExclusive();}//当head节点不为null且head节点的下一个节点s不为null且s是独占模式(写线程)且s的线程不为null时,返回true。//目的是不应该让写锁始终等待。作为一个启发式方法用于避免可能的写线程饥饿,这只是一种概率性的作用,因为如果有一个等待的写线程在其他尚未从队列中出队的读线程后面等待,那么新的读线程将不会被阻塞。final boolean apparentlyFirstQueuedIsExclusive() {Node h, s;return (h = head) != null &&(s = h.next) != null &&!s.isShared() &&s.thread != null;}
fullTryAcquireShared方法
final int fullTryAcquireShared(Thread current) {/** This code is in part redundant with that in* tryAcquireShared but is simpler overall by not* complicating tryAcquireShared with interactions between* retries and lazily reading hold counts.*/HoldCounter rh = null;for (;;) {int c = getState();//如果当前线程不是写锁的持有者,直接返回-1,结束尝试获取读锁,需要排队去申请读锁if (exclusiveCount(c) != 0) {if (getExclusiveOwnerThread() != current)return -1;// else we hold the exclusive lock; blocking here// would cause deadlock.//如果需要阻塞,说明除了当前线程持有写锁外,还有其他线程已经排队在申请写锁,故,即使申请读锁的线程已经持有写锁(写锁内部再次申请读锁,俗称锁降级)还是会失败,因为有其他线程也在申请写锁,此时,只能结束本次申请读锁的请求,转而去排队,否则,将造成死锁。} else if (readerShouldBlock()) {// Make sure we're not acquiring read lock reentrantlyif (firstReader == current) {//如果当前线程是第一个获取了写锁,那其他线程无法申请写锁// assert firstReaderHoldCount > 0;} else {//从readHolds中移除当前线程的持有数,然后返回-1,然后去排队获取读锁。if (rh == null) {rh = cachedHoldCounter;if (rh == null || rh.tid != current.getId()) {rh = readHolds.get();if (rh.count == 0)readHolds.remove();}}if (rh.count == 0)return -1;}}if (sharedCount(c) == MAX_COUNT)throw new Error("Maximum lock count exceeded");if (compareAndSetState(c, c + SHARED_UNIT)) {//示成功获取读锁,后续就是更新readHolds等内部变量,if (sharedCount(c) == 0) {firstReader = current;firstReaderHoldCount = 1;} else if (firstReader == current) {firstReaderHoldCount++;} else {if (rh == null)rh = cachedHoldCounter;if (rh == null || rh.tid != current.getId())rh = readHolds.get();else if (rh.count == 0)readHolds.set(rh);rh.count++;cachedHoldCounter = rh; // cache for release}return 1;}}}
释放锁
public void unlock() {sync.releaseShared(1);}public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) {doReleaseShared();return true;}return false;}protected final boolean tryReleaseShared(int unused) {Thread current = Thread.currentThread();//更新计数if (firstReader == current) {// assert firstReaderHoldCount > 0;if (firstReaderHoldCount == 1)firstReader = null;elsefirstReaderHoldCount--;} else {HoldCounter rh = cachedHoldCounter;if (rh == null || rh.tid != current.getId())rh = readHolds.get();int count = rh.count;if (count <= 1) {readHolds.remove();if (count <= 0)throw unmatchedUnlockException();}--rh.count;}//自旋CAS,减去1<<16for (;;) {int c = getState();int nextc = c - SHARED_UNIT;if (compareAndSetState(c, nextc))// Releasing the read lock has no effect on readers,// but it may allow waiting writers to proceed if// both read and write locks are now free.return nextc == 0;}}
5.3.5、应用场景
这两个demo其实在我目前的开发中基本上哪个也用不上,但是我能不能通过ReentrantReadWriteLock手写一个简单的缓存容器呢?缓存容器本质上非常接近RWDictionary 但是需要提供增量缓存的方法。
我们先定义一个缓存容器的接口: ```java /**
- 缓存容器 *
@param
/ public interface ICacheContainer { /**
- 获取对象 *
- @param key
- @return
*/
T get(String key, Function
/**
- 移除对象 *
- @param key
- @return */ T remove(String key); }
2、使用**ReentrantReadWriteLock+HashMap**提供一个实现```java/*** 缓存容器** @param <T>**/public class ReadWriteLockCacheContainer<T> implements ICacheContainer<T> {private final HashMap<String, T> cacheMap = new HashMap<>();private final ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();@Overridepublic T get(String key, Function<String, T> mappingFunction) {//读之前先上读锁readWriteLock.readLock().lock();try {//判断map中是否已经有了boolean has = cacheMap.containsKey(key);if (!has) {//没有数据,需要写,读锁释放readWriteLock.readLock().unlock();//加写锁,必须先释放读锁,不然这里直接GGreadWriteLock.writeLock().lock();try {//并发二重校验has = cacheMap.containsKey(key);if (!has) {T data = mappingFunction.apply(key);cacheMap.put(key, data);}} finally {//这里要先降级,给自己占一个坑,防止当前线程释放写锁之后,//马上有其他线程获取到写锁,并对对象修改readWriteLock.readLock().lock();//finally里面释放写锁readWriteLock.writeLock().unlock();}}//考虑到并发,这里一定要从HashMap中读,并且一定要加读锁return cacheMap.get(key);} finally {//finally里面释放写锁readWriteLock.readLock().unlock();}}@Overridepublic T remove(String key) {readWriteLock.writeLock().lock();try {return cacheMap.remove(key);} finally {readWriteLock.writeLock().unlock();}}}
5.4、应用场景
1、CopyOnWriteArrayList
CopyOnWriteArrayList是ArrayList的线程安全版本,从他的名字可以推测,CopyOnWriteArrayList是在有写操作的时候会copy一份数据,然后写完再设置成新的数据。CopyOnWriteArrayList适用于读多写少的并发场景,CopyOnWriteArraySet是线程安全版本的Set实现,它的内部通过一个CopyOnWriteArrayList来代理读写等操作,使得CopyOnWriteArraySet表现出了和CopyOnWriteArrayList一致的并发行为,他们的区别在于数据结构模型的不同,set不允许多个相同的元素插入容器中,具体的细节将在下文中分析。
CopyOnWriteArrayList的实现
/** The lock protecting all mutators */final transient ReentrantLock lock = new ReentrantLock();/** The array, accessed only via getArray/setArray. */private transient volatile Object[] array;
可以看到,CopyOnWriteArrayList使用了ReentrantLock来支持并发操作,array就是实际存放数据的数组对象。ReentrantLock是一种支持重入的独占锁,任意时刻只允许一个线程获得锁,所以可以安全的并发去写数组
CopyOnWriteArrayList是如何使用这个lock来实现并发写的,下面首先展示了add方法的代码:
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock(); //上锁,只允许一个线程进入try {Object[] elements = getArray(); // 获得当前数组对象int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝到一个新的数组中newElements[len] = e;//插入数据元素setArray(newElements);//将新的数组对象设置回去return true;} finally {lock.unlock();//释放锁}}
为了对比ArrayList,下面展示了ArrayList中的add方法的细节:
public boolean add(E e) {ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;}private void ensureCapacityInternal(int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}ensureExplicitCapacity(minCapacity);}private void ensureExplicitCapacity(int minCapacity) {modCount++;// overflow-conscious codeif (minCapacity - elementData.length > 0)grow(minCapacity);}private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);}
2、CopyOnWriteArraySet类似
6、公平锁
6.1、公平锁概述
公平锁指的是按照线程请求的顺序,来分配锁;而非公平锁指的是不完全按照请求的顺序,在一定情况下,可以允许插队。但需要注意这里的非公平并不是指完全的随机,不是说线程可以任意插队,而是仅仅“在合适的时机”插队
用图示来说明公平和非公平的场景,先来看公平的情况。假设我们创建了一个公平锁,此时有 4 个线程按顺序来请求公平锁,线程 1 在拿到这把锁之后,线程 2、3、4 会在等待队列中开始等待,然后等线程 1 释放锁之后,线程 2、3、4 会依次去获取这把锁,线程 2 先获取到的原因是它等待的时间最长
公平锁是一种思想: 多个线程按照申请锁的顺序来获取锁。在并发环境中,每个线程会先查看此锁维护的等待队列,如果当前等待队列为空,则占有锁,如果等待队列不为空,则加入到等待队列的末尾,按照FIFO的原则从队列中拿到线程,然后占有锁。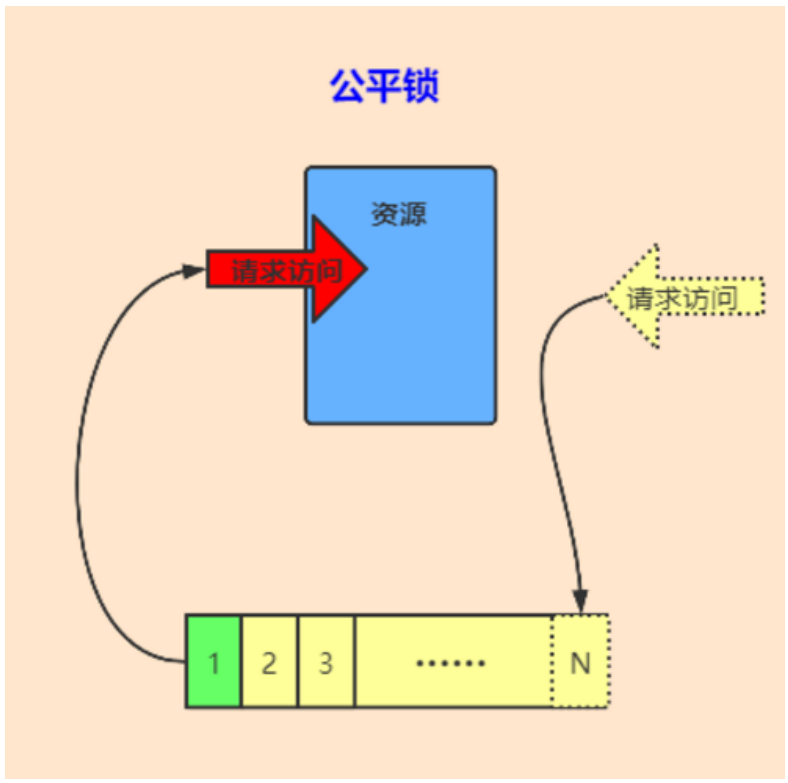

6.2、ReentrantLock实现公平锁
ReentrantLock的UML类图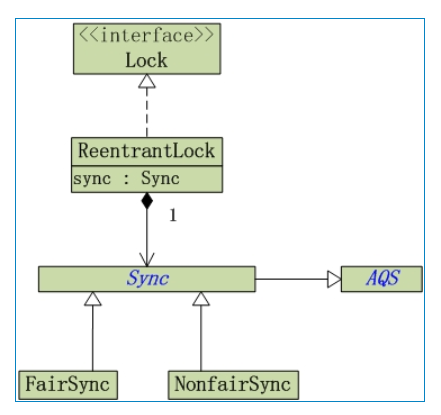
从图中可以看出:
(01) ReentrantLock实现了Lock接口。
(02) ReentrantLock与sync是组合关系。ReentrantLock中,包含了Sync对象;而且,Sync是AQS的子类;更重要的是,Sync有两个子类FairSync(公平锁)和NonFairSync(非公平锁)。ReentrantLock是一个独占锁,至于它到底是公平锁还是非公平锁,就取决于sync对象是”FairSync的实例”还是”NonFairSync的实例”。
1、ReentrantLock 默认采用非公平锁,除非在构造方法中传入参数 true 。
//默认public ReentrantLock() {sync = new NonfairSync();}//传入true or falsepublic ReentrantLock(boolean fair) {sync = fair ? new FairSync() : new NonfairSync();}
2、公平锁的 lock 方法:
static final class FairSync extends Sync {final void lock() {acquire(1);}// AbstractQueuedSynchronizer.acquire(int arg)public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}protected final boolean tryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {// 1. 和非公平锁相比,这里多了一个判断:是否有线程在等待if (!hasQueuedPredecessors() &&compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0)throw new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}}
们可以看到,在注释1的位置,有个!hasQueuedPredecessors()条件,意思是说当前同步队列没有前驱节点(也就是没有线程在等待)时才会去compareAndSetState(0, acquires)使用CAS修改同步状态变量。所以就实现了公平锁,根据线程发出请求的顺序获取锁。
6.3、公平锁实例
如果是公平锁,则会按照队列的顺序进行执行
package lockTest;import java.util.concurrent.locks.ReentrantLock;public class FairLockTest {//公平锁static ReentrantLock lock=new ReentrantLock(true);public static void main(String[] args) {new Thread(()->{//设置优先级 1-最低 10-最高Thread.currentThread().setPriority(1);lock.lock();System.out.println(Thread.currentThread().getName()+"执行");lock.unlock();},"线程A").start();new Thread(()->{//设置优先级 1-最低 10-最高Thread.currentThread().setPriority(10);lock.lock();System.out.println(Thread.currentThread().getName()+"执行");lock.unlock();},"线程B").start();}/*** 执行结果:* 线程A执行* 线程B执行*/}
实例2
package com.thread.fair;import java.util.concurrent.locks.ReentrantLock;/*** Created by Fant.J.*/public class MyFairLock {/*** true 表示 ReentrantLock 的公平锁*/private ReentrantLock lock = new ReentrantLock(true);public void testFail(){try {lock.lock();System.out.println(Thread.currentThread().getName() +"获得了锁");}finally {lock.unlock();}}public static void main(String[] args) {MyFairLock fairLock = new MyFairLock();Runnable runnable = () -> {System.out.println(Thread.currentThread().getName()+"启动");fairLock.testFail();};Thread[] threadArray = new Thread[10];for (int i=0; i<10; i++) {threadArray[i] = new Thread(runnable);}for (int i=0; i<10; i++) {threadArray[i].start();}}}
Thread-0启动Thread-0获得了锁Thread-1启动Thread-1获得了锁Thread-2启动Thread-2获得了锁Thread-3启动Thread-3获得了锁Thread-4启动Thread-4获得了锁Thread-5启动Thread-5获得了锁Thread-6启动Thread-6获得了锁Thread-8启动Thread-8获得了锁Thread-7启动Thread-7获得了锁Thread-9启动Thread-9获得了锁
6.4、公平锁优缺点
优点:
线程按照顺序获取锁,不会出现饿死现象(注:饿死现象是指一个线程的CPU执行时间都被其他线程占用,导致得不到CPU执行)。
缺点:
整体吞吐效率相对非公平锁要低,等待队列中除一个线程以外的所有线程都会阻塞,CPU唤醒线程的开销比非公平锁要大。
6.5、应用场景
使用场景的话呢,其实还是和他们的属性一一相关,举个栗子:如果业务中线程占用(处理)时间要远长于线程等待,那用非公平锁其实效率并不明显,但是用公平锁会给业务增强很多的可控制性。
7、非公平锁
7.1、非公平锁的概述
非公平锁指的是不完全按照请求的顺序,在一定情况下,可以允许插队。但需要注意这里的非公平并不是指完全的随机,不是说线程可以任意插队,而是仅仅“在合适的时机”插队。
假设当前线程在请求获取锁的时候,恰巧前一个持有锁的线程释放了这把锁,那么当前申请锁的线程就可以不顾已经等待的线程而选择立刻插队。但是如果当前线程请求的时候,前一个线程并没有在那一时刻释放锁,那么当前线程还是一样会进入等待队列
我们都知道非公平是 ReentrantLock的默认策略,如果我们不加以设置的话默认就是非公平的,难道我的这些排队的时间都白白浪费了吗,为什么别人比我有优先权呢?毕竟公平是一种很好的行为,而非公平是一种不好的行为
让我们考虑一种情况,假设线程 A 持有一把锁,线程 B 请求这把锁,由于线程 A 已经持有这把锁了,所以线程 B 会陷入等待,在等待的时候线程 B 会被挂起,也就是进入阻塞状态,那么当线程 A 释放锁的时候,本该轮到线程 B 苏醒获取锁,但如果此时突然有一个线程 C 插队请求这把锁,那么根据非公平的策略,会把这把锁给线程 C,这是因为唤醒线程 B 是需要很大开销的,很有可能在唤醒之前,线程 C 已经拿到了这把锁并且执行完任务释放了这把锁。相比于等待唤醒线程 B 的漫长过程,插队的行为会让线程 C 本身跳过陷入阻塞的过程,如果在锁代码中执行的内容不多的话,线程 C 就可以很快完成任务,并且在线程 B 被完全唤醒之前,就把这个锁交出去,这样是一个双赢的局面,对于线程 C 而言,不需要等待提高了它的效率,而对于线程 B 而言,它获得锁的时间并没有推迟,因为等它被唤醒的时候,线程 C 早就释放锁了,因为线程 C 的执行速度相比于线程 B 的唤醒速度,是很快的,所以 Java 设计非公平锁,是为了提高整体的运行效率。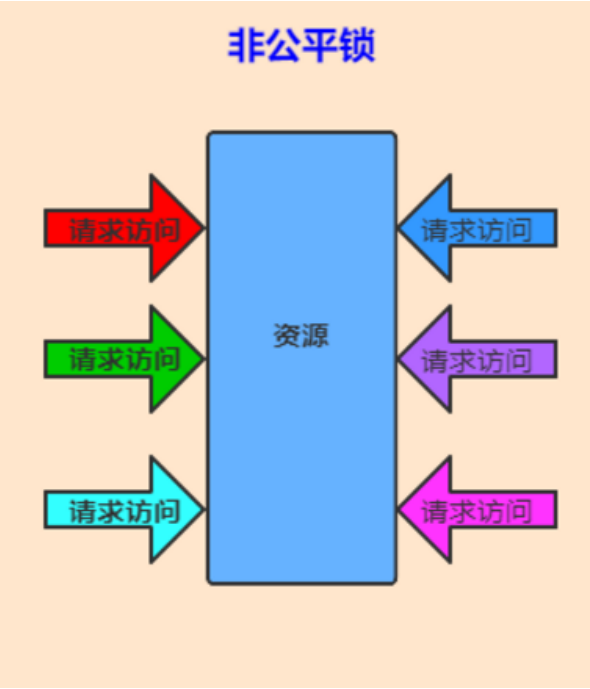
非公平锁是一种思想: 线程尝试获取锁,如果获取不到,则再采用公平锁的方式。多个线程获取锁的顺序,不是按照先到先得的顺序,有可能后申请锁的线程比先申请的线程优先获取锁。
优点: 非公平锁的性能高于公平锁。
缺点: 有可能造成线程饥饿(某个线程很长一段时间获取不到锁)
Java中的非公平锁:synchronized是非公平锁,ReentrantLock通过构造函数指定
该锁是公平的还是非公平的,默认是非公平的。
7.2、不公平的场景
假设线程 1 在解锁的时候,突然有线程 5 尝试获取这把锁,那么根据我们的非公平策略,线程 5 是可以拿到这把锁的,尽管它没有进入等待队列,而且线程 2、3、4 等待的时间都比线程 5 要长,但是从整体效率考虑,这把锁此时还是会交给线程 5 持有
可以看出,非公平情况下,存在抢锁“插队”的现象,比如Thread 1在释放锁后又能优先获取到锁,虽然此时在等待队列中已经有 Thread 2 ~ Thread 4 在排队了
7.3、ReentrantLock
7.3.1、底层实现
ReentrantLock 默认采用非公平锁,除非在构造方法中传入参数 true 。
//默认public ReentrantLock() {sync = new NonfairSync();}//传入true or falsepublic ReentrantLock(boolean fair) {sync = fair ? new FairSync() : new NonfairSync();}
非公平锁的lock方法
static final class NonfairSync extends Sync {final void lock() {// 2. 和公平锁相比,这里会直接先进行一次CAS,成功就返回了if (compareAndSetState(0, 1))setExclusiveOwnerThread(Thread.currentThread());elseacquire(1);}// AbstractQueuedSynchronizer.acquire(int arg)public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}protected final boolean tryAcquire(int acquires) {return nonfairTryAcquire(acquires);}}/*** Performs non-fair tryLock. tryAcquire is implemented in* subclasses, but both need nonfair try for trylock method.*/final boolean nonfairTryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {//3.这里也是直接CAS,没有判断前面是否还有节点。if (compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0) // overflowthrow new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}
非公平锁的实现在刚进入lock方法时会直接使用一次CAS去尝试获取锁,不成功才会到acquire方法中,如注释2。而在nonfairTryAcquire方法中并没有判断是否有前驱节点在等待,直接CAS尝试获取锁,如注释3。由此实现了非公平锁。
7.3.2、实例
非公平锁:
/*** Created by Fant.J.*/public class MyNonfairLock {/*** false 表示 ReentrantLock 的非公平锁*/private ReentrantLock lock = new ReentrantLock(false);public void testFail(){try {lock.lock();System.out.println(Thread.currentThread().getName() +"获得了锁");}finally {lock.unlock();}}public static void main(String[] args) {MyNonfairLock nonfairLock = new MyNonfairLock();Runnable runnable = () -> {System.out.println(Thread.currentThread().getName()+"启动");nonfairLock.testFail();};Thread[] threadArray = new Thread[10];for (int i=0; i<10; i++) {threadArray[i] = new Thread(runnable);}for (int i=0; i<10; i++) {threadArray[i].start();}}}
Thread-1启动Thread-0启动Thread-0获得了锁Thread-1获得了锁Thread-8启动Thread-8获得了锁Thread-3启动Thread-3获得了锁Thread-4启动Thread-4获得了锁Thread-5启动Thread-2启动Thread-9启动Thread-5获得了锁Thread-2获得了锁Thread-9获得了锁Thread-6启动Thread-7启动Thread-6获得了锁Thread-7获得了锁
7.4、synchronized
- synchronized是JVM内置锁,基于Monitor机制实现。
- 依赖底层操作系统的互斥原语Mutex(互斥量)。
- 表面上它是一个重量级锁,性能较低。
- 实际上JVM内置锁在1.5之后版本做了重大的优化,如锁粗化(Lock Coarsening)、锁消除(Lock Elimination)、轻量级锁(Lightweight Locking)、偏向锁(Biased Locking)、自适应自旋(Adaptive Spinning)等技术来减少锁操作的开销,内置锁的并发性能已经基本与Lock持平。
sychronized底层是基于mutex(互斥锁)的lock。sychrnozied并不是根据线程来获取锁的先后顺序来分配锁的,而是等待的线程都是先有机会获取锁的。这样做的目的是为提高性能,缺点则是可能会产生饥饿现象(某个线程一直得到锁)
8、共享锁
8.1、共享锁的概念
在ReentrantReadWriteLock中包含读锁和写锁,其中读锁是可以多线程共享的,即共享锁,而写锁是排他锁,在更改时候不允许其他线程操作。读写锁其实是一把锁,所以会有同一时刻不允许读写锁共存的规定。之所以要细分读锁和写锁也是为了提高效率,将读和写分离,对比ReentrantLock就可以发现,无论并发读还是写,它总会先锁住全部再说。
共享锁在同一时间能被多个线程持有,不过 AQS 中加锁条件的判断已经抽象成 tryAcquireShared 操作了,由具体的实现类实现。AQS 只负责唤醒等待共享锁的线程。
为了标识一个节点是在哪种模式(互斥/共享)下工作,Node 类需要增加额外的标识:
static final class Node {static final Node SHARED = new Node();static final Node EXCLUSIVE = null;static final int CANCELLED = 1;static final int SIGNAL = -1;static final int CONDITION = -2;static final int PROPAGATE = -3;volatile int waitStatus;Node nextWaiter;// ...}
当 nextWaiter 等于预定义的 SHARED 时认为是在共享模式下工作,后续也被用在条件变量的等待队列中。共享锁模式下节点有多种状态,用 waitStatus 存储,跟共享锁有关的主要有:
- SIGNAL,代表后继节点被阻塞了,当前节点释放后需要唤醒后继节点
- 为了避免竞态条件,抢锁时应先把 prev 节点的状态改成 SIGNAL,尝试抢锁,失败时再阻塞
- PROPAGATE,只在 head 节点设置,代表有共享锁释放,需要唤醒后续共享节点
- CANCELLED,用于取消等待,抢锁出错或线程中断时使用
共享锁是指该锁可被多个线程所持有。如果线程T对数据A加上共享锁后,则其他线程只能对A再加共享锁,不能加排他锁。获得共享锁的线程只能读数据,不能修改数据。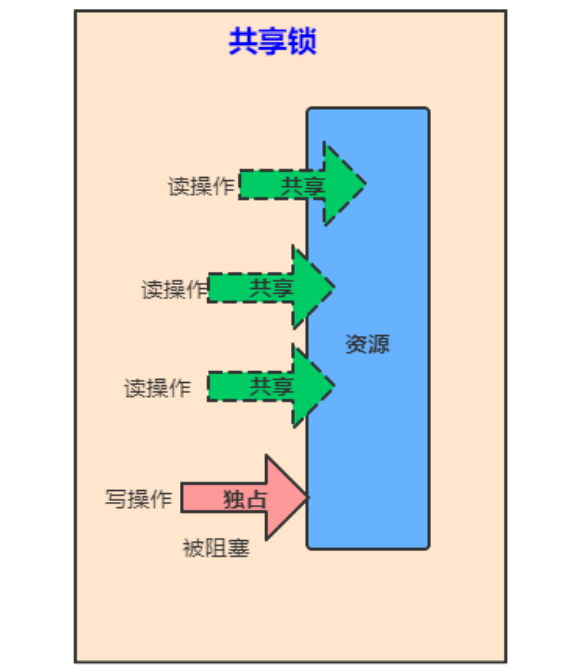
共享锁是一种思想: 可以有多个线程获取读锁,以共享的方式持有锁。和乐观锁、读写锁同义。
Java中用到的共享锁:ReentrantReadWriteLock。
8.2、读写锁的结构
ReentrantReadWriteLock采用读写分离的策略,允许多个线程可以同时获取读锁。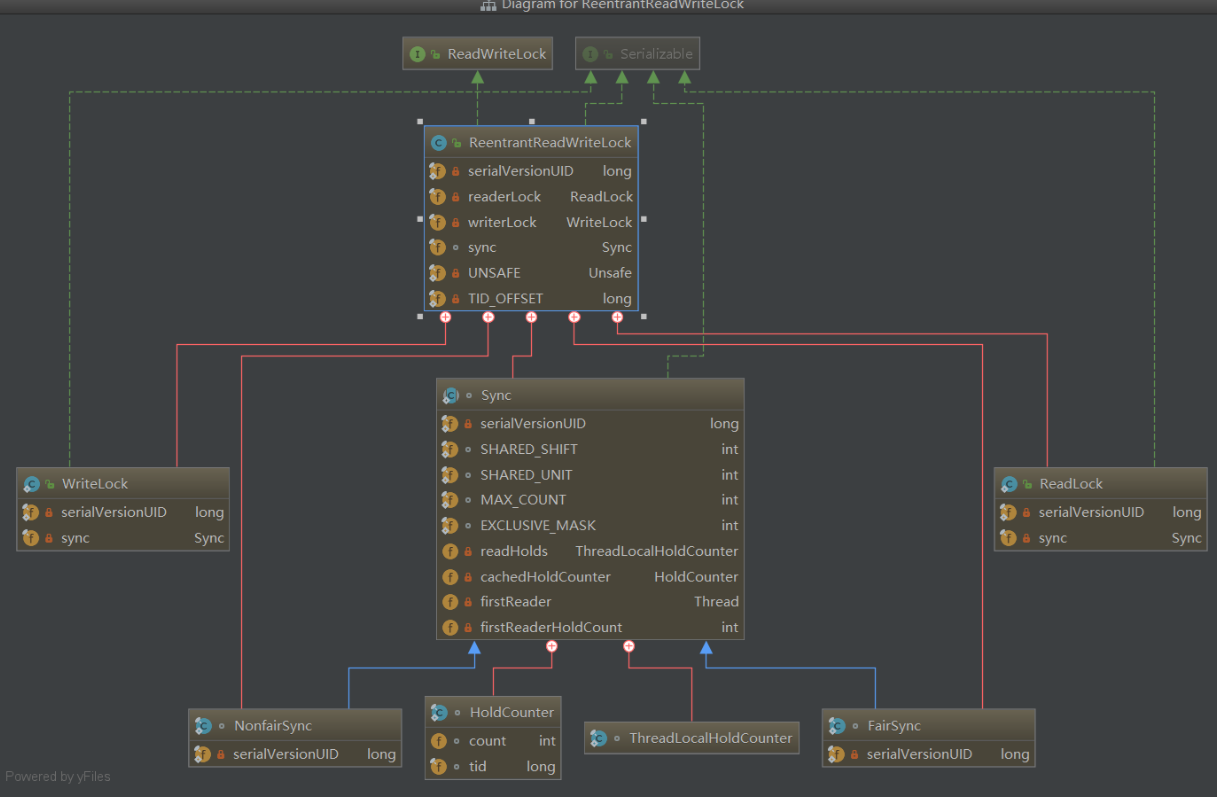
由类图可知,读写锁内部维护了一个ReadLock和一个WriteLock,他们依赖Sync实现具体功能,而Sync继承自AQS,并且提供了公平和非公平的实现。
1、ReentrantReadWriteLock源码
public class ReentrantReadWriteLock implements ReadWriteLock, java.io.Serializable {private final ReentrantReadWriteLock.ReadLock readerLock;//读锁?private final ReentrantReadWriteLock.WriteLock writerLock;//写锁?final Sync sync;public ReentrantReadWriteLock() {//使用默认(非公平)的排序属性创建一个新的ReentrantReadWriteLockthis(false);}public ReentrantReadWriteLock(boolean fair) {//使用给定的公平策略创建一个新的ReentrantReadWriteLocksync = fair ? new FairSync() : new NonfairSync();readerLock = new ReadLock(this);writerLock = new WriteLock(this);}public ReentrantReadWriteLock.WriteLock writeLock() { return writerLock; }//返回用于写入操作的锁?public ReentrantReadWriteLock.ReadLock readLock() { return readerLock; }//返回用于读取操作的锁?abstract static class Sync extends AbstractQueuedSynchronizer { ....static final class NonfairSync extends Sync {....}//非公平策略static final class FairSync extends Sync {.... }//公平策略public static class ReadLock implements Lock, java.io.Serializable {}//读锁?....public static class WriteLock implements Lock, java.io.Serializable {}//写锁?....}
说明:可以看到ReentrantReadWriteLock实现了ReadWriteLock接口,ReadWriteLock接口规范了读写锁方法,具体操作由子类去实现,同时还实现了Serializable接口,表示可以进行序列化操作。
2、读写锁的状态设计
读写锁需要在同步状态(一个整形变量)上维护多个读线程和一个写线程的状态。
读写锁对于同步状态的实现是在一个整形变量上通过“按位切割使用”:将变量切割成两部分,高16位表示读状态,也就是获取到读锁的次数,低16位表示获取到写线程的可重入次数。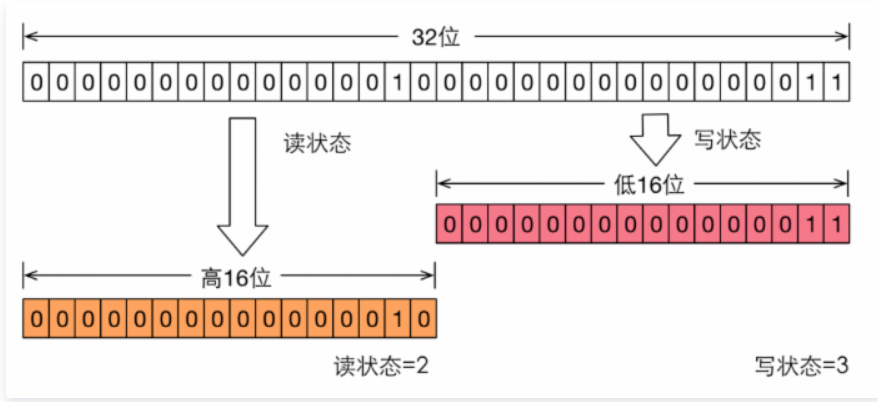
假设当前同步状态值为S,get和set的操作如下:(1)获取写状态:S&0x0000FFFF:将高16位全部抹去(2)获取读状态:S>>>16:无符号补0,右移16位(3)写状态加1:S+1(4)读状态加1:S+(1<<16)即S + 0x00010000在代码层的判断中,如果S不等于0,当写状态(S&0x0000FFFF),而读状态(S>>>16)大于0,则表示该读写锁的读锁已被获取。
3、读锁的获取与释放
类似于写锁,读锁的lock和unlock的实际实现对应Sync的 tryAcquireShared 和 tryReleaseShared方法。
tryAcquireShared
protected final int tryAcquireShared(int unused) {//获取当前线程Thread current = Thread.currentThread();//获取状态int c = getState();//如果写锁线程数!=0,且独占锁不是当前线程则返回失败,因为存在锁?降级若是当前线程已经获取了 //写锁,那么它可以继续尝试获得读锁。//当它把写锁释放后,只剩读锁了。这个过程可以理解为锁的降级。if (exclusiveCount(c) != 0 &&getExclusiveOwnerThread() != current)return -1;//读锁数量int r = sharedCount(c);if (!readerShouldBlock() &&//读锁是否需要等待(公平锁原则)r < MAX_COUNT &&//持有线程小于最大数(65535)compareAndSetState(c, c + SHARED_UNIT)) {//设置读取锁状态//r=0,表示第一个读锁线程,第一个读锁firstReader是不会加入到readHolds中if (r == 0) {firstReader = current;//设置第一个读线程firstReaderHoldCount = 1;//读线程占用的资源数为1} else if (firstReader == current) {//当前线程为第一个读线程,表示第一个读锁线程重入firstReaderHoldCount++;//占用资源数+1} else {//读锁数量不为0,并且不为当前线程HoldCounter rh = cachedHoldCounter;//获取计数器if (rh == null || rh.tid != getThreadId(current))//计数器为空,或者计数器的tid不为当前正在运行的线程的tidcachedHoldCounter = rh = readHolds.get();//获取当前线程的计数器else if (rh.count == 0)//计数器为0readHolds.set(rh);//加入到readHolds中rh.count++;//计数器+1}return 1;}return fullTryAcquireShared(current);}
其中sharedCount方法表示占有读锁的线程数量,源码如下:
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
说明:直接将state右移16位,就可以得到读锁的线程数量,因为state的高16位表示读锁,对应的第十六位表示写锁数量。
读锁获取锁的过程比写锁稍微复杂些,首先判断写锁是否为0并且当前线程不占有独占锁,直接返回;否则,判断读线程是否需要被阻塞并且读锁数量是否小于最大值并且比较设置状态成功,
若当前没有读锁,则设置第一个读线程firstReader和firstReaderHoldCount;若当前线程线程为第一个读线程,则增加firstReaderHoldCount;否则,将设置当前线程对应的HoldCounter对象的值。流程图如下。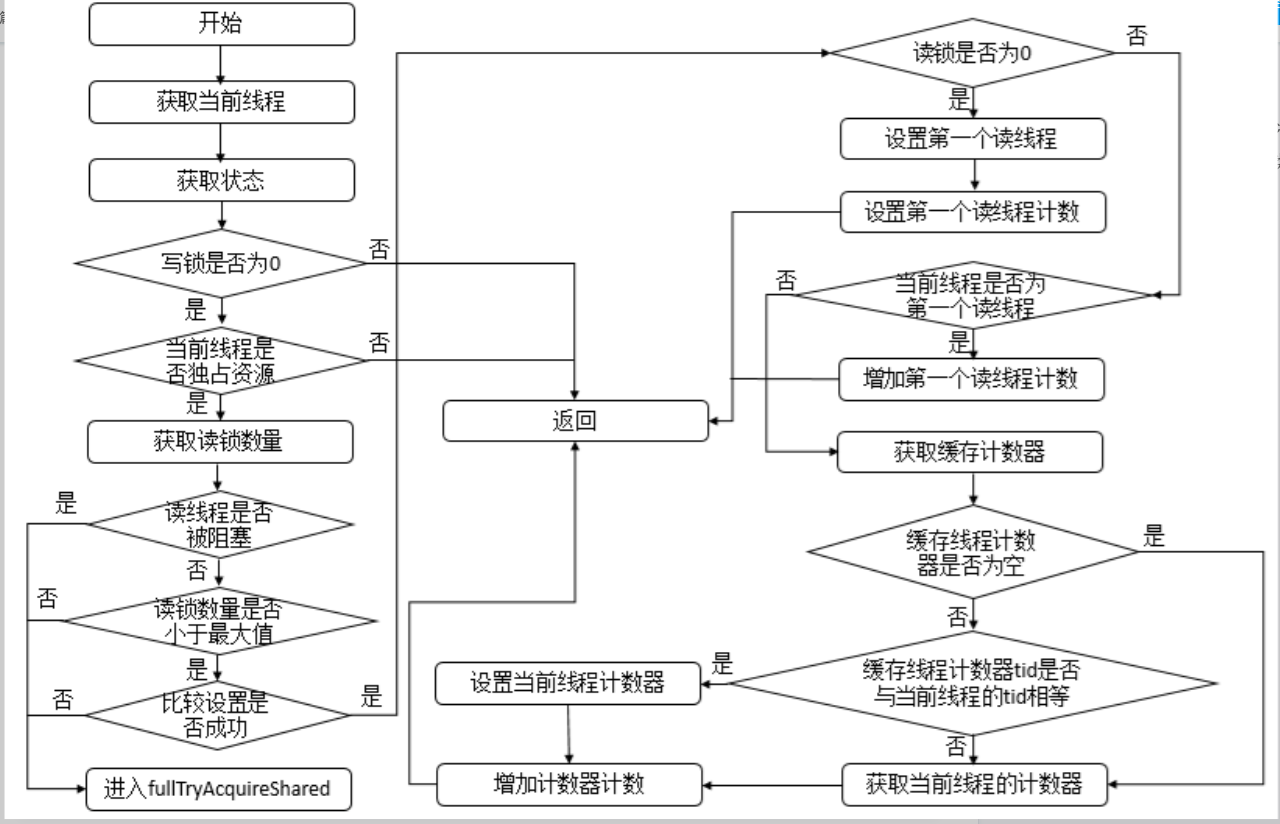
注意:更新成功后会在firstReaderHoldCount中或readHolds(ThreadLocal类型的)本地线程副本中记录当前线程的重入数,如果当前只有一个线程的话,还不需要动用ThreadLocal,直接往firstReaderHoldCount这个成员变量里存重入数, 当第二个线程来的时候,就要动用ThreadLocal变量的readHolds了,每个线程拥有自己的副本,用来保存自己的重入数。
final int fullTryAcquireShared(Thread current) {HoldCounter rh = null;for (;;) { // 无限循环// 获取状态int c = getState();if (exclusiveCount(c) != 0) { // 写线程数量不为0if (getExclusiveOwnerThread() != current) // 不为当前线程return -1;} else if (readerShouldBlock()) { // 写线程数量为0并且读线程被阻塞// Make sure we're not acquiring read lock reentrantlyif (firstReader == current) { // 当前线程为第一个读线程// assert firstReaderHoldCount > 0;} else { // 当前线程不为第一个读线程if (rh == null) { // 计数器不为空//rh = cachedHoldCounter;if (rh == null || rh.tid != getThreadId(current)) { // 计数器为空或者计数器的tid不为当前正在运行的线程的tidrh = readHolds.get();if (rh.count == 0)readHolds.remove();}}if (rh.count == 0)return -1;}}if (sharedCount(c) == MAX_COUNT) // 读锁数量为最大值,抛出异常throw new Error("Maximum lock count exceeded");if (compareAndSetState(c, c + SHARED_UNIT)) { // 比较并且设置成功if (sharedCount(c) == 0) { // 读线程数量为0// 设置第一个读线程firstReader = current;//firstReaderHoldCount = 1;} else if (firstReader == current) {firstReaderHoldCount++;} else {if (rh == null)rh = cachedHoldCounter;if (rh == null || rh.tid != getThreadId(current))rh = readHolds.get();else if (rh.count == 0)readHolds.set(rh);rh.count++;cachedHoldCounter = rh; // cache for release}return 1;}}}
说明:在tryAcquireShared函数中,如果下列三个条件不满足(读线程是否应该被阻塞、小于最大值、比较设置成功)则会进行fullTryAcquireShared函数中,它用来保证相关操作可以成功。其逻辑与tryAcquireShared逻辑类似,不再累赘。
4、读锁的释放
tryReleaseShared
protected final boolean tryReleaseShared(int unused) {// 获取当前线程Thread current = Thread.currentThread();if (firstReader == current) { // 当前线程为第一个读线程// assert firstReaderHoldCount > 0;if (firstReaderHoldCount == 1) // 读线程占用的资源数为1firstReader = null;else // 减少占用的资源firstReaderHoldCount--;} else { // 当前线程不为第一个读线程// 获取缓存的计数器HoldCounter rh = cachedHoldCounter;if (rh == null || rh.tid != getThreadId(current)) // 计数器为空或者计数器的tid不为当前正在运行的线程的tid// 获取当前线程对应的计数器rh = readHolds.get();// 获取计数int count = rh.count;if (count <= 1) { // 计数小于等于1// 移除readHolds.remove();if (count <= 0) // 计数小于等于0,抛出异常throw unmatchedUnlockException();}// 减少计数--rh.count;}for (;;) { // 无限循环// 获取状态int c = getState();// 获取状态int nextc = c - SHARED_UNIT;if (compareAndSetState(c, nextc)) // 比较并进行设置// Releasing the read lock has no effect on readers,// but it may allow waiting writers to proceed if// both read and write locks are now free.return nextc == 0;}}
说明:此方法表示读锁线程释放锁。首先判断当前线程是否为第一个读线程firstReader,若是,则判断第一个读线程占有的资源数firstReaderHoldCount是否为1,若是,则设置第一个读线程firstReader为空,否则,将第一个读线程占有的资源数firstReaderHoldCount减1;若当前线程不是第一个读线程,那么首先会获取缓存计数器(上一个读锁线程对应的计数器 ),若计数器为空或者tid不等于当前线程的tid值,则获取当前线程的计数器,如果计数器的计数count小于等于1,则移除当前线程对应的计数器,如果计数器的计数count小于等于0,则抛出异常,之后再减少计数即可。无论何种情况,都会进入无限循环,该循环可以确保成功设置状态state。其流程图如下。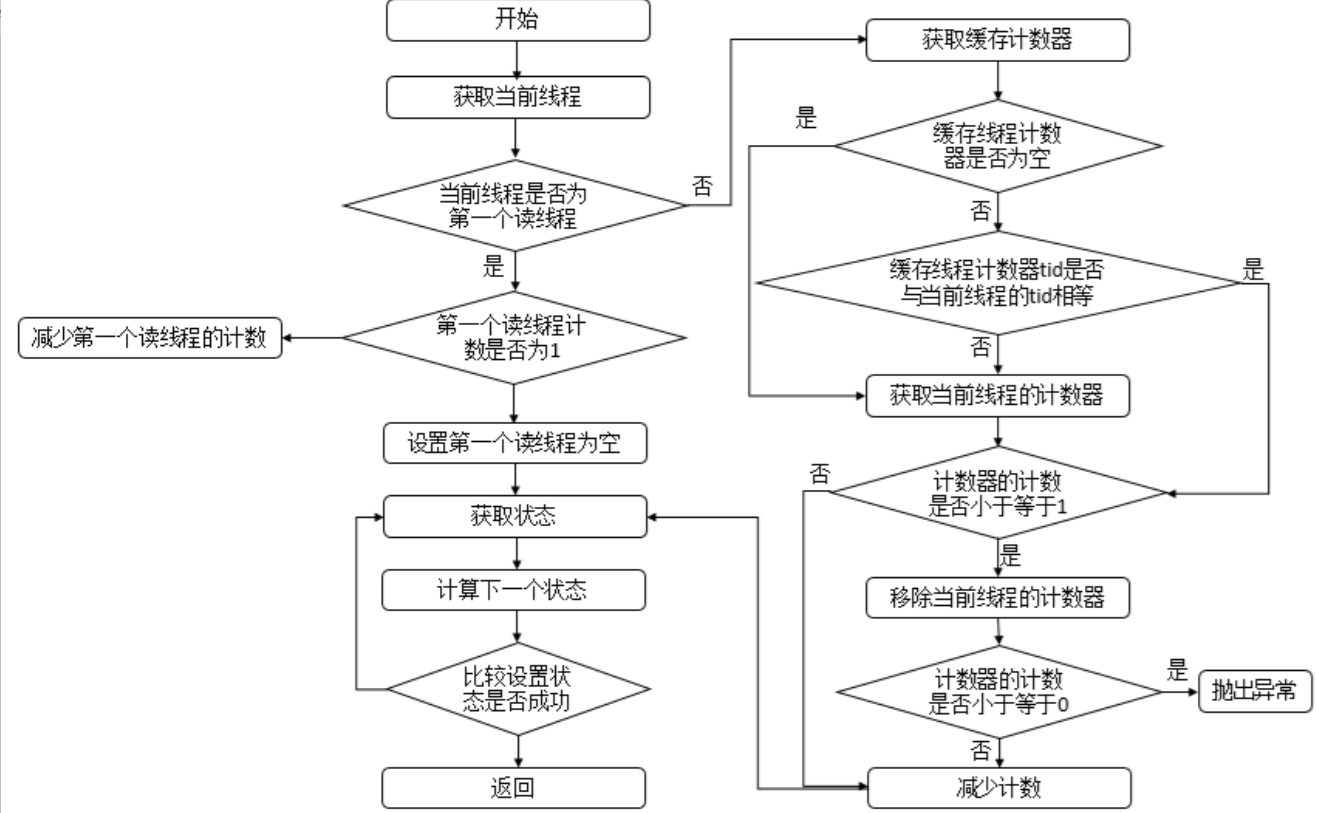
在读锁的获取、释放过程中,总是会有一个对象存在着,同时该对象在获取线程获取读锁是+1,释放读锁时-1,该对象就是HoldCounter。
要明白HoldCounter就要先明白读锁。前面提过读锁的内在实现机制就是共享锁,对于共享锁其实我们可以稍微的认为它不是一个锁的概念,它更加像一个计数器的概念。
一次共享锁操作就相当于一次计数器的操作,获取共享锁计数器+1,释放共享锁计数器-1。只有当线程获取共享锁后才能对共享锁进行释放、重入操作。所以HoldCounter的作用就是当前线程持有共享锁的数量,这个数量必须要与线程绑定在一起,否则操作其他线程锁就会抛出异常。
先看读锁获取锁的部分:
if (r == 0) {//r == 0,表示第一个读锁线程,第一个读锁firstRead是不会加入到readHolds中firstReader = current;firstReaderHoldCount = 1;} else if (firstReader == current) {//第一个读锁线程重入firstReaderHoldCount++;} else { //非firstReader计数HoldCounter rh = cachedHoldCounter;//readHoldCounter缓存//rh == null 或者 rh.tid != current.getId(),需要获取rhif (rh == null || rh.tid != current.getId())cachedHoldCounter = rh = readHolds.get();else if (rh.count == 0)readHolds.set(rh); //加入到readHolds中rh.count++; //计数+1}
这里为什么要搞一个firstRead、firstReaderHoldCount呢?而不是直接使用else那段代码?这是为了一个效率问题,firstReader是不会放入到readHolds中的,
如果读锁仅有一个的情况下就会避免查找readHolds。可能就看这个代码还不是很理解HoldCounter。我们先看firstReader、firstReaderHoldCount的定义:
private transient Thread firstReader = null;private transient int firstReaderHoldCount;
这两个变量比较简单,一个表示线程,当然该线程是一个特殊的线程,一个是firstReader的重入计数。
HoldCounter的定义:
static final class HoldCounter {int count = 0;final long tid = Thread.currentThread().getId();}
在HoldCounter中仅有count和tid两个变量,其中count代表着计数器,tid是线程的id。但是如果要将一个对象和线程绑定起来仅记录tid肯定不够的,而且HoldCounter根本不能起到绑定对象的作用,只是记录线程tid而已。
诚然,在java中,我们知道如果要将一个线程和对象绑定在一起只有ThreadLocal才能实现。所以如下:
static final class ThreadLocalHoldCounterextends ThreadLocal<HoldCounter> {public HoldCounter initialValue() {return new HoldCounter();}}
故而,HoldCounter应该就是绑定线程上的一个计数器,而ThradLocalHoldCounter则是线程绑定的ThreadLocal。从上面我们可以看到ThreadLocal将HoldCounter绑定到当前线程上,同时HoldCounter也持有线程Id,这样在释放锁的时候才能知道ReadWriteLock里面缓存的上一个读取线程(cachedHoldCounter)是否是当前线程。这样做的好处是可以减少ThreadLocal.get()的次数,因为这也是一个耗时操作。需要说明的是这样HoldCounter绑定线程id而不绑定线程对象的原因是避免HoldCounter和ThreadLocal互相绑定而GC难以释放它们(尽管GC能够智能的发现这种引用而回收它们,但是这需要一定的代价),所以其实这样做只是为了帮助GC快速回收对象而已。
8.3、共享锁的应用
1、读读共享
public class MyTask {private ReentrantReadWriteLock lock = new ReentrantReadWriteLock();public void read() {try {lock.readLock().lock();System.out.println(Thread.currentThread().getName() + " start");Thread.sleep(10000);System.out.println(Thread.currentThread().getName() + " end");} catch (InterruptedException e) {e.printStackTrace();} finally {lock.readLock().unlock();}}}public class ReadReadTest {public static void main(String[] args) {final MyTask myTask = new MyTask();Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {myTask.read();}});t1.setName("t1");Thread t2 = new Thread(new Runnable() {@Overridepublic void run() {myTask.read();}});t2.setName("t2");t1.start();t2.start();}}
t2 startt1 startt1 endt2 end
2、写写互斥
public class MyTask {private ReentrantReadWriteLock lock = new ReentrantReadWriteLock();public void write() {try {lock.writeLock().lock();System.out.println(Thread.currentThread().getName() + " start");Thread.sleep(10000);System.out.println(Thread.currentThread().getName() + " end");} catch (InterruptedException e) {e.printStackTrace();} finally {lock.writeLock().unlock();}}}public class ReadReadTest {public static void main(String[] args) {final MyTask myTask = new MyTask();Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {myTask.write();}});t1.setName("t1");Thread t2 = new Thread(new Runnable() {@Overridepublic void run() {myTask.write();}});t2.setName("t2");t1.start();t2.start();}}
t1 startt1 endt2 startt2 end
3、读写互斥|写读互斥
public class MyTask {private ReentrantReadWriteLock lock = new ReentrantReadWriteLock();public void read() {try {lock.readLock().lock();System.out.println(Thread.currentThread().getName() + " start");Thread.sleep(10000);System.out.println(Thread.currentThread().getName() + " end");} catch (InterruptedException e) {e.printStackTrace();} finally {lock.readLock().unlock();}}public void write() {try {lock.writeLock().lock();System.out.println(Thread.currentThread().getName() + " start");Thread.sleep(10000);System.out.println(Thread.currentThread().getName() + " end");} catch (InterruptedException e) {e.printStackTrace();} finally {lock.writeLock().unlock();}}}public class ReadReadTest {public static void main(String[] args) {final MyTask myTask = new MyTask();Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {myTask.read();}});t1.setName("t1");Thread t2 = new Thread(new Runnable() {@Overridepublic void run() {myTask.write();}});t2.setName("t2");t1.start();try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}t2.start();}}
t1 startt1 endt2 startt2 end
8.4、共享锁的应用场景
适用于读多写少的场景,这是一个轻量级锁,减少加锁的cpu负担。
9、独占锁
9.1、独占锁概念
独占锁也叫排他锁,是指该锁一次只能被一个线程所持有。如果线程T对数据A加上排他锁后,则其他线程不能再对A加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。JDK中的synchronized和 JUC中Lock的实现类就是互斥锁。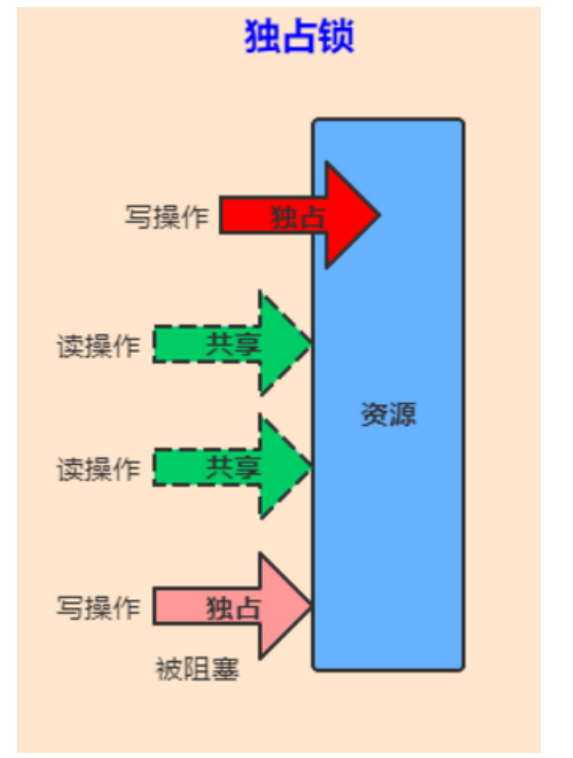
独占锁是一种思想: 只能有一个线程获取锁,以独占的方式持有锁。和悲观锁、互斥
锁同义。
Java中用到的独占锁: synchronized,ReentrantLock
9.2、ReentrantLock
1、概念
ReentrantLock 是可重入的独占锁 , 同 时 只能有 一个线程可 以 获取该锁,其他获取该锁的线程会被阻塞而被放入该锁的 AQS 阻塞队列里面
public ReentrantLock() {sync = new NonfairSync();}/*** Creates an instance of {@code ReentrantLock} with the* given fairness policy.** @param fair {@code true} if this lock should use a fair ordering policy*/public ReentrantLock(boolean fair) {sync = fair ? new FairSync() : new NonfairSync();}
ReentrantLock是基于AQS实现的一款独占锁,有公平锁和非公平锁两种模式。
protected final boolean tryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) { // state == 0,说明没有其他线程持有锁。if (!hasQueuedPredecessors() &&compareAndSetState(0, acquires)) {/*`!hasQueuedPredecessors()` 说明AQS的同步队列中,没有比自己更优先的线程在等待*/setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {/*如果当前线程正是`独占锁持有者`,叠加state,实现`可重入`,tryAcqire成功。也就是说AQS的同步列表中,有多个当前线程的节点。*/int nextc = c + acquires;if (nextc < 0)throw new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}
public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}
addWaiter就是AQS的入队列的操作。
当线程正在被持有则会入阻塞队列
2、实际应用
class X {private final ReentrantLock lock = new ReentrantLock();// ...public void m() {lock.lock(); // block until condition holdstry {// ... method body} finally {lock.unlock()}}}
9.3、synchronized
1、概念
我们一般用 synchronized 来做独占锁,而且线程是阻塞的。比如在设计单例的时候,同步代码块或者同步方法。
我们来看一个列子,我们写两个方法,都用 synchronized 锁住代码块。并且synchronized(lockObject)的lockObject锁住对象分别是两个不同的对象。
10、重量级锁
10.1、重量级锁的概念
相比起轻量级锁,再膨胀的锁,一般称之为重量级锁,因为是依赖于每个对象内部都有的monitor锁来实现的,而monitor又依赖于操作系统的MutexLock(互斥锁)来实现,所以一般重量级锁也叫互斥锁。
由于需要在操作系统的内核态和用户态之间切换的,需要将线程阻塞挂起,切换线程的上下文,再恢复等操作,所以当synchronized升级成互斥锁,依赖monitor的时候,开销就比较大了,而这也是之前为什么说synchronized是一个很重的操作的原因了。
当然,升级成互斥锁之后,锁对象头的Markword内容也是会变化的,其内容如下:
每次检查当前线程是否获得锁,其实就是检查Mutex的值是否为0,不为0,说明其为其线程所占有,此时操作系统就会介入,将线程阻塞,挂起,释放CPU时间,等待下一次的线程调度。
好了,到这里,对于synchronized所修改的同步方法或者同步代码块,虚拟机是如何操作的,大家应该也有一个简单的印象了。
当使用synchronized关键字的时候,在java1.6之后,根据不同的条件和场景,虚拟机是一步一步地将偏向锁升级成轻量级锁,再最终升级成重量级锁的,而这个过程是不可逆的,因为一旦升级成重量级锁,则说明偏向锁和轻量级锁是不适用于当前的应用场景的,那再降级回去也没什么意义。
从这一点,也可以看出,如果我们的应用场景本身就不适用于偏向锁和轻量级锁,那么我们在程序一开始,就应该禁用掉偏向锁和轻量级锁,直接使用重量级锁,省去无谓的开销。
我们知道,Java中的轻量级锁是基于CAS的,CAS是不走系统调用的,是在用户态的代码中“插入” cmpxchg 汇编指令,由这种CPU原语性质的汇编指令保证原子性。所以整体来看一直是在用户态代码中执行,而没有走入内核的代码。没有用户态/内核态之间的上下文切换。
而重量级锁才是进行了系统调用、用户态代码发起系统调用向内核申请mutex互斥量,CPU接着执行进入内核代码、内核代码进行了后续的高低电位锁总线等一系列硬件操作,最后互斥的设置了一个内存中的标志位称为互斥锁,然后把这个锁返回给了用户态代码。这个过程中当然是有上下文/用户态内核态切换的。
重量级锁可以理解为是大致这么一个关系:
synchronized(Java代码) -> Monitor(JVM底层C++) -> mutex(内核维护)
最底层是mutex,是内核维护的内存标志,外部使用需要走系统调用,然后再上一层是JVM在mutex这个同步原语的基础上进行了封装,提供了所谓Monitor监视器对象机制,然后再上层是Java语言,通过synchronized关键字进行同步操作来保护临界区代码段、当锁升级膨胀为重量级锁的时候就是使用监视器锁了,对应的进出临界区的字节码指令是monitorenter和monitorexit,这俩是由c++编写的代码逻辑,新版的jdk有所谓锁升级的一个优化逻辑(偏向锁 -> 轻量锁 -> 重量锁)。而旧版的jdk的内置锁直接就使用操作系统的互斥量,要进行用户态到内核态的切换。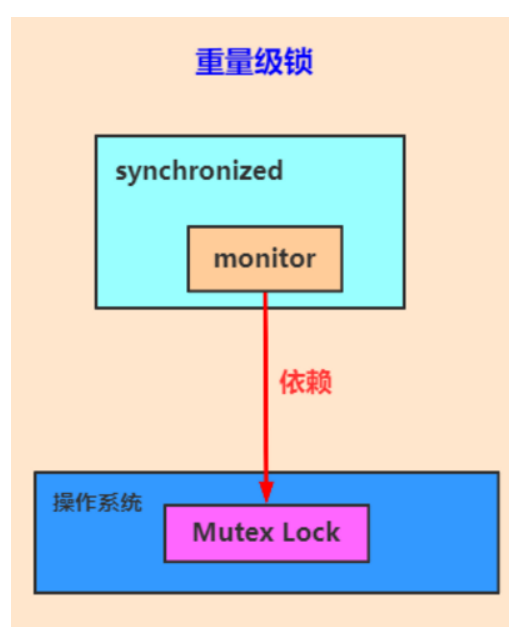
重量级锁是一种称谓:synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本身依赖底层的操作系统的 Mutex Lock来实现。操作系统实现线程的切换需要从用户态切换到核心态,成本非常高。这种依赖于操作系统 Mutex Lock来实现的锁称为重量级锁。为了优化synchonized,引入了轻量级锁,偏向锁。
Java中的重量级锁: synchronized
10.2、重量级锁底层实现
1、基本概念
volatile为什么不能保证原子性? 从JMM内存模型就可以看出来,多个线程同时修改一个变量,都是在自己本地内存中修改,volatile只是保证一个线程修改,另一个线程读的时候,发起修改的线程是强制刷新数据主存,过期其他线程的工作内存的缓存,没法做到多个线程在本地内存同时写的时候,限制只能有一个线程修改,因为线程自己修改自己内存的数据没有发生竞争关系。而且之后会给各自写入主内存,当然就保证不了只能有一个线程修改主内存的数据,做不到原子性了。
使用syncrhonized给修改这个操作加一把锁,一旦说某个线程加了一把锁之后,就会保证,其他的线程没法去读取和修改这个变量的值了,同一时间,只有一个线程可以读这个数据以及修改这个数据,别的线程都会卡在尝试获取锁那儿。这样也就不会出现并发同时修改,数据出错,原子性问题了。
JDK 早期 sychronized 使用的时候,直接创建的重量级锁,性能很不好。
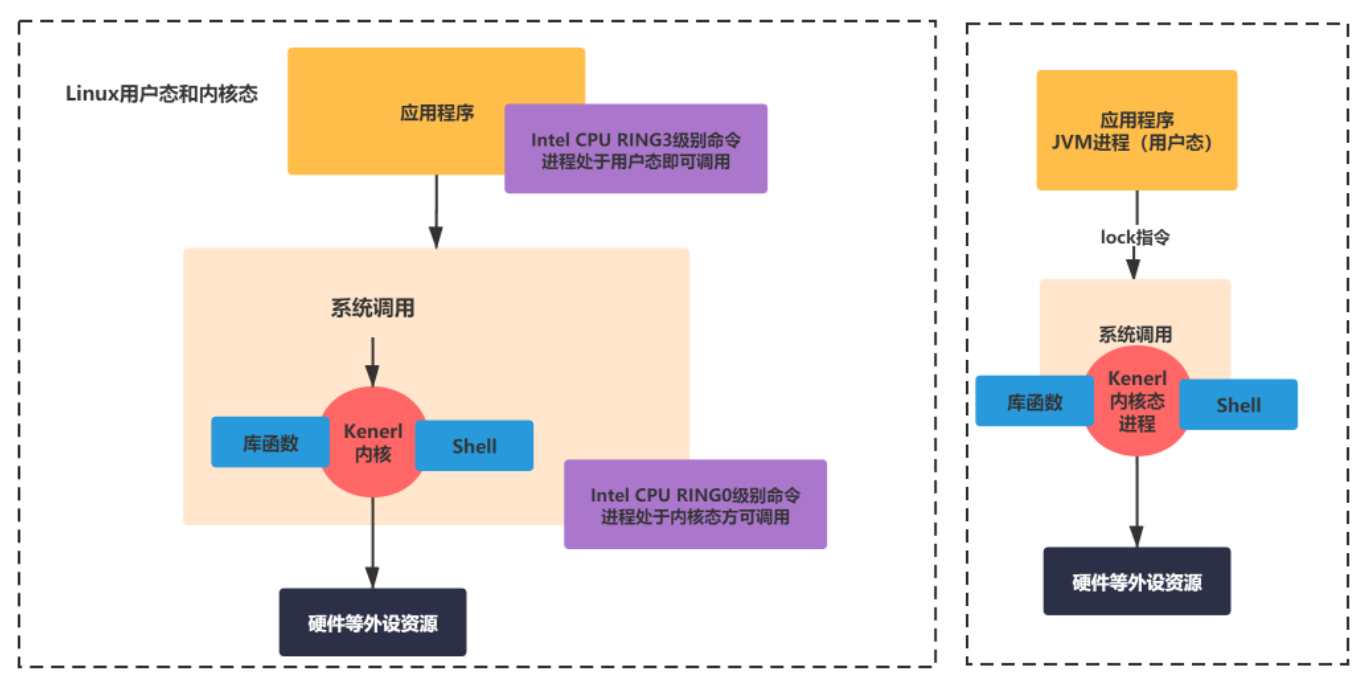
这个和synchronized有什么关系呢?因为synchronized加重量级锁的操作,是对硬件资源的锁指令操作,所以肯定是需要处于内核态的进程才可以操作,JVM的进程只是处于用户态的进程,所以需要向操作系统申请,这个过程肯定会很消耗资源的。
比如,synchronized的本质是JVM用户空间的一个进程(处于用户态)向操作系统(内核态)发起一个lock的锁指令操作 。
C++代码如下:
//Adding a lock prefix to an instruction on MP machine\#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; local; 1 : "
2、synchronized锁状态的记录
了解了sychronized的锁的几种类型后,怎么标识是什么样的synchronized锁呢?这个就要聊到Java的对象在JVM的内存中的结构了。不同虚拟机结构略有差别,这里讲一下HotSpot虚拟机中的对象结构: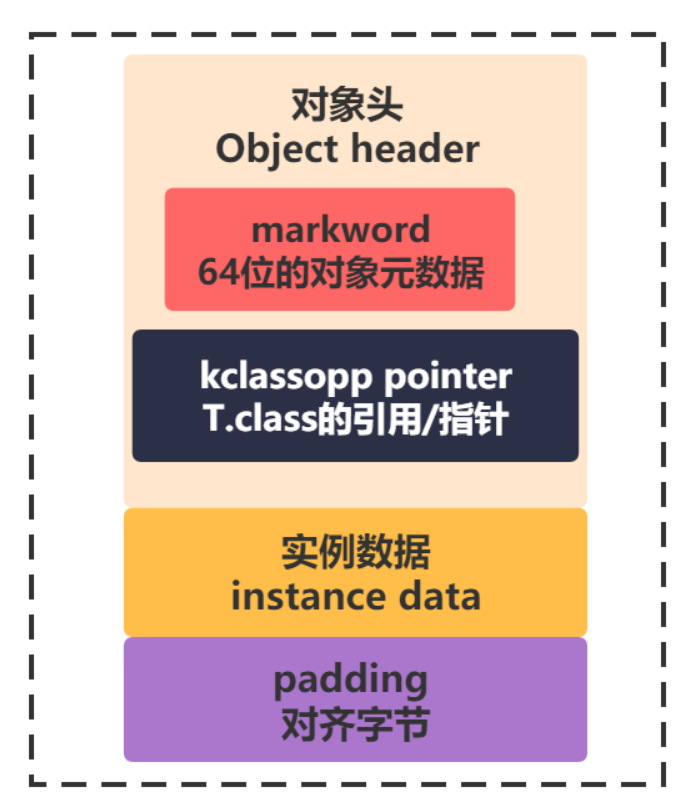
synchronized锁状态的信息就记录在markword中。markword在64位的操作系统上,8字节,64位大小的空间的区域。
不同的锁的标记在如下图所示: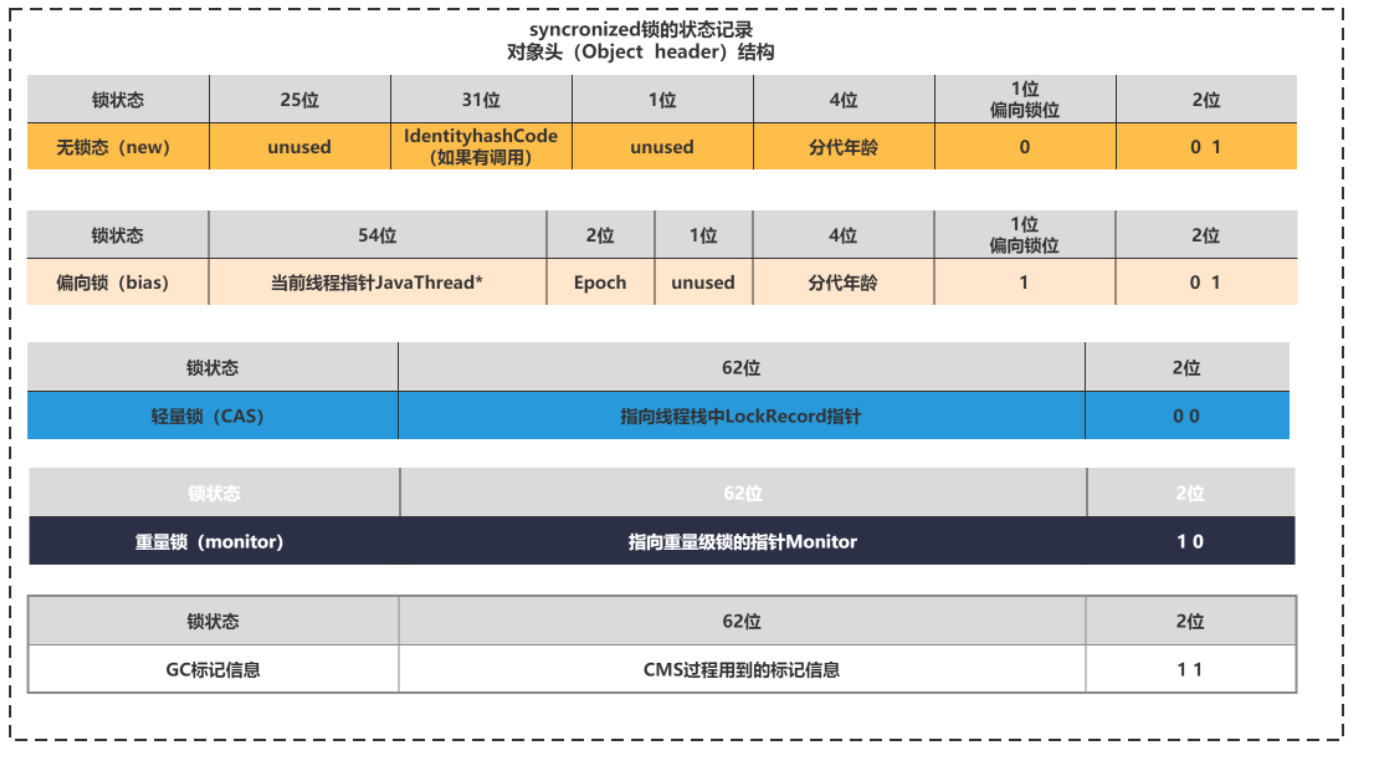
这个表你不用背下来,你只要知道,synchronized的轻量锁和重量锁通过2位即可以区分出来,偏向锁和无锁需要3位。
有了上面的基础知识后,就可以开始研究synchronized的底层原理了。
3、重量级锁加锁过程
1)初次加锁
回顾偏向锁、轻量级锁加锁流程核心:修改Mark Word。
而在膨胀为重量级锁时也是修改了Mark Word,不同的是此过程并没有线程占用重量级锁。来看看重量级锁的抢占过程:
#ObjectMonitor.cppvoid ATTR ObjectMonitor::enter(TRAPS) {//当前线程Thread * const Self = THREAD ;void * cur ;//尝试修改_owner字段为当前线程,也就是尝试获取锁cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;if (cur == NULL) {//修改成功,则获取了重量级锁return ;}//以下都是CAS失败后的处理//如果当前_owner值为当前线程,则认为是重入了该锁if (cur == Self) {//重入次数+1,成功获取了锁_recursions ++ ;return ;}//_owner值为Lock Record,说明当前线程是之前轻量级锁的持有者if (Self->is_lock_owned ((address)cur)) {//重入次数为1次_recursions = 1 ;//改为当前线程_owner = Self ;OwnerIsThread = 1 ;return ;}...{...for (;;) {//没有获取到锁,则执行该函数EnterI (THREAD) ;..._recursions = 0 ;_succ = NULL ;exit (false, Self) ;jt->java_suspend_self();}}
由上可知,enter(xx)函数主要做了如下事情:
先CAS尝试修改ObjectMonitor的_owner字段,会有几种结果:
1、锁没被其它线程占用,当前线程成功获取锁。
2、锁被当前线程占用,当前线程重入该锁,获取锁成功。
3、锁被LockRecord占用,而LockRecord又属于当前线程,属于重入,重入次数为1。
4、以上条件都不满足,调用EnterI()函数。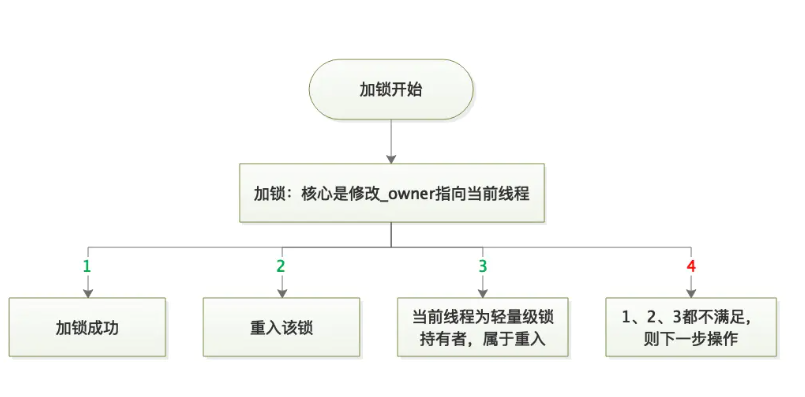
2)再次尝试加锁
初次获取锁失败后,会走到下面的流程,也就是EnterI()函数的实现:
#ObjectMonitor.cppvoid ATTR ObjectMonitor::EnterI (TRAPS) {//当前线程Thread * Self = THREAD ;//尝试加锁----------->(1)if (TryLock (Self) > 0) {return ;}//尝试自旋加锁----------->(2)if (TrySpin (Self) > 0) {return ;}//构造ObjectWaiter 节点ObjectWaiter node(Self) ;//挂起/唤醒线程重置参数Self->_ParkEvent->reset() ;//前驱节点为无效节点node._prev = (ObjectWaiter *) 0xBAD ;//当前节点状态为CXQ,也就是说节点在_cxq队列里node.TState = ObjectWaiter::TS_CXQ ;ObjectWaiter * nxt ;for (;;) {node._next = nxt = _cxq ;//将节点插入_cxq队列的头----------->(3)if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;//尝试获取锁----------->(4)if (TryLock (Self) > 0) {return ;}}...for (;;) {//再次尝试获取锁----------->(5)if (TryLock (Self) > 0) break ;if ((SyncFlags & 2) && _Responsible == NULL) {Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;}//挂起线程----------->(6)if (_Responsible == Self || (SyncFlags & 1)) {//挂起有超时时间Self->_ParkEvent->park ((jlong) RecheckInterval) ;} else {//挂起没有超时时间Self->_ParkEvent->park() ;}//唤醒后再次获取锁,成功则退出循环----------->(7)if (TryLock(Self) > 0) break ;//...还是一些自旋策略}//将节点从_cxq或_EntryList里移除----------->(8)UnlinkAfterAcquire (Self, &node) ;...return ;}
上述代码标注了8点重点,来看看更详细的解释:
(1)
TryLock 顾名思义尝试获取锁:
#ObjectMonitor.cppint ObjectMonitor::TryLock (Thread * Self) {for (;;) {//for 循环名存实亡void * own = _owner ;//中途判断_owner是否已经被更改,若是则退出if (own != NULL) return 0 ;//还是尝试更新_ownerif (Atomic::cmpxchg_ptr (Self, &_owner, NULL) == NULL) {return 1 ;}if (true) return -1 ;}}
(2)
TryLock 只执行一次CAS,而TrySpin顾名思义:自旋获取锁。
#ObjectMonitor.cppint ObjectMonitor::TrySpin_VaryDuration (Thread * Self) {...for (ctr = Knob_PreSpin + 1; --ctr >= 0 ; ) {if (TryLock(Self) > 0) {...return 1 ;}//休息一下继续SpinPause () ;}...}
可以看出TrySpin里多次调用TryLock,次数是10次。源码里指出经验值20-100可能最佳。
(3)
此处是死循环,直到插入队列成功或者获取了锁。
此处是往_cxq写数据,并且它的_next指针指向_cxq,因此每次新节点都放在队列头。又因为可能存在多线程修改_cxq,因此需要CAS。
(4)
插入队列失败后,再尝试获取锁。
(5)
又是个死循环,先尝试获取锁。
(6)
至此,线程放弃获取锁的动作,将自己挂起了,线程阻塞于此处,等待别的线程唤醒它。
(7)
当某个线程唤醒在(6)被挂起的线程后,被唤醒的线程立即再尝试获取锁,如果还是失败了,则继续回到(5)的循环。
(8)
获取锁成功后,因为前边已经加入到队列了,因此需要将节点从队列(_cxq/_EntryList)移除。
通过上述(1)~(8)的分析可知,enterI()函数主要做了如下事情:
1、多次尝试加锁。
2、实在不行将线程包装后加入到阻塞队列里。
3、再尝试获取锁。
4、失败后将自己挂起。
5、被唤醒后继续尝试获取锁。
6、成功则退出流程,失败继续走上面的流程。
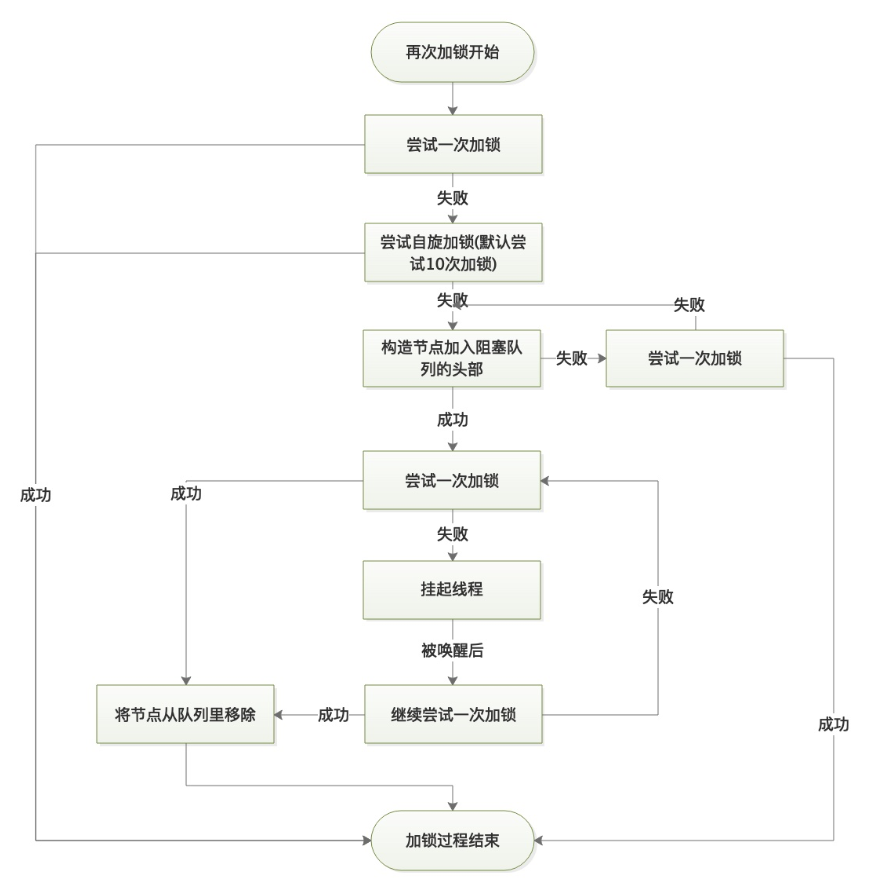
4、重量级锁解锁过程
上面分析了加锁的过程,它有两种结果:
1、成功获取锁,那么可以执行临界区代码。
2、获取锁失败,挂起等待别人唤醒。
关于2思考一个问题:是谁唤醒了它,如何唤醒的?
先来看看1,线程执行完临界区代码后需要释放锁,偏向锁和轻量级锁的释放上篇文章已经分析:若是释放失败,则会走到重量级锁的释放流程。
重量级锁的释放流程,也就是exit()函数的实现:
#ObjectMonitor.cppvoid ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) {Thread * Self = THREAD ;//释放锁的线程不一定是重量级锁的获得者-------->(1)if (THREAD != _owner) {if (THREAD->is_lock_owned((address) _owner)) {//释放锁的线程是轻量级锁的获得者,先占用锁_owner = THREAD ;} else {//异常情况return;}}if (_recursions != 0) {//是重入锁,简单标记后退出_recursions--;return ;}...for (;;) {if (Knob_ExitPolicy == 0) {//默认走这里//释放锁,别的线程可以抢占了OrderAccess::release_store_ptr (&_owner, NULL) ; // drop the lockOrderAccess::storeload() ; // See if we need to wake a successor//如果没有线程在_cxq/_EntryList等待,则直接退出if ((intptr_t(_EntryList)|intptr_t(_cxq)) == 0 || _succ != NULL) {TEVENT (Inflated exit - simple egress) ;return ;}//有线程在等待,再把之前释放的锁拿回来if (Atomic::cmpxchg_ptr (THREAD, &_owner, NULL) != NULL) {//若是失败,说明被人抢占了,直接退出return ;}} else {...}ObjectWaiter * w = NULL ;int QMode = Knob_QMode ;//此处省略代码//根据QMode不同,选不同的策略,主要是操作_cxq和_EntryList的方式不同//默认QMode=0w = _EntryList ;if (w != NULL) {//_EntryList不为空,则释放锁---------(2)ExitEpilog (Self, w) ;return ;}//_EntryList 为空,则看_cxq有没有数据w = _cxq ;if (w == NULL) continue ;//没有继续循环for (;;) {//将_cxq头节点置空ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;if (u == w) break ;w = u ;}if (QMode == 1) {...} else {// QMode == 0 or QMode == 2//_EntryList指向_cxq_EntryList = w ;ObjectWaiter * q = NULL ;ObjectWaiter * p ;//该循环的目的是为了将_EntryList里的节点前驱连接起来---------(3)for (p = w ; p != NULL ; p = p->_next) {guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;//改为ENTER状态p->TState = ObjectWaiter::TS_ENTER ;p->_prev = q ;q = p ;}}w = _EntryList ;if (w != NULL) {//释放锁---------(4)ExitEpilog (Self, w) ;return ;}}}
依旧是列出了4个点,exit()函数主要做了如下事情:
(1)
若膨胀的时候锁是轻量级锁,此时_owner指向Lock Record。当轻量级锁的占有者线程释放锁后会走到此,因此释放锁的线程不一定是重量级锁的获得者。
(2)
ExitEpilog (Self, w) 释放锁:
void ObjectMonitor::ExitEpilog (Thread * Self, ObjectWaiter * Wakee) {//从队列节点里取出ParkEventParkEvent * Trigger = Wakee->_event ;Wakee = NULL ;//释放锁,将_owner置空OrderAccess::release_store_ptr (&_owner, NULL) ;OrderAccess::fence() ; // ST _owner vs LD in unpark()//唤醒节点里封装的线程Trigger->unpark() ;}
release_store_ptr内部是汇编语句实现的原子操作。
(3)
之前_EntryList只用了后驱节点,也就是单向链表实现的队列,此处将前驱节点使用上了,也就是_EntryList变为双向链表了。
(4)
和(2)一样的作用,释放锁并唤醒对应的线程。
再来看看上面提出的2问题,从释放锁的流程已经得知:
当前占有锁的线程释放锁后会唤醒阻塞等待锁的线程
具体唤醒哪个线程,要看QMode值,以默认值QMode=0为例:
1、若是_EntryList队列不为空,则取出_EntryList队头节点并唤醒。
2、若是_EntryList为空,将_EntryList指向_cxq,并取出队头节点唤醒。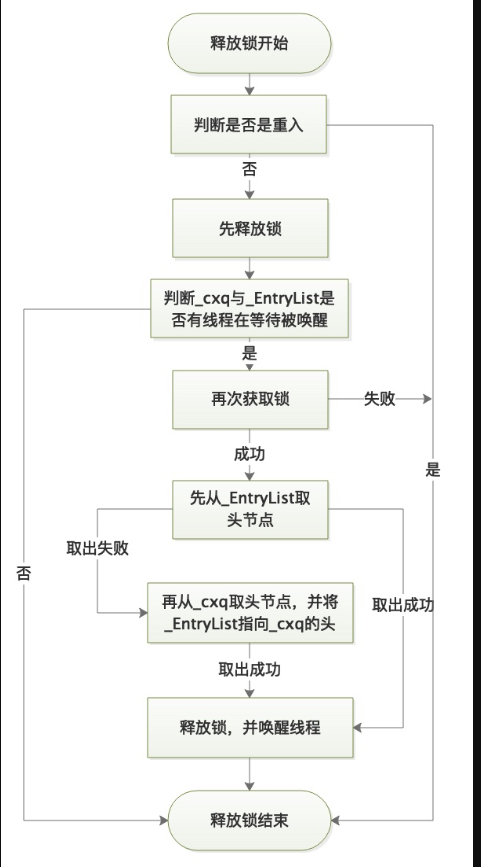
10.3、小结
从加锁、解锁的流程可以明显地看出:
1、加锁过程是不断地尝试加锁,实在不行了才放入队列里,而且还是插入队列头的位置,最后才挂起自己。
2、想象一种场景:现在A线程持有锁,B线程在队列里等待,在A释放锁的时候,C线程刚好插进来获取锁,还未等B被A唤醒,C就获取了锁,B苦苦等待那么久还是没有获取锁。B线程不排队的行为造成了不公平竞争锁。
3、再想象另一种场景:还是A线程持有锁,B线程在队列里等待,此时C线程也要获取锁,因此要进入队列里排队,此处进入的是队列头,也就是在B的前面排着。当A释放锁后,唤醒队列里的头节点,也就是C线程。C线程插队的行为造成了不公平竞争锁。
4、综合1、2、3点可知,因为有走后门(不排队)、插队(插到队头)、重量级锁是不公平锁。
综合加锁、解锁流程,用图表示如下:
图上流程对应的场景如下:
1、线程A先抢占锁,A在进入阻塞队列前已经成功获取锁。
2、而后线程B抢占锁,发现锁已被占有,于是加入阻塞队列队头。
3、最后线程C也来抢占锁,发现锁已经被占有,于是加入阻塞队列队头,此时B已经被C抢了队头位置。
4、当A释放锁后,唤醒阻塞队列里的队头线程C,C开始去抢占锁。
5、C拿到锁后,将自己从阻塞队列里移出。
6、后面的流程和之前一样。
上面的流程可能比较枯燥,用代码来演示以上场景:
public class TestThread {static Object object = new Object();static Thread a, b, c;public static void main(String args[]) {a = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("A before get lock");synchronized (object) {System.out.println("A get lock");try {Thread.sleep(1000);b.start();//等待b已经启动并去抢占锁Thread.sleep(1000);c.start();//等待b/c都已经启动,并且去抢占锁Thread.sleep(2000);} catch (Exception e) {}}System.out.println("A after get lock");}});a.start();b = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("B before get lock");synchronized (object) {System.out.println("B get lock");}System.out.println("B after get lock");}});b.start();c = new Thread(new Runnable() {@Overridepublic void run() {System.out.println("C before get lock");synchronized (object) {System.out.println("C get lock");}System.out.println("C after get lock");}});c.start();}}
10.4、优缺点
优点:
能够解决线程不安全的问题,可以保证方法或代码块在运行时,同一时刻只有一个线程可以进入到临界区(互斥性)所以它也是 排它锁 ,同时它还保证了共享变量的内存可见性。 在JDK1.6版本之前一直被称为’’重量级锁’’,但是在1.6之后进行了大量的优化.
缺点:
(1)效率低
synchronized关键字是不可中断的,这也就意味着一个等待的线程如果不能获取到锁将会一直等待,而不能再去做其他的事了。
对synchronized关键字的一个改进措施,那就是设置超时时间,如果一个线程长时间拿不到锁,就可以去做其他事情了。
(2)不够灵活
加锁和解锁的时候,每个锁只能有一个对象处理,这对于目前分布式等思想格格不入。
(3)无法知道是否成功获取到锁
锁如果获取到了,我们无法得知。既然无法得知也就很不容易进行改进。
11、轻量级锁
11.1、轻量级锁概念
为了优化Java的Lock机制,从Java6开始引入了轻量级锁的概念。
轻量级锁(Lightweight Locking)本意是为了减少多线程进入互斥的几率,并不是要替代互斥。
它利用了CPU原语Compare-And-Swap(CAS,汇编指令CMPXCHG),尝试在进入互斥前,进行补救。
CAS就是利用原子性和自旋来实现轻量级,进行无锁状态再进行锁升级。轻量级锁和重量级锁是同一个lock,只不过分了2个锁状态的地方(应该叫标记的地方)。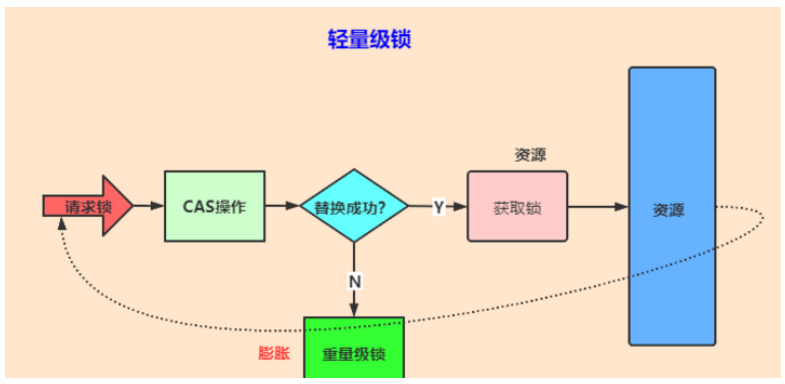
轻量级锁是JDK6时加入的一种锁优化机制: 轻量级锁是在无竞争的情况下使用CAS操作去消除同步使用的互斥量。轻量级是相对于使用操作系统互斥量来实现的重量级锁而言的。轻量级锁在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。如果出现两条以上的线程争用同一个锁的情况,那轻量级锁将不会有效,必须膨胀为重量级锁。
优点: 如果没有竞争,通过CAS操作成功避免了使用互斥量的开销。
缺点: 如果存在竞争,除了互斥量本身的开销外,还额外产生了CAS操作的开销,因此在有竞争的情况下,轻量级锁比传统的重量级锁更慢。 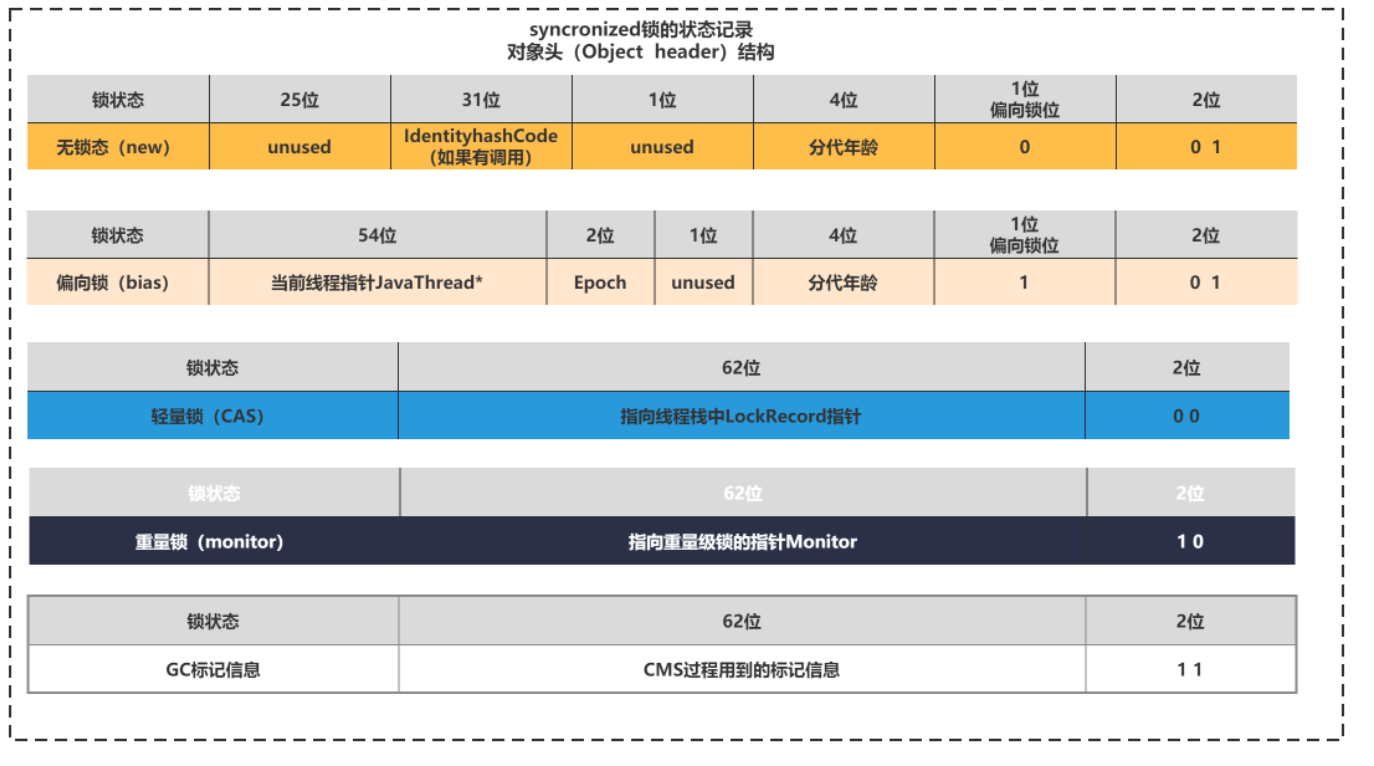
LockRecord就是轻量锁CAS的指针。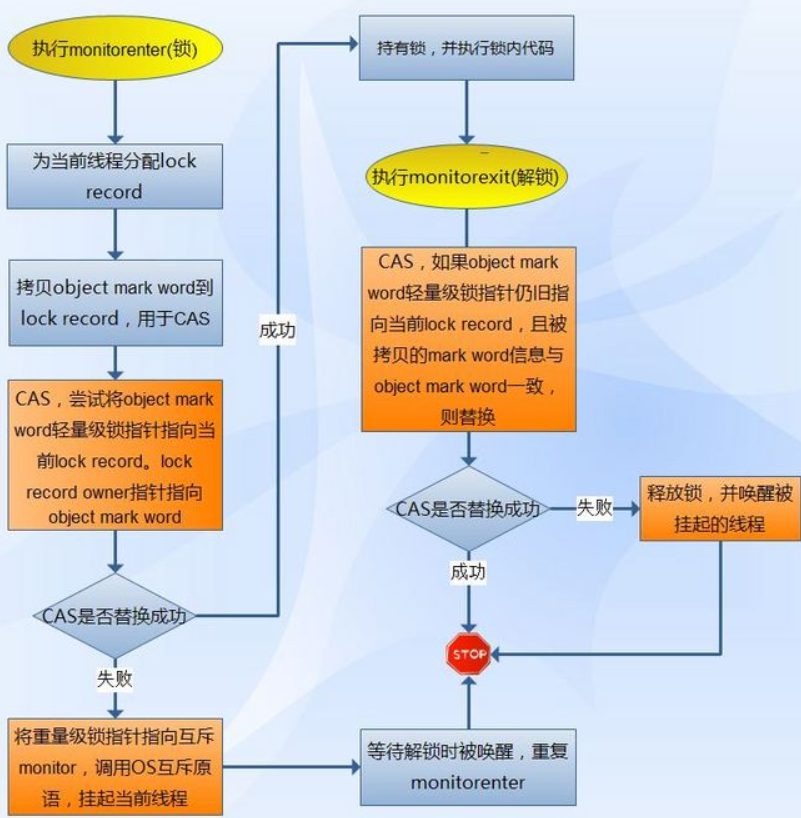
11.2、轻量级锁过程
1、每次指向到synchronized代码块时,都会创建锁记录(Lock Record)对象,每个线程都会包括一个锁记录的结构,锁记录内部可以储存对象的Mark Word和对象引用reference
lock record地址中 00轻量级锁 10重量级锁 11GC 再与Object的对象头的Hashcode交换 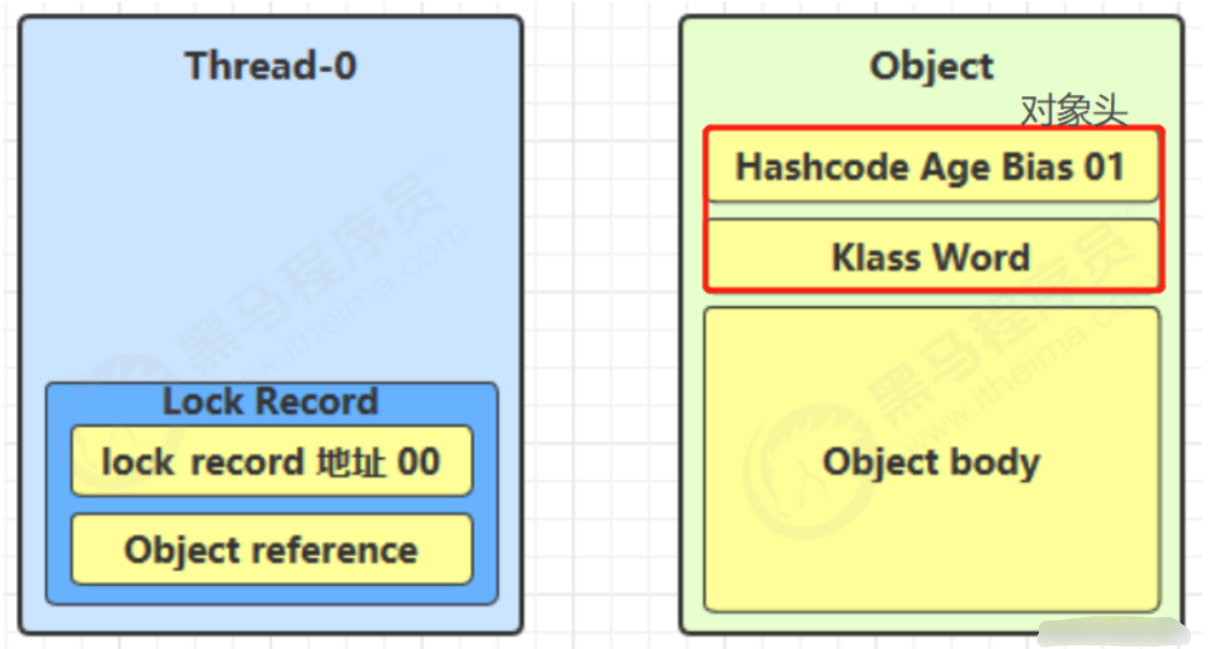
2、让锁记录中的Object reference指向对象,并且尝试用cas(compare and sweep)替换Object对象的Mark Word ,将Mark Word 的值存入锁记录中
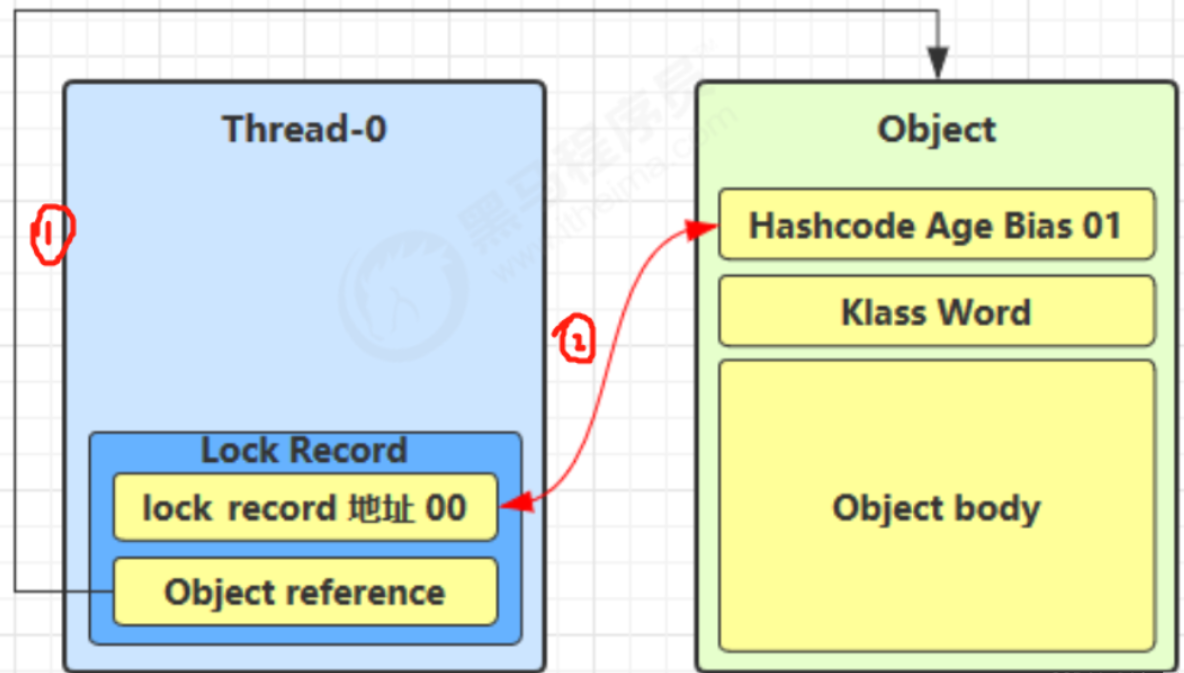
3、如果cas替换成功,那么对象的对象头储存的就是锁记录的地址和状态01,如下所示
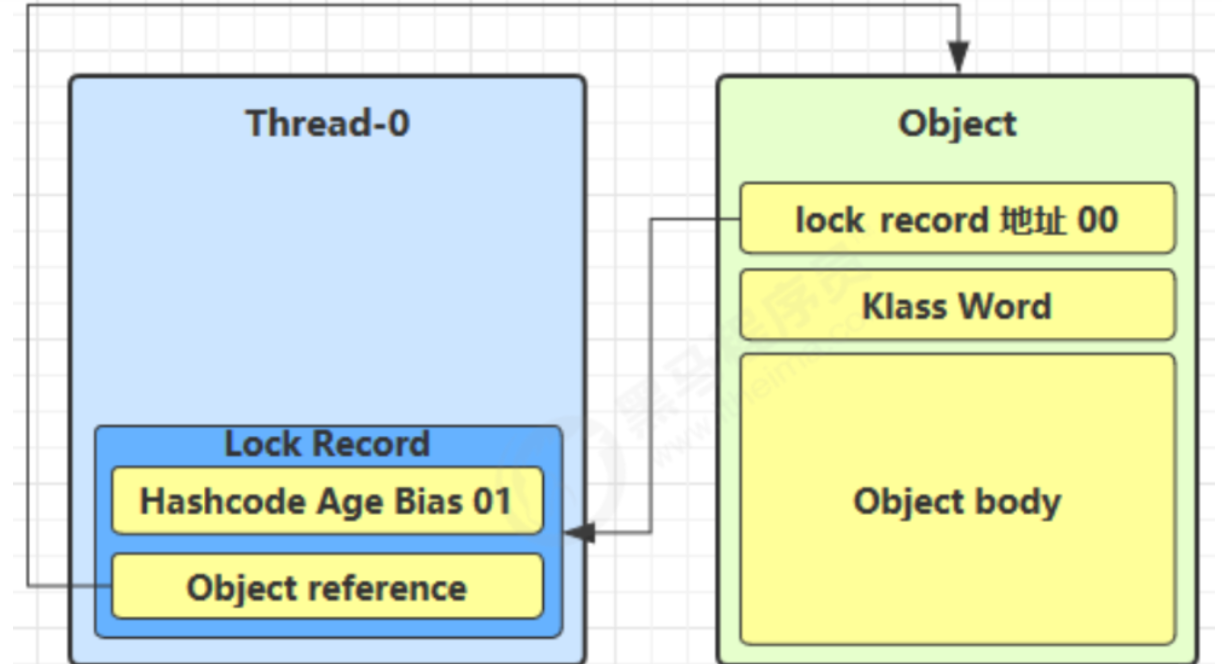
4、如果cas失败,有两种情况
- 如果是其它线程已经持有了该Object的轻量级锁,那么表示有竞争,将进入锁膨胀阶段
- 如果是自己的线程已经执行了synchronized进行加锁,那么那么再添加一条 Lock Record 作为重入的计数
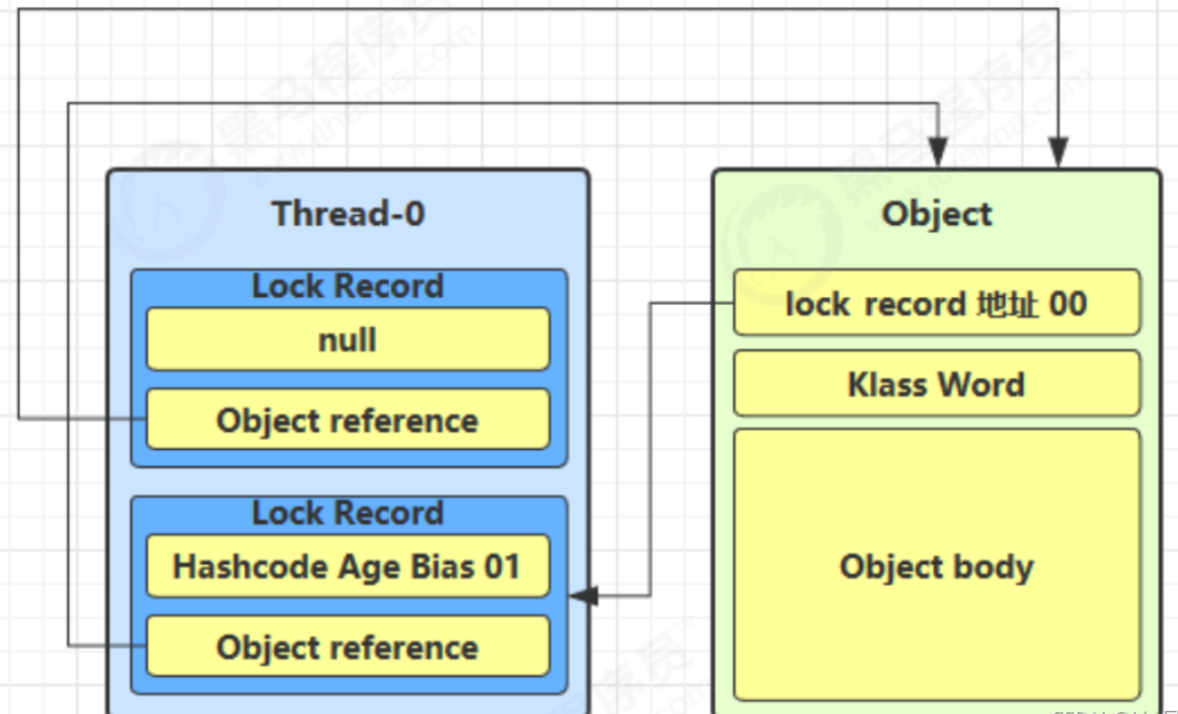
5、当线程退出synchronized代码块的时候,如果获取的是取值为 null 的锁记录 ,表示有重入,这时重置锁记录,表示重入计数减1
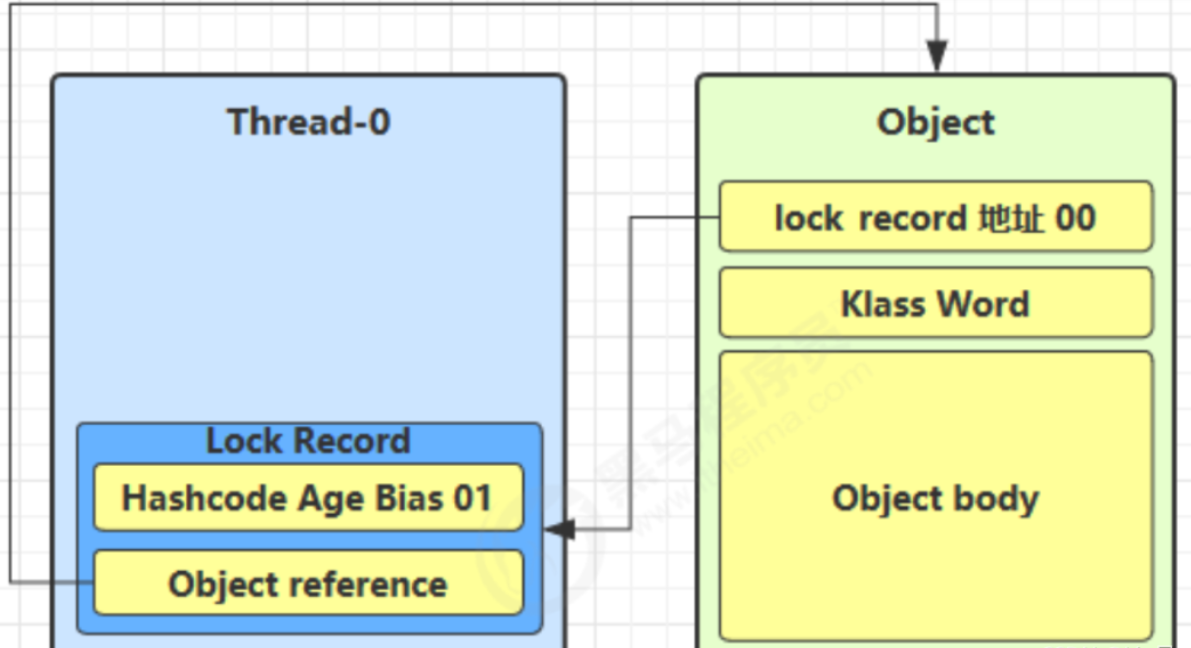
6、当线程退出synchronized代码块的时候,如果获取的锁记录取值不为 null,那么使用cas将Mark Word的值恢复给对象
- 成功则解锁成功
- 失败,则说明轻量级锁进行了锁膨胀或已经升级为重量级锁,进入重量级锁解锁流程
无锁状态获取锁
线程执行到同步块时,同步对象处于无锁状态,锁标志位为01,偏向标志位为0,偏向锁被禁用,对象处于无锁态。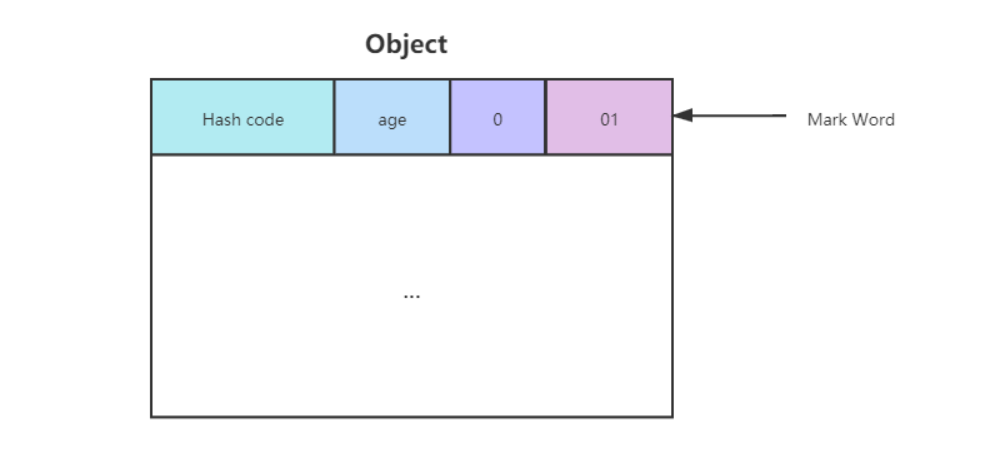
在加锁前,虚拟机需要在当前线程的栈帧中建立锁记录(Lock Record)的空间。Lock Record 中包含一个 _displaced_header 属性,用于存储锁对象的 Mark Word 的拷贝。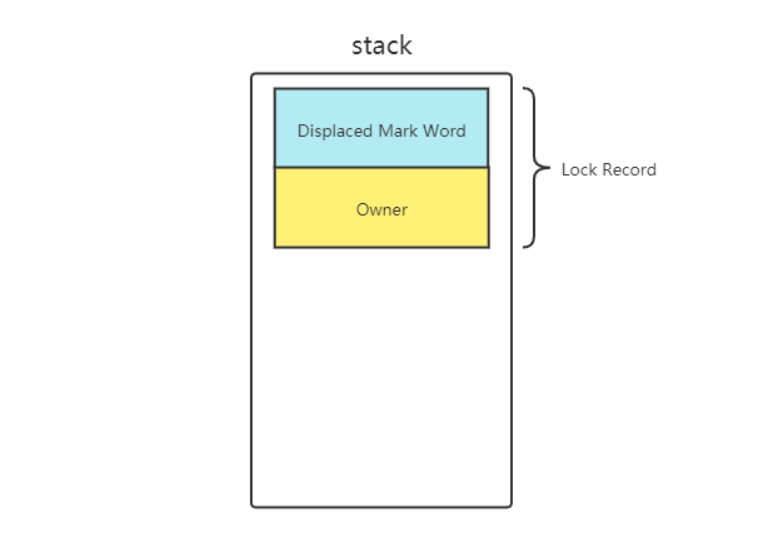
将锁对象的 Mark Word 复制到锁记录中,这个复制过来的记录叫做 Displaced Mark Word。具体来讲,是将 mark word 放到锁记录的 _displaced_header 属性中,将Owner指向当前对象。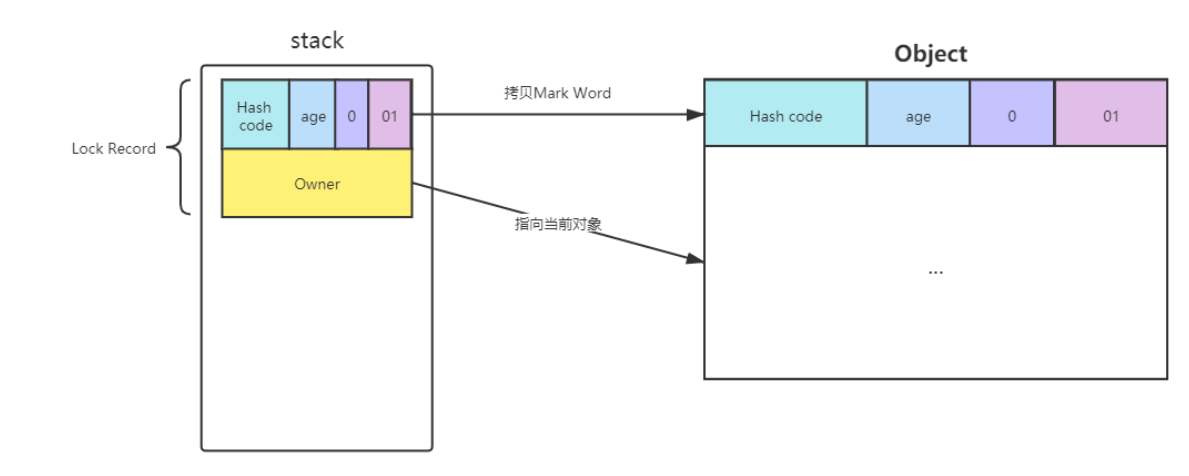
虚拟机使用 CAS 操作尝试将锁对象的 Mark Word 更新为指向锁记录的指针。如果更新成功,这个线程就获得了该对象的锁。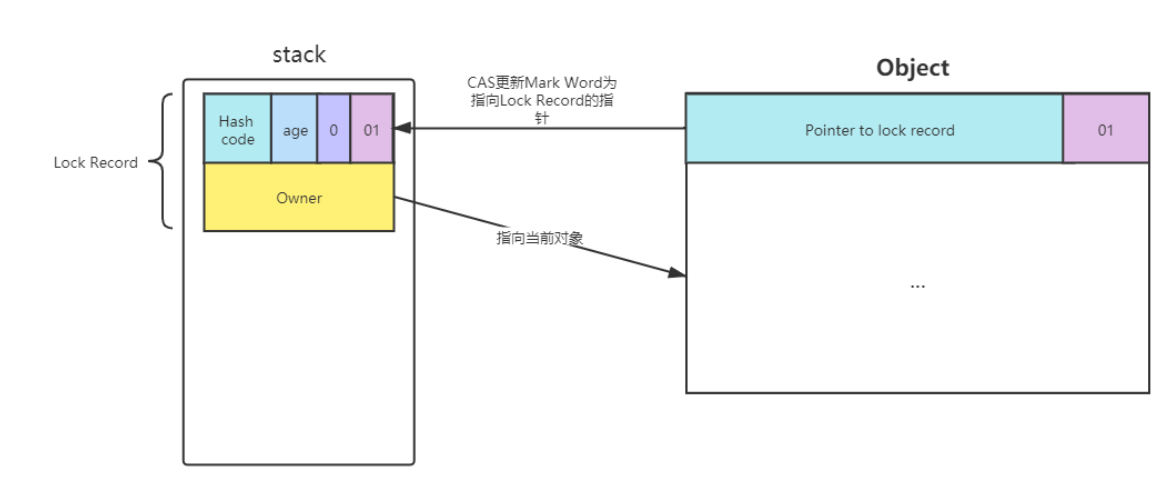
更新成功后,需要修改原对象头Mark Word中的锁状态标志位为00,目的是告诉其它线程此对象已经被轻量级锁定。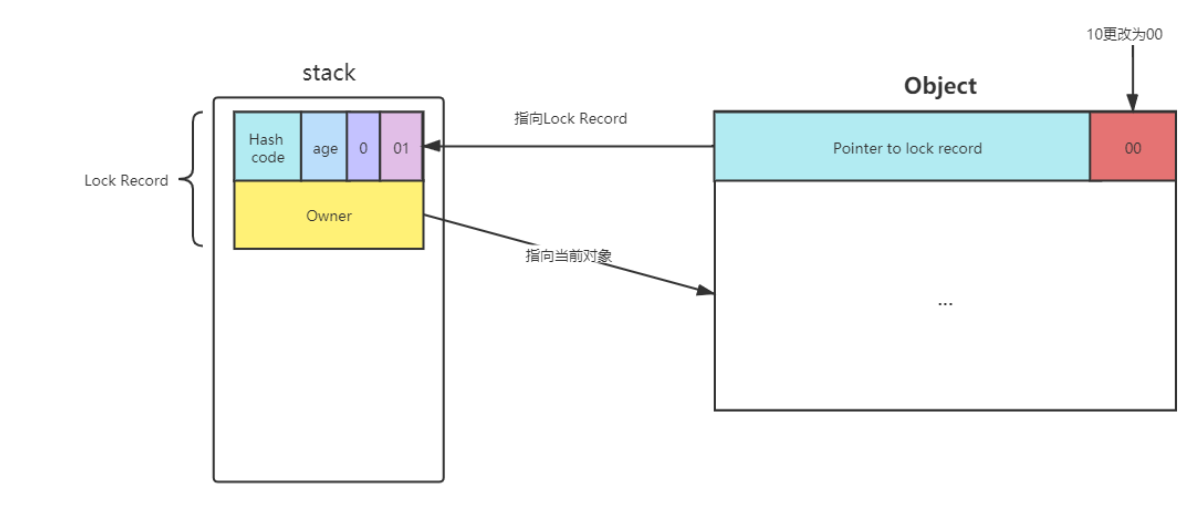
重入锁
当对象处于加锁状态时,会去检验Mark Word是否指向当前线程的栈帧,如果是则将刚刚建立的Lock Record中的Displaced Mark Word设置为null,记录线程重入锁。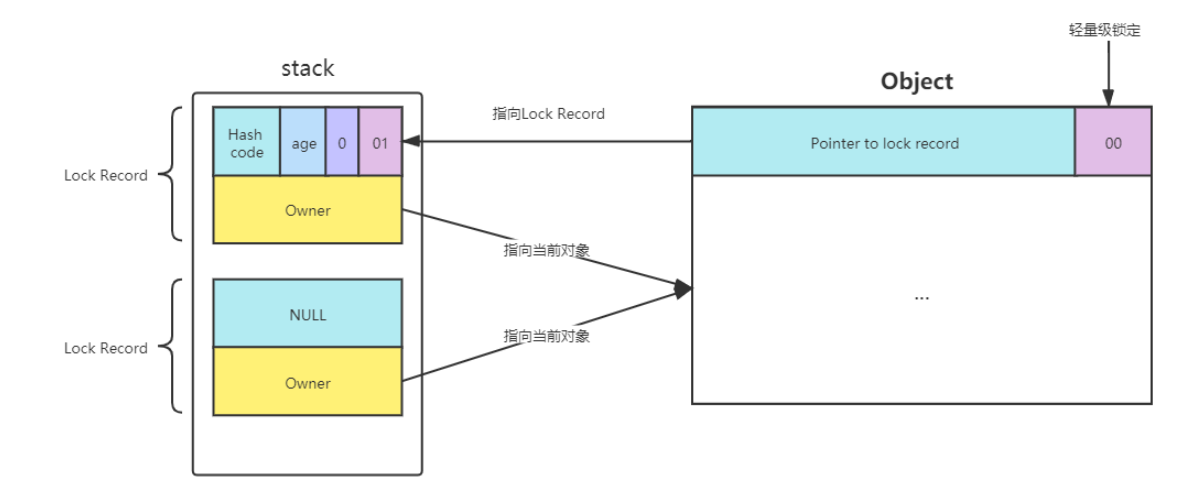
非重入锁
如果指向的不是当前线程的栈帧则会触发锁膨胀,膨胀为重量级锁。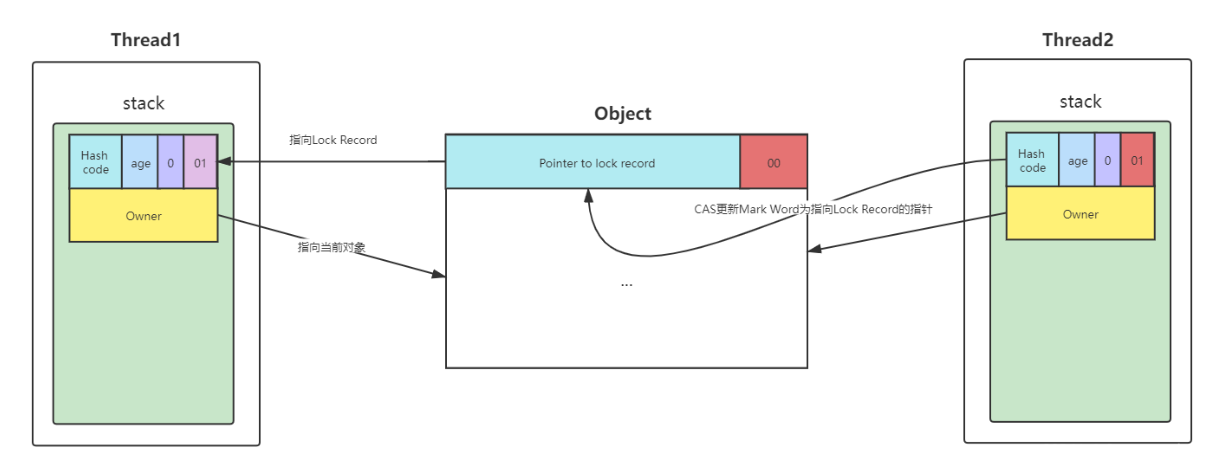
Thread2把锁膨胀为重量级锁,Thread1获取到重量级锁,Thread2适应性自旋尝试获取锁,到达临界值后进入等待队列阻塞。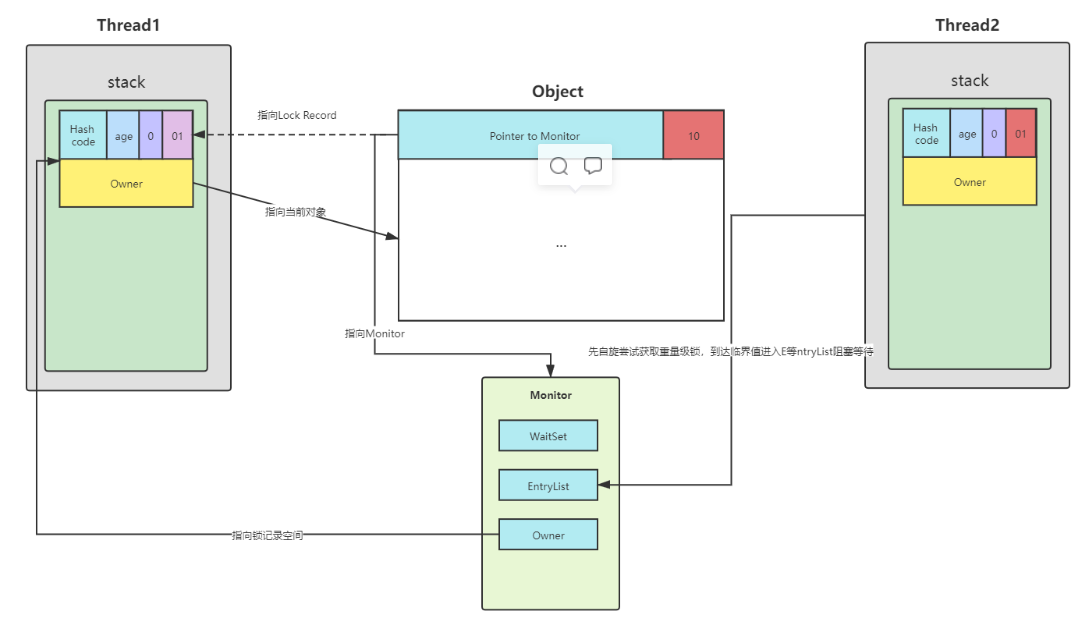
这里注意执行锁膨胀的线程为Thread2,而非原轻量级锁的持有者Thread1。
非重入释放锁
解锁的思路是使用 CAS 操作把当前线程的栈帧中的 Displaced Mark Word 替换回锁对象中去,如果替换成功,则解锁成功。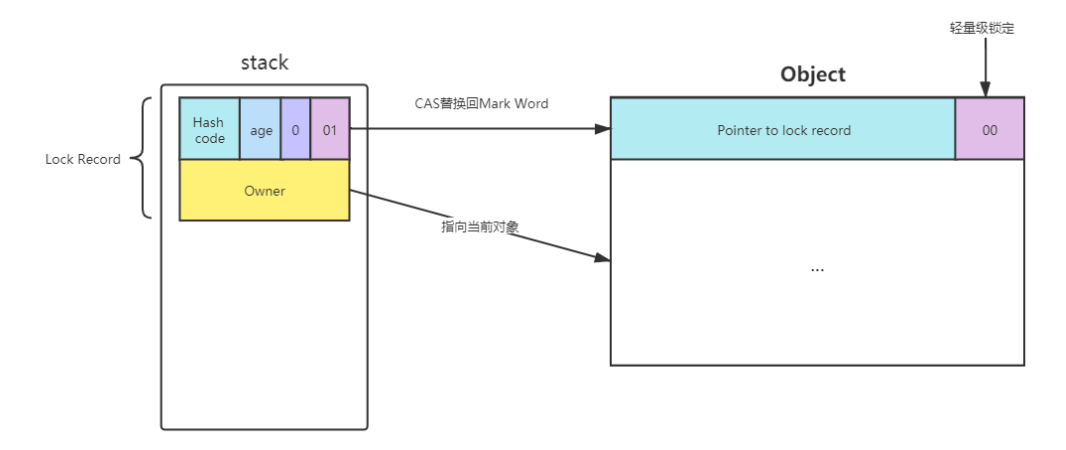
CAS成功
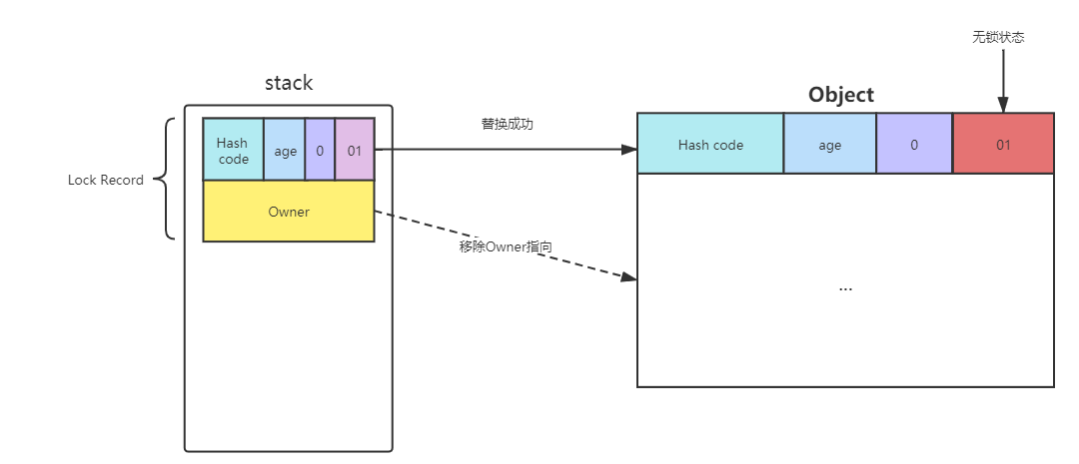
失败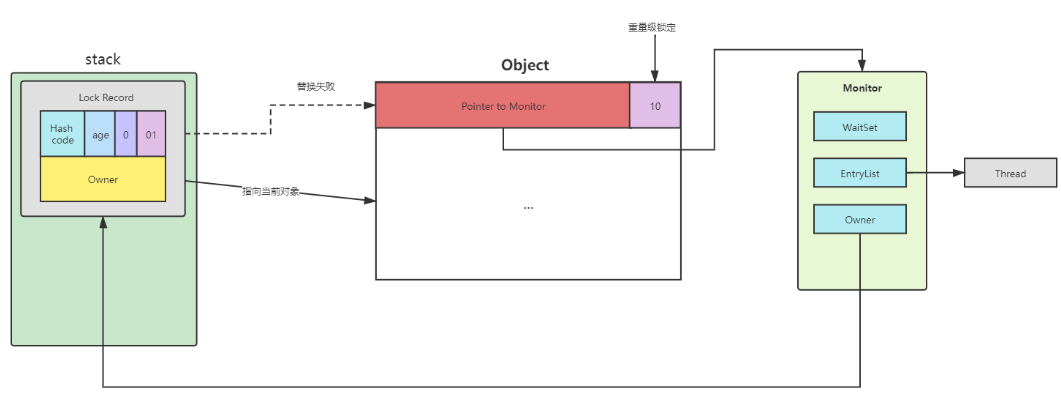
轻量级锁未释放前被其它线程尝试获取,此时Mark Word指针已经被替换为指向Monitor,释放锁时CAS会失败,此时需要走重量级解锁流程。
重入释放锁
加锁时,如果是锁重入,会将 Displaced Mark Word 设置为 null。相对应地,解锁时,如果判断 Displaced Mark Word 为 null 则说明是锁重入,不做替换操作。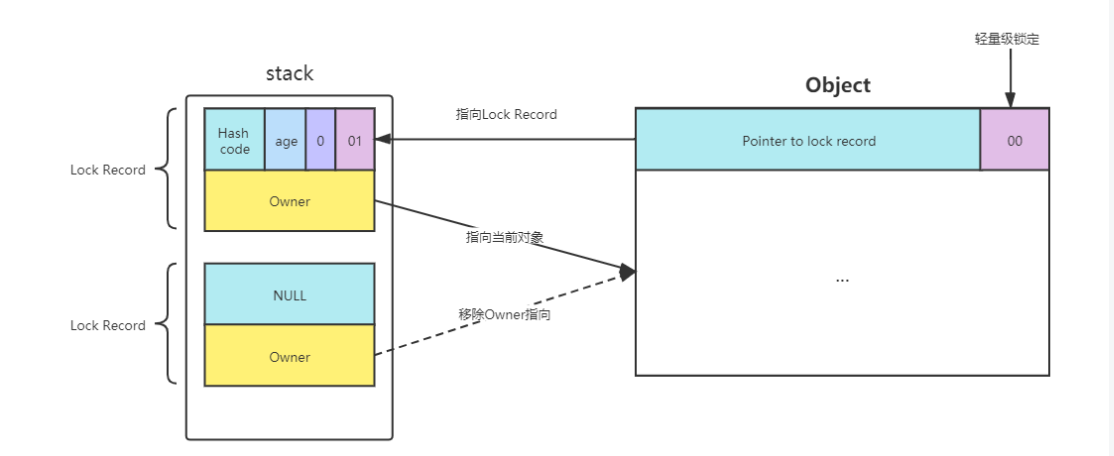
11.3、锁膨胀(重量级锁)
1、定义
如果在尝试加轻量级锁的过程中,cas操作无法成功,这是有一种情况就是其它线程已经为这个对象加上了轻量级锁,这是就要进行锁膨胀,将轻量级锁变成重量级锁。
2、转换过程
1)当 Thread-1 进行轻量级加锁时,Thread-0 已经对该对象加了轻量级锁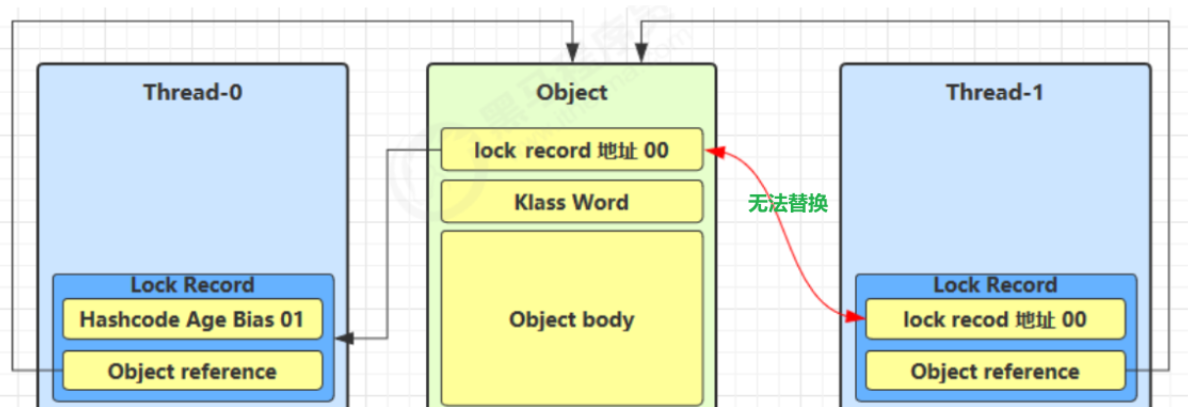
2)这时 Thread-1 加轻量级锁失败,进入锁膨胀流程
即为对象申请Monitor锁,让Object指向重量级锁地址,然后自己进入Monitor 的EntryList 变成BLOCKED状态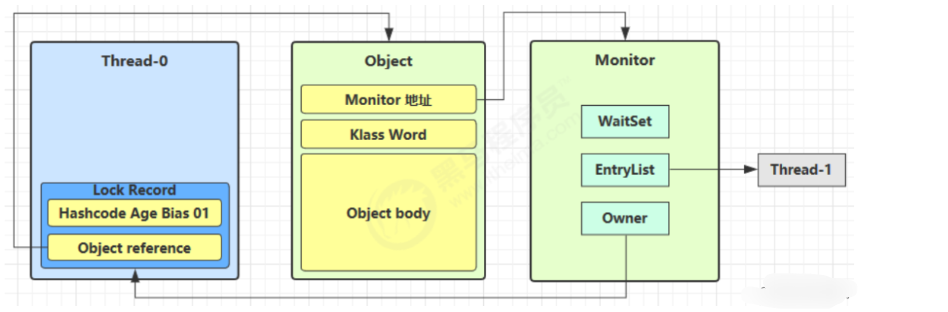
当Thread-0 退出synchronized同步块时,使用cas将Mark Word的值恢复给对象头,失败,那么会进入重量级锁的解锁过程,即按照Monitor的地址找到Monitor对象,将Owner设置为null,唤醒EntryList 中的Thread-1线程
11.4、底层分析
还是上面的例子,假设现在t1、t2是交替执行testLock()方法,此时t1、t2没必要阻塞,因为它们之间没有竞争,也就是不需要重量级锁。
线程之间交替执行临界区的情形下使用的锁称为轻量级锁。
轻量级锁相比重量级锁的优势:
1、每次加锁只需要一次CAS
2、不需要分配ObjectMonitor对象
3、线程无需挂起与唤醒
1、加锁
偏向锁的撤销操作比较复杂,而轻量级锁的加锁、释放锁则简单得多。
#synchronizer.cppvoid ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {//取出Mark WordmarkOop mark = obj->mark();//走到此说明已经不是偏向锁了assert(!mark->has_bias_pattern(), "should not see bias pattern here");if (mark->is_neutral()) {//如果是无锁状态//将Mark Word拷贝到Lock Record的_displaced_header 字段里lock->set_displaced_header(mark);//CAS修改Mark Word使之指向Lock Recordif (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {TEVENT (slow_enter: release stacklock) ;return ;}} elseif (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) {//mark->has_locker() -->表示已经是轻量级锁//THREAD->is_lock_owned((address)mark->locker()) 并且是当前线程获取了轻量级锁//这两点说明当前线程重入该锁//直接设置header==nulllock->set_displaced_header(NULL);return;}//走到这说明不能使用轻量级锁,则需要升级为重量级锁
此时,我们发现Lock Record与轻量级锁的关系更加紧密。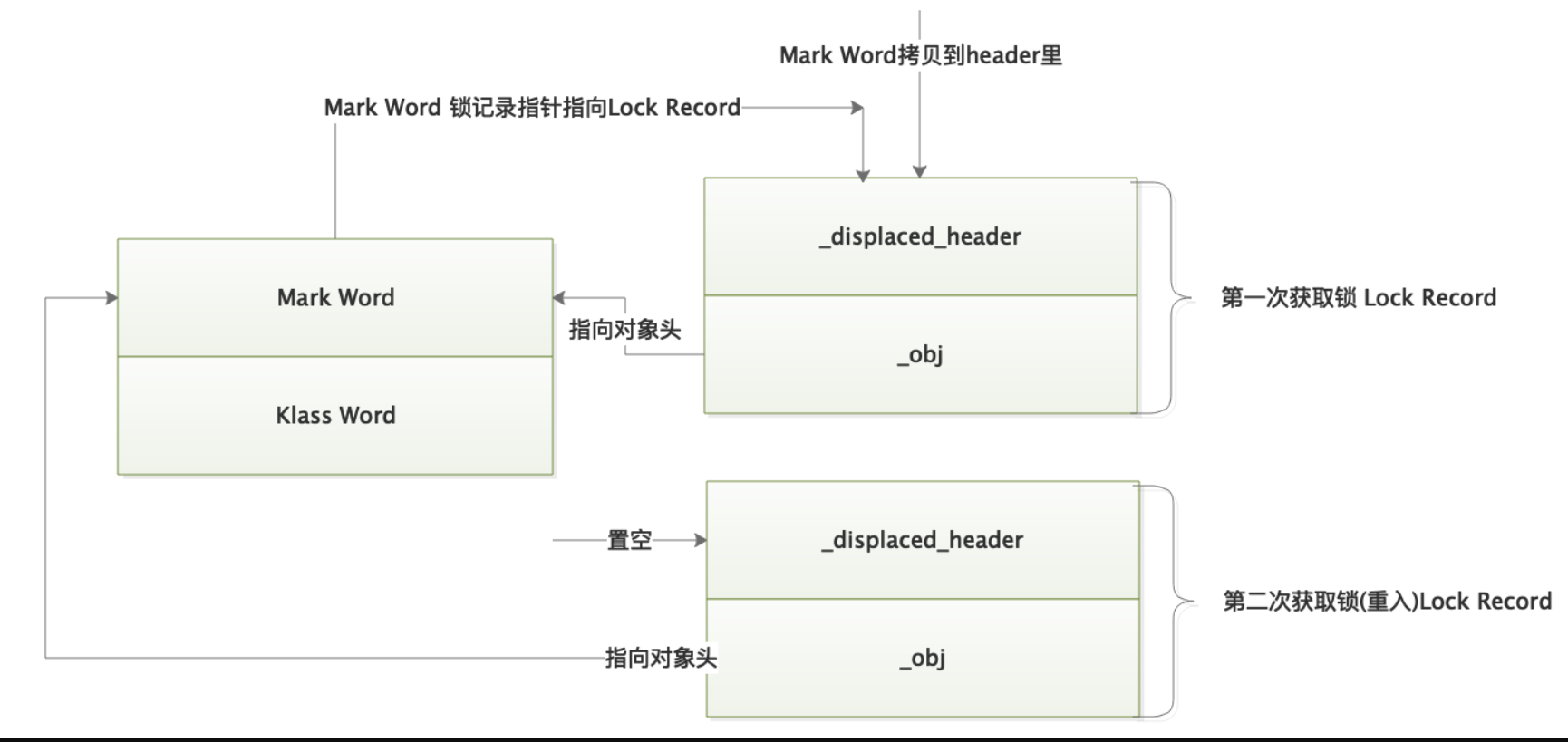
偏向锁了没用的_displaced_header用上了,用以存储无锁状态的Mark Word,待释放锁时恢复(保留了hash值等)。
而Mark Word里的锁记录指针指向了Lock Record,表示该Lock Record所在的线程获取了轻量级锁。
2、释放锁
#bytecodeInterpreter.cppCASE(_monitorexit): {oop lockee = STACK_OBJECT(-1);CHECK_NULL(lockee);BasicObjectLock* limit = istate->monitor_base();BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();while (most_recent != limit ) {if ((most_recent)->obj() == lockee) {BasicLock* lock = most_recent->lock();markOop header = lock->displaced_header();most_recent->set_obj(NULL);//以上部分和偏向锁释放一致的if (!lockee->mark()->has_bias_pattern()) {//不是偏向模式bool call_vm = UseHeavyMonitors;//header 不为空,说明是线程第一次获取轻量级锁时占用的Lock Recordif (header != NULL || call_vm) {//而header存储的是无锁状态的Mark Word//因此需要将Mark Word修改恢复为之前的无锁状态if (call_vm || Atomic::cmpxchg_ptr(header, lockee->mark_addr(), lock) != lock) {//失败的话,再将obj设置上,为了重量级锁使用most_recent->set_obj(lockee);CALL_VM(InterpreterRuntime::monitorexit(THREAD, most_recent), handle_exception);}}}UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);}most_recent++;}...}
与偏向锁不同的是,轻量级锁是真的释放了锁,因为修改Mark Word为无锁状态了。
你可能会有疑惑:只有拿到锁的线程才会有释放锁的操作,为什么此处还需要CAS呢?
考虑一种情况:线程A获取了轻量级锁,此时线程B也想要获取锁,由于锁被A占用,因此B将锁膨胀为重量级锁(修改了Mark Word)。而此时A还在执行临界区代码,它并不知道Mark Word已经被更改了。所以当A退出临界区释放锁的时候,它不能直接修改Mark Word,于是使用CAS尝试更新Mark Word。若是Mark Word已经改变了,也就是说之前Mark Word是指向线程A的Lock Reocrd指针,现在是指向ObjectMonitor了,当然A的CAS会
1、轻量级锁的”锁”即是Mark Word,想要获取锁就需要对Mark Word进行修改,可能会有多线程竞争修改,因此需要借助CAS。
2、如果初始锁为无锁状态,则每次进入都需要一次CAS尝试修改为轻量级锁,否则判断是否重入。
3、如果不满足2的条件,则膨胀为重量级锁。
4、轻量级锁退出时即释放锁,变为无锁状态。
5、可以看出轻量级锁比较敏感,一旦有线程竞争就会膨胀为重量级锁。
12、偏向锁
引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次 CAS 原子指令,而偏向锁只需要在置换 ThreadID 的时候依赖一次 CAS 原子指令,代价就是一旦出现多线程竞争的情况就必须撤销偏向锁。
假设线程 1 访问代码块并获取锁对象时,会在 Java 对象头和栈帧中记录偏向的锁的 threadID,因为偏向锁不会主动释放锁,因此以后线程 1 再次获取锁的时候,需要比较当前线程的 threadID 和 Java 对象头中的 threadID 是否一致。如果一致(还是线程 1 获取锁对象),则无需使用 CAS 来加锁、解锁;如果不一致(其他线程,如线程 2 要竞争锁对象,而偏向锁不会主动释放因此还是存储的线程 1 的 threadID),那么需要查看 Java 对象头中记录的线程 1 是否存活,如果没有存活,那么锁对象被重置为无锁状态,其它线程(线程 2)可以竞争将其设置为偏向锁;如果存活,那么立刻查找该线程(线程 1)的栈帧信息,如果还是需要继续持有这个锁对象,那么暂停当前线程 1,撤销偏向锁,升级为轻量级锁,如果线程 1 不再使用该锁对象,那么将锁对象状态设为无锁状态,重新偏向新的线程。
12.1、偏向锁的概述
偏向锁是JDK6中引入的一项锁优化,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。
偏向锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁没有被其他的线程获取,则持有偏向锁的线程将永远不需要同步。
在实际场景中,如果一个同步块(或方法)没有多个线程竞争,而且总是由同一个线程多次 重入获取锁,如果每次还有阻塞线程,唤醒 CPU 从用户态转核心态,那么对于 CPU 是一种资源 的浪费,为了解决这类问题,就引入了偏向锁的概念。
偏向锁的核心原理是: 如果不存在线程竞争的一个线程获得了锁,那么锁就进入偏向状态, 此时 Mark Word 的结构变为偏向锁结构,锁对象的锁标志位(lock)被改为 01,偏向标志位 (biased_lock)被改为 1,然后线程的 ID 记录在锁对象的 Mark Word 中(使用 CAS 操作完成)。以后该线程获取锁的时,判断一下线程 ID 和标志位,就可以直接进入同步块,连 CAS 操作都不需要,这样就省去了大量有关锁申请的操作,从而也就提供程序的性能。
消除无竞争情况下的同步原语,进一步提升程序性能,所在于没有锁竞争的场合,偏向锁有很好的优化效果。但是,一旦有第二条线程需要竞争锁,那么偏向模式立即结束,进入轻量级锁的状态。
在 JDK1.5 之前,面对 Java 并发问题, synchronized 是一招鲜的解决方案:
- 普通同步方法,锁上当前实例对象
- 静态同步方法,锁上当前类 Class 对象
- 同步块,锁上括号里面配置的对象
拿同步块来举例:
public void test(){synchronized (object) {i++;}}
经过 javap -v 编译后的指令如下: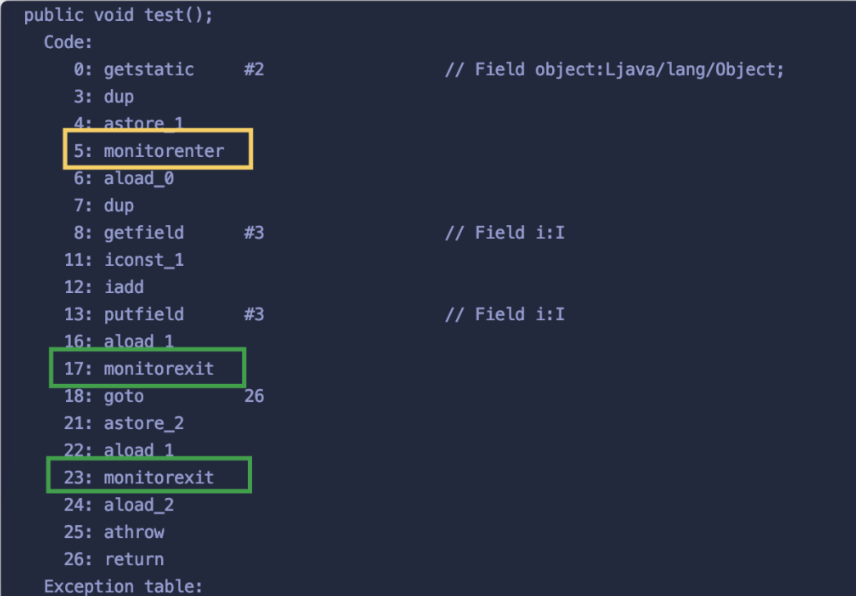 ‘
‘
成重量级锁,阻塞线程排队竞争,也就有了轻量级锁升级成重量级锁的过程
它通过消除资源无竞争情况下的同步原语,进一步提高了程序的运行性能。
说白了,就是怕使用者乱用,比方说一个线程的情况下也去竞争锁,避免浪费资源。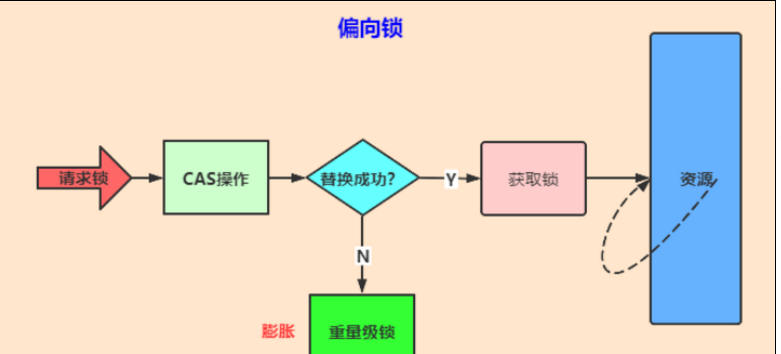
偏向锁是JDK6时加入的一种锁优化机制: 在无竞争的情况下把整个同步都消除掉,连CAS操作都不去做了。偏是指偏心,它的意思是这个锁会偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁一直没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作(例如加锁、解锁及对Mark Word的更新
操作等)。
优点: 把整个同步都消除掉,连CAS操作都不去做了,优于轻量级锁。
缺点: 如果程序中大多数的锁都总是被多个不同的线程访问,那偏向锁就是多余的。
引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令(由于一旦出现多线程竞争的情况就必须撤销偏向锁,所以偏向锁的撤销操作的性能损耗必须小于节省下来的CAS原子指令的性能消耗)。上面说过,轻量级锁是为了在线程交替执行同步块时提高性能,而偏向锁则是在只有一个线程执行同步块时进一步提高性能。
12.2、偏向锁的实现
依旧是上面的例子,假设testLock()始终只有一个线程t1在执行呢?这个时候若是使用轻量级锁,每次t1获取锁都需要进行一次CAS,有点浪费性能。
因此就出现了偏向锁:
当锁偏向某个线程时,该线程再次获取锁时无需CAS,只需要一个简单的比较就可以获取锁,这个过程效率很高。
偏向锁相比轻量级锁的优势:
同一个线程多次获取锁时,无需再次进行CAS,只需要简单比较。
1、偏向锁入口
synchronized分为synchronized代码块和synchronized方法,其底层获取锁的逻辑都是一样的,本文讲解的是synchronized代码块的实现。上篇文章也说过,synchronized代码块是由monitorenter和monitorexit两个指令实现的。
2、偏向锁获取过程: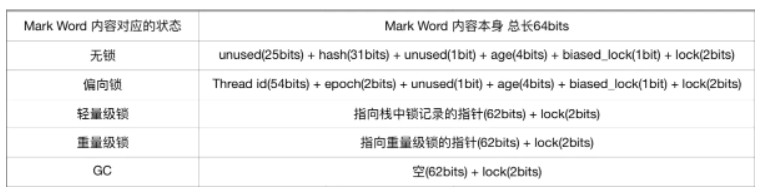
可以看到偏向锁里存储了偏向线程的id,epoch,偏向锁标记(biased_lock),锁标记(lock)等信息。这些信息统称为Mark Word。
在看源码之前,先来朴素(脑补)地猜测线程t1获取偏向锁的过程:
1、先判断Mark Word里的线程id是否有值。
1.1、如果没有,说明还没有线程占用锁,则直接将t1的线程id记录到Mark Word里。可能会存在多个线程同时修改Mark Word,因此需要进行CAS修改Mark Word。
1.2、如果已有id值,那么判断分两种情况:
1.2.1、该id是t1的id,则此次获取锁是个重入的过程,直接就获取了。
1.2.2、如果该id不是t1的id,说明已经有其它线程获取了锁,t1想要获取锁就需要走撤销流程。
(1)访问Mark Word中偏向锁的标识是否设置成1,锁标志位是否为01——确认为可偏向状态。
(2)如果为可偏向状态,则测试线程ID是否指向当前线程,如果是,进入步骤(5),否则进入步骤(3)。
(3)如果线程ID并未指向当前线程,则通过CAS操作竞争锁。如果竞争成功,则将Mark Word中线程ID设置为当前线程ID,然后执行(5);如果竞争失败,执行(4)。
(4)如果CAS获取偏向锁失败,则表示有竞争。当到达全局安全点(safepoint)时获得偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码。
(5)执行同步代码。
CASE(_monitorenter): {//获取对象头,用oop表示对象头 -------->(1)oop lockee = STACK_OBJECT(-1);CHECK_NULL(lockee);BasicObjectLock* limit = istate->monitor_base();BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();BasicObjectLock* entry = NULL;while (most_recent != limit ) {//遍历线程栈,找到对应的空闲的BasicObjectLock (2)if (most_recent->obj() == NULL) entry = most_recent;else if (most_recent->obj() == lockee) break;most_recent++;}if (entry != NULL) {//BasicObjectLock _obj字段指向oop ------>(3)entry->set_obj(lockee);int success = false;uintptr_t epoch_mask_in_place = (uintptr_t)markOopDesc::epoch_mask_in_place;//取出对象头里的Mark WordmarkOop mark = lockee->mark();intptr_t hash = (intptr_t) markOopDesc::no_hash;// 支持偏向锁if (mark->has_bias_pattern()) {uintptr_t thread_ident;uintptr_t anticipated_bias_locking_value;//当前的线程idthread_ident = (uintptr_t)istate->thread();//异或运算结果-------->(4)anticipated_bias_locking_value =(((uintptr_t)lockee->klass()->prototype_header() | thread_ident) ^ (uintptr_t)mark) &~((uintptr_t) markOopDesc::age_mask_in_place);if (anticipated_bias_locking_value == 0) {//完全相等,则认为是重入了该锁------>(5)if (PrintBiasedLockingStatistics) {(* BiasedLocking::biased_lock_entry_count_addr())++;}success = true;}else if ((anticipated_bias_locking_value & markOopDesc::biased_lock_mask_in_place) != 0) {//不支持偏向锁了-------->(6)//构造无锁的Mark WordmarkOop header = lockee->klass()->prototype_header();if (hash != markOopDesc::no_hash) {header = header->copy_set_hash(hash);}//CAS 修改Mark Word为无锁状态if (Atomic::cmpxchg_ptr(header, lockee->mark_addr(), mark) == mark) {if (PrintBiasedLockingStatistics)(*BiasedLocking::revoked_lock_entry_count_addr())++;}}else if ((anticipated_bias_locking_value & epoch_mask_in_place) !=0) {//epoch 过期了------->(7)//使用当前线程id构造偏向锁markOop new_header = (markOop) ( (intptr_t) lockee->klass()->prototype_header() | thread_ident);if (hash != markOopDesc::no_hash) {new_header = new_header->copy_set_hash(hash);}//CAS修改if (Atomic::cmpxchg_ptr((void*)new_header, lockee->mark_addr(), mark) == mark) {if (PrintBiasedLockingStatistics)//成功则获取了锁(* BiasedLocking::rebiased_lock_entry_count_addr())++;}else {//否则进行下一步CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);}success = true;}else {//构造匿名偏向锁---------(8)markOop header = (markOop) ((uintptr_t) mark & ((uintptr_t)markOopDesc::biased_lock_mask_in_place |(uintptr_t)markOopDesc::age_mask_in_place |epoch_mask_in_place));if (hash != markOopDesc::no_hash) {header = header->copy_set_hash(hash);}//构造指向当前线程的偏向锁markOop new_header = (markOop) ((uintptr_t) header | thread_ident);// debugging hintDEBUG_ONLY(entry->lock()->set_displaced_header((markOop) (uintptr_t) 0xdeaddead);)//CAS 修改为偏向当前线程的锁if (Atomic::cmpxchg_ptr((void*)new_header, lockee->mark_addr(), header) == header) {if (PrintBiasedLockingStatistics)(* BiasedLocking::anonymously_biased_lock_entry_count_addr())++;}else {//不成功则进行下一步CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);}success = true;}}if (!success) {//上面尝试使用偏向锁,可惜没有成功,则尝试升级为轻量级锁markOop displaced = lockee->mark()->set_unlocked();entry->lock()->set_displaced_header(displaced);bool call_vm = UseHeavyMonitors;if (call_vm || Atomic::cmpxchg_ptr(entry, lockee->mark_addr(), displaced) != displaced) {// Is it simple recursive case?if (!call_vm && THREAD->is_lock_owned((address) displaced->clear_lock_bits())) {entry->lock()->set_displaced_header(NULL);} else {CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);}}}UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);} else {istate->set_msg(more_monitors);UPDATE_PC_AND_RETURN(0); // Re-execute}}
3、偏向锁的释放:
偏向锁的撤销在上述第四步骤中有提到。偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程不会主动去释放偏向锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行),它会首先暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态,撤销偏向锁后恢复到未锁定(标志位为“01”)或轻量级锁(标志位为“00”)的状态。
这里说的撤销是指在获取偏向锁的过程因为不满足条件导致要将锁对象改为非偏向锁状态;释放是指退出同步块时的过程,释放锁的逻辑会在下一小节阐述。请读者注意本文中撤销与释放的区别。
演示类
该类中有个整形变量 i ,和一个同步方法,每调用一次incr,对变量i进行+1操作。并打印对象的布局信息
public class Foo {private int i;public synchronized void incr(){i++;System.out.println(Thread.currentThread().getName()+"-"+ ClassLayout.parseInstance(this).toPrintable());}}
Runnable实现类
里面的run方法每次都会调用incr方法。
public class LockTest implements Runnable {private final Foo foo;LockTest(Foo foo) {this.foo = foo;}@Overridepublic void run() {this.foo.incr();}}
偏向锁演示
为什么要先睡5秒?
JVM 在启动的时候会延迟启用偏向锁机制。JVM 默认就把偏向 锁延迟了 4000ms,这就解释了为什么演示案例首先 5 秒才能看到对象锁的偏向状态。
如果不想等待(在代码里边让线程睡眠),可以直接通过修改 JVM 的启动选项来禁止偏向 锁延迟,其具体的启动选项如下:
-XX:+UseBiasedLocking
-XX:BiasedLockingStartupDelay=0
睡完5秒后,创建了一个Foo实例,然后先打印一下对象头信息,执行incr方法,执行完后,再次打印对象头信息。
@Testpublic void test() throws InterruptedException {TimeUnit.SECONDS.sleep(5);Foo foo = new Foo();System.err.println(ClassLayout.parseInstance(foo).toPrintable());foo.incr();System.err.println(ClassLayout.parseInstance(foo).toPrintable());}
输出结果:
org.ywb.Foo object internals:OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x0000000000000005 (biasable; age: 0)8 4 (object header: class) 0xf8011d2112 4 int Foo.i 0Instance size: 16 bytesSpace losses: 0 bytes internal + 0 bytes external = 0 bytes totalmain-org.ywb.Foo object internals:OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x00007ff84180f005 (biased: 0x0000001ffe10603c; epoch: 0; age: 0)8 4 (object header: class) 0xf8011d2112 4 int Foo.i 1Instance size: 16 bytesSpace losses: 0 bytes internal + 0 bytes external = 0 bytes totalorg.ywb.Foo object internals:OFF SZ TYPE DESCRIPTION VALUE0 8 (object header: mark) 0x00007ff84180f005 (biased: 0x0000001ffe10603c; epoch: 0; age: 0)8 4 (object header: class) 0xf8011d2112 4 int Foo.i 1Instance size: 16 bytesSpace losses: 0 bytes internal + 0 bytes external = 0 bytes total
解释:
- 第一次打印,从对象结构可以看出biased_lock(偏向锁)状态已经启用,值为 1 ;其 lock (锁状态)的值为 01。lock 和 biased_lock 组合在一起为 101,转换成16进制正好为5表明当前的 Foo 实例处于偏向锁状态。但是由于还没有任何线程使用,所以偏向线程为空。
- 第二次打印,从对象结构可以看出此时偏向锁已经已经被正在执行同步代码线程获取。对象头的MarkWord记录了该偏向线程id和偏向时间戳。
- 第三次打印的时候已经是线程执行完同步代码,但是可以看到对象的MarkWord仍然指向了刚刚偏向的线程,以便下次之前的线程获取到同步锁的时候,只需要判断是否和自己的线程id是否一致就可以了。也可以看出,偏向线程是没有解锁这个操作的。
12.3、偏向锁的撤销和膨胀
假如有多个线程来竞争偏向锁话,如果此对象锁已经偏向了,其他的线程发现偏向锁并不是偏向自己,则说明存在了竞争,就尝试撤销偏向锁,然后膨胀到轻量级锁。
1、偏向锁的膨胀
具体过程如下:
- 在一个安全点停止拥有锁的线程
- 遍历线程的栈帧,检查是否存在存在锁记录。如果存在锁记录的话,需要清空锁记录,使其变成无锁状态,并修复锁记录指向的Mark Word,清除其线程ID。
- 将当前锁升级成轻量级锁。
- 唤醒当前线程。
所以,如果某些临界区存在两个及以上的线程竞争的话,那么偏向锁就会反而会降低性能。 在这种情况情况下,可以在启动 JVM时就把偏向锁的默认功能给关闭。
2、撤销偏向锁的条件
- 多个线程竞争偏向锁。
- 调用偏向锁对象的 hashcode()方法或者 System.identityHashCode() 方法计算对象的 HashCode 之后,哈希码将放置到 Mark Word中,内置锁变成无锁状态,偏向锁将被撤销。
偏向锁的膨胀
如果偏向锁被占据,一旦有第二个线程争抢这个对象,因为偏向锁不会主动释放,所以第二个线程可以看到内置锁偏向状态,这时表明在这个对象锁上已经存在竞争了。
- JVM 检查原来持有该对象锁的占有线程是否依然存活,如果挂了,则可以将对象变为无锁状态,然后进行重新偏向,偏向为抢锁线程。
- 如果JVM 检查到原来的线程依然存活,则进一步检查占有线程的调用堆栈,是否通过锁记录持有偏向锁。如果存在锁记录,则表明原来的线程还在使用偏执锁,发生锁竞争,撤销原来的偏向锁,将偏向锁膨胀为轻
12.4、小结
1、偏向锁的”锁”即是Mark Word,想要获取锁就需要对Mark Word进行修改,可能会有多线程竞争修改,因此需要借助CAS。
2、因为撤销操作可能需要在安全点执行,效率比较低,多次撤销更会影响效率,因此引入了批量重偏向与批量撤销。
3、偏向锁的重入计数依靠线程栈里Lock Record个数。
4、偏向锁撤销失败,最终会升级为轻量级锁。
5、偏向锁退出时并没有修改Mark Word,也就是没有释放锁。
13、分段锁
13.1、分段锁概述
1、线程不安全的HashMap
因为多线程环境下,使用Hashmap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
2、效率低下的HashTable容器
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
3、ConcurrentHashMap分段锁技术
ConcurrentHashMap是Java 5中支持高并发、高吞吐量的线程安全HashMap实现。
我们以ConcurrentHashMap来说一下分段锁的含义以及设计思想,ConcurrentHashMap中的分段锁称为Segment,类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在哪一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。
但是,在统计size的时候,可就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计。
分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
4、用法
模拟信息的发送和接收,场景是这样的:
服务器向客户端发送信息,要保证信息100%的发送给客户端,那么发给客户端之后,客户端返回一个消息告诉服务器,已经收到。当服务器一直没有收到客户端返回的消息,那么服务器会一直发送这个信息,直到客户端接收并确认该信息,这时候再删除重复发送的这个信息。
为了模拟该场景,这里写两个线程,一个是发送线程,一个是接收线程,把要发送的信息保存到线程安全的对象里面,防止发生线程安全问题,这里采用ConcurrentHashMap。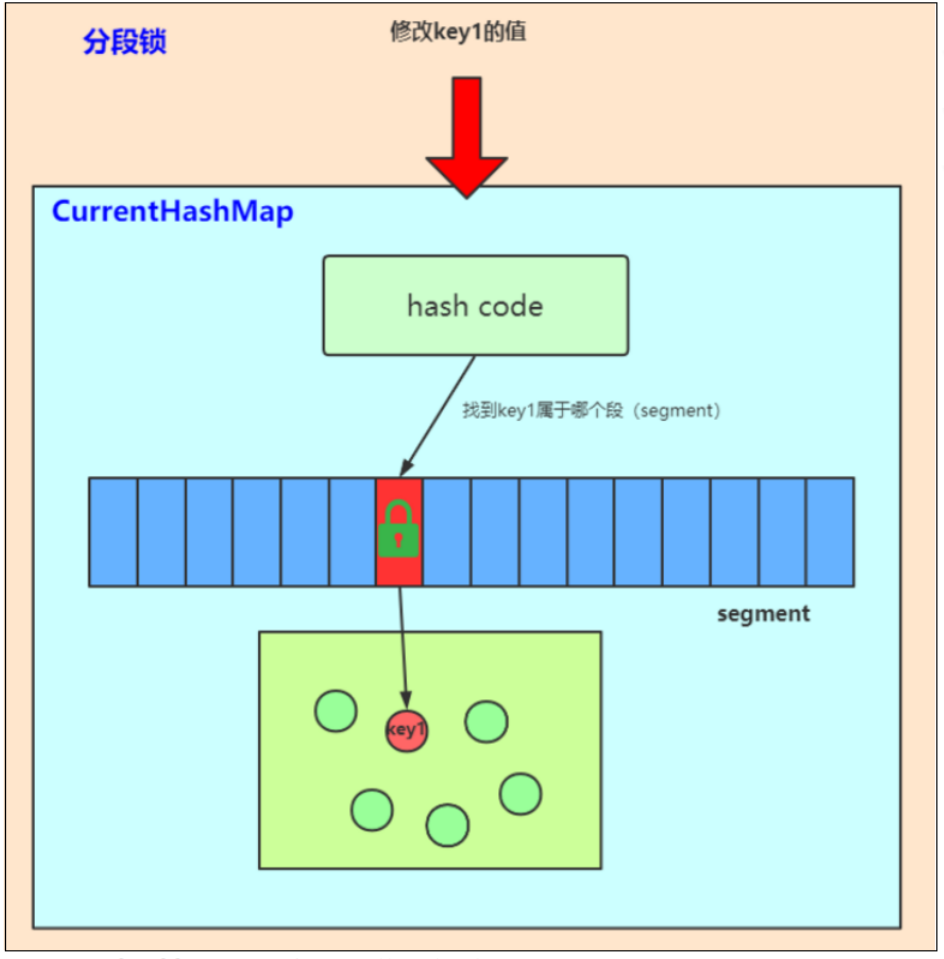
分段锁是一种机制: 最好的例子来说明分段锁是ConcurrentHashMap。ConcurrentHashMap原理:它内部细分了若干个小的 HashMap,称之为段(Segment)。 默认情况下一个 ConcurrentHashMap 被进一步细分为 16 个段,既就是锁的并发度。如果需要在 ConcurrentHashMap 添加一项key-value,并不是将整个 HashMap 加锁,而是首先根据 hashcode 得到该key-value应该存放在哪个段中,然后对该段加锁,并完成 put 操作。在多线程环境中,如果多个线程同时进行put操作,只要被加入的key-value不存放在同一段中,则线程间可以做到真正的并行。
线程安全:ConcurrentHashMap 是一个 Segment 数组, Segment 通过继承ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全
13.2、底层实现
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里“按顺序”是很重要的,否则极有可能出现死锁,在ConcurrentHashMap内部,段数组是final的,并且其成员变量实际上也是final的,但是,仅仅是将数组声明为final的并不保证数组成员也是final的,这需要实现上的保证。这可以确保不会出现死锁,因为获得锁的顺序是固定的。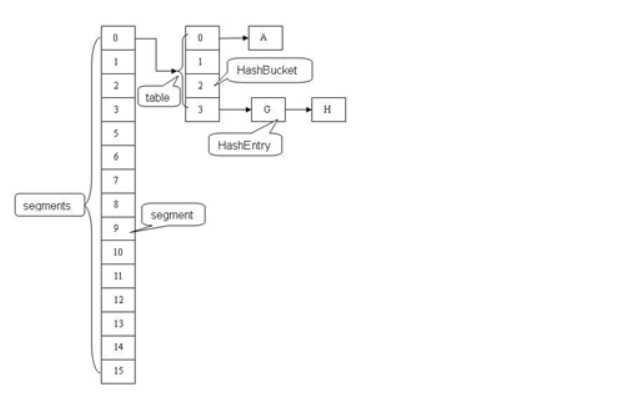
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
为什么要用ConcurrentHashMap?
在并发编程中使用HashMap可能会导致程序陷入死循环,而使用线程安全的HashTable效率又非常低,所以采用了ConcurrentHashMap。
能说一下ConcurrentHashMap在JDK1.7和JDK1.8中的区别吗?
1、JDK1.7:
HashEntry数组 + Segment数组 + Unsafe 「大量方法运用」
JDK1.7中数据结构是由一个Segment数组和多个HashEntry数组组成的,每一个Segment元素中存储的是HashEntry数组+链表,而且每个Segment均继承自可重入锁ReentrantLock,也就带有了锁的功能,当线程执行put的时候,只锁住对应的那个Segment 对象,对其他的 Segment 的 get put 互不干扰,这样子就提升了效率,做到了线程安全。
额外补充:我们对 ConcurrentHashMap 最关心的地方莫过于如何解决 HashMap 在 put 时候扩容引起的不安全问题?
在 JDK1.7 中 ConcurrentHashMap 在 put 方法中进行了两次 hash 计算去定位数据的存储位置,尽可能的减小哈希冲突的可能行,然后再根据 hash 值以 Unsafe 调用方式,直接获取相应的 Segment,最终将数据添加到容器中是由 segment对象的 put 方法来完成。由于 Segment 对象本身就是一把锁,所以在新增数据的时候,相应的 Segment对象块是被锁住的,其他线程并不能操作这个 Segment 对象,这样就保证了数据的安全性,在扩容时也是这样的,在 JDK1.7 中的 ConcurrentHashMap扩容只是针对 Segment 对象中的 HashEntry 数组进行扩容,还是因为 Segment 对象是一把锁,所以在 rehash 的过程中,其他线程无法对 segment 的 hash 表做操作,这就解决了 HashMap 中 put 数据引起的闭环问题。
ConcurrentHashMap(1.7及之前)中主要实体类就是三个:ConcurrentHashMap(整个Hash表),Segment(桶),HashEntry(节点),对应上面的图可以看出之间的关系
/*** The segments, each of which is a specialized hash table*/final Segment<K,V>[] segments;
不变(Immutable)和易变(Volatile)
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。如果使用传统的技术,如HashMap中的实现,如果允许可以在hash链的中间添加或删除元素,读操作不加锁将得到不一致的数据。ConcurrentHashMap实现技术是保证HashEntry几乎是不可变的。HashEntry代表每个hash链中的一个节点,其结构如下所示:
static final class HashEntry<K,V> {final K key;final int hash;volatile V value;final HashEntry<K,V> next;}
可以看到除了value不是final的,其它值都是final的,这意味着不能从hash链的中间或尾部添加或删除节点,因为这需要修改next 引用值,所有的节点的修改只能从头部开始。对于put操作,可以一律添加到Hash链的头部。但是对于remove操作,可能需要从中间删除一个节点,这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点。这在讲解删除操作时还会详述。为了确保读操作能够看到最新的值,将value设置成volatile,这避免了加锁。
final Segment<K,V> segmentFor(int hash) {return segments[(hash >>> segmentShift) & segmentMask];}
既然ConcurrentHashMap使用分段锁Segment来保护不同段的数据,那么在插入和获取元素的时候,必须先通过哈希算法定位到Segment。可以看到ConcurrentHashMap会首先使用Wang/Jenkins hash的变种算法对元素的hashCode进行一次再哈希。
再哈希,其目的是为了减少哈希冲突,使元素能够均匀的分布在不同的Segment上,从而提高容器的存取效率。假如哈希的质量差到极点,那么所有的元素都在一个Segment中,不仅存取元素缓慢,分段锁也会失去意义。我做了一个测试,不通过再哈希而直接执行哈希计算。
所有的成员都是final的,其中segmentMask和segmentShift主要是为了定位段,参见上面的segmentFor方法。
关于Hash表的基础数据结构,这里不想做过多的探讨。Hash表的一个很重要方面就是如何解决hash冲突,ConcurrentHashMap 和HashMap使用相同的方式,都是将hash值相同的节点放在一个hash链中。与HashMap不同的是,ConcurrentHashMap使用多个子Hash表,也就是段(Segment)。
每个Segment相当于一个子Hash表,它的数据成员如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {/*** The number of elements in this segment's region.*/transient volatileint count;/*** Number of updates that alter the size of the table. This is* used during bulk-read methods to make sure they see a* consistent snapshot: If modCounts change during a traversal* of segments computing size or checking containsValue, then* we might have an inconsistent view of state so (usually)* must retry.*/transient int modCount;/*** The table is rehashed when its size exceeds this threshold.* (The value of this field is always <tt>(int)(capacity ** loadFactor)</tt>.)*/transient int threshold;/*** The per-segment table.*/transient volatile HashEntry<K,V>[] table;/*** The load factor for the hash table. Even though this value* is same for all segments, it is replicated to avoid needing* links to outer object.* @serial*/final float loadFactor;}
count用来统计该段数据的个数,它是volatile,它用来协调修改和读取操作,以保证读取操作能够读取到几乎最新的修改。协调方式是这样的,每次修改操作做了结构上的改变,如增加/删除节点(修改节点的值不算结构上的改变),都要写count值,每次读取操作开始都要读取count的值。
这利用了 Java 5中对volatile语义的增强,对同一个volatile变量的写和读存在happens-before关系。modCount统计段结构改变的次数,主要是为了检测对多个段进行遍历过程中某个段是否发生改变,在讲述跨段操作时会还会详述。threashold用来表示需要进行rehash的界限值。table数组存储段中节点,每个数组元素是个hash链,用HashEntry表示。table也是volatile,这使得能够读取到最新的 table值而不需要同步。loadFactor表示负载因子。
删除操作remove(key)
public V remove(Object key) {hash = hash(key.hashCode());return segmentFor(hash).remove(key, hash, null);}
整个操作是先定位到段,然后委托给段的remove操作。当多个删除操作并发进行时,只要它们所在的段不相同,它们就可以同时进行。
下面是Segment的remove方法实现:
V remove(Object key, int hash, Object value) {lock();try {int c = count - 1;HashEntry<K,V>[] tab = table;int index = hash & (tab.length - 1);HashEntry<K,V> first = tab[index];HashEntry<K,V> e = first;while (e != null && (e.hash != hash || !key.equals(e.key)))e = e.next;V oldValue = null;if (e != null) {V v = e.value;if (value == null || value.equals(v)) {oldValue = v;// All entries following removed node can stay// in list, but all preceding ones need to be// cloned.++modCount;HashEntry<K,V> newFirst = e.next;*for (HashEntry<K,V> p = first; p != e; p = p.next)*newFirst = new HashEntry<K,V>(p.key, p.hash,newFirst, p.value);tab[index] = newFirst;count = c; // write-volatile}}return oldValue;} finally {unlock();}}
**put操作
**
同样地put操作也是委托给段的put方法。下面是段的put方法:
V put(K key, int hash, V value, boolean onlyIfAbsent) {lock();try {int c = count;if (c++ > threshold) // ensure capacityrehash();HashEntry<K,V>[] tab = table;int index = hash & (tab.length - 1);HashEntry<K,V> first = tab[index];HashEntry<K,V> e = first;while (e != null && (e.hash != hash || !key.equals(e.key)))e = e.next;V oldValue;if (e != null) {oldValue = e.value;if (!onlyIfAbsent)e.value = value;}else {oldValue = null;++modCount;tab[index] = new HashEntry<K,V>(key, hash, first, value);count = c; // write-volatile}return oldValue;} finally {unlock();}}
2、JDK1.8:
JDK1.7:ReentrantLock+Segment+HashEntry
JDK1.8:Synchronized+CAS+Node+红黑树
JDK1.8屏蔽了JDK1.7中的Segment概念呢,而是直接使用「Node数组+链表+红黑树」的数据结构来实现,并发控制采用 「Synchronized + CAS机制」来确保安全性,为了兼容旧版本保留了Segment的定义,虽然没有任何结构上的作用。
总之JDK1.8中优化了两个部分:
放弃了 HashEntry 结构而是采用了跟 HashMap 结构非常相似的 Node数组 + 链表(链表长度大于8时转成红黑树)的形式
Synchronize替代了ReentrantLock,我们一直固有的思想可能觉得,Synchronize是重量级锁,效率比较低,但为什么要替换掉ReentrantLock呢?
1、随着JDK版本的迭代,本着对Synchronize不放弃的态度,内置的Synchronize变的越来越“轻”了,某些场合比使用API更加灵活。
2、加锁力度的不同,在JDK1.7中加锁的力度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点),也就是1.8中加锁力度更低了,在粗粒度加锁中 ReentrantLock 可能通过 Condition 来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了,所以使用内置的 Synchronize 并不比ReentrantLock效果差。
舍弃原因:
通过 JDK 的源码和官方文档看来, 他们认为的弃用分段锁的原因由以下几点:
- 加入多个分段锁浪费内存空间。
- 生产环境中, map 在放入时竞争同一个锁的概率非常小,分段锁反而会造成更新等操作的长时间等待。
- 为了提高 GC 的效率
14、互斥锁
14.1、互斥锁的概述
互斥锁futex,全拼fast userspace mutexes,直翻为快速用户空间互斥器,它是我们上层应用实现锁的最常用方法。futex是一块所有进程都可以访问的内存,是通过cpu的原子操作修改内存中的值来尝试获取琐,如果没有竞争,则直接在用户空间完成操作,无需切换内核空间,以此保证了futex的性能。
原子性问题的源头是线程切换,如果我们能保证同一时刻只有一个线程执行,原子性问题就得到解决了。同一时刻只有一个线程执行 这个条件非常重要,我们称之为互斥。如果我们能够保证对共享变量的修改是互斥的,那么,无论是单核CPU还是多核CPU,就都能保证原子性了。
我们把一段需要互斥执行的代码称为临界区。线程在进入临界区之前,首先尝试加锁lock(),如果成功,则进入临界区,此时我们称这个线程持有锁;否则呢就等待,直到持有锁的线程解锁;持有锁的线程执行完临界区的代码后,执行解锁unlock()。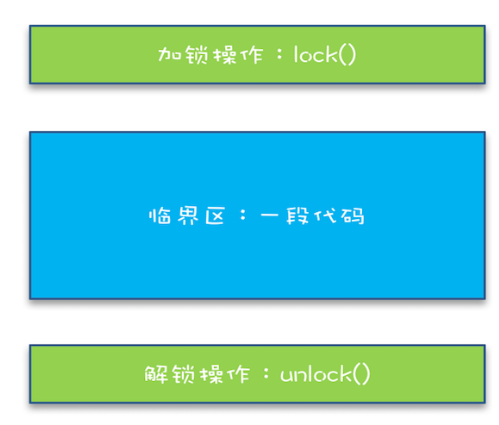
不知道你有没有想过:我们锁的是什么?我们保护的又是什么?
改进后的锁模型
在现实世界里,锁和锁要保护的资源是有对应关系的,比如你用你家的锁保护你家的东西,我用我家的锁保护我家的东西。在并发编程世界里,锁和资源也应该有这个关系,但这个关系在我们上面的模型中是没有体现的,所以我们需要完善一下我们的模型。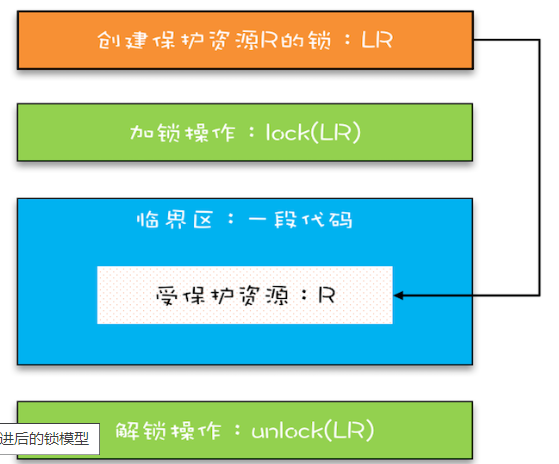
- 首先,把临界区要保护的资源标注出来,如图中临界区里增加了一个元素:受保护的资源R;
- 其次,为要保护资源R创建一把锁LR;
- 最后,针对这把锁LR,在进出临界区时添上加锁操作和解锁操作。
注意:在锁LR和受保护资源之间也特地用一条线做了关联,这个关联关系非常重要。很多并发Bug的出现都是因为把它忽略了,然后就出现了类似锁自家门来保护他家资产的事情,这样的Bug非常不好诊断,因为潜意识里我们认为已经正确加锁了。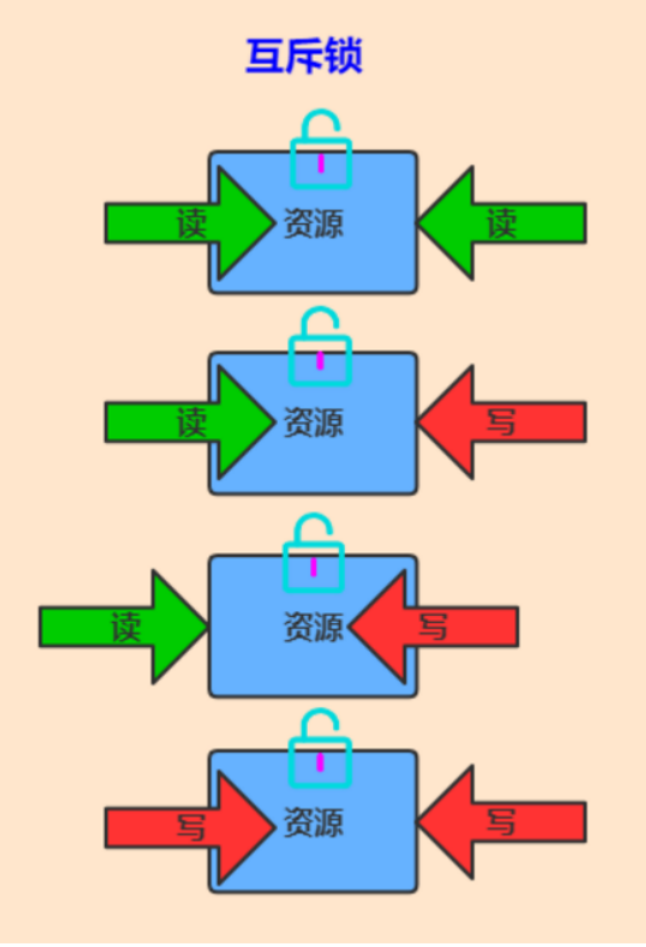
互斥锁与悲观锁、独占锁同义,表示某个资源只能被一个线程访问,其他线程不能访问。
- 读-读互斥
- 读-写互斥
- 写-读互斥
- 写-写互斥
这里就会读写锁不同了,读写锁出现当读读是可以实现无锁状态的,可以多个读锁同时访问。
14.2、synchronized
锁是一种通用的技术方案,Java语言提供的synchronized关键字,就是锁的一种实现。
synchronized关键字可以用来修饰方法,也可以用来修饰代码块,它的使用示例基本上都是下面这个样子:
class X {// 修饰非静态方法synchronized void foo() {// 临界区}// 修饰静态方法synchronized static void bar() {// 临界区}// 修饰代码块Object obj = new Object();void baz() {synchronized(obj) {// 临界区}}}
看完之后不知道你是否有这样的疑问:加锁lock()和解锁unlock()在哪里呢?
其实这两个操作都是有的,只是这两个操作是被Java默默加上的,Java编译器会在synchronized修饰的方法或代码块前后自动加上加锁lock()和解锁unlock(),这样做的好处就是加锁lock()和解锁unlock()一定是成对出现的,毕竟忘记解锁unlock()可是个致命的Bug(意味着其他线程只能死等下去了)。
那synchronized里的加锁lock()和解锁unlock()锁定的对象在哪里呢?上面的代码我们看到只有修饰代码块的时候,锁定了一个obj对象,那修饰方法的时候锁定的是什么呢?这个也是Java的一条隐式规则:
- 当修饰静态方法的时候,锁定的是当前类的Class对象,在上面的例子中就是Class X;
- 当修饰非静态方法的时候,锁定的是当前实例对象this。
对于上面的例子,synchronized修饰静态方法相当于:
class X {// 修饰静态方法synchronized(X.class) static void bar() {// 临界区}}
修饰非静态方法,相当于:
class X {// 修饰非静态方法synchronized(this) void foo() {// 临界区}}
问题出现?
举个例子,一个银行的转账系统包含四个操作:取款、查看余额、修改密码、查看密码。
如果使用同一把锁来管理这四个操作,会使得整套操作都是串行进行的。而我们不难看出,在这四个操作中:(取款、查看余额),(修改密码、查看密码)两组之间并不存在竞争关系,因此我们可以对两组操作分别采用两把锁管理,这样可以两组操作并行执行,大大提高效率。这种对特定资源精细化管理的锁,也可以称之为细粒度锁
但是,实际业务中事情往往不是那么简单的!锁的粒度究竟能够细化多少,需要看对象之间的业务联系
例如,如果新增一个转账业务,那么这个如何保证用户之间转账操作的原子性呢?
原子性的本质是什么? 其实不是不可分割,不可分割只是外在表现,其本质是多个资源间有一致性的要求,操作的中间状态对外不可见。例如,在 32 位的机器上写 long 型变量有中间状态(只写了 64 位中的 32 位),在银行转账的操作中也有中间状态(账户 A 减少了 100,账户 B 还没来得及发生变化)。所以解决原子性问题,是要保证中间状态对外不可见。
class Account {private int balance;// 转账void transfer(Account target, int amt){if (this.balance > amt) {this.balance -= amt;target.balance += amt;}}}
也许第一直觉会是这样的:
class Account {private int balance;// 转账synchronized void transfer(Account target, int amt){if (this.balance > amt) {this.balance -= amt;target.balance += amt;}}}
可惜,这样根本行不通,因为这里 synchronized 是一个实例锁,它只能保护 this 实例,就相当于我们不能用自己家的锁去锁别人家的门。
因此,这里就需要提高 synchronized 的粒度,解决方案可以是这样的:
class Account {private int balance;// 转账void transfer(Account target, int amt){synchronized(Account.class) {if (this.balance > amt) {this.balance -= amt;target.balance += amt;}}}}
这里将锁的粒度提升至类锁,Account.class 对所有的 Account 实例是唯一且共享的,因此即便是不同的实例对象运行到这里时都会使用同一把锁,这样就保证了不同实例之间的线程安全。
14.3、总结
互斥锁,在并发领域的知名度极高,只要有了并发问题,大家首先容易想到的就是加锁,因为大家都知道,加锁能够保证执行临界区代码的互斥性。这样理解虽然正确,但是却不能够指导你真正用好互斥锁。临界区的代码是操作受保护资源的路径,类似于球场的入口,入口一定要检票,也就是要加锁,但不是随便一把锁都能有效。所以必须深入分析锁定的对象和受保护资源的关系,综合考虑受保护资源的访问路径,多方面考量才能用好互斥锁。
synchronized是Java在语言层面提供的互斥原语,其实Java里面还有很多其他类型的锁,但作为互斥锁,原理都是相通的:锁,一定有
15、同步锁
15.1、同步锁的概述
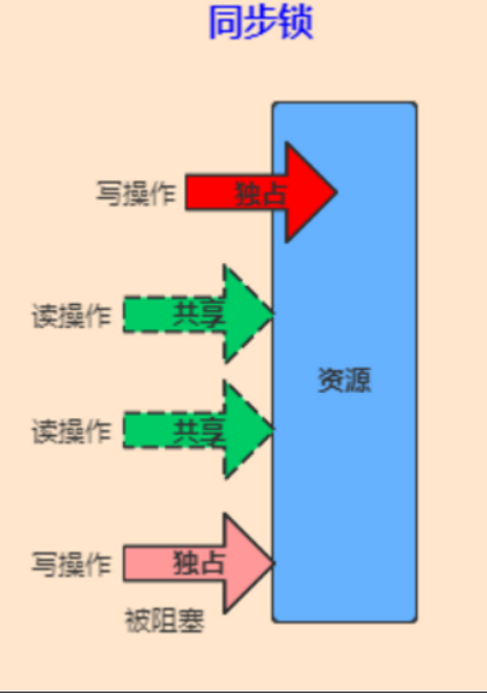
同步锁与互斥锁同义,表示并发执行的多个线程,在同一时间内只允许一个线程访问
共享数据。
Java中的同步锁: synchronized
目的:为了保证共享数据在同一时刻只被一个线程使用,我们有一种很简单的实现思想,就是
1.在共享数据里保存一个锁 ,当没有线程访问时,锁是空的。
2.当有第一个线程访问时,就 在锁里保存这个线程的标识 并允许这个线程访问共享数据。
3.在当前线程释放共享数据之前,如果再有其他线程想要访问共享数据,就要 等待锁释放 。
Jvm同步的实现
15.2、同步锁实现
JVM规范中描述:每个对象有一个监视器锁(monitor)。
当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
1、如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
2、如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
3、如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,
这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的。
但是监视器锁本质又是依赖于底层的操作系统的互斥锁(Mutex Lock)来实现的。而操作系统实现线程之间的切换这就需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么Synchronized效率低的原因。
因此,这种依赖于操作系统互斥锁(Mutex Lock)所实现的锁我们称之为“重量级锁”。
16、死锁
16.1、死锁的概述
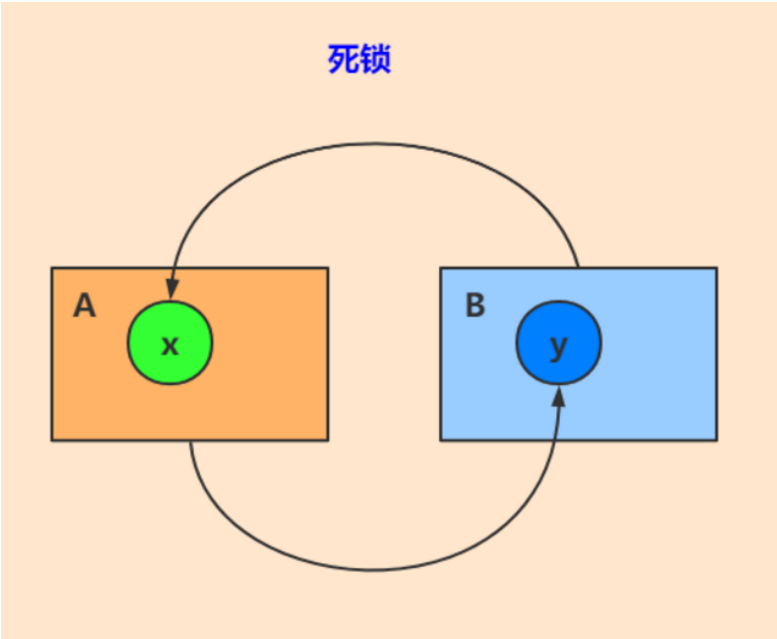
多线程以及多进程改善了系统资源的利用率并提高了系统 的处理能力。然而,并发执行也带来了新的问题——死锁。所谓死锁是指多个线程因竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法向前推进。
所谓死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
死锁是一种现象:如线程A持有资源x,线程B持有资源y,线程A等待线程B释放资源y,线程B等待线程A释放资源x,两个线程都不释放自己持有的资源,则两个线程都获取不到对方的资源,就会造成死锁。Java中的死锁不能自行打破,所以线程死锁后,线程不能进行响应。所以一定要注意程序的并发场景,避免造成死锁。
16.2、死锁产生的原因
1、系统资源的竞争
通常系统中拥有的不可剥夺资源,其数量不足以满足多个进程运行的需要,使得进程在运行过程中,会因争夺资源而陷入僵局,如磁带机、打印机等。只有对不可剥夺资源的竞争才可能产生死锁,对可剥夺资源的竞争是不会引起死锁的。
2、进程推进顺序非法
进程在运行过程中,请求和释放资源的顺序不当,也同样会导致死锁。例如,并发进程 P1、P2分别保持了资源R1、R2,而进程P1申请资源R2,进程P2申请资源R1时,两者都会因为所需资源被占用而阻塞。
Java中死锁最简单的情况是,一个线程T1持有锁L1并且申请获得锁L2,而另一个线程T2持有锁L2并且申请获得锁L1,因为默认的锁申请操作都是阻塞的,所以线程T1和T2永远被阻塞了。导致了死锁。这是最容易理解也是最简单的死锁的形式。但是实际环境中的死锁往往比这个复杂的多。可能会有多个线程形成了一个死锁的环路,比如:线程T1持有锁L1并且申请获得锁L2,而线程T2持有锁L2并且申请获得锁L3,而线程T3持有锁L3并且申请获得锁L1,这样导致了一个锁依赖的环路:T1依赖T2的锁L2,T2依赖T3的锁L3,而T3依赖T1的锁L1。从而导致了死锁。
从上面两个例子中,我们可以得出结论,产生死锁可能性的最根本原因是:线程在获得一个锁L1的情况下再去申请另外一个锁L2,也就是锁L1想要包含了锁L2,也就是说在获得了锁L1,并且没有释放锁L1的情况下,又去申请获得锁L2,这个是产生死锁的最根本原因。另一个原因是默认的锁申请操作是阻塞的。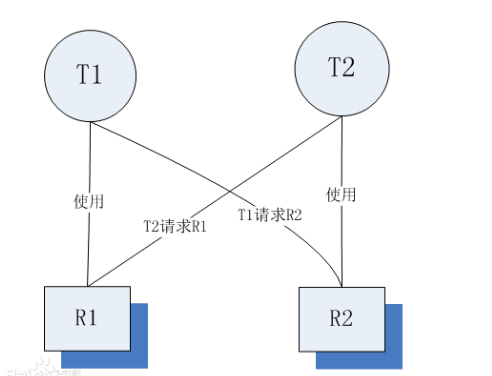
3、死锁产生的必要条件:
产生死锁必须同时满足以下四个条件,只要其中任一条件不成立,死锁就不会发生。
(1)互斥条件:进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内某资源仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
(2)不剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的进程自己来释放(只能是主动释放)。
(3)请求和保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
(4)循环等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被链中下一个进程所请求。即存在一个处于等待状态的进程集合{Pl, P2, …, pn},其中Pi等 待的资源被P(i+1)占有(i=0, 1, …, n-1),Pn等待的资源被P0占有,如图1所示。
直观上看,循环等待条件似乎和死锁的定义一样,其实不然。按死锁定义构成等待环所 要求的条件更严,它要求Pi等待的资源必须由P(i+1)来满足,而循环等待条件则无此限制。 例如,系统中有两台输出设备,P0占有一台,PK占有另一台,且K不属于集合{0, 1, …, n}。
Pn等待一台输出设备,它可以从P0获得,也可能从PK获得。因此,虽然Pn、P0和其他 一些进程形成了循环等待圈,但PK不在圈内,若PK释放了输出设备,则可打破循环等待, 如图2-16所示。因此循环等待只是死锁的必要条件。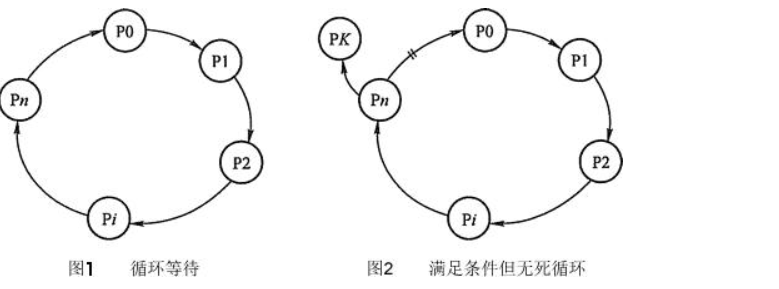
资源分配图含圈而系统又不一定有死锁的原因是同类资源数大于1。但若系统中每类资 源都只有一个资源,则资源分配图含圈就变成了系统出现死锁的充分必要条件。
下面再来通俗的解释一下死锁发生时的条件:
(1)互斥条件:一个资源每次只能被一个进程使用。独木桥每次只能通过一个人。
(2)请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。乙不退出桥面,甲也不退出桥面。
(3)不剥夺条件: 进程已获得的资源,在未使用完之前,不能强行剥夺。甲不能强制乙退出桥面,乙也不能强制甲退出桥面。
(4)循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。如果乙不退出桥面,甲不能通过,甲不退出桥面,乙不能通过。
16.3、死锁实例
package com.demo.test;/*** 一个简单的死锁类* t1先运行,这个时候flag==true,先锁定obj1,然后睡眠1秒钟* 而t1在睡眠的时候,另一个线程t2启动,flag==false,先锁定obj2,然后也睡眠1秒钟* t1睡眠结束后需要锁定obj2才能继续执行,而此时obj2已被t2锁定* t2睡眠结束后需要锁定obj1才能继续执行,而此时obj1已被t1锁定* t1、t2相互等待,都需要得到对方锁定的资源才能继续执行,从而死锁。*/public class DeadLock implements Runnable{private static Object obj1 = new Object();private static Object obj2 = new Object();private boolean flag;public DeadLock(boolean flag){this.flag = flag;}@Overridepublic void run(){System.out.println(Thread.currentThread().getName() + "运行");if(flag){synchronized(obj1){System.out.println(Thread.currentThread().getName() + "已经锁住obj1");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}synchronized(obj2){// 执行不到这里System.out.println("1秒钟后,"+Thread.currentThread().getName()+ "锁住obj2");}}}else{synchronized(obj2){System.out.println(Thread.currentThread().getName() + "已经锁住obj2");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}synchronized(obj1){// 执行不到这里System.out.println("1秒钟后,"+Thread.currentThread().getName()+ "锁住obj1");}}}}}
package com.demo.test;public class DeadLockTest {public static void main(String[] args) {Thread t1 = new Thread(new DeadLock(true), "线程1");Thread t2 = new Thread(new DeadLock(false), "线程2");t1.start();t2.start();}}
线程1运行线程1已经锁住obj1线程2运行线程2已经锁住obj2
线程1锁住了obj1(甲占有桥的一部分资源),线程2锁住了obj2(乙占有桥的一部分资源),线程1企图锁住obj2(甲让乙退出桥面,乙不从),进入阻塞,线程2企图锁住obj1(乙让甲退出桥面,甲不从),进入阻塞,死锁了。
从这个例子也可以反映出,死锁是因为多线程访问共享资源,由于访问的顺序不当所造成的,通常是一个线程锁定了一个资源A,而又想去锁定资源B;在另一个线程中,锁定了资源B,而又想去锁定资源A以完成自身的操作,两个线程都想得到对方的资源,而不愿释放自己的资源,造成两个线程都在等待,而无法执行的情况。
16.4、如何避免死锁
在有些情况下死锁是可以避免的。下面介绍三种用于避免死锁的技术:
- 加锁顺序(线程按照一定的顺序加锁)
- 加锁时限(线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁)
- 死锁检测
1、加锁顺序
当多个线程需要相同的一些锁,但是按照不同的顺序加锁,死锁就很容易发生。如果能确保所有的线程都是按照相同的顺序获得锁,那么死锁就不会发生。看下面这个例子: ```java Thread 1: lock A lock B
Thread 2: wait for A lock C (when A locked)
Thread 3: wait for A wait for B wait for C
如果一个线程(比如线程3)需要一些锁,那么它必须按照确定的顺序获取锁。它只有获得了从顺序上排在前面的锁之后,才能获取后面的锁。<br />例如,线程2和线程3只有在获取了锁A之后才能尝试获取锁C(_获取锁A是获取锁C的必要条件_)。因为线程1已经拥有了锁A,所以线程2和3需要一直等到锁A被释放。然后在它们尝试对B或C加锁之前,必须成功地对A加了锁。<br />按照顺序加锁是一种有效的死锁预防机制。但是,这种方式需要你事先知道所有可能会用到的锁(_并对这些锁做适当的排序_),但总有些时候是无法预知的。<a name="TgeAZ"></a>#### 2、加锁时限另外一个可以避免死锁的方法是在尝试获取锁的时候加一个超时时间,这也就意味着在尝试获取锁的过程中若超过了这个时限该线程则放弃对该锁请求。若一个线程没有在给定的时限内成功获得所有需要的锁,则会进行回退并释放所有已经获得的锁,然后等待一段随机的时间再重试。这段随机的等待时间让其它线程有机会尝试获取相同的这些锁,并且让该应用在没有获得锁的时候可以继续运行(_加锁超时后可以先继续运行干点其它事情,再回头来重复之前加锁的逻辑_)。<br />以下是一个例子,展示了两个线程以不同的顺序尝试获取相同的两个锁,在发生超时后回退并重试的场景:```javaThread 1 locks AThread 2 locks BThread 1 attempts to lock B but is blockedThread 2 attempts to lock A but is blockedThread 1's lock attempt on B times outThread 1 backs up and releases A as wellThread 1 waits randomly (e.g. 257 millis) before retrying.Thread 2's lock attempt on A times outThread 2 backs up and releases B as wellThread 2 waits randomly (e.g. 43 millis) before retrying.
17、锁粗化
17.1、锁粗化的概述
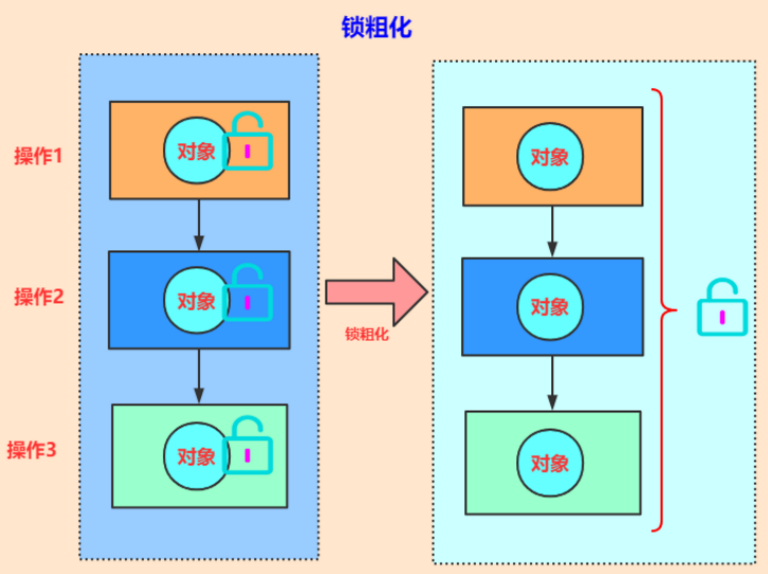
锁粗化是一种优化技术: 如果一系列的连续操作都对同一个对象反复加锁和解锁,甚 至加锁操作都是出现在循环体体之中,就算真的没有线程竞争,频繁地进行互斥同步 操作将会导致不必要的性能损耗,所以就采取了一种方案:
把加锁的范围扩展(粗 化)到整个操作序列的外部,这样加锁解锁的频率就会大大降低,从而减少了性能损耗。避免频繁的加锁释放锁,引起线程的内核态和用户态切换。
锁粗化是jvm在编译时会做的优化,本质就是减少加锁以及锁释放的次数。
17.2、锁粗化的实例
StringBuffer ```java public static void main(String[] args) {
StringBuffer stringBuffer = new StringBuffer();stringBuffer.append("1");stringBuffer.append("2");stringBuffer.append("3");
}
append源码:```javapublic synchronized StringBuffer append(String str) {toStringCache = null;super.append(str);return this;}
append方法是synchronized的,当我们重复多次调用一个Stringbuffer的append方法,例如循环等,jvm为了提高效率,就可能发生锁粗化。
public static void main(String[] args) {for (int i = 0; i < 100; i++) {synchronized (Test.class){// TODO}}}
实例二
public void doSomethingMethod(){synchronized(lock){//do some thing}//这是还有一些代码,做其它不需要同步的工作,但能很快执行完毕synchronized(lock){//do other thing}}
上面的代码是有两块需要同步操作的,但在这两块需要同步操作的代码之间,需要做一些其它的工作,而这些工作只会花费很少的时间,那么我们就可以把这些工作代码放入锁内,将两个同步代码块合并成一个,以降低多次锁请求、同步、释放带来的系统性能消耗,
合并后的代码如下:public void doSomethingMethod(){//进行锁粗化:整合成一次锁请求、同步、释放synchronized(lock){//do some thing//做其它不需要同步但能很快执行完的工作//do other thing}}
另一种需要锁粗化的极端的情况是:
for(int i=0;i<size;i++){synchronized(lock){}}
17.3、锁粗化的前提
这样做是有前提的,就是中间不需要同步的代码能够很快速地完成,如果不需要同步的代码需要花很长时间,就会导致同步块的执行需要花费很长的时间,这样做也就不合理了。
将大对象,拆成小对象,大大增加并行度,降低锁竞争。
偏向锁,轻量级锁成功率提高
比如 ConcurrentHashMap 对于竞争的优化,相对于 HashMap。思考:
减少锁粒度后,可能会带来什么负面影响呢?
以 ConcurrentHashMap 为例,说明分割为多个 Segment后,在什么情况下,会有性能损耗?
18、锁消除
18.1、锁消除的概述
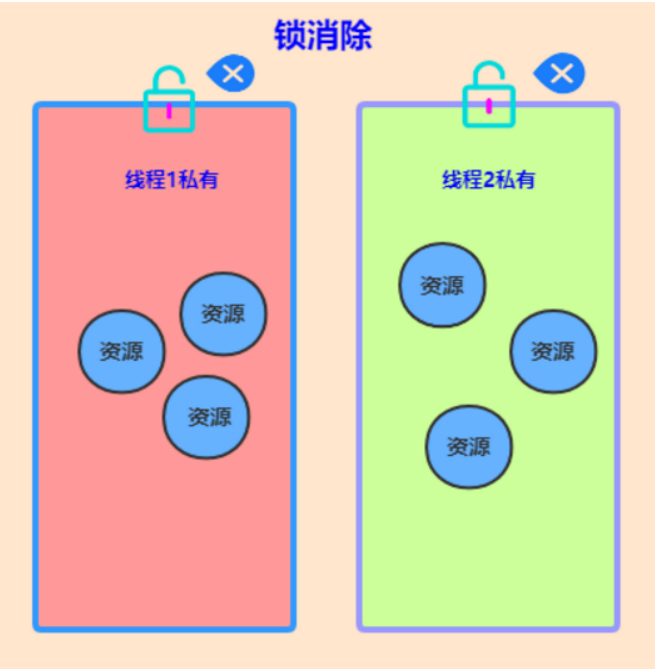
锁消除是一种优化技术: 就是把锁干掉。当Java虚拟机运行时发现有些共享数据不会被线程竞争时就可以进行锁消除。
那如何判断共享数据不会被线程竞争?
利用逃逸分析技术:分析对象的作用域,如果对象在A方法中定义后,被作为参数传递到B方法中,则称为方法逃逸;如果被其他线程访问,则称为线程逃逸。
在堆上的某个数据不会逃逸出去被其他线程访问到,就可以把它当作栈上数据对待,认为它是线程私有的,同步加锁就不需要了。
锁削除是指虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行削除。
锁削除的主要判定依据来源于逃逸分析的数据支持,如果判断到一段代码中,在堆上的所有数据都不会逃逸出去被其他线程访问到,那就可以把它们当作栈上数据对待,认为它们是线程私有的,同步加锁自然就无须进行。
也许读者会有疑问,变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是程序员自己应该是很清楚的,怎么会在明知道不存在数据争用的情况下要求同步呢?
答案是有许多同步措施并不是程序员自己加入的,同步的代码在Java程序中的普遍程度也许超过了大部分读者的想象。
18.2、锁消除的实例
StringBuffer类的append操作:
@Overridepublic synchronized StringBuffer append(String str) {toStringCache = null;super.append(str);return this;}
从源码中可以看出,append方法用了synchronized关键词,它是线程安全的。
但我们可能仅在线程内部把StringBuffer当作局部变量使用:
public class Demo {public static void main(String[] args) {long start = System.currentTimeMillis();int size = 10000;for (int i = 0; i < size; i++) {createStringBuffer("Hyes", "为分享技术而生");}long timeCost = System.currentTimeMillis() - start;System.out.println("createStringBuffer:" + timeCost + " ms");}public static String createStringBuffer(String str1, String str2) {StringBuffer sBuf = new StringBuffer();sBuf.append(str1);// append方法是同步操作sBuf.append(str2);return sBuf.toString();}}
代码中createStringBuffer方法中的局部对象sBuf,就只在该方法内的作用域有效,不同线程同时调用createStringBuffer()方法时,都会创建不同的sBuf对象,因此此时的append操作若是使用同步操作,就是白白浪费的系统资源。
开启锁消除
这时我们可以通过编译器将其优化,将锁消除,前提是java必须运行在server模式(server模式会比client模式作更多的优化),同时必须开启逃逸分析:
-server -XX:+DoEscapeAnalysis -XX:+EliminateLocks
其中+DoEscapeAnalysis表示开启逃逸分析,+EliminateLocks表示锁消除。
逃逸分析:比如上面的代码,它要看sBuf是否可能逃出它的作用域?
如果将sBuf作为方法的返回值进行返回,那么它在方法外部可能被当作一个全局对象使用,就有可能发生线程安全问题,这时就可以说sBuf这个对象发生逃逸了,因而不应将append操作的锁消除,但我们上面的代码没有发生锁逃逸,锁消除就可以带来一定的性能提升。
我们来看看下面代码清单13-6中的例子,这段非常简单的代码仅仅是输出三个字符串相加的结果,无论是源码字面上还是程序语义上都没有同步。
public String concatString(String s1, String s2, String s3) {return s1 + s2 + s3;}
我们也知道,由于String是一个不可变的类,对字符串的连接操作总是通过生成新的String对象来进行的,因此Javac编译器会对String连接做自动优化。
在JDK 1.5之前,会转化为StringBuffer对象的连续append()操作,在JDK 1.5及以后的版本中,会转化为StringBuilder对象的连续append()操作。
即代码清单13-6中的代码可能会变成代码清单13-7的样子 。
public String concatString(String s1, String s2, String s3) {StringBuffer sb = new StringBuffer();sb.append(s1);sb.append(s2);sb.append(s3);return sb.toString();}
实事求是地说,既然谈到锁削除与逃逸分析,那虚拟机就不可能是JDK 1.5之前的版本,所以实际上会转化为非线程安全的StringBuilder来完成字符串拼接,并不会加锁。但是这也不影响笔者用这个例子证明Java对象中同步的普遍性。)
现在大家还认为这段代码没有涉及同步吗?
每个StringBuffer.append()方法中都有一个同步块,锁就是sb对象。
虚拟机观察变量sb,很快就会发现它的动态作用域被限制在concatString()方法内部。也就是sb的所有引用永远不会“逃逸”到concatString()方法之外,其他线程无法访问到它,所以这里虽然有锁,但是可以被安全地削除掉,在即时编译之后,这段代码就会忽略掉所有的同步而直接执行了。
19、synchronized
19.1、synchronized概述
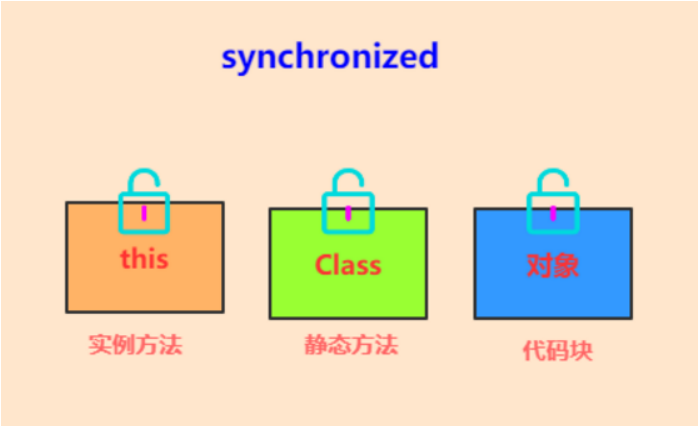
synchronized是Java中的关键字:用来修饰方法、对象实例。属于独占锁、悲观锁、可重入锁、非公平锁。
1.作用于实例方法时,锁住的是对象的实例(this);
2.当作用于静态方法时,锁住的是 Class类,相当于类的一个全局锁,会锁所有调用该方法的线程;
3.synchronized 作用于一个非 NULL的对象实例时,锁住的是所有以该对象为锁的代码块。 它有多个队列,当多个线程一起访问某个对象监视器的时候,对象监视器会将这些线程存储在不同的容器中。
每个对象都有个 monitor 对象, 加锁就是在竞争 monitor 对象,代码块加锁是在代
码块前后分别加上 monitorenter 和 monitorexit 指令来实现的,方法加锁是通过一个标记位来判断的。
1、内存可见性
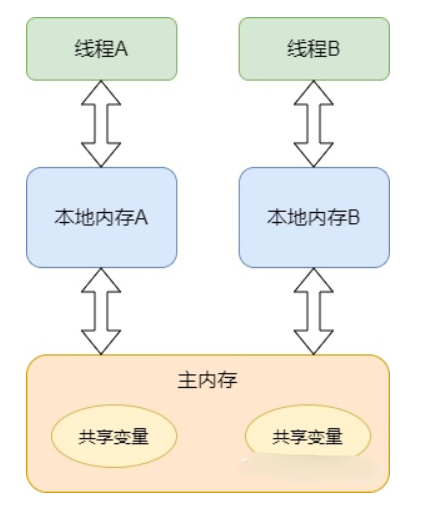
这里的本地内存并不是真实存在的,只是 Java 内存模型的一个抽象概念,它包含了控制器、运算器、缓存等。同时 Java 内存模型规定,线程对共享变量的操作必须在自己的本地内存中进行,不能直接在主内存中操作共享变量。这种内存模型会出现什么问题呢?
线程 A 获取到共享变量 X 的值,此时本地内存 A 中没有 X 的值,所以加载主内存中的 X 值并缓存到本地内存 A 中,线程 A 修改 X 的值为 1,并将 X 的值刷新到主内存中,这时主内存及本地内存中的 X 的值都为 1
线程 B 需要获取共享变量 X 的值,此时本地内存 B 中没有 X 的值,加载主内存中的 X 值并缓存到本地内存 B 中,此时 X 的值为 1。线程 B 修改 X 的值为 2,并刷新到主内存中,此时主内存及本地内存 B 中的 X 值为 2,本地内存 A 中的 X 值为 1
线程 A 再次获取共享变量 X 的值,此时本地内存中存在 X 的值,所以直接从本地内存中 A 获取到了 X 为 1 的值,但此时主内存中 X 的值为 2,到此出现了所谓内存不可见的问题
该问题 Java 内存模型是通过 synchronized 关键字和 volatile 关键字就可以解决,那么 synchronized 关键字是如何解决的呢,其实进入 synchronized 块就是把在 synchronized 块内使用到的变量从线程的本地内存中擦除,这样在 synchronized 块中再次使用到该变量就不能从本地内存中获取了,需要从主内存中获取,解决了内存不可见问题。
2、synchronized的特征
圈内经常拿 synchronized 关键字和 volatile 关键字的特性进行对比,synchronized 关键字可以保证并发编程的三大特性:原子性、可见性、有序性,而 volatile 关键字只能保证可见性和有序性,不能保证原子性,也称为是轻量级的 synchronized。
- 原子性:一个或多个操作要么全部执行成功,要么全部执行失败。synchronized 关键字可以保证只有一个线程拿到锁,访问共享资源
- 可见性:当一个线程对共享变量进行修改后,其他线程可以立刻看到。执行 synchronized 时,会对应执行 lock、unlock 原子操作,保证可见性
- 有序性:程序的执行顺序会按照代码的先后顺序执行
这里聊到了volatile关键字的使用 这里来介绍一个volatile关键字的含义
volatile是什么?
volatile在java语言中是一个关键字,用于修饰变量。被volatile修饰的变量后,表示这个变量在不同线程中是共享,编译器与运行时都会注意到这个变量是共享的,因此不会对该变量进行重排序。上面这句话可能不好理解,但是存在两个关键,共享和重排序。
变量的共享:
先来看一个被举烂了的例子:
public class VolatileTest {boolean isStop = false;public void test() {Thread t1 = new Thread() {@Overridepublic void run() {isStop = true;}};Thread t2 = new Thread() {@Overridepublic void run() {while (!isStop) {}}};t2.start();t1.start();}public static void main(String args[]) throws InterruptedException {new VolatileTest().test();}}
上面的代码是一种典型用法,检查某个标记(isStop)的状态判断是否退出循环。但是上面的代码有可能会结束,也可能永远不会结束。因为每一个线程都拥有自己的工作内存,当一个线程读取变量的时候,会把变量在自己内存中拷贝一份。之后访问该变量的时候都通过访问线程的工作内存,如果修改该变量,则将工作内存中的变量修改,然后再更新到主存上。这种机制让程序可以更快的运行,然而也会遇到像上述例子这样的情况。
存在一种情况,isStop变量被分别拷贝到t1、t2两个线程中,此时isStop为false。t2开始循环,t1修改本地isStop变量称为true,并将isStop=true回写到主存,但是isStop已经在t2线程中拷贝过一份,t2循环时候读取的是t2 工作内存中的isStop变量,而这个isStop始终是false,程序死循环。我们称t2对t1更新isStop变量的行为是不可见的。就是目前的isStop变量是之前拷贝的,另外线程修改本线程不会获取到修改后的值。
如果isStop变量通过volatile进行修饰,t2修改isStop变量后,会立即将变量回写到主存中,并将t1里的isStop失效。t1发现自己变量失效后,会重新去主存中访问isStop变量,而此时的isStop变量已经变成true。循环退出。
volatile boolean isStop = false;
volatile如何使用
volatile关键字一般用于标记变量的修饰,类似上述例子。《Java并发编程实战》中说,volatile只保证可见性,而加锁机制既可以确保可见性又可以确保原子性。当且仅当满足以下条件下,才应该使用volatile变量:
1、对变量的写入操作不依赖变量的当前值,或者确保只有单个线程变更变量的值。
2、该变量不会于其他状态一起纳入不变性条件中
3、在访问变量的时候不需要加锁。
逐一分析:
第一条说明volatile不能作为多线程中的计数器,计数器的count++操作,分为三步,第一步先读取count的数值,第二步count+1,第三步将count+1的结果写入count。volatile不能保证操作的原子性。上述的三步操作中,如果有其他线程对count进行操作,就可能导致数据出错。
public class VolatileTest {private volatile int lower = 0;private volatile int upper = 5;public int getLower() {return lower;}public int getUpper() {return upper;}public void setLower(int lower) {if (lower > upper) {return;}this.lower = lower;}public void setUpper(int upper) {if (upper < lower) {return;}this.upper = upper;}}
述程序中,lower初始为0,upper初始为5,并且upper和lower都用volatile修饰。我们期望不管怎么修改upper或者lower,都能保证upper>lower恒成立。然而如果同时有两个线程,t1调用setLower,t2调用setUpper,两线程同时执行的时候。有可能会产生upper<lower这种不期望的结果。
public void test() {Thread t1 = new Thread() {@Overridepublic void run() {try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}setLower(4);}};Thread t2 = new Thread() {@Overridepublic void run() {try {Thread.sleep(10);} catch (InterruptedException e) {e.printStackTrace();}setUpper(3);}};t1.start();t2.start();while (t1.isAlive() || t2.isAlive()) {}System.out.println("(low:" + getLower() + ",upper:" + getUpper() + ")");}public static void main(String args[]) throws InterruptedException {for (int i = 0; i < 100; i++) {VolatileTest volaitil = new VolatileTest();volaitil.test();}}

此时程序一直正常运行,但是出现的结果却是我们不想要的。
第三条:当访问一个变量需要加锁时,一般认为这个变量需要保证原子性和可见性,而volatile关键字只能保证变量的可见性,无法保证原子性。
最后贴个volatile的常见例子,在单例模式双重检查中的使用:
public class Singleton {private static volatile Singleton instance=null;private Singleton(){}public static Singleton getInstance(){if(instance==null){synchronized(Singleton.class){if(instance==null){instance=new Singleton();}}}return instance;}}
new Singleton()分为三步,1、分配内存空间,2、初始化对象,3、设置instance指向被分配的地址。然而指令的重新排序,可能优化指令为1、3、2的顺序。如果是单个线程访问,不会有任何问题。但是如果两个线程同时获取getInstance,其中一个线程执行完1和3步骤,此时其他的线程可以获取到instance的地址,在进行if(instance==null)时,判断出来的结果为false,导致其他线程直接获取到了一个未进行初始化的instance,这可能导致程序的出错。所以用volatile修饰instance,禁止指令的重排序,保证程序能正常运行。(Bug很难出现,没能模拟出来)。
然而,《java并发编程实战中》中有对DCL的描述如下:”DCL的这种使用方法已经被广泛废弃了——促使该模式出现的驱动力(无竞争同步的执行速度很慢,以及JVM启动很慢)已经不复存在了,因而它不是一种高效的优化措施。延迟初始化占位类模式能带来同样的优势,并且更容易理解。”,其实我个小码畜的角度来看,服务端的单例更多时候做延迟初始化并没有很大意义,延迟初始化一般用来针对高开销的操作,并且被延迟初始化的对象都是不需要马上使用到的。然而,服务端的单例在大部分的时候,被设计为单例的类大部分都会被系统很快访问到。本篇文章只是讨论volatile,并不针对设计模式进行讨论,因此后续有时间,再补上替代上述单例的写法。
3、实现什么类型的锁
- 悲观锁:synchronized 关键字实现的是悲观锁,每次访问共享资源时都会上锁
- 非公平锁:synchronized 关键字实现的是非公平锁,即线程获取锁的顺序并不一定是按照线程阻塞的顺序
- 可重入锁:synchronized 关键字实现的是可重入锁,即已经获取锁的线程可以再次获取锁
- 独占锁或者排他锁:synchronized 关键字实现的是独占锁,即该锁只能被一个线程所持有,其他线程均被阻塞
4、底层原理
synchronized 底层原理是比较难理解的,理解 synchronized 需要一定的 Java 虚拟机的知识。
在 jdk1.6 之前,synchronized 被称为重量级锁,在 jdk1.6 中,为了减少获得锁和释放锁带来的性能开销,引入了偏向锁和轻量级锁。下面先介绍 jdk1.6 之前的 synchronized 原理。1)对象头
我们知道,Java 对象保存在堆内存中。一个 Java 对象包含三部分:对象头、实例数据和对齐填充。其中对象头是一个很关键的部分,因为对象头中包含锁状态标志、线程持有的锁等标志。
synchronized 是悲观锁,在操作同步资源之前需要给同步资源先加锁,这把锁就是存在 Java 对象头里的,而 Java 对象头又是什么呢?
每一个 Java 类,在被 JVM 加载的时候,JVM 会给这个类创建一个 instanceKlass,保存在方法区,用来在 JVM 层表示该 Java 类。当我们在 Java 代码中,使用 new 创建一个对象的时候,JVM 会创建一个 instanceOopDesc 对象,这个对象中包含了对象头以及实例数据。
我们以 Hotspot 虚拟机为例,Hotspot 的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)
Mark Word: 默认存储对象的 HashCode,分代年龄和锁标志位信息。Mark Word 用于存储对象自身的运行时数据,所以 Mark Word 被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间 Mark Word 里存储的数据会随着锁标志位的变化而变化。
Klass Point: 对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
重量级锁的底部实现原理是Monitor ,jdk1.6之前只能实现重量级锁,基于Monitor对象来实现重量级锁,底层原理是由C++编写。
jdk1.6之后synchronized进行优化 进行锁升级。
在 JDK1.6 中,为了减少获得锁和释放锁带来的性能消耗,引入了偏向锁和轻量级锁,锁的状态变成了四种,如下图所示。锁的状态会随着竞争激烈逐渐升级,但通常情况下,锁的状态只能升级不能降级。这种只能升级不能降级的策略是为了提高获得锁和释放锁的效率。
常见问题汇总:
1、了解锁消除吗?
锁消除是指 Java 虚拟机在即时编译时,通过对运行上下的扫描,消除那些不可能存在共享资源竞争的锁。锁消除可以节约无意义的请求锁时间。
2、了解锁粗化吗?
一般情况下,为了提高性能,总是将同步块的作用范围限制到最小,这样可以使得需要同步的操作尽可能地少。但如果一系列连续的操作一直对某个对象反复加锁和解锁,频繁地进行互斥同步操作也会引起不必要的性能消耗。
如果虚拟机检测到有一系列操作都是对某个对象反复加锁和解锁,会将加锁同步的范围粗化到整个操作序列的外部。可以看下面这个经典案例。
for(int i=0;i<n;i++){synchronized(lock){}}
这段代码会导致频繁地加锁和解锁,锁粗化后
synchronized(lock){for(int i=0;i<n;i++){}}
3、当线程 1 进入到一个对象的 synchronized 方法 A 后,线程 2 是否可以进入到此对象的 synchronized 方法 B?
不能,线程 2 只能访问该对象的非同步方法。因为执行同步方法时需要获得对象的锁,而线程 1 在进入 sychronized 修饰的方 A 时已经获取到了锁,线程 2 只能等待,无法进入到 synchronized 修饰的方法 B,但可以进入到其他非 synchronized 修饰的方法。
4、synchronized 和 volatile 的区别?
- volatile 主要是保证内存的可见性,即变量在寄存器中的内存是不确定的,需要从主存中读取。synchronized 主要是解决多个线程访问资源的同步性
- volatile 作用于变量,synchronized 作用于代码块或者方法
- volatile 仅可以保证数据的可见性,不能保证数据的原子性。synchronized 可以保证数据的可见性和原子性
- volatile 不会造成线程的阻塞,synchronized 会造成线程的阻塞
5、synchronized 和 Lock 的区别?
- Lock 是显示锁,需要手动开启和关闭。synchronized 是隐士锁,可以自动释放锁
- Lock 是一个接口,是 JDK 实现的。synchronized 是一个关键字,是依赖 JVM 实现的
- Lock 是可中断锁,synchronized 是不可中断锁,需要线程执行完才能释放锁
- 发生异常时,Lock 不会主动释放占有的锁,必须通过 unloc k进行手动释放,因此可能引发死锁。synchronized 在发生异常时会自动释放占有的锁,不会出现死锁的情况
- Lock 可以判断锁的状态,synchronized 不可以判断锁的状态
- Lock 实现锁的类型是可重入锁、公平锁。synchronized 实现锁的类型是可重入锁,非公平锁
- Lock 适用于大量同步代码块的场景,synchronized 适用于少量同步代码块的场景
20、Lock和synchronize的区别
Lock: 是Java中的接口,可重入锁、悲观锁、独占锁、互斥锁、同步锁。
- Lock需要手动获取锁和释放锁。就好比自动挡和手动挡的区别
- Lock 是一个接口,而 synchronized 是 Java 中的关键字, synchronized 是内置的语言实现。
- synchronized 在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而 Lock 在发生异常时,如果没有主动通过 unLock()去释放锁,则很可能造成死锁现象,因此使用 Lock 时需要在 finally 块中释放锁。
- Lock 可以让等待锁的线程响应中断,而 synchronized 却不行,使用synchronized 时,等待的线程会一直等待下去,不能够响应中断。
- 通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
- Lock 可以通过实现读写锁提高多个线程进行读操作的效率。
synchronized的优势:
足够清晰简单,只需要基础的同步功能时,用synchronized。Lock应该确保在finally块中释放锁。如果使用synchronized,JVM确保即使出现异常,锁也能被自动释放。使用Lock时,Java虚拟机很难得知哪些锁对象是由特定线程锁持有的。
21、ReentrantLock和synchronized的区别
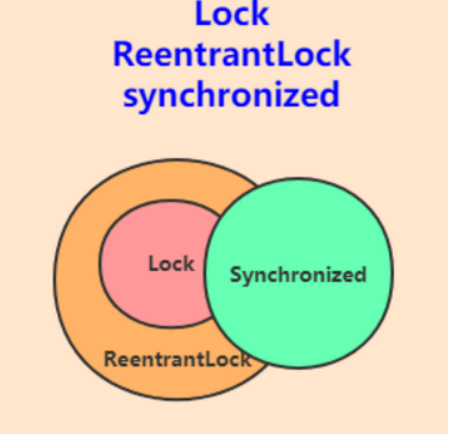
ReentrantLock是Java中的类 : 继承了Lock类,可重入锁、悲观锁、独占锁、互斥锁、同步锁。
划重点
相同点:
1.主要解决共享变量如何安全访问的问题
2.都是可重入锁,也叫做递归锁,同一线程可以多次获得同一个锁,
3.保证了线程安全的两大特性:可见性、原子性。
不同点:
1.ReentrantLock 就像手动汽车,需要显示的调用lock和unlock方法,synchronized 隐式获得释放锁。
2.ReentrantLock 可响应中断, synchronized 是不可以响应中断的,ReentrantLock 为处理锁的不可用性提供了更高的灵活性
3.ReentrantLock 是 API 级别的, synchronized 是 JVM 级别的
4.ReentrantLock 可以实现公平锁、非公平锁,默认非公平锁,synchronized 是非公平锁,且不可更改。
5.ReentrantLock 通过 Condition 可以绑定多个条件

若有收获,就点个赞吧
0 人点赞
