- 1、分布式缓存
2、分布式锁">
2、分布式锁
1、分布式缓存
随着互联网的发展,用户规模和数据规模越来越大,对系统的性能提出了更高的要求,缓存就是其中一个非常关键的组件,从简单的商品秒杀,到全民投入的双十一,我们都能见到它的身影。
分布式缓存首先也是缓存,一种性能很好但是相对稀缺的资源,和我们在课本上学习的CPU缓存原理基本相同,CPU是用性能更好的静态RAM来为性能一般的DRAM加速,分布式缓存则是通过内存或者其他高速存储来加速,但是由于用到了分布式环境中,涉及到并发和网络的问题,所以会更加复杂一些,但是有很多方面的共性,比如缓存淘汰策略。计算机行业有一句鼎鼎大名的格言就指出了缓存失效的复杂性。
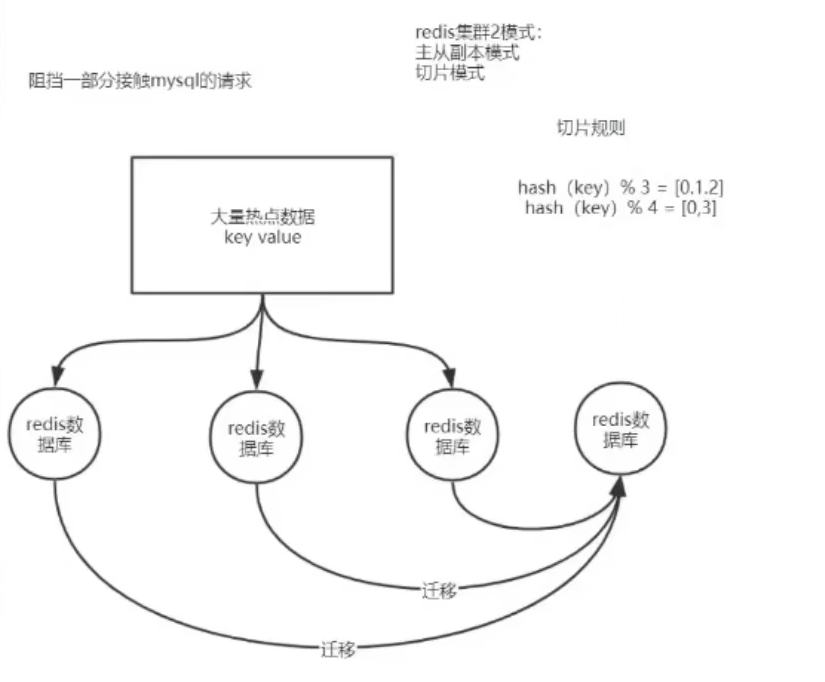
切片规则:
对添加一个节点和删除一个节点都需要大量的数据迁移导致出现集群的Redis的I/O瘫痪。
使用一致性Hash算法实现切片规则能够解决这个问题,如下: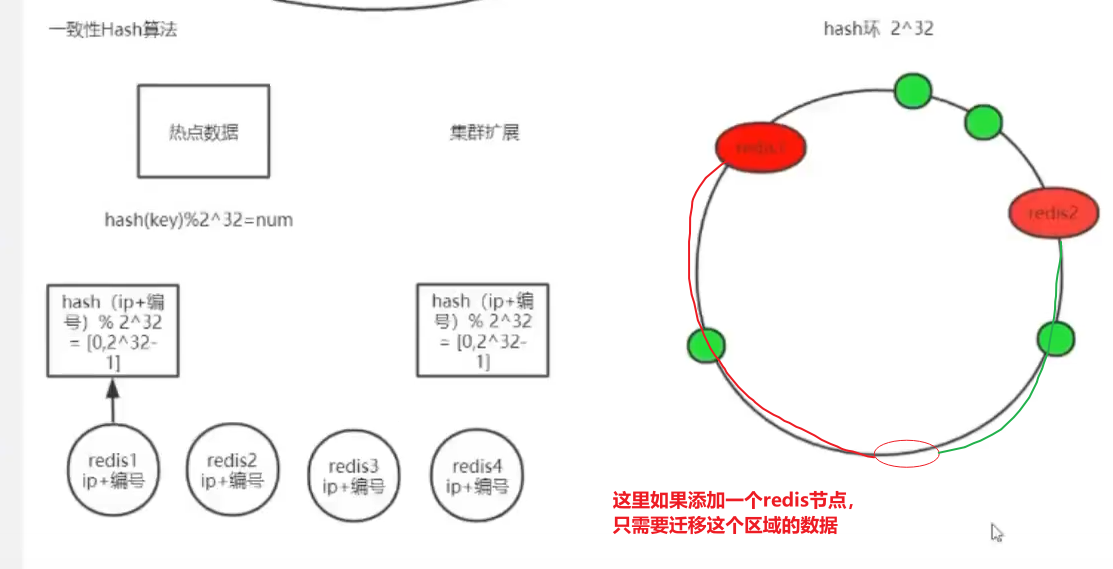
但是Hash环会造成数据倾斜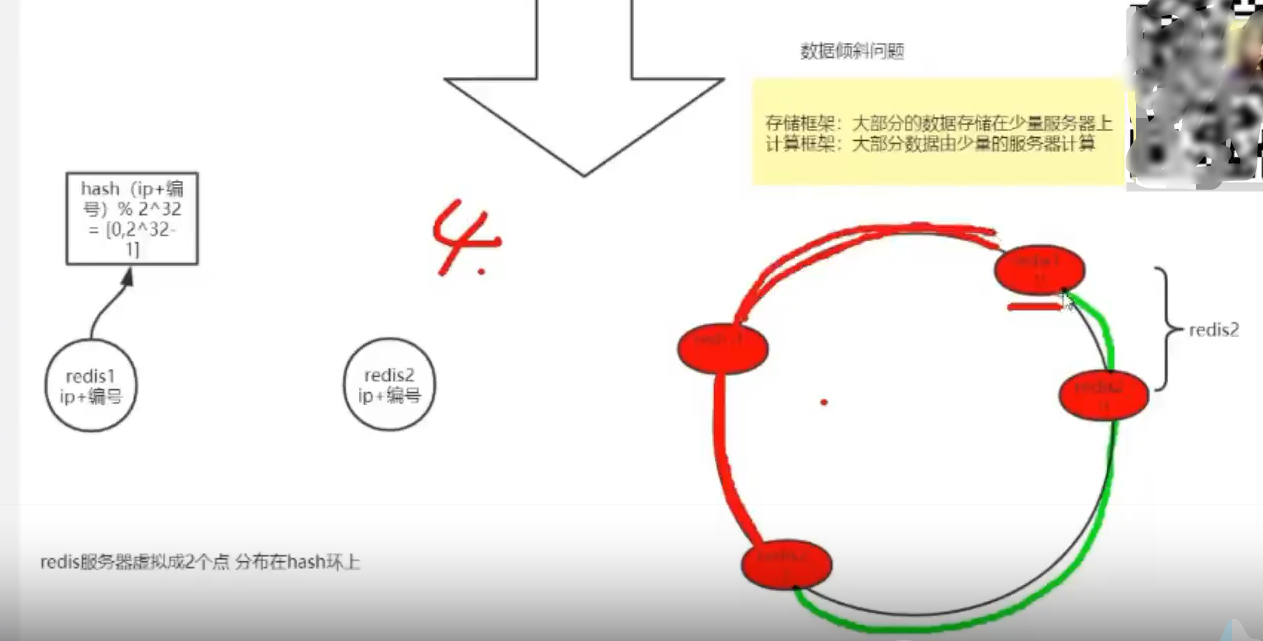
如果出现数据倾斜如何解决?
可以在Redis服务器上虚拟n个点分布在hash环上来均衡redis的数据。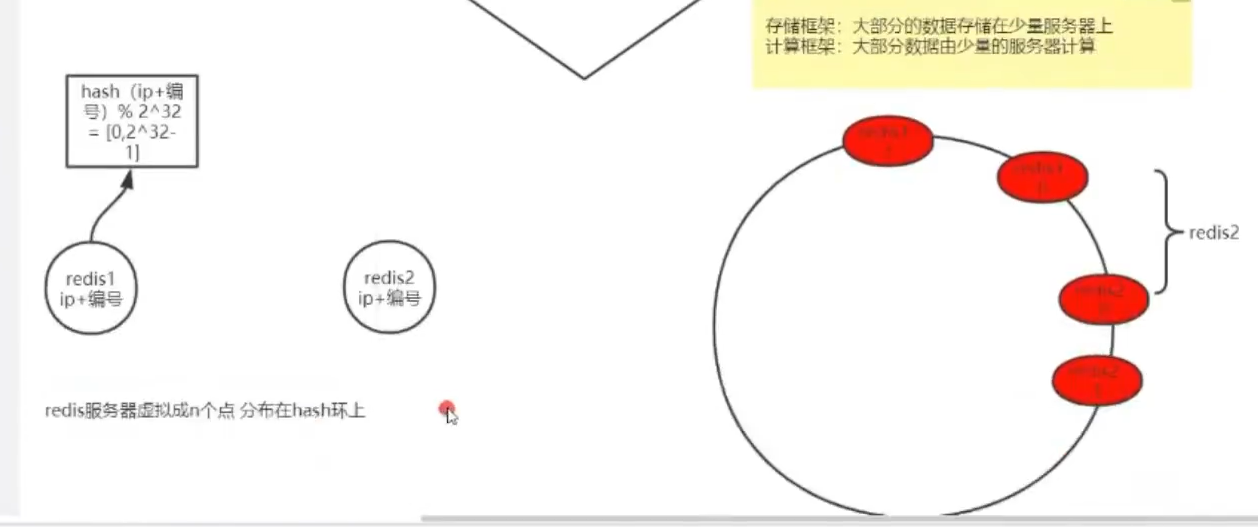
发生缓存穿透怎么办?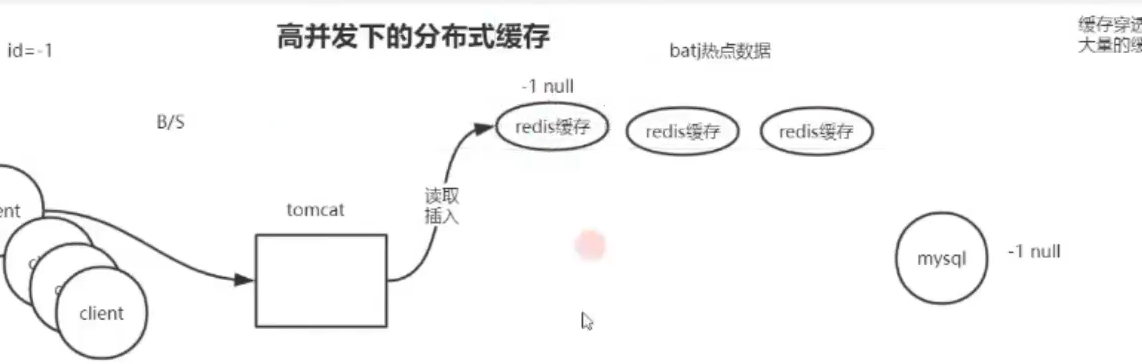
通过mysql查找id == -1 的数据 如何缓存到redis缓存再进行拦截。
但是这个不不太现实的解决办法,因为入侵不可能使用一个简单的id来攻击。
可以在redis后添加一个过滤器filiter 但是占内存多大
使用布隆算法来解决id的穿透可以实现部分的拦截,通过错误率来换空间占用
- 数据hash结果存在则真实数据不一定存在
- 数据hash结果不存在真实数据一定不存在
布隆算法对hash数组的长度要求都高 错误率依靠数组长度的影响。
1、增大bit数组的长度会减少错误率。
2、增加hash值节点的数量就是下面设置1 和 6 的个数。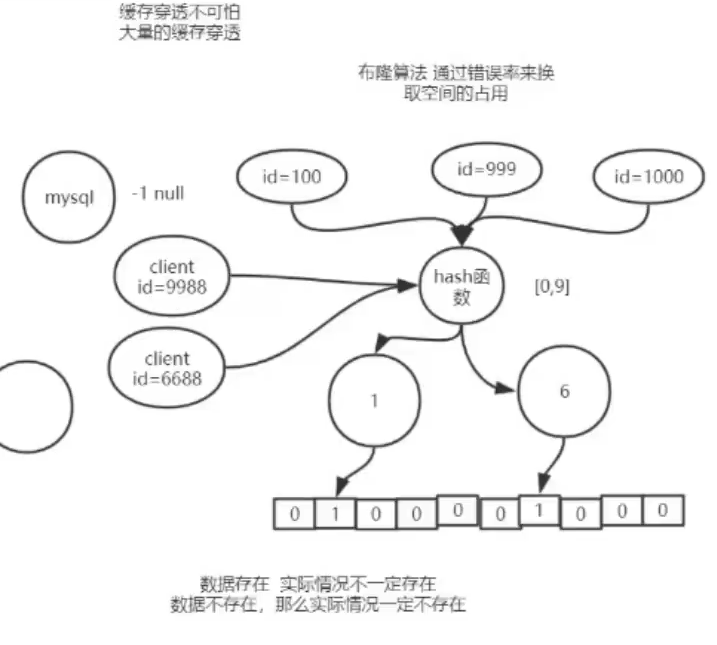
布隆算法的使用场景(面试算法)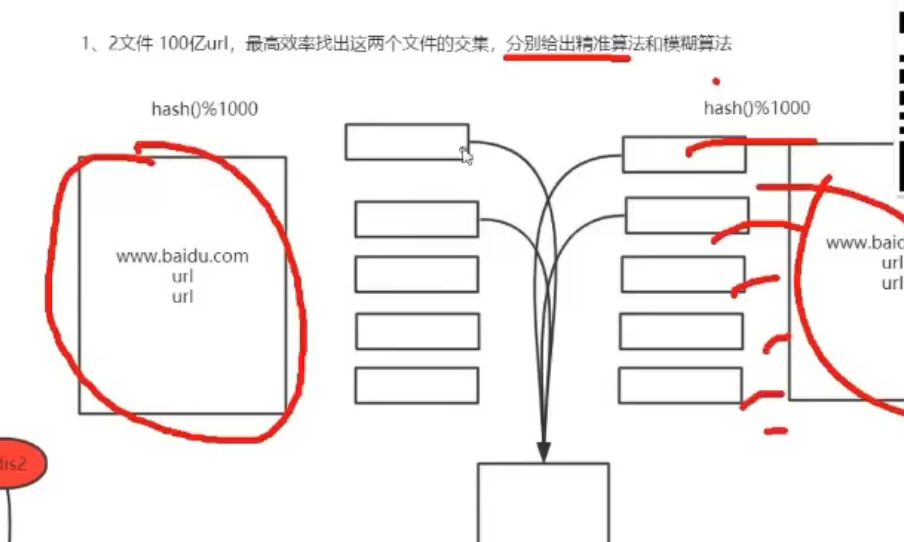
这里就是对两个文件分别进行hash值的分类,url一样的一定在同一个文件夹里,不一样的也可能在
所以减少不必要的比较。小文件之间的比较。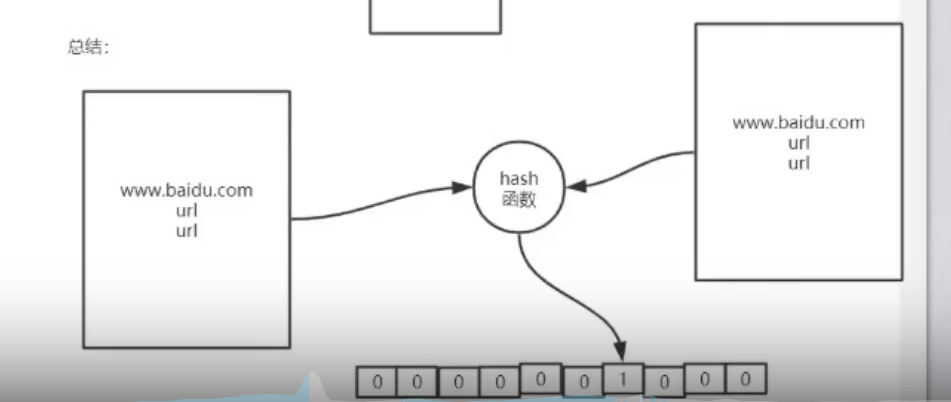
比较一次I/O比较,只需要在对应的索引里比较交集的
1.2、缓存雪崩
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间所有原本应该访问缓存的请求都去查询数据库了,而对数据库 CPU 和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。 一般有三种处理办法:
一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
为 key 设置不同的缓存失效时间。
1.3、缓存穿透
存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法, 如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。
1.4、缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据。
1.5、缓存更新
缓存更新除了缓存服务器自带的缓存失效策略之外(Redis 默认的有 6 种策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
(1)定时去清理过期的缓存。
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
1.6、缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
2、分布式锁

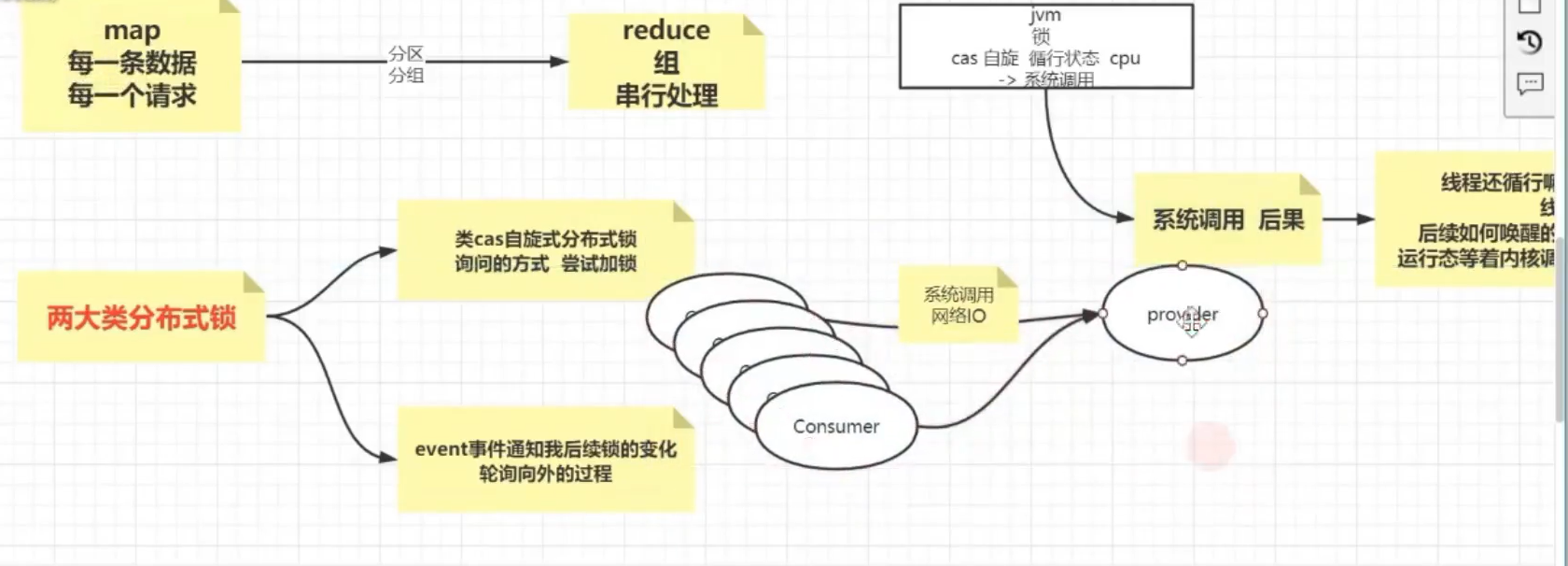
学习目标
- 什么是分布式
- 什么是锁
- 什么是分布式锁
- 分布式锁的使用场景-为什么要使用分布式锁
- 分布式锁需要具备哪些功能/条件
- 分布式锁的解决方案
2.1、分布式锁介绍
2.1.1、什么是分布式锁
一个大型的系统往往被分为几个子系统来做,一个子系统可以部署在一台机器的多个 JVM(java虚拟机) 上,也可以部署在多台机器上。但是每一个系统不是独立的,不是完全独立的。需要相互通信,共同实现业务功能。
一句话来说:分布式就是通过计算机网络将后端工作分布到多台主机上,多个主机一起协同完成工作。
2.1.2、什么是锁— 作用安全
现实生活中,当我们需要保护一样东西的时候,就会使用锁。例如门锁,车锁等等。很多时候可能许多人会共用这些资源,就会有很多个钥匙。但是有些时候我们希望使用的时候是独自不受打扰的,那么就会在使用的时候从里面反锁,等使用完了再从里面解锁。这样其他人就可以继续使用了。
JAVA程序中,当存在多个线程可以同时改变某个变量(可变共享变量)时,就需要对变量或代码块做同步,使其在修改这种变量时能够线性执行消除并发修改变量,而同步的本质是通过锁来实现的。如 Java 中 synchronize 是在对象头设置标记,Lock 接口的实现类基本上都只是某一个 volitile 修饰的 int 型变量其保证每个线程都能拥有对该 int 的可见性和原子修改
2.1.3、什么是分布式锁
任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。CAP
当在分布式模型下,数据只有一份(或有限制),此时需要利用锁的技术控制某一时刻修改数据的进程数。
分布式锁: 在分布式环境下,多个程序/线程都需要对某一份(或有限制)的数据进行修改时,针对程序进行控制,保证同一时间节点下,只有一个程序/线程对数据进行操作的技术。
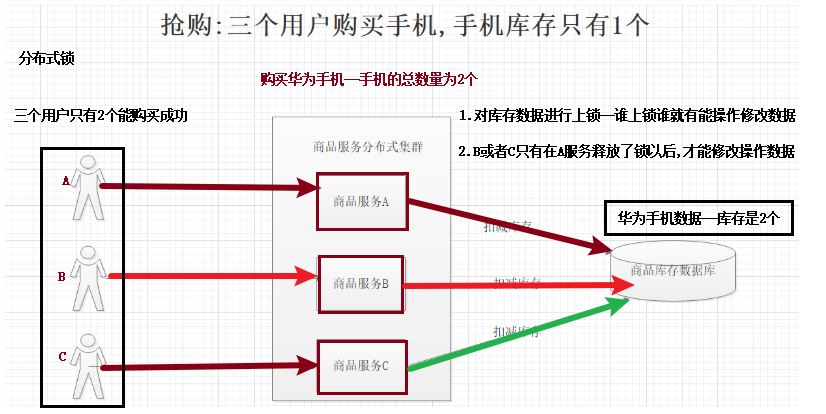
2.1.4、分布式锁的使用场景
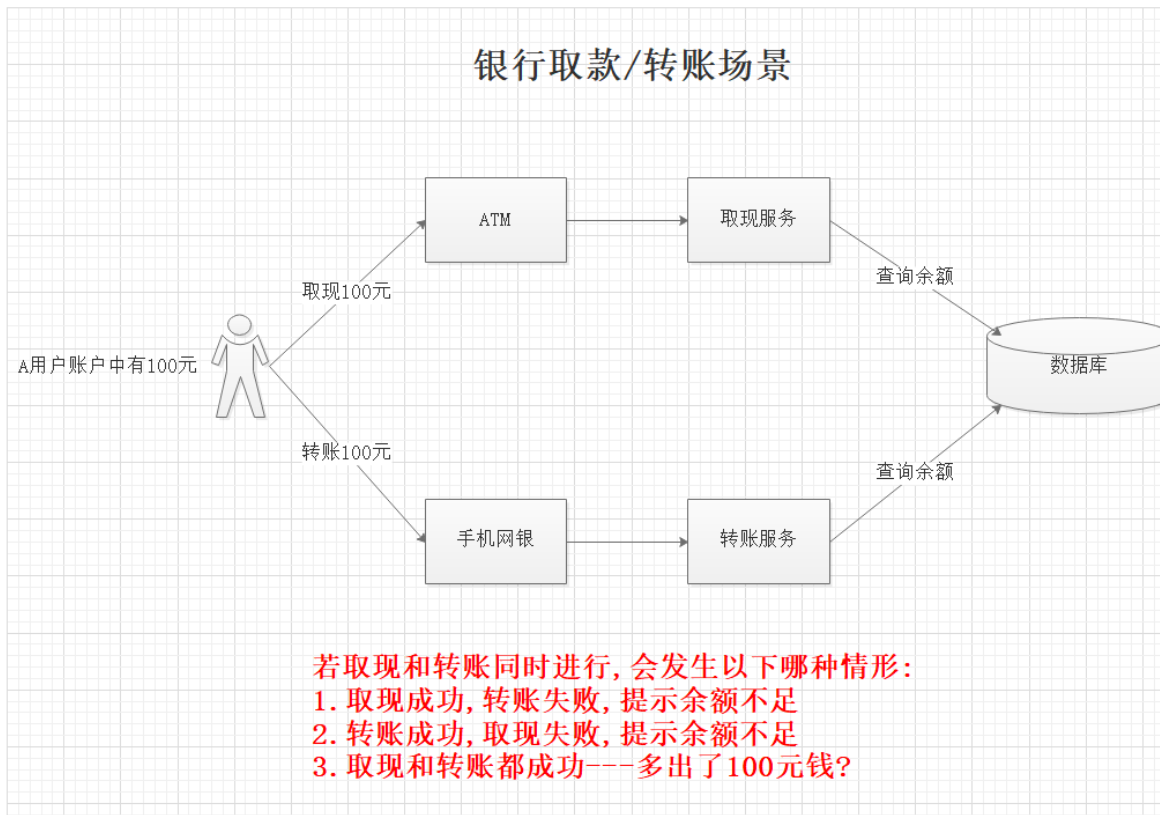
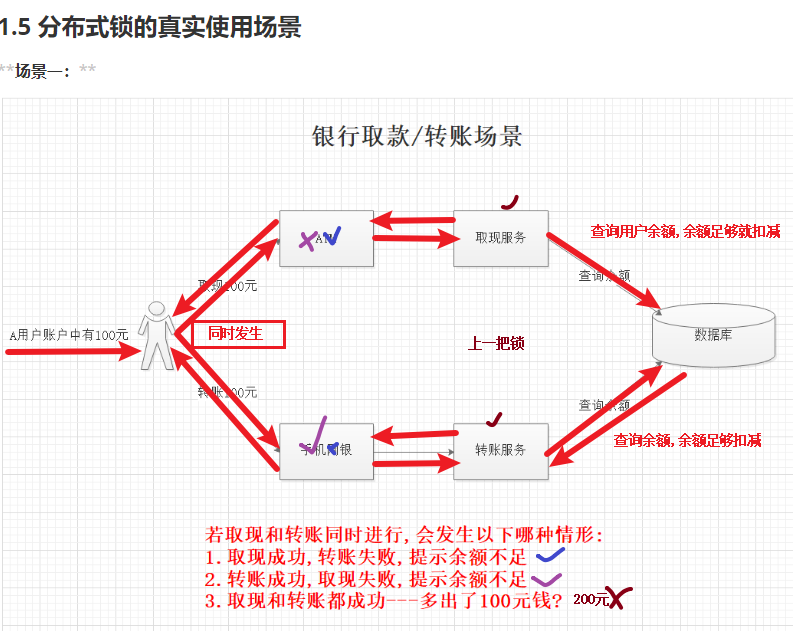
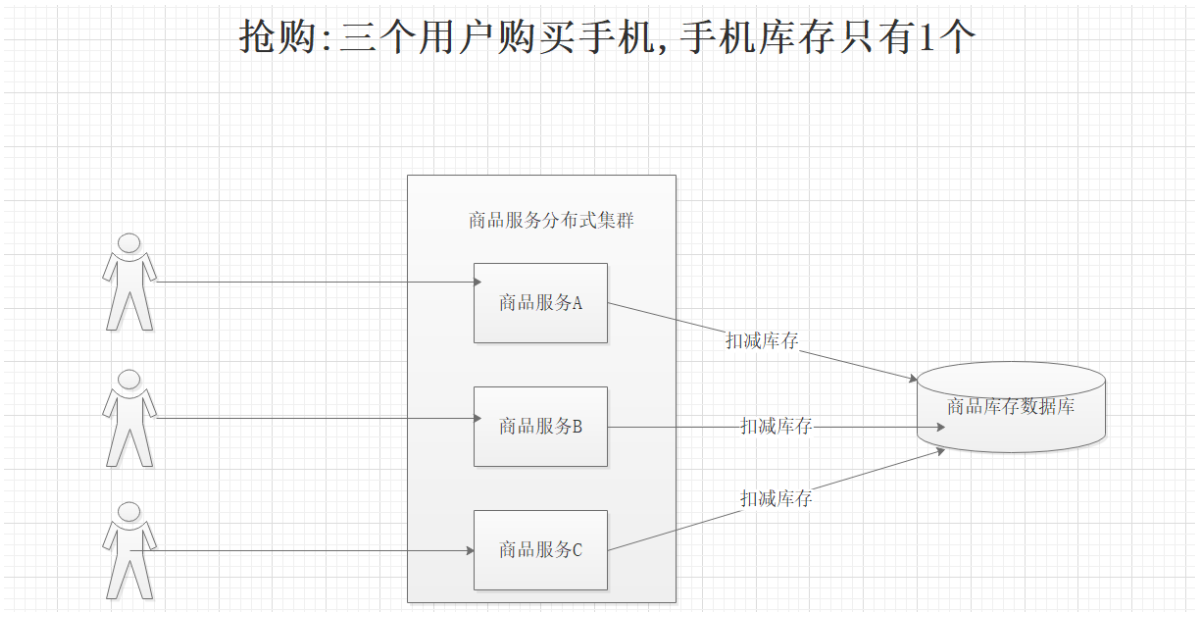
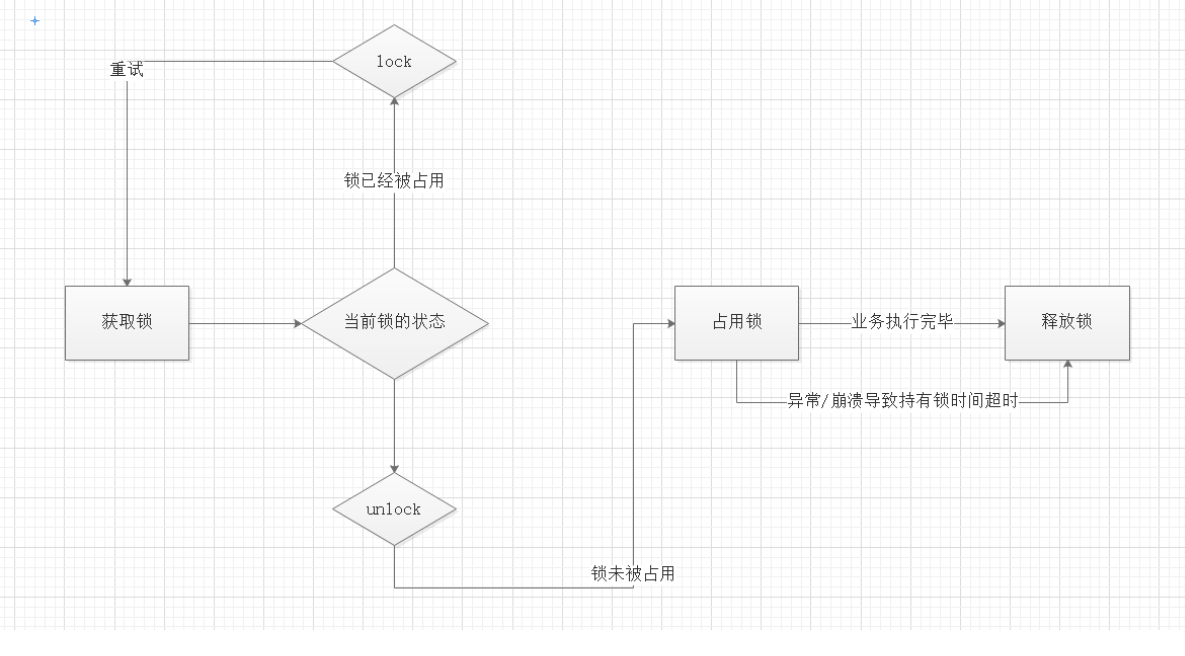
2.1.5、分布式锁的执行流程
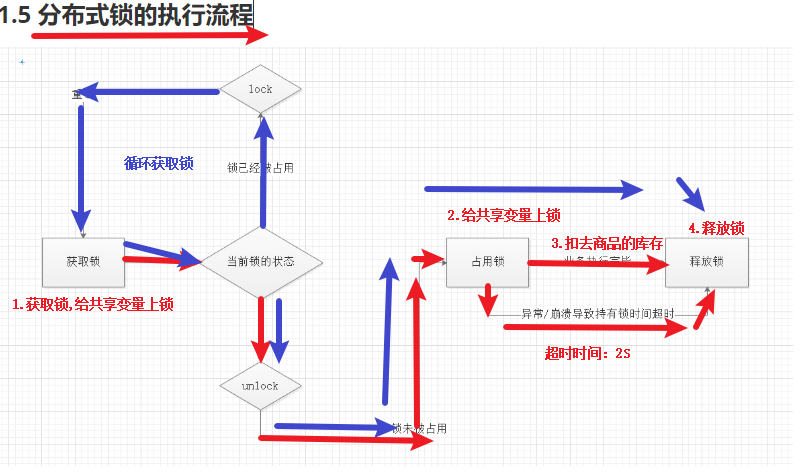
2.1.6、分布式锁具备的条件
- 互斥性:同一时刻只能有一个服务(或应用)访问资源,特殊情况下有读写锁
- 原子性:一致性要求保证加锁和解锁的行为是原子性的
- 安全性:锁只能被持有该锁的服务(或应用)释放
- 容错性:在持有锁的服务崩溃时,锁仍能得到释放避免死锁
- 可重用性:同一个客户端获得锁后可递归调用—-重入锁和不可重入锁
- 公平性:看业务是否需要公平,避免饿死—公平锁和非公平锁
- 支持阻塞和非阻塞:和 ReentrantLock 一样支持 lock 和 trylock 以及 tryLock(long timeOut)—-阻塞锁和非阻塞锁==PS:::自选锁==
- 高可用:获取锁和释放锁 要高可用
- 高性能:获取锁和释放锁的性能要好
- 持久性:锁按业务需要自动续约/自动延期
下面简单介绍一下这些特性:
可重入性
(使用了可重入锁:可重入锁就是当前获取的锁库给当前业务进行多次加锁,加了几把锁就要释放几把。)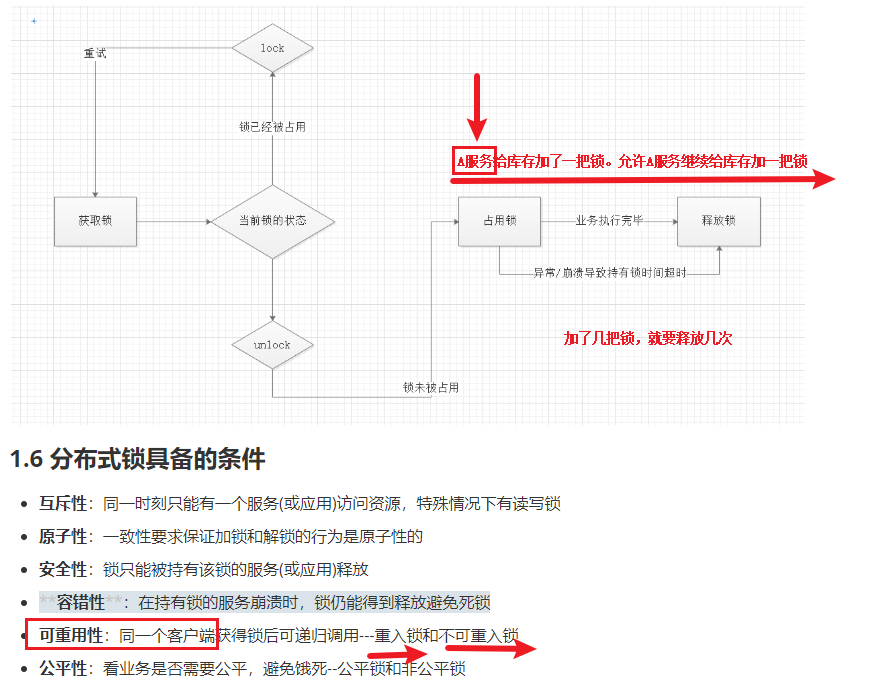
阻塞和非阻塞
下面图片解释
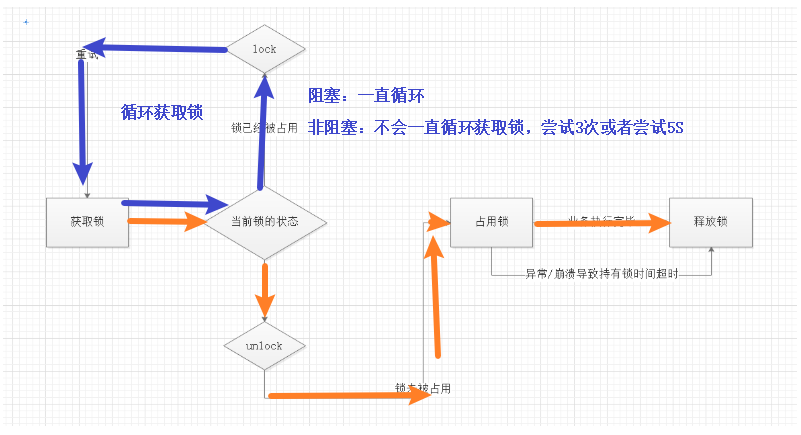
持久性:
持久性就是当前业务执行时间中途不会释放锁,锁会自动续约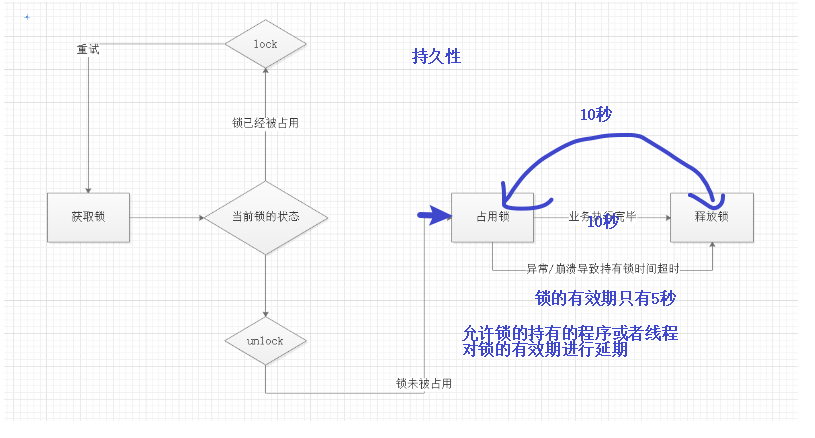
公平锁、非公平锁
公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
区别:非公平锁在 CAS 失败后,和公平锁一样都会进入到 tryAcquire 方法,在 tryAcquire 方法中,如果发现锁这个时候被释放了(state == 0),非公平锁会直接 CAS 抢锁,但是公平锁会判断等待队列是否有线程处于等待状态,如果有则不去抢锁,乖乖排到后面。
2.2、分布式锁的解决方案
2.2.1、数据库实现分布式锁
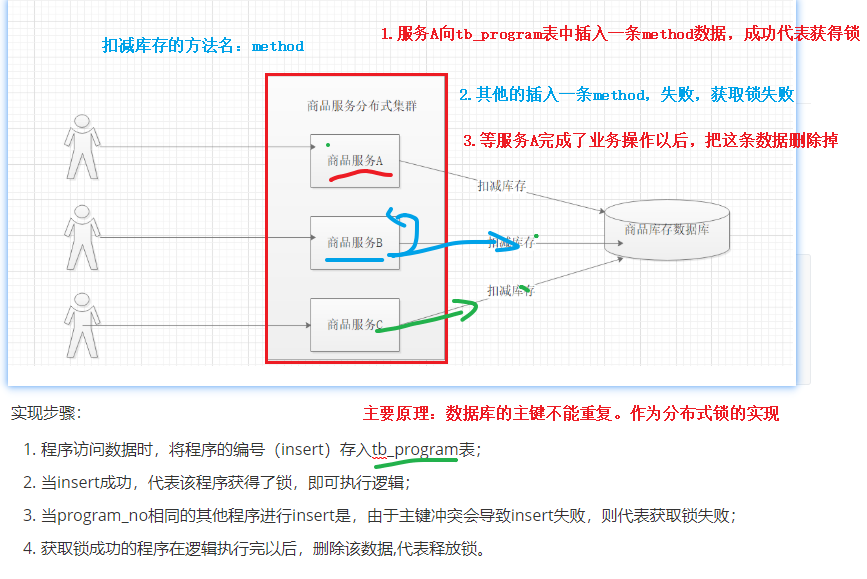
1、基于数据库表的实现
准备工作:创建tb_program表,用于记录当前哪个程序正在使用数据
CREATE TABLE `tb_program` (`program_no` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '程序的编号'PRIMARY KEY (`program_no`) USING BTREE) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
实现步骤:
- 程序访问数据时,将程序的编号(insert)存入tb_program表;
- 当insert成功,代表该程序获得了锁,即可执行逻辑;
- 当program_no相同的其他程序进行insert是,由于主键冲突会导致insert失败,则代表获取锁失败;
- 获取锁成功的程序在逻辑执行完以后,删除该数据,代表释放锁。
2、基于数据库的排他锁实现
除了可以通过增删操作数据表中的记录以外,其实还可以借助数据中自带的锁来实现分布式的锁。我们还用刚刚创建的那张数据库表,基于MySql的InnoDB引擎(MYSQL的引擎种类)可以通过数据库的排他锁来实现分布式锁。
实现步骤:
- 在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁
- 获得排它锁的线程即可获得分布式锁,执行方法的业务逻辑
- 执行完方法之后,再通过connection.commit();操作来释放锁。
业务分析: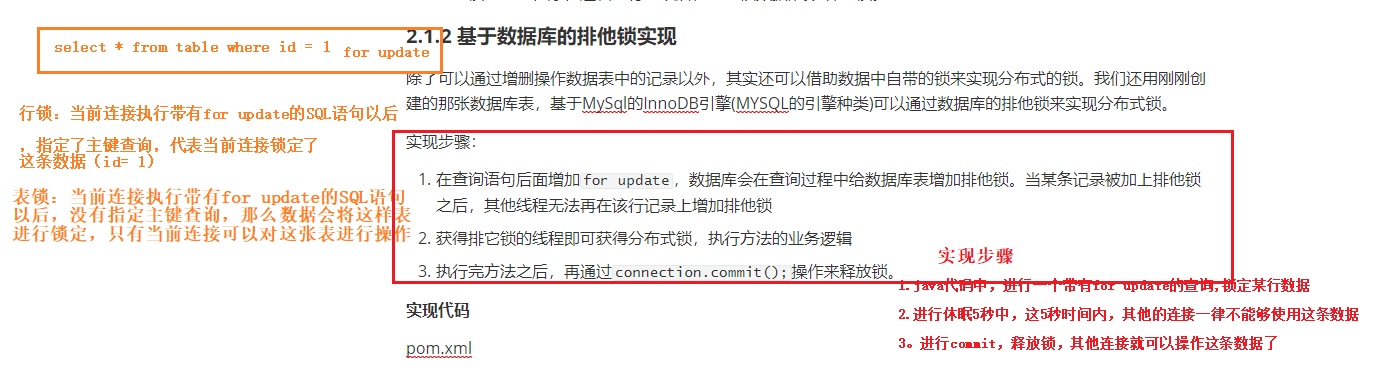
上面介绍了行锁和表锁的含义
下面举一个小demo来实现
pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.itheima</groupId><artifactId>mysql-demo</artifactId><version>1.0-SNAPSHOT</version><!--依赖包--><dependencies><!--核心包--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>5.3.1</version></dependency><!--一般分词器,适用于英文分词--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId><version>5.3.1</version></dependency><!--中文分词器--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-smartcn</artifactId><version>5.3.1</version></dependency><!--对分词索引查询解析--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>5.3.1</version></dependency><!--检索关键字高亮显示--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-highlighter</artifactId><version>5.3.1</version></dependency><!-- MySql --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.32</version></dependency><!-- Test dependencies --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency></dependencies></project>
Book
public class Book {// 图书IDprivate Integer id;// 图书名称private String name;// 图书价格private Float price;// 图书图片private String pic;// 图书描述private String desc;}
BookDao
public interface BookDao {/*** 查询所有的book数据* @return*/List<Book> queryBookList(String name) throws Exception;}
BookDaoImpl实现类
public class BookDaoImpl implements BookDao {/**** 查询数据库数据* @return* @throws Exception*/public List<Book> queryBookList(String name) throws Exception{// 数据库链接Connection connection = null;// 预编译statementPreparedStatement preparedStatement = null;// 结果集ResultSet resultSet = null;// 图书列表List<Book> list = new ArrayList<Book>();try {// 加载数据库驱动Class.forName("com.mysql.jdbc.Driver");// 连接数据库connection = DriverManager.getConnection("jdbc:mysql://39.108.189.37:3306/lucene", "ybbmysql", "ybbmysql");//关闭自动提交connection.setAutoCommit(false);// SQL语句String sql = "SELECT * FROM book where id = 1 for update";// 创建preparedStatementpreparedStatement = connection.prepareStatement(sql);// 获取结果集resultSet = preparedStatement.executeQuery();// 结果集解析while (resultSet.next()) {Book book = new Book();book.setId(resultSet.getInt("id"));book.setName(resultSet.getString("name"));list.add(book);}System.out.println(name + "执行了for update");System.out.println("结果为:" + list);//锁行后休眠5秒Thread.sleep(5000);//休眠结束释放connection.commit();System.out.println(name + "结束");} catch (Exception e) {e.printStackTrace();}return list;}}
测试类
public class Test {private BookDao bookDao = new BookDaoImpl();@org.junit.Testpublic void testLock() throws Exception {new Thread(new LockRunner("线程1")).start();new Thread(new LockRunner("线程2")).start();new Thread(new LockRunner("线程3")).start();new Thread(new LockRunner("线程4")).start();new Thread(new LockRunner("线程5")).start();Thread.sleep(200000L);}class LockRunner implements Runnable {private String name;public LockRunner(String name) {this.name = name;}public void run() {try {bookDao.queryBookList(name);}catch (Exception e){e.printStackTrace();}}}}
执行结果
这里5秒之后会执行commit就会释放锁,因为我们代码前面取消了自动提交。
3、优点及缺点
优点:简单,方便,快速实现
缺点:基于数据库,开销比较大,对数据库性能可能会存在影响
2.2.2、Redis实现分布式锁
1、基于 REDIS 的 SETNX()、EXPIRE() 、GETSET()方法做分布式锁
实现原理:
setnx():setnx 的含义就是 SET if Not Exists,其主要有两个参数 setnx(key, value)。该方法是原子的,如果 key 不存在,则设置当前 key 成功,返回 1;如果当前 key 已经存在,则设置当前 key 失败,返回 0
expire():expire 设置过期时间,要注意的是 setnx 命令不能设置 key 的超时时间,只能通过 expire() 来对 key 设置。
getset():这个命令主要有两个参数 getset(key,newValue)。该方法是原子的,对 key 设置 newValue 这个值,并且返回 key 原来的旧值。假设 key 原来是不存在的,那么多次执行这个命令,会出现下边的效果:
getset(key, “value1”) 返回 null 此时 key 的值会被设置为 value1 getset(key, “value2”) 返回 value1 此时 key 的值会被设置为 value2
 实现流程
实现流程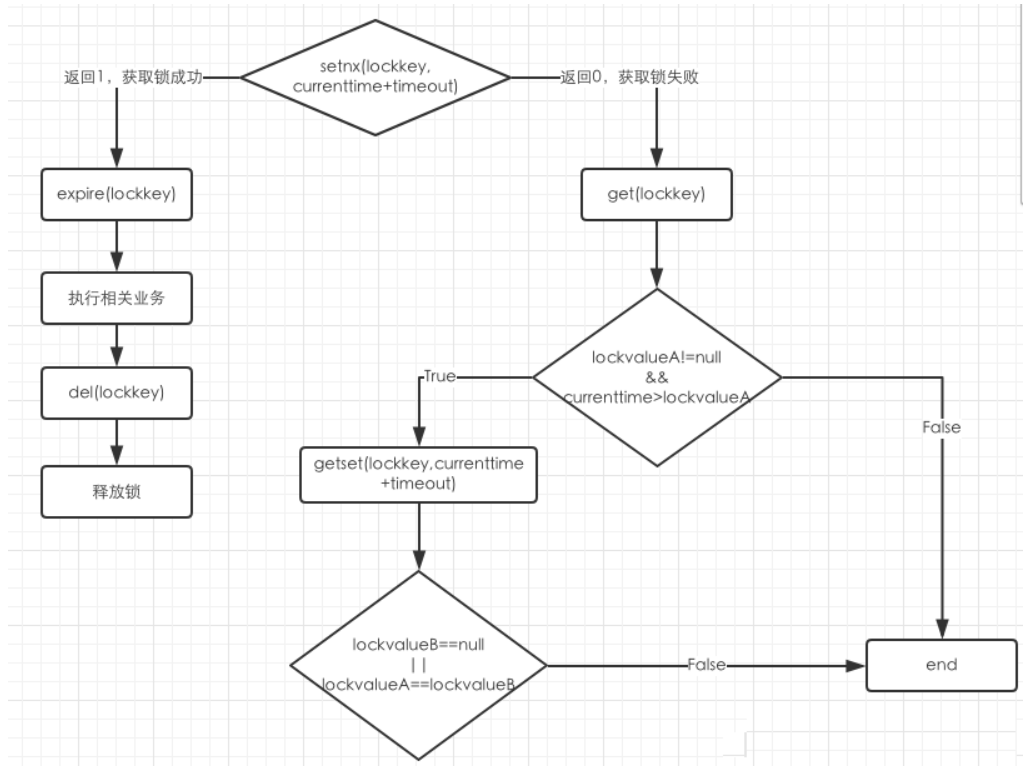
- setnx(lockkey, 当前时间+过期超时时间),如果返回 1,则获取锁成功;如果返回 0 则没有获取到锁。
- get(lockkey) 获取值 oldExpireTime ,并将这个 value 值与当前的系统时间进行比较,如果小于当前系统时间,则认为这个锁已经超时,可以允许别的请求重新获取。
- 计算 newExpireTime = 当前时间+过期超时时间,然后 getset(lockkey, newExpireTime) 会返回当前 lockkey 的值currentExpireTime。判断 currentExpireTime 与 oldExpireTime 是否相等,如果相等,说明当前 getset 设置成功,获取到了锁。如果不相等,说明这个锁又被别的请求获取走了,那么当前请求可以直接返回失败,或者继续重试。
- 在获取到锁之后,当前线程可以开始自己的业务处理,当处理完毕后,比较自己的处理时间和对于锁设置的超时时间,如果小于锁设置的超时时间,则直接执行 delete 释放锁;如果大于锁设置的超时时间,则不需要再锁进行处理。
代码实现:
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.6.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.itheima</groupId><artifactId>redis</artifactId><version>0.0.1-SNAPSHOT</version><name>redis</name><description>redis实现分布式锁测试</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
RedisUtil工具类
@Componentpublic class RedisUtil {//定义默认超时时间:单位毫秒private static final Integer LOCK_TIME_OUT = 10000;@Autowiredprivate StringRedisTemplate stringRedisTemplate;/*** 外部调用加锁方法*/public Boolean tryLock(String key, Long timeout) throws Exception{//获取当前系统时间设置为开始时间Long startTime = System.currentTimeMillis();//设置返回默认值-false:加锁失败boolean flag = false;//死循环获取锁:1.获取锁成功退出 2.获取锁超时退出while(true){//判断是否超时if((System.currentTimeMillis() - startTime) >= timeout){break;}else{//获取锁flag = lock(key);//判断是否获取成功if(flag){break;}else{//休息0.1秒重试,降低服务压力Thread.sleep(100);}}}return flag;}/*** 加锁实现* @param key* @return*/private Boolean lock(String key){return (Boolean) stringRedisTemplate.execute((RedisCallback) redisConnection -> {//获取当前系统时间Long time = System.currentTimeMillis();//设置锁超时时间Long timeout = time + LOCK_TIME_OUT + 1;//setnx加锁并获取解锁结果Boolean result = redisConnection.setNX(key.getBytes(), String.valueOf(timeout).getBytes());//加锁成功返回trueif(result){return true;}//加锁失败判断锁是否超时if(checkLock(key, timeout)){//getset设置值成功后,会返回旧的锁有效时间byte[] newtime = redisConnection.getSet(key.getBytes(), String.valueOf(timeout).getBytes());if(time > Long.valueOf(new String(newtime))){return true;}}//默认加锁失败return false;});}/*** 释放锁*/public Boolean release(String key){return (Boolean) stringRedisTemplate.execute((RedisCallback) redisConnection -> {Long del = redisConnection.del(key.getBytes());if (del > 0){return true;}return false;});}/*** 判断锁是否超时*/private Boolean checkLock(String key, Long timeout){return (Boolean) stringRedisTemplate.execute((RedisCallback) redisConnection -> {//获取锁的超时时间byte[] bytes = redisConnection.get(key.getBytes());try {//判断锁的有效时间是否大与当前时间if(timeout > Long.valueOf(new String(bytes))){return true;}}catch (Exception e){e.printStackTrace();return false;}return false;});}}
RedisController测试类
@RestController@RequestMapping(value = "/redis")public class RedisController {@Autowiredprivate RedisUtil redisUtil;/*** 获取锁* @return*/@GetMapping(value = "/lock/{name}")public String lock(@PathVariable(value = "name")String name) throws Exception{Boolean result = redisUtil.tryLock(name, 3000L);if(result){return "获取锁成功";}return "获取锁失败";}/*** 释放锁* @param name*/@GetMapping(value = "/unlock/{name}")public String unlock(@PathVariable(value = "name")String name){Boolean result = redisUtil.release(name);if(result){return "释放锁成功";}return "释放锁失败";}}
2、优点及缺点
优点:性能极高
缺点:失效时间设置没有定值。设置的失效时间太短,方法没等执行完锁就自动释放了,那么就会产生并发问题。如果设置的时间太长,其他获取锁的线程就可能要平白的多等一段时间,用户体验会降低。
2.2.3、Zookeeper实现分布式锁
1、Zookeeper锁相关知识
- zookeeper 一般由多个节点构成(单数),采用 zab 一致性协议。因此可以将 zk 看成一个单点结构,对其修改数据其内部自动将所有节点数据进行修改而后才提供查询服务。
- zookeeper 的数据以目录树的形式,每个目录称为 znode, znode 中可存储数据(一般不超过 1M),还可以在其中增加子节点。
- 子节点有三种类型。序列化节点,每在该节点下增加一个节点自动给该节点的名称上自增。临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除。最后就是普通节点。
Watch 机制,client 可以监控每个节点的变化,当产生变化会给 client 产生一个事件。
2、Zookeeper分布式锁原理
获取和释放锁原理:利用临时节点与 watch 机制。每个锁占用一个普通节点 /lock,当需要获取锁时在 /lock 目录下创建一个临时节点,创建成功则表示获取锁成功,失败则 watch/lock 节点,有删除操作后再去争锁。临时节点好处在于当进程挂掉后能自动上锁的节点自动删除即取消锁。
- 获取锁的顺序原理:上锁为创建临时有序节点,每个上锁的节点均能创建节点成功,只是其序号不同。只有序号最小的可以拥有锁,如果这个节点序号不是最小的则 watch 序号比本身小的前一个节点 (公平锁)。

3、Zookeeper实现分布式锁流程
简易流程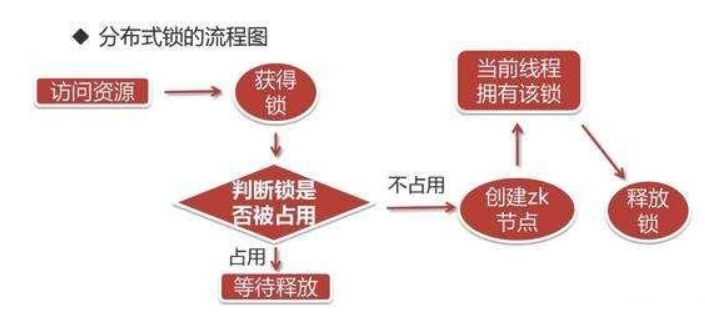
获取锁流程:
- 先有一个锁根节点,lockRootNode,这可以是一个永久的节点
- 客户端获取锁,先在 lockRootNode 下创建一个顺序的临时节点,保证客户端断开连接,节点也自动删除
- 调用 lockRootNode 父节点的 getChildren() 方法,获取所有的节点,并从小到大排序,如果创建的最小的节点是当前节点,则返回 true,获取锁成功,否则,关注比自己序号小的节点的释放动作(exist watch),这样可以保证每一个客户端只需要关注一个节点,不需要关注所有的节点,避免羊群效应。
- 如果有节点释放操作,重复步骤 3
释放锁流程:
只需要删除步骤 2 中创建的节点即可
4、 优点及缺点
优点:
- 客户端如果出现宕机故障的话,锁可以马上释放
- 可以实现阻塞式锁,通过 watcher 监听,实现起来也比较简单
- 集群模式,稳定性比较高
缺点:
- 一旦网络有任何的抖动,Zookeeper 就会认为客户端已经宕机,就会断掉连接,其他客户端就可以获取到锁。
- 性能不高,因为每次在创建锁和释放锁的过程中,都要动态创建、销毁临时节点来实现锁功能。ZK 中创建和删除节点只能通过 Leader 服务器来执行,然后将数据同步到所有的 Follower 机器上。(zookeeper对外提供服务的只有leader)
2.2.4、consul实现分布式锁(eureka/Register:保存服务的IP 端口 服务列表)
1、实现原理及流程
基于Consul注册中心的Key/Value存储来实现分布式锁以及信号量的方法主要利用Key/Value存储API中的acquire和release操作来实现。acquire和release操作是类似Check-And-Set的操作:
acquire操作只有当锁不存在持有者时才会返回true,并且set设置的Value值,同时执行操作的session会持有对该Key的锁,否则就返回false
release操作则是使用指定的session来释放某个Key的锁,如果指定的session无效,那么会返回false,否则就会set设置Value值,并返回true
实现流程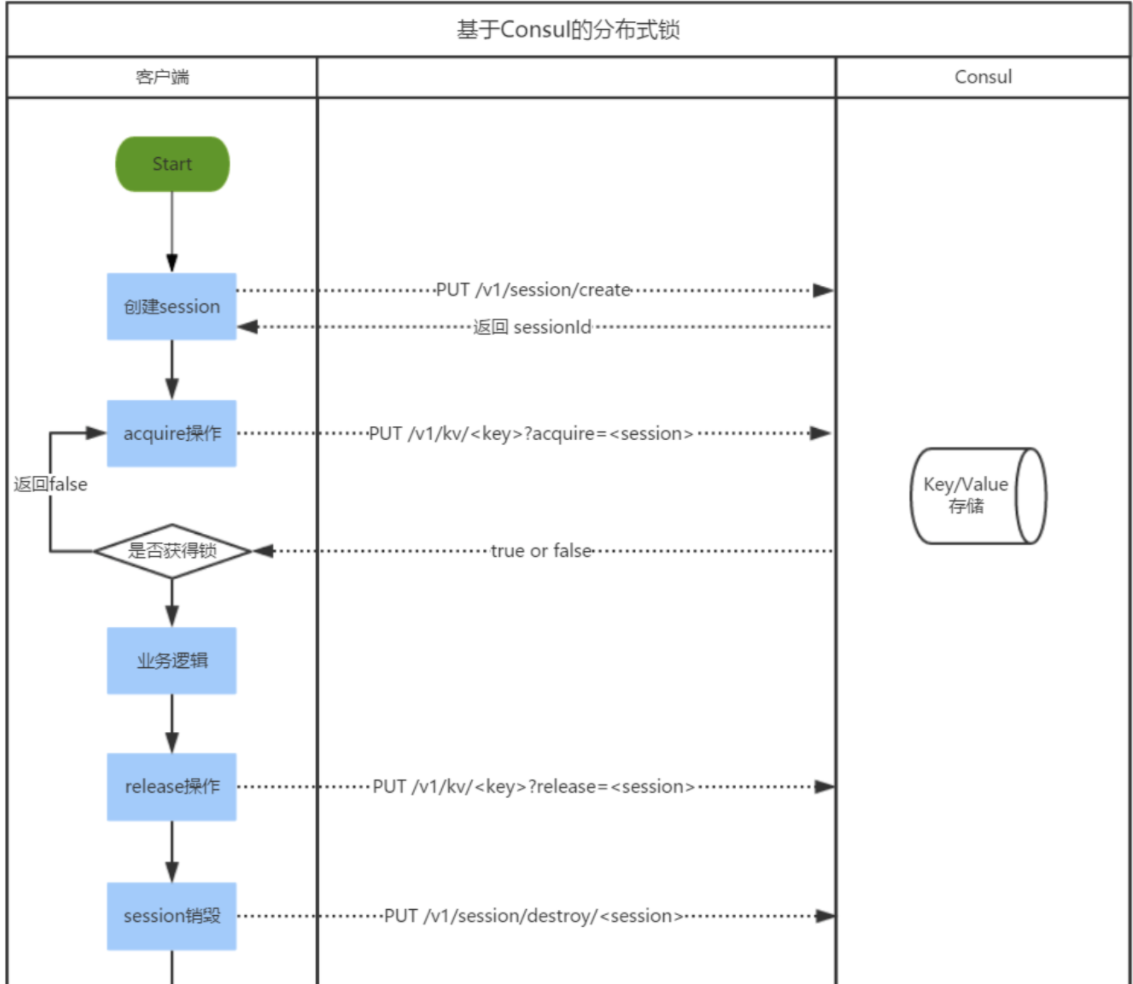

实现步骤:
- 客户端创建会话session,得到sessionId;
- 使用acquire设置value的值,若acquire结果为false,代表获取锁失败;
- acquire结果为true,代表获取锁成功,客户端执行业务逻辑;
- 客户端业务逻辑执行完成后,执行release操作释放锁;
- 销毁当前session,客户端连接断开。
代码:
下载consul
启动consul命令: consul agent -dev
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.2.5.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.example</groupId><artifactId>demo-consul</artifactId><version>0.0.1-SNAPSHOT</version><name>demo-consul</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version><spring-cloud.version>Hoxton.SR3</spring-cloud.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-consul-discovery</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>
public class ConsulUtil {private ConsulClient consulClient;private String sessionId = null;/*** 构造函数*/public ConsulUtil(ConsulClient consulClient) {this.consulClient = consulClient;}/*** 创建session*/private String createSession(String name, Integer ttl){NewSession newSession = new NewSession();//设置锁有效时长newSession.setTtl(ttl + "s");//设置锁名字newSession.setName(name);String value = consulClient.sessionCreate(newSession, null).getValue();return value;}/*** 获取锁*/public Boolean lock(String name, Integer ttl){//定义获取标识Boolean flag = false;//创建sessionsessionId = createSession(name, ttl);//死循环获取锁while (true){//执行acquire操作PutParams putParams = new PutParams();putParams.setAcquireSession(sessionId);flag = consulClient.setKVValue(name, "local" + System.currentTimeMillis(), putParams).getValue();if(flag){break;}}return flag;}/*** 释放锁*/public Boolean release(String name){//执行acquire操作PutParams putParams = new PutParams();putParams.setReleaseSession(sessionId);Boolean value = consulClient.setKVValue(name, "local" + System.currentTimeMillis(), putParams).getValue();return value;}
测试代码:
@SpringBootTestclass DemoApplicationTests {@Testpublic void testLock() throws Exception {new Thread(new LockRunner("线程1")).start();new Thread(new LockRunner("线程2")).start();new Thread(new LockRunner("线程3")).start();new Thread(new LockRunner("线程4")).start();new Thread(new LockRunner("线程5")).start();Thread.sleep(200000L);}class LockRunner implements Runnable {private String name;public LockRunner(String name) {this.name = name;}@Overridepublic void run() {ConsulUtil lock = new ConsulUtil(new ConsulClient());try {if (lock.lock("test", 10)) {System.out.println(name + "获取到了锁");//持有锁5秒Thread.sleep(5000);//释放锁lock.release("test");System.out.println(name + "释放了锁");}} catch (Exception e) {e.printStackTrace();}}}}

2、优点及缺点
优点:基于consul注册中心即可实现分布式锁,实现简单、方便、快捷
缺点:
- lock delay:consul实现分布式锁存在延迟,一个节点释放锁了,另一个节点不能立马拿到锁。需要等待lock delay时间后才可以拿到锁。
- 高负载的场景下,不能及时的续约,导致session timeout, 其他节点拿到锁。

若有收获,就点个赞吧
0 人点赞
