

HDFS全称是Hadoop Distributed File System, 也就是Hadoop分布式文件系统,是一种在硬件上运行的分布式文件系统。它与现有的分布式文件系统有许多相似之处。
但是,与其他分布式文件系统的区别很明显。HDFS具有高度的容错能力,旨在部署在低成本硬件上。HDFS提供对应用程序数据的高吞吐量访问,并且适用于具有大数据集的应用程序。
HDFS是一种适合大文件存储的分布式文件系统,不适合小文件存储,也就是几KB和几M的那些文件。
一、HDFS语法
接下来我们通过实操来加深对HDFS的理解,针对HDFS,我们可以在命令行中进行操作,操作起来和Linux差不多,但还是有一丝不同,语法为
hdfs dfs -<命令> hdfs://<ip>:<port>//<path>
如果你未配置HDFS到系统环境变量,那么应该进入到HDFS的bin目录中运行HDFS命令。其实右半部分hdfs://xxx这块就是我们在core-site.xml中配置的fs.defaultFS的值,如果系统配置了HADOOP_HOME那么是不需要在写了,因为会自动读取
二、HDFS的基本操作
如果没有安装大数据平台的话,建议先去看我的上一篇CDH6.2大数据平台安装部署手册。接下来我们就来介绍一下HDFS中常见的一些命令操作,HDFS的命令很多,但是很多都用的不多,这里就不全部介绍了,只介绍一些常用的命令,其他的你们就自己去看 HDFS的文档 哈,我们通过hdfs dfs就可以带出后面的所有命令
[root@hadoop1 conf]# hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
- -ls命令
这个命令和Linux系统中的ls一样,查看目录下的所有内容
[root@hadoop1 conf]# hdfs dfs -ls /
Found 3 items
drwxr-xr-x - hdfs supergroup 0 2020-12-03 17:24 /test
drwxrwxrwt - hdfs supergroup 0 2020-12-02 15:59 /tmp
drwxr-xr-x - hdfs supergroup 0 2020-12-02 15:58 /user
可以看到列出了在根目录下的所有内容,因为上一篇安装大数据平台的时候有生成目录,所以这里有内容
- -mkdir [-p]
创建文件夹
# 创建个/test2文件夹
[root@hadoop1 conf]# hdfs dfs -mkdir /test2
# 查看是否存在我们刚刚创建的目录
[root@hadoop1 conf]# hdfs dfs -ls /
Found 4 items
drwxr-xr-x - hdfs supergroup 0 2020-12-03 17:24 /test
drwxr-xr-x - hdfs supergroup 0 2020-12-07 10:27 /test2
drwxrwxrwt - hdfs supergroup 0 2020-12-02 15:59 /tmp
drwxr-xr-x - hdfs supergroup 0 2020-12-02 15:58 /user
如果需要递归创建文件夹,就在命令后加上-p参数
[root@hadoop1 conf]# hdfs dfs -mkdir -p /test3/test
[root@hadoop1 conf]# hdfs dfs -ls /test3
Found 1 items
drwxr-xr-x - hdfs supergroup 0 2020-12-07 10:31 /test3/test
- -put
向HDFS中上传一个文件,我们先事先创建一个文本文件,然后上传到HDFS的根目录
[root@hadoop1 /]# hdfs dfs -put hello.txt /
[root@hadoop1 /]# hdfs dfs -ls /
Found 6 items
-rw-r--r-- 3 hdfs supergroup 6 2020-12-07 10:34 /hello.txt
drwxr-xr-x - hdfs supergroup 0 2020-12-03 17:24 /test
drwxr-xr-x - hdfs supergroup 0 2020-12-07 10:27 /test2
drwxr-xr-x - hdfs supergroup 0 2020-12-07 10:31 /test3
drwxrwxrwt - hdfs supergroup 0 2020-12-02 15:59 /tmp
drwxr-xr-x - hdfs supergroup 0 2020-12-02 15:58 /user
- -cat
查看文件中的内容
# 查看刚刚上传的文本内容
[root@hadoop1 /]# hdfs dfs -cat /hello.txt
hello
- -get
下载HDFS中的文件到本地
[root@hadoop1 /]# hdfs dfs -get /test .

- -rm
删除目录和文件
删除文件
[root@hadoop1 /]# hdfs dfs -rm /hello.txt
20/12/07 11:12:30 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop1:8020/hello.txt' to trash at: hdfs://hadoop1:8020/user/hdfs/.Trash/Current/hello.txt
删除目录
[root@hadoop1 /]# hdfs dfs -rm -r /test2
20/12/07 11:13:34 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop1:8020/test2' to trash at: hdfs://hadoop1:8020/user/hdfs/.Trash/Current/test2
如果开启了回收策略,那么如果你想彻底删除,需要在命令后加上-skipTrash,这样就彻底删除了
[root@hadoop1 /]# hdfs dfs -rm -r -skipTrash /test
Deleted /test
三、Java操作HDFS
事先我们创建好一个Maven项目,然后引入Hadoop的依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
然后编写代码
package com.gjing.projects.bigdata.hdfs;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
/**
* Java操作HDFS, 这里只举例了部分操作例子,其他的自己可以一一实现下哈
*
* @author Gjing
**/
public class HdfsDemo {
public static void main(String[] args) throws IOException {
// 创建一个配置
Configuration configuration = new Configuration();
// 设置HDFS的地址
configuration.set("fs.defaultFS","hdfs://hadoop1:8020");
// 此处副本数最好设置和集群中的hdfs-site.xml中一致,否则可能会出现副本块不足的警告
configuration.set("dfs.replication","3");
// 获取HDFS的操作对象
FileSystem fileSystem = FileSystem.get(configuration);
// 1、创建目录
boolean mkdirs = fileSystem.mkdirs(new Path("/test"));
System.out.println("创建目录: " + mkdirs);
// 2、创建文件并写入内容
FSDataOutputStream outputStream = fileSystem.create(new Path("/test/hello.txt"));
outputStream.writeUTF("hello world");
outputStream.flush();
outputStream.close();
// 3、查看写入的内容
FSDataInputStream inputStream = fileSystem.open(new Path("/test/hello.txt"));
IOUtils.copy(inputStream, System.out);
// 4、删除目录 并递归删除其下面的文件和目录
boolean delete = fileSystem.delete(new Path("/test"), true);
System.out.println("\n删除文件: " + delete);
}
}
这时候尝试启动下发现会报一个权限异常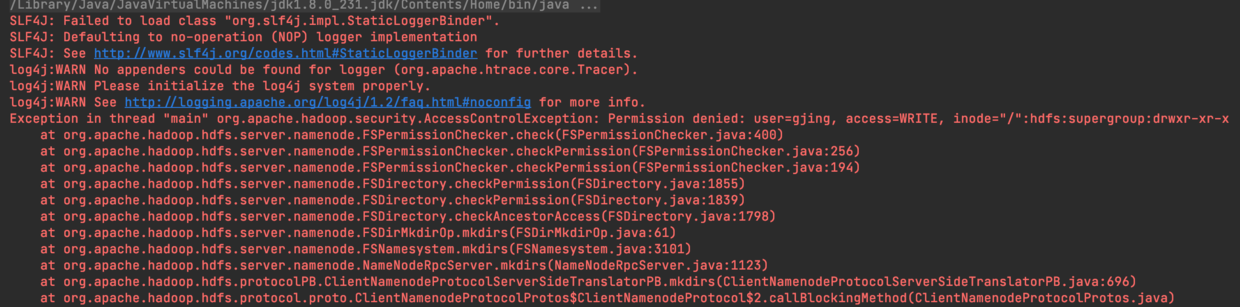
回想一下我们在刚搭建完大数据平台的时候,通过服务器去操作HDFS的时候,也报了权限异常,后来在环境变量中设置了Hadoop的执行用户得以解决,这里也同理,在代码第一行加入System.setProperty("HADOOP_USER_NAME", "hdfs");
/**
* Java操作HDFS, 这里只举例了部分操作例子,其他的自己可以一一实现下哈
*
* @author Gjing
**/
public class HdfsDemo {
public static void main(String[] args) throws IOException {
// 加入这行代码,设置执行用户,解决权限不足问题
System.setProperty("HADOOP_USER_NAME", "hdfs");
// 创建一个配置
Configuration configuration = new Configuration();
// 设置HDFS的地址
configuration.set("fs.defaultFS","hdfs://hadoop1:8020");
// 此处副本数最好设置和集群中的hdfs-site.xml中一致,否则可能会出现副本块不足的警告
configuration.set("dfs.replication","3");
// 获取HDFS的操作对象
FileSystem fileSystem = FileSystem.get(configuration);
// 1、创建目录
boolean mkdirs = fileSystem.mkdirs(new Path("/test"));
System.out.println("创建目录: " + mkdirs);
// 2、创建文件并写入内容
FSDataOutputStream outputStream = fileSystem.create(new Path("/test/hello.txt"));
outputStream.writeUTF("hello world");
outputStream.flush();
outputStream.close();
// 3、查看写入的内容
FSDataInputStream inputStream = fileSystem.open(new Path("/test/hello.txt"));
IOUtils.copy(inputStream, System.out);
// 4、删除目录 并递归删除其下面的文件和目录
boolean delete = fileSystem.delete(new Path("/test"), true);
System.out.println("\n删除文件: " + delete);
}
}
接下来可以看到执行成功了,控制台也输出了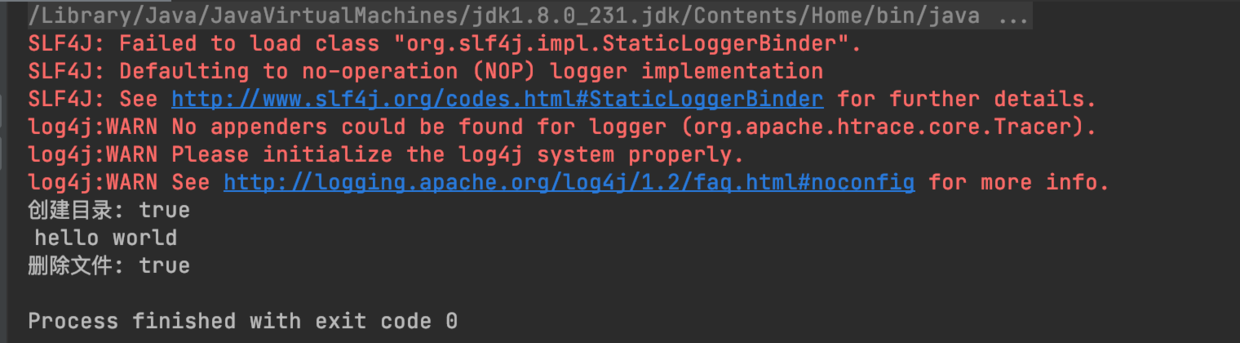
四、HDFS架构体系
HDFS具有主/从体系结构。主节点称为NameNode,因为其节点上运行了NameNode进程,NameNode支持多个,目前我们集群中就配置了一个,在文章的末尾我们会介绍如何通过CM来搭建多主多从的HDFS集群。
从节点称为DataNode,节点中有启动DataNode进程。DataNode支持多个,目前集群中配了两个。
还有一个进程SecondaryNameNode,字面意思为第二个NameNode,但是作用和NameNode有点不同哈,下面会为大家介绍。接下来看看下面的这张图,这是HDFS官网的体系图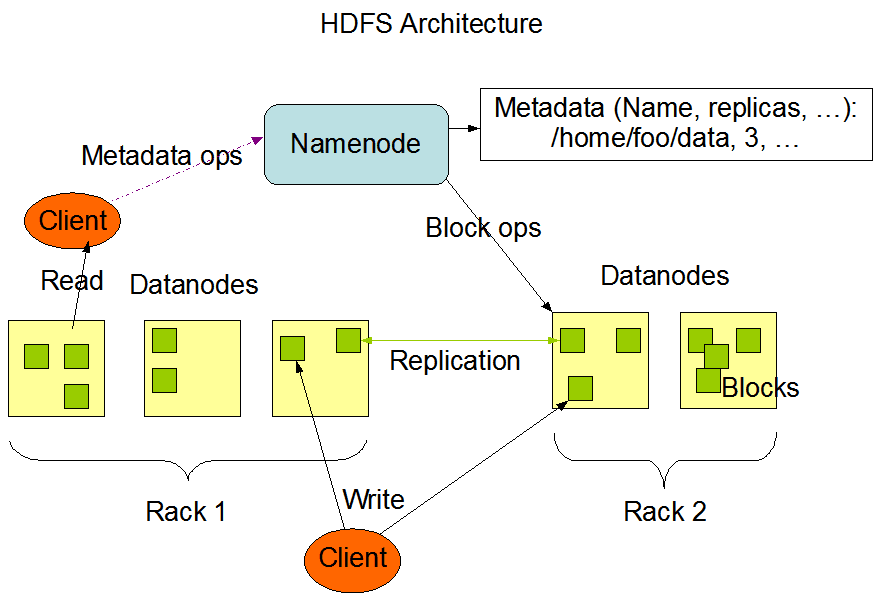
1、NameNode
NameNode是整个文件系统的管理节点,它主要维护整个文件系统的目录树、文件、目录的信息和每个文件对应的数据块列表,并且还负责接收用户的请求:
- 目录树:就是我们通过
-ls命令查看的目录结构 - 文件、目录信息:文件的基本信息,像什么用户组、文件大小、修改时间等等
- 数据块列表:文件太大会被切割为多个块,存储到不同机器上面,所以会记录有多少块,每一块的存储位置
- 接收用户的请求:在我们通过命令行或者代码的时候都是需要先和NameNode通信的,其次才会开始去操作
接下来我们看看NameNode到底包含哪些文件:
- fsimage
- edits
- seed_txid
- VERSION
这些文件存储位置是通过hdfs-site.xml配置文件指定的,由于我们是通过CM来安装的,所以配置文件位置在/etc/hadoop/conf目录,进入到这个目录然后打开这个配置文件,查询dfs.namenode.name.dir这个配置,值就是我们要找的存储位置了
接下来我们进入到这个目录/dfs/nn,这时候通过ls查看可以发现一个current目录和in_use.lock文件,in_use.lock文件相当于是一把锁,如果没有的话才可以启动NameNode成功,否则启动失败,停止的时候会把这个锁去掉。接下来我们进入到current目录,里面有我们前面讲到的那四个文件了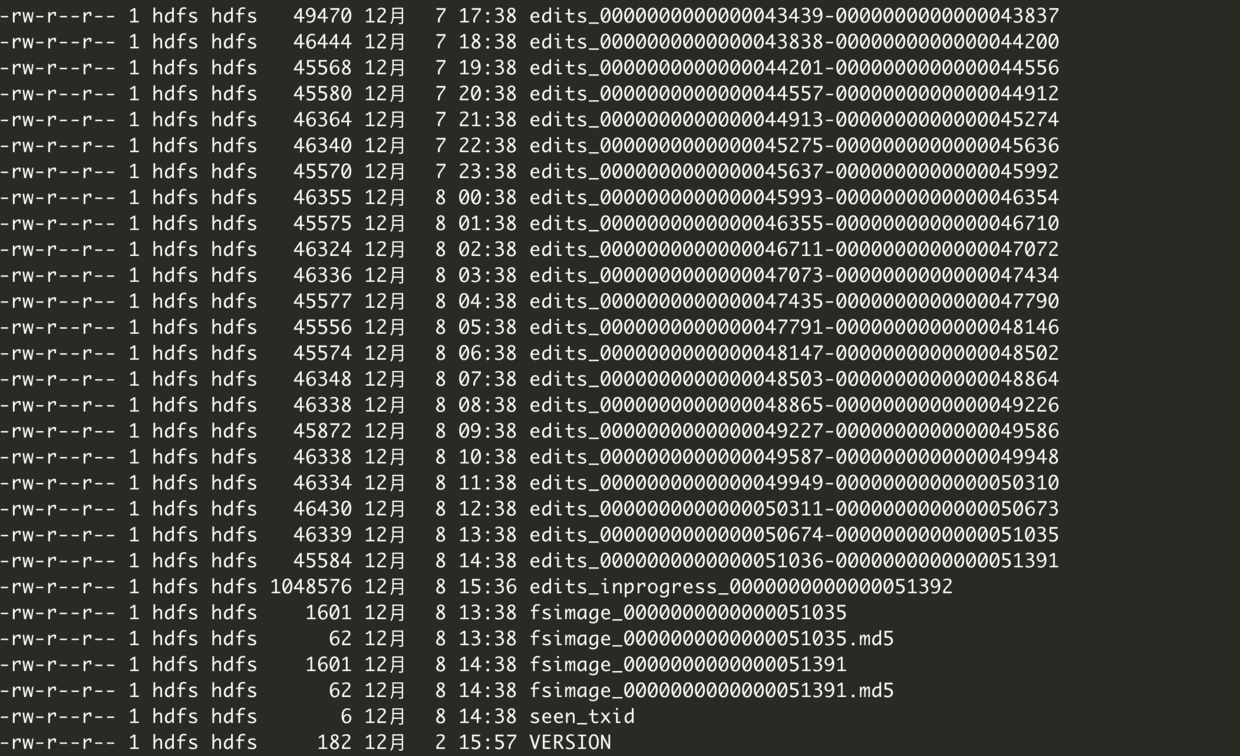
可以看到fsimage文件有两个文件名相同的,有一个后缀为md5,这其实是用来做MD5校验的,为了保证传输过程中不出问题,相同的文件内容MD5是一样的,接下来我们来看看fsimage文件,我们先随意找到一个文件,然后格式化成xml,否则无法观看
[root@hadoop1 current]# hdfs oiv -p XML -i fsimage_0000000000000051391 -o fsimage51391.xml
然后将生成的fsimage51391.xml文件拉取到我们电脑上去看,这样会看的比较直观,下面就是这个文件的内容了
<?xml version="1.0"?>
<fsimage><version><layoutVersion>-64</layoutVersion><onDiskVersion>1</onDiskVersion><oivRevision>7ce7dcdb76fd7f700cd7749bbc6390f76ff2abae</oivRevision></version>
<NameSection><namespaceId>710664213</namespaceId><genstampV1>1000</genstampV1><genstampV2>9509</genstampV2><genstampV1Limit>0</genstampV1Limit><lastAllocatedBlockId>1073750333</lastAllocatedBlockId><txid>51391</txid></NameSection>
<ErasureCodingSection>
<erasureCodingPolicy>
<policyId>1</policyId><policyName>RS-6-3-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema>
<codecName>rs</codecName><dataUnits>6</dataUnits><parityUnits>3</parityUnits></ecSchema>
</erasureCodingPolicy>
<erasureCodingPolicy>
<policyId>2</policyId><policyName>RS-3-2-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema>
<codecName>rs</codecName><dataUnits>3</dataUnits><parityUnits>2</parityUnits></ecSchema>
</erasureCodingPolicy>
<erasureCodingPolicy>
<policyId>3</policyId><policyName>RS-LEGACY-6-3-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema>
<codecName>rs-legacy</codecName><dataUnits>6</dataUnits><parityUnits>3</parityUnits></ecSchema>
</erasureCodingPolicy>
<erasureCodingPolicy>
<policyId>4</policyId><policyName>XOR-2-1-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema>
<codecName>xor</codecName><dataUnits>2</dataUnits><parityUnits>1</parityUnits></ecSchema>
</erasureCodingPolicy>
<erasureCodingPolicy>
<policyId>5</policyId><policyName>RS-10-4-1024k</policyName><cellSize>1048576</cellSize><policyState>DISABLED</policyState><ecSchema>
<codecName>rs</codecName><dataUnits>10</dataUnits><parityUnits>4</parityUnits></ecSchema>
</erasureCodingPolicy>
</ErasureCodingSection>
<INodeSection><lastInodeId>24918</lastInodeId><numInodes>18</numInodes><inode><id>16385</id><type>DIRECTORY</type><name></name><mtime>1607330993617</mtime><permission>hdfs:supergroup:0755</permission><nsquota>9223372036854775807</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16386</id><type>DIRECTORY</type><name>tmp</name><mtime>1606895984184</mtime><permission>hdfs:supergroup:1777</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16387</id><type>DIRECTORY</type><name>user</name><mtime>1607310750934</mtime><permission>hdfs:supergroup:0755</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16388</id><type>DIRECTORY</type><name>history</name><mtime>1606895969221</mtime><permission>mapred:hadoop:0777</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16389</id><type>DIRECTORY</type><name>logs</name><mtime>1606895909065</mtime><permission>mapred:hadoop:1777</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16390</id><type>DIRECTORY</type><name>yarn</name><mtime>1606895922067</mtime><permission>hdfs:supergroup:0755</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16391</id><type>DIRECTORY</type><name>mapreduce</name><mtime>1606895922067</mtime><permission>hdfs:supergroup:0755</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16392</id><type>DIRECTORY</type><name>mr-framework</name><mtime>1606895944188</mtime><permission>yarn:hadoop:0775</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16393</id><type>FILE</type><name>3.0.0-cdh6.2.1-mr-framework.tar.gz</name><replication>2</replication><mtime>1606895958279</mtime><atime>1606895944188</atime><preferredBlockSize>134217728</preferredBlockSize><permission>yarn:hadoop:0644</permission><blocks><block><id>1073741825</id><genstamp>1001</genstamp><numBytes>134217728</numBytes></block>
<block><id>1073741826</id><genstamp>1002</genstamp><numBytes>98472263</numBytes></block>
</blocks>
<storagePolicyId>0</storagePolicyId></inode>
<inode><id>16394</id><type>DIRECTORY</type><name>done</name><mtime>1606895969160</mtime><permission>mapred:hadoop:0771</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16395</id><type>DIRECTORY</type><name>done_intermediate</name><mtime>1606895969221</mtime><permission>mapred:hadoop:1777</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>16396</id><type>DIRECTORY</type><name>.cloudera_health_monitoring_canary_files</name><mtime>1607409437182</mtime><permission>hdfs:supergroup:0000</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>23264</id><type>DIRECTORY</type><name>hdfs</name><mtime>1607310750935</mtime><permission>hdfs:supergroup:0700</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>23265</id><type>DIRECTORY</type><name>.Trash</name><mtime>1607400000070</mtime><permission>hdfs:supergroup:0700</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>23611</id><type>DIRECTORY</type><name>test</name><mtime>1607332229117</mtime><permission>hdfs:supergroup:0755</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>23617</id><type>DIRECTORY</type><name>201207170000</name><mtime>1607331241353</mtime><permission>hdfs:supergroup:0700</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>23618</id><type>DIRECTORY</type><name>test</name><mtime>1607331295270</mtime><permission>hdfs:supergroup:0700</permission><nsquota>-1</nsquota><dsquota>-1</dsquota></inode>
<inode><id>23640</id><type>FILE</type><name>hello.txt</name><replication>3</replication><mtime>1607335831056</mtime><atime>1607332229117</atime><preferredBlockSize>134217728</preferredBlockSize><permission>hdfs:supergroup:0644</permission><storagePolicyId>0</storagePolicyId></inode>
</INodeSection>
<INodeReferenceSection></INodeReferenceSection><SnapshotSection><snapshotCounter>0</snapshotCounter><numSnapshots>0</numSnapshots></SnapshotSection>
<INodeDirectorySection><directory><parent>16385</parent><child>23611</child><child>16386</child><child>16387</child></directory>
<directory><parent>16386</parent><child>16396</child><child>16389</child></directory>
<directory><parent>16387</parent><child>23264</child><child>16388</child><child>16390</child></directory>
<directory><parent>16388</parent><child>16394</child><child>16395</child></directory>
<directory><parent>16390</parent><child>16391</child></directory>
<directory><parent>16391</parent><child>16392</child></directory>
<directory><parent>16392</parent><child>16393</child></directory>
<directory><parent>23264</parent><child>23265</child></directory>
<directory><parent>23265</parent><child>23617</child></directory>
<directory><parent>23611</parent><child>23640</child></directory>
<directory><parent>23617</parent><child>23618</child></directory>
</INodeDirectorySection>
<FileUnderConstructionSection></FileUnderConstructionSection>
<SecretManagerSection><currentId>0</currentId><tokenSequenceNumber>0</tokenSequenceNumber><numDelegationKeys>0</numDelegationKeys><numTokens>0</numTokens></SecretManagerSection><CacheManagerSection><nextDirectiveId>1</nextDirectiveId><numDirectives>0</numDirectives><numPools>0</numPools></CacheManagerSection>
</fsimage>
最外层可以看到是fsimage标签,然后往下看,可以看到inode标签,每个inode表示的是hdfs中的一个目录或者文件,例如:
那么inode标签内的那些子标签是啥意思呢
| 标签 | 描述 |
|---|---|
| id | 唯一编号 |
| type | 文件类型 |
| name | 文件名称 |
| replication | 副本数量 |
| mtime | 修改时间 |
| atime | 访问时间 |
| preferredBlockSize | 推荐每一个数据块的大小 |
| permission | 权限信息 |
| blocks | 包含多少数据块 |
| block | 内部的id表示为块的id,genstamp是唯一编号,numBytes表示块的实际大小,storagePolicyId表示存储策略 |
从这个表格里我们可以看出,这个文件存储了hdfs里最核心的数据。
那么edits文件里面存储了哪些东西呢,其实,可以把它看成是一个事务文件,为啥捏?举个栗子,加入你要上传个几G的文件,那么hdfs会把他拆成好几个块,那么edits文件会记录每个块上传的状态,只有上传成功了edits文件才会记录这个文件上传成功了,这时候就能通过hdfs dfs -ls <目录>查看到这个文件了。
接下来我们来查看下edits文件的内容,和查看fsimage文件一样,先转成xml,在拉到本机查看
[root@hadoop1 current]# hdfs oev -i edits_0000000000000050674-0000000000000051035 -o edits.xml
这里我们就不展示所有内容了, 你们可以自行查看哈,我们通过查看文件可以看到里面有很多的record标签,每一个record都是代表不同的操作,例如OPP_ADD、OPP_DELETE等等,都能直观理解哈,这里就不讲解了,这里面的record都有一个事务id和txid,事务id是连续的,上传一个文件会生成很多record,这个我们都看不了。
通过介绍上面两个文件,我们发现两个文件不一致,那么是内部是如何将fsimage文件和edits文件保持一致的,其实是定期合并的哈,hdfs内部会对edits文件进行精简,至于如何精简的,有兴趣的同学就去自己看看框架源码了解其原理哈,这里就不多说了哈。
那么是什么进程在执行这个操作呢,是NameNode吗,显然不是,不然它还不得累死啊,又要接收用户请求又要处理合并。这时候就要祭出我们之前提到的第二个NameNode了,那就是SecondaryNamenode,他只做一件事,那就是合并edits文件到fsimage文件中,实际工作中部署时最好部署在单独的节点上。
current目录下还有一个seen_txid文件,这里面存的是hdfs format之后edits_*文件的尾数,
NameNode重启的时候会从头开始读edits_000000000000001到seen_txid的数字,如果根据对应的seen_txid找不到对应的文件,那么就会启动失败以保护数据一致性。
最后一个文件VERSION存的就是集群的版本信息了
2、SecondaryNameNode
该进程主要就是将edits文件合并到fsimage文件中,这个操作称为checkpoint,下面是整个checkpoint的流程图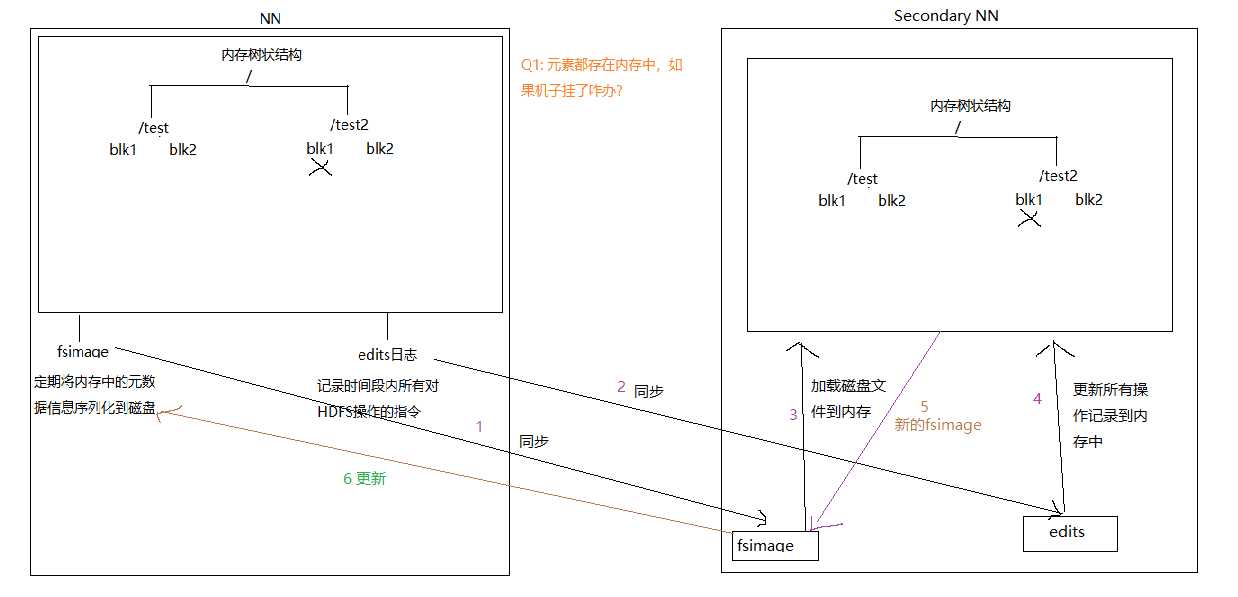
3、DataNode
DataNode是提供具体文件存储的服务,也称为数据节点。对于DataNode有两个概念要了解,一个是block一个是replication。Hdfs会按照固定的大小和顺序对文件进行切割和编号,切割完后的每一块就是一个block,block默认大小是128M,Block块是HDFS的读写数据的基本单位,无论什么数据,对于HDFS来说都是字节。
由于我们是CM来安装Hadoop集群的,我们可以直接在CM的管理界面点击HDFS组件进入管理界面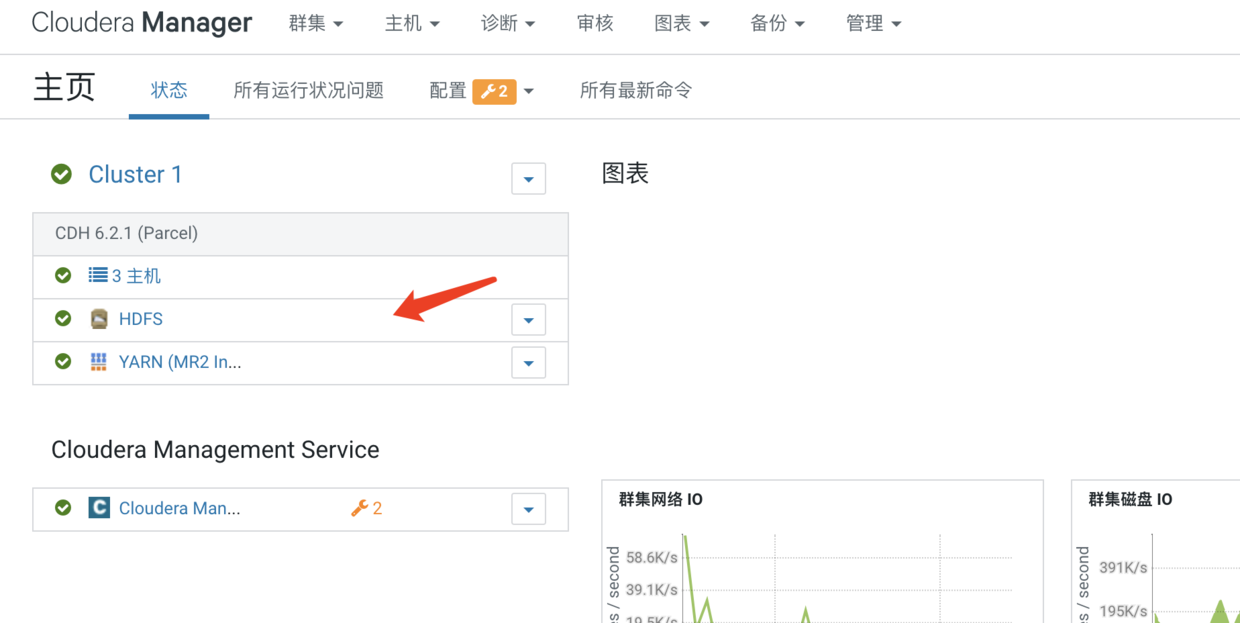
然后点击配置标签,在搜索框输入dfs.datanode.data.dir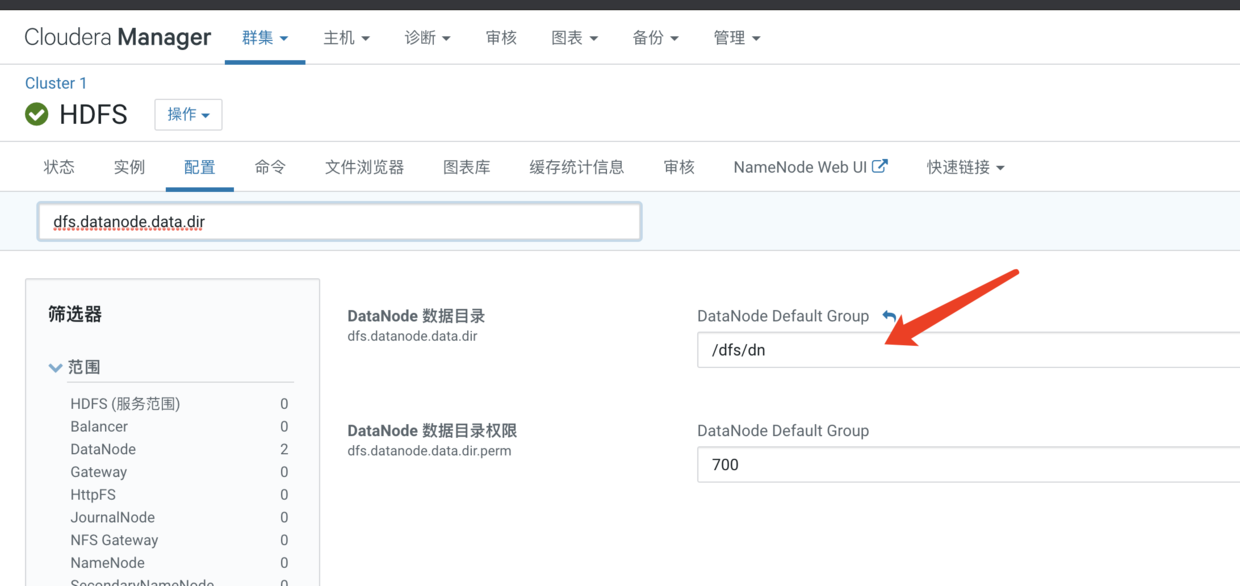
可以看到数据存储目录在/data/dn目录,我们就随便选择一个数据节点登录进去看看,这里我们就登录hadoop2节点,然后进入到这个目录
我们现在hadoop1节点手动put一个文件到HDFS中,然后通过HDFS的web-ui,访问地址为:http://hadoop1:9870,查看下刚刚手动上传的文件存储信息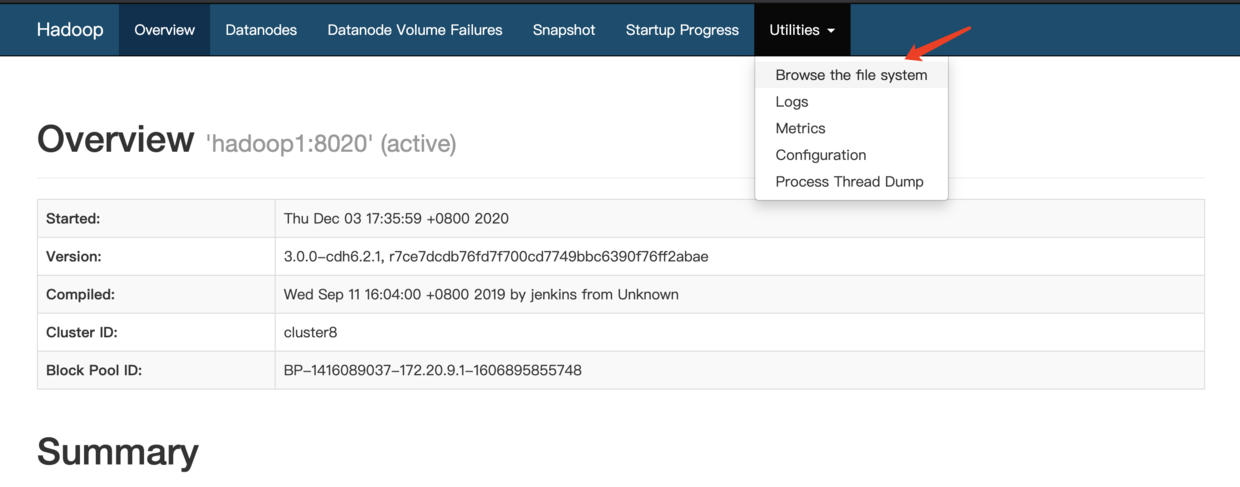
找到我们刚手动上传的文件,并点击,可以看到如下信息,这时候我们去数据节点上看看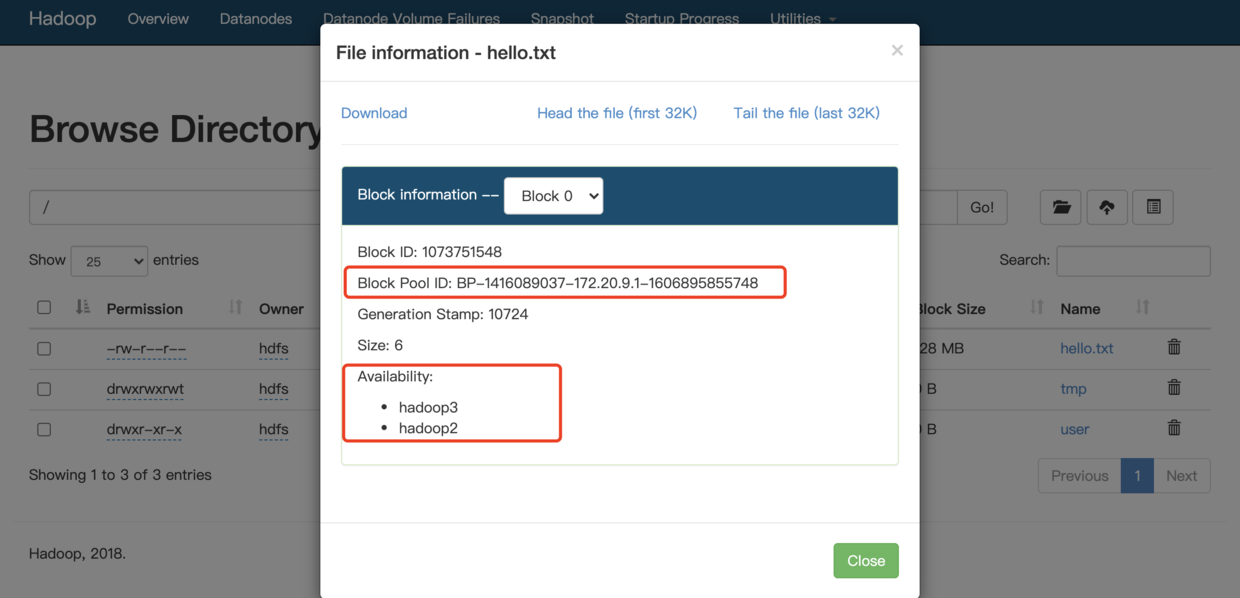
我们一路往下进入,最终到达这个目录,BP这一段就是我们上图中红框圈出来的
这时候我们通过ll命令查看下目录下的目录,然后根据我们上传时间的找到对应的目录,并进入
然后可以看到里面有很多文件,这里面就有Block块了,这里.meta后缀的文件也是做校验用的,我们尝试打印出来看看
输出的就是我们这个block块中的内容了,这个block块中的内容可能只是文件中的一小部分,因为文件一旦超过了设置的block块大小就会切割成多个block块,如果没有默认的大,那么就只是一个block,在HDFS中,如果你的文件大小没有block默认大小大, 那么是不会占用整个block块的存储空间的。
block块的存储位置只有DataNode自己知道,在启动集群的时候,DataNode会扫描自己节点里面的所有block块信息,然后上传个NameNode节点,所以数据越多,启动越慢,还有个注意的地方,那就是NameNode启动时候会将所有文件的元信息加载到内存中,每个元数据信息都会占用150字节,所以这也是为啥不适合存储小文件,会造成内存满了,但是文件整体的大小很小。
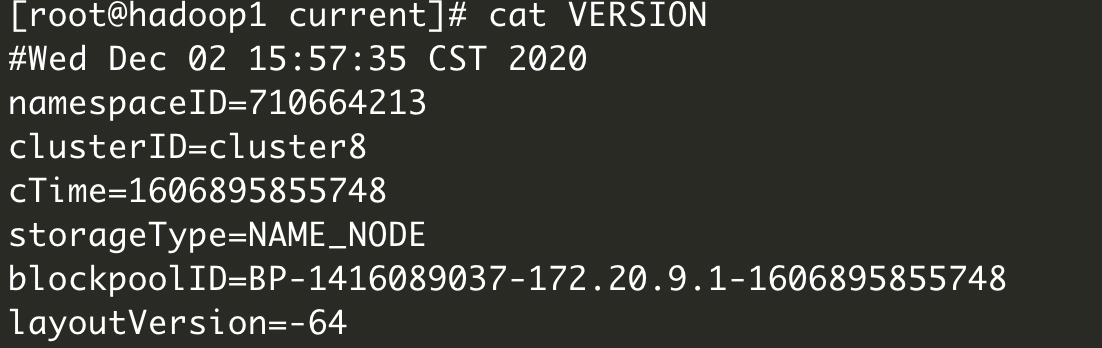
最后,我们在/dfs/dn目录中也发现了一个VERSION文件,这个跟我们前面介绍的NameNode存储目录里的VERSION文件是有一些相似的地方的,我们分别打开DataNode和NameNode的VERSION文件
- NameNode
- DataNode
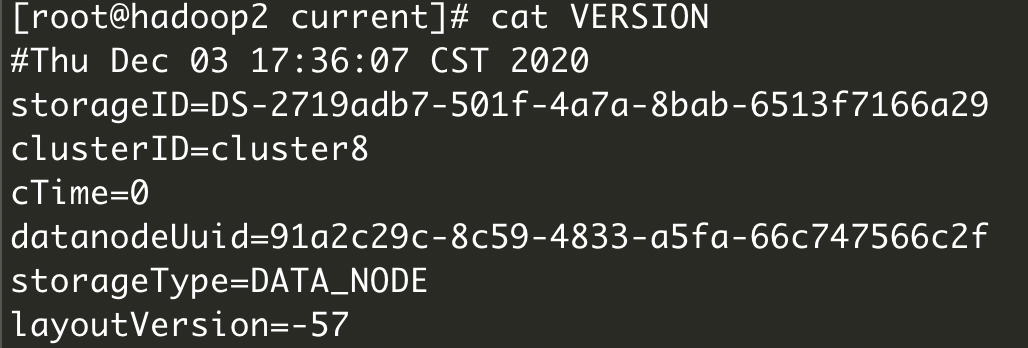
可以看到两个clusterId是一样的,所以NameNode是不能随意格式化的,会造成两边对不上,所以,如果你们是通过hadoop官方方式安装的话,在不得不重新格式化的时候,一定要删除干净储存目录下的内容。
五、HDFS回收站
我们在上文有提到过如果在删除的时候,没有指定-skipTrash参数,那么是不会直接删除的,会移动到回收站,回收站里面有个日期,如果超过这个日期没有被恢复的话,就会被自动永远删除了,通过CM安装集群的话,是会默认开启的,时间为1分钟,我们可以手动去的调整,参数在core-site.xml文件中,当然你们也可以在CM平台上修改
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
修改配置文件一定要同步到其他节点,然后在重新启动集群才会生效
六、安全模式
HDFS在每次启动的时候,都会去检查集群中文件信息是否完整,副本是否丢失等,所以这段时间内是不允许用户对HDFS集群进行操作的,这时候就需要我们耐心的等待一下啦!!我们可以在HDFS的web-ui查看当前状态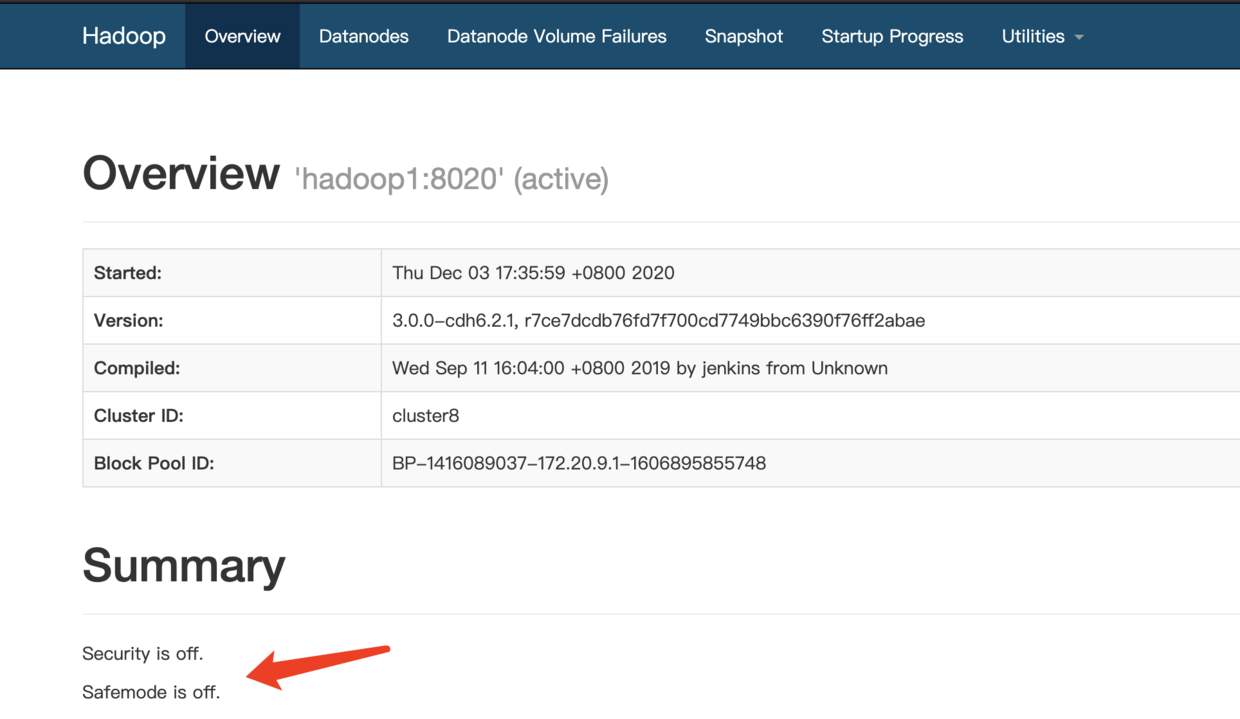
当然也可以通过命令行查看
[root@hadoop1 /]# hdfs dfsadmin -safemode get
Safe mode is OFF
如果你猴急了不想等了,你也可以强制退出,当然不建议你这么做
[root@hadoop1 /]# hdfs dfsadmin -safemode leave
七、HDFS升级高可用
HDFS高可用其实就是部署多个NameNode节点,这样就不会担心NameNode挂了导致整个集群瘫痪,接下来就给大家介绍如果通过CM来将之前安装的单节点HDFS升级为HA
1、安装Zookeeper
我们来到CM的首页,点击添加服务,并选择Zookeeper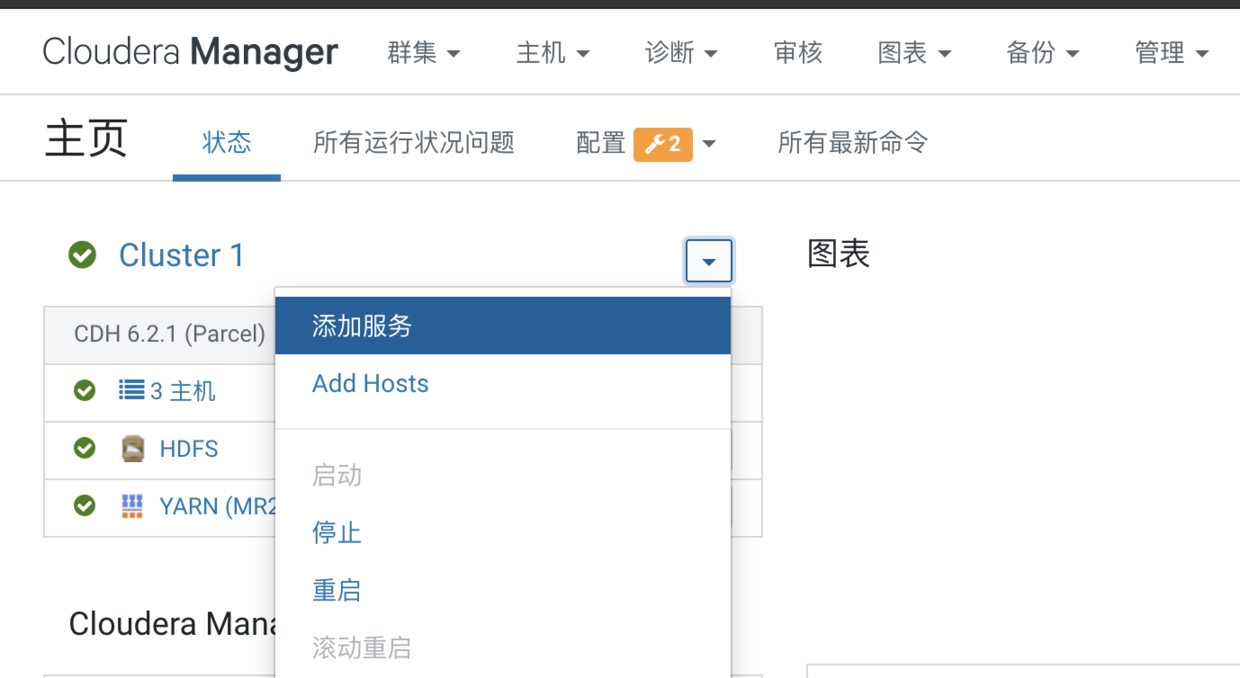
找到Zookeeper并点击继续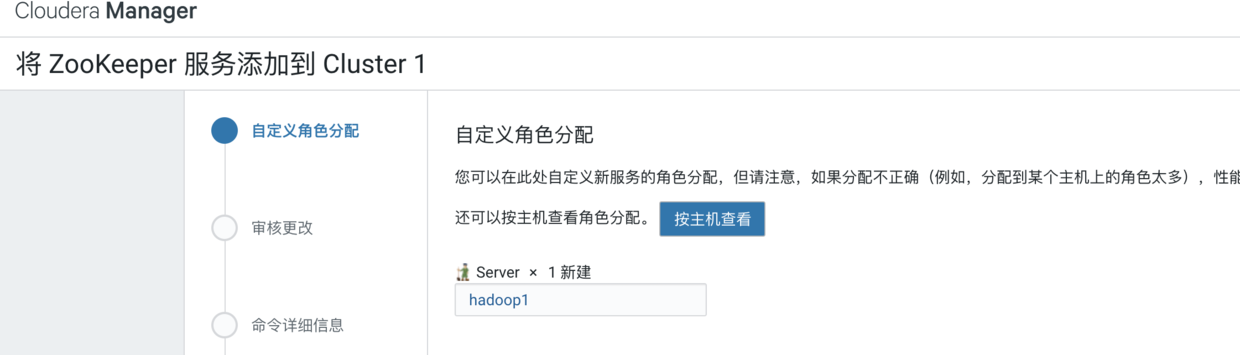
来到了Zookeeper Server的角色分配,这里CM会根据服务器配置自动给你推荐机器,当然你也可以根据自己的计划选择机器,我们点击那个框框,然后自定义分配角色,这里我们就将集群中的三台机子都作为Zookeeper的节点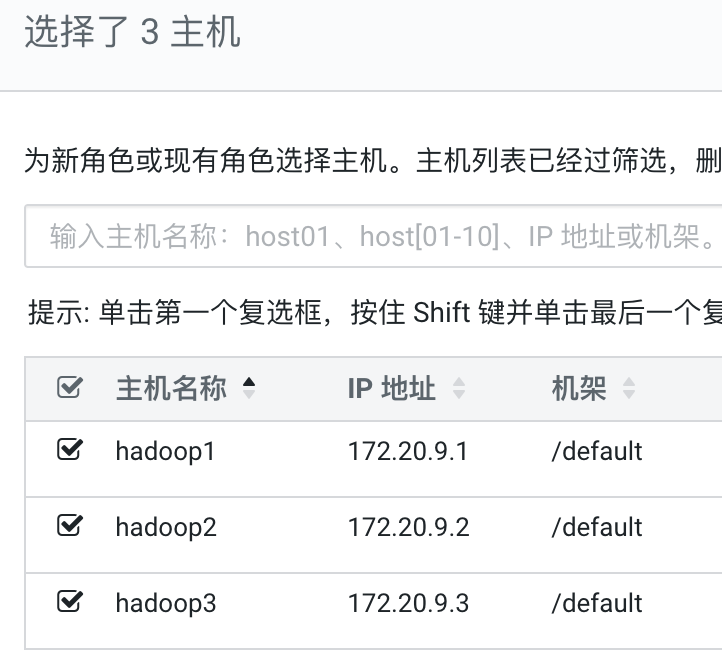
选择完毕后确定并继续下一步,这里来到了数据目录配置,这里我们就随便设置一个目录,如果是生产环境你们一定好好合理规划哦
点击继续,我们就开始安装啦,这里需要耐心的等待一下
好了,我们安装好了
接下来我们点击继续,这是个汇总页了,我们看完描述信息就点击完成
回到主页,我们就看到多出了一个zookeeper服务了
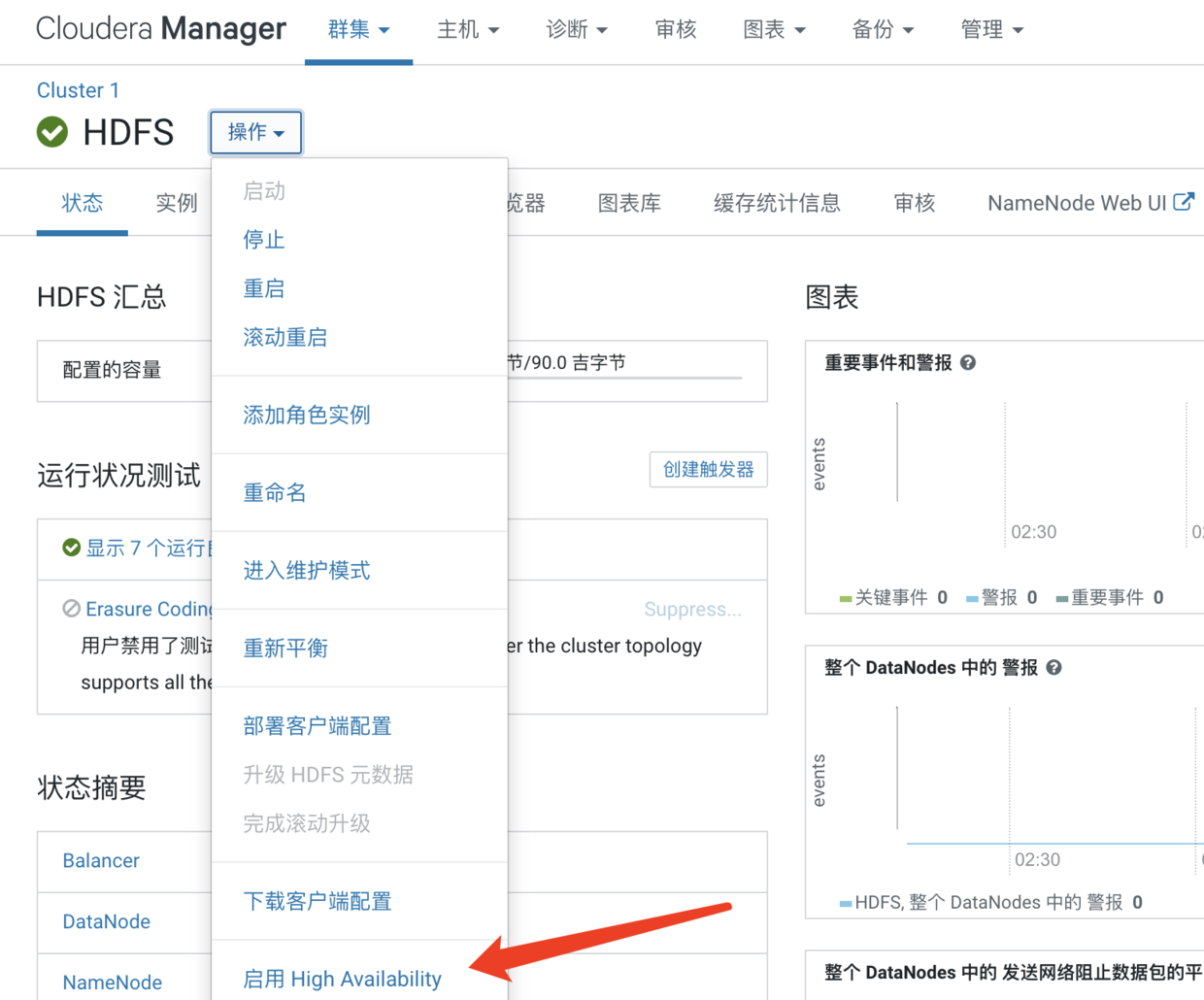
2、启用HA
这里需要填写namespace名称,有默认的,也可以自己指定。这个namespace就是后面你们要是想通过代码或者命令连接hdfs的地址哦,hdfs://<namespace>/[目录]。这里我们就使用默认的,然后下一步
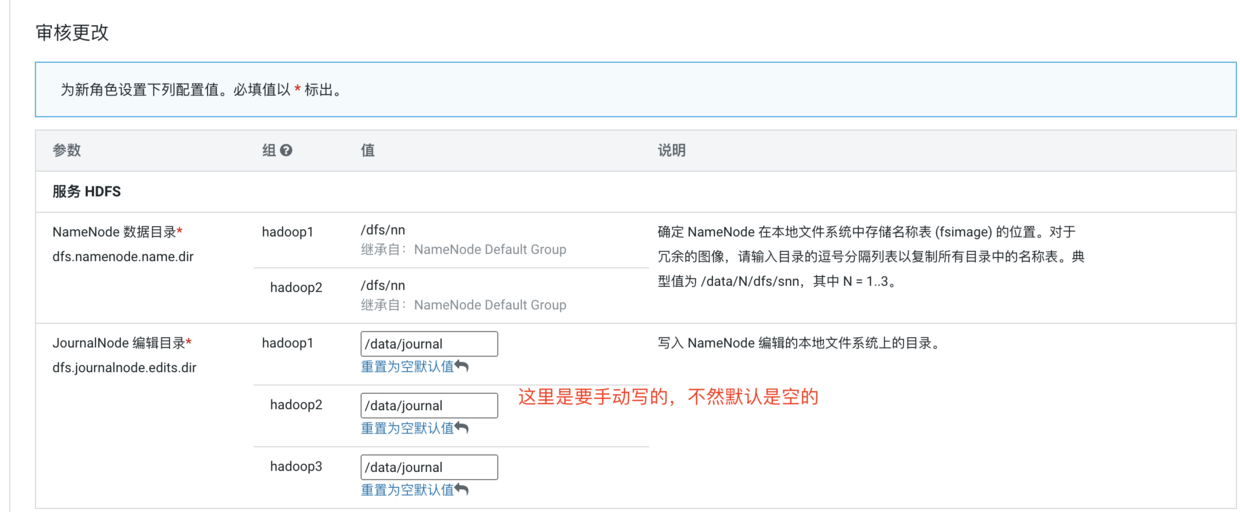
这里是分配角色了,由于我们只有三个节点,因此就只能找个数据节点作为NameNode了,三台都选中为JournalNode,然后继续
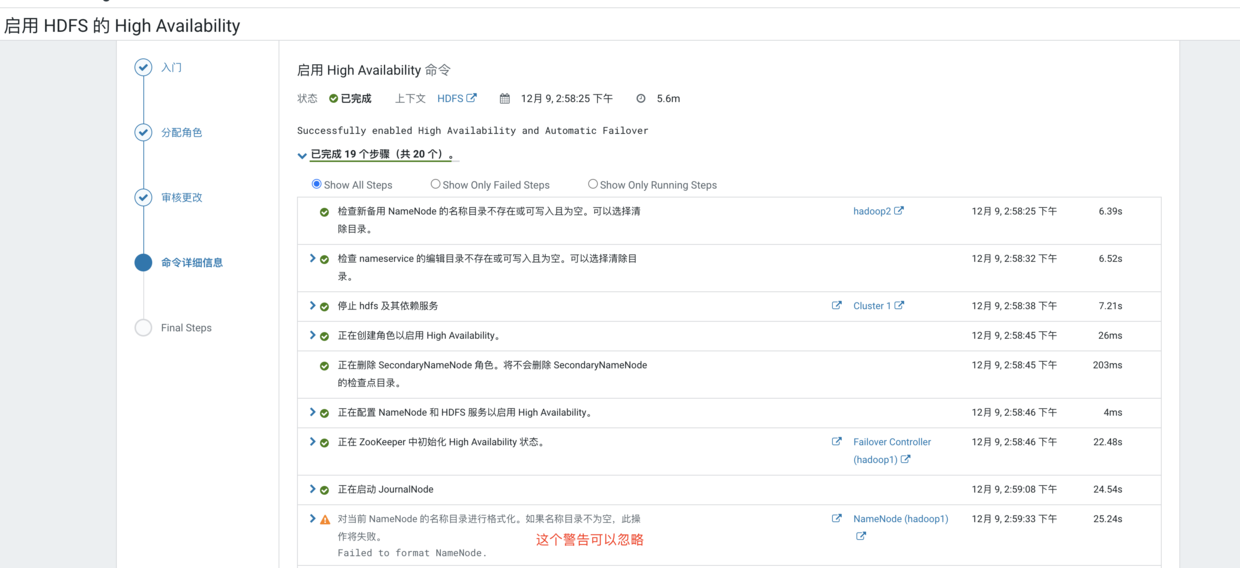
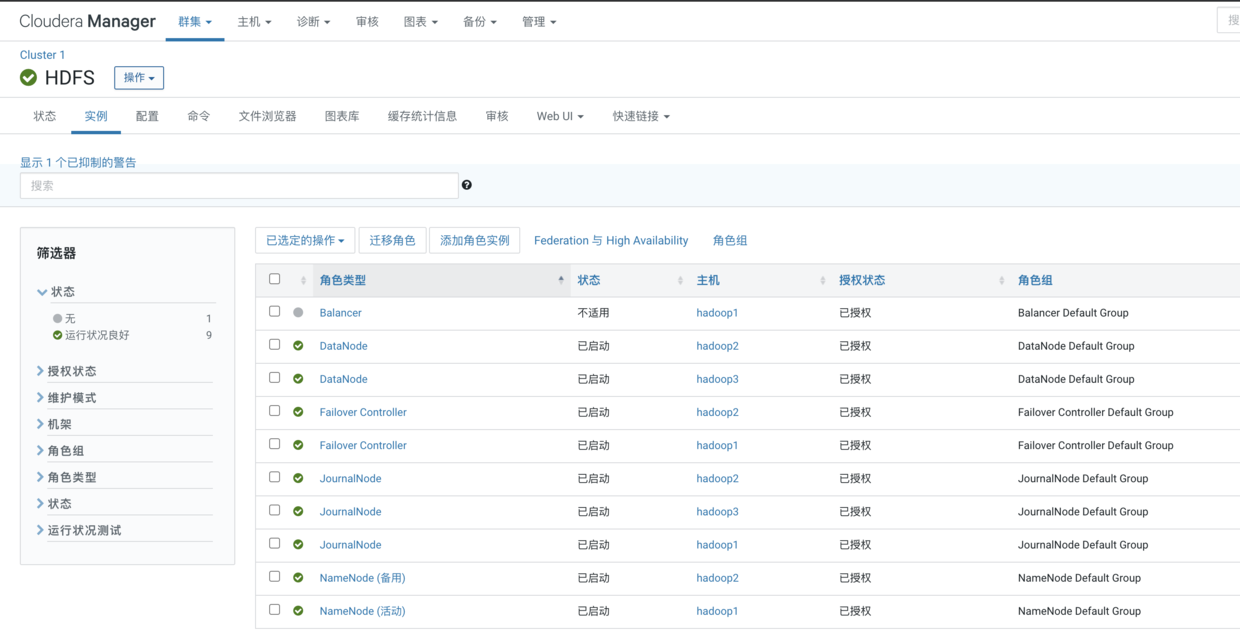
然后我们点击继续并完成即可,这时候我们在进入到HDFS的操作界面,点击实例,就可以看到HA后的HDFS所有实例了
本手册到这就结束啦,篇幅过长,如果大家发现有啥问题可以在留言哦

若有收获,就点个赞吧
0 人点赞
