算法复杂度分为时间复杂度和空间复杂度
O 后面的括号中有一个函数,指明 某个算法的耗时 / 耗空间 与 数据增长量 之间的关系。其中的 n 代表输入数据的量。
时间复杂度
在一个算法存在最好、平均、最坏三种情况,我们一般关注的是最坏情况,原因是,最坏情况是任何输入实例在运行时间的上界,对于某些算法来说,最坏情况出现的比较频繁,从大体上来看,平均情况和最坏情况一样差。
分析方法(很多看不太懂,跳过)
频度统计法
频度统计法指以程序中语句执行次数的多少作为算法时间度量分析的一种方法。通常情况下,算法的时间效率主要取决于程序中包含的语句条数和采用的控制结构这两者的综合效果。因此,最原始且最牢靠的方法是求出所有主要语句的频度f(n),然后求所有频度之和。
例如:如下形式的语句段:
for (i=1;i<n;i++){y++;for (j=0;j<(2*n);j++) {x++;}}
这个由两个for语句构成的程序段,外循环的重复执行次数是n-1次,内循环的单趟重复执行次数是2×n次。因此,语句y++的频度为n-1,语句 x++ 的频度为 2×n×(n-1)
所以, T(n)=O(∑f(n))=O(n-1+2×n2-2×n)
取增长最快的一项作为数量级,则 T(n)=O(n2)
该方法简单,结果绝对精确,适用于大多数程序。但分析算法时间效率时往往只需计算出其大致数量级,此时,采用频度估算法即可。
频度估计法
先找出对于所求解的问题来说是共同的原操作,并求出原操作的语句频度 f(n),然后直接以 f(n) 衡量 T(n) 。在使用频度估算法时应注意到一个显著的标志,就是原操作往往是最内层循环的循环体,并且,完成该操作所需的时间与操作数的具体取值无关。这种方法比较适合于带有多重循环的程序。
例如:数学中求两个矩阵乘法的常规方法是用了一个三重循环,如下:
for (i = 1; i <= n; i++) {for (j = 1; j <= n; j++) {c[i][j] = 0;for (k = 1; k <= n; k++) {c[i][j] = c[i][j] + a[i][k] * b[k][j];}}}
这个程序段的原操作是处于最内层循环的语句 c[i][j]=c[i][j]+a[i][k]*b[k][j],该语句的重复执行次数即原操作的频度是 n3,可以直接得出:该算法的时间复杂度T(n)=O(n3)。
对于一些复杂的算法,可以将算法分解成容易估算的几个部分,利用频度估算法分别求出这几部分的时间复杂度,然后利用求和的原则得到整个算法的时间复杂度。
频度估算法的优点是结果较精确,方法简单且易掌握,但对于原操作的频度不易直接确定的程序,却无能为力。
频度未知数法
当不能直接求出原操作的重复执行次数 f(n),但通过对程序主要语句的分析,确信可以通过间接的方式计算得出。其基本规律是:首先将原操作的频度设为一个未知数,然后根据原操作执行结束的条件及特征列方程求出它,如果结果是不等式,取其极大值。
比如程序段:
i=s=0;while (s<n) {i++;s+=i;}
分析:该程序段的原操作是语句 s+=i,无法一眼看出原操作的频度f(n)。为求得f(n),设循环体共执行了k次后结束,即令f(n)=k,则根据语义,可以得出
1+2+3+……+k>=n 且 1+2+3+……+(k-1)
取其极值,并忽略常数对数量级的影响,可得 T(n)=O( )=O( )
列举频度归纳法
程序中经常会出现带有倍增型循环的情况。倍增循环指内循环的执行次数随外循环控制变量而变化的多重循环结构。
例如:
m = 1;for (i = 1; i <= n; i++) {m = m * 2;for (j = 1; j <= m; j++) {x++;}}
分析:当外循环变量i分别从1,2,……,一直取到n时,内循环的执行次数依次是2,4,8,……,2n,这是一个几何级数序列,其中每一项的值是前一项的常数倍。
因此,
这种算法的特征是,原操作的频度和一个变化的量有关,比如内循环的执行次数依赖于外循环的循环控制变量,或每执行一次循环,循环控制变量将被乘以(除以)一个常数。
再如:
for (i = 0; i < n; i++) {for (j = i; j < n; j++) {for (k = j; k < n; k++) {x++;}}}
分析:由于最内层for循环控制语句执行1次,其循环体即原操作 x++ 恰好执行了n-j次,因此,整个算法完成时共执行了 次x++语句,而
结论:当分析带有倍增循环结构程序的运行时间开销时,需要把每次执行循环的时间累加起来,其结果表达式往往就被转化为一个级数求和的问题。
频度期望值法
当原操作的执行次数不仅依赖于问题的规模,而且随原始数据集状态的不同而不同时,往往需要根据原始数据的分布特点,考虑数据在某种概率分布下频度的一个平均值。此时,即使问题规模相同,对于不同的特定输入,其时间开销也不同。在这种情形下,考虑求符合某种概率分布情况下的原操作的平均频度,然后以平均频度的一个数量级作为算法的时间度量。
例如:顺序查找算法
int Search_Seq (Table S, KeyType key){
// Table是查找表类型,KeyType表示关键字类型
S.elem[0].key = key;
for (i = S.length; S.elem[i] != key;i--);{
return i;
}
}
分析:该算法中的原操作是“将记录的关键字和给定值进行比较”,但根据 for循环的判断条件,比较的次数取决于待查记录在查找表中的位置i。根据所查找数据在查找表中位置的不同,其时间开销可能在一个很大的范围内浮动。为求出时间复杂度,通常转而求“其关键字和给定值进行过比较的记录的个数的平均值”,即“比较次数”的平均频度。一般来说,在进行研究时,为方便讨论,对于经典的查找和排序算法,总是考虑“等概率”条件。
所以,各记录的查找概率依次为:
第i个记录的比较次数 是: =n-i+1
故,平均频度
所以,T(n)= =O(n)
根据原始数据集的分布特点,有些查找问题的检索概率不一定相等,但求解的方法相同,都是求某种概率分布下的一个期望值。对于原操作的执行次数依赖于原始数据排列情况的问题来说,内循环体的执行次数取决于外循环控制变量的情形非常常见,其求解方法也完全适用。例如:大多数静态的排序算法。
需要说明的一点是:数据分布的特点对于很多查找算法效率都会有很大的影响,而平均情况分析并不总是可行。因为,首先要求了解清楚数据是如何分布的。对于这一类问题,有时候要根据各种可能出现的最坏情况来估算算法的时间复杂度。
迭代时间复杂度的计算
递归过程的运行时间一般都能通过一个递归关系式得到很好的体现。根据对递归关系式的不同计算方法,将递归算法的求解方法提炼为如下两种。
扩展递归迭代法
当需要找到一个递归问题的精确答案时,可采用一种递归扩展技术。其基本方法是:方程右边较小的项根据定义被依次替代,如此反复扩展,直到得到一个没有递归式的完整数列,从而将复杂的递归问题转化为了新的求和问题。
例如:
float fact(long int n) {
if (n < 0) return (-1);
else if (n == 0 || n == 1) return (1);
else return (n * fact(n - 1));
}
分析:递归函数fact每递归调用自身一次,问题规模就减少1。该函数中出口语句的运行时间为O(1);调用返回的结果与输入参数相乘,这个操作的运行时间是一个常量可以记为O(1)。因此,函数fact的时间代价就等于该常数加上执行递归调用的时间,可以表示成
C n<=1
T(n)= C为递归调用语句的运行时间,这里是常数O(1)
则,
=……
所以,函数fact的时间复杂度是O(n)。
利用递归本身的特点采用这种扩展技术求解递归程序的时间效率,是一种保守且可靠的方法。但有些问题,其求和序列的推导可能会是一项比较繁琐而枯燥的纯数学工作。遇到这种情况时,完全可以让个人的经验充分发挥作用,利用经验去猜测答案。
上下限猜测法。
先试着猜测答案,找出一个认为是正确的上下限估计,然后再去证明它。如果归纳证明成功,那么再试着收缩上下限;如果证明失败,那么就放松限制重试;一旦上下限符合要求,就得到了所求的答案。
例如:以下方程描述归并排序的运行时间,其数学的推导方法非常繁琐,现用上下限猜测技术来估算其渐进时间复杂度。
1 n=2
T(n)=
不失一般性,先猜测这个递归有一个上限 O(n2),更准确地说,假定T(n)≤n2,通过归纳来证明这个假定是否正确。如果正确,继续收缩上限,猜测一个更小的估计。
为了使计算简便,假定n是2的乘方。初始情况:T(2)=1≤22,显然成立。
假设当i≤n时 T(i)≤i2 成立,要证明对于所有的n=2N,N≥1,T(n) ≤n2能够得到T(2n) ≤(2n)2。
而 T(2n)=2T(n)+2n≤2n2+2n≤4n2≤(2n)2 至此命题得证。
所以,猜测T(n)≤O(n2)是正确的。
但是O(n2)可能是一个很高的估计。如果猜测更小一些,例如T(n)≤cn(c为某个常数),很明显,因为c2n=2cn,没有为额外的代价n留下余地,使待排序的两块归并在一起,因此T(n)≤cn不可能成立。这样就可以初步得知,真正的代价一定在cn与n2之间。
继续尝试T(n)≤nlog2n。初始情况: T(2)=1≤(2•log22)=2。归纳假设T(n)≤nlog2n,那么:T(2n)=2T(n)+2n≤2nlog2n+2n≤2n(log2n+1) ≤2nlog22n
类似地,还可以证明T(n)≥(nlog2n)。所以,T(n)就是O(nlog2n)。
在求解渐近时间复杂度时,这种猜测技术是一种很有用的技术,当寻找精确解时,就不适用了。
O 函数(这个好理解一些)
一般计算方法
- 用 1 代替所有运行时间中出现的加法常数;
- 在修改后的运行函数中保留最高阶的项;
- 如果最高阶的项系数不是1,则去除这个项系数。
- 递归算法的时间复杂度为:递归总次数 * 每次递归中基本操作执行的次数
常见的时间复杂度有以下七种:O(1)常数型;O(log2N)对数型,O(N)线性型,O(Nlog2N)二维型,O(N2)平方型,O(N3)立方型,O(2N)指数型。
O(1)解析
O(1)就是最低的时空复杂度了,也就是耗时/耗空间与输入数据大小无关,无论输入数据增大多少倍,耗时/耗空间都不变。 哈希算法就是典型的 O(1) 时间复杂度,无论数据规模多大,都可以在一次计算后找到目标(不考虑冲突的话),冲突的话很麻烦的,指向的 value 会做二次hash到另外一快存储区域。
int i = 1;
int j = 2;
int k = i + j;
O(n)解析
比如时间复杂度为O(n),就代表数据量增大几倍,耗时也增大几倍。
比如常见的遍历算法。
要找到一个数组里面最大的一个数,你要把n个变量都扫描一遍,操作次数为n,那么算法复杂度是O(n).
for (int i = 0; i < n; i++) {
j = i;
j++;
}
O(n2)解析
O(n2)的写法为:O(n^2)
再比如时间复杂度O(n^2),就代表数据量增大n倍时,耗时增大n的平方倍,这是比线性更高的时间复杂度。比如冒泡排序,就是典型的O(n^2)的算法,对n个数排序,需要扫描n×n次。
for(x=1; i<=n; x++) {
for(i=1; i<=n; i++) {
j = i;
j++;
}
}
用冒泡排序排一个数组,对于n个变量的数组,需要交换变量位置次,那么算法复杂度就是O(n2).
O(n3)解析
for (i = 0; i < n; i++) {
for (j = 0; j < i; j++) {
for (k = 0; k < j; k++) {
x++;
}
}
}
O(log n)解析
再比如O(log n),当数据增大n倍时,耗时增大log n倍(这里的log是以2为底的,比如,当数据增大256倍时,耗时只增大8倍,是比线性还要低的时间复杂度)
求二分法的时间复杂度
int select(int a[], int k, int len) {
int left = 0;
int right = len - 1;
while (left <= right) {
int mid = left + ((right - left) >> 2);
if (a[mid] == k) {
return 1;
}
else if (a[mid] > k) {
right = mid - 1;
}
else {
left = mid + 1;
}
}
return NULL;
}
分析:
在最坏的情况下循环x次后找到,n/(2^x)=1;x=log2n;
所以二分查找的时间复杂度为:O(log2n);空间复杂度O(1);
O(n log n)解析
O(n log n)同理,就是n乘以log n,当数据增大256倍时,耗时增大256*8=2048倍。这个复杂度高于线性低于平方。归并排序就是O(n log n)的时间复杂度。
O(2n)解析
表示一个算法的性能会随着输入数据的每次增加而增大两倍,最经典的就是斐波那契数列
int fib(int n) {
if (n < 2) {
return 1;
} else {
return fib(n-1) + fib(n - 2);
}
}
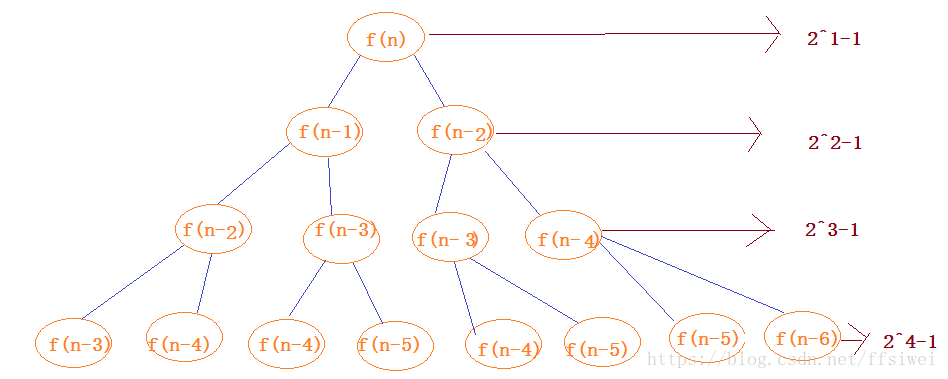
将其用流程图画出来发现是一个完全二叉树,节点数为2^n-1,深度为n,根据最坏情况,时间复杂度为O(2^n),空间复杂度为O(n)
普通的递归: 用递归算法求n的阶乘
int fac(int n) {
if (n <= 2) {
return n;
} else {
return fac(n - 1)*n;
}
}
n的阶乘的时间复杂度很简单:就是n次递归算法,所以为O(n),空间复杂度O(n),递归的深度是n。

空间复杂度
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的一个量度,同样反映的是一个趋势,一个算法所需的存储空间用f(n)表示。S(n)=O(f(n)),其中n为问题的规模,S(n)表示空间复杂度。
是对一个算法在运行过程中临时占用存储空间的度量
一个算法在计算机存储器上所占用的存储空间包括存储算法本身所占用的空间,算数和输入输出所占用的存储空间以及临时占用存储空间三个部分
- 算法的输入输出数据所占用的存储空间是由待解决的问题来决定的,通过参数表由调用函数而来,它随本算法的不同而改变。
- 存储算法本身所占用的存储空间有算法的书写长短成正比。
- 算法在运行过程中占用的临时空间由不同的算法决定。
复杂度速查表
来源:https://liam.page/2016/06/20/big-O-cheat-sheet/ 源地址:https://www.bigocheatsheet.com/
图例


抽象数据结构的操作复杂度

数组排序

图操作

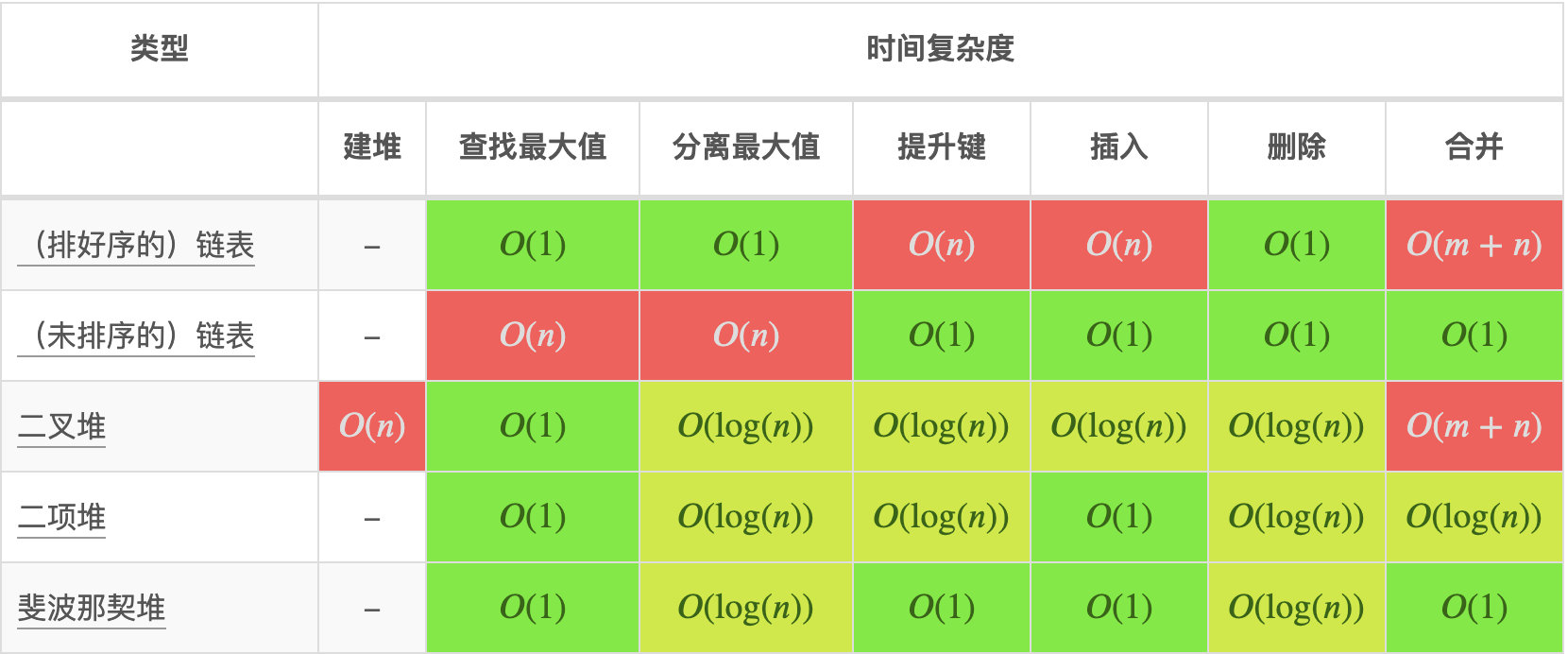
堆操作
参考:
https://blog.csdn.net/lkp1603645756/article/details/85013126
https://blog.csdn.net/ffsiwei/article/details/80424275
https://www.cnblogs.com/lazyegg/p/12572421.html
https://www.cnblogs.com/chenying99/articles/3801293.html

若有收获,就点个赞吧
0 人点赞
