一、实验目的
1、掌握字符串的输入输出;
2、理解字符串的存储方式,掌握字符串切片;
3、掌握常见的字符串内建函数的使用;
4、掌握常见的字符串运算符应用。
二、实验环境
装有Python运行环境、Pycharm平台的PC电脑一台
三、实验内容
1、输入一行字符,分别统计出其中英文字母、空格、数字和其它字符的个数。 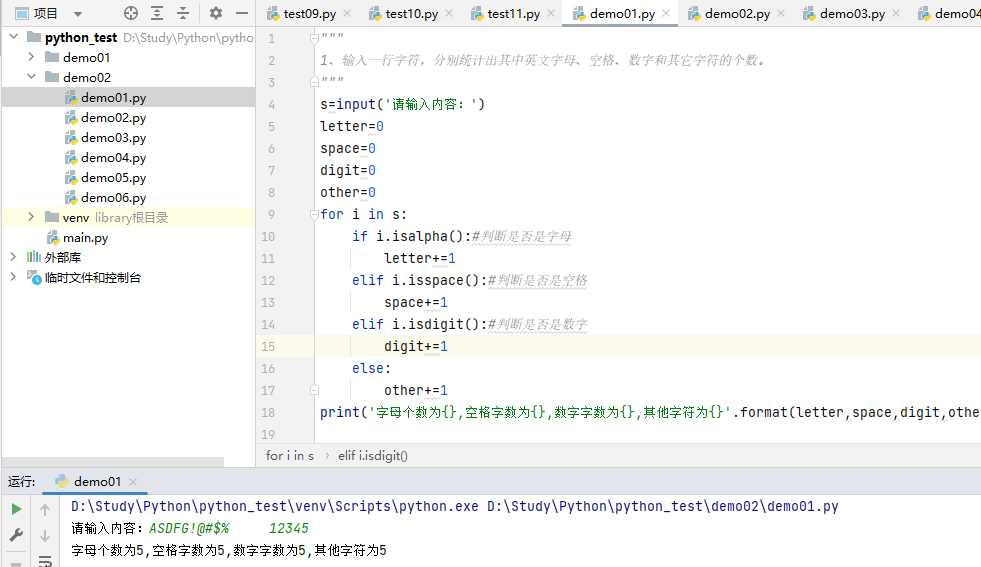
2、字符串大小写转换:1)将用户输入的字符串全部转换为大写字母;2)将用户输入的字符串全部转为小写字母等。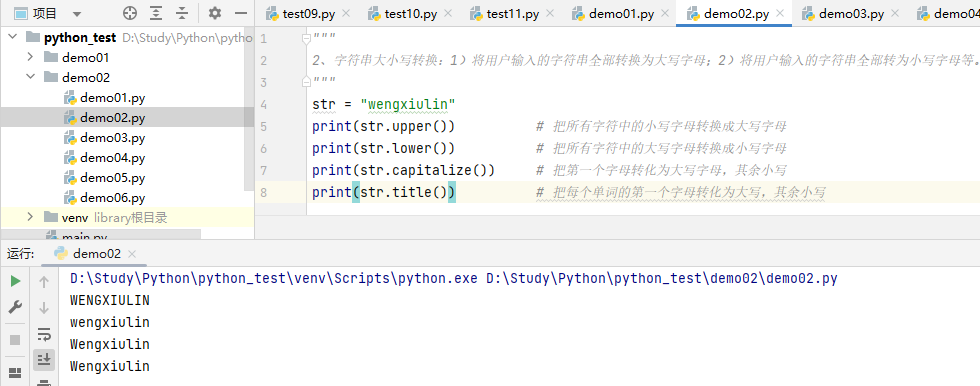
3、求正整数与其反序数之和:键盘输入正整数n,求出n与其反序数之和并输出,例如,输入2038,输出应为2038+8302=10340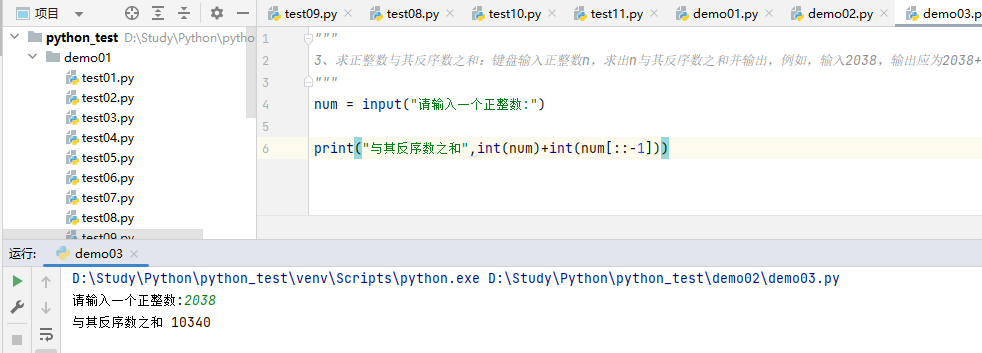
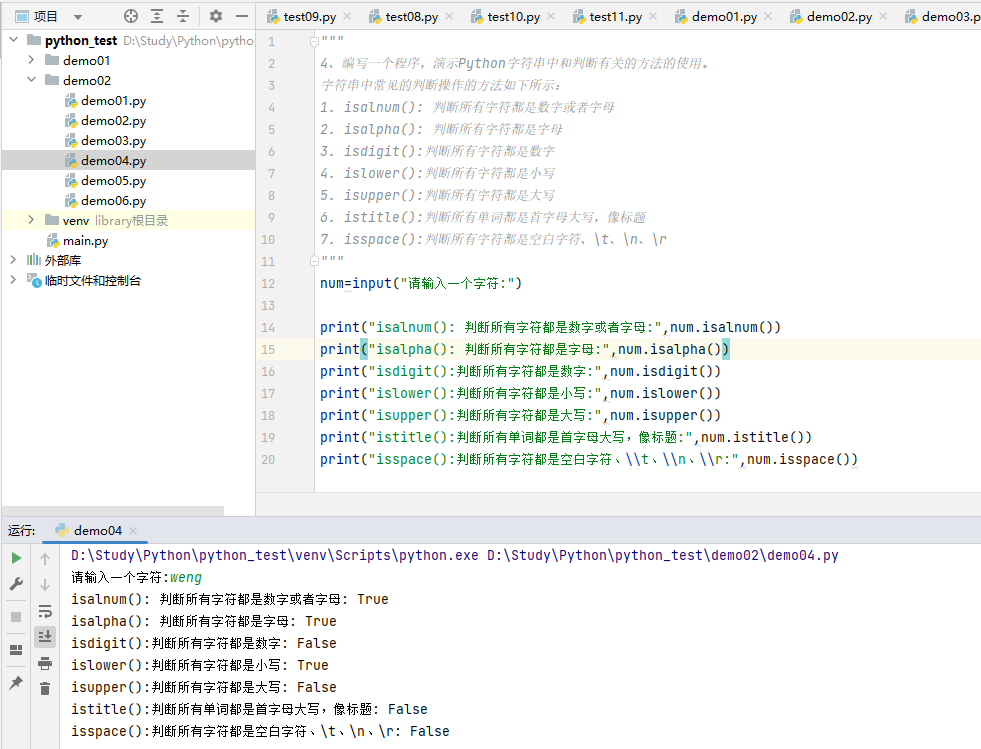
4、编写一个程序,演示Python字符串中和判断有关的方法的使用。
字符串中常见的判断操作的方法如下所示:
- isalnum(): 判断所有字符都是数字或者字母
- isalpha(): 判断所有字符都是字母
- isdigit():判断所有字符都是数字
- islower():判断所有字符都是小写
- isupper():判断所有字符都是大写
- istitle():判断所有单词都是首字母大写,像标题
- isspace():判断所有字符都是空白字符、\t、\n、\r
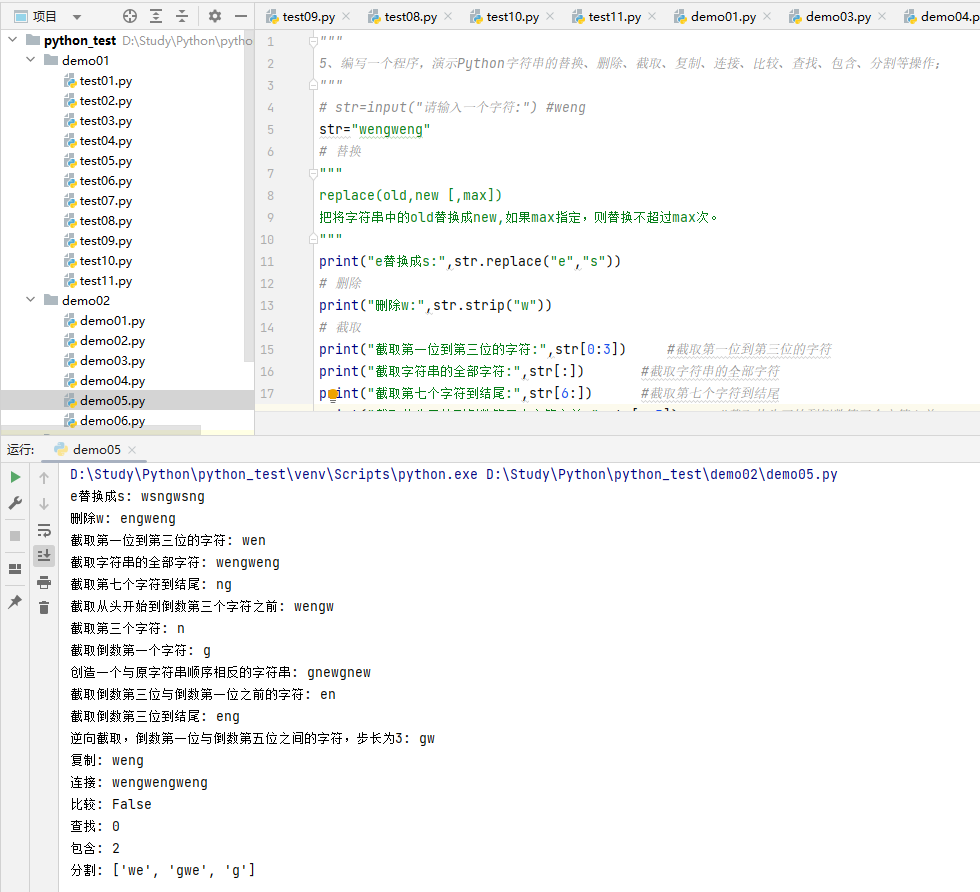
5、编写一个程序,演示Python字符串的替换、删除、截取、复制、连接、比较、查找、包含、分割等操作;
"""5、编写一个程序,演示Python字符串的替换、删除、截取、复制、连接、比较、查找、包含、分割等操作;"""# str=input("请输入一个字符:") #wengstr="wengweng"# 替换"""replace(old,new [,max])把将字符串中的old替换成new,如果max指定,则替换不超过max次。"""print("e替换成s:",str.replace("e","s"))# 删除print("删除w:",str.strip("w"))# 截取print("截取第一位到第三位的字符:",str[0:3]) #截取第一位到第三位的字符print("截取字符串的全部字符:",str[:]) #截取字符串的全部字符print("截取第七个字符到结尾:",str[6:]) #截取第七个字符到结尾print("截取从头开始到倒数第三个字符之前:",str[:-3]) #截取从头开始到倒数第三个字符之前print("截取第三个字符:",str[2]) #截取第三个字符print("截取倒数第一个字符:",str[-1]) #截取倒数第一个字符print("创造一个与原字符串顺序相反的字符串:",str[::-1]) #创造一个与原字符串顺序相反的字符串print("截取倒数第三位与倒数第一位之前的字符:",str[-3:-1]) #截取倒数第三位与倒数第一位之前的字符print("截取倒数第三位到结尾:",str[-3:]) #截取倒数第三位到结尾print("逆向截取,倒数第一位与倒数第五位之间的字符,步长为3:",str[:-5:-3]) #逆向截取,倒数第一位与倒数第五位之间的字符,步长为3# 复制str1=str[0:4]print("复制:",str1)# 连接print("连接:",str+str1)# 比较print("比较:",str==str1)# 查找print("查找:",str.find("weng"))# 包含print("包含:",str.find("ng"))# 分割print("分割:",str.split("n"))
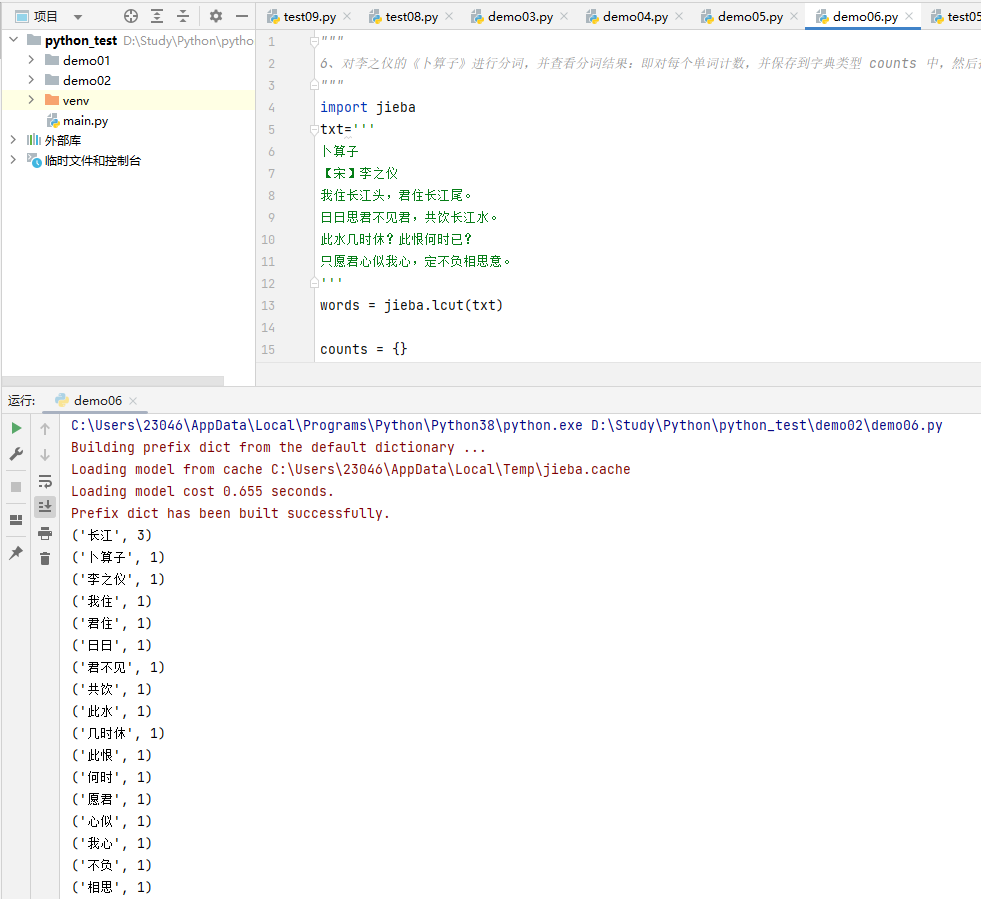
6、对李之仪的《卜算子》进行分词,并查看分词结果:即对每个单词计数,并保存到字典类型 counts 中,然后按照单词出现的次数从高到低排序。
"""6、对李之仪的《卜算子》进行分词,并查看分词结果:即对每个单词计数,并保存到字典类型 counts 中,然后按照单词出现的次数从高到低排序。"""import jiebatxt='''卜算子【宋】李之仪我住长江头,君住长江尾。日日思君不见君,共饮长江水。此水几时休?此恨何时已?只愿君心似我心,定不负相思意。'''words = jieba.lcut(txt)counts = {}for word in words:if len(word) == 1:continueelse:rword = wordcounts[rword] = counts.get(rword,0) + 1items = list(counts.items())items.sort(key=lambda x:x[1], reverse=True)for item in items:print(item)
心得体会
练习了python的输入输出和字符串的基本使用

若有收获,就点个赞吧
0 人点赞
