数据结构:
物理性(线性):数组(import numpy),链表
逻辑性:栈,队列(import Queue),堆,树
时间复杂度:
O(1)
Debug调试:
当我们在代码出现错误时,这是可以在pycharm 里点击调试的代码,进行debug查看代码运行的每一步
1. 数组Array:
数组,所有元素都连续的存储于一段内存中,且每个元素占用的内存大小相同。这使得数组具备了通过下标快速访问数据的能力。<br />但连续存储的缺点也很明显,增加容量,增删元素的成本很高,时间复杂度均为 O(n)。<br />增加数组容量需要先申请一块新的内存,然后复制原有的元素。如果需要的话,可能还要删除原先的内存。<br /><br />删除元素时需要移动被删除元素之后的所有元素以保证所有元素是连续的。增加元素时需要移动指定位置及之后的所有元素,然后将新增元素插入到指定位置,如果容量不足的话还需要先进行扩容操作。<br />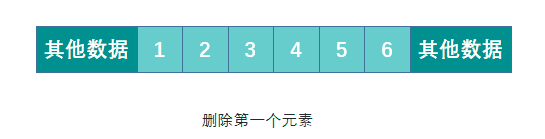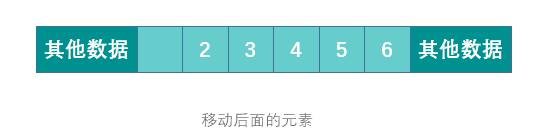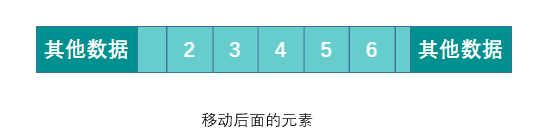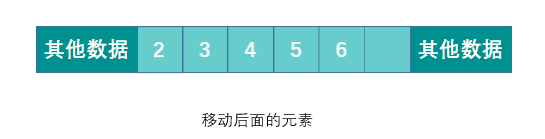<br />优点:可以根据偏移实现快速的随机读写。<br /> 缺点:扩容,增删元素极慢。**
数组的方法:增删改查
创建类:class Array,
维护内存大小&数组长度属性:self.array=[None]capacity
Self.size=0
2.**插入:O(n) index[优化后时间复杂度由O(n)降低为O(1)]
1. 边界条件
2. 扩容:当索引大于内存或者有效长度大于内存
3. 利用切片,将数组插入位置index到结尾的有效元素整体往后挪一位:L[index+1:size+1]=L[index:size].L[index]=插入值O(1)
4. 倒着遍历,O(n)
5. 长度加一
3.删除:遍历数组(删除下标)index到末尾),[i]=[i+1].覆盖index值
4.扩容*:由于数组的增加会导致数组的内存大小不够,这是需要对内存扩容
l 创建新的内存大小为原来俩倍.
l 遍历原数组.将旧内存元素更新到新数组.重新更新内存对象
```python class Array:#列表来实现数组 def init(self,capacity):#参数是容量# 内存大小self.array=[None]*capacityself.size=0#有效值长度
def output(self):
for i in range(self.size):print(self.array[i])
def insert(self,index,element):
#边界条件:索引值小于1if index<0 or index>self.size:raise IndexError("索引越界")# 扩容条件:索引值大于内存大小,或者有效值的长度大于内存的大小if index>=len(self.array) or self.size>=len(self.array):self.addcapacity()#第一种插入 从索引位置开始往后挪一位# for i in range(self.size-1,index-1,-1):# 从索引位置开始往后挪一位# self.array[i+1]=self.array[i]# 第二种:时间复杂度降低为O(1)利用切片将index后面的有效元素都后移一位self.array[index+1:self.size+1]=self.array[index:self.size]# 索引位置等于添加的元素,self.array[index]=elementself.size+=1
def remove(self,index):
判断是否越界
if index<0:raise IndexError("The index is out of range")
遍历
for i in range(index,self.size):self.array[i]=self.array[i+1]self.size-=1
def addcapacity(self):
# 创建新数组为原内存俩倍new_array=[None]*len(self.array)*2# 遍历有效值长度for i in range(len(self.array)):# 将旧地址元素复制到新内存里new_array[i]=self.array[i]# 使用新数组self.array=new_array
if name == ‘main‘:
a=Array(3)a.insert(0,0)a.insert(1,1)a.insert(2,2)a.insert(3,3)a.insert(2,9)# a.remove(2)# a.addcapacity()print(a.array)# a.output()# print('----')# print(a.size)
<a name="I9rP8"></a># 2.链表:LinkList(单链表)l链表与数组最大的区别在于链表是有指向的而数组没有,链表可以是非连续,非顺序的存储结构,<br />数组可以索引,链表不可以<br />链表的增删改查都需要维护结点的指向.<br />** **在存储单元上非连续、非顺序的存储结构。链表由结点构成.逻辑顺序由指针连接<br />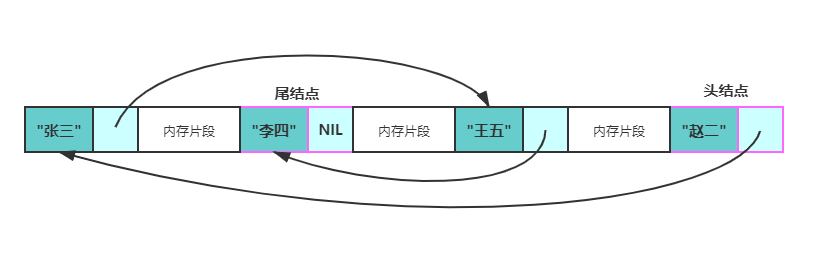<br />每个结点包含(元素与指针)<br /> 链表没有索引,所以每次的增删改都需要记录结点指向.然后遍历链表,并且将不需要的结点指向空<br /> 链表的内存:<br />** **链表,由若干个结点组成,每个结点包含数据域和指针域。结点结构如下图所示:<br /> 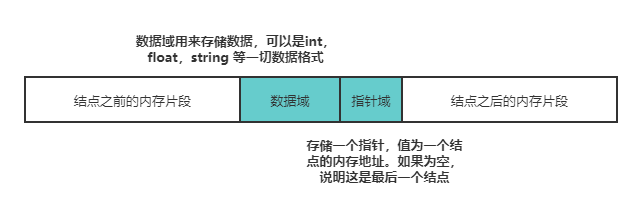<br />链表的存储方式使得它可以高效的在指定位置插入与删除,时间复杂度均为 O(1)。<br />1.在结点 p 之后增加一个结点 q 总共分三步:<br /> <br /> 1.申请一段内存用以存储 q (可以使用内存池避免频繁申请和销毁内存)。<br /> 2.将 p 的指针域数据复制到 q 的指针域。<br /> 3.更新 p 的指针域为 q 的地址。<br /> <br />**2.**删除结点 p 之后的结点 q 总共分两步<br /> 1.将 q 的指针域复制到 p 的指针域。<br /> 2.释放 q 结点的内存。**<a name="AXPwv"></a>## 链表的方法:** **Get()获取下标元素<br /> Insert():添加元素<br /> Remove():删除元素<br /> Reverse():翻转链表<br />**1. ****创建结点类**<br /> 属性:结点元素:node.data <br /> 指向:next=None<br /> 长度:size=0<br /> 打印<br />**2. 创建链表类:**<br /> 属性:头部,尾部与长度维护<br /> 方法:<br />1. Get(index):记录头结点,然后遍历到下标index,用记录的结点取下标结点的下一个指向元素<br />2. Insert(index,data):插入后先了解后事(指向),在赋值<br />1. 创建新结点传入数据<br />2. 判断边界:index<0 或者index>self.size<br />3. 判断空链表 :将新结点赋值与头和尾<br />4. 头部添加:当index=0时,新结点指向头部把新结点在赋值给头部<br />5. 尾部添加: 当index=size时,尾部指向新结点,把新结点在赋值给尾部<br />6. 中间插入:记录index前一位,后一位,利用get(index-1)得到前一位,<br /> 新结点指向前一个结点的下一个,前一个结点指向新结点<br /> 长度加一.<br />3. remove(index):<br />1. 判断边界:index<0 或者index>self.size/ raise IndexError<br />2. 删除头:index==0:记录头部,将头部指向下一个.旧头部指向空<br />3. 删除尾:index=size-1,记录尾部,将尾部的前一个(index-1)指向空,重新维护尾部<br />4. 删除中间;找到删除结点前一位结点prev,记录删除结点node=pre.next.<br />Prev指向prev.next.next.将删除结点指向空<br />4.reverse():<br /> 1.pre=None<br /> 2.记录头结点:cur<br /> 3.遍历链表<br /> 向右看齐:next_node=cur.next<br /> 转后转: cur.next=pre<br /> 齐步走: pre=cur cur=next_node <br />4. 重置头部:self.head=pre<br />5. repr():打印链表<a name="KX0RJ"></a># 指针的应用:<a name="GPrpm"></a>## 双指针双指针在访问一个序列时使用俩个指针进行扫描,俩个指针可以是同向的也可以是反向的.我们需要关注的是这俩个指针指向的元素本身.<br /> 一类是快慢指针,一类是左右指针.<a name="pHeqd"></a>### 快慢指针:主要解决链表中的问题.俩个指针同向移动,某一刻看俩个指针一个在前一个后.<br /> 速度相同:出发位置不同,出发后俩个指针都以固定的距离一前一后向前移动(删除数组重复项)<br />出发位置相同:俩个指针速度不同,之后以固定的速度一前一后向前移动,俩个指针距离随时间规律递增.()<br />数组里:一般用于寻找满足某个条件的连续区间<br />链表里:相关问题中经常会使用快慢双指针来寻找某个节点[虚拟结点的巧妙结合]<br /> 经典问题<br /> 数组(删除排序数组中的重复项1,删除排序数组中重复项2,移动零,删除指定元素)<br /> 链表(判断是否有环,入环点)<a name="VS77F"></a>### 左右指针:主要解决数组或字符串的问题,一般用于寻找满足条件的俩个节点,<br />如果是寻找多个节点;则需要固定n-2个数.<br />为了不遗漏所有的可能情况,可能要求数组有序,<br /> 经典问题<br /> (二分查找,俩数之和,三数之和,最接近的三数之和).<a name="8pevS"></a>### 分离双指针:输入是俩个数组/链表,俩个指针分别在俩个容器中移动;<br />根据问题的不同,初始位置可能都在头部,或者都在尾部,或一头一尾<br />经典问题:<br /> 俩个数组的交集,合并俩个有序数组,合并俩个有序链表<a name="9FgUV"></a>### 滑动窗口:是双指针的高级用法,可以解决大部分字符串匹配问题(最小数组长度)<br /> **三个指针**(荷兰旗子)**二分查找:**<br /><a name="s6yO5"></a># 力扣题 <br /><a name="G6D13"></a>## 1. 数组快慢指针只要是数组有序就应该想到双指针<br /><a name="sRS4r"></a>### 1.1删除数组重复项给定一个排序数组,你需要在[** 原地**](http://baike.baidu.com/item/%E5%8E%9F%E5%9C%B0%E7%AE%97%E6%B3%95) 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度<br />思路:<br />数组是有序的,那么重复的元素一定会相邻. 要求删除重复元素,实际上就是将不重复的元素移到数组的左侧。<br />考虑用 2 个指针,一个在下标0记作慢指针: p,一个在下标1记作快指针: q,算法流程如下:<br />1.比较 p 和 q 位置的元素是否相等<br />2.如果相等,q 后移 1 位<br />3.如果不相等,将 q 位置的元素复制到p+1 位置上,p 后移一位,q 后移 1 位<br />4.重复上述过程,直到 q 等于数组长度<br />5.返回 p + 1,即为新数组长度<br />```pythonclass Solution:def removeDuplicated(self,nums ):slow=0#慢指针fast=1#快指针while fast<len(nums):if nums[fast] !=nums[slow]:slow+=1nums[slow]=nums[fast]fast+=1elif nums[fast] == nums[slow] :fast+=1print( nums)a = Solution()a.removeDuplicated([1, 1,1, 2, 2, 5, 26])
1.2 去除数组重复项2
给定一个增序排列数组 `nums` ,你需要在 [**原地 **](http://baike.baidu.com/item/%E5%8E%9F%E5%9C%B0%E7%AE%97%E6%B3%95)删除重复出现的元素,使得每个元素最多出现两次,返回移除后数组的新长度
思路:覆盖重复值
1.我们使用了两个指针,fast 是遍历指针,指向当前遍历的元素;slow 指向下一个要覆盖元素的位置。
2.同样,我们用 count 记录当前数字出现的次数。count 的最小计数始终为 1。
3.我们从索引 1 开始一次处理一个数组元素。
4.若当前元素与前一个元素相同,即 nums[fast]==nums[slow],则 count++。若 count > 2,则说明遇到了多余的重复项。在这种情况下,我们只向前移动fast,而 slow 不动。
5.若 count <=2,则我们将 slow 所指向的元素移动到 fast 位置,并同时增加 slow 和 fast。
6.若当前元素与前一个元素不相同,即 nums[fast] != nums[slow],说明遇到了新元素,则我们更新 count = 1,并且将该元素移动到 fast 位置,并同时增加 fast和 slow。
当数组遍历完成,则返回 slow+1。
class Solution(object):def removeDuplicates(self, nums):slow=0fast=1count=1while fast<len(nums):if nums[fast]==nums[slow]:count+=1if count==2:slow+=1nums[slow]=nums[fast]fast+=1else:slow+=1nums[slow]=nums[fast]fast+=1count=1return slow+1
1.2 移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
思路:覆盖0
我们创建两个指针i和j,第一次遍历的时候指针j用来记录当前有多少非0元素。即遍历的时候每遇到一个非0元素就将其往数组左边挪,第一次遍历完后,j指针的下标就指向了最后一个非0元素下标。
第二次遍历的时候,起始位置就从j开始到结束,将剩下的这段区域内的元素全部置为0。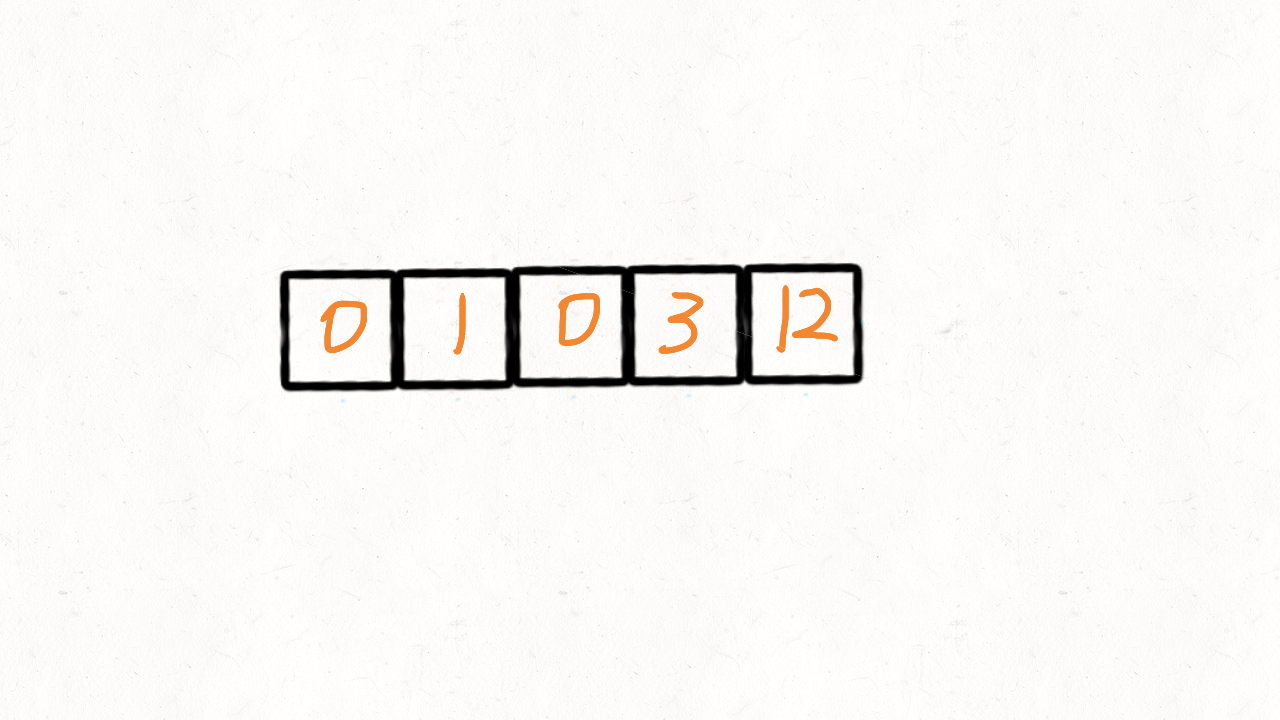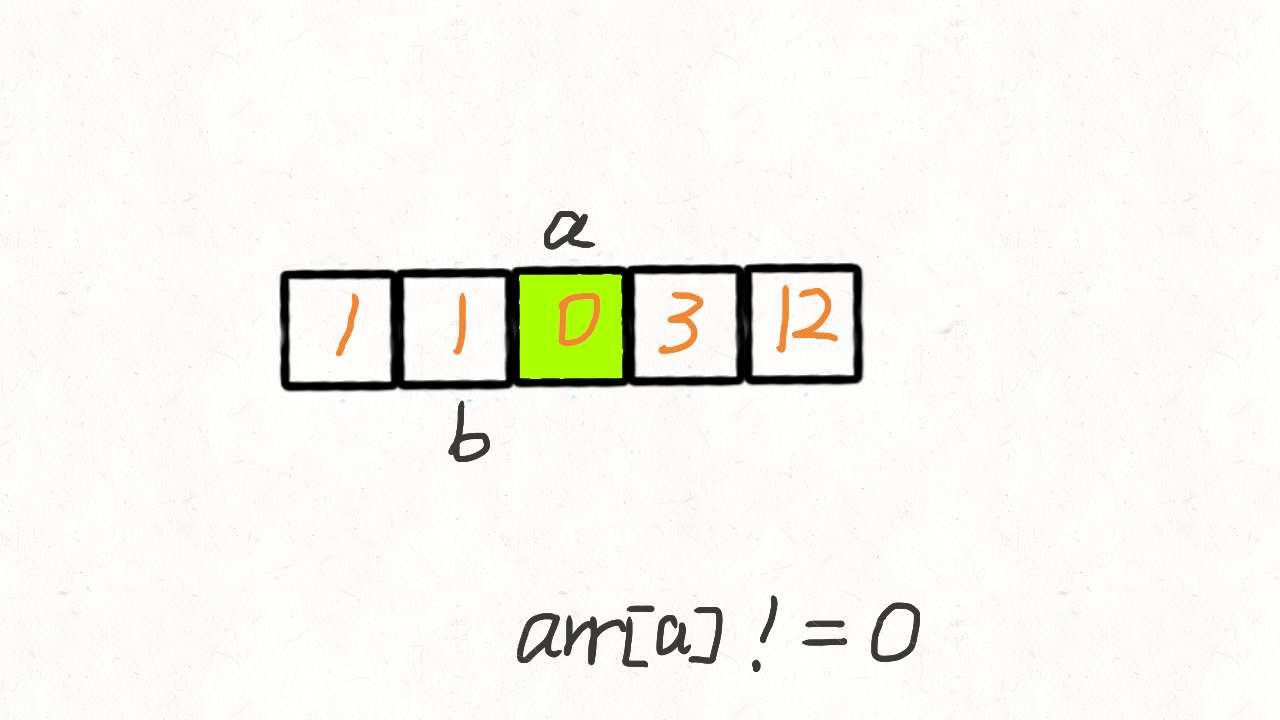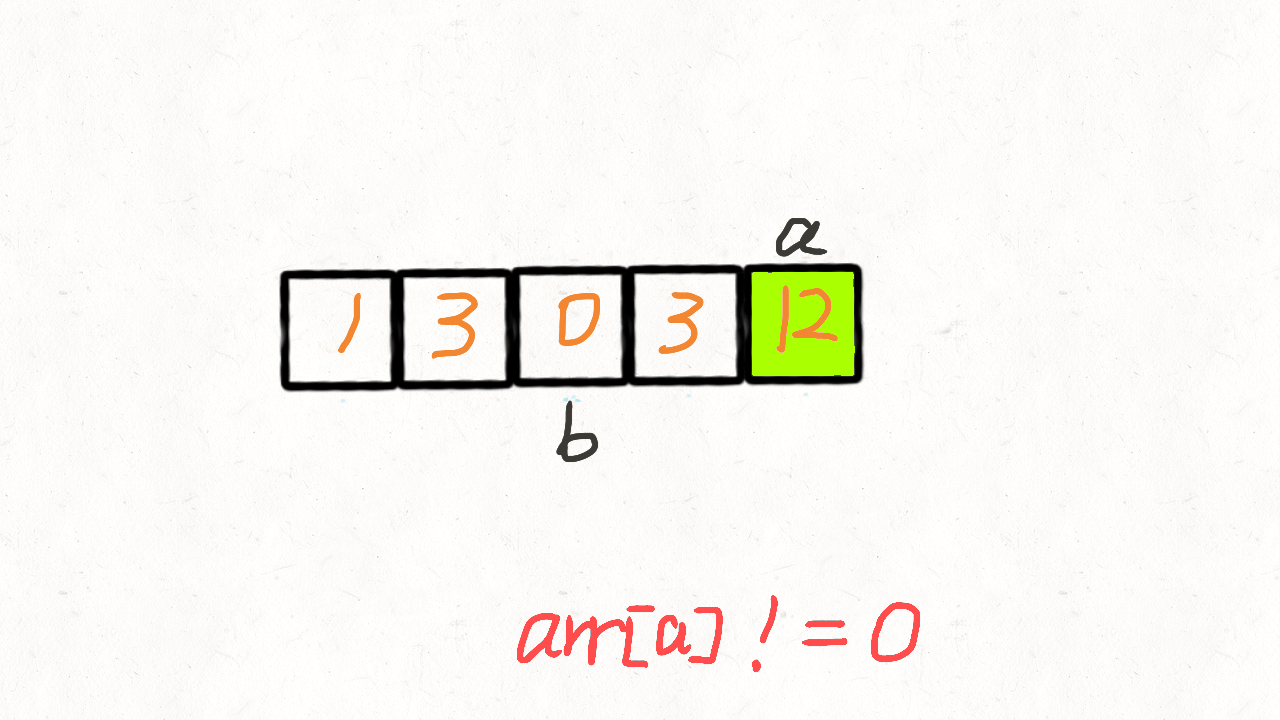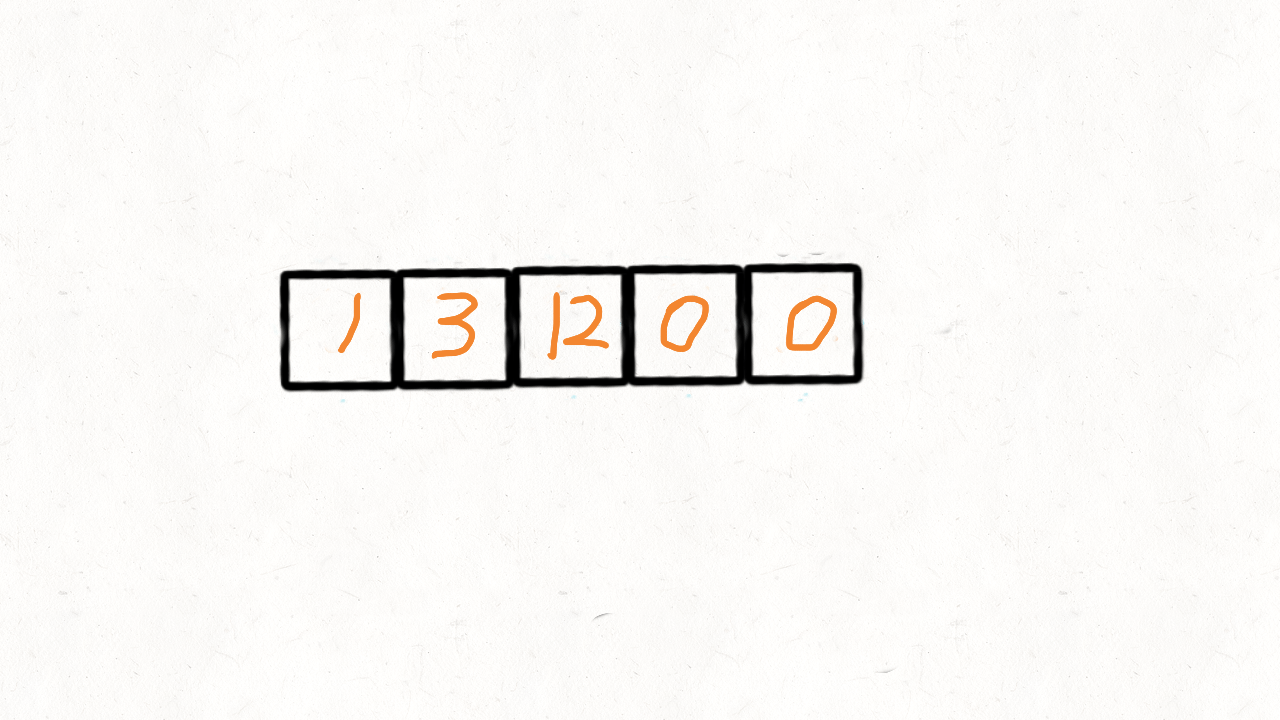
def removeDuplicated(nums):slow = 0fast = 0while fast < len(nums):if nums[fast] == 0:fast += 1else:# slow占位置,调换fast不同的值,会发生覆盖.快指针发现不同的值后慢指针前进.nums[slow] = nums[fast]slow += 1fast += 1for i in range(slow, len(nums)):nums[i] = 0print(nums, slow + 1)removeDuplicated([2,0,2,1,3,0,7,1])
1.2 删除指定元素
与移动零思路一样,只不过将0替换为指定值,通过覆盖元素做到了删除指定元素,并且不需要第二个循环覆盖值.
2. 链表快慢指针
在链表里快慢指针一般都初始化指向链表的头结点head,前进时快指针fast在前慢指针slow在后,巧妙的可以解决链表里的一些问题
2.1判断链表是否有环以及入环点:
慢指针一次走一步,快指针一次走两步,快指针在单位时间内是慢指针不熟的一倍,入环后,快指针追赶慢指针.随着时间的推移,快指针肯定会追上慢指针.若不存在环,则快指针不会相遇并且快指针会指向空.
由计算得出,当第一次相遇后,此时从头结点到入环点的距离等于小雨点到入环点的距离
因此让慢指针回到头结点,快指针继入环点.续从相遇点出发.当再次相遇后此时的相遇点就是入环点.
from typing import Optionalclass Node:def __init__(self,data):self.data=dataself.next=nextdef __repr__(self):# return "Node({})".format(self.data)return f"Node{self.data}"def detectCirclePoint(head : Optional[Node]=None):# optional 可选择的可以是 None 也可以是nodeslow=head#传入头结点fast=head# 快指针先越界,当快指针指向None停止while fast and fast.next :fast=fast.next.nextslow = slow.nextif slow==fast:# return True 判断是否有环breakslow=head#slow回到起点fast继续走while slow!=fast:slow=slow.nextfast=fast.nextreturn slow,fast#入环点# return Falseif __name__ == '__main__':n=Node(1)n1=Node(2)n2=Node(3)n4=Node(4)n5=Node(5)n6=Node(6)n.next=n1n1.next=n2n2.next=n4n4.next=n5n5.next=n6n6.next=n2# print(cir(n))print(detectCirclePoint(n))
3.对撞/左右指针
3.1俩数之和
这是一个很简单的左右指针运用的题.
第一种:
利用俩个指针,一个在下标0,一个在末尾,相向而行,当俩个指针不碰面时,求左右指针指向的元素和
如果和等于目标.则将这俩个元素打印俩个指针都相向走一步
当和小于目标时,左指针走一步
当大于时,右指针走一步
第二种:
利用字典接收值和下标
目标值减去遍历元素,如果这个差不在字典里就就将其下标与值添加到字典
def two_sum(nums: list ,target):#对撞指针(O(nlogn),返回值而不是下标right=len(nums)-1left=0while left<right:sum_two=nums[right]+nums[left]if sum_two==target:print(nums[left],nums[right])left+=1right-=1elif sum_two<target:left+=1else:right-=1
def two1_sum(nums : list,target):# 借用空间,时间复杂度On,空间复杂度大,时间最短# 字典收集遍历的值和下标dic={}# 遍历数组下标for i in range(len(nums)):# 差值cha=target-nums[i]# 判断差值是否在字典里if cha not in dic:# 不存在则把遍历 的值和下标存在字典里dic[nums[i]]=ielse:# 打印print(i,dic[cha])
3.2三数之和
思路:一个固定指针,俩个左右指针
这个题与俩数之和类似.首先排序.
创建一个接收结果的列表,遍历列表下标到倒数第二位.
如果排序后前后俩个数相同,则下次循环跳过继续执行
设置俩个指针,分别是遍历下标left=i+1,right=len(nums)-1.在固定元素后做求和
当俩个指针不相遇时,如果三数之和大于0 right-1
如果小于0,left+1
当等于时,将三个元素添加到列表中
优化:
当不相遇时并且左指针元素与下一位元素相同,左指针向前走一步
当不相遇时并且右指针元素与下一位元素相同,右指针向前走一步
def three_sum(nums):nums.sort()res=[]for i in range(len( nums)-2):if i>0 and nums[i]==nums[i-1]:continueleft=i+1right=len(nums)-1while left<right:temp=nums[i]+nums[left]+nums[right]if temp>0:right-=1elif temp<0:left+=1else:# res+=[[nums[i],nums[left],nums[right]]]res.append([nums[i],nums[left],nums[right]])while left<right and nums[left]==nums[left+1]:left+=1while left < right and nums[right] == nums[right - 1]:right-=1left += 1right -= 1return resprint(three_sum([-1,0,1,3,4,5,-2]))
3.3最接近三数之和
题目
思路与三数之和接近首先要排序,
设置变量min 是下标0,1,2三个元素和res与目标值的绝对差值
其次遍历数组固定一个值,然后设置左右指针向中间逼近
如果 三数之和与目标值的绝对差值小于min 就把差值赋予最小值 min
如果三数和 >= target,右指针左移
如果三数和 < target, 左指针右移
返回 res
from typing import Listdef threenumCloest(num: List,target):num.sort()# 排序后的三数和最大差值min=abs(num[0]+num[1]+num[2]-target)res=num[0]+num[1]+num[2]for i in range(len(num)-2):left=i+1right=len(num)-1while left<right:sum=num[i]+num[left]+num[right]if abs(sum-target)<min:min=abs(sum-target)res=sumif sum>target:right-=1if sum<target:left+=1else:return sum,return res,print(threenumCloest([-1,2,1,-4],1))
3.4 二分查找
链接
描述:
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
想法:
二分查找值,先找出中间位置:mid,然后设置左右指针在数组的首尾.当目标值大于中间值时,左指针移动到mid+1,当中间值小于目标值时,右指针移动到mid-1.相等时返回mid
时间复杂度:O(logn),空间复杂度(O(1))
def search(self, nums: List[int], target: int) -> int:left = 0;right = len(nums) - 1while left <= right:mid = left + (right-left) // 2if target == nums[mid]:return midif target < nums[mid]:right = mid – 1#最后一个字的边界查找bug 解决else :left = mid + 1return -1
3.5翻转数组
def reverse(nums):left = 0right = len(nums) - 1while left < right:nums[left], nums[right] = nums[right], nums[left]left += 1right -= 1return nums
4. 分离指针
4.1合并有序数组
设置一个新列表/默认某一个数组长度足够长
利用归并排序的并想法,分别在俩个排序数组数组指针在下标0.
比较俩个排序数组里的元素大小,然后将小的元素添加到
from typing import Listnums1=[1, 5, 6,3,0,0,0]def merge(nums1: List[int], m: int, nums2: List[int], n: int):i = m - 1j = n - 1k = m + n - 1 # 控制输出的数组大小# 倒着遍历while i >= 0 and j >= 0:if nums1[i] >= nums2[j]:nums1[k] = nums1[i]i -= 1elif nums1[i] < nums2[j]:nums1[k] = nums2[j]j -= 1k -= 1while i >= 0:nums1[k] = nums1[i]i -= 1k -= 1while j >= 0:nums1[k] = nums2[j]j -= 1k -= 1return nums1
4.2合并有序链表
https://leetcode-cn.com/problems/he-bing-liang-ge-pai-xu-de-lian-biao-lcof/
创建虚拟结点,记录虚拟结点cur.
当俩个链表有结点时循环遍历,如果第一个链表a的值小于第二个链表b
,cur指向a的结点 a指向下一个结点
否则cur指向b的结点,b指向下一个结点
判断完后cur向前走一步继续循环直到有一个链表先空
循环后判断哪个链表还没完,将cur指向剩链表
 额
额
# 俩个有序链表合并(归并排序)def mergeTwoLists(l1: Node,l2 : Node):# 另外创建一个空间dummy=Node(0)cur=dummywhile l1 and l2 :if l1.data<l2.data:cur.next=Node(l1.data)l1=l1.nextelse:cur.next=Node(l2.data)l2=l2.nextcur=cur.nextif l1 is None:cur.next=l2if l2 is None:cur.next=l1pre=dummy.nextwhile pre:print(pre.data,end='->')pre=pre.next
5.链表虚拟结点与指针结合
在很多链表的问题处理时,都要考虑到头结点的处理,有了虚拟头结点,在链表里 删除或者插入,交换就不会出现头部为空的发生.
5.1合并有序链表-4.2
5.2链表俩俩交换
链接:https://leetcode-cn.com/problems/swap-nodes-in-pairs/solution/24-liang-liang-jiao-huan-lian-biao-zhong-de-jie-58/
使用虚拟头结点,会方便很多,要不然每次针对头结点(没有前一个指针指向头结点),还要单独处理。
对虚拟头结点的操作,
接下来就是交换相邻两个元素了,如下图.虚拟头指向头结点,,用cur 记录好虚拟头.
当cur的下一个和下下一个结点存在,即考虑奇数和偶数个结点情况:循环
指针上岗: slow=cur.next fast=cur.next.next
交换位置:cur指向快指针元素, 慢指针指向快指针的下一个,fast指向慢指针.
结点前进:cur走到快指针位置
初始时,cur指向虚拟头结点,然后进行如下三步:
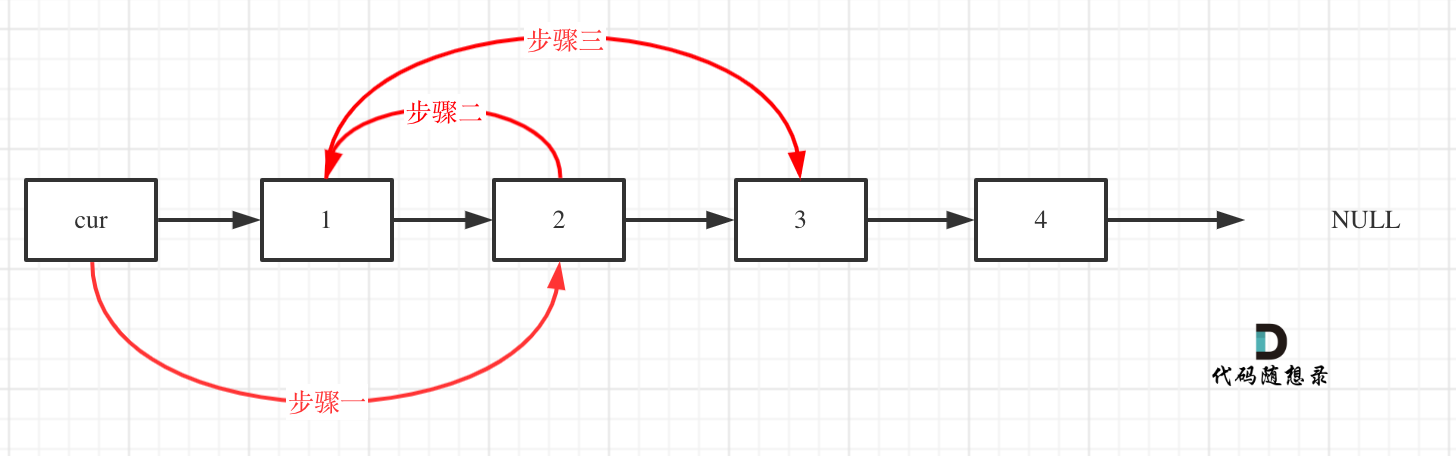
def swapPairs(self, head):""":type head: ListNode:rtype: ListNode"""dummy=ListNode(0)dummy.next=headpre=dummy# pre 的后面必须有俩个才循环while pre.next and pre.next.next:# 指针上岗slow=pre.nextfast=pre.next.next# 交换位置pre.next=fastslow.next=fast.nextfast.next=slow# 结点前进pre=pre.next.nextreturn dummy.next
5.3链表插入排序
https://leetcode-cn.com/problems/insertion-sort-list/
插入排序默认最左边一部分已排序,类似扑克牌排序,.每次对一个元素排序,

若有收获,就点个赞吧
0 人点赞
