排序是计算机程序设计中的一种重要操作,它的功能是将一个数据元素的任意序列,重新排列成一个关键字有序的序列。
一、冒泡排序 BubbleSort
介绍:
冒泡排序的原理非常简单,它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
步骤:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对第0个到第n-1个数据做同样的工作。这时,最大的数就“浮”到了数组最后的位置上。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
稳定性:
冒泡排序在相邻元素相等不会交换位置,所以他是稳定排序适用场景:
适合小数据的排序排序演示:

源代码:def bubble(nums):count = 0for i in range(1, len(nums)):fl = Truefor j in range(len(nums) - i):if nums[j] > nums[j + 1]:nums[j], nums[j + 1] = nums[j + 1], nums[j]count += 1print('第%s轮排序结果' % (count), nums)return nums
不过针对上述代码还有优化方案。
优化1:某一趟遍历如果没有数据交换,则说明已经排好序了,因此不用再进行迭代了。用一个标记记录这个状态即可。def bubble(nums):count = 0for i in range(1, len(nums)):flag = Truefor j in range(len(nums) - i):if nums[j] > nums[j + 1]:nums[j], nums[j + 1] = nums[j + 1], nums[j]flag=Falsecount += 1print('第%s轮排序结果' % (count), nums)if flag:breakreturn nums
二、选择排序 SelectionSort
介绍:
选择排序是一种最简单直观的排序,和冒泡有一定的相似度.可以说是冒泡排序的改进
步骤:
- 在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 以此类推,直到所有元素均排序完毕。
稳定性:
他是一种不稳定的排序方法适用场景:
适用于简单数据排序,优于冒泡,但大数据面前有些力不从心.排序演示:
源代码:def selection_sort(nums):count=0for i in range(len(nums)-1):for j in range(i+1,len(nums)):if nums[i]>nums[j]:count+=1nums[i],nums[j]=nums[j],nums[i]print('第%s次结果为'%(count),nums)print(nums)
三、插入排序 InsertionSort
介绍:
插入排序的工作原理是,通过构建有序序列,对于每个未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
步骤:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果被扫描的元素(已排序)大于新元素,将该元素后移一位
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5步
稳定性:
由于只需要找到不大于当前数的位置而不需要交换,因此,插入排序是稳定的适用场景:
适用于数据比较少的时候
排序演示:
源代码:def insert_sort(nums:List):for r in range(1,len(nums)):target=nums[r]for l in range(r):if nums[l]>nums[r]:nums[l+1:r+1]=nums[l:r]nums[l]=targetbreakreturn nums
四、计数排序 Counting sort
介绍:
计数排序不是比较的排序算法,核心是把输入的数据转化伪建存在额外开辟的数组空间中.
步骤:
1.找出待排数组中最大的值,开辟一份空间
2.放到新开辟的空间中
3.按顺利依次取出
稳定性:
适合场景:
计数排序是一种牺牲空间换取时间的排序方式,它仅适用于数据比较集中的情况
排序演示:
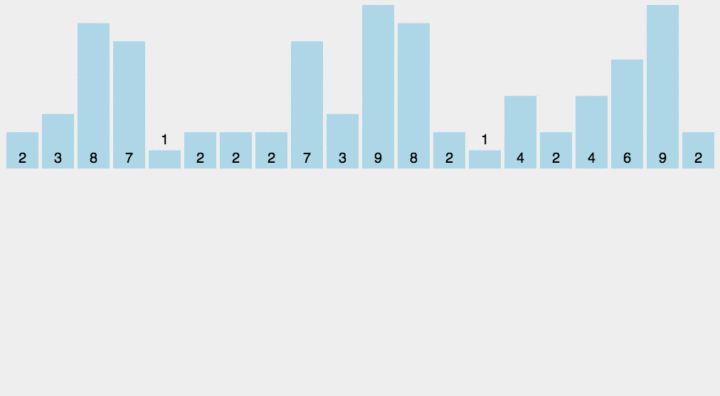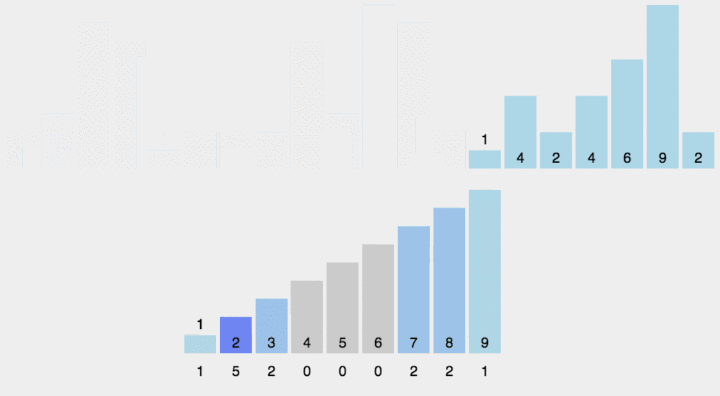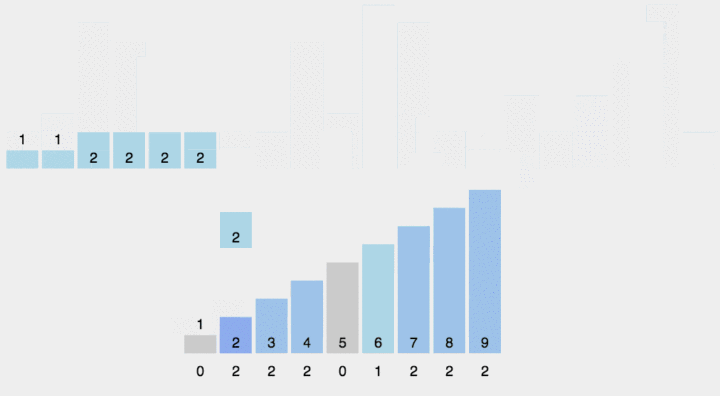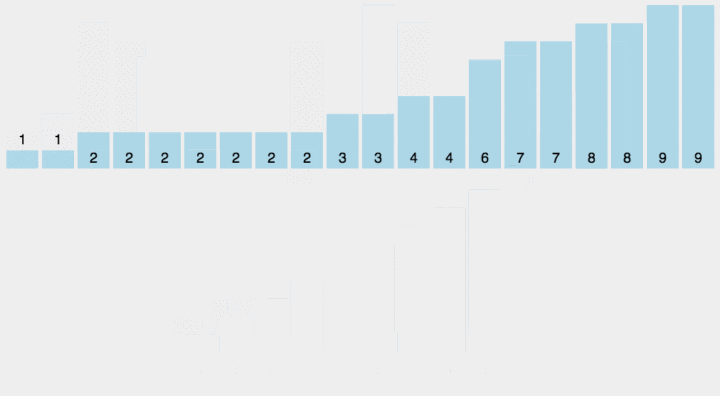
源代码:
def countSort(arr:List):max_value=max(arr)count_arr=[0]*(max_value+1)for i in range(len(arr)):count_arr[arr[i]]+=1sort_arr=[]for i in range(len(count_arr)):for j in range(count_arr[i]):sort_arr.append(i)return sort_arr
五、归并排序 MergeSort
介绍:
归并排序是采用分治法的一个非常典型的应用。归并排序的思想就是先递归分解数组,再合并数组。
先考虑合并两个有序数组,基本思路是比较两个数组的最前面的数,谁小就先取谁,取了后相应的指针就往后移一位。然后再比较,直至一个数组为空,最后把另一个数组的剩余部分复制过来即可。
再考虑递归分解,基本思路是将数组分解成left和right,如果这两个数组内部数据是有序的,那么就可以用上面合并数组的方法将这两个数组合并排序。如何让这两个数组内部是有序的?可以再二分,直至分解出的小组只含有一个元素时为止,此时认为该小组内部已有序。然后合并排序相邻二个小组即可。
稳定性:
归并排序严格遵循从左到右或从右到左的顺序合并子数据序列, 它不会改变相同数据之间的相对顺序, 因此归并排序是一种稳定的排序算法.
应用场景:
内存空间不足的时候使用归并排序
排序演示: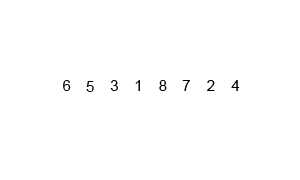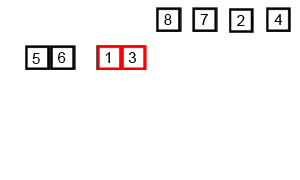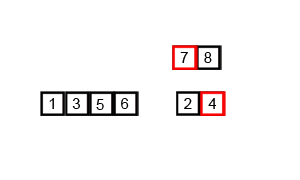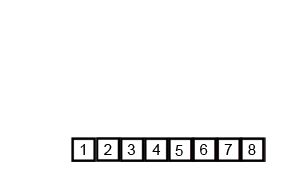
源代码:
def mergeSort(nums):if len(nums)<=1:return numsmiddle=len(nums)//2left,right=nums[0:middle],nums[middle:]return merge(mergeSort(left),mergeSort(right))def merge(left,right):list=[]while left and right:if left[0]>=right[0]:list.append(right.pop(0))else:list.append(left.pop(0))if left:list.extend(left)if right:list.extend(right)return list
六、快速排序 QuickSort
介绍:
快速排序通常明显比同为Ο(n log n)的其他算法更快,因此常被采用,而且快排采用了分治法的思想,所以在很多笔试面试中能经常看到快排的影子。可见掌握快排的重要性。
步骤:
- 从数列中挑出一个元素作为基准数。
- 分区过程,将比基准数大的放到右边,小于或等于它的数都放到左边。
- 再对左右区间递归执行第二步,直至各区间只有一个数。
稳定性:
快速排序是一种不稳定的排序应用场景:
适合大多数情况下适用
排序演示: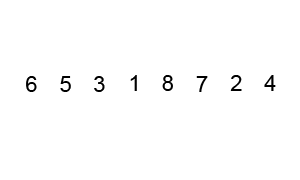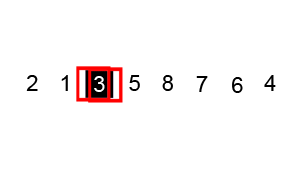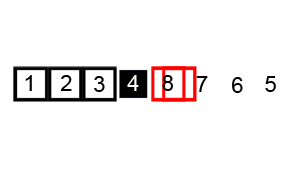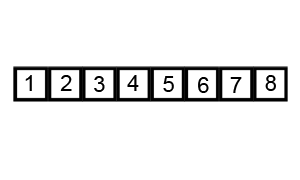
源代码:
def quickSort(array):if len(array)<2:return arrayelse:pivot=array[0]less=[i for i in array[1:] if i <= pivot]greater=[i for i in array[1:] if i > pivot]return quickSort(less)+[pivot]+quickSort(greater)
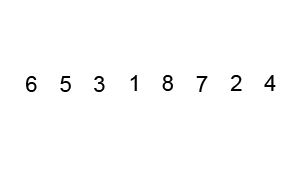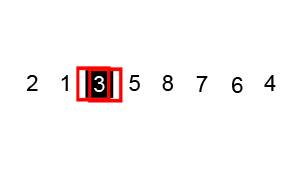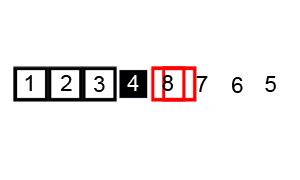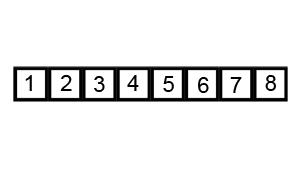
七、桶排序 Bucket Sort
介绍:
它是将数组划分到一定数量的有序的桶里,然后再对每个桶中的数据进行排序,最后再将各个桶里的数据有序的合并到一起。
排序图示:

源代码:
def bucketSort(nums: list):maxnum = max(nums)minnum = min(nums)d = maxnum - minnumbucket_num = len(nums)count_list = []for i in range(bucket_num):count_list.append([])for i in range(len(nums)):num = int((nums[i] - minnum) * (bucket_num - 1) / d)bucket = count_list[num]bucket.append(nums[i])for i in range(len(count_list)):count_list[i].sort()sort_nums = []for i in count_list:for j in i:sort_nums.append(j)return sort_nums
总结
下面为七种经典排序算法指标对比情况:
| 排序法 | 平均时间 | 最差情形 | 稳定度 |
|---|---|---|---|
| 冒泡排序 | O(n) | O(n) | 稳定 |
| 选择排序 | O(n) | O(n) | 不稳定 |
| 快速排序 | O(nlogn) | O(n) | 不稳定 |
| 插入排序 | O(n) | O(n) | 稳定 |
| 计数排序 | O(n+k) | O(n+k) | 稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | 稳定 |
| 桶排序 | O(n+k) | O(n+k) | 不稳定 |

若有收获,就点个赞吧
0 人点赞
