1.多条件检索,结果高亮处理 (业务场景 索引库设计 实现流程)
业务场景:酒店系统需要根据用户查询的关键字(酒店名、地址、星级)等搜索出对应的酒店信息。
设计思考:考虑到MySQL对海量数据的搜索效率不高,无法进行及时的结果反馈给用户,故选择elasticsearch技术来实现数据的快速搜索。
实现流程:首先建立索引库
将name字段设计为text支持分词;band,city等设置为poswprd,添加拼音分词器等。
PUT /hotel{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}}
从数据库将数据导入索引库,建立相应文档,一条数据就是一个文档。
//批量导入文档 BulkRequest@Testvoid testcreateAll() throws IOException {//1.在mysql中查询出所以字段List<Hotel> list = hotelService.list();//遍历//2.创建请求对象BulkRequest request = new BulkRequest();for (Hotel hotel : list) {//3.将字段封装成hotelDocHotelDoc hotelDoc = new HotelDoc(hotel);//4.将hotelDoc转化成JSON格式(FastJson)String json = JSON.toJSONString(hotelDoc);//5.准备请求参数(一般都是request.source(json参数,参数格式))request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(json, XContentType.JSON));}//6.发送请求,处理结果client.bulk(request, RequestOptions.DEFAULT);}
关键字搜索
1.请求对象
2.设置参数
3.发送请求
4.解析查询结果
/*** @功能: 查询所有* @return: cn.itcast.hotel.pojo.PageResult*/@Overridepublic PageResult searchAll(RequestParams requestParams, SearchRequest request) {//requestParams:{key: "", page: 1, size: 5, sortBy: "default"}//创建索引库客户端(提取到bean里)// RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(// HttpHost.create("http://192.168.200.130:9200")// ));PageResult pageResult = null;try {//1.创建请求对象BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();//2.设置请求参数 "query": "match": {"all": "外滩如家"}}if (StringUtils.isNotBlank(requestParams.getKey())) {boolQuery.must(QueryBuilders.matchQuery("all", requestParams.getKey()));} else {boolQuery.must(QueryBuilders.matchAllQuery());}//过滤条件 brand city startName minPrice maxPriceif (StringUtils.isNotBlank(requestParams.getCity())) {boolQuery.filter(QueryBuilders.termQuery("city", requestParams.getCity()));}if (StringUtils.isNotBlank(requestParams.getBrand())) {boolQuery.filter(QueryBuilders.termQuery("brand", requestParams.getBrand()));}if (StringUtils.isNotBlank(requestParams.getStarName())) {boolQuery.filter(QueryBuilders.termQuery("starName", requestParams.getStarName()));}//价格用rangeif (requestParams.getMinPrice() != null && requestParams.getMinPrice() != null) {boolQuery.filter(QueryBuilders.rangeQuery("price").gte(requestParams.getMinPrice()).lte(requestParams.getMaxPrice()));}request.source().query(boolQuery);//分页int page = requestParams.getPage();int size = requestParams.getSize();request.source().from((page - 1) * size).size(size);//排序 "sort": [{"_geo_distance":// {"location": {"lat": 31.146538,"lon": 121.671663},// "order": "asc"}}]String location = requestParams.getLocation();if (StringUtils.isNotBlank(location)) {request.source().sort(SortBuilders.geoDistanceSort("location",new GeoPoint(location)).order(SortOrder.ASC).unit(DistanceUnit.KILOMETERS));}//竞价排名GET /hotel/_search{"query": {"function_score": {// "query": {"match": {"name": "如家"}},// "functions": [{"filter": {"term": {"name": "如家"}},// "weight": 2}],// "boost_mode": "multiply"}}}FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(boolQuery, new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{new FunctionScoreQueryBuilder.FilterFunctionBuilder(//加分条件QueryBuilders.termQuery("isAD", true),//加分权重ScoreFunctionBuilders.weightFactorFunction(15))});request.source().query(functionScoreQuery);//排序 判断sortBy default 默认 score 按评分自定义排序 price 按价格自定义排序String sortBy = requestParams.getSortBy();if (sortBy.equals("score")) {//评分排序request.source().sort("score", SortOrder.DESC);} else if (sortBy.equals("price")) {//价格排序request.source().sort("price", SortOrder.DESC);}//高亮 "highlight": {// "fields": {"name": {// "pre_tags": "<em>",// "post_tags": "</em>"}}}if (StringUtils.isNotBlank(requestParams.getKey())) {HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("name");highlightBuilder.requireFieldMatch(false);highlightBuilder.preTags("<em>");highlightBuilder.postTags("</em>");request.source().highlighter(highlightBuilder);}//3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//获取结果pageResult = getRestult(response);} catch (IOException e) {log.error("查询出错信息:{}", e.getMessage());}return pageResult;}/*** @功能: 解析处理结果* @return: cn.itcast.hotel.pojo.PageResult*/public PageResult getRestult(SearchResponse response) {//4.解析结果SearchHits hits = response.getHits();SearchHit[] searchHits = hits.getHits();long total = hits.getTotalHits().value; //总页数//遍历 拿到 source字段List<HotelDoc> hotels = new ArrayList<>(); //存储查询返回的酒店信息for (SearchHit hit : searchHits) {String sourceAsString = hit.getSourceAsString(); //JSON 格式HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class); //转换为HotelDoc对象if(hit.getHighlightFields().size()>0){//处理高亮结果 hits: highlight:nameMap<String, HighlightField> highlightFields = hit.getHighlightFields();HighlightField highlightField = highlightFields.get("name");Text[] fragments = highlightField.fragments();String newname = "";for (Text fragment : fragments) {newname += fragment;}hotelDoc.setName(newname);}hotels.add(hotelDoc);//获取地址排序Object[] sortValues = hit.getSortValues();if (sortValues.length > 0) {Object sortValue = sortValues[0];hotelDoc.setDistance(sortValue);}}return new PageResult(total, hotels);}
2. 按距离排序 查询离我最近的XXX (业务场景 索引库设计 实现流程)
业务场景:客户需要查询离他最近的酒店,按距离排序的需求就有了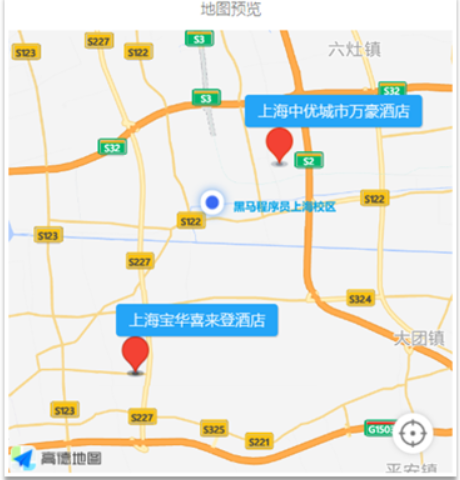
设计思考:由前端发送当前客户坐标地址,后台接受数据后,利用es的“geo_distance”功能查询后按距离进行排序。
实现流程:
//排序 "sort": [{"_geo_distance":// {"location": {"lat": 31.146538,"lon": 121.671663},// "order": "asc"}}]String location = requestParams.getLocation();if (StringUtils.isNotBlank(location)) {request.source().sort(SortBuilders.geoDistanceSort("location",new GeoPoint(location)).order(SortOrder.ASC).unit(DistanceUnit.KILOMETERS));}//获取地址排序Object[] sortValues = hit.getSortValues();if (sortValues.length > 0) {Object sortValue = sortValues[0];hotelDoc.setDistance(sortValue);}
3. XXX竞价排名? (业务场景 索引库设计 实现流程)
业务场景:可以根据商家的广告费,在搜索的结果里排到首条显示,是增收的功能,比较重要。
设计思考:给酒店增加一个字段属性isAD(boolean类型),true表示有广告,再根据es的自定义算分函数function_score进行分数加权,这样保证有广告的酒店分数最高,排在首页。前端可以根据此字段显示广告的标记。function_score三要素:过滤条件,加权值,加权方式。
实现流程:
//竞价排名GET /hotel/_search{"query": {"function_score": {// "query": {"match": {"name": "如家"}},// "functions": [{"filter": {"term": {"name": "如家"}},// "weight": 2}],// "boost_mode": "multiply"}}}FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(boolQuery, new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{new FunctionScoreQueryBuilder.FilterFunctionBuilder(//加分条件QueryBuilders.termQuery("isAD", true),//加分权重ScoreFunctionBuilders.weightFactorFunction(15))});
4. 聚合查询搜索条件? (业务场景 索引库设计 实现流程)
业务场景:在进行相关酒店搜索后,可选项应该只包含此类酒店的信息,实现动态搜索。比如搜索如家的时候,如果杭州没有如家,则不会再城市选项中出现。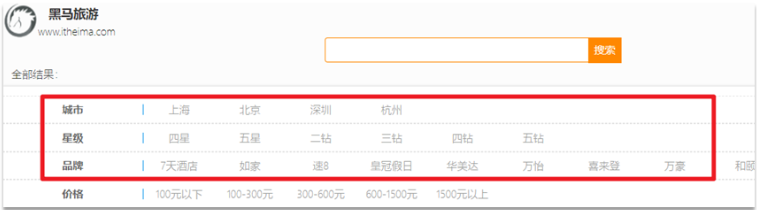
设计思考:按城市分桶,存入map集合,key=”上海”,value=list
实现流程:
/*** @功能: 聚合索引库* @return: java.util.Map<java.lang.String, java.util.List < java.lang.String>>*/@Overridepublic Map<String, List<String>> getFilters(RequestParams params, SearchRequest request) {Map<String, List<String>> result = new HashMap<>();try {// { “aggs” :{ "brand_agg" :{"terms":{"field": "brand","size":20 }} }}//1.创建请求//2.设置请求参数//先按之前的进行搜索searchAll(params, request);//全文搜索不显示request.source().size(0);//按品牌分桶request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));//按城市分桶request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));//按商圈分桶request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(100));//3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析结果Aggregations aggregations = response.getAggregations();//根据名称获取结果List<String> brandAgg = getAggByName(aggregations, "brandAgg");result.put("brand", brandAgg);List<String> cityAgg = getAggByName(aggregations, "cityAgg");result.put("city", cityAgg);List<String> starAgg = getAggByName(aggregations, "starAgg");result.put("starName", starAgg);} catch (IOException e) {log.error("聚合搜索出错{}", e.getMessage());}return result;}/*** @功能: 获取聚合结果桶里的数据* @return: java.util.List<java.lang.String>*/public List<String> getAggByName(Aggregations aggregations, String aggname) {Terms terms = aggregations.get(aggname);//获取桶 bucketsList<? extends Terms.Bucket> buckets = terms.getBuckets();List<String> list = new ArrayList<>();for (Terms.Bucket bucket : buckets) {String key = bucket.getKeyAsString();list.add(key);}return list;}
5. 自动补全及拼音查询? (业务场景 索引库设计 实现流程)
业务场景:当在搜索框里输入拼音时在下拉框自动生成相应相关字段提示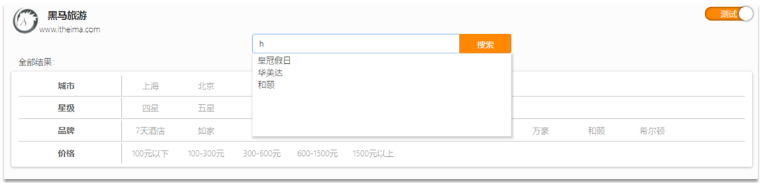
设计思考:按name进行分词,再使用拼音分词器转成拼音分词,当输入相应拼音后能查出对应的汉字词组。再使用es的suggestion功能实现自动补全。
实现流程:
修改索引库结构增加拼音分词器
// 酒店数据索引库PUT /hotel{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}}
在映射的实体类增加suggestion字段
重新导入索引库文档
代码实现功能
/*** @功能: 搜索自动回显* @return: java.util.List<java.lang.String>*/@Overridepublic List<String> getSuggestions(String key) {List<String> list = new ArrayList<>();try {//1.准备请求SearchRequest request = new SearchRequest("hotel");//2.设置参数request.source().suggest(new SuggestBuilder().addSuggestion("suggestions", SuggestBuilders.completionSuggestion("suggestion").prefix(key).skipDuplicates(true).size(5)));//3.发起请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析结果Suggest suggest = response.getSuggest();//5.获取补全结果CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();//6.返回结果for (CompletionSuggestion.Entry.Option option : options) {String text = option.getText().toString();list.add(text);}return list;} catch (IOException e) {log.error("获取出错:原因为{}", e.getMessage());}return list;}
6.es和mysql数据同步思路?
可以有三种方案实现:
1)使用微服务间的同步调用,使用Feign组件实现。
2)使用消息队列进行异步通知,使用RabbitMQ组件实现。
3)使用监听binglog进行监听。
目前使用第二种方案进行实现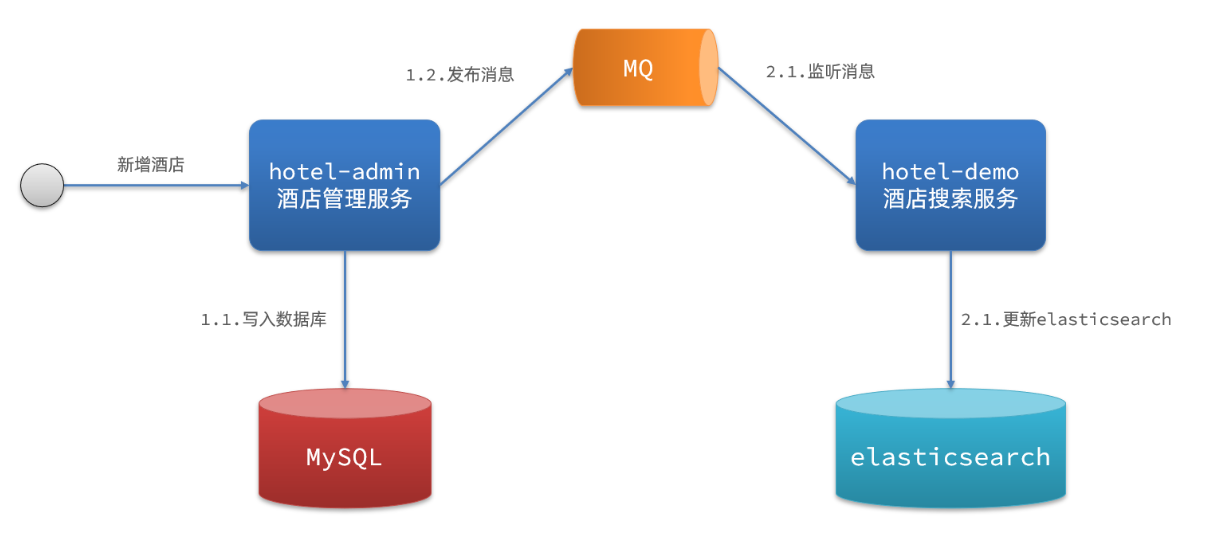
思路:
当酒店管理服务发生数据的增加、删除、修改时,将更改消息发送给RabbitMQ的主题交换机(hotel.exchange),与交换机绑定的有删除(deleta_queue)和增加修改队列(insert_queue)。酒店搜索服务对消息队列进行监听,当消息过来后,依据消息的类型和参数,调用服务层方法,通过相应es的API对索引库中的片段进行相应的操作,从而达到MySQL数据库与Elasticsearch文档中的数据保持一致。
代码实现:
a.在hotel_domo与hotel_admin中导入rabbitMQ的依赖。
b.在hotel_domo与hotel_admin中配置连接信息。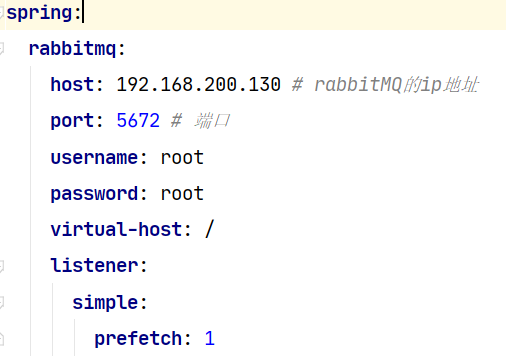
c.在hotel_domo与hotel_admin中声明exchange、queue、bing实例与常量名。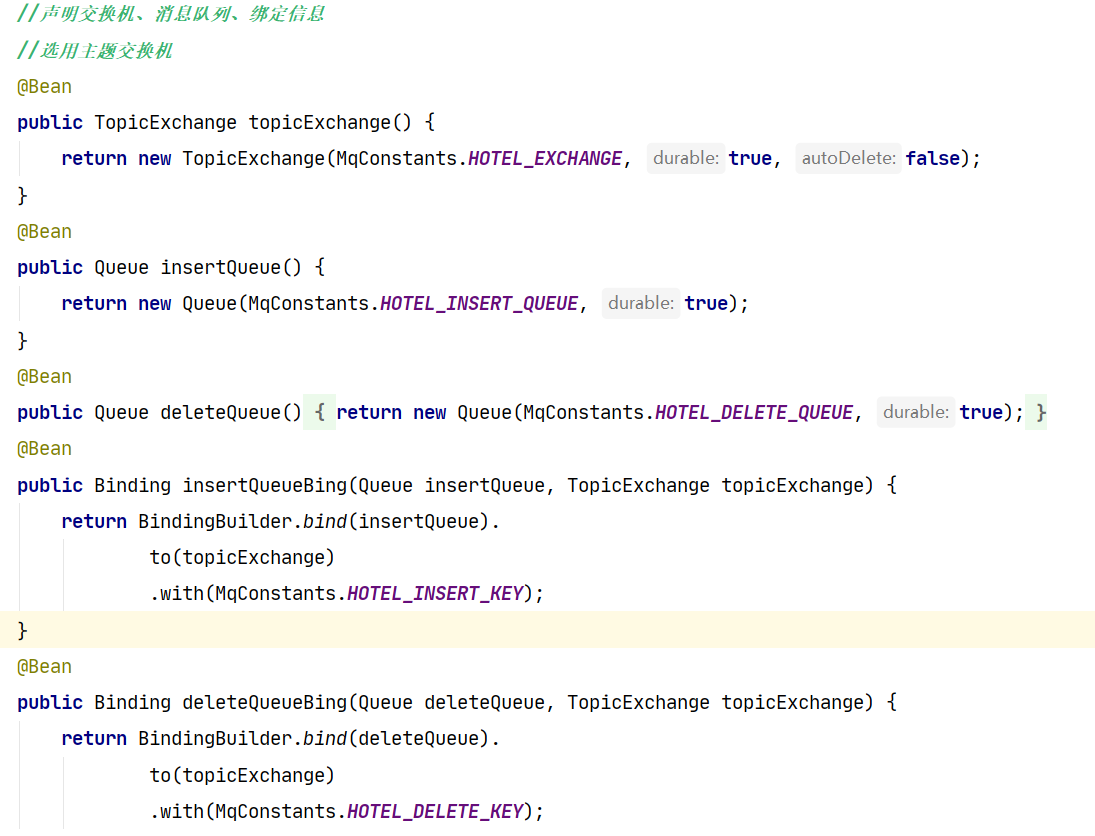
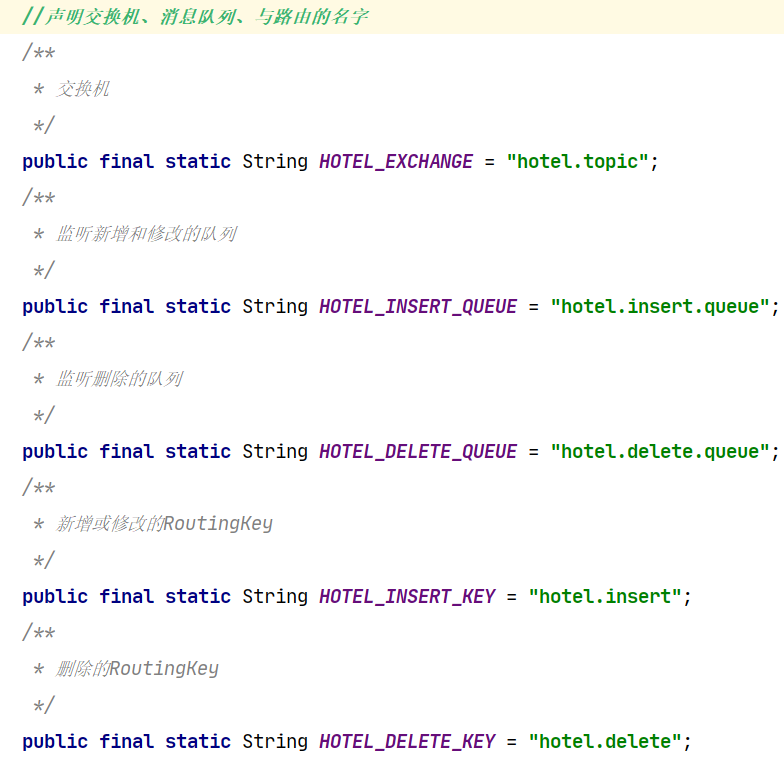
d.在hotel_admin中发消息。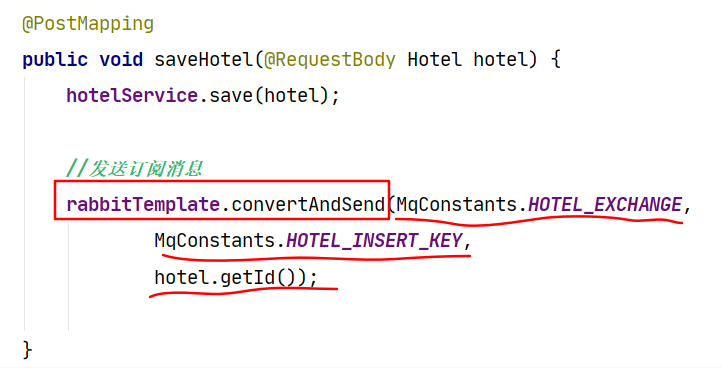
e.在hotel_demo中j接收消息,并调用服务层执行相关操作。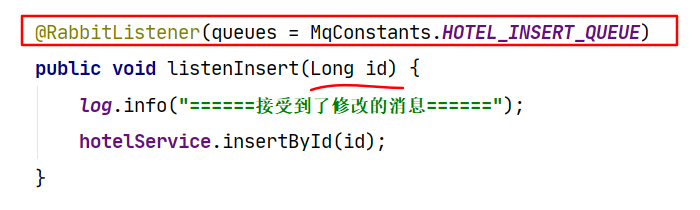
7.es如何保证高可用?(集群介绍)
- 集群(cluster):一组拥有共同的 cluster name 的 节点。
- 节点(node) :集群中的一个 Elasticearch 实例
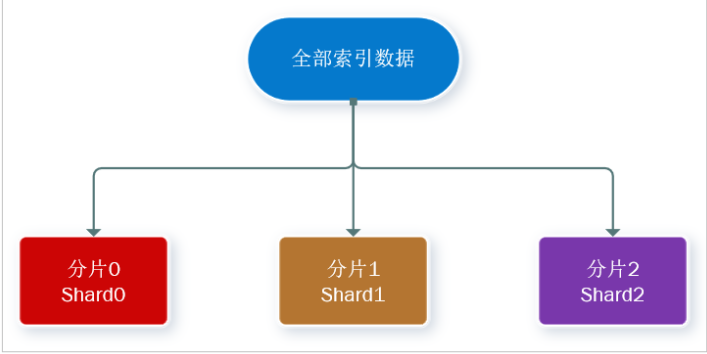
- 分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
-
8.es集群中分片和副本介绍?
主分片(Primary shard):相对于副本分片的定义。
- 副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
9.es集群中的脑裂现象?
脑裂是由于网络阻塞,分节点与主节点失联,所有分节点重新选出新节点作为主节点,而网络正常后,之前的主节点恢复通讯,造成一个集群出现2个主节点,形成脑裂现象。不过一般这种情况很少出现。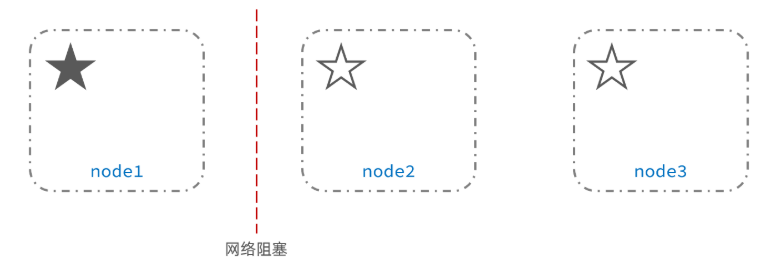
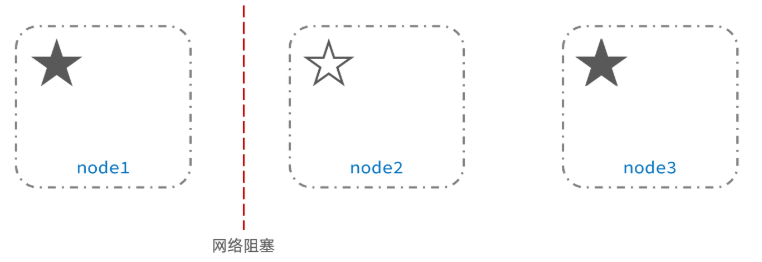
10.es集群中的故障转移? (集群容错)
集群分布式储存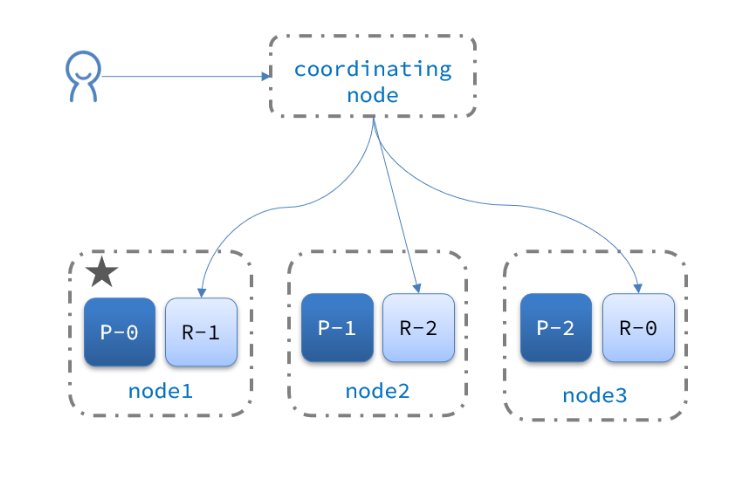
故障转移:当节点node1宕机后,node2和node3会重选主节点,并创建P-0主分片和R-1副主分片。流程图如下: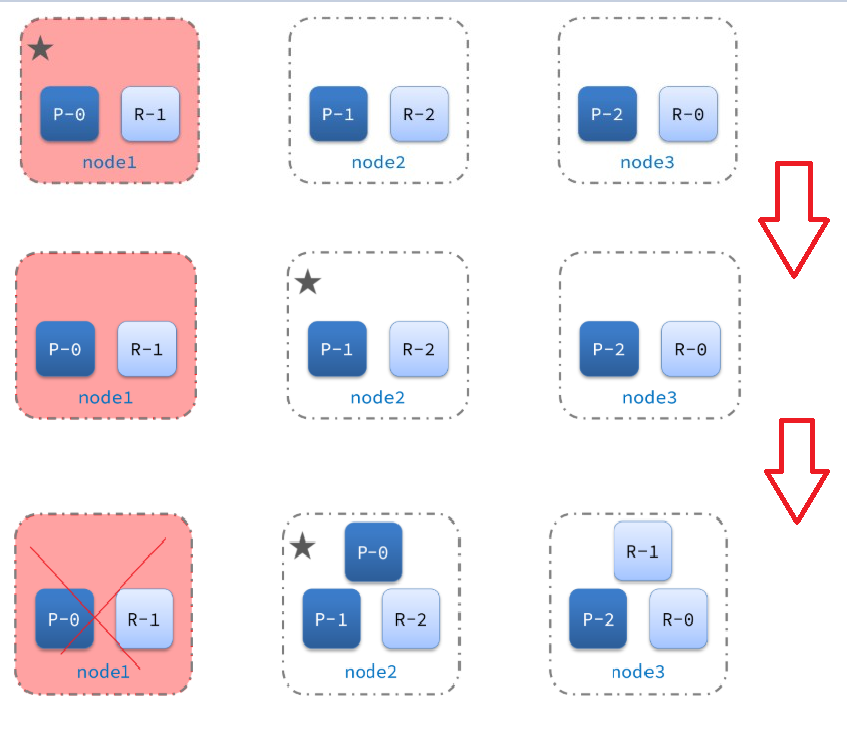

若有收获,就点个赞吧
0 人点赞
