1.es介绍及作用?
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容。与mysql相比,es主要突出在海量数据的搜索能力比较强,以下是es的核心组件:
2. es和lucene的关系?
elasticsearch底层是基于lucene来实现的。es将lucene进行了封装,减少了开发人员的开发工作量。
3. 倒排索引介绍?
倒排索引中有两个非常重要的概念:
文档(Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个商品信息。
词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条。
如上图所示,倒排索引是先根据词条搜索到对应的文档ID,再由文档ID得到相应文档并提取出对应的数据。而正向索引搜索词条时,主键ID失效,只能全表扫描搜索。
4.中文分词器介绍?
中文分词器是解决es对中文数据分词不准确问题而开发的插件,目前使用较多的是ik分词器,ik分词器具有ik_smart与ik_max_word两种分词策略,并且支持扩展词词典与停用词词典,能够满足大多数分词场景。
5. 如何扩展新词 如何忽略停顿词?
a.打开IK分词器config目录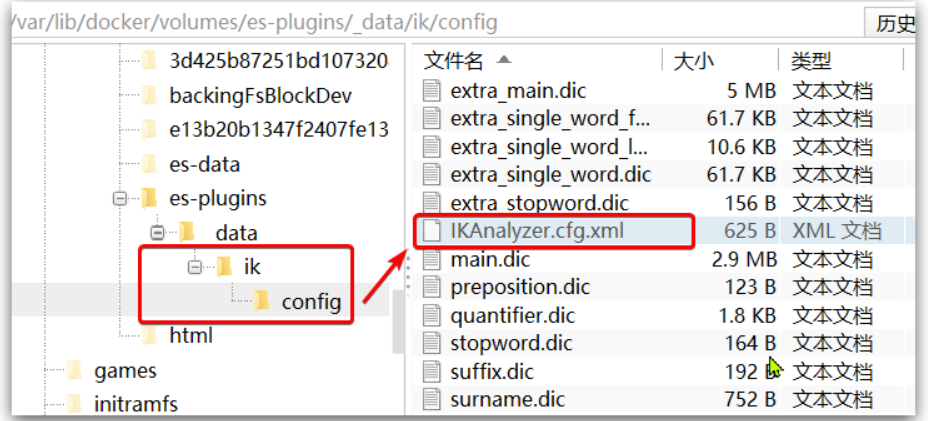
b.在IKAnalyzer.cfg.xml配置文件内容添加ext.dic (新词) 与stopwords.dis(停止词):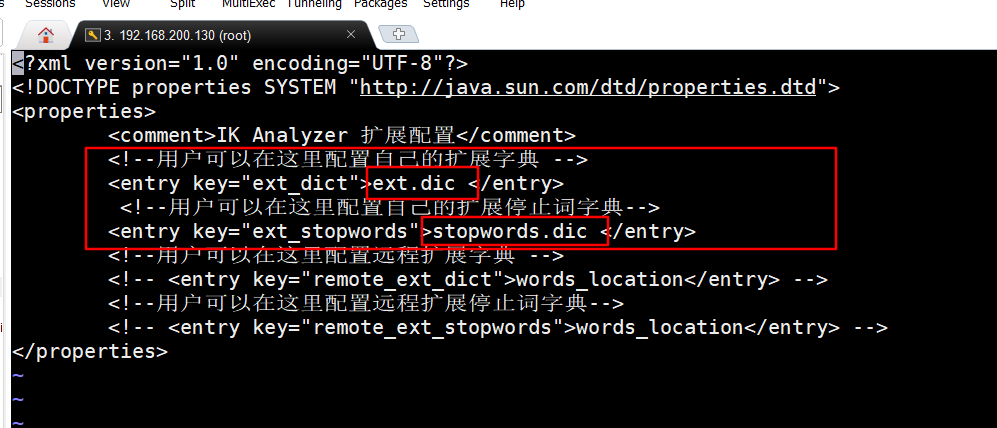
c.在config目录下创建ext.dic文件,stopword.dic默认已存在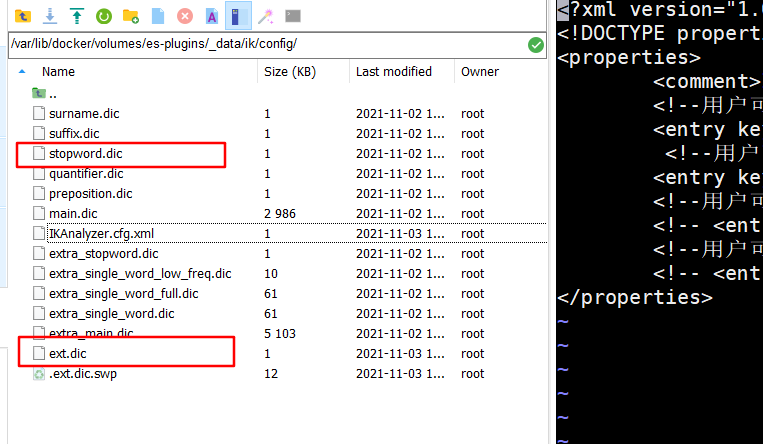
d.进入ext.dic文件添加新词,在stopword.dic文件中添加停止词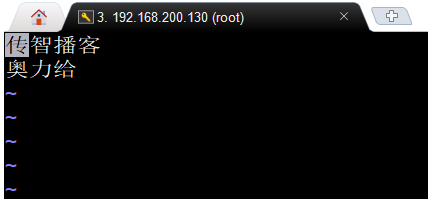
6. mysql和es 对比?
MySQL作为开源关系型数据库,应用范围非常广泛,非常适合于结构化数据存储和查询。在数据查询场景下,默认返回所有满足匹配条件的记录;
而ES作为新生代NoSQL数据库代表之一,非常适合于非结构化文档类数据存储、更创新支持智能分词匹配模糊查询。比如在电商网站商品搜索栏中,用户输入以空格为分隔符的字符串(如:家电电视等),后台ES数据库搜索引擎会根据用户输入的信息,对数据库中保存的非结构化数据进行分词模糊匹配查询,返回满足匹配条件的前N条记录给用户;另外ES更典型应用在于根据用户浏览记录日志来追踪用户行为,智能推送用户期望浏览的数据信息,此时通常借助ELK三大组件互相配合完成。
ES支持倒排索引,非主键字段搜索速度远比Mysql快。
7.java中如何操作es?
引入依赖
<!-- ES Client --><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><elasticsearch.version>7.12.1</elasticsearch.version></dependency>
初始化RestHighLevelClient
private RestHighLevelClient client;//创建索引库客户端@BeforeEachpublic void getClient() {client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.200.130:9200")));}//关闭客户端@AfterEachvoid colseClient() throws IOException {client.close();}
具体操作索引库与文档
步骤为:1.创建请求对象
2.添加请求参数
3.发送请求,处理结果
例1:创建索引库/*创建索引库,索引库操作都是 client.indices().xxx*/@Testvoid testcreate() throws IOException {//1.创建请求对象(参数为索引库名)CreateIndexRequest request = new CreateIndexRequest("hotel");//2.添加请求参数(参数,参数类型)request.source(HotelContants.MAPPING_TEMPLATE, XContentType.JSON);//3.发起请求,处理请求结果client.indices().create(request, RequestOptions.DEFAULT);}
例2:创建文档
//创建文档 client.xxx@Testvoid testcreate() throws IOException {//1.根据ID在mysql中查询出字段Hotel hotel = hotelService.getById(38609l);//2.将字段封装成hotelDocHotelDoc hotelDoc = new HotelDoc(hotel);//3.将hotelDoc转化成JSON格式(FastJson)String json = JSON.toJSONString(hotelDoc);//4.创建请求对象(ID如果不加会默认添加)IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());//5.准备请求参数(一般都是request.source(json参数,参数格式))request.source(json, XContentType.JSON);//6.发送请求,处理结果client.index(request, RequestOptions.DEFAULT);}

若有收获,就点个赞吧
0 人点赞
