1. 主从复制概述
1.1 主从复制的作用
主从同步设计不仅可以提高数据库的吞吐量,还有以下 3 个方面的作用。
第1个作用:读写分离。
第2个作用:数据备份。
第3个作用:具有高可用性。
1.2 主从复制的原理
实际上主从同步的原理就是基于 binlog 进行数据同步的。在主从复制过程中,会基于 3 个线程来操作,一个主库线程,两个从库线程。
二进制日志转储线程(Binlog dump thread)是一个主库线程。当从库线程连接的时候, 主库可以将二进制日志发送给从库,当主库读取事件(Event)的时候,会在 Binlog 上加锁,读取完成之后,再将锁释放掉。
从库 I/O 线程会连接到主库,向主库发送请求更新 Binlog。这时从库的 I/O 线程就可以读取到主库的二进制日志转储线程发送的 Binlog 更新部分,并且拷贝到本地的中继日志 (Relay log)。
从库 SQL 线程会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
1.3 数据一致性问题
进行主从同步的内容是二进制日志,它是一个文件,在进行网络传输的过程中就一定会存在主从延迟(比如 500ms),这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的数据不一致性问题。
主备延迟最直接的表现是,从库消费中继日志(relay log)的速度,比主库生产binlog的速度要慢。
造成原因:
1、从库的机器性能比主库要差
2、从库的压力大
3、大事务的执行
方法 1:异步复制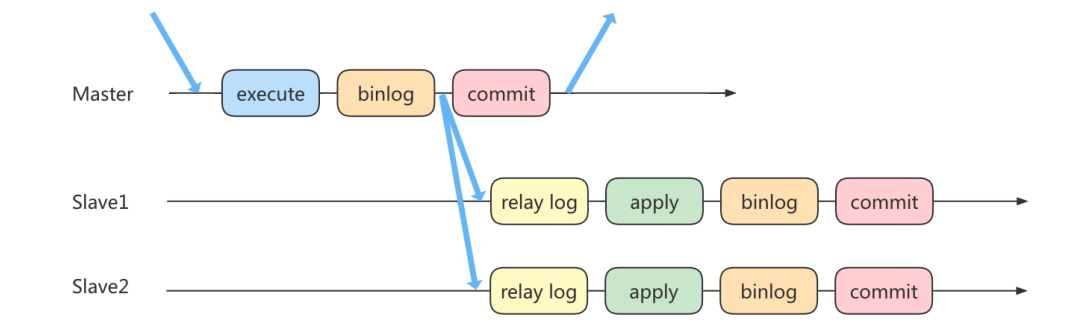
方法 2:半同步复制
一个从库发送ack给主库后主库再返回给客户端。
方法 3:组复制
首先我们将多个节点共同组成一个复制组,在执行读写(RW)事务的时候,需要通过一致性协议层(Consensus 层)的同意,也就是读写事务想要进行提交,必须要经过组里“大多数人”(对应 Node 节点)的同意,大多数指的是同意的节点数量需要大于 (N/2+1),这样才可以进行提交,而不是原发起方一个说了算。而针对只读(RO)事务则不需要经过组内同意,直接 COMMIT 即可。
2、读写分离
2.2 读写分离概述
在单台mysql实例的情况下,所有的读写操作都集中在这一个实例上。当读压力太大,单台mysql实例扛不住时,此时DBA一般会将数据库配置成集群,一个master(主库),多个slave(从库),master将数据通过binlog的方式同步给slave,可以将slave节点的数据理解为master节点数据的全量备份。
从应用的角度来说,需要对读(select、show、explain等)、写(insert、update、delete等)操作进行区分。如果是写操作,就走主库,主库会将数据同步给从库;之后有读操作,就走从库,从多个slave中选择一个,查询数据。上述流程如下图所示:
读写分离的优点:
- 避免单点故障。
负载均衡,读能力水平扩展。通过配置多个slave节点,可以有效的避免过大的访问量对单个库造成的压力。
2.2 读写分离的挑战
对sql类型进行判断。如果是select等读请求,就走从库,如果是insert、update、delete等写请求,就走主库。可以通过路由策略解决这个问题。
- 主从数据同步延迟问题。因为数据是从master节点通过网络同步给多个slave节点,因此必然存在延迟。因此有可能出现我们在master节点中已经插入了数据,但是从slave节点却读取不到的问题。对于一些强一致性的业务场景,要求插入后必须能读取到,因此对于这种情况,我们需要提供一种方式,让读请求也可以走主库,而主库上的数据必然是最新的。
- 事务问题。如果一个事务中同时包含了读请求(如select)和写请求(如insert),如果读请求走从库,写请求走主库,由于跨了多个库,那么jdbc本地事务已经无法控制,属于分布式事务的范畴。而分布式事务非常复杂且效率较低。因此对于读写分离,目前主流的做法是,事务中的所有sql统一都走主库,由于只涉及到一个库,jdbc本地事务就可以搞定。
- 高可用问题。主要包括:
- 新增slave节点:如果新增slave节点,应用应该感知到,可以将读请求转发到新的slave节点上。
- slave宕机或下线:如果其中某个slave节点挂了/或者下线了,应该对其进行隔离,那么之后的读请求,应用将其转发到正常工作的slave节点上。
master宕机:需要进行主从切换,将其中某个slave提升为master,应用之后将写操作转到新的master节点上。
2.3 数据库中间件设计方案
典型的数据库中间件设计方案有2种:服务端代理(proxy:代理数据库)、客户端代理(datasource:代理数据源)。下图演示了这两种方案的架构:

可以看到不论是代理数据库还是代理数据源,底层都操作了多个数据库实例。不同的是:服务端代理(proxy:代理数据库)中:
我们独立部署一个代理服务,这个代理服务背后管理多个数据库实例。而在应用中,我们通过一个普通的数据源(c3p0、druid、dbcp等)与代理服务器建立连接,所有的sql操作语句都是发送给这个代理,由这个代理去操作底层数据库,得到结果并返回给应用。在这种方案下,分库分表和读写分离的逻辑对开发人员是完全透明的。
- 客户端代理(datasource:代理数据源):
应用程序需要使用一个特定的数据源,其作用是代理,内部管理了多个普通的数据源(c3p0、druid、dbcp等),每个普通数据源各自与不同的库建立连接。应用程序产生的sql交给数据源代理进行处理,数据源内部对sql进行必要的操作,如sql改写等,然后交给各个普通的数据源去执行,将得到的结果进行合并,返回给应用。数据源代理通常也实现了JDBC规范定义的API,因此能够直接与orm框架整合。在这种方案下,用户的代码需要修改,使用这个代理的数据源,而不是直接使用c3p0、druid、dbcp这样的连接池。
数据库代理
目前的实现方案有:阿里巴巴开源的cobar,mycat团队在cobar基础上开发的mycat,mysql官方提供的mysql-proxy,奇虎360在mysql-proxy基础开发的atlas。目前除了mycat,其他几个项目基本已经没有维护。
优点:多语言支持。也就是说,不论你用的php、java或是其他语言,都可以支持。原因在于数据库代理本身就实现了mysql的通信协议,你可以就将其看成一个mysql 服务器。mysql官方团队为不同语言提供了不同的客户端驱动,如java语言的mysql-connector-java,python语言的mysql-connector-python等等。因此不同语言的开发者都可以使用mysql官方提供的对应的驱动来与这个代理服务器建通信。
缺点:实现复杂。因为代理服务器需要实现mysql服务端的通信协议,因此实现难度较大。延迟较高。
数据源代理
目前的实现方案有:阿里巴巴开源的tddl,大众点评开源的zebra,当当网开源的sharding-jdbc。需要注意的是tddl的开源版本只有读写分离功能,没有分库分表,且开源版本已经不再维护。大众点评的zebra开源版本代码已经很久更新,基本上处于停滞的状态。当当网的sharding-jdbc目前算是做的比较好的,代码时有更新,文档资料比较全。
优点:更加轻量,可以与任何orm框架整合。这种方案不需要实现mysql的通信协议,因为底层管理的普通数据源,可以直接通过mysql-connector-java驱动与mysql服务器进行通信,因此实现相对简单。延迟较低。
缺点:仅支持某一种语言。例如tddl、zebra、sharding-jdbc都是使用java语言开发,因此对于使用其他语言的用户,就无法使用这些中间件。版本升级困难,因为应用使用数据源代理就是引入一个jar包的依赖,在有多个应用都对某个版本的jar包产生依赖时,一旦这个版本有bug,所有的应用都需要升级。而数据库代理升级则相对容易,因为服务是单独部署的,只要升级这个代理服务器,所有连接到这个代理的应用自然也就相当于都升级了。
3、分库分表
3.1 分库分表概述
读写分离,主要是为了数据库读能力的水平扩展。而分库分表则是为了写能力的水平扩展。
一旦业务表中的数据量大了,从维护和性能角度来看,无论是任何的 CRUD 操作,对于数据库而言都是一件极其耗费资源的事情。即便设置了索引, 仍然无法掩盖因为数据量过大从而导致的数据库性能下降的事实 ,这个时候就该对数据库进行 水平分区 (sharding,即分库分表 ),将原本一张表维护的海量数据分配给 N 个子表进行存储和维护。
水平分表从具体实现上又可以分为3种:只分表、只分库、分库分表,下图展示了这三种情况:
只分表:将db库中的user表拆分为2个分表,user_0和user_1,这两个表还位于同一个库中。
只分库:将db库拆分为db_0和db_1两个库,同时在db_0和db_1库中各自新建一个user表,db_0.user表和db_1.user表中各自只存原来的db.user表中的部分数据。
分库分表:将db库拆分为db_0和db_1两个库,db_0中包含user_0、user_1两个分表,db_1中包含user_2、user_3两个分表。
下图演示了在分库分表的情况下,数据是如何拆分的:假设db库的user表中原来有4000W条数据,现在将db库拆分为2个分库db_0和db_1,user表拆分为user_0、user_1、user_2、user_3四个分表,每个分表存储1000W条数据。


分库分表的优点:
分库的好处:
降低单台机器的负载压力,提升写入性能
分表的好处:
提高数据操作的效率。举个例子说明,比如user表中现在有4000w条数据,此时我们需要在这个表中增加(insert)一条新的数据,insert完毕后,数据库会针对这张表重新建立索引,4000w行数据建立索引的系统开销还是不容忽视的。但是反过来,假如我们将这个表分成4 个table呢,从user_0一直到user_3,4000w行数据平均下来,每个子表里边就只有1000W行数据,这时候我们向一张 只有1000W行数据的table中insert数据后建立索引的时间就会下降,从而提高DB的运行时效率,提高了DB的并发量。除了提高写的效率,更重要的是提高读的效率,提高查询的性能。当然分表的好处还不止这些,还有诸如写操作的锁操作等,都会带来很多显然的好处。
3.2 分库分表挑战
分库分表的挑战主要体现在4个方面:基本的数据库增删改功能,分布式id,分布式事务,动态扩容,下面逐一进行讲述。
3.2.1 基本的数据库增删改功能
对于开发人员而言,虽然分库分表的,但是其还是希望能和单库单表那样的去操作数据库。例如我们要批量插入四条用户记录,并且希望根据用户的id字段,确定这条记录插入哪个库的哪张表。例如1号记录插入user_1表,2号记录插入user_2表,3号记录插入user_3表,4号记录插入user_0表,以此类推。sql如下所示:
insert into user(id,name) values (1,”tianshouzhi”),(2,”huhuamin”), (3,”wanghanao”),(4,”luyang”)
这样的sql明显是无法执行的,因为我们已经对库和表进行了拆分,这种sql语法只能操作mysql的单个库和单个表。所以必须将sql改成4条如下所示,然后分别到每个库上去执行。
insert into user_1(id,name) values (1,”tianshouzhi”)insert into user_2(id,name) values (2,”huhuamin”)insert into user_3(id,name) values (3,”wanghanao”)insert into user_0(id,name) values (4,”luyang”)
具体流程可以用下图进行描述:
解释如下:
- sql解析:首先对sql进行解析,得到需要插入的四条记录的id字段的值分别为1,2,3,4
- sql路由:sql路由包括库路由和表路由。库路由用于确定这条记录应该插入哪个库,表路由用于确定这条记录应该插入哪个表。
- sql改写:上述批量插入的语法将会在 每个库中都插入四条记录,明显是不合适的,因此需要对sql进行改写,每个库只插入一条记录。
- sql执行:一条sql经过改写后变成了多条sql,为了提升效率应该并发的到不同的库上去执行,而不是按照顺序逐一执行
- 结果集合并:每个sql执行之后,都会有一个执行结果,我们需要对分库分表的结果集进行合并,从而得到一个完整的结果。
3.2.2 分布式id
在分库分表后,我们不能再使用mysql的自增主键。因为在插入记录的时候,不同的库生成的记录的自增id可能会出现冲突。因此需要有一个全局的id生成器。关于分布式id的生成,可以使用美团的Leaf组件。
3.2.3 分布式事务
分布式事务是分库分表绕不过去的一个坎,因此涉及到了同时更新多个数据库。例如上面的批量插入记录到四个不同的库,如何保证要么同时成功,要么同时失败。关于分布式事务,mysql支持XA事务,但是效率较低。柔性事务是目前比较主流的方案,柔性事务包括:最大努力通知型、可靠消息最终一致性方案以及TCC两阶段提交。但是无论XA事务还是柔性事务,实现起来都是非常复杂的。
3.2.4 动态扩容
动态扩容指的是增加分库分表的数量。
例如原来的user表拆分到2个库的四张表上。现在我们希望将分库的数量变为4个,分表的数量变为8个。这种情况下一般要伴随着数据迁移。例如在4张表的情况下,id为7的记录,7%4=3,因此这条记录位于user_3这张表上。但是现在分表的数量变为了8个,而7%8=7,而user_7这张表上根本就没有id=7的这条记录,因此如果不进行数据迁移的话,就会出现记录找不到的情况。
3.2.5 数据迁移
对于新的应用,如果预估到未来数据量比较大,可以提前进行分库分表。但是对于一些老的应用,单表数据量已经比较大了,这个时候就涉及到数据迁移的过程。
3.3 路由策略
哈希分表:
range分表:
3.4 预估分片数量
分库:
分库主要关注的是在写能力上的扩展性,评估依据主要参考单库内数据容量和连接数。
计算公式:分库数量 =(3到5年内的存储容量)/单个库建议存储容量(单个库建议存储容量< 500G)
分表:
分表数量预估时需要一次将表数量建够,避免后续需要对分表进行扩容的情况。分表扩容往往伴随数据的重新分配,代价极大
计算公式:分表数量=(未来3到5年内总共的记录行数)/单张表建议记录行数(单张表建议记录行数=1000万)分表数量也不宜过多,分表过多往往需要拆分出更多SQL影响性能。此外分表数量建议是2的幂次方。
3.5 分表键
分表键:路由的时候根据这个分表键选择路由到哪个库哪个表去。
多维度数据冗余同步:
优点:使用场景比较广泛,逻辑简单。
缺点:冗余一套全量数据,占用磁盘空间,需要一直进行数据同步,存在维护成本,数据同步存在一定延迟,不支持对延迟要求较高的业务场景。
主维度:即数据的写入维度,辅维度数据通过主维度进行实时同步,用户写入数据时必须通过主维度进行计算,原则上不允许直接写入辅维度。
辅维度:数据的查询维度,数据的来源是通过主维度进行数据同步。
3.6 热点数据分库分表
问题:北上广深杭等大城市,数据量和访问量明显超过其他城市。分表后单表的数据量和访问流量过高,仍然达到了分表的要求。
解决思路:
1.热点数据隔离
资源隔离:热点库表从原库表中单独拆分,独立部署。
冷热数据隔离:通过数据归档等方式,避免冷数据影响热点数据。
2.热点数据分散
数据/操作分散:对于热点数据可以引入其他辅助字段进行进一步分表,将热点单表数据分散到多表中。
3.增加缓存
对于热点数据相关逻辑进行整体优化,在数据库上层引入缓存,提升系统整体性能。
3.7 逻辑库、逻辑表、物理库、物理表

最底层是实际存在的物理库/表,上两层则是逻辑上的库/表,数据库中间件的路由实际是针对逻辑库/表的

若有收获,就点个赞吧
0 人点赞
