聚焦爬虫:
爬取页面中指定的页面类容
—指定url
—发起请求
—获取相应数据
—数据解析
—持久化存储
数据解析分类:
数据解析原理概述:
—解析的局部文本内容都会在标签之间或者标签对应的属性进行存储
—进行指定标签的定位
—变迁或者标签对应的属性中存储的数据值进行提取(解析)
1.爬取糗事百科中糗图面板下所有的糗图图片

如何提取出img的数据
使用聚焦爬虫将页面中所有的糗图进行解析、提取
ex=’
符号.*? 非贪婪,遇到开始和结束就进行截取,因此截取多次符合的结果,中间没有字符也会被截取
符号(.*?) 非贪婪,与上面一样,只是与上面的相比多了一个括号,只保留括号的内容
str = ‘aabbabaabbaa’
print(re.findall(r’a.*?b’,str))
#[‘aab’, ‘ab’, ‘aab’]
print(re.findall(r’a(.*?)b’,str))
#[‘a’, ‘’, ‘a’]

在获取到图片序列后会发现缺少图片url的头部信息,拼接出一个完整的图片地址(url),在前加入“https:”
此代码只有第一页的糗图图集
此为改进方式,将后面代码都缩进循环内
2.bs4进行数据解析
数据解析的原理:
bs4数据解析的原理:
—实例化一个BeautifulSoup对象,并将页面源码数据加载到该对象当中
—通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位或者数据提取
如何实例化BeautifulSoup对象:
—from bs4 import BeautifulSoup
—对象实例化:
-1.将本地的html文档各种的数据加载到该对象中
fp = open(‘./sogou.html’,‘r’,encoding=‘utf-8’) #本地html文件任意选择
soup=BeautifulSoup(fp,‘lxml’)
print(soup)
-2.将或联网获取的页面源码加载到该对象中
page_text = response.text
soup = BeautifulSoup(page_text,’lxml’)
—提供的用于数据解析的方法和属性:(源代码day-03 bs4解析基础)
-soup.tagName:返回的是文档中第一次出现的TagName标签
例如下图
-soup.find():
—find(‘tagName’):等同于soup.tagName
—属性定位:soup.find(’tagName’,class_/id/attr=’targetName’)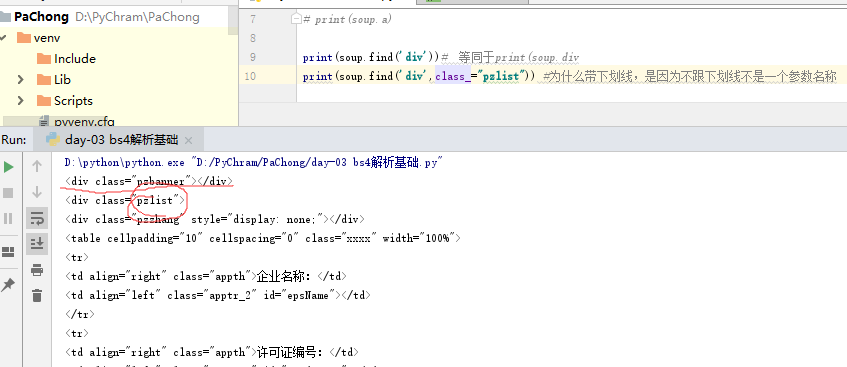
-soup.find_all(‘tagName’):返回符合要求的所有标签,返回列表
-select:
1.select(‘某种选择器(id,class,标签。。。)’),返回一个列表
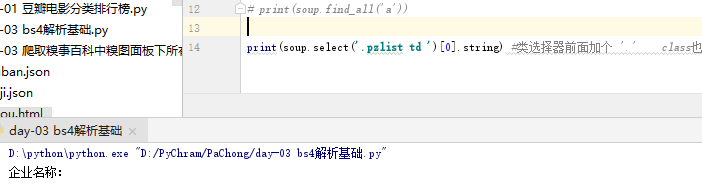
print(soup.select(‘.pzlist’))#类选择器前面加个 ‘.’ class也就是类,选择pzlist类就在前面加一点
若想要更深入的信息,‘.pzlist>>‘即可 一个’>’表示一个层级;如果想直接跳过多个层级,用空格分隔
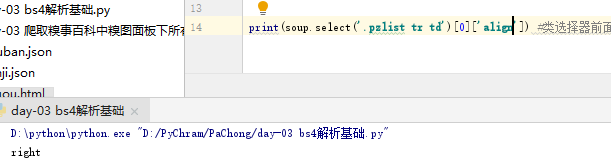
-获取标签之间的文本数据:
—soup.a.text/string/get_text()
—text/get_text()可以获取某一标签内所有的文本内容
—string只可以获取标签下直系的文本内容
爬取三国演义小说所有的章节和章节内容
https://www.shicimingju.com/book/sanguoyanyi.html
对首页的页面数据进行爬取
获取li标签内a标签
注意:pagetext = requests.get(url=url,headers=headers).text.encode(‘iso-8859-1’)#中文乱码在text后加encode(‘iso-8859-1’)_
最终代码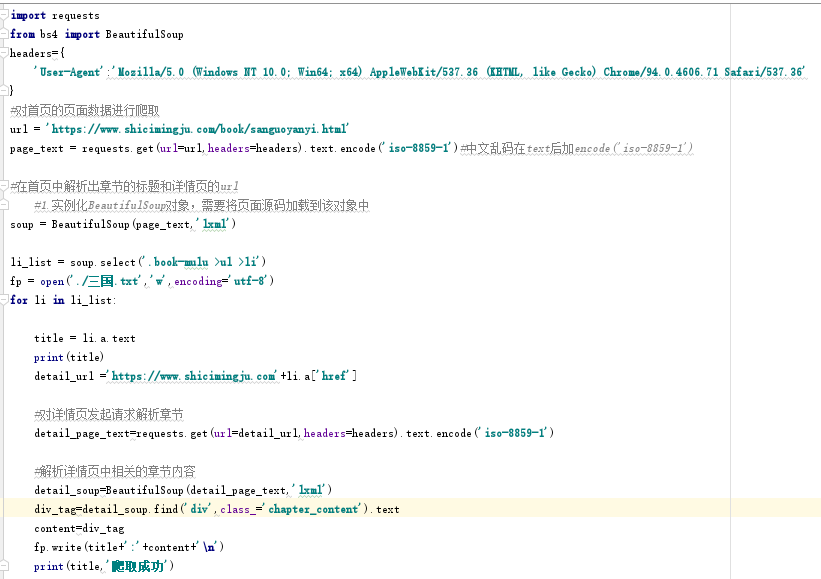
xpath解析:
最常用且最高效的一种解析方式。通用性
—xpath解析原理:
1.实例化一个etree的对象,并且需要将被解析的页面源码数据加载到该对象当中
2.调用etree对象中的xpath方法结合spath表达式实现标签的定位和内容的捕获
—如何实例化一个etree对象(from lxml import etree)
1.将本地的html文档中的源码数据加载到etree对象中:
etree.pasre(filePath)
2.可以将从互联网获取的源码数据加载到该对象当中:
etree.HTML(‘page_text’)
—xpath(‘xpath表达式’)
在练习lxml数据解析的时候,用parse方法加载本地的html文件时出现如下错误
lxml.etree.XMLSyntaxError: Entity ‘copy’ not defined, line 61, column 38
原因:
html代码书写不规范,不符合xml解析器的使用规范
解决的办法:
使用parse方法的parser参数:
parser = etree.HTMLParser(encoding=“utf-8”)
tree = etree.parse(‘huazhuang.html’,parser=parser)
如果body中有多(例如三组)组div,将返回多(三组)组element,想要第几个标签就写入【标签顺序】,要注意的是他的标签其实是从 1 开始的
如:tree.xpath(‘/div[@class=’你所需要的class的标签名’]//li[3]/a’)
也可以tree.xpath(‘/div[@class=’你所需要的class的标签名’]//li[3]//text()’)
属性定位:
— /:表示的是从根节点开始定位,表示的是一层级
— //:表示的是多个层级。可以从任意位置开始定位
— /text() 获取标签中之息的文本内容
— //text()获取标签中非直系的文本内容(所有文本内容)
取属性值:
tree.xpath(‘/div[@class=’你所需要的class的标签名’]/img/@src’)
/@attrName
xpath返回的是一个列表

若有收获,就点个赞吧
0 人点赞
