1.什么是爬虫:
通过编写程序,模拟浏览器上网,让其去互联网上抓取数据的过程。
抓数据的两种选择:1.将互联网上某一张完整的页面对应的数据
2.一张页面指定的、特定的、局部的数据
2.爬虫的价值:

—实际应用
—就业
3.爬虫是否合法?
1.在法律中是不被禁止
2.具有违法风险
—爬虫干扰被访问网站的正常运营
—抓去了受到法律保护的特定类型的数据或信息
4.爬虫在使用场景的分类
—通用爬虫
抓取系统重要组成部分,抓取的是互联网一整张页面数据
—聚焦爬虫
建立在通用爬虫的基础之上,抓取的是页面中特定的局部内容
—增量式爬虫
检测网站中数据更新的情况,只会爬取网站中最新更新的数据
5.爬虫的矛与盾
反爬机制
门户网站可以通过制定相应的策略或技术手段,防止爬虫程序进行数据的爬取
反反爬机制
爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,宠儿可以获取门户网站的相关数据
robots.txt协议
君子协议:规定了网站中哪些数据可以被爬哪些不可以被爬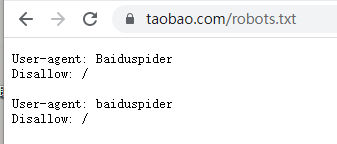
5.http协议
—概念:服务器和客户端进行数据交互的一种形式
常用头信息
— User-Agent:请求载体的身份标识
— Connection:请求完毕后,是断开链接还是保持链接
常用响应头信息
— Content-Type:服务器响应客户端的数据类型
6.https协议
--安全的超文本传输协议<br />**加密方式**<br />**--对称密钥加密**<br />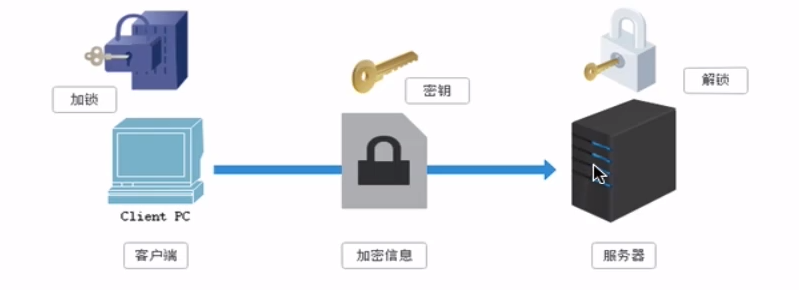
—非对称密钥加密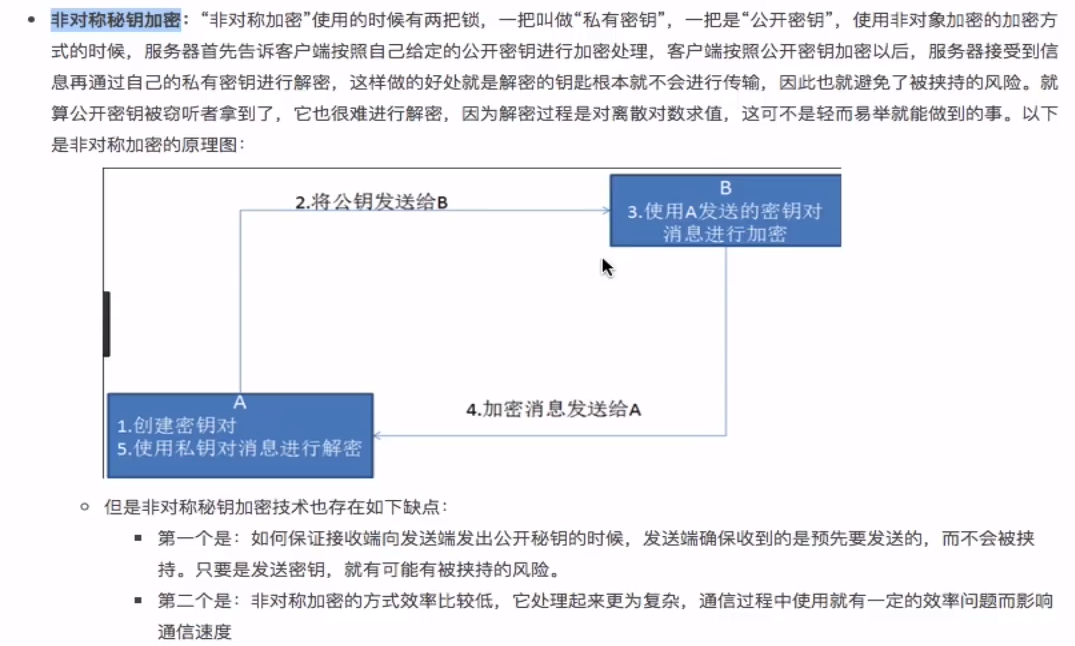
公钥(加密方式)加密,私钥(解密方式)解密
—证书密钥加密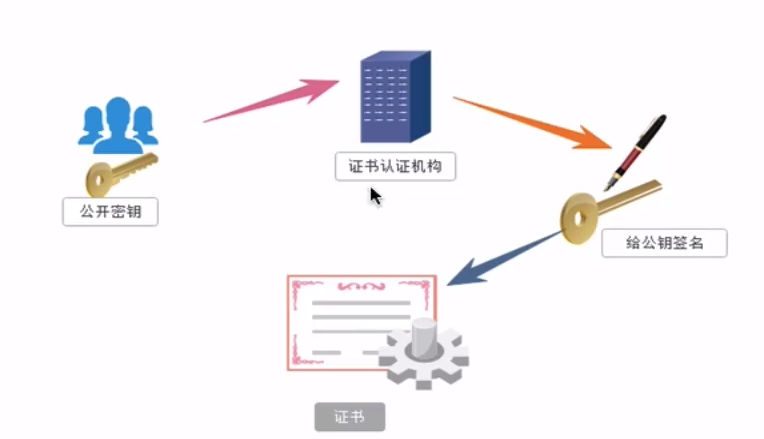
7.request模块
网络请求的两个模块
—urllib模块(相对来说有点老了)
—request模块(本次课程重点)
python中原生的一款基于网络请求模块,功能强大,简单便捷,效率极高
作用:模拟浏览器发请求
url:“URL是Uniform Resource Location的缩写,译为“统一资源定位符”。通俗地说,URL是Internet上用来描述信息资源的字符串,主要用在各种客户程序和服务器程序上,特别是著名的Mosaic。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。”
如何使用:(request模块的编码流程)
—指定url
—发起请求
—获取响应数据
— 持久化存储
实战编码:
—需求:爬取搜狗首页的页面数据
提升题
网页采集器


破解百度翻译
AJAX请求:在抓包工具中network的XHR的sug内寻找
查看抓包工具后得知:post请求(携带了参数)
响应数据是一组json数据
获取UA以及请求类型(此次为post请求)
确定响应数据的类型
最终代码

若有收获,就点个赞吧
0 人点赞
