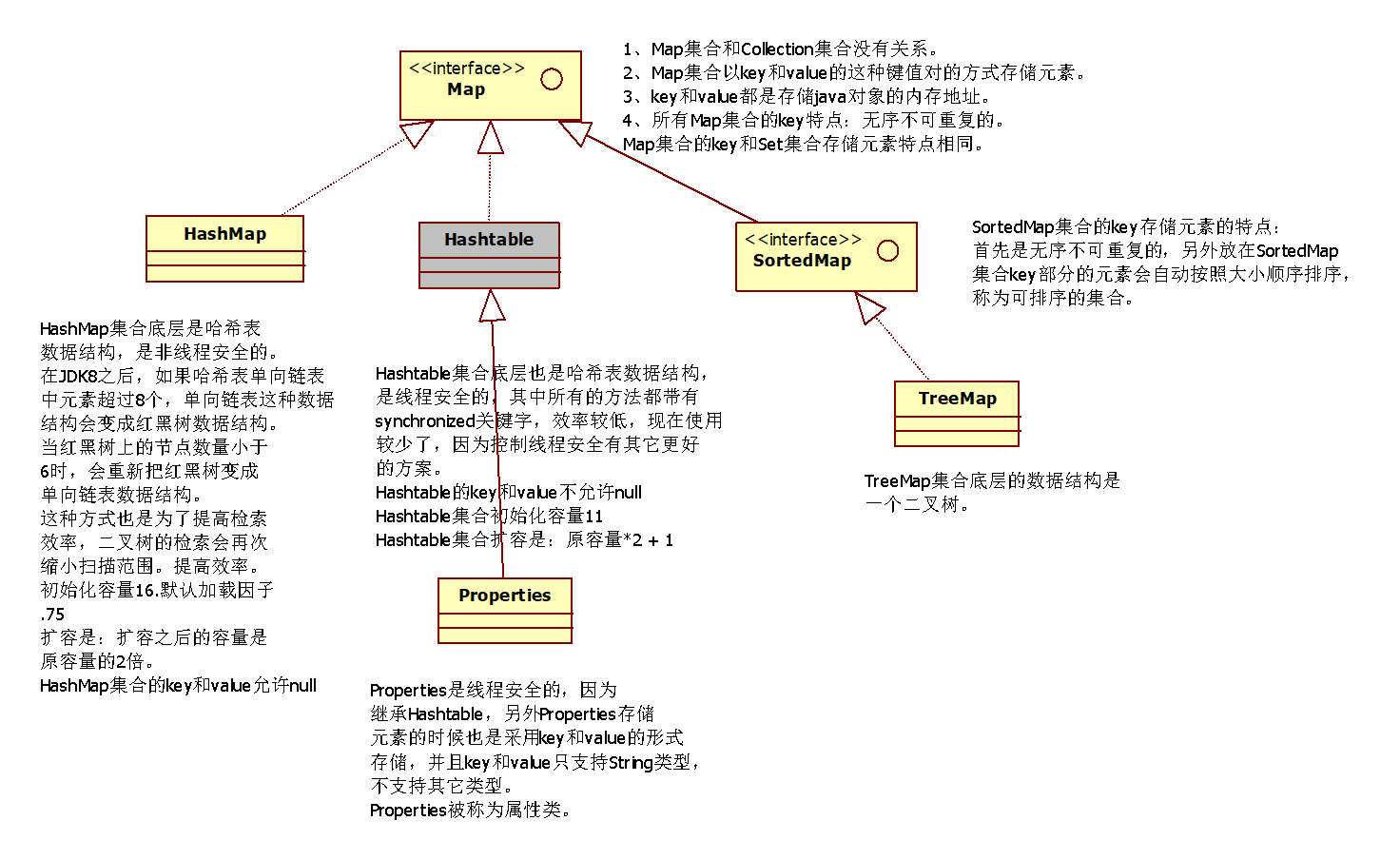
Map集合
https://www.bilibili.com/video/BV1Rx411876f?p=696
1.Map接口中常用方法。
public V put(K key, V value) : 把指定的键与指定的值添加到Map集合中,其中指定的键必须唯一,否则新添加的值会取代已有的值。
public void putAll(Map<? extends K, ? extends V> m):将Map集合中的所有映射关系复制到调用此方法的映射中。
public V remove(Object key) : 把指定的键所对应的键值对元素 在Map集合中删除,返回被删除元素的值。
public V get(Object key) 根据指定的键,在Map集合中获取对应的值,若指定的键不存在则返回null。
public boolean containsKey(Object key):判断Map集合中是否包含指定的键。
public boolean containsValue(Object value):判断Map集合中是否包含指定的值。
public Set
public Collection
public Set
2.遍历Map集合的三种方式
2.1.通过keySet()方法来遍历,此方法可以得到对应的key和value
public class MapTestSet { //使用keySet进行遍历 public static void main(String[] args) { Map
2.2通过EntrySet()方法来遍历,此方法可以获取到key-value键值对的集合
public class MapTestEntry { //使用EntrySet()方法进行遍历 public static void main(String[] args) { Map
2.3.通过map.values()方法只能获取其中值的集合
public class MapTestValues { // 通过map.getValues取map的值的集合(list集合) public static void main(String[] args) { Map
3、了解哈希表数据结构。
3.1 HashMap集合底层是哈希表/散列表的数据结构。
哈希表是一个数组和单向链表的结合体。
数组∶在查询方面效率很高,随机增删方面效率很低。
单向链表:在随机增删方面效率较高,在查询方面效率很低。
哈希表将以上的两种数据结构融合在一起,充分发挥它们各自的优点。
3.2 HashMap集合底层的源代码∶
public cLass HashMap{ //HashMap底层实际上就是一个数组。(一维数组) Node
哈希表/散列表∶一维数组,这个数组中每一个元素是一个单向链表。(数组和链表的结合体。)
3.3哈希表或者散列表数据结构
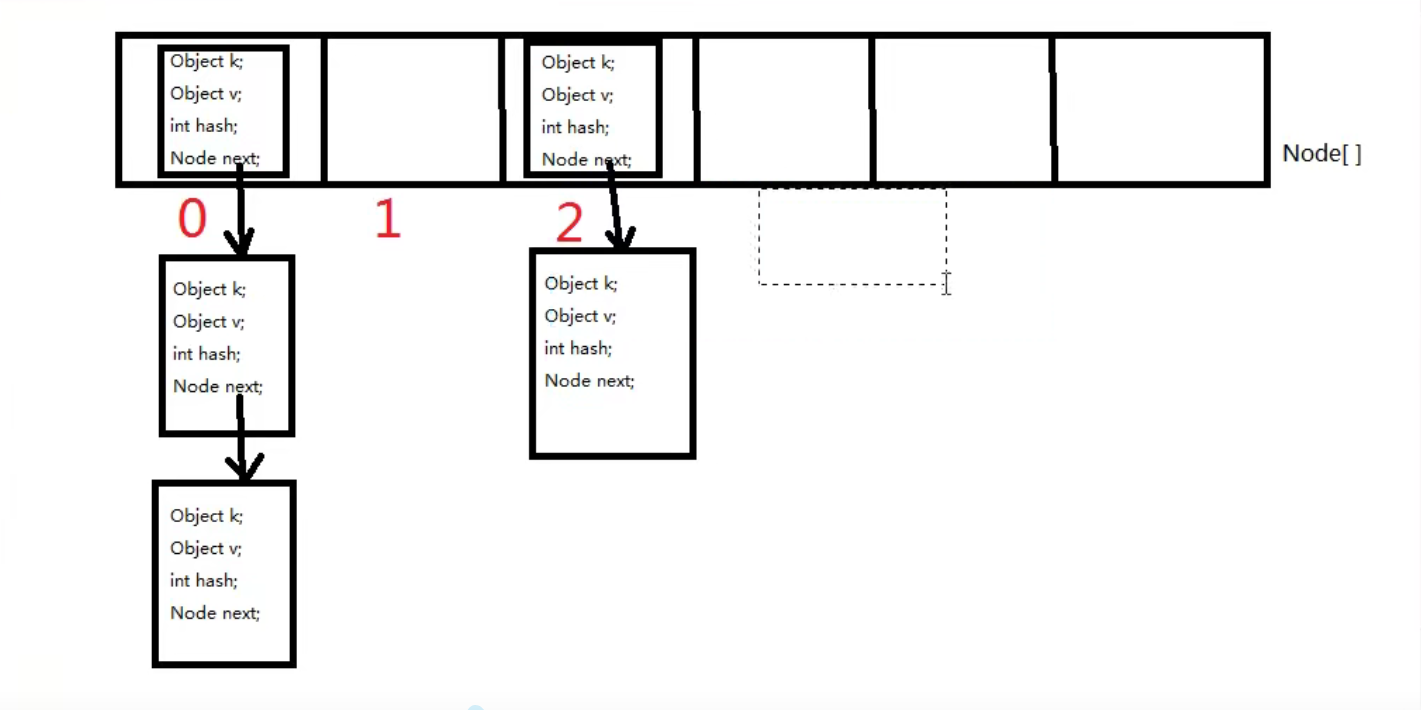
3.2.1 map.put(k,v)实现原理:
第—步∶先将k,v封装到Node对象当中。
第二步∶底层会调用k的hashCode(方法得出hash值,然后通过哈希函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上了。如果说下标对应的位置上有链表,此时会拿着k和链表上每一个节点中的k进行equals ,如果所有的equals方法返回都是false,那么这个新节点将会被添加到链表的末尾。如果其中有一个equals返回了true,那么这个节点的value将会被覆盖。
3.2.2 map.get(k)实现原理:
先调用k的hashCodel方法得出哈希值,通过哈希算法转换成数组下标,通过数组下标快速定位到某个位置上,如果这个位置上什么也没有,返回null。如果这个位置上有单向链表,那么会拿着参数k和单向链表上的每个节点中的k进行equals ,如果所有equals方法返回false,那么get方法返回null,只要其中有一个节点的k和参数k equals的时候返回true,那么此时这个节点的value就是我们要找的value , get方法最终返回这个要找的value。
3.2.3 为什么哈希表的随机增删,以及查询效率都很高?
3.2.4 hashmap为什么要重写key的hashCode()和equals()方法
假设一:假如不重写hashCode()和equals()方法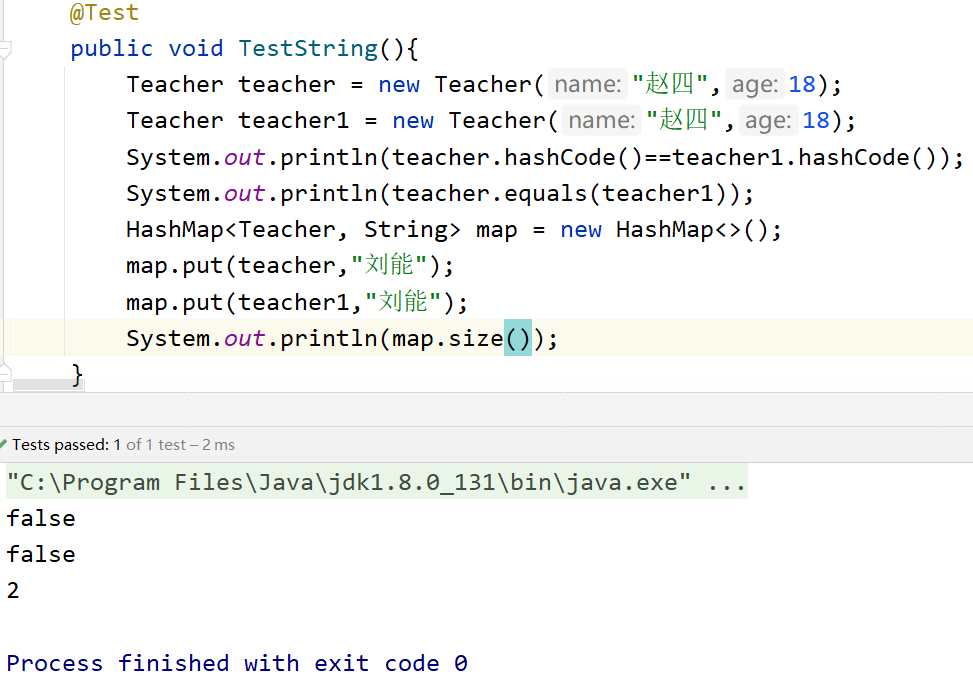
重写hashCode()和equals()后,以确保K在哈希表中具有可替代性
假设二:假设将所有的hashCode()方法返回值固定为某个值
若将所有的hashCode()方法返回值固定为某个值,那么会导致底层哈希表变成了纯单向链表。这种情况我们成为:散列分布不均匀。
假设三:将所有的hashCode()方法返回值都设定为不一样的值
这样的话导致底层哈希表就成为一维数组了,没有链表的概念了。也是散列分布不均匀。
注意:向map集合中存,以及从Map集合中取,都是先调用key的hashCode方法,然后再调用equals方法!
equals方法有可能调用,也有可能不调用。
拿put(k , v)举例,什么时候equals不会调用?
k.hashCode()方法返回哈希值,
哈希值经过哈希算法转换成数组下标。
数组下标位置上如果是null , equals不需要执行。拿get(k)举例,什么时候equals不会调用?
k .hashCode()方法返回哈希值,哈希值经过哈希算法转换成数组下标。
数组下标位置上如果是null , equals不需要执行。
JDK8之后哈希表的改进和扩容原理
HashMap集合底层是哈希表数据结构,是非线程安全的。在JDK8之后,如果哈希表单向链表中元素超过8个,单向链表这种数据结构会变成红黑树数据结构。
当红黑树上的节点数量小于6时,会重新把红黑树变成单向链表数据结构。
这种方式也是为了提高检索效率,二叉树的检索(使用二分法)会再次缩小扫描范围。提高效率。初始化容量16.默认加载因子.75
扩容是:扩容之后的容量是原容量的2倍。
HashMap集合的key和value允许null
HashMap的为啥用尾插法?
https://www.jianshu.com/p/0df1f25139e4
hashmap与hashtable的区别
Hashtable集合底层也是哈希表数据结构,是线程安全的其中所有的方法都带有synchronzed关建字,
效率较低,现在使用较少了,因为控制线程安全有其它更好的方案。
Hashtable的key,和value不允许null HashMap集合的key和value允许null
Hashtabe集合初始化容量11 hashmap初始化容量16.
Hashtable集合扩容是:原容量*2+1 hashmap扩容之后的容量是原容量的2倍。
Properties集合
Properties是线程安全的,因为继承Hashtable,另列外Properties存储元素的时候也是采用key和value的形式存储,并且key和value只支持strng类型,不支持其它类型。
Properties被称为属性类。

若有收获,就点个赞吧
0 人点赞
