面试梳理
JavaSE
1. 重写equals()方法比较, 为什么还有重写hashcode()方法?
* equals()底层先使用了 == 比较地址值, 所以重写可以提高比较时的效率
2. Java中锁的分类和介绍
# 1.乐观锁和悲观锁 --思想*乐观锁与悲观锁并不是特指某两种类型的锁,是一种的**概念或思想**, 主要是指看待并发同步的角度。乐观锁: 更新的时候会判断期间是否有数据更新, 基于CAS(Compare and Swap 比较并交换)实现.悲观锁: 每次在拿数据的时候都会上锁. synchronized关键字的实现就是悲观锁.乐观锁在Java中的使用,是无锁编程,常常采用的是CAS算法,典型的例子就是原子类,通过CAS自旋实现原子操作的更新。 还可使用版本号, mysql的乐观锁实现.悲观锁适合写操作非常多的场景,乐观锁适合读操作非常多的场景,不加锁会带来大量的性能提升。# 2.独享锁/共享锁 --概念独享锁是指该锁一次只能被一个线程所持有。共享锁是指该锁可被多个线程所持有。共享锁一般用与读的操作, 可读不可写.对于Synchronized而言,当然是独享锁。# 3.互斥锁/读写锁 --实现* 独享锁/共享锁就是一种广义的说法,互斥锁/读写锁就是具体的实现。互斥锁在Java中的具体实现就是ReentrantLock。读写锁在Java中的具体实现就是ReadWriteLock。# 4.可重入锁* 可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。可重入锁的一个好处是可一定程度避免死锁。Synchronized 和 ReentrantLock 都是可重入锁。# 5.公平锁/非公平锁公平锁是指多个线程按照申请锁的顺序来获取锁。非公平锁在释放锁的时候, 会检查是否有线程申请锁, 如果没有, 唤醒等待队列的线程, 就变成类似公平锁. 如果有, 交给最近申请的线程, 就是不公平。Synchronized是一种非公平锁。# 6.分段锁 --一种锁的设计*分段锁其实是一种锁的设计,并不是具体的一种锁。ConcurrentHashMap 而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在哪一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。# 7.偏向锁/轻量级锁/重量级锁 --锁的状态* 三种锁是指锁的状态,并且是针对Synchronized。在Java5通过引入锁升级的机制来实现高效Synchronized。偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让他申请的线程进入阻塞,性能降低。# 8.自旋锁在Java中,自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
3. CAS和ABA是什么?

* CAS是Java乐观锁的一种实现机制,在Java并发包中,大部分类就是通过CAS机制实现的线程安全,它不会阻塞线程,如果更改失败则可以自旋重试.CAS(V,A,B)1:V表示内存中的地址2:A表示预期值3:B表示要修改的新值CAS的原理就是预期值A与内存中的值相比较,如果相同则将内存中的值改变成新值B。这样比较有两类:第一类:如果操作的是基本变量,则比较的是 值 是否相等。第二类:如果操作的是对象的引用,则比较的是对象在 内存的地址 是否相等。* ABA问题见上图所示.即在cas比较过程中, 经历了多次修改操作后, 变量值又等于A.解决方案: 添加一个标记来记录更改.(时间戳)1:AtomicMarkableReference 利用一个boolean类型的标记来记录,只能记录它改变 过,不能记录改变的次数2:AtomicStampedReference 利用一个int类型的标记来记录,它能够记录改变的次数。
4. HashMap相关
# 1.71.数据结构: 数组+链表2.扩容: 默认因子0.75, 当元素个数>=12, 且当前插入的元素发生hash冲突(即该桶已有元素), 在插入前扩容.3.插入方式:头插法,并发情况下可能出现死循环.# 1.81.数据结构: 数组+链表+红黑树- 链表长度>8, 升级成红黑树- 集合扩容后链表长度<=6, 降级为链表.- 删除红黑树元素后,没有左儿子左孙子和右儿子, 降低为链表- 基本很少出现红黑树, 因为二次哈希计算插入位置,降低冲突的可能.2.扩容: 默认因子0.75, 当元素个数>12, 即插入第13个元素后扩容, 先插入后扩容.3.插入方式:尾插法, 所以可以先插入后扩容.
5. IO的类别
- BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。- NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。- AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
6. 线程池常用种类以及7大参数
# 常用种类1. Executors.newCachedThreadPool();创建一个可缓存线程池2. Executors.newFixedThreadPool(3);创建一个指定工作线程数量的线程池3. Executors.newSingleThreadExecutor();创建一个单线程化的Executor4. Executors.newScheduledThreadPool(5);创建一个定长的线程池,而且支持定时的以及周期性的任务执行# 异步线程池.- 七个核心参数.corePoolSize: 线程池中常驻核心线程数.maximumPoolSize: 同时执行的最大线程数.keepAliveTime: 多余的空闲线程存活时间.unit: keepAliveTime的时间单位,默认为秒second.workQueue: 缓冲队列数,被提交但尚未执行的任务.线程工厂: 生成线程池中的工作线程的线程工厂,用于创建线程,一般为默认线程工厂.handler: 线程池线程已满,且任务队列也到到最大时,对于新加入任务的拒绝策略.- 拒绝策略.1. 拒绝新加入的任务,并将其丢弃,抛出异常. --默认策略.2. 拒绝新加入的任务,并将其丢弃,不抛出异常.3. 让调用该任务的线程来执行该任务.4. 丢弃任务队列中最早的任务, 将新加入的任务添加到队列末尾.
7. volatile了解过么?可以保证线程安全么?
不能保证线程安全. 无法保证保证原子性.原子性, 可见性, 有序性可以使用Atomic.
Redis
1.Redis缓存穿透, 缓存击穿, 缓存雪崩区别?
# 缓存穿透指用户查询到redis缓存和mysql数据库都没有的数据, 如果用户是恶意攻击者, 不断的发起请求, 可能会导致数据库压力过大.解决: 1. 布隆过滤器 2. 向redis缓存一个空值, 设置过期时间# 缓存击穿缓存击穿:大量的请求同时查询一个 key 时,此时这个 key 正好失效了,就会导致大量的请求都落到数据库。缓存击穿是查询缓存中失效的 key,而缓存穿透是查询不存在的 key。解决方法:加分布式锁,第一个请求的线程可以拿到锁,拿到锁的线程查询到了数据之后设置缓存,其他的线程获取锁失败会等待50ms然后重新到缓存取数据,这样便可以避免大量的请求落到数据库。# 缓存雪崩缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重挂掉。解决方法:在原有的失效时间基础上增加一个随机值,使得过期时间分散一些。
2. 分布式锁实现方案 —redission
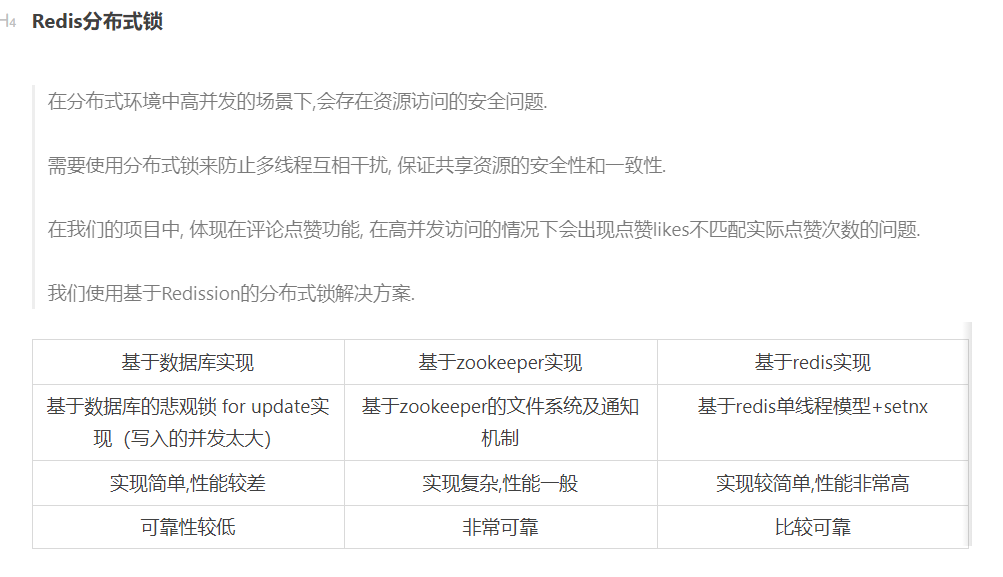
# 原理:传统的加锁方式,如sync同步锁, 其加锁是基于JVM来锁定, 只能保证同一台服务器上 多线程访问的安全. 当有来自不同服务器的并发访问发生时, 由于服务器的JVM相互独立, 锁对象也相互独立,导致加锁失败, 可能会出现安全问题.Redission分布式锁, 它的锁对象存储在redis数据库中, redis集群之间数据同步,所有的线程共用一把锁.当线程去获取锁,获取成功: 执行lua脚本,保存数据到redis数据库。获取失败: 一直通过while循环尝试获取锁,获取成功后,执行lua脚本,保存数据到redis# 如何使用:1. 获取Rlock锁对象 RLock lock = redissonClient.getLock(key)2. 上锁 lock.lock() 这是个重载的方法, 有不同的参数, 可以设定锁的有效时间.3. 尝试获取锁 lock.tryLock() 尝试获取锁,如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返回false. 方法重载:(等待时间, 锁有效时间, 时间单位)注: 在获取到锁后, 它自动上锁了, 不需要在调用.lock()方法4. 释放锁 lock.unlock() 建议写在finally中, 保证一定执行# WatchDog自动延期机制是什么:1. 假如一个线程获得锁后,服务器宕机了,在一定时间后这个锁会自动释放,可以设置锁的有效时间(默认30秒),防止死锁.2. 如果某一个线程任务执行的时间过长, 超过了锁的有效时间,就会启动一个watch dog后台线程,不断的延长锁key的生存时间.
3. Redis为什么这么快?
1. 基于内存, 没有磁盘IO上的开销2. 单线程实现(Redis6.0以前):Redis使用单个线程处理请求,避免了多个线程之间线程切换和锁资源争用的开销。3. IO多路复用模型4. 高效的数据结构:Redis 每种数据类型底层都做了优化
4. 内存淘汰策略
- volatile-lru:LRU(Least Recently Used),最近使用。利用LRU算法移除设置了过期时间的key- allkeys-lru:当内存不足以容纳新写入数据时,从数据集中移除最近最少使用的key- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰0- volatile-random:从已设置过期时间的数据集中任意选择数据淘汰- allkeys-random:从数据集中任意选择数据淘汰- no-eviction:禁止删除数据,当内存不足以容纳新写入数据时,新写入操作会报错- volatile-lfu:LFU,Least Frequently Used,最少使用,从已设置过期时间的数据集中挑选最不经常使用的数据淘汰。- allkeys-lfu:当内存不足以容纳新写入数据时,从数据集中移除最不经常使用的key。
5. Lua脚本 和 pipeline管道命令
1、Lua脚本在Redis中是原子执行的,执行过程中间不会插入其他命令。2、Lua脚本可以将多条命令一次性打包,有效地减少网络开销。pipeline是非原子性。pipeline命令中途异常退出,之前执行成功的命令不会回滚。近似原子性,打包多条语句一并顺序执行, 执行速度快.
Spring
1. springboot循环依赖
循环依赖就是两个类互相依赖,互相调用,例如:serviceA 中调用serviceB,serviceB中又调用serviceA,两个类,互相注入,互相调用。循环依赖的发生于你使用构造函数注入的时候,其他注入方式不会发生此问题,# 解决方案1.最好是重新设计你的程序,明显依赖比较乱,分层没有处理好。2.使用@Lazy注解: 第一种方法是标记@Lazy注解到你的构造函数的参数内,让Spring懒惰的初始化这个Bean,即给这个Bean创建一个代理,当真正使用到这个Bean时才会完全创建。3.使用setter注入
2. mysql隔离级别
读未提交 脏读 线程A读取到线程B未提交的数据 绝不允许读已提交 不可重复读 线程A前后读取一条数据, 中途线程B修改了数据 orcale默认可重复读 幻读 线程A去读取数据时, B将数插入或删除了数据 mysql默认可序列化 没有安全问题
技术框架概念
1. RPC框架
RPC 是一种技术思想而非一种规范或协议,常见 RPC 技术和框架有:应用级的服务框架:阿里的 Dubbo/Dubbox、Google gRPC、Spring Boot/Spring Cloud。远程通信协议:RMI、Socket、SOAP(HTTP XML)、REST(HTTP JSON)。通信框架:MINA 和 Netty。
2. ORM
ORM指的是对象(object)关系(Relation)映射(Mapping)的技术,对象-关系映射系统一般以中间件的形式存在,主要实现程序对象到关系数据库数据的映射。ORM模型的简单性简化了数据库查询过程,使用ORM查询工具,用户可以访问期望数据,而不必理解数据库的底层结构.JDBC ---封装>> Mybatis, Hibrnate

若有收获,就点个赞吧
0 人点赞
