- 使用的技术栈
- 1. 即时通信 —环信
- 2. 分布式日志技术
- 3. 数据库列式存储
- 4. 项目中哪些地方遇到了分布式事务问题
- 5. 消息队列中间件RabbitMq
- 6. 非关系型数据库之 —Redis
- 7. 非关系型数据库之 —MongoDb
- 8. 分布式事务 —Seata
- 9. 延时任务方案 —四种常见方案
- 10. 页面静态化之模板引擎 —Freemarker
- 11. 基于RPC的远程调用 —Dubbo
- 12. 消息队列中间件 —Kafka
- 13. 分布式文件存储 —fastDFS
- 14. alibaba旧类注册中心 —zookeeper
- 15. 连接数据库封装JDBC —hibrnate
- 16. alibaba连接数据库封装JDBC —Netty
- 17. 分库分表 —Sharding-JDBC
- 18. Websocket
- 19. Kubernetes —即k8s
- 开发bug:
- 面试题:
使用的技术栈
1. 即时通信 —环信

* 我开发过的项目在涉及到 用户之间的即时通信, 联系客服等功能时, 使用的是环信的 即时通讯云IM技术.应用场景:小程序社交, 单聊/群聊/聊天室, 私密社交, 直播互动等功能如上图.使用官方提供的ServerSDK.
2. 分布式日志技术

日志消息是基于http的协议发送到logstash中, http协议会占用微服务的性能,关于分布式日志的采集尽量采用异步的方式收集, ELK的数据采集 也支持基于redis 或 kafka来采集日志数据.需引入依赖, 其次修改logstash容器的配置, 修改配置文件logback.xml.
3. 数据库列式存储

#将原本每一行存储一条对象数据, 变为多行共同存储一个对象数据. POJO对象
4. 项目中哪些地方遇到了分布式事务问题
# 存在前提:1. 存在多服务之间的远程调用, 每个微服务使用独立的数据源.2. 对每个数据源进行了增删改操作.# 存在位置:1. shop模块中的 注册品牌功能.
5. 消息队列中间件RabbitMq

# MQ消息队列中间件,提供应用与应用之间的,安全可靠的消息传递方式.- 优点: 异步调用,降低服务于服务之间的耦合,提高的运行效率.对请求的流量进行控制,保护微服务的安全.通过消息持久化策略,保证消息的可靠性.# RabbitMQ支持的消息模式- Basic Queue 简单队列.publisher(生产者) -> queue(队列) -> consumer(消费者)生产者发消息给队列,消费者从队列中接收消息,队列与消费者是一对一的关系- Work Queue 工作对列.publ -> queue -> cons1,cons2...类似简单队列,但是队列和消费者是一对多的关系- 发布/订阅模型新增exchange(交换机)的角色,生产者发消息给交换机,交换机路由到queue,再由消费者消费- Fanout 广播模式.publ -> exchange -> queue1,queue2... -> cons1,cons2....交换机接收到消息后,会广播给所有绑定它的队列,每个队列都会收到消息.- Direct 订阅模式生产者发送消息的同时,需要指定routeingkey, 交换机只会把消息路由绑定指定routingkey的队列.默认消费方式是轮询. 会浪费性能,可以开启能者多劳的消费方式.spring.rabbitmq.listener.simple.prefetch: 1- Topic 通配符模式Topic类型的Exchange可以让队列在绑定routeingkey的时候使用通配符.# 匹配一个或多个单词 * 匹配一个单词 ex.# ex.* #.ex 等等# springAMQP 基于AMQP协议提供的一套API,底层默认实现是RabbitMQ.- 自动声明队列,交换机及绑定关系- 基于注解的监听器模式,异步接收消息- 封装了RabbitTemplate工具,用于发送消息- 默认序列化方式是JDK,可通过配置第三方转换器提高性能.# RabbitMQ 保证高可用- 通过使用集群来保证高可用. 普通集群 镜像集群# RabbitMQ 保证消息的可靠性* 可以在消息传递的全阶段,采用不同的方式,来保证消息的可靠性.- 生产者发送消息的可靠性. 消息确认机制* 发送者确认. publisher-confirm- 消息成功投递到交换机,返回ack- 消息未投递到交换机,返回nack* 确认模式- simple 同步等待结果,直到超时- correlated 异步回调,定义ConfirmCallback* 发送者回调.- 消息投递到交换机,但是没有路由到队列。返回ACK,及路由失败原因。- 定义ReturnCallback- 消息队列保证投递可靠性. 消息持久化* 交换机持久化* 队列持久化* 消息持久化- 消费者消费消息的可靠性. 消息回执,失败重试* RabbitMQ默认阅后即焚.即确认消息被消费者消费后会立刻删除,通过消费者回执来确认.* 确认方式- manual 手动ack,即开发者主动调用API发送ack- auto 自动ack,默认模式- none 关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除* 消费重试机制,如果消息消费失败,应采取的策略- 自动补偿 在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列.- 在配置文件中,设置最大重试次数,等待时长等- 但是在最大重试次数后,消息仍然消费失败,默认就会被丢弃* 失败策略- 死信队列,本地持久化.# 保证消息的幂等性- 使用全局MessageID判断消费方是否消费- 使用业务ID+逻辑保证唯一# 大量积压的消息如何快速消费- 紧急扩容. 即临时声明一个分发数据的consumer, 再创建大量的临时queue,临时的consumer,来快速消费积压的消息. 在消息消费完毕后,再将队列和消费者数量恢复正常.
6. 非关系型数据库之 —Redis
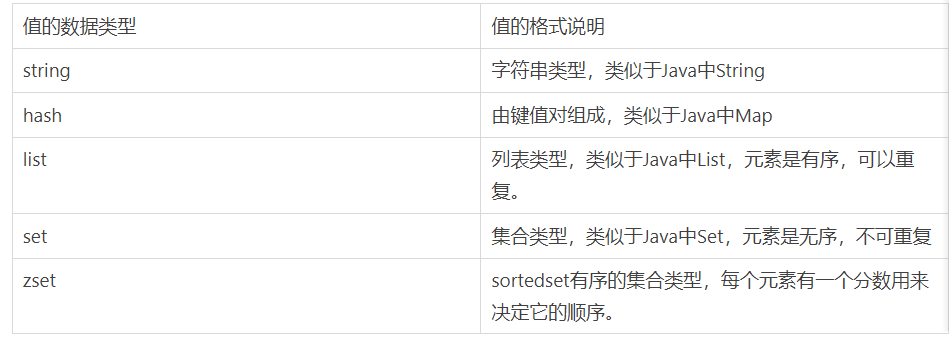
● redis是键值(Key-Value)存储数据库。● 性能极高 – Redis读的速度是110000次/s,写的速度是81000次/s 。● 丰富的数据类型 – Redis支持 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。● Redis运行在内存中但是可以持久化到磁盘。# 持久化机制○ RDB持久化机制. 默认○ AOF持久化机制.# Redis的高可用架构○ 主从架构,实现读写分离.○ 哨兵(Sentinel)机制来实现主从集群的自动故障恢复。○ 分片集群, 实现海量数据存储和高并发写入数据.
7. 非关系型数据库之 —MongoDb
#* 是一个非关系型数据库. 但是它的数据结构很类似关系型数据库mysql.* MongoDB中的记录是一个文档,它是一个由字段和值对(field:value)组成的数据结构即BSON, 类似于JSON, 或者说, 就是参数均是二进制表示的 JSON格式.* 文档的ID是自动生成的UUID, 因此, 映射的pojo类中, 主键类型必须是String.* 如果绑定的文档不存在, 那么在连接数据库时,会自动创建文档.1. 数据量大的场景. 比如社交应用中用户的发言,点赞等行为, 游戏中玩家的装备信息, 商品的物流数据等.2. 读写操作频繁的场景. MongoDB支持2000+ 的QPS. (query pre second 每秒搜索)3. 存储价值较低, 而且对事务的要求不高的数据. MongoDB的事务能力很低.
8. 分布式事务 —Seata
#- 分布式架构的项目中,经常会有些功能,需要调用别的微服务的接口,修改多个数据库中的多张表.- 也有些项目,由于数据量过大,单表会极大的影响效率,会将表中的数据进行分库分表操作,以提高服务的响应速 度,优化用户体验.- 在这些情况下,一旦任务执行过程中某个地方出错,即使开启了事务,@Transactional 数据依然无法回滚到错 误发生之前的状态. 进而数据错乱,导致更严重的后果.- 这种时候,就需要采用分布式事务的技术.* 基础理论CAP定理- Consistency 强一致性- Availability 高可用性- Partition tolerance 分区容错- 这三个指标不能同时做到,只能实现两个,而P是必须保证实现的.# seata* seata是阿里巴巴和蚂蚁金服共同开源的一种分布式事务解决方案.- @GlobalTransactional 在要开启分布式事务的入口方法上添加该注解# 三个角色* TC 事务协调者维护全局事务,负责协调全局事务的提交或回滚.* TM 事务管理者开始全局事务、提交或回滚全局事务.* RM 分支事务管理单个分支事务的状态.# 四种模式* XA模式- 所有分支事务执行完毕后不提交,而是将执行状态发送给TC,由TC确认事务执行成功与否,- 决定是提交事务还是回滚事务.- 强一致性,无业务侵入,会阻塞别的事务* AT模式 (seata默认模式)- 分支事务RM记录sql执行前后的数据快照undo-log,执行完毕后立即提交或回滚,并将状态报告给TC- 二阶段有TC决定是提交还是回滚.- 提交,各个RM删除undo-log , 回滚,读取undo-log,恢复数据- 最终一致,无业务侵入.- 有可能出现脏读,可通过开启全局锁解决,但会影响效率.* TCC模式- 为每个分支事务RM提供了三个方法,try confirm cancel- 一阶段完成后,直接提交事务,释放锁- 二段端,TC根据事务状态决定执行那个方法. 提交: canfirm 回滚: cancel- try 对要操作的资源进行检查和预留- confirm 业务执行和提交- cancel 释放预留的资源- 最终一致,有业务侵入.* SAGA模式-主要面向长事务,使用较少.
9. 延时任务方案 —四种常见方案
# ...延时任务方案...1. 定期轮询数据库.- 优点: 实现简单,且任务所在的服务可以设立集群,保证高可用.- 缺点: 定期扫描数据库压力大. 扫描频率难以均衡. 多线程可能出现安全问题等...2. 定时任务 ..xxljob- 优点: 实现简单- 缺点: 每个定时业务都要开启一次任务...3. Redis键过期通知- 优点: 高可用 实时性 支持消息的删除- 缺点: 负载大 没有确认机制,可能会出现消息丢失4. RabbitMQ 死信队列- 优点: 实现简单 高可用 可持久化 保证消息的可靠性- 缺点: 无法删除消息 不适合时间跨度大的定时任务
10. 页面静态化之模板引擎 —Freemarker
# 常用的java模板引擎有 Jsp, Freemarker, Thymeleaf, Velocity.● jsp绑定了servlet,不实用. velocity久不更新,过时了.● 天下英雄,唯freemarker和 thymeleaf尔.● Freemarker简单方便,效率高.● Thymeleaf功能强大,效率较低.● 我们使用Freemarker.# Freemarker的使用● 需要一个模板文件, 确定静态网页的样式布局.● 需要开发者提供真实数据, 填充模板中差值表达式的数据位置.● 模板 + 数据 = 静态文件.● 基础语法 :○ 兼容html的语法格式.○ 可以在标签中加上 #, 来使用FTL语言特有的标签功能. <#...>___</#...>○ 差值表达式语法类似jsp. ${ }○ 内建函数. 在 标签\变量后加 ? [函数名] 来使用内置的函数.○ 更具体的语法, 在使用时面向百度编程.
11. 基于RPC的远程调用 —Dubbo
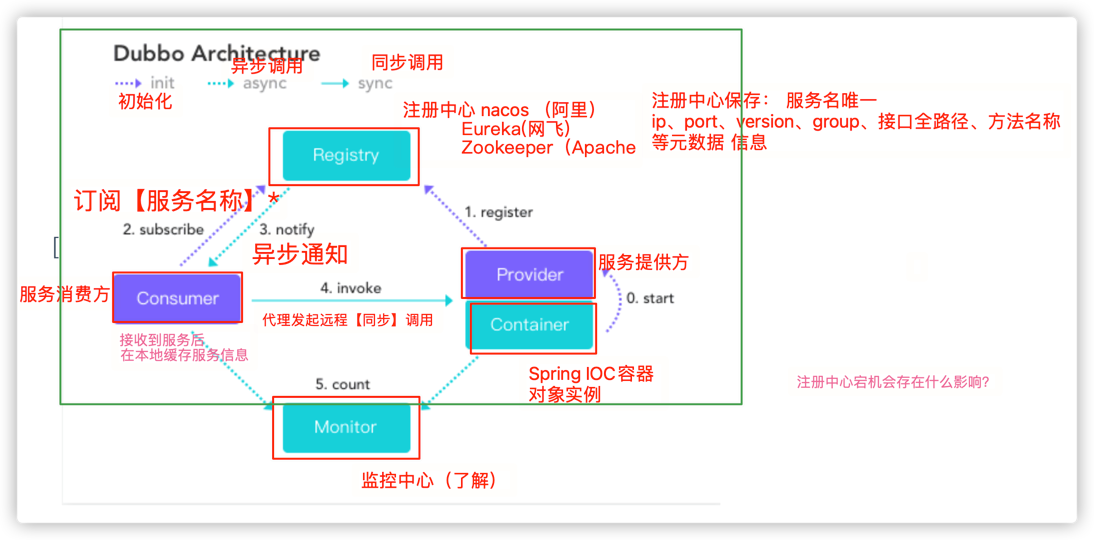
1. 简介- 面向接口代理的高性能RPC调用- 智能容错和负载均衡- 服务自动注册和发现- 高度可扩展能力- 运行期流量调度- 可视化的服务治理与运维2. dubbo与feign的区别* dubbo: 基于RPC的远程调用(默认基于TCP协议), 面向接口, 智能负载均衡.- 支持多种连接协议.- 利用Netty,TCP传输,单一、异步、长连接,适合数据量小、高并发的场景.- 负载均衡的算法可以精准到某个服务接口的某个方法提供方 @DubboService 消费端 @DubboReference* feign: 基于http协议的远程调用, 也是面向接口.- 通过短连接的方式进行通信,不适合高并发的访问.- Feign默认使用Ribbon作为负载均衡的组件,Hystrix作为服务熔断的组件.- 负载均衡是Client级别的.客户端 @FeignCilent 消费端 @Autowired 自动注入二者都是同步调用.3. dubbo的配置原则* dubbo推荐在Provider上尽量多配置Consumer端属性. 提供方拥有具体的业务实现的逻辑代码,可以提供基础的, 参考配置.优先级: 方法级 > 接口级 > 全局配置, 其中 消费方consumer的配置优先于服务提供方Provider的配置.在@DubboService 和 @DubboReference注解中, 有一个methods属性, 可以针对指定的方法进行配置.4. 常用配置- timeout 超时时间, 默认1s- retries 重试次数, 默认为2次- version 灰度发布, 即在版本更新时 分时分段 的更新服务者和消费者的版本.5. 隐式传参* org.apache.dubbo.rpc.RpcContext ;线程共享数据的处理类RpcContext.getContext().setAttachment(key, value)RpcContext.getContext().getAttachment(key, value)多个微服务之间的上下文信息不同, 隐式传递的参数不能跨过多个微服务.6. 负载均衡配置* Random LoadBalance 加权随机调用(默认策略)- 按权重设置随机概率. 调用次数越多, 调用越接近权重的策略* RoundRobin LoadBalance 加权轮询策略- 按公约后的权重设置轮循比率.- 在首轮分配后, 继续按照权重的次数来分配路由, 直到所有的权重分配结束, 算是一次完整的轮询, 之后开启下次轮询.* LeastActive LoadBalance 最少活跃调用数- 类似能者多劳模式, 每个服务会计算执行前后的时间差, 执行越慢的服务分配到的任务越少, 越快的服务会接到更多的请求.* ConsistentHash LoadBalance 一致性 Hash- 把请求的hash值, 对服务总数取模,把相同余数的请求路由到同一个服务.- 默认只计算第一个请求参数的hash, 默认使用160分虚拟节点.7. 服务降级和集群容错策略* 服务降级- 自定义降级后的返回策略.* 集群容错- Failover Cluster 失败自动切换(默认容错模式)失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries=“2” 来设置重试次数.- Failfast Cluster 快速失败快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。- Failsafe Cluster 失败安全失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。- Failback Cluster失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。- Forking Cluster并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=“2” 来设置最大并行数。- Broadcast Cluster广播调用所有提供者,逐个调用,任意一台报错则报错 [2]。通常用于通知所有提供者更新缓存或日志等本地资源信息。8. 整合hystrix的微服务保护* 添加依赖在Application类上增加@EnableHystrix来启用hystrix starter.<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-hystrix</artifactId><version>1.5.9.RELEASE</version></dependency>* 配置Provider端在Dubbo的Provider上增加 @HystrixCommand 配置.注:1. 注册中心宕机会有什么影响?- 监控中心宕掉不影响使用,只是丢失部分采样数据- 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯- 服务提供者无状态,任意一台宕掉后,不影响使用- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复2. dubbo可以直连调用吗?可以, 添加服务提供方的地址就可以, 但是不推荐,失去了高可用性.@Reference(url=“127.0.0.1:20880”)3. 可以使用别的注册中心吗?可以, zookeeper, redis等.* redis 存储的结构为 HASH, 通过订阅/发布实现注册功能, HASH KEY是当前服务的全限定名+类型(提供方/消费方), 存储的MAP对象的key 是服务的ID, value是过期时间引入依赖<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId></dependency>修改配置dubbo:registry:address: redis://${host}:6379
12. 消息队列中间件 —Kafka
# Kafka 是一款分布式流处理框架,用于实时构建流处理应用。高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒可扩展性:kafka集群支持热扩展持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)高并发:支持数千个客户端同时读写消费者组: 是Kafka独有的概念,是Kafka提供的可扩展且具有容错性的消费者机制.在Kafka 中,消费者组是一个由多个消费者实例 构成的组。多个实例共同订阅若干个主题,实现共同消费。同一个组下的每个实例都配置有 相同的组 ID,被分配不同的订阅分区。当某个实例挂掉的时候,其他实例会自动地承担起 它负责消费的分区。
13. 分布式文件存储 —fastDFS
# FastDFS 是一个开源的轻量级分布式文件系统,它可以对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等- 搭建太过复杂, 不如minIO简单.- 自从阿里云oss出现后,两个都不用了.
14. alibaba旧类注册中心 —zookeeper
# Zookeeper 是一个分布式协调服务的开源框架, 主要用来解决分布式集群中应用系统的一致性问题.ZooKeeper 本质上是一个分布式的小文件存储系统,提供基于类似于文件系统的目录树方式的数据存储 在ZooKeeper中还支持一种watch(监听)机制, 它允许对ZooKeeper注册监听, 当监听的对象发生指定的事件的时候, ZooKeeper就会返回一个通知. Watcher 分为以下三个过程:客户端向ZK服务端注册 Watcher、服务端事件发生触发 Watcher、客户端回调 Watcher 得到触发事件情况.触发事件种类很多,如:节点创建,节点删除,节点改变,子节点改变等。 Watcher是一次性的. 一旦被触发将会失效. 如果需要反复进行监听就需要反复进行注册.简单来说zookeeper=文件系统+监听通知机制. 现在我们用nacos替代.
15. 连接数据库封装JDBC —hibrnate
# 连接数据库的一个实现方案, 封装了JDBC, 是 ORM(对象关系映射) 关系的一种实现.我们使用的是Mybatis.
16. alibaba连接数据库封装JDBC —Netty
# Netty 是基于Java NIO的异步事件驱动的 网络应用框架它提供了对TCP、UDP 和文件传输的支持,作为一个异步 NIO 框架,Netty 的所有 IO 操作都是异步非阻塞的.我们项目使用的都是springboot, 内置了tomcat, 所以没有使用netty
17. 分库分表 —Sharding-JDBC
18. Websocket
# websocket是html5规范中的一个部分,它借鉴了socket这种思想,为web应用程序客户端和服务端之间(注意是客户端服务端)提供了一种全双工通信机制。 是一种通信协议说白话, 就是 HTTP 协议有一个缺陷:通信只能由客户端发起.websocket协议, 服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息,是真正的双向平等对话,属于服务器推送技术的一种.<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency>使用入门:https://zhengkai.blog.csdn.net/article/details/80275084?spm=1001.2101.3001.6650.3&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-3.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-3.no_search_link
19. Kubernetes —即k8s
* Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。\作用是部署环境和容器, 正在逐渐的取代docker.有时间可以学习下入门文档 https://www.kubernetes.org.cn/k8s
开发bug:
1. 热点新闻更新错误
1. rabbitmq自定义配置, 采用jackson2json序列化消息, 体积更小,效率更高2. 在文章微服务监听消息, 收到的消息多了一对双引号, 存入redis中, 再取出序列化失败.3. 解决方法:1. 发消息的微服务采用默认序列化方式2. 监听器接收到消息后, 先对内容进行处理, 去除两端的双引号,在存入redis
2. Long类型数据精度丢失
* 如果是对象, 主键ID修改序列化方式.* 如果是Long对象, 可选一: 转为String返回 可选二: 前段js修改, 异步请求接收结果时不做转换,直接返回
3. redis分布式锁失效
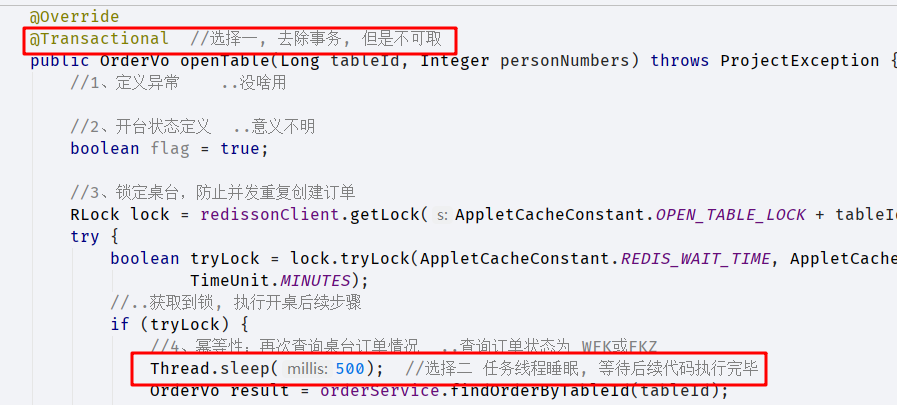
起因: 测试开桌的时候, 模拟前段多个请求, 而服务器内部网络堵塞(debug模拟), 恢复后会出现重复开桌的安全问题.原理: 在释放分布式锁后, 该任务仍有很多后续代码要执行, 而由于方法上加了事务, 在执行完毕之前, order表并不会写入数据. 此时下一个线程获取了分布式锁, 并通过了order状态判断, 导致重复开桌.解决方案: 见图.选择三: 该段代码结束后直接return 当前结果参数, 从web层的方法里调用后续步骤并传参. (推荐)
4. mybatis的分页插件bug
# 问题描述一个本来没有做分页的查询,通过输出日志可以看到,在执行查询的时候却用了分页。导致查询不到数据,或是查询到错误的数据。# 问题原因mybaits分页插件底层使用了ThreadLocal封装了Page对象, 这个变量内封装了分页查询要用的参数,以及查询的结果。它会在执行sql时自动插入分页语句. 底层源码在finally里执行了clear(), 似乎是不会出现脏数据的问题. 但是, 如果还没有进入try就抛异常了,就会导致没能让finally中的内容执行到。因为它只有在执行过mapper查询语句后, 才会执行finally清空缓存的逻辑!!!在我们的业务代码里获取到Page对象后,没有立即调用mapper做查询。而是执行了一些其他的内容。正是这些其他的内容抛出了异常,导致后面没有调用mapper做查询,也就无法进入到上面贴的插件中的代码,更没有可能清空ThreadLocal变量了。在这个线程下次被使用时,如果正好是一个不需要分页查询的功能,也就没法把ThreadLocal中已有的变量覆盖掉,导致把一个不需要分页查询的功能做了分页查询。# 解决方案要使用MyBatis分页插件PageHelper做分页查询时 ,一定要记得,在获得了Page对象后要立即调用mapper做查询,不要有其他的逻辑插入其中。
面试题:
1. 选择排序优化
//选择排序的优化for(int i = 0; i < arr.length - 1; i++) {// 做第i趟排序int k = i;for(int j = k + 1; j < arr.length; j++){// 选最小的记录if(arr[j] < arr[k]){k = j; //记下目前找到的最小值所在的位置}}//在内层循环结束,也就是找到本轮循环的最小的数以后,再进行交换if(i != k){ //交换a[i]和a[k]int temp = arr[i];arr[i] = arr[k];arr[k] = temp;}}
2. 冒泡排序优化
public static void bubbleSort3(int[] values) {System.out.println("排序前:" + Arrays.toString(values));int tmp;// 循环外创建变量,减少垃圾产生,提高性能int count = 0;// 比较了多少趟int num = 0; // 比较次数// 外层循环,n 个元素,最多需要 n -1 趟循环for(int i = 0; i < values.length -1 ; i++) {// 定义一个boolean 值,标记数组是否达到有序状态boolean flag = true;count ++;// 内层循环, 每一次都从开始两个元素开始两两比较到最后/* 每一趟循环都可以找你最大的数,内循环可以比上一趟循环减少一次比较 */for (int j = 0; j < values.length - 1 - i; j++) {if(values[j] > values[j + 1]) {tmp = values[j];values[j] = values[j + 1];values[j + 1] = tmp;// 如果本趟发生了交换,表明数组还是无序,需要进入下一轮循环flag = false;}num ++;}// 根据标记的布尔值判断数组是否达到有序状态,如有序,则退出循环if( flag) {break;}}System.out.println("排序后:" + Arrays.toString(values));System.out.println("比较趟数:"+count + ",比较次数:" + num);}

若有收获,就点个赞吧
0 人点赞
