一、概述
官网:https://azkaban.github.io/
业务场景描述:假设某个业务每天产生100GB原始数据,要对其进行处理,处理步骤如下:
(1)通过Hadoop先将数据同步到HDFS上。
(2)借助MapReduce计算框架对原始数据进行转换,生成的数据以分区表的形式存储在多张Hive表中。
(3)对Hive表的数据进行统计分析,得到结果报表信息
(4)需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
一个完整的数据分析系统通常由大量任务单元组成,各任务单元之间存在时间先后及前后依赖关系。为了很好的组织这样的复杂执行计划,需要一个工作流调度系统来调度执行。
二、安装部署
Azkaban包含如下3个组件:MySQL服务器、Web服务器和Executor服务器。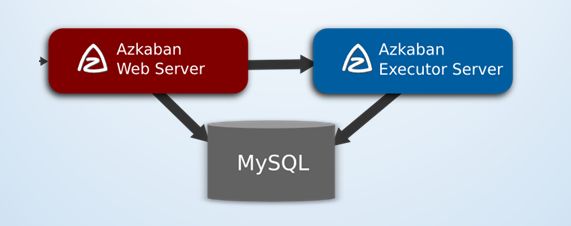
- MySQL服务器:存储项目、执行计划、执行情况等信息
- Web服务器:用户通过Web页面实现方便的管理
- Executor服务器:负责具体工作流的提交和执行
安装包:azkaban2.5.rar
1)把Azkaban Web服务器、Azkaban Executor服务器压缩包上传至Linux的”~/Downloads”目录下,并解压
cd ~/Downloadssudo tar -zxvf azkaban-web-server-2.5.0.tar.gz -C /usr/local/sudo tar -zxvf azkaban-executor-server-2.5.0.tar.gz -C /usr/local/sudo chown -R hadoop:hadoop /usr/local/azkaban-web-2.5.0/sudo chown -R hadoop:hadoop /usr/local/azkaban-executor-2.5.0/
2)Azkaban SQL脚本解压
cd ~/Downloadssudo tar -zxvf azkaban-sql-script-2.5.0.tar.gz -C /usr/local/
进入mysql,将解压的SQL导入到mysql中:
create database azkaban;use azkaban;source /usr/local/azkaban-2.5.0/create-all-sql-2.5.0.sql
3)配置SSL
cd ~keytool -keystore keystore -alias jetty -genkey -keyalg RSA#将生成的keystore证书文件拷贝至azkaban-web-server目录中sudo cp keystore /usr/local/azkaban-web-2.5.0/
4)Azkaban Web服务器配置
配置文件路径:
/usr/local/azkaban-web-2.5.0/conf/azkaban.properties
配置内容:
#Azkaban Personalization Settingsazkaban.name=Testazkaban.label=My Local Azkabanazkaban.color=#FF3601azkaban.default.servlet.path=/indexweb.resource.dir=web/default.timezone.id=Asia/Shanghai#Azkaban UserManager classuser.manager.class=azkaban.user.XmlUserManageruser.manager.xml.file=conf/azkaban-users.xml#Loader for projectsexecutor.global.properties=conf/global.propertiesazkaban.project.dir=projectsdatabase.type=mysqlmysql.port=3306mysql.host=localhostmysql.database=azkabanmysql.user=rootmysql.password=rootmysql.numconnections=100# Velocity dev modevelocity.dev.mode=false# Azkaban Jetty server properties.jetty.maxThreads=25jetty.ssl.port=8443jetty.port=8081jetty.keystore=keystorejetty.password=000000jetty.keypassword=000000jetty.truststore=keystorejetty.trustpassword=000000# Azkaban Executor settingsexecutor.port=12321# mail settingsmail.sender=mail.host=job.failure.email=job.success.email=lockdown.create.projects=falsecache.directory=cache
5)Azkaban Executor服务器配置
配置文件路径:
/usr/local/azkaban-executor-2.5.0/conf/azkaban.properties
配置内容:
#Azkabandefault.timezone.id=Asia/Shanghai# Azkaban JobTypes Pluginsazkaban.jobtype.plugin.dir=plugins/jobtypes#Loader for projectsexecutor.global.properties=conf/global.propertiesazkaban.project.dir=projectsdatabase.type=mysqlmysql.port=3306mysql.host=localhostmysql.database=azkabanmysql.user=rootmysql.password=rootmysql.numconnections=100# Azkaban Executor settingsexecutor.maxThreads=50executor.port=12321executor.flow.threads=30
6)Azkaban Web服务器启动
cd /usr/local/azkaban-web-2.5.0/nohup bin/azkaban-web-start.sh
7)Azkaban Executor服务器启动
cd /usr/local/azkaban-executor-2.5.0/nohup bin/azkaban-executor-start.sh

三、应用实例
3.1 浏览器访问Azkaban服务
访问地址:https://localhost:8443
默认登录用户名和密码:azkaban/azkaban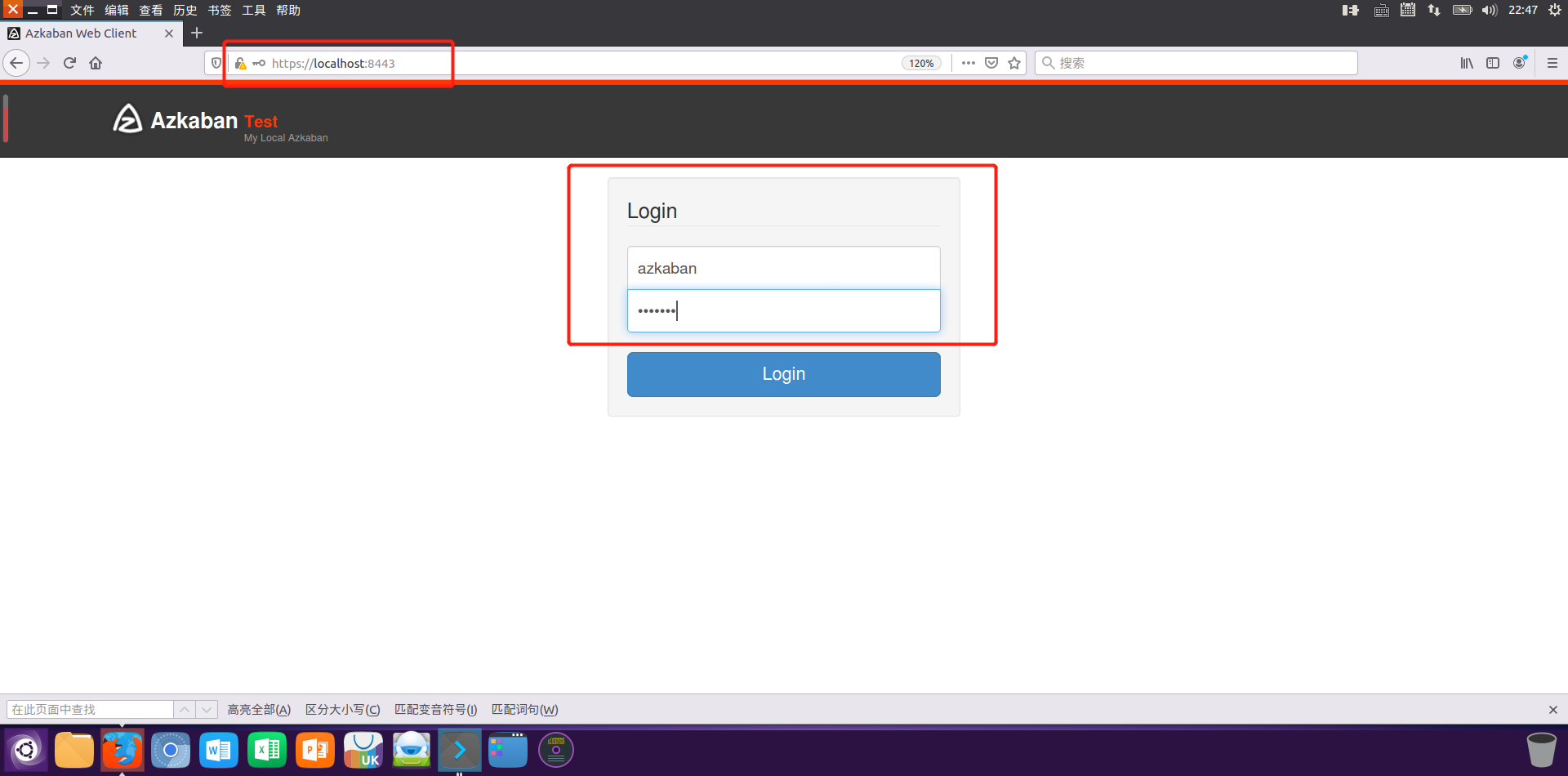
3.2 创建单一Job工作流
(1)创建Job描述文件:command.job
vim command.job
#command.jobtype=commandcommand=echo "Hello World"
(2)将Job资源文件打包成zip文件
zip first.zip command.job
(3)通过Azkaban的Web管理平台创建Project并上传first.zip压缩包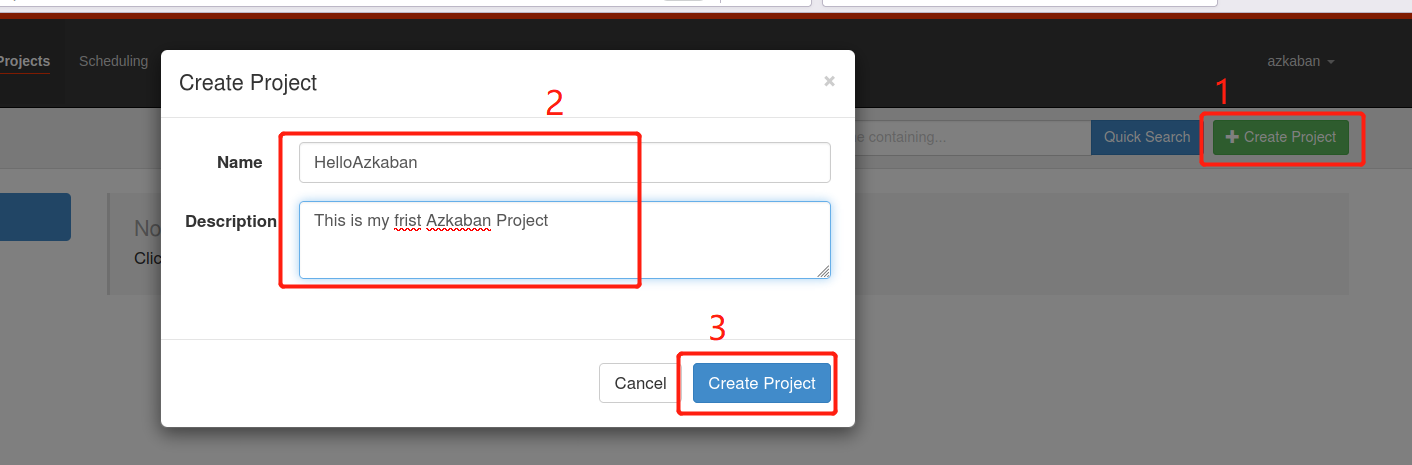
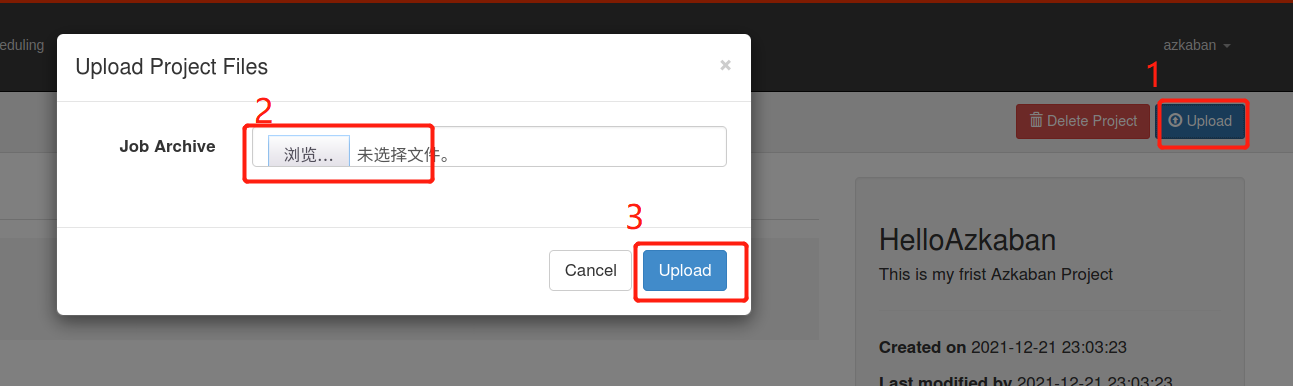
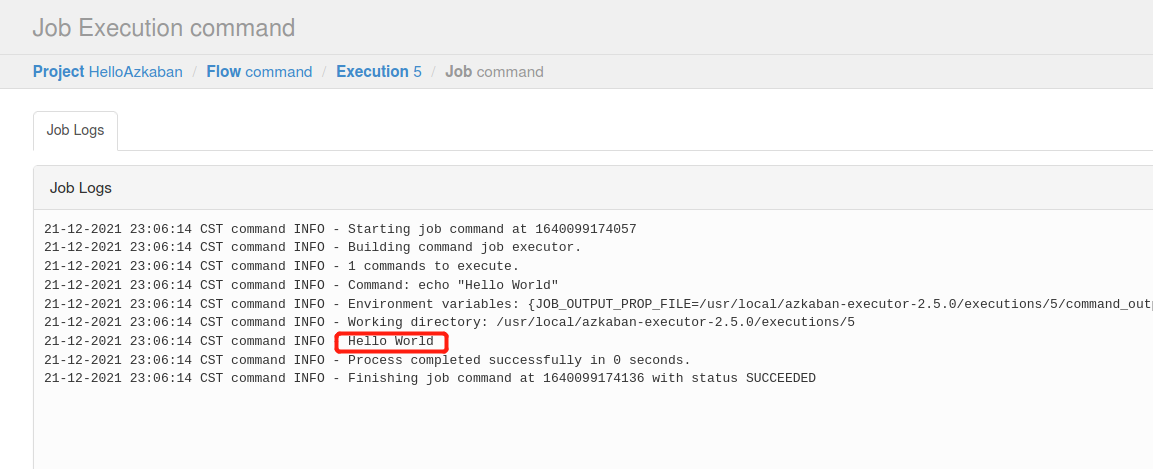
(4)执行该Job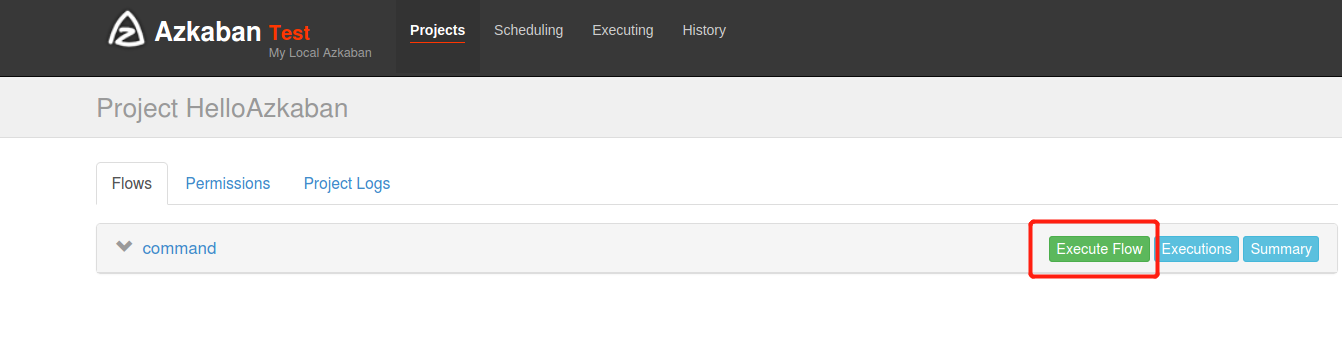
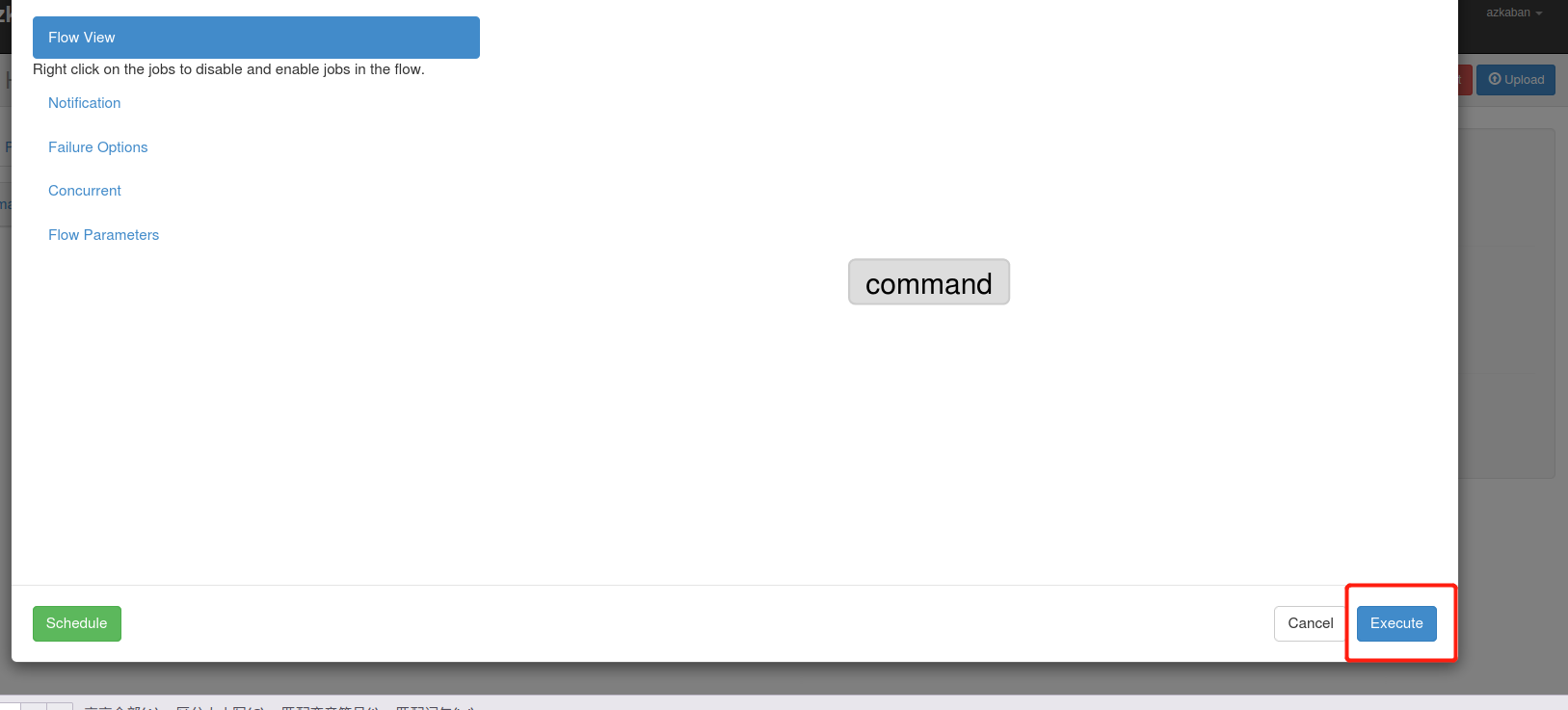
5)执行完之后会显示执行状态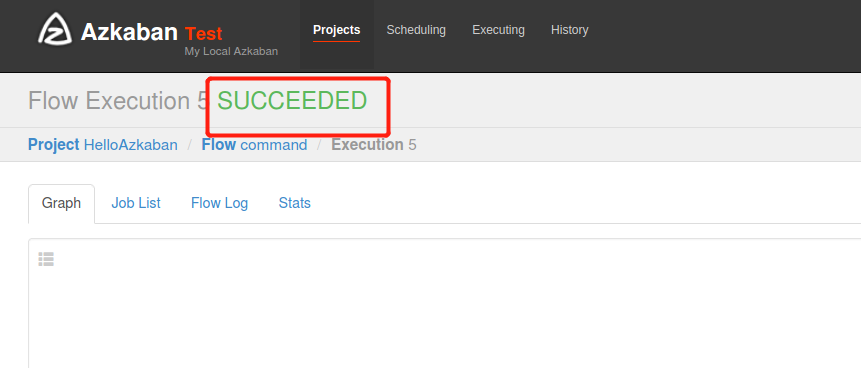
可以点击job list-Details查看日志
3.3 创建多Job工作流
(1)创建有依赖关系的多个Job描述文件
vim step1.job
#step1.jobtype=commandcommand=echo foo
vim step2.job
#step2.jobtype=commanddependencies=step1command=echo bar
(2)将step1.job、step2.job打包
zip second.zip step1.job step2.job
(3)通过Azkaban的Web管理平台创建Project并上传second.zip压缩包,然后执行该Job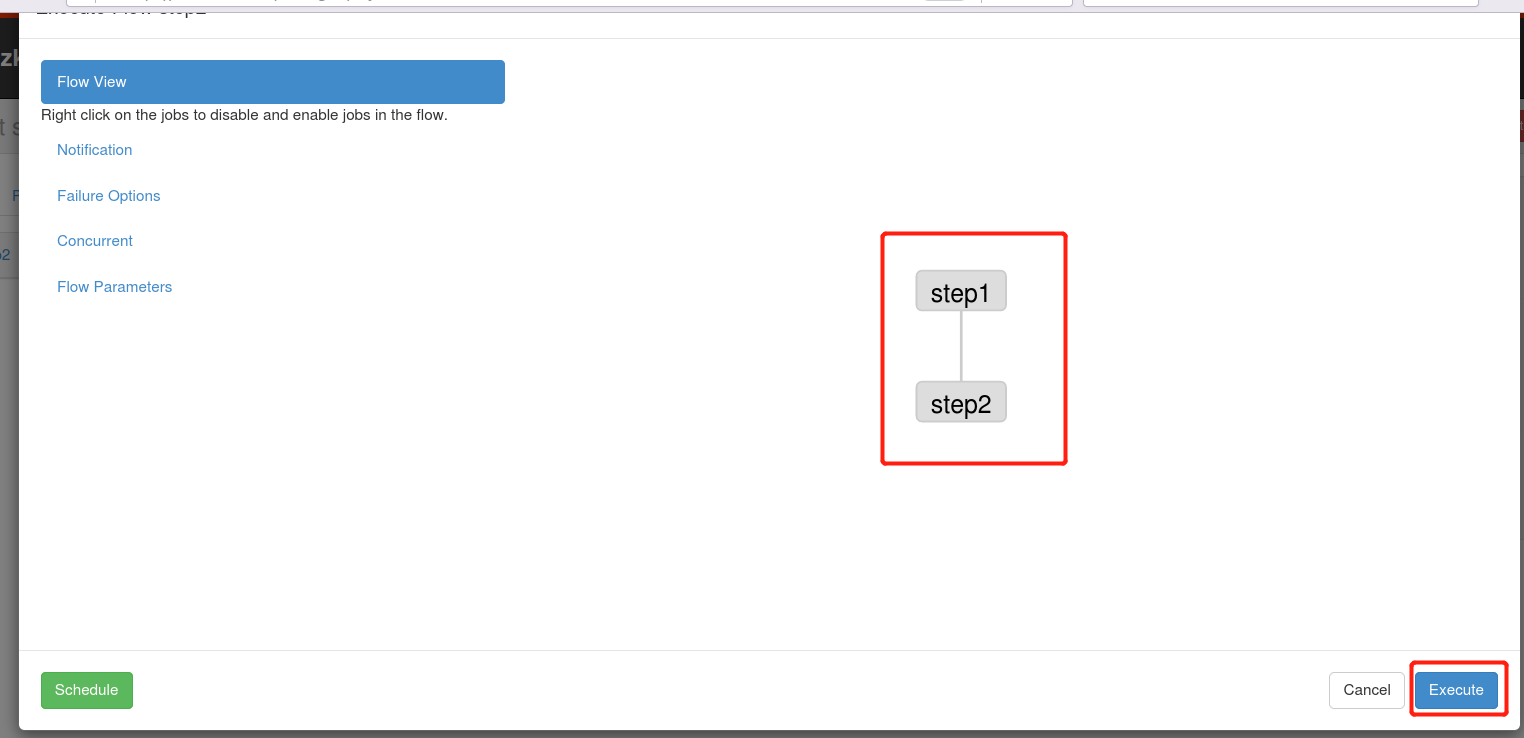

3.4 创建HDFS Job
(1)创建Job描述文件
vim hdfs.job
#hdfs.jobtype=commandcommand=hdfs dfs -mkdir /azkaban_job
3.5 创建Hive Job
(1)创建Job描述文件
vim hive.job
#hive.jobtype=commandcommand=hive -f'hive.hql'
创建hive.hql文件
vim hive.hql
use test;create table emp_stat as select deptno,count(*) from emp group by deptno;

若有收获,就点个赞吧
0 人点赞
