一、案例简介
数据集网站用户购物行为数据集,包括2000万条记录。
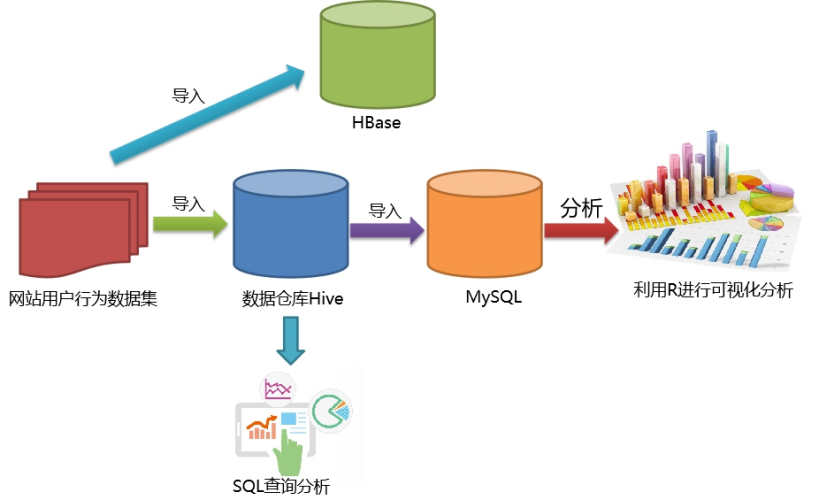
步骤一:本地数据集上传到数据仓库Hive
步骤二:Hive数据分析
步骤三:Hive、MySQL通过sqoop数据互导
软件.rar
二、数据预处理
2.1 数据集介绍
本案例采用的数据集包含了一个大规模数据集raw_user.csv(包含2000万条记录),和一个小数据集small_user.csv(只包含30万条记录)。小数据集small_user.csv是从大规模数据集raw_user.csv中抽取的一小部分数据。之所以抽取出一少部分记录单独构成一个小数据集,是因为在第一遍跑通整个实验流程时,会遇到各种错误、各种问题,先用小数据集测试,可以大量节约程序运行时间。等到第一次完整实验流程都顺利跑通以后,可以最后用大规模数据集进行最后的测试。
small_user.csv
| user_id | item_id | behavior_type | user_geohash | item_category | time |
|---|---|---|---|---|---|
| 用户id | 商品id | 浏览(1),收藏(2),加购物车(3),购买(4) | 用户地理位置哈希值 | 商品分类 | 记录产生时间 |
#数据集存放在/usr/local/bigdatacase/dataset#为该目录赋权sudo chown -R hadoop:hadoop /usr/local/bigdatacase
2.2 数据集的预处理
1)删除第一行字段数据
cd /usr/local/bigdatacase/dataset#查看前5行数据head -5 small_user.csv删除small_user中的第1行sed -i '1d' small_user.csv#再次查看前5行数据head -5 small_user.csv
2)字段预处理
处理内容包括:
- 为每行记录增加id字段,唯一标识该行记录
- 增加省份字段
- 删除user_geohash字段
通过运行脚本文件实现上述处理,首先新建一个脚本文件。
cd /usr/local/bigdatacase/datasetvim pre_deal.sh
pre_deal.sh脚本的内容如下:
awk -F “,” ‘处理逻辑’ $infile> $outfile
#!/bin/bash#下面设置输入文件,把用户执行pre_deal.sh命令时提供的第一个参数作为输入文件名称infile=$1#下面设置输出文件,把用户执行pre_deal.sh命令时提供的第二个参数作为输出文件名称outfile=$2#注意,最后的$infile> $outfile必须跟在}’这两个字符的后面awk -F "," 'BEGIN{srand();id=0;Province[0]="山东";Province[1]="山西";Province[2]="河南";Province[3]="河北";Province[4]="陕西";Province[5]="内蒙古";Province[6]="上海市";Province[7]="北京市";Province[8]="重庆市";Province[9]="天津市";Province[10]="福建";Province[11]="广东";Province[12]="广西";Province[13]="云南";Province[14]="浙江";Province[15]="贵州";Province[16]="新疆";Province[17]="西藏";Province[18]="江西";Province[19]="湖南";Province[20]="湖北";Province[21]="黑龙江";Province[22]="吉林";Province[23]="辽宁"; Province[24]="江苏";Province[25]="甘肃";Province[26]="青海";Province[27]="四川";Province[28]="安徽"; Province[29]="宁夏";Province[30]="海南";Province[31]="香港";Province[32]="澳门";Province[33]="台湾";}{id=id+1;value=int(rand()*34);print id"\t"$1"\t"$2"\t"$3"\t"$5"\t"substr($6,1,10)"\t"Province[value]}' $infile> $outfile
编辑后退出。
执行脚本文件,对small_user.csv进行数据预处理:
bash ./pre_deal.sh small_user.csv user_table.txthead -5 user_table.txt
2.3 导入Hive数据仓库
1)把处理好的数据文件user_table.txt上传到HDFS的/bigdatacase/dataset目录下,上传完之后查看前5条数据验证是否上传成功。
hdfs dfs -mkdir -p /bigdatacase/datasethdfs dfs -put /usr/local/bigdatacase/dataset/user_table.txt /bigdatacase/datasethdfs dfs -cat /bigdatacase/dataset/user_table.txt | head -5
2)在Hive中创建外部表
create database dblab;use dblab;create external table dblab.bigdata_user(id INT,uid STRING,item_id STRING,behavior_type INT,item_category STRING,visit_date DATE,province STRING)row format delimited fields terminated by '\t' STORED AS TEXTFILElocation '/bigdatacase/dataset';#简单查询select *From bigdata_user limit 10;
三、Hive数据分析
3.1 简单查询
1)计算表内有多少行数据
2)计算用户总数
3)查询不重复的数据有多少条
select count(*) from bigdata_user;select count(distinct uid) from bigdata_user;select count(*) from (select uid,item_id,behavior_type,item_category,visit_date,provincefrom bigdata_usergroup by uid,item_id,behavior_type,item_category,visit_date,provincehaving count(*)=1)a;
3.2 关键字条件查询分析
1)查询2014年12月10日~13日有多少人浏览了商品
2)以月的第n天为统计单位,依此显示第n天网站卖出去的商品的个数
select count(*) from bigdata_user where behavior_type='1' and visit_date<'2014-12-13' and visit_date>'2014-12-10';select month(visit_date) as month,day(visit_date) as day,count(distinct item_id) as ids from bigdata_user where behavior_type='4' group by month(visit_date),day(visit_date);
3.3 根据用户行为分析
1)查询某商品在某天的购买转化率(购买量/点击量)
2)给定购买商品的数量范围,查询某天在该网站的购买该数量商品的用户id
#查询2014-12-11当天,商品'217620949'的购买转化率select item_id,sort_array(collect_list(num))[0] / sort_array(collect_list(num))[1] btrfrom (select distinct item_id,behavior_type,count(*) over(partition by behavior_type) as numfrom bigdata_userwhere visit_date ='2014-12-11' and item_id = '217620949' and behavior_type in (1,4)order by num)agroup by item_id;#查询2014-12-12当天,在该网站购买商品超过5次的用户idselect uid from bigdata_user where behavior_type='4' and visit_date='2014-12-12' group by uid having count(behavior_type='4')>5;
四、 Hive、MySQL数据互导
4.1 Hive建表
#创建一个临时表,用于写数据create table dblab.user_action(id STRING,uid STRING,item_id STRING,behavior_type STRING,item_category STRING,visit_date DATE,province STRING)row format delimited fields terminated by ',' STORED AS TEXTFILE;insert overwrite table dblab.user_action select * from dblab.bigdata_user;
4.2 MySQL建表
1)登录MySQL,创建新的数据库
create database dblab;use dblab;
2)查看数据的编码并修改
show variables like "char%";set character_set_server=utf8;set character_set_database=utf8;
3)创建表
CREATE TABLE `dblab`.`user_action`(`id` varchar(50),`uid` varchar(50),`item_id` varchar(50),`behavior_type` varchar(10),`item_category` varchar(50),`visit_date` DATE,`province` varchar(20))ENGINE=InnoDB DEFAULT CHARSET=utf8;
4.3 安装sqoop
安装包:sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar
1)下载解压安装包,修改权限。
cd ~/Downloads/ #注意切换到自己保存的目录下sudo tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /usr/localcd /usr/localsudo mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoopsudo chown -R hadoop:hadoop sqoop
2)编辑sqoop-env.sh
cd sqoop/conf/cat sqoop-env-template.sh >> sqoop-env.sh #将sqoop-env-template.sh复制一份并命名为sqoop-env.shvim sqoop-env.sh #编辑sqoop-env.sh
sqoop-env.sh文件插入以下内容:
export HADOOP_COMMON_HOME=/usr/local/hadoopexport HADOOP_MAPRED_HOME=/usr/local/hadoopexport HIVE_HOME=/usr/local/hive
3)编辑环境变量,增加sqoop的相关内容。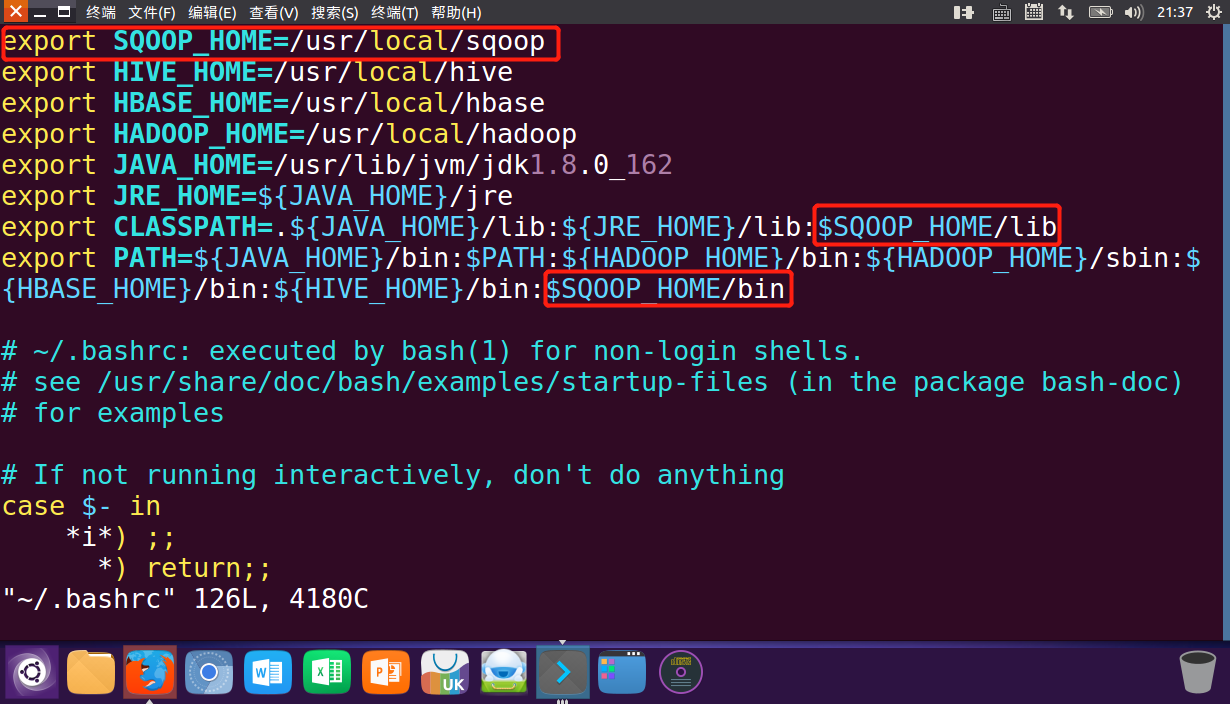
4)将mysql驱动包拷贝到/usr/local/sqoop/lib目录下。
mysql5.+驱动包:mysql-connector-java-5.1.40.tar
mysql8.+驱动包:
cd Downloads/ #切换到mysql驱动包所在目录sudo tar -zxvf mysql-connector-java-5.1.40.tar.gz #解压mysql驱动包cp ./mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/sqoop/lib
- 测试与MySQL的连接(确保MySQL启动)
sqoop list-databases --connect jdbc:mysql://127.0.0.1:3306/ --username root -P
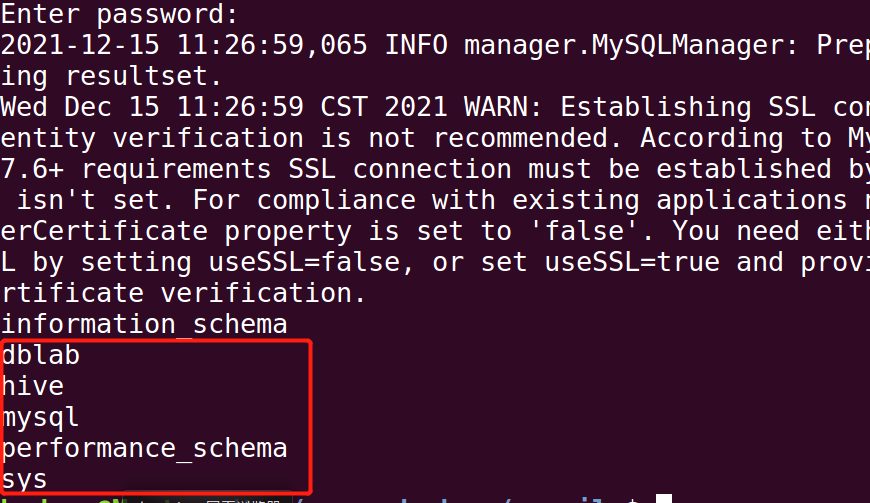
4.4 Hive数据导入至MySQL
成功导入后可以进入mysql中查询数据是否存在sqoop export --connect jdbc:mysql://localhost:3306/dblab --username root --password root --table user_action --export-dir '/user/hive/warehouse/dblab.db/user_action' -- fields-terminated-by ',' --blind /usr/local/sqoop/lib/
如果有报错,把/tmp/sqoop-hadoop/compile目录下最新目录下的所有文件拷贝到/usr/local/sqoop/lib/下,再重新运行。

若有收获,就点个赞吧
0 人点赞
