栈
栈的代码实现
栈的主要操作有 push pop isEmpty size clear 等
function Stack(){this.items = []}Stack.prototype ={push(item){this.items.push(item)},pop(){return this.items.pop()},clear(){this.items = []},size(){return this.item.length},isEmpty(){return this.items.length === 0}}
浏览器中的JS运行机制
我们知道js是单线程的 所谓单线程就是js引擎中负责解释和执行js的代码的线程唯一,同一时间只能执行一件任务
为什么是单线程的呢?
因为js是可以操作dom的, 如果js引擎的现成是多线程的 那么可以同时执行多段javascript代码,如果多段js代码都在修改dom, 就会造成js冲突
但是单线程有一个问题 如果一个任务队列中有一个任务是非常耗时的 那么后面的任务就会一直排队等着 就会发生页面卡死 严重影响用户体验
为了解决这个问题 js将任务的执行模式分为两种 同步和异步
同步任务是在主线程是执行的 形成一个调用栈 又称执行栈
主线程之外还有一个任务队列 也成为消息队列 用于管理异步任务的回调 在调用栈的任务执行完毕疑惑系统会检查任务队列 看是否有可以执行的异步任务
注意:任务队列 存放的是异步任务的回调
**
setTimeout(() => {console.log('时间到')}, 1000)
比如时候上面的代码 setTimeout本身是同步执行的 放进任务队列的是它的回调函数
调用栈
下面我们从两个方面来介绍下 调用栈
调用栈是做什么的 如何利用调用栈
调用栈的职责
调用栈就是用来管理函数调用管理的一种栈结构
我们来举例说明
var a = 1function add(a) {var b = 2let c = 3return a + b + c}// 函数调用add(a)
下面我们来一步一步来介绍函数的执行过程
在这段代码执行之前 js引擎会先创建一个全局执行上下文 包含所有已生命的函数和变量 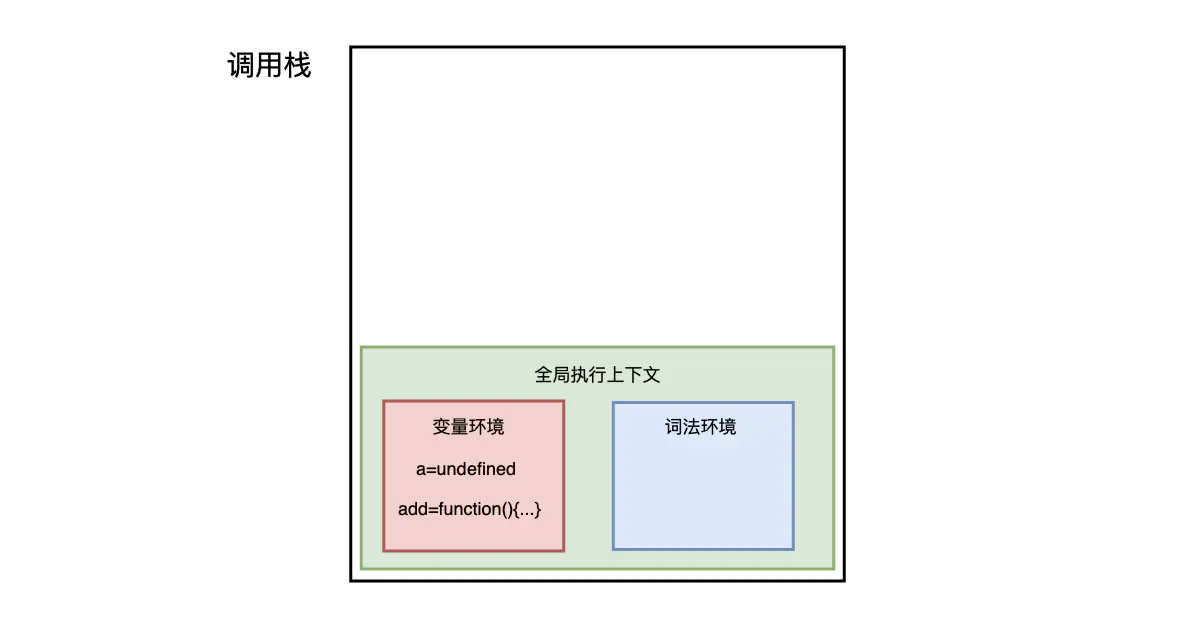
从图中可以看出 代码中的全局变量 a 以及函数add 都保存在变量环境中
执行上下文准备好之后 就开始执行全局代码 首先执行 a = 1 的赋值操作 
赋值操作完成以后 a 的值由 undefined 变为 1 然后执行add函数 javascript判断出这是一个函数调用 然后就进行一下操作
- 首先从全局执行上下文中 拿出add 函数
- 其次 对add函数就行编译 并创建该函数的执行上下文和可执行代码 并将上下文压入栈中
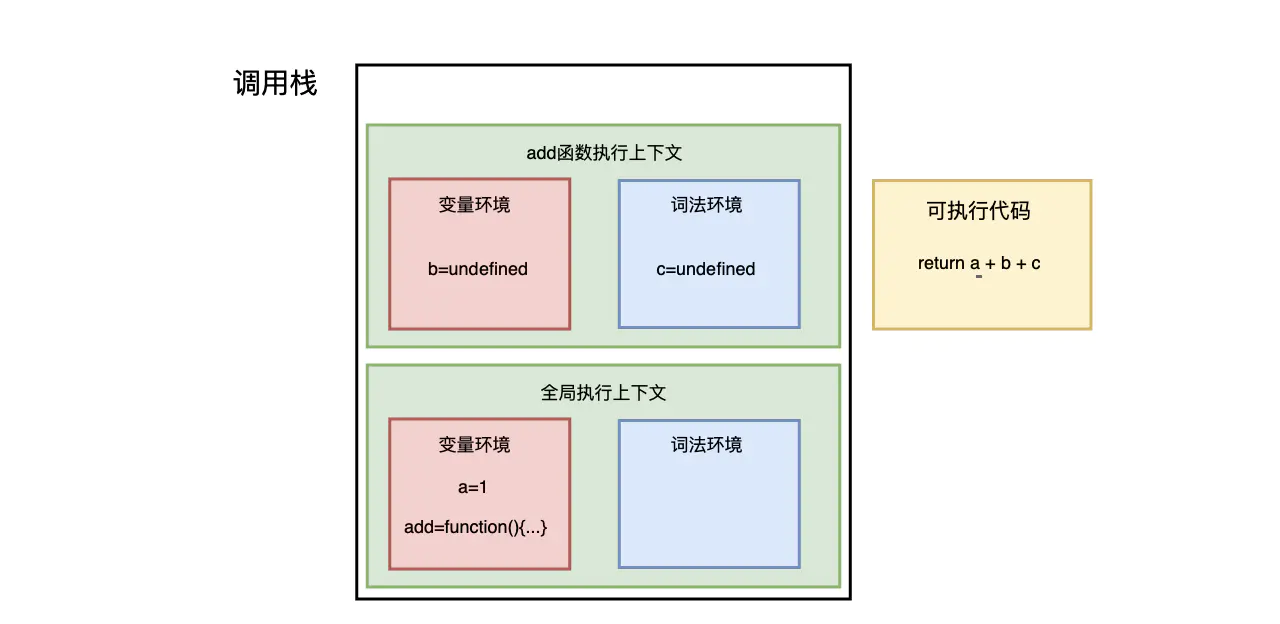
- 然后 执行代码 返回结果 并将add的执行上下文也会从调用栈的顶部弹出 此时调用栈就剩下一个全局上下文了
至此整个过程就结束了
所以说 调用栈是javaScript用来管理含糊执行上下文的一种数据结果 它记录了当前函数执行栈的位置 那个位置正在被执行 如果我们执行一个函数 就会为这个函数创建上下文并放入栈顶 如果我们从函数返回 就将他的执行上下文从栈顶弹出
懂调用栈的开发人员有哪些优势
栈溢出
我们在执行javascript的时候 有时候会出现这种情况 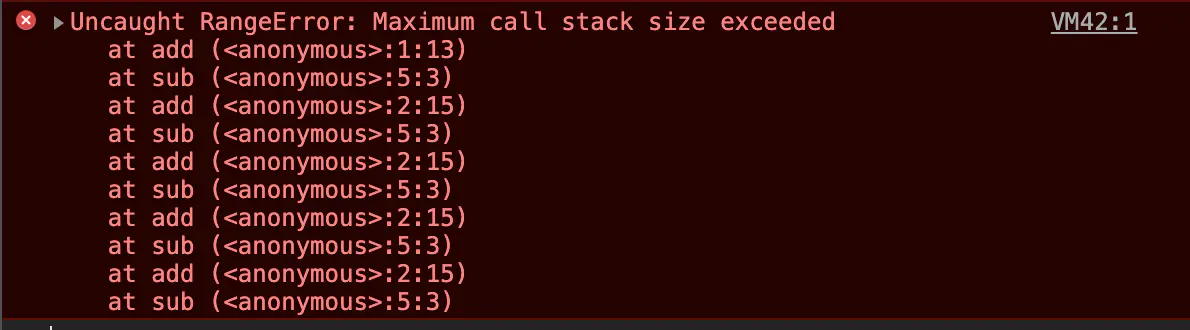
这种情况大概率出现该递归中 递归函数中
在浏览器器中获取调用栈的信息
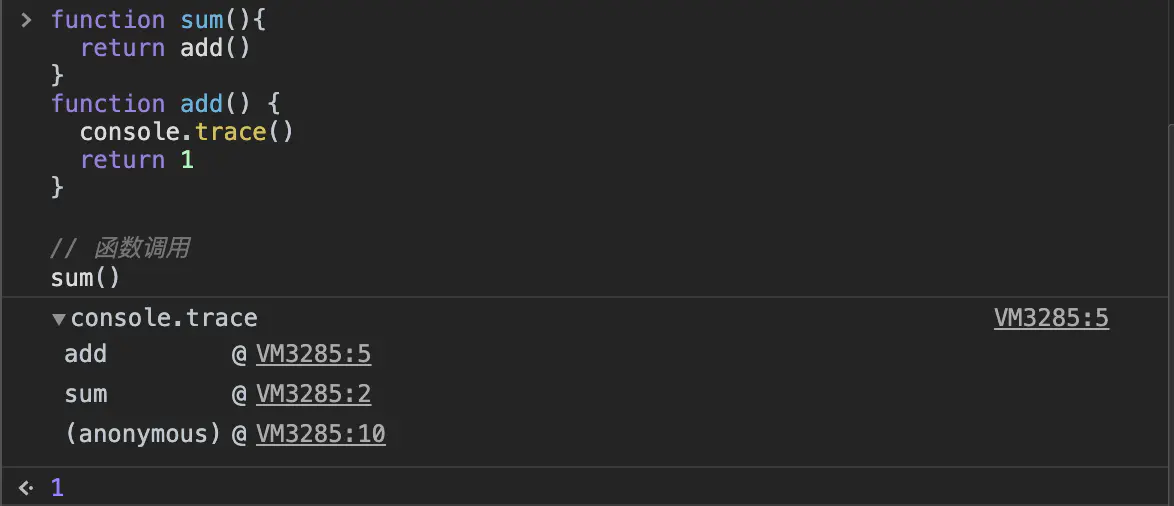
两种方式 一种是断点调试 另外一个就是console.trace()
function sum(){return add()}function add() {console.trace()return 1}// 函数调用sum()
js 的内存机制 栈(基本类型 引用类型地址) 堆(引用数据类型)
javascript的内存空间主要分为三种类型
- 代码空间 主要存放可执行的代码
- 栈空间 调用栈的存储空间就是站空间
- 堆空间

若有收获,就点个赞吧
0 人点赞
