二叉树
迭代遍历二叉树
二叉树结构:
// Definition for a binary tree node.type TreeNode struct {Val intLeft *TreeNodeRight *TreeNode}
迭代法遍历的核心:出栈节点即为当前需要遍历的节点。
- 前序遍历的出栈节点的左兄弟和父节点都应该已经遍历过(或为空);
- 中序遍历的出栈节点的左子树已经遍历过(或为空);
- 后续遍历的栈顶节点的左子树已经遍历过,用一个指针表示上一个出栈的节点,如果是从右边返回的,那么说明该节点的左右节点都已经遍历过;
func preorderTraversal(root *TreeNode) (ans []int) {if root == nil {return}stack := []*TreeNode{root}for len(stack) > 0 {root = stack[len(stack)-1]stack = stack[:len(stack)-1]for root != nil {ans = append(ans, root.Val) // 先遍历本节点if root.Right != nil {stack = append(stack, root.Right) // 右子树放入栈最后统计}root = root.Left // 遍历完本节点,遍历左子树}}return}
func inorderTraversal(root *TreeNode) (ans []int) {stack := []*TreeNode{}for root != nil || len(stack) > 0 {// 本节点入栈,先遍历左子树for root != nil {stack = append(stack, root)root = root.Left}// 回溯,出栈节点左子树为空或者已访问,遍历出栈节点root = stack[len(stack)-1]stack = stack[:len(stack)-1]ans = append(ans, root.Val)// 最后遍历右子树root = root.Right}return}
func postorderTraversal(root *TreeNode) (ans []int) {stack := []*TreeNode{}var prev *TreeNodefor root != nil || len(stack) > 0 {// 找到最左端for root != nil {stack = append(stack, root)root = root.Left}root = stack[len(stack)-1]// 如果从右子树返回或右子树为空,说明要遍历当前的节点if root.Right == prev || root.Right == nil {ans = append(ans, root.Val)stack = stack[:len(stack)-1]prev = rootroot = nil} else { // 否则先递归访问右子树root = root.Right}}return}
102.二叉树的层序遍历
使用 BFS 思想即可
二叉树还原
为什么至少要得到前、中、后序遍历中的两种才能还原二叉树?
因为无法确定空指针的位置,使得不同的二叉树可能得到同样的遍历结果。
BST
BST的基本定义?
- 左子树所有值小于根值,右子树所有值大于根值;
- 任一节点左右子树都为BST;
- 空树也为BST;
BST的特殊性质?
中序遍历有序
什么情况下使用到后续遍历?
当前节点的状态需要左右节点为依据时使用后续遍历。
二叉堆
二叉堆是一种特殊的二叉树,分为:
大顶堆,每个非叶子节点都大于等于子节点;
小顶堆,每个非叶子节点都小于等于子节点;
二叉堆一般以数组的形式存储,所以一般称为
这类数据结构一般有两个API:
- insert(),插入一个元素,具体操作是:将要插入元素放入堆底,再将元素上浮(swim)至正确位置;
- delMax()/delMin(),删除堆顶元素(删除最大/小值),将堆顶A元素与堆底B元素对调,删除A元素,最后将B元素下沉(sink)到正确位置;
sink和swim具体操作:
以大顶堆为例,为了保持大顶堆的性质,sink时应该交换两个子节点中较大的值,swim则只有一个选择。
大顶堆实现(自己写的,可能效率一般):
type Priorityqueue struct {list []int // 定义一个优先队列(大顶堆)}func (pq *Priorityqueue) swim(s int) { // 从位置s向上浮for f := (s - 1) / 2; (s != 0) && (pq.list[f] < pq.list[s]); {pq.list[f], pq.list[s] = pq.list[s], pq.list[f]s = ff = (f - 1) / 2}}func (pq *Priorityqueue) sink() {for f, p := 0, 1; p < len(pq.list); { // p指向父子节点三点中的最大点if pq.list[p] < pq.list[f] {p = f}if f*2+2 < len(pq.list) && pq.list[p] < pq.list[f*2+2] {p = f*2 + 2}if p == f {return}pq.list[f], pq.list[p] = pq.list[p], pq.list[f]f = pp = p*2 + 1}}func (pq *Priorityqueue) push(x int) {if len(pq.list) == 0 {pq.list = []int{x}} else {pq.list = append(pq.list, x)pq.swim(len(pq.list) - 1)}}func (pq *Priorityqueue) pop() {if l := len(pq.list); l != 0 {pq.list[0], pq.list[l-1] = pq.list[l-1], pq.list[0]pq.list = pq.list[:l-1]pq.sink()}}
递归
递归的原理:
在《数据结构与算法分析》中学习到了递归的实质其实就是数学归纳法,当时跟着做了证明觉得很有道理,但是半知半解。直到自己在练习使用递归实现反转链表方向时,发现了递归的巧妙之处。
type node struct {num intnext *node}func reverseList(l *node) *node {if l.next == nil {return l}last := reverseList(l.next)l.next.next = ll.next = nilreturn last}
在写递归程序时,千万不要直接跳入递归栈的深渊!人脑不是机器!
下面将递归的过程和数学归纳的过程做一个对比。
- 递归程序设计步骤:
- 确定递归基,就是递归的“出口”,保证基情况是一定正确的;
- 假设上一级递归能够实现想要的效果;
- 利用上一级实现的结果来实现本级递归;
- 数学归纳法证明步骤:
- 当n = 1时,等式成立;
- 假设n = k时,等式成立;
- 通过n = k时成立,证明n = k+1时成立;
仔细对比可以发现,递归和数学归纳的思想完全一致,递归的第三步就相当于完成归纳法第三部的证明,从而证明k项之后的程序都正确,当k = 1时,即1,2,3… n项都成立,所以无论n为几,整个程序都是正确的。
- 递归程序三要素
- 递归逻辑;
- 终止条件;
- 返回值;
分析递归问题的好帮手:递归树
比如计算斐波那契数列问题
func fib(N int) int {if N == 1 || N == 2 {return 1}return fib(N - 1) + fib(N - 2)}
列出递归树: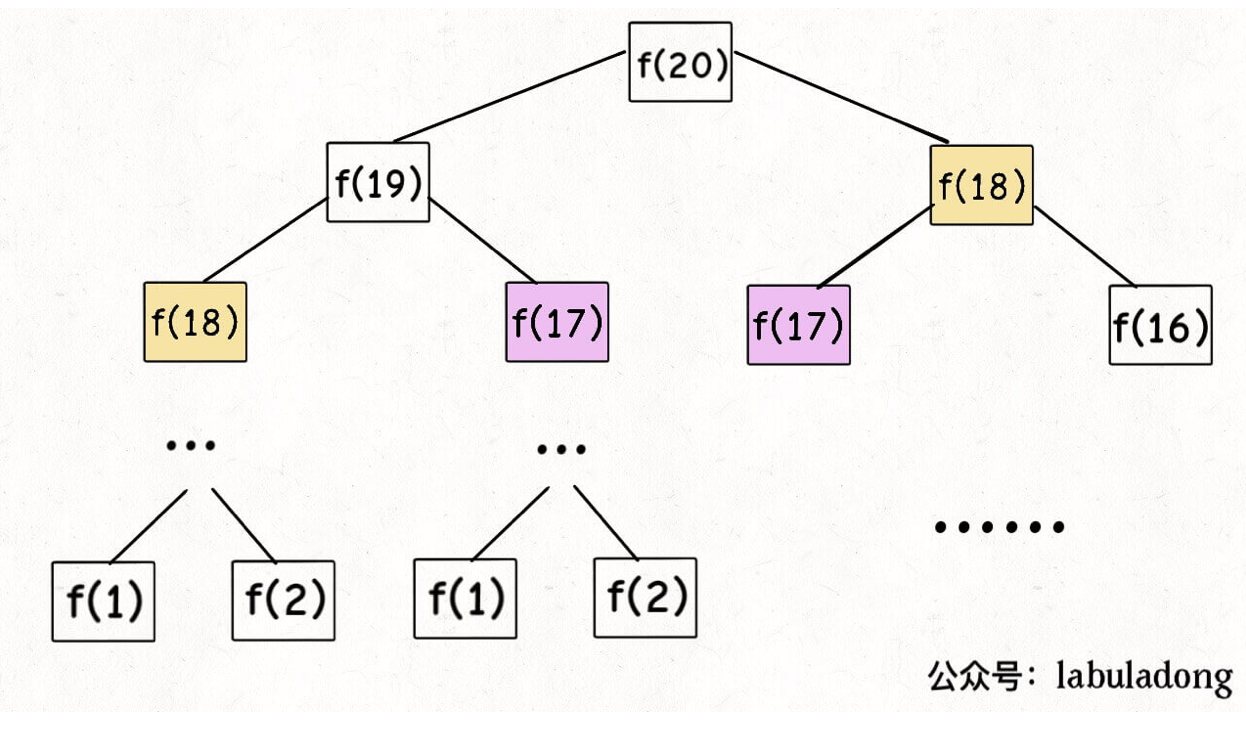
根据递归树,分析该算法的时间复杂度:
时间复杂度 = 子问题个数 * 一个子问题的运算次数
通过递归树可以清晰的看出,子问题数量为:2n-1,复杂度为O(2^n);
而单个子问题只有f(n - 1) + f(n - 2) 一个加法操作,时间为 O(1);
总体时间复杂度为O(2^n)
斐波那契算法优化:
首先明白为什么要优化。从递归树可看出,复杂度高的原因是做了很多重复计算,比如f(18)和f(17)都计算了两次。
所以优化的思路为减少重复计算,方法为使用一个“备忘录”,形式上为递归树的剪枝。将递归路径上的已经计算的节点保存下来,下次调用该节点的值时,无需继续递归的重复计算。
func fib(n int) int {recorder := make([]int, n+1) // 备忘录return helper(n, recorder)}func helper(n int, rec []int) int {if n == 0 || n == 1 {return n}if rec[n] != 0 {return rec[n]}rec[n] = helper(n-1, rec) + helper(n-2, rec)return rec[n]}
再使用递归树来分析:
可以观察到,一个庞大的递归树被剪枝成了一条单一的路径:
PS:这两种解法都不是最优解,只作为递归树的例子
回溯
什么时候使用回溯算法?
当问题可以转化为决策树的遍历时。
如全排列问题: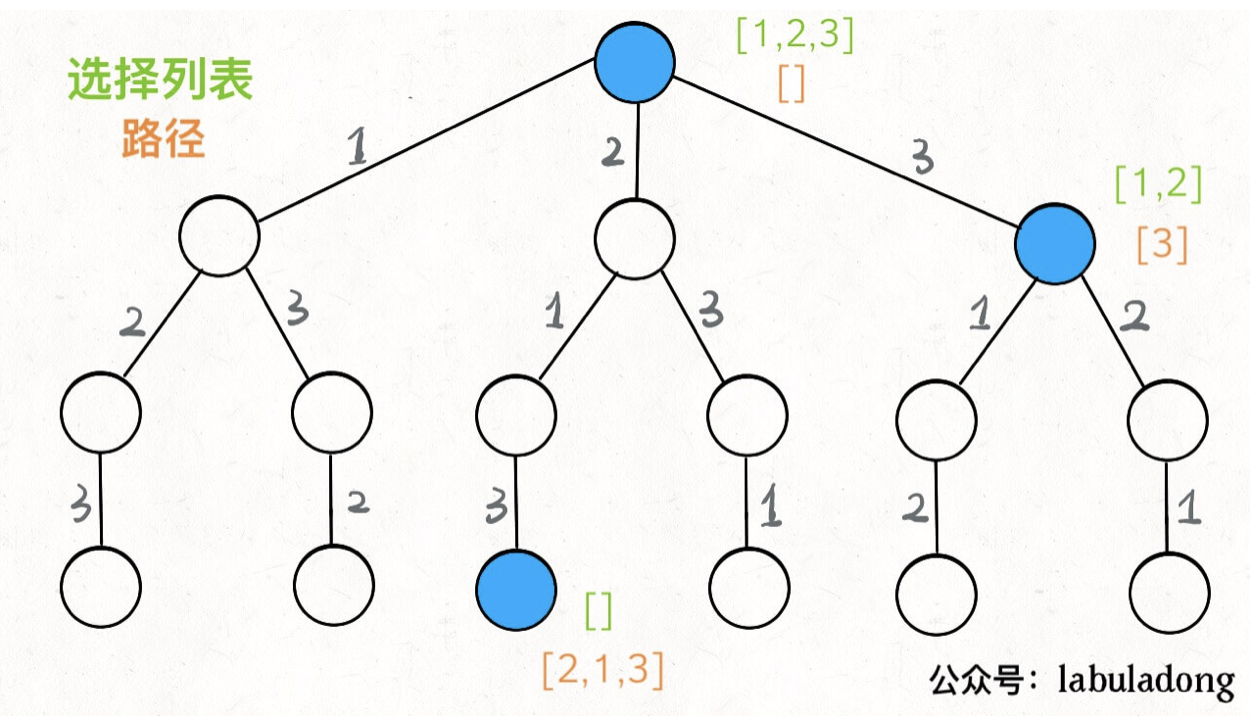
DFS的核心思想就是三个条件:
- 已走路径
- 选择列表(剪枝)
- 结束条件
贪心算法和动态规划
什么是贪心算法?和动态规划有什么关系?
- 贪心算法的思想是在对子问题求解时,通过做出对当前子问题最好的决策所形成的子结构集合正好是最优子结构,且每个子问题的求解不依赖于上一个子问题的结果,所以贪心算法不具有重叠子问题;
- 贪心算法简单高效,但是不一定正确,一般不适合贪心算法的问题通过反例可以轻松证明该问题不适合使用贪心解法;
- 动态规划也是通过将问题分解为若干个子问题,找到最优子结构从而得到全局最优解,通过数学归纳法,可以轻松证明动态规划算法的正确性;
- 虽然动态规划正确性很容易证明,但是子问题之间的依赖性强,具有很多重叠子问题,通过备忘录表的方式记录子问题的解,从而在下一次需要重复计算子问题时,直接查表,以空间换时间;
所以通过以上分析,在面对问题时如何选取正确的解法呢?
如果能证明贪心是错误的,则选用动态规划,否则用贪心。
动态规划问题的核心(括号内内容为对应数学归纳法的内容):
- 状态的定义( f(x)的定义 )
- 初始状态( 保证f(0)正确 )
- 状态转移方程( 通过f(k-1)得到f(k) )
分治
核心思想:
将原问题不断分解为规模更小的子问题,知道子问题可以直接求解,最后根据将子问题汇总得出原问题答案。一个典型的实例就是归并排序。
BFS
BFS节点的3种状态:
- 未探索
- 已探索未扩展探索(没有探索该节点周围节点)
- 已探索且已扩展探索
图
拓扑排序
一般用来判断有无循环依赖,步骤为:
- 使用邻接表来存储
- 统计各节点的入度
- 从入度为 0 的节点开始迭代并统计入度为0的节点个数,直到所有点都迭代过一次
- 如果最后入度为 0 的节点等于总节点数,说明没有循环依赖
摩尔投票
核心思想:
从头至尾,对拼消耗。最差情况是每个非众数都用来抵消众数,由于众数占一半以上,所以即使是最坏情况也成立。Knuth洗牌算法
什么是洗牌算法?
将一个序列随机打乱。
什么才算公平的洗牌算法?
假设总元素为n个,每个元素位于每个位置的概率都为1/n。
Knuth算法实现:
rand.Seed(time.Now().Unixnano())for i := n-1; i >= 0; i-- {j := rand.Intn(i+1)s[i], s[j] = s[j], s[i]}
如何验证算法的正确性?
假设总共有5个元素,逐个分析:
对于第五个位置,显而易见,每个元素位于最后一个位置的概率为1/5;
对于第四个位置,每个元素没被选到第五个位置但是被选到第四个位置的概率为4/5 1/4 = 1/5;
对于第三个位置,每个元素没被选到最后两个位置但是被选到第三个位置的概率为3/5 1/3 = 1/5;
…
从而可以证明,每个元素位于每个位置的概率都为1/5 。
快速划分(快速选择)
解决问题类型:
快速找出一个数组中最大或最小的k个数。
核心思想:
利用快排的思想,进行一次快排交换后,返回分界节点x。
如果x等于k-1,则0~x为最小(大)的k个元素;
如果x小于k-1,则对[x+1:]进行划分;
如果x大于k-1,则对[:x]进行划分。
时间复杂度分析:
- 最坏情况下,比如一个有n个元素的递增数组,求其最小的n个元素,每次划分的比较次数为:n-1,n-2……2, 1. 共划分n-1次,复杂度为O(n^2);
- 平均情况下,每次划分的元素位置为n/2,每次划分的元素数量为n,n/2,n/2^2……1,最多进行logn次划分,复杂度为O(n);
为了保持高效,避免最坏情况的发生,最好在快速选择之前使用洗牌算法将数组打乱。
单调栈/单调队列
单调栈是一个普通栈的辅助栈,当普通栈在pop和push时,单调栈的top始终维护当前普通栈中元素的最小/最大值,易知单调栈中的元素也应该是非严格递减/递增。
在解决滑动窗口的最值问题时,由于滑动窗口具有头加入和尾删除的特性,和队列的特性一致,因此考虑使用单调队列。
位运算
异或运算满足交换律,且相等的数异或后为0,0和任何数异或等于任何数。
二分查找
二分查找的前提是数组有序,无序数组别直接搁这二分,开始就错了。所以以下数组默是不存在递减子序列的序列。
简洁写出二分的技巧在于对中间节点指针 m 大小准确拿捏:
- m = (l + r) / 2,m = l + (r - l) / 2 等价,不知道为什么那么多人写后面这种,多一次运算看着难受;
- 三个判断条件的二分不但看着烦还容易出错,以论证如何实现两个判断条件的简洁且不容易出错的二分;
- 首先要知道,在 l < r 的情况下,m 一定小于 r,但是 m 可能等于 l (当 l + 1 = r 时);
- l 在什么情况下会等于 r 从而跳出循环呢?基于上面一点,l < r 时,l = m < r,所以对 l 来说,需要 l = m + 1 的操作才能主动跳出循环,对于 r 来说,r = m就能保证迭代正常运转,为什么不用 r = m - 1 呢?先看第5点;
- 比如寻找一个数 target,如果 num[m] < target,说明 [l, m] 是要排除的区间,用 l = m + 1进行直接排除;如果 num[m] >= target,说明 m 指针可能是需要的结果,但是[m+1, r] 是要排除的区间,用 r = m 来排除,这里解决了第4点的疑惑,如果 r = m - 1,可能将 m 指向的可能的正确结果排除掉了;
- 循环结束的最后一次迭代有两种情况,一是 r - l = 2 情况下,l = m + 1 = r ;二是 l + 1 = r 的情况下 l = m + 1 = r 或者 r = m = l;当 r - l > 2 时,将需要不止一次迭代,所以最后一次迭代一定时前两种情况,而前两种情况最终结果都是 l == r;
- 第4点论证了循环的顺利结束,第5点论证了算法的正确性,第6点论证了循环结束时 l == r。所以当循环结束时,l 和 r 都代表正确解,如果 l 和 r 不是正确解,则说明正确解不存在。
拿捏了 m 指针,写出简洁漂亮无误的二分就很简单了,下面提供几个不同目标的二分模板:
从左向右查找等于第一个等于或者大于且最接近 target 的值的下标
func binarytSerach(nums []int, target int) int {l, r := 0, len(nums)-1for l < r {m := (l + r) >> 1if nums[m] < target {l = m + 1} else {r = m}}return l}
查找小于且最接近 target 的值的下标:
func binarytSerach(nums []int, target int) int {l, r := 0, len(nums)-1for l < r {m := (l + r) >> 1if nums[m] < target {l = m + 1} else {r = m}}return l - 1 // 可能返回负数}
查找第一个大于 target 的值的下标:
func binarytSerach(nums []int, target int) int {l, r := 0, len(nums)for l < r {m := (l + r) >> 1if nums[m] <= target {l = m + 1} else {r = m}}return l // l 可能等于 len(nums)}
KMP
首先要明白什么是字符串的前缀和后缀,举个例子就明白了:
- aabaac
- 前缀:包含首字符不包含尾字符的所有子串,a、aa、aaba、aabaa
- 后缀:包含尾字符不包含首字符的所有子串,c、ac、aac、baac、abaac
其次要知道什么是最长公共前后缀,还以上为例:
- a:没有公共前后缀,0
- aa:a,1
- aab:无,0
- aaba:a,1
- aabaa:aa,2
- aabaac:无,0
后续的数字为最长公共前后缀的长度,这样一个长度集合[]int{0,1,0,1,2,0}称为前缀表。
func strStr(haystack, needle string) int {nLen, hLen := len(needle), len(haystack)// 创建 next 数组next := make([]int, nLen)for i, j := 1, 0; i < nLen; i++ { // i 指向后缀的最后, j 指向前缀的最后for j > 0 && needle[i] != needle[j] {j = next[j-1]}if needle[i] == needle[j] {j++}next[i] = j}// 进行匹配for i, j := 0, 0; i < hLen; i++ {for j > 0 && needle[j] != haystack[i] {j = next[j-1]}if needle[j] == haystack[i] {j++}if j == nLen {return i - nLen + 1}}return -1}

若有收获,就点个赞吧
0 人点赞
