参考资料
- https://blog.csdn.net/u012835097/article/details/79407591 -哈希函数
- https://www.cnblogs.com/huxianglin/p/6925119.html -go heap解析
- https://www.cnblogs.com/sench/p/7786718.html -AVL
- https://www.cnblogs.com/skywang12345/p/3245399.html - RBT
- https://baike.sogou.com/v66237892.htm Trie Tree
- https://www.liwenzhou.com/posts/Go/read_gin_sourcecode/#autoid-0-0-0 Radix Tree
哈希
为什么需要哈希?
通过一次哈希运算,大幅缩小关键字的查找范围;原理是使用哈希函数将随机存储优化为有逻辑的存储。
哈希函数有哪几种类型?
- 直接定址法:通过一个线性函数直接映射;
- 除留余数法:将key对某个不大于散列表长度的数p取余得到散列地址;
- 随机数法:通过一个随机函数,key的随机函数值为散列地址;n
如何解决哈希冲突?
- 拉链法
将散列定义为一个指针数组,数组的每个元素为一个链表的头指针,每个链表存储相同哈希值的数据。
Java 的 hashmap 使用的就是拉链法(链地址法)。
- 开放定址法
产生冲突时,通过某种方式在散列表中寻找下一个为空的散列地址。
- 线性探查法:从冲突位置的下一个位置开始循环遍历散列表;
- 双重散列法:再使用一个哈希函数对地址进行运算,再加上原地址后除以余数;
python 的 dict 就是使用的开放定址法。
什么是哈希桶?
一个哈希桶就是拉链法中一个数组元素即一个头指针指向的一个链表。
什么是加载因子?加载因子大小对哈希表有什么影响?
加载因子 = 已存储的数据长度 / 散列表的容量,当加载因子超过指定值,哈希表将扩容。
加载因子过大:产生哈希冲突的概率太高;
加载因子过小:空间利用率太小,扩容操作过于频繁;
除了哈希表,哈希还有什么应用?
分布式存储:一致性哈希算法(参考前沿知识库)
堆
二叉堆是一种特殊的二叉树,分为:
大顶堆,每个非叶子节点都大于等于子节点;
小顶堆,每个非叶子节点都小于等于子节点;
二叉堆一般以数组的形式存储。
这类数据结构一般有两个API:
- Push(),插入一个元素,具体操作是:将要插入元素放入堆底(数组的最后),再将元素上浮(swim)至正确位置;
- Pop(),删除堆顶元素(删除最大/小值),具体操作是:将堆顶A元素与堆底B元素对调,再删除A元素,最后将B元素下沉(sink)到正确位置;
为什么堆的结构近似一个完全二叉树?
因为每次Pop()都是将元素插入数组的最后,也就是二叉树最底层的第一个空位。而其他操要么是首尾交换后删除最后一个元素,要么是交换元素,所以总能维持一个近似的完全二叉树结构。
sink和swim具体操作:
以大顶堆为例,为了保持大顶堆的性质,sink时应该交换两个子节点中较大的值,swim则只有一个选择(因为只有一个父节点)。
大顶堆实现(自己写的,可能效率一般,并且没有错误处理,重在思想):
type hp struct {l []int}// 从最后一个位置上浮func (h *hp) swim() {idx := len(h.l)-1for f := (idx-1)/2; idx > 0 && h.l[f] > h.l[idx]; f = (idx-1)/2 {h.l[f], h.l[idx] = h.l[idx], h.l[f]idx = f}}// 从 root 下沉func (h *hp) sink() {root, end := 0, len(h.l)-1for {maxChild := root * 2 + 1 // maxChild指向子节点中较大的一个if maxChild > end {return}if maxChild + 1 <= end && nums[maxChild] < nums[maxChild+1] {maxChild++}if nums[root] > nums[maxChild] {return}nums[root], nums[maxChild] = nums[maxChild], nums[root]root = maxChild}}func (h *hp) pop() int {h.l[0], h.l[len(h.l)-1] = h.l[len(h.l)-1], h.l[0]ans := h.l[len(h.l)-1]h.l = h.l[:len(h.l)-1]h.sink()return ans}func (h *hp) push(x int) {h.l = append(h.l, x)h.swim()}
建堆时间复杂度
假设建成的堆为高度为h的完全二叉树
总节点数 N = 1 + 2 + 2^2 + … + 2^(h-1) = 2^h - 1
则高度 h = log(n+1)
倒数第二层有2^(h-2)个节点,从底部到达该层最多需要swim一次;倒数第三层有2^(h-3),最多swim两次……倒数第h层(根节点)有1个,最多swim (h-1) 次.
sum = 2h-2 * 1 + 2h-3 * 2 + ...... + 22 * (h-2) + 21 * (h-1)2 sum = 2h-1 1 + 2h-2 2 + 2h-3 3 + …… + 22 * (h-1)
错位相减求和可得:sum = 2^h - 1 - h = n - log(n+1) = O(n)
AVL
- AVL具有BST的性质
- AVL每个节点的平衡因子(左子树和右子树之差)的绝对值不大于12
旋转
什么是AVL的旋转?
AVL的插入和删除操作可能会影响AVL的平衡,所以在每次插入和删除之后或之前都会检查是否会出现不平衡的节点,找到距离插入或删除元素最近的失衡节点,对其进行旋转操作,以重新获得平衡。
旋转分为哪几种类型?分别怎么进行?
- LL型
 →
→ 
插入节点1导致失衡,最近失衡节点5的左子树的左子树发生插入操作,称为LL型。
旋转步骤为:
将左子树作为根节点,原根节点作为右子树,左子树的右子树作为原根节点的左节点
- RR型
与LL对称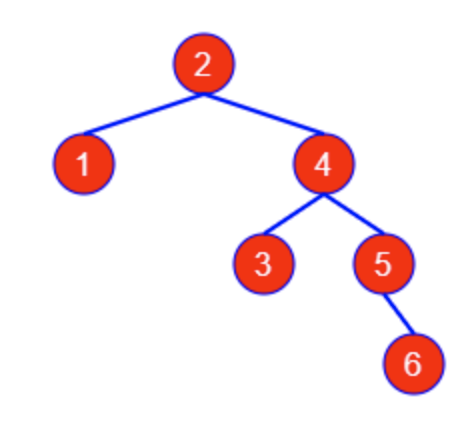 →
→ 
- LR型
需要先对失衡节点进行左旋变为LL型,再进行右旋。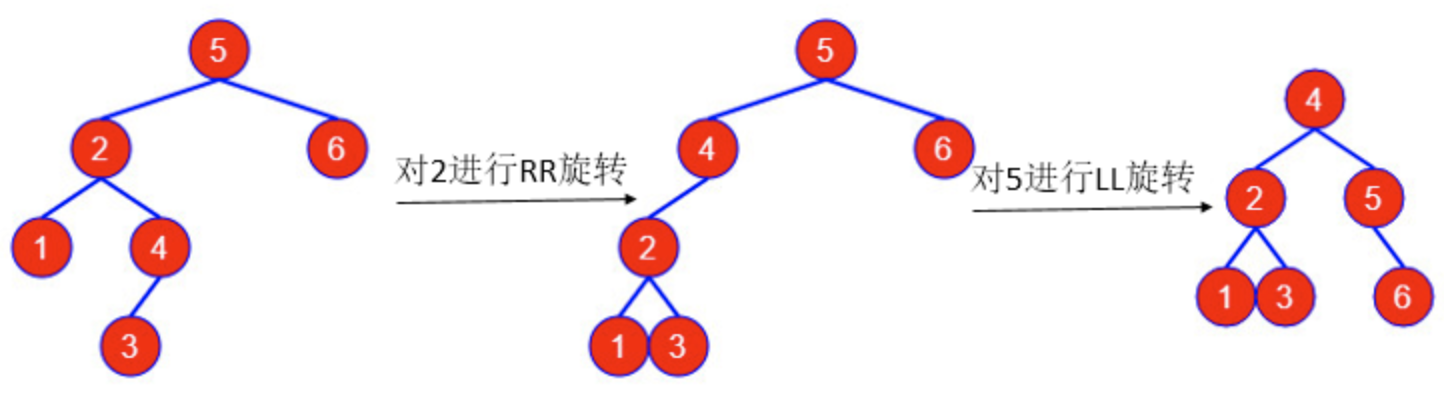
- RL型
与LR型对称,先进行右旋转化为RR型,再进行左旋。
红黑树
性质:
- 节点要么红要么黑
- 根节点为黑
- 叶子节点(叶子节点都是空节点)一定为黑
- 红节点的子节点一定为黑
- 从一个节点到任意一个叶子节点路径上的黑节点一定相同

(注意叶子节点都为空)
后面的插入删除操作以后再复习
前缀树(字典树) -Trie Tree

性质:
- 根节点不包含节点
- 存储字符串的最后一个节点标记为红色
- 每个节点的子节点不包含重复元素
从以上性质可知:从根节点到某个红色节点所经过的路径为该树存储的一个字符串。
应用领域:


若有收获,就点个赞吧
0 人点赞
