注意:通配符和正则表达式(元字符)是两个不同的概念,前者是针对文件或目录名称的,后者多用于文件内容。
grep
-i 忽略大小写
—color 匹配的显示颜色
-v 反向查找
-o 只显示被匹配的字符
-E 使用扩展正则表达式 grep -E =egrep;fgrep不支持正则表达式,执行速度快。
-A
元字符
默认情况下正则表达式工作在贪婪模式下(尽可能匹配更长的结果)
.:匹配任意单个字符
:任意长度的任意字符。ab,a可以出现任意次数
.:匹配任意长度的任意字符
[]:匹配指定范围内的任意单个字符
[^]:匹配指定范围外的任意单个字符
\?:匹配其前面的字符1次或0次
{m,n}:匹配其前面的字符至少m次,至多n次
^:匹配以什么开头的字符
$:匹配以什么结尾的字符
^$:匹配空白行
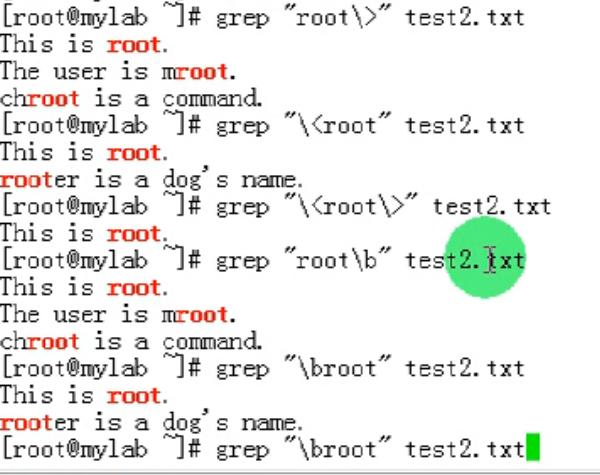
\<:锚定词首,其后面的任意字符必须作为单词首部出现
>:锚定词尾,其前面的任意字符必须作为单词的尾部出现
(ab):把ab作为一个整体,ab可以出现任意次。后向引用,\1:引用第一个左括号以及与之对应的右括号所包括的所有内容

REGXPR: REGular EXPression
正则表达式:
基本正则表达式
扩展正则表达式
扩展正则表达式
字符匹配:
.
[]
[^]
次数匹配:
*
?
+:匹配其前面的字符至少1次
{m,n}:和正则表达式不同,不用加\
位置锚定:
^
$
\<
>
分组:
():分组
或者
| : C|cat 匹配 C或者cat

若有收获,就点个赞吧
0 人点赞
